
【Python】Pandas技巧:groupby+agg/transform
公眾號:尤而小屋
作者:Peter
編輯:Peter
本文介紹的是分組groupby分組之后如何使用agg和transform

模擬數(shù)據(jù)
import pandas as pd
import numpy as np
employees = ["小明","小周","小孫","小王","小張"] # 5位員工
time = ["上半年", "下半年"]
df=pd.DataFrame({
"employees":np.random.choice(employees,10), # 在員工中重復(fù)選擇10次
# 另一種寫法
#"employees":[employees[x] for x in np.random.randint(0,len(employees),10)],
"time":np.random.choice(time,10),
"salary":np.random.randint(800,1000,10), # 800-1000之間的薪資選擇10個(gè)數(shù)值
"score":np.random.randint(6,12,10) # 6-11的分?jǐn)?shù)選擇10個(gè)
})
df
| employees | time | salary | score | |
|---|---|---|---|---|
| 0 | 小周 | 上半年 | 873 | 11 |
| 1 | 小王 | 下半年 | 818 | 10 |
| 2 | 小王 | 下半年 | 804 | 6 |
| 3 | 小張 | 下半年 | 811 | 7 |
| 4 | 小張 | 上半年 | 955 | 10 |
| 5 | 小張 | 上半年 | 975 | 11 |
| 6 | 小明 | 上半年 | 858 | 9 |
| 7 | 小明 | 上半年 | 993 | 11 |
| 8 | 小王 | 上半年 | 841 | 8 |
| 9 | 小王 | 下半年 | 967 | 7 |
groupby+單個(gè)字段+單個(gè)聚合
求解每個(gè)人的總薪資金額:
total_salary = df.groupby("employees")["salary"].sum().reset_index()
total_salary
| employees | salary | |
|---|---|---|
| 0 | 小周 | 873 |
| 1 | 小張 | 2741 |
| 2 | 小明 | 1851 |
| 3 | 小王 | 3430 |
使用agg也能夠?qū)崿F(xiàn)上面的效果:
df.groupby("employees").agg({"salary":"sum"}).reset_index()
| employees | salary | |
|---|---|---|
| 0 | 小周 | 873 |
| 1 | 小張 | 2741 |
| 2 | 小明 | 1851 |
| 3 | 小王 | 3430 |
df.groupby("employees").agg({"salary":np.sum}).reset_index()
| employees | salary | |
|---|---|---|
| 0 | 小周 | 873 |
| 1 | 小張 | 2741 |
| 2 | 小明 | 1851 |
| 3 | 小王 | 3430 |
groupby+單個(gè)字段+多個(gè)聚合
求解每個(gè)人的總薪資金額和薪資的平均數(shù):
方法1:使用groupby+merge
mean_salary = df.groupby("employees")["salary"].mean().reset_index()
mean_salary
| employees | salary | |
|---|---|---|
| 0 | 小周 | 873.000000 |
| 1 | 小張 | 913.666667 |
| 2 | 小明 | 925.500000 |
| 3 | 小王 | 857.500000 |
然后將上面的兩個(gè)結(jié)果進(jìn)行組合;在合并之前為了字段的名字更加的直觀,我們重命名下:
total_salary.rename(columns={"employees":"total_salary"})
mean_salary.columns = ["employees","mean_salary"]
total_mean = total_salary.merge(mean_salary)
total_mean
| employees | salary | mean_salary | |
|---|---|---|---|
| 0 | 小周 | 873 | 873.000000 |
| 1 | 小張 | 2741 | 913.666667 |
| 2 | 小明 | 1851 | 925.500000 |
| 3 | 小王 | 3430 | 857.500000 |
方法2:使用groupby+agg
total_mean = df.groupby("employees")\
.agg(total_salary=("salary", "sum"),
mean_salary=("salary", "mean"))\
.reset_index()
total_mean
| employees | total_salary | mean_salary | |
|---|---|---|---|
| 0 | 小周 | 873 | 873.000000 |
| 1 | 小張 | 2741 | 913.666667 |
| 2 | 小明 | 1851 | 925.500000 |
| 3 | 小王 | 3430 | 857.500000 |
groupby+多個(gè)字段+單個(gè)聚合
針對多個(gè)字段的同時(shí)聚合:
df.groupby(["employees","time"])["salary"].sum().reset_index()
| employees | time | salary | |
|---|---|---|---|
| 0 | 小周 | 上半年 | 873 |
| 1 | 小張 | 上半年 | 1930 |
| 2 | 小張 | 下半年 | 811 |
| 3 | 小明 | 上半年 | 1851 |
| 4 | 小王 | 上半年 | 841 |
| 5 | 小王 | 下半年 | 2589 |
# 使用agg來實(shí)現(xiàn)
df.groupby(["employees","time"]).agg({"salary":"sum"}).reset_index()
| employees | time | salary | |
|---|---|---|---|
| 0 | 小周 | 上半年 | 873 |
| 1 | 小張 | 上半年 | 1930 |
| 2 | 小張 | 下半年 | 811 |
| 3 | 小明 | 上半年 | 1851 |
| 4 | 小王 | 上半年 | 841 |
| 5 | 小王 | 下半年 | 2589 |
groupby+多個(gè)字段+多個(gè)聚合
使用的方法是:
agg(’新列名‘=(’原列名‘, ’統(tǒng)計(jì)函數(shù)/方法‘))
df.groupby(["employees","time"])\
.agg(total_salary=("salary", "sum"),
mean_salary=("salary", "mean"),
total_score=("score", "sum")
)\
.reset_index()
| employees | time | total_salary | mean_salary | total_score | |
|---|---|---|---|---|---|
| 0 | 小周 | 上半年 | 873 | 873.0 | 11 |
| 1 | 小張 | 上半年 | 1930 | 965.0 | 21 |
| 2 | 小張 | 下半年 | 811 | 811.0 | 7 |
| 3 | 小明 | 上半年 | 1851 | 925.5 | 20 |
| 4 | 小王 | 上半年 | 841 | 841.0 | 8 |
| 5 | 小王 | 下半年 | 2589 | 863.0 | 23 |
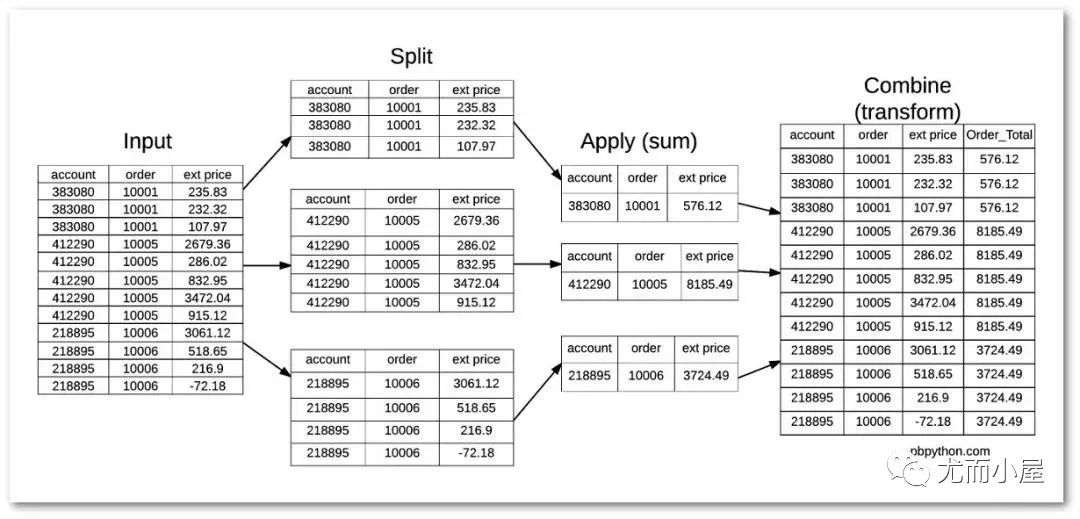
groupby+transform
關(guān)于transform函數(shù)的使用請參考(建議一定要看):Pandas高階函數(shù)transform使用機(jī)制
一張關(guān)于transform函數(shù)的備忘錄:
往期精彩回顧
適合初學(xué)者入門人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請掃碼
評論
圖片
表情