
Kafka性能篇:為何Kafka這么"快"?
『碼哥』的 Redis 系列文章有一篇講透了 Redis 的性能優(yōu)化 ——《Redis 核心篇:唯快不破的秘密》。深入地從 IO、線程、數(shù)據(jù)結(jié)構(gòu)、編碼等方面剖析了 Redis “快”的內(nèi)部秘密。65 哥深受啟發(fā),在學(xué)習(xí) Kafka 的過程中,發(fā)現(xiàn) Kafka 也是一個性能十分優(yōu)秀的中間件,遂要求『碼哥』講一講 Kafka 性能優(yōu)化方面的知識,所以『碼哥』決定將這篇性能方面的博文作為 Kafka 系列的開篇之作。
先預(yù)告一下 Kafka 系列文章,大家敬請期待哦:
以講解性能作為 Kafka 之旅的開篇之作,讓我們一起來深入了解 Kafka “快”的內(nèi)部秘密。你不僅可以學(xué)習(xí)到 Kafka 性能優(yōu)化的各種手段,也可以提煉出各種性能優(yōu)化的方法論,這些方法論也可以應(yīng)用到我們自己的項目之中,助力我們寫出高性能的項目。
關(guān)公戰(zhàn)秦瓊
“65: Redis 和 Kafka 完全是不同作用的中間件,有比較性嗎?
”
是的,所以此文講的不是《分布式緩存的選型》,也不是《分布式中間件對比》。我們聚焦于這兩個不同領(lǐng)域的項目對性能的優(yōu)化,看一看優(yōu)秀項目對性能優(yōu)化的通用手段,以及在針對不同場景下的特色的優(yōu)化方式。
很多人學(xué)習(xí)了很多東西,了解了很多框架,但在遇到實際問題時,卻常常會感覺到知識不足。這就是沒有將學(xué)習(xí)到的知識體系化,沒有從具體的實現(xiàn)中抽象出可以行之有效的方法論。
學(xué)習(xí)開源項目很重要的一點就是歸納,將不同項目的優(yōu)秀實現(xiàn)總結(jié)出方法論,然后演繹到自我的實踐中去。
開篇寄語
“碼哥:理性、客觀、謹(jǐn)慎是程序員的特點,也是優(yōu)點,但是很多時候我們也需要帶一點感性,帶一點沖動,這個時候可以幫助我們更快的做決策。「悲觀者正確、樂觀者成功。」希望大家都是一個樂觀地解決問題的人。
”
Kafka 性能全景
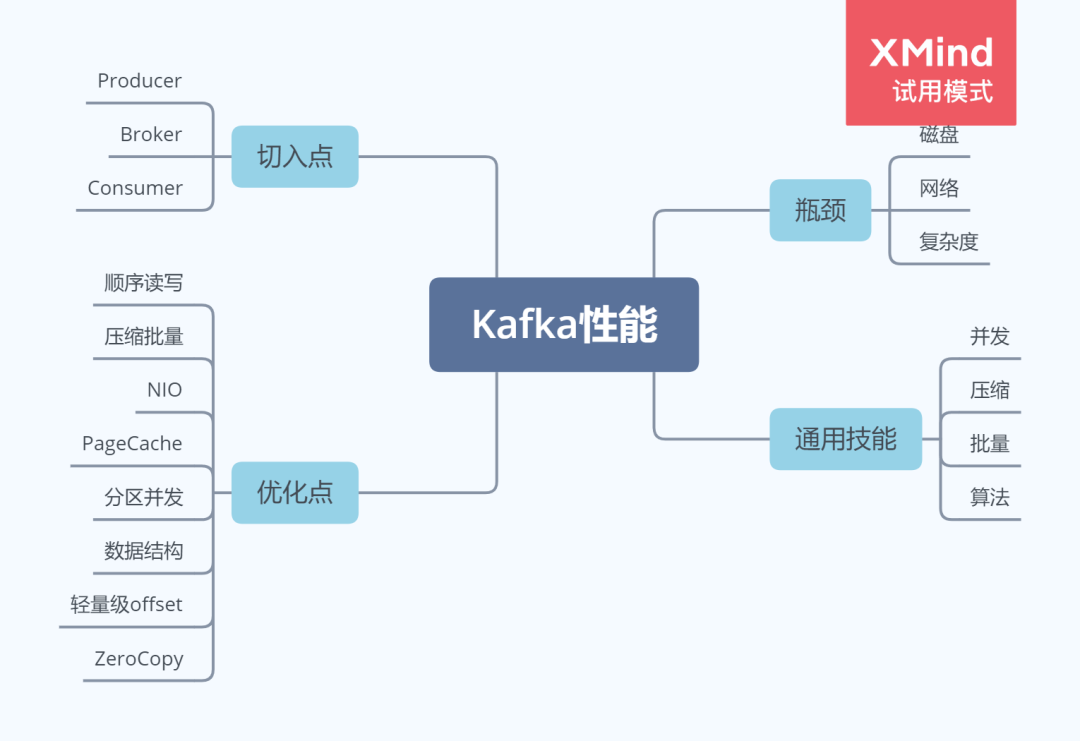
從高度抽象的角度來看,性能問題逃不出下面三個方面:
網(wǎng)絡(luò) 磁盤 復(fù)雜度
對于 Kafka 這種網(wǎng)絡(luò)分布式隊列來說,網(wǎng)絡(luò)和磁盤更是優(yōu)化的重中之重。針對于上面提出的抽象問題,解決方案高度抽象出來也很簡單:
并發(fā) 壓縮 批量 緩存 算法
知道了問題和思路,我們再來看看,在 Kafka 中,有哪些角色,而這些角色就是可以優(yōu)化的點:
Producer Broker Consumer
是的,所有的問題,思路,優(yōu)化點都已經(jīng)列出來了,我們可以盡可能的細化,三個方向都可以細化,如此,所有的實現(xiàn)便一目了然,即使不看 Kafka 的實現(xiàn),我們自己也可以想到一二點可以優(yōu)化的地方。
這就是思考方式。提出問題 > 列出問題點 > 列出優(yōu)化方法 > 列出具體可切入的點 > tradeoff和細化實現(xiàn)。
現(xiàn)在,你也可以嘗試自己想一想優(yōu)化的點和方法,不用盡善盡美,不用管好不好實現(xiàn),想一點是一點。
“65 哥:不行啊,我很笨,也很懶,你還是直接和我說吧,我白嫖比較行。
”
順序?qū)?/span>
“65 哥:人家 Redis 是基于純內(nèi)存的系統(tǒng),你 kafka 還要讀寫磁盤,能比?
”
為什么說寫磁盤慢?
我們不能只知道結(jié)論,而不知其所以然。要回答這個問題,就得回到在校時我們學(xué)的操作系統(tǒng)課程了。65 哥還留著課本嗎?來,翻到講磁盤的章節(jié),讓我們回顧一下磁盤的運行原理。
“65 哥:鬼還留著哦,課程還沒上到一半書就沒了。要不是考試俺眼神好,估計現(xiàn)在還沒畢業(yè)。
”
看經(jīng)典大圖:
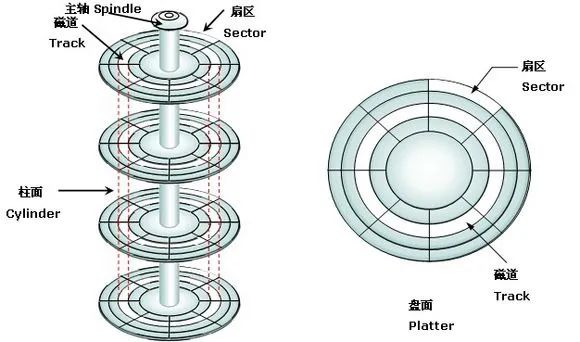
完成一次磁盤 IO,需要經(jīng)過尋道、旋轉(zhuǎn)和數(shù)據(jù)傳輸三個步驟。
影響磁盤 IO 性能的因素也就發(fā)生在上面三個步驟上,因此主要花費的時間就是:
尋道時間:Tseek 是指將讀寫磁頭移動至正確的磁道上所需要的時間。尋道時間越短,I/O 操作越快,目前磁盤的平均尋道時間一般在 3-15ms。 旋轉(zhuǎn)延遲:Trotation 是指盤片旋轉(zhuǎn)將請求數(shù)據(jù)所在的扇區(qū)移動到讀寫磁盤下方所需要的時間。旋轉(zhuǎn)延遲取決于磁盤轉(zhuǎn)速,通常用磁盤旋轉(zhuǎn)一周所需時間的 1/2 表示。比如:7200rpm 的磁盤平均旋轉(zhuǎn)延遲大約為 60*1000/7200/2 = 4.17ms,而轉(zhuǎn)速為 15000rpm 的磁盤其平均旋轉(zhuǎn)延遲為 2ms。 數(shù)據(jù)傳輸時間:Ttransfer 是指完成傳輸所請求的數(shù)據(jù)所需要的時間,它取決于數(shù)據(jù)傳輸率,其值等于數(shù)據(jù)大小除以數(shù)據(jù)傳輸率。目前 IDE/ATA 能達到 133MB/s,SATA II 可達到 300MB/s 的接口數(shù)據(jù)傳輸率,數(shù)據(jù)傳輸時間通常遠小于前兩部分消耗時間。簡單計算時可忽略。
因此,如果在寫磁盤的時候省去尋道、旋轉(zhuǎn)可以極大地提高磁盤讀寫的性能。
Kafka 采用順序?qū)?/code>文件的方式來提高磁盤寫入性能。順序?qū)?/code>文件,基本減少了磁盤尋道和旋轉(zhuǎn)的次數(shù)。磁頭再也不用在磁道上亂舞了,而是一路向前飛速前行。
Kafka 中每個分區(qū)是一個有序的,不可變的消息序列,新的消息不斷追加到 Partition 的末尾,在 Kafka 中 Partition 只是一個邏輯概念,Kafka 將 Partition 劃分為多個 Segment,每個 Segment 對應(yīng)一個物理文件,Kafka 對 segment 文件追加寫,這就是順序?qū)懳募?/p>
“65 哥:為什么 Kafka 可以使用追加寫的方式呢?
”
這和 Kafka 的性質(zhì)有關(guān),我們來看看 Kafka 和 Redis,說白了,Kafka 就是一個Queue,而 Redis 就是一個HashMap。Queue和Map的區(qū)別是什么?
Queue 是 FIFO 的,數(shù)據(jù)是有序的;HashMap數(shù)據(jù)是無序的,是隨機讀寫的。Kafka 的不可變性,有序性使得 Kafka 可以使用追加寫的方式寫文件。
其實很多符合以上特性的數(shù)據(jù)系統(tǒng),都可以采用追加寫的方式來優(yōu)化磁盤性能。典型的有Redis的 AOF 文件,各種數(shù)據(jù)庫的WAL(Write ahead log)機制等等。
“所以清楚明白自身業(yè)務(wù)的特點,就可以針對性地做出優(yōu)化。
”
零拷貝
“65 哥:哈哈,這個我面試被問到過。可惜答得一般般,唉。
”
什么是零拷貝?
我們從 Kafka 的場景來看,Kafka Consumer 消費存儲在 Broker 磁盤的數(shù)據(jù),從讀取 Broker 磁盤到網(wǎng)絡(luò)傳輸給 Consumer,期間涉及哪些系統(tǒng)交互。Kafka Consumer 從 Broker 消費數(shù)據(jù),Broker 讀取 Log,就使用了 sendfile。如果使用傳統(tǒng)的 IO 模型,偽代碼邏輯就如下所示:
readFile(buffer)
send(buffer)
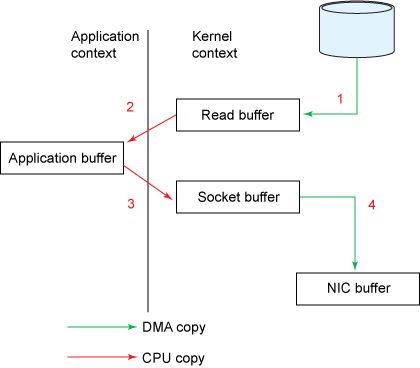
如圖,如果采用傳統(tǒng)的 IO 流程,先讀取網(wǎng)絡(luò) IO,再寫入磁盤 IO,實際需要將數(shù)據(jù) Copy 四次。
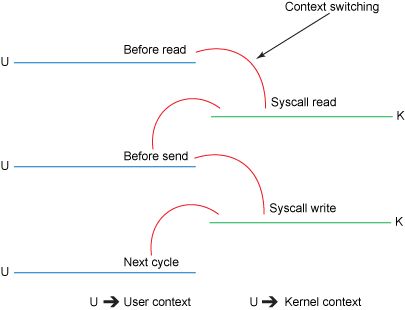
第一次:讀取磁盤文件到操作系統(tǒng)內(nèi)核緩沖區(qū); 第二次:將內(nèi)核緩沖區(qū)的數(shù)據(jù),copy 到應(yīng)用程序的 buffer; 第三步:將應(yīng)用程序 buffer 中的數(shù)據(jù),copy 到 socket 網(wǎng)絡(luò)發(fā)送緩沖區(qū); 第四次:將 socket buffer 的數(shù)據(jù),copy 到網(wǎng)卡,由網(wǎng)卡進行網(wǎng)絡(luò)傳輸。
“65 哥:啊,操作系統(tǒng)這么傻嗎?copy 來 copy 去的。
”
并不是操作系統(tǒng)傻,操作系統(tǒng)的設(shè)計就是每個應(yīng)用程序都有自己的用戶內(nèi)存,用戶內(nèi)存和內(nèi)核內(nèi)存隔離,這是為了程序和系統(tǒng)安全考慮,否則的話每個應(yīng)用程序內(nèi)存滿天飛,隨意讀寫那還得了。
不過,還有零拷貝技術(shù),英文——Zero-Copy。零拷貝就是盡量去減少上面數(shù)據(jù)的拷貝次數(shù),從而減少拷貝的 CPU 開銷,減少用戶態(tài)內(nèi)核態(tài)的上下文切換次數(shù),從而優(yōu)化數(shù)據(jù)傳輸?shù)男阅堋?/p>
常見的零拷貝思路主要有三種:
直接 I/O:數(shù)據(jù)直接跨過內(nèi)核,在用戶地址空間與 I/O 設(shè)備之間傳遞,內(nèi)核只是進行必要的虛擬存儲配置等輔助工作; 避免內(nèi)核和用戶空間之間的數(shù)據(jù)拷貝:當(dāng)應(yīng)用程序不需要對數(shù)據(jù)進行訪問時,則可以避免將數(shù)據(jù)從內(nèi)核空間拷貝到用戶空間; 寫時復(fù)制:數(shù)據(jù)不需要提前拷貝,而是當(dāng)需要修改的時候再進行部分拷貝。
Kafka 使用到了 mmap 和 sendfile 的方式來實現(xiàn)零拷貝。分別對應(yīng) Java 的 MappedByteBuffer 和 FileChannel.transferTo。
使用 Java NIO 實現(xiàn)零拷貝,如下:
FileChannel.transferTo()
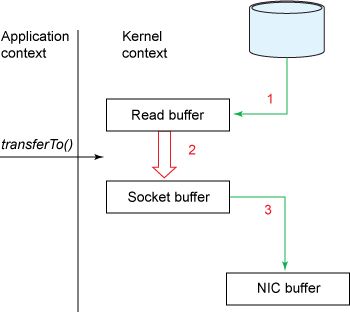
在此模型下,上下文切換的數(shù)量減少到一個。具體而言,transferTo()方法指示塊設(shè)備通過 DMA 引擎將數(shù)據(jù)讀取到讀取緩沖區(qū)中。然后,將該緩沖區(qū)復(fù)制到另一個內(nèi)核緩沖區(qū)以暫存到套接字。最后,套接字緩沖區(qū)通過 DMA 復(fù)制到 NIC 緩沖區(qū)。
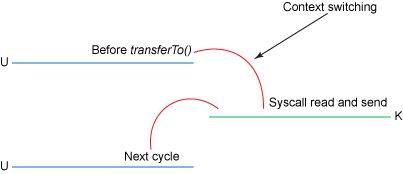
我們將副本數(shù)從四減少到三,并且這些副本中只有一個涉及 CPU。我們還將上下文切換的數(shù)量從四個減少到了兩個。這是一個很大的改進,但是還沒有查詢零副本。當(dāng)運行 Linux 內(nèi)核 2.4 及更高版本以及支持收集操作的網(wǎng)絡(luò)接口卡時,后者可以作為進一步的優(yōu)化來實現(xiàn)。如下所示。
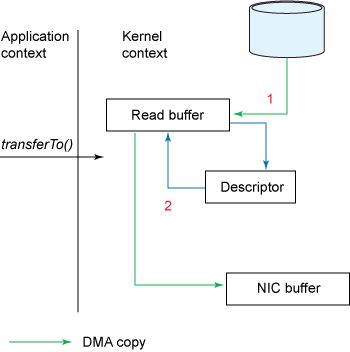
根據(jù)前面的示例,調(diào)用transferTo()方法會使設(shè)備通過 DMA 引擎將數(shù)據(jù)讀取到內(nèi)核讀取緩沖區(qū)中。但是,使用gather操作時,讀取緩沖區(qū)和套接字緩沖區(qū)之間沒有復(fù)制。取而代之的是,給 NIC 一個指向讀取緩沖區(qū)的指針以及偏移量和長度,該偏移量和長度由 DMA 清除。CPU 絕對不參與復(fù)制緩沖區(qū)。
關(guān)于零拷貝詳情,可以詳讀這篇文章零拷貝 (Zero-copy) 淺析及其應(yīng)用。
PageCache
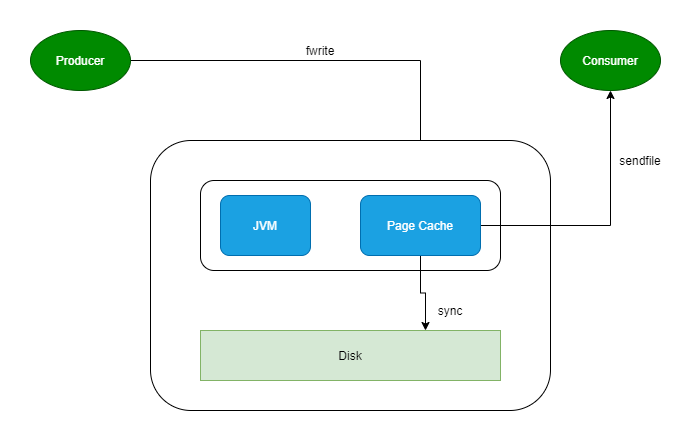
producer 生產(chǎn)消息到 Broker 時,Broker 會使用 pwrite() 系統(tǒng)調(diào)用【對應(yīng)到 Java NIO 的 FileChannel.write() API】按偏移量寫入數(shù)據(jù),此時數(shù)據(jù)都會先寫入page cache。consumer 消費消息時,Broker 使用 sendfile() 系統(tǒng)調(diào)用【對應(yīng) FileChannel.transferTo() API】,零拷貝地將數(shù)據(jù)從 page cache 傳輸?shù)?broker 的 Socket buffer,再通過網(wǎng)絡(luò)傳輸。
leader 與 follower 之間的同步,與上面 consumer 消費數(shù)據(jù)的過程是同理的。
page cache中的數(shù)據(jù)會隨著內(nèi)核中 flusher 線程的調(diào)度以及對 sync()/fsync() 的調(diào)用寫回到磁盤,就算進程崩潰,也不用擔(dān)心數(shù)據(jù)丟失。另外,如果 consumer 要消費的消息不在page cache里,才會去磁盤讀取,并且會順便預(yù)讀出一些相鄰的塊放入 page cache,以方便下一次讀取。
因此如果 Kafka producer 的生產(chǎn)速率與 consumer 的消費速率相差不大,那么就能幾乎只靠對 broker page cache 的讀寫完成整個生產(chǎn) - 消費過程,磁盤訪問非常少。
網(wǎng)絡(luò)模型
“65 哥:網(wǎng)絡(luò)嘛,作為 Java 程序員,自然是 Netty
”
是的,Netty 是 JVM 領(lǐng)域一個優(yōu)秀的網(wǎng)絡(luò)框架,提供了高性能的網(wǎng)絡(luò)服務(wù)。大多數(shù) Java 程序員提到網(wǎng)絡(luò)框架,首先想到的就是 Netty。Dubbo、Avro-RPC 等等優(yōu)秀的框架都使用 Netty 作為底層的網(wǎng)絡(luò)通信框架。
Kafka 自己實現(xiàn)了網(wǎng)絡(luò)模型做 RPC。底層基于 Java NIO,采用和 Netty 一樣的 Reactor 線程模型。
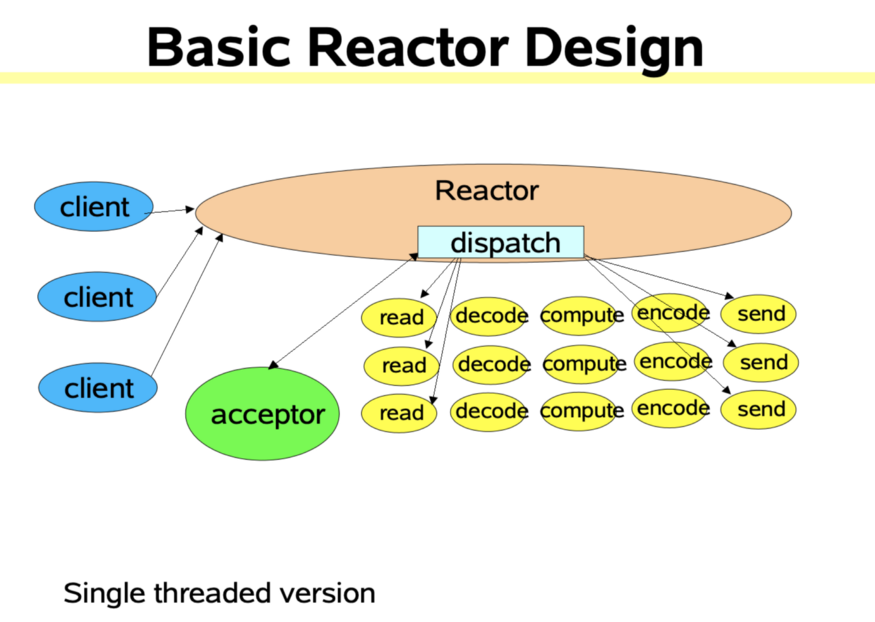
Reacotr 模型主要分為三個角色
Reactor:把 IO 事件分配給對應(yīng)的 handler 處理 Acceptor:處理客戶端連接事件 Handler:處理非阻塞的任務(wù)
在傳統(tǒng)阻塞 IO 模型中,每個連接都需要獨立線程處理,當(dāng)并發(fā)數(shù)大時,創(chuàng)建線程數(shù)多,占用資源;采用阻塞 IO 模型,連接建立后,若當(dāng)前線程沒有數(shù)據(jù)可讀,線程會阻塞在讀操作上,造成資源浪費
針對傳統(tǒng)阻塞 IO 模型的兩個問題,Reactor 模型基于池化思想,避免為每個連接創(chuàng)建線程,連接完成后將業(yè)務(wù)處理交給線程池處理;基于 IO 復(fù)用模型,多個連接共用同一個阻塞對象,不用等待所有的連接。遍歷到有新數(shù)據(jù)可以處理時,操作系統(tǒng)會通知程序,線程跳出阻塞狀態(tài),進行業(yè)務(wù)邏輯處理
Kafka 即基于 Reactor 模型實現(xiàn)了多路復(fù)用和處理線程池。其設(shè)計如下:
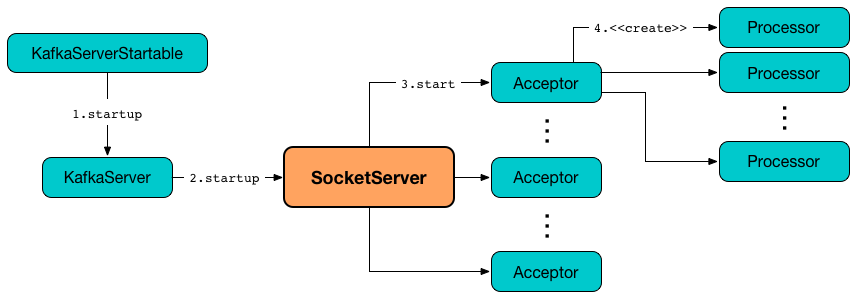
其中包含了一個Acceptor線程,用于處理新的連接,Acceptor 有 N 個 Processor 線程 select 和 read socket 請求,N 個 Handler 線程處理請求并相應(yīng),即處理業(yè)務(wù)邏輯。
I/O 多路復(fù)用可以通過把多個 I/O 的阻塞復(fù)用到同一個 select 的阻塞上,從而使得系統(tǒng)在單線程的情況下可以同時處理多個客戶端請求。它的最大優(yōu)勢是系統(tǒng)開銷小,并且不需要創(chuàng)建新的進程或者線程,降低了系統(tǒng)的資源開銷。
總結(jié): Kafka Broker 的 KafkaServer 設(shè)計是一個優(yōu)秀的網(wǎng)絡(luò)架構(gòu),有想了解 Java 網(wǎng)絡(luò)編程,或需要使用到這方面技術(shù)的同學(xué)不妨去讀一讀源碼。后續(xù)『碼哥』的 Kafka 系列文章也將涉及這塊源碼的解讀。
批量與壓縮
Kafka Producer 向 Broker 發(fā)送消息不是一條消息一條消息的發(fā)送。使用過 Kafka 的同學(xué)應(yīng)該知道,Producer 有兩個重要的參數(shù):batch.size和linger.ms。這兩個參數(shù)就和 Producer 的批量發(fā)送有關(guān)。
Kafka Producer 的執(zhí)行流程如下圖所示:
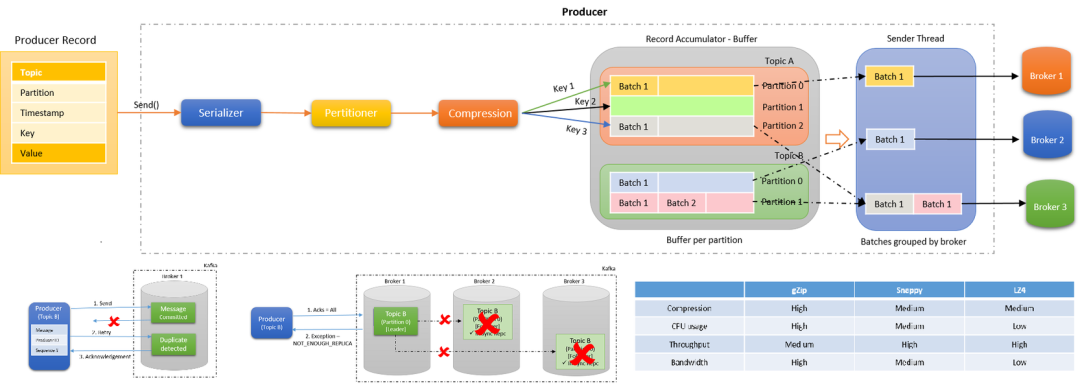
發(fā)送消息依次經(jīng)過以下處理器:
Serialize:鍵和值都根據(jù)傳遞的序列化器進行序列化。優(yōu)秀的序列化方式可以提高網(wǎng)絡(luò)傳輸?shù)男省?/section> Partition:決定將消息寫入主題的哪個分區(qū),默認(rèn)情況下遵循 murmur2 算法。自定義分區(qū)程序也可以傳遞給生產(chǎn)者,以控制應(yīng)將消息寫入哪個分區(qū)。 Compress:默認(rèn)情況下,在 Kafka 生產(chǎn)者中不啟用壓縮.Compression 不僅可以更快地從生產(chǎn)者傳輸?shù)酱恚€可以在復(fù)制過程中進行更快的傳輸。壓縮有助于提高吞吐量,降低延遲并提高磁盤利用率。 Accumulate: Accumulate顧名思義,就是一個消息累計器。其內(nèi)部為每個 Partition 維護一個Deque雙端隊列,隊列保存將要發(fā)送的批次數(shù)據(jù),Accumulate將數(shù)據(jù)累計到一定數(shù)量,或者在一定過期時間內(nèi),便將數(shù)據(jù)以批次的方式發(fā)送出去。記錄被累積在主題每個分區(qū)的緩沖區(qū)中。根據(jù)生產(chǎn)者批次大小屬性將記錄分組。主題中的每個分區(qū)都有一個單獨的累加器 / 緩沖區(qū)。Group Send:記錄累積器中分區(qū)的批次按將它們發(fā)送到的代理分組。批處理中的記錄基于 batch.size 和 linger.ms 屬性發(fā)送到代理。記錄由生產(chǎn)者根據(jù)兩個條件發(fā)送。當(dāng)達到定義的批次大小或達到定義的延遲時間時。
Kafka 支持多種壓縮算法:lz4、snappy、gzip。Kafka 2.1.0 正式支持 ZStandard —— ZStandard 是 Facebook 開源的壓縮算法,旨在提供超高的壓縮比 (compression ratio),具體細節(jié)參見 zstd。
Producer、Broker 和 Consumer 使用相同的壓縮算法,在 producer 向 Broker 寫入數(shù)據(jù),Consumer 向 Broker 讀取數(shù)據(jù)時甚至可以不用解壓縮,最終在 Consumer Poll 到消息時才解壓,這樣節(jié)省了大量的網(wǎng)絡(luò)和磁盤開銷。
分區(qū)并發(fā)
Kafka 的 Topic 可以分成多個 Partition,每個 Paritition 類似于一個隊列,保證數(shù)據(jù)有序。同一個 Group 下的不同 Consumer 并發(fā)消費 Paritition,分區(qū)實際上是調(diào)優(yōu) Kafka 并行度的最小單元,因此,可以說,每增加一個 Paritition 就增加了一個消費并發(fā)。
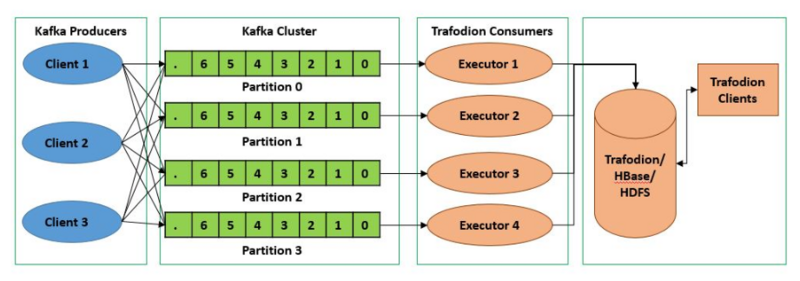
Kafka 具有優(yōu)秀的分區(qū)分配算法——StickyAssignor,可以保證分區(qū)的分配盡量地均衡,且每一次重分配的結(jié)果盡量與上一次分配結(jié)果保持一致。這樣,整個集群的分區(qū)盡量地均衡,各個 Broker 和 Consumer 的處理不至于出現(xiàn)太大的傾斜。
“65 哥:那是不是分區(qū)數(shù)越多越好呢?
”
當(dāng)然不是。
越多的分區(qū)需要打開更多的文件句柄
在 kafka 的 broker 中,每個分區(qū)都會對照著文件系統(tǒng)的一個目錄。在 kafka 的數(shù)據(jù)日志文件目錄中,每個日志數(shù)據(jù)段都會分配兩個文件,一個索引文件和一個數(shù)據(jù)文件。因此,隨著 partition 的增多,需要的文件句柄數(shù)急劇增加,必要時需要調(diào)整操作系統(tǒng)允許打開的文件句柄數(shù)。
客戶端 / 服務(wù)器端需要使用的內(nèi)存就越多
客戶端 producer 有個參數(shù) batch.size,默認(rèn)是 16KB。它會為每個分區(qū)緩存消息,一旦滿了就打包將消息批量發(fā)出。看上去這是個能夠提升性能的設(shè)計。不過很顯然,因為這個參數(shù)是分區(qū)級別的,如果分區(qū)數(shù)越多,這部分緩存所需的內(nèi)存占用也會更多。
降低高可用性
分區(qū)越多,每個 Broker 上分配的分區(qū)也就越多,當(dāng)一個發(fā)生 Broker 宕機,那么恢復(fù)時間將很長。
文件結(jié)構(gòu)
Kafka 消息是以 Topic 為單位進行歸類,各個 Topic 之間是彼此獨立的,互不影響。每個 Topic 又可以分為一個或多個分區(qū)。每個分區(qū)各自存在一個記錄消息數(shù)據(jù)的日志文件。
Kafka 每個分區(qū)日志在物理上實際按大小被分成多個 Segment。
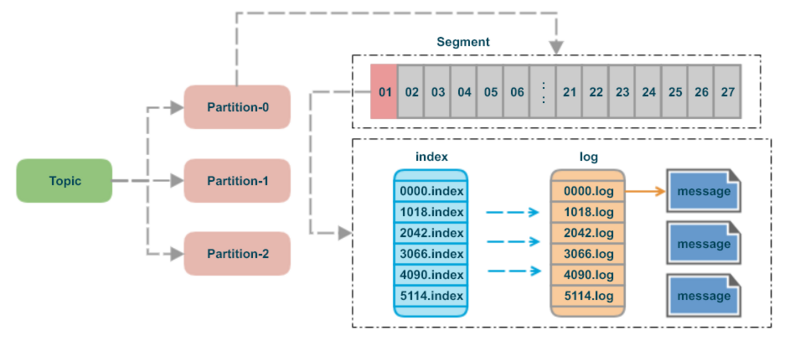
segment file 組成:由 2 大部分組成,分別為 index file 和 data file,此 2 個文件一一對應(yīng),成對出現(xiàn),后綴”.index”和“.log”分別表示為 segment 索引文件、數(shù)據(jù)文件。 segment 文件命名規(guī)則:partion 全局的第一個 segment 從 0 開始,后續(xù)每個 segment 文件名為上一個 segment 文件最后一條消息的 offset 值。數(shù)值最大為 64 位 long 大小,19 位數(shù)字字符長度,沒有數(shù)字用 0 填充。
index 采用稀疏索引,這樣每個 index 文件大小有限,Kafka 采用mmap的方式,直接將 index 文件映射到內(nèi)存,這樣對 index 的操作就不需要操作磁盤 IO。mmap的 Java 實現(xiàn)對應(yīng) MappedByteBuffer 。
“65 哥筆記:mmap 是一種內(nèi)存映射文件的方法。即將一個文件或者其它對象映射到進程的地址空間,實現(xiàn)文件磁盤地址和進程虛擬地址空間中一段虛擬地址的一一對映關(guān)系。實現(xiàn)這樣的映射關(guān)系后,進程就可以采用指針的方式讀寫操作這一段內(nèi)存,而系統(tǒng)會自動回寫臟頁面到對應(yīng)的文件磁盤上,即完成了對文件的操作而不必再調(diào)用 read,write 等系統(tǒng)調(diào)用函數(shù)。相反,內(nèi)核空間對這段區(qū)域的修改也直接反映用戶空間,從而可以實現(xiàn)不同進程間的文件共享。
”
Kafka 充分利用二分法來查找對應(yīng) offset 的消息位置:
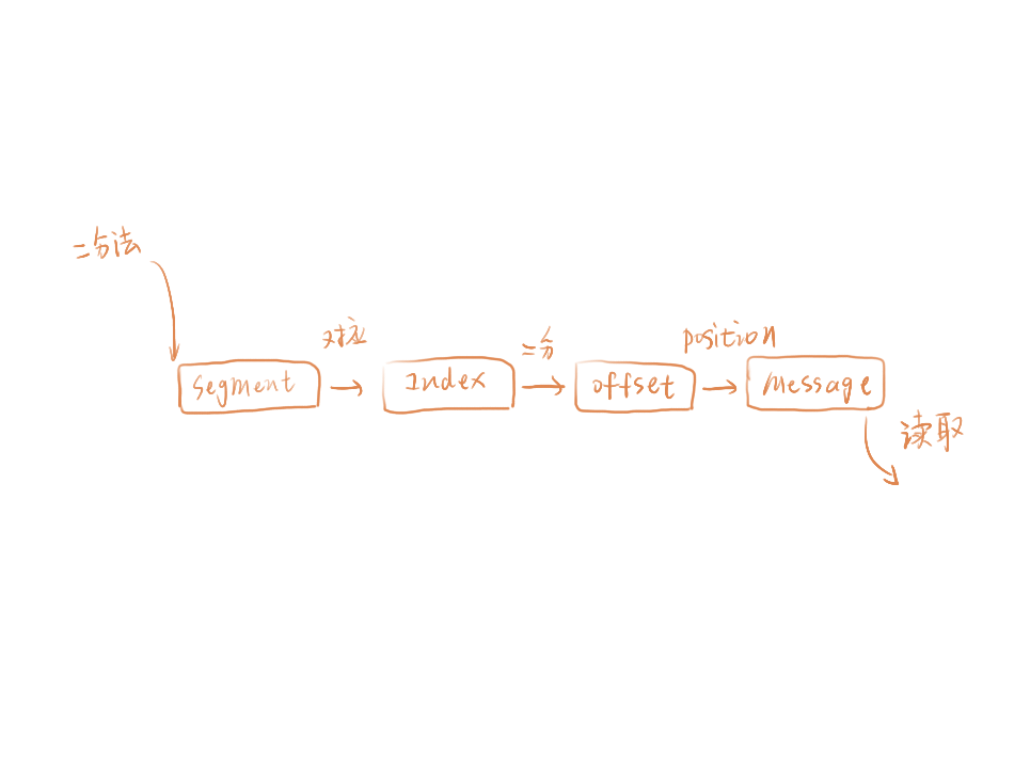
按照二分法找到小于 offset 的 segment 的.log 和.index 用目標(biāo) offset 減去文件名中的 offset 得到消息在這個 segment 中的偏移量。 再次用二分法在 index 文件中找到對應(yīng)的索引。 到 log 文件中,順序查找,直到找到 offset 對應(yīng)的消息。
總結(jié)
Kafka 是一個優(yōu)秀的開源項目。其在性能上面的優(yōu)化做的淋漓盡致,是很值得我們深入學(xué)習(xí)的一個項目。無論是思想還是實現(xiàn),我們都應(yīng)該認(rèn)真的去看一看,想一想。
Kafka 性能優(yōu)化:
零拷貝網(wǎng)絡(luò)和磁盤 優(yōu)秀的網(wǎng)絡(luò)模型,基于 Java NIO 高效的文件數(shù)據(jù)結(jié)構(gòu)設(shè)計 Parition 并行和可擴展 數(shù)據(jù)批量傳輸 數(shù)據(jù)壓縮 順序讀寫磁盤 無鎖輕量級 offset
往期回顧
文章如有錯誤,感謝指正,關(guān)注我,獲取真正的硬核知識點。另外技術(shù)讀者群也開通了,后臺回復(fù)「加群」獲取「碼哥字節(jié)」作者微信,一起成長交流。
以上就是 Kafka“快”的秘密,覺得不錯請點贊、分享,「碼哥字節(jié)」感激不盡。