
這些年背過的面試題——Kafka篇

阿里妹導(dǎo)讀
Why kafka
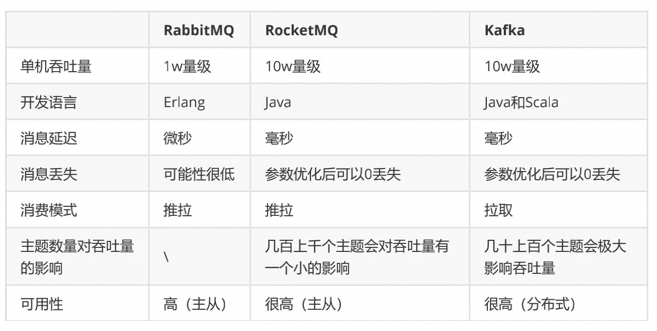
輕量級,快速,部署使用方便
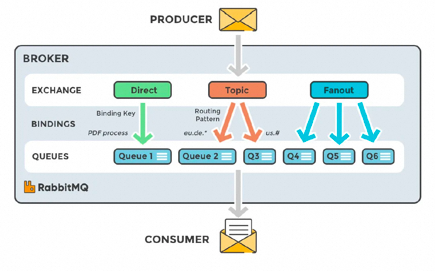
支持靈活的路由配置。RabbitMQ中,在生產(chǎn)者和隊列之間有一個交換器模塊。根據(jù)配置的路由規(guī)則,生產(chǎn)者發(fā)送的消息可以發(fā)送到不同的隊列中。路由規(guī)則很靈活,還可以自己實現(xiàn)。
RabbitMQ的客戶端支持大多數(shù)的編程語言,支持AMQP協(xié)議。
如果有大量消息堆積在隊列中,性能會急劇下降
每秒處理幾萬到幾十萬的消息。如果應(yīng)用要求高的性能,不要選擇RabbitMQ。
RabbitMQ是Erlang開發(fā)的,功能擴(kuò)展和二次開發(fā)代價很高。
RocketMQ主要用于有序,事務(wù),流計算,消息推送,日志流處理,binlog分發(fā)等場景。
經(jīng)過了歷次的雙11考驗,性能,穩(wěn)定性可靠性沒的說。
java開發(fā),閱讀源代碼、擴(kuò)展、二次開發(fā)很方便。
對電商領(lǐng)域的響應(yīng)延遲做了很多優(yōu)化。
每秒處理幾十萬的消息,同時響應(yīng)在毫秒級。如果應(yīng)用很關(guān)注響應(yīng)時間,可以使用RocketMQ。
性能比RabbitMQ高一個數(shù)量級。
支持死信隊列,DLX 是一個非常有用的特性。它可以處理異常情況下,消息不能夠被消費(fèi)者正確消費(fèi)而被置入死信隊列中的情況,后續(xù)分析程序可以通過消費(fèi)這個死信隊列中的內(nèi)容來分析當(dāng)時所遇到的異常情況,進(jìn)而可以改善和優(yōu)化系統(tǒng)。
Kafka高效,可伸縮,消息持久化。支持分區(qū)、副本和容錯。
對批處理和異步處理做了大量的設(shè)計,因此Kafka可以得到非常高的性能。
每秒處理幾十萬異步消息消息,如果開啟了壓縮,最終可以達(dá)到每秒處理2000w消息的級別。
但是由于是異步的和批處理的,延遲也會高,不適合電商場景。
What Kafka
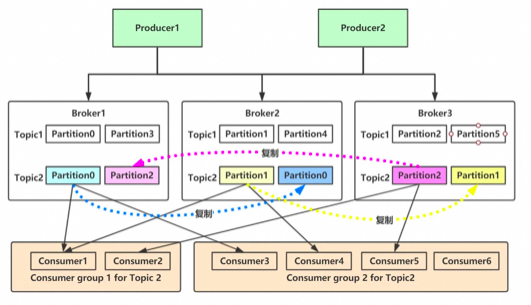
Producer API:允許應(yīng)用程序?qū)⒂涗浟靼l(fā)布到一個或多個Kafka主題。
Consumer API:允許應(yīng)用程序訂閱一個或多個主題并處理為其生成的記錄流。
Streams API:允許應(yīng)用程序充當(dāng)流處理器,將輸入流轉(zhuǎn)換為輸出流。
-
直接指定消息的分區(qū) -
根據(jù)消息的key散列取模得出分區(qū) 輪詢指定分區(qū)。
broker接收來自生產(chǎn)者的消息,為消息設(shè)置偏移量,并提交消息到磁盤保存。
broker為消費(fèi)者提供服務(wù),響應(yīng)讀取分區(qū)的請求,返回已經(jīng)提交到磁盤上的消息。
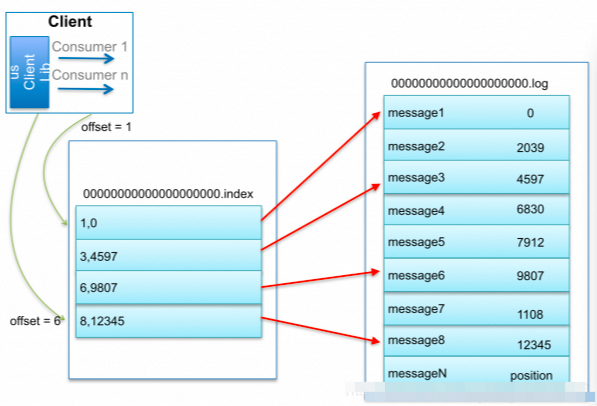
一個分區(qū)由多個LogSegment組成,
一個LogSegment由.log .index .timeindex組成
.log追加是順序?qū)懭氲模募且晕募械谝粭lmessage的offset來命名的
.Index進(jìn)行日志刪除的時候和數(shù)據(jù)查找的時候可以快速定位。
.timeStamp則根據(jù)時間戳查找對應(yīng)的偏移量。
How Kafka
高吞吐量:單機(jī)每秒處理幾十上百萬的消息量。即使存儲了TB及消息,也保持穩(wěn)定的性能。
零拷貝 減少內(nèi)核態(tài)到用戶態(tài)的拷貝,磁盤通過sendfile實現(xiàn)DMA 拷貝Socket buffer
順序讀寫 充分利用磁盤順序讀寫的超高性能
-
頁緩存mmap,將磁盤文件映射到內(nèi)存, 用戶通過修改內(nèi)存就能修改磁盤文件。 高性能:單節(jié)點(diǎn)支持上千個客戶端,并保證零停機(jī)和零數(shù)據(jù)丟失。
持久化:將消息持久化到磁盤。通過將數(shù)據(jù)持久化到硬盤以及replication防止數(shù)據(jù)丟失。
分布式系統(tǒng),易擴(kuò)展。所有的組件均為分布式的,無需停機(jī)即可擴(kuò)展機(jī)器。
可靠性 - Kafka是分布式,分區(qū),復(fù)制和容錯的。
-
客戶端狀態(tài)維護(hù):消息被處理的狀態(tài)是在Consumer端維護(hù),當(dāng)失敗時能自動平衡。
日志收集:用Kafka可以收集各種服務(wù)的Log,通過大數(shù)據(jù)平臺進(jìn)行處理;
消息系統(tǒng):解耦生產(chǎn)者和消費(fèi)者、緩存消息等;
用戶活動跟蹤:Kafka經(jīng)常被用來記錄Web用戶或者App用戶的各種活動,如瀏覽網(wǎng)頁、搜索、點(diǎn)擊等活動,這些活動信息被各個服務(wù)器發(fā)布到Kafka的Topic中,然后消費(fèi)者通過訂閱這些Topic來做運(yùn)營數(shù)據(jù)的實時的監(jiān)控分析,也可保存到數(shù)據(jù)庫;
生產(chǎn)消費(fèi)基本流程
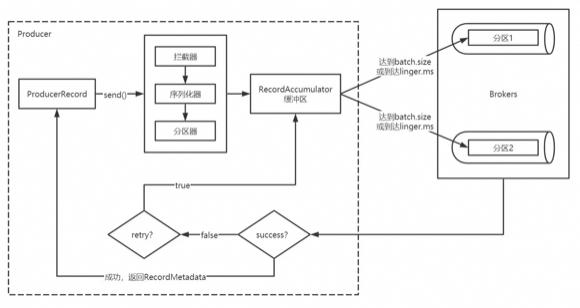
Producer創(chuàng)建時,會創(chuàng)建一個Sender線程并設(shè)置為守護(hù)線程。
生產(chǎn)的消息先經(jīng)過攔截器->序列化器->分區(qū)器,然后將消息緩存在緩沖區(qū)。
批次發(fā)送的條件為:緩沖區(qū)數(shù)據(jù)大小達(dá)到batch.size或者linger.ms達(dá)到上限。
批次發(fā)送后,發(fā)往指定分區(qū),然后落盤到broker;
acks=0只要將消息放到緩沖區(qū),就認(rèn)為消息已經(jīng)發(fā)送完成。
acks=1表示消息只需要寫到主分區(qū)即可。在該情形下,如果主分區(qū)收到消息確認(rèn)之后就宕機(jī)了,而副本分區(qū)還沒來得及同步該消息,則該消息丟失。
acks=all (默認(rèn))首領(lǐng)分區(qū)會等待所有的ISR副本分區(qū)確認(rèn)記錄。該處理保證了只要有一個ISR副本分區(qū)存活,消息就不會丟失。
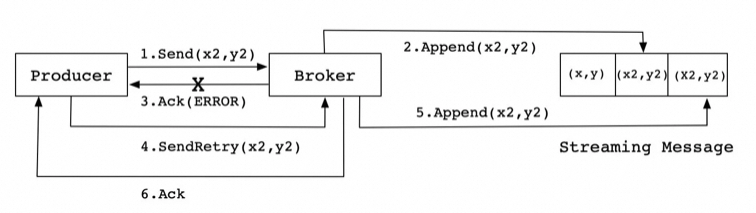
如果生產(chǎn)者配置了retrires參數(shù)大于0并且未收到確認(rèn),那么客戶端會對該消息進(jìn)行重試。
落盤到broker成功,返回生產(chǎn)元數(shù)據(jù)給生產(chǎn)者。
Kafka會在Zookeeper上針對每個Topic維護(hù)一個稱為ISR(in-sync replica)的集合;
當(dāng)集合中副本都跟Leader中的副本同步了之后,kafka才會認(rèn)為消息已提交;
只有這些跟Leader保持同步的Follower才應(yīng)該被選作新的Leader;
假設(shè)某個topic有N+1個副本,kafka可以容忍N(yùn)個服務(wù)器不可用,冗余度較低
如果ISR中的副本都丟失了,則:
可以等待ISR中的副本任何一個恢復(fù),接著對外提供服務(wù),需要時間等待;
從OSR中選出一個副本做Leader副本,此時會造成數(shù)據(jù)丟失;
LEO:即日志末端位移(log end offset),記錄了該副本日志中下一條消息的位移值。如果LEO=10,那么表示該副本保存了10條消息,位移值范圍是[0, 9]。
HW:水位值HW(high watermark)即已備份位移。對于同一個副本對象而言,其HW值不會大于LEO值。小于等于HW值的所有消息都被認(rèn)為是“已備份”的(replicated)。
-
組成員數(shù)量發(fā)生變化 -
訂閱主題數(shù)量發(fā)生變化 訂閱主題的分區(qū)數(shù)發(fā)生變化
原理是按照消費(fèi)者總數(shù)和分區(qū)總數(shù)進(jìn)行整除運(yùn)算平均分配給所有的消費(fèi)者;
訂閱Topic的消費(fèi)者按照名稱的字典序排序,分均分配,剩下的字典序從前往后分配;
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic topic_x --partitions 1 --replication-factor 1kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic topic_xkafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic topic_x --config max.message.bytes=1048576kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic topic_x
大小分片 當(dāng)前日志分段文件的大小超過了 broker 端參數(shù) log.segment.bytes 配置的值;
時間分片 當(dāng)前日志分段中消息的最大時間戳與系統(tǒng)的時間戳的差值大于log.roll.ms配置的值;
索引分片 偏移量或時間戳索引文件大小達(dá)到broker端 log.index.size.max.bytes配置的值;
偏移分片 追加的消息的偏移量與當(dāng)前日志分段的偏移量之間的差值大于 Integer.MAX_VALUE;
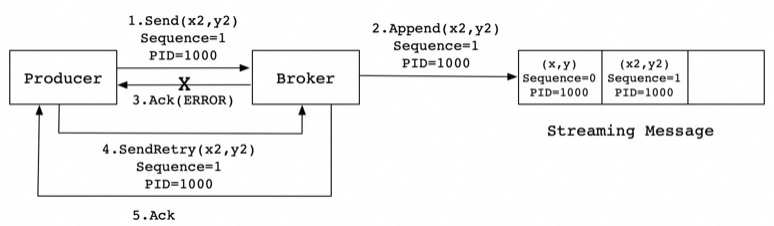
一致性
ProducerID:#在每個新的Producer初始化時,會被分配一個唯一的PIDSequenceNumber:#對于每個PID發(fā)送數(shù)據(jù)的每個Topic都對應(yīng)一個從0開始單調(diào)遞增的SN值
使用 Zookeeper 的分布式鎖選舉控制器,并在節(jié)點(diǎn)加入集群或退出集群時通知控制器。
控制器負(fù)責(zé)在節(jié)點(diǎn)加入或離開集群時進(jìn)行分區(qū)Leader選舉。
-
控制器使用epoch忽略小的紀(jì)元來避免腦裂:兩個節(jié)點(diǎn)同時認(rèn)為自己是當(dāng)前的控制器。
可用性
創(chuàng)建Topic的時候可以指定 --replication-factor 3 ,表示不超過broker的副本數(shù)
只有Leader是負(fù)責(zé)讀寫的節(jié)點(diǎn),F(xiàn)ollower定期地到Leader上Pull數(shù)據(jù)。
ISR是Leader負(fù)責(zé)維護(hù)的與其保持同步的Replica列表,即當(dāng)前活躍的副本列表。如果一個Follow落后太多,Leader會將它從ISR中移除。選舉時優(yōu)先從ISR中挑選Follower。
-
設(shè)置 acks=all 。Leader收到了ISR中所有Replica的ACK,才向Producer發(fā)送ACK。
面試題
線上問題rebalance
因集群架構(gòu)變動導(dǎo)致的消費(fèi)組內(nèi)重平衡,如果kafka集內(nèi)節(jié)點(diǎn)較多,比如數(shù)百個,那重平衡可能會耗時導(dǎo)致數(shù)分鐘到數(shù)小時,此時kafka基本處于不可用狀態(tài),對kafka的TPS影響極大。
組成員數(shù)量發(fā)生變化
訂閱主題數(shù)量發(fā)生變化
訂閱主題的分區(qū)數(shù)發(fā)生變化
組成員崩潰和組成員主動離開是兩個不同的場景。因為在崩潰時成員并不會主動地告知coordinator此事,coordinator有可能需要一個完整的session.timeout周期(心跳周期)才能檢測到這種崩潰,這必然會造成consumer的滯后。可以說離開組是主動地發(fā)起rebalance;而崩潰則是被動地發(fā)起rebalance。
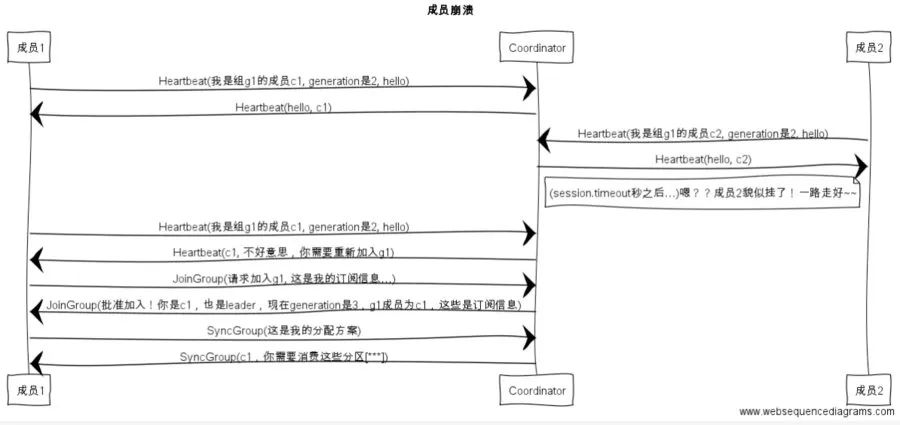
加大超時時間 session.timout.ms=6s加大心跳頻率 heartbeat.interval.ms=2s增長推送間隔 max.poll.interval.ms=t+1 minutesZooKeeper 的作用
存放元數(shù)據(jù)是指主題分區(qū)的所有數(shù)據(jù)都保存在 ZooKeeper 中,其他“人”都要與它保持對齊。
成員管理是指 Broker 節(jié)點(diǎn)的注冊、注銷以及屬性變更等 。
Controller 選舉是指選舉集群 Controller,包括但不限于主題刪除、參數(shù)配置等。
Replica副本的作用
自 Kafka 2.4 版本開始,社區(qū)可以通過配置參數(shù),允許 Follower 副本有限度地提供讀服務(wù)。
-
之前確保一致性的主要手段是高水位機(jī)制, 但高水位值無法保證 Leader 連續(xù)變更場景下的數(shù)據(jù)一致性,因此,社區(qū)引入了 Leader Epoch 機(jī)制,來修復(fù)高水位值的弊端。
為什么不支持讀寫分離?
自 Kafka 2.4 之后,Kafka 提供了有限度的讀寫分離。
場景不適用。讀寫分離適用于那種讀負(fù)載很大,而寫操作相對不頻繁的場景。
-
同步機(jī)制。Kafka 采用 PULL 方式實現(xiàn) Follower 的同步,同時復(fù)制延遲較大。
如何防止重復(fù)消費(fèi)
代碼層面每次消費(fèi)需提交offset;
通過Mysql的唯一鍵約束,結(jié)合Redis查看id是否被消費(fèi),存Redis可以直接使用set方法;
-
量大且允許誤判的情況下,使用布隆過濾器也可以;
如何保證數(shù)據(jù)不會丟失
生產(chǎn)者生產(chǎn)消息可以通過comfirm配置ack=all解決;
Broker同步過程中l(wèi)eader宕機(jī)可以通過配置ISR副本+重試解決;
-
消費(fèi)者丟失可以關(guān)閉自動提交offset功能,系統(tǒng)處理完成時提交offset;
如何保證順序消費(fèi)
單 topic,單partition,單 consumer,單線程消費(fèi),吞吐量低,不推薦;
-
如只需保證單key有序,為每個key申請單獨(dú)內(nèi)存 queue,每個線程分別消費(fèi)一個內(nèi)存 queue 即可,這樣就能保證單key(例如用戶id、活動id)順序性。
【線上】如何解決積壓消費(fèi)
修復(fù)consumer,使其具備消費(fèi)能力,并且擴(kuò)容N臺;
寫一個分發(fā)的程序,將Topic均勻分發(fā)到臨時Topic中;
-
同時起N臺consumer,消費(fèi)不同的臨時Topic;
如何避免消息積壓
-
提高消費(fèi)并行度 -
批量消費(fèi) -
減少組件IO的交互次數(shù) 優(yōu)先級消費(fèi)
if (maxOffset - curOffset > 100000) { // TODO 消息堆積情況的優(yōu)先處理邏輯 // 未處理的消息可以選擇丟棄或者打日志 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}// TODO 正常消費(fèi)過程return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;如何設(shè)計消息隊列
一致性:生產(chǎn)者的消息確認(rèn)、消費(fèi)者的冪等性、Broker的數(shù)據(jù)同步;
可用性:數(shù)據(jù)如何保證不丟不重、數(shù)據(jù)如何持久化、持久化時如何讀寫;
分區(qū)容錯:采用何種選舉機(jī)制、如何進(jìn)行多副本同步;
海量數(shù)據(jù):如何解決消息積壓、海量Topic性能下降;