
掌握pandas中的transform

點(diǎn)擊上方"藍(lán)字"關(guān)注我們
記錄? ?分享? ?成長(zhǎng)
?本文示例代碼及文件已上傳至我的
?Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡(jiǎn)介
開門見山,在pandas中,transform是一類非常實(shí)用的方法,通過它我們可以很方便地將某個(gè)或某些函數(shù)處理過程(非聚合)作用在傳入數(shù)據(jù)的每一列上,從而返回與輸入數(shù)據(jù)形狀一致的運(yùn)算結(jié)果。
本文就將帶大家掌握pandas中關(guān)于transform的一些常用使用方式。

2 pandas中的transform
在pandas中transform根據(jù)作用對(duì)象和場(chǎng)景的不同,主要可分為以下幾種:
2.1 transform作用于Series
當(dāng)transform作用于單列Series時(shí)較為簡(jiǎn)單,以前段時(shí)間非常流行的「企鵝數(shù)據(jù)集」為例:
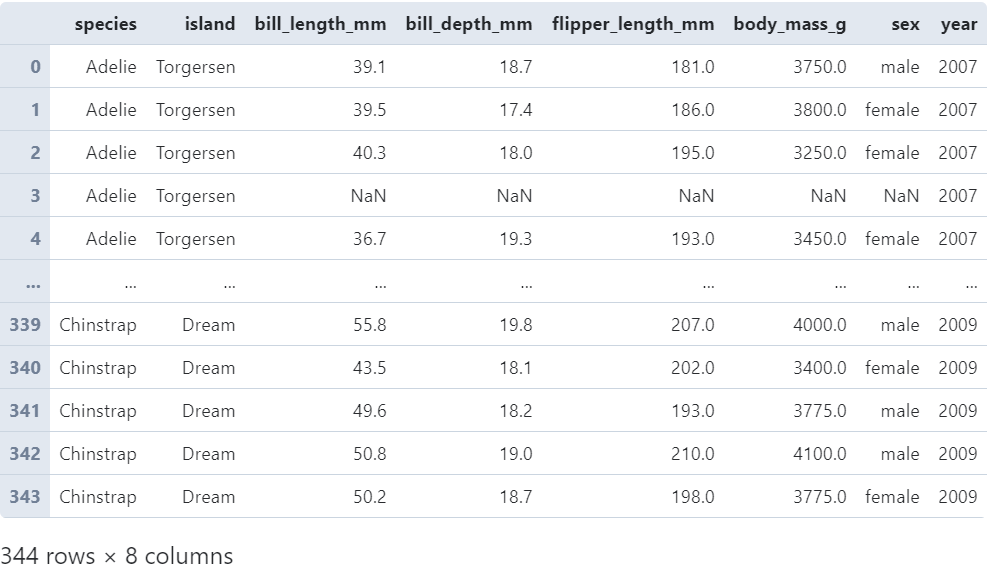
我們?cè)谧x入數(shù)據(jù)后,對(duì)bill_length_mm列進(jìn)行transform變換:
「單個(gè)變換函數(shù)」
我們可以傳入任意的非聚合類函數(shù),譬如對(duì)數(shù)化:
#?對(duì)數(shù)化
penguins['bill_length_mm'].transform(np.log)
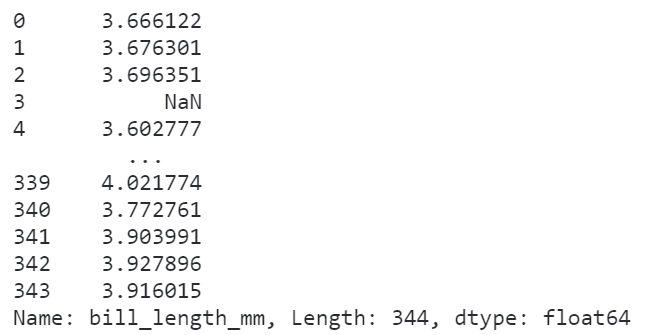
或者傳入「lambda」函數(shù):
#?lambda函數(shù)
penguins['bill_length_mm'].transform(lambda?s:?s+1)

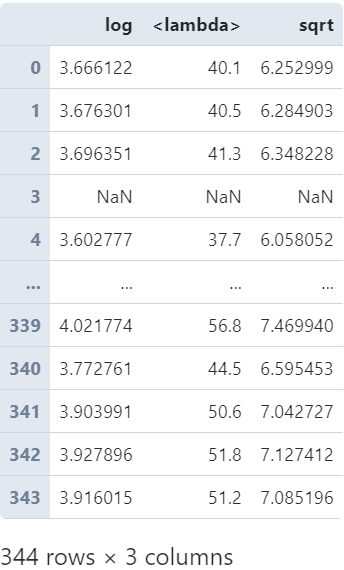
「多個(gè)變換函數(shù)」
也可以傳入包含多個(gè)變換函數(shù)的「列表」來一口氣計(jì)算出多列結(jié)果:
penguins['bill_length_mm'].transform([np.log,?
??????????????????????????????????????lambda?s:?s+1,?
??????????????????????????????????????np.sqrt])
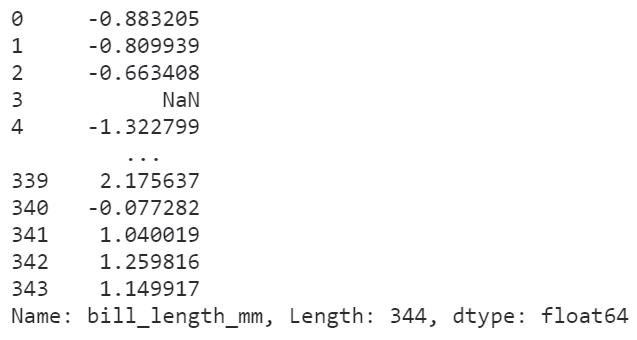
而又因?yàn)?code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;overflow-wrap: break-word;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">transform傳入的函數(shù),在執(zhí)行運(yùn)算時(shí)接收的輸入?yún)?shù)是對(duì)應(yīng)的「整列數(shù)據(jù)」,所以我們可以利用這個(gè)特點(diǎn)實(shí)現(xiàn)諸如「數(shù)據(jù)標(biāo)準(zhǔn)化」、「歸一化」等需要依賴樣本整體統(tǒng)計(jì)特征的變換過程:
#?利用transform進(jìn)行數(shù)據(jù)標(biāo)準(zhǔn)化
penguins['bill_length_mm'].transform(lambda?s:?(s?-?s.mean())?/?s.std())
2.2 transform作用于DataFrame
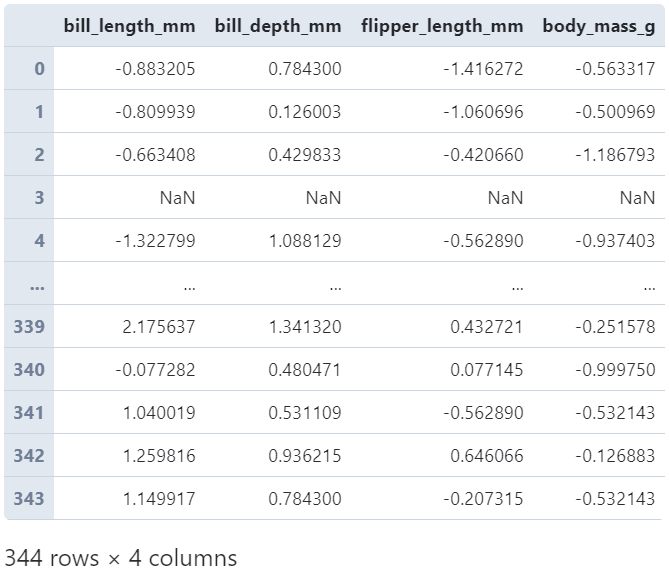
當(dāng)transform作用于整個(gè)DataFrame時(shí),實(shí)際上就是將傳入的所有變換函數(shù)作用到每一列中:
#?分別對(duì)每列進(jìn)行標(biāo)準(zhǔn)化
(
????penguins
????.loc[:,?'bill_length_mm':?'body_mass_g']
????.transform(lambda?s:?(s?-?s.mean())?/?s.std())
)
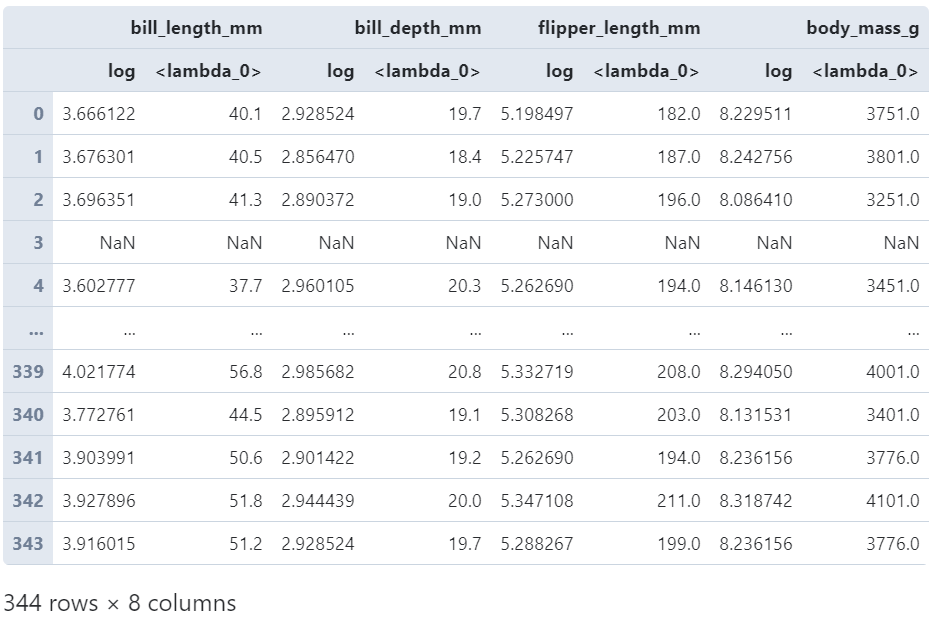
而當(dāng)傳入多個(gè)變換函數(shù)時(shí),對(duì)應(yīng)的返回結(jié)果格式類似agg中的機(jī)制,會(huì)生成MultiIndex格式的字段名:
(
????penguins
????.loc[:,?'bill_length_mm':?'body_mass_g']
????.transform([np.log,?lambda?s:?s+1])
)
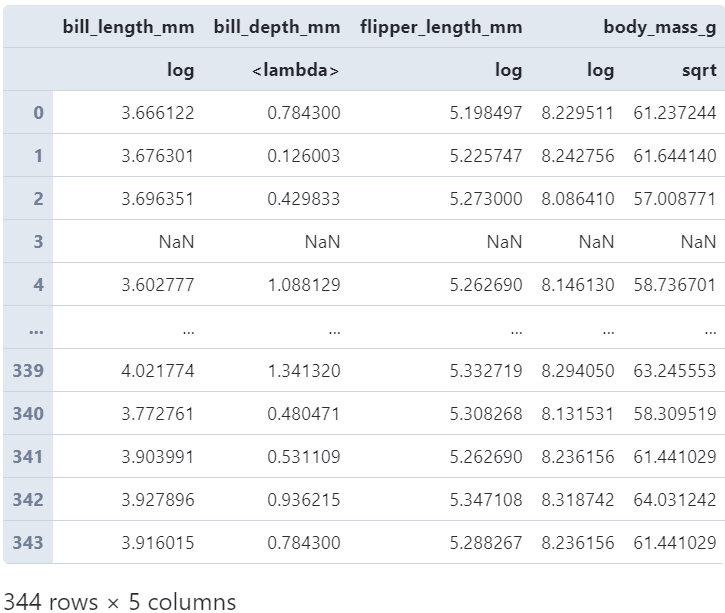
而且由于作用的是DataFrame,還可以利用字典以鍵值對(duì)的形式,一口氣為每一列配置單個(gè)或多個(gè)變換函數(shù):
#?根據(jù)字典為不同的列配置不同的變換函數(shù)
(
????penguins
????.loc[:,?'bill_length_mm':?'body_mass_g']
????.transform({'bill_length_mm':?np.log,
????????????????'bill_depth_mm':?lambda?s:?(s?-?s.mean())?/?s.std(),
????????????????'flipper_length_mm':?np.log,
????????????????'body_mass_g':?[np.log,?np.sqrt]})
)
2.3 transform作用于DataFrame的分組過程
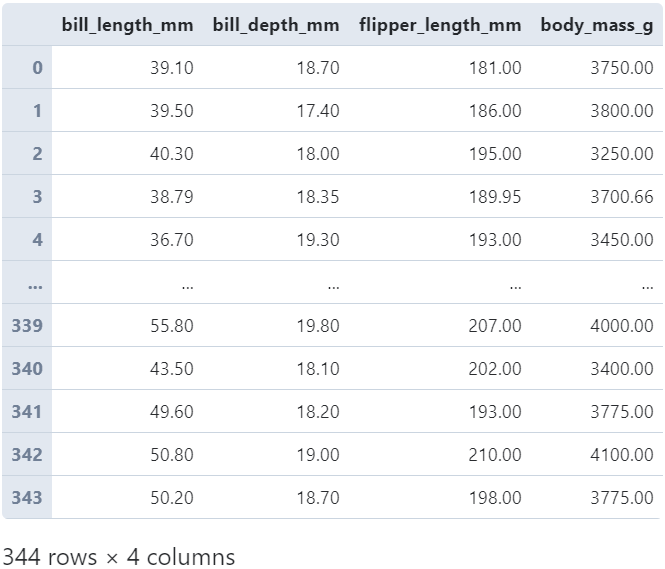
在對(duì)DataFrame進(jìn)行分組操作時(shí),配合transform可以完成很多有用的任務(wù),譬如對(duì)缺失值進(jìn)行填充時(shí),根據(jù)分組內(nèi)部的均值進(jìn)行填充:
#?分組進(jìn)行缺失值均值填充
(
????penguins
????.groupby('species')[['bill_length_mm',?'bill_depth_mm',?
?????????????????????????'flipper_length_mm',?'body_mass_g']]
????.transform(lambda?s:?s.fillna(s.mean().round(2)))
)
并且在pandas1.1.0版本之后為transform引入了新特性,可以配合Cython或Numba來實(shí)現(xiàn)更高性能的數(shù)據(jù)變換操作,詳細(xì)的可以閱讀( https://github.com/pandas-dev/pandas/pull/32854 )了解更多。
除了以上介紹的內(nèi)容外,transform還可以配合時(shí)間序列類的操作譬如resample等,功能都大差不差,感興趣的朋友可以自行了解。
以上就是本文的全部?jī)?nèi)容,歡迎在評(píng)論區(qū)與我進(jìn)行討論~
加入我們的知識(shí)星球【Python大數(shù)據(jù)分析】
愛上數(shù)據(jù)分析!

在pandas中利用hdf5高效存儲(chǔ)數(shù)據(jù)
Python大數(shù)據(jù)分析
data creates?value
掃碼關(guān)注我們