
AAAI21最佳論文Informer:效果遠(yuǎn)超Transformer的長序列預(yù)測神器!

極市導(dǎo)讀
?在很多實(shí)際應(yīng)用問題中,我們需要對(duì)長序列時(shí)間序列進(jìn)行預(yù)測。為解決使用Transformer進(jìn)行預(yù)測時(shí)存在的二次時(shí)間復(fù)雜度、高內(nèi)存使用率等問題,本文介紹了一種基于變換器的LSTF模型informer。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
01 簡介
在很多實(shí)際應(yīng)用問題中,我們需要對(duì)長序列時(shí)間序列進(jìn)行預(yù)測,例如用電使用規(guī)劃。長序列時(shí)間序列預(yù)測(LSTF)要求模型具有很高的預(yù)測能力,即能夠有效地捕捉輸出和輸入之間精確的長程相關(guān)性耦合。最近的研究表明,Transformer具有提高預(yù)測能力的潛力。然而,Transformer存在一些嚴(yán)重的問題,如:
二次時(shí)間復(fù)雜度、高內(nèi)存使用率以及encoder-decoder體系結(jié)構(gòu)的固有限制。
為了解決這些問題,我們?cè)O(shè)計(jì)了一個(gè)有效的基于變換器的LSTF模型Informer,它具有三個(gè)顯著的特點(diǎn):
ProbSparse Self-Attention,在時(shí)間復(fù)雜度和內(nèi)存使用率上達(dá)到了,在序列的依賴對(duì)齊上具有相當(dāng)?shù)男阅堋?/section> self-attention 提取通過將級(jí)聯(lián)層輸入減半來突出控制注意,并有效地處理超長的輸入序列。 產(chǎn)生式decoder雖然概念上簡單,但在一個(gè)正向操作中預(yù)測長時(shí)間序列,而不是一步一步地進(jìn)行,這大大提高了長序列預(yù)測的推理速度。
在四個(gè)大規(guī)模數(shù)據(jù)集上的大量實(shí)驗(yàn)表明,Informer的性能明顯優(yōu)于現(xiàn)有的方法,為LSTF問題提供了一種新的解決方案。
02 背景
Intuition:Transformer是否可以提高計(jì)算、內(nèi)存和架構(gòu)效率,以及保持更高的預(yù)測能力?
原始Transformer的問題
self-attention的二次計(jì)算復(fù)雜度,self-attention機(jī)制的操作,會(huì)導(dǎo)致我們模型的時(shí)間復(fù)雜度為; 長輸入的stacking層的內(nèi)存瓶頸:J個(gè)encoder/decoder的stack會(huì)導(dǎo)致內(nèi)存的使用為; 預(yù)測長輸出的速度驟降:動(dòng)態(tài)的decoding會(huì)導(dǎo)致step-by-step的inference非常慢。
本文的重大貢獻(xiàn)
本文提出的方案同時(shí)解決了上面的三個(gè)問題,我們研究了在self-attention機(jī)制中的稀疏性問題,本文的貢獻(xiàn)有如下幾點(diǎn):
我們提出Informer來成功地提高LSTF問題的預(yù)測能力,這驗(yàn)證了類Transformer模型的潛在價(jià)值,以捕捉長序列時(shí)間序列輸出和輸入之間的單個(gè)的長期依賴性; 我們提出了ProbSparse self-attention機(jī)制來高效的替換常規(guī)的self-attention并且獲得了的時(shí)間復(fù)雜度以及的內(nèi)存使用率; 我們提出了self-attention distilling操作全縣,它大幅降低了所需的總空間復(fù)雜度; 我們提出了生成式的Decoder來獲取長序列的輸出,這只需要一步,避免了在inference階段的累計(jì)誤差傳播;
問題定義
在固定size的窗口下的rolling預(yù)測中,我們?cè)跁r(shí)刻的輸入為,我們需要預(yù)測對(duì)應(yīng)的輸出序列,LSTF問題鼓勵(lì)輸出一個(gè)更長的輸出,特征維度不再依賴于univariate例子().
Encoder-decoder框架:許多流行的模型被設(shè)計(jì)對(duì)輸入表示進(jìn)行編碼,將編碼為一個(gè)隱藏狀態(tài)表示并且將輸出的表示解碼.在推理的過程中設(shè)計(jì)到step-by-step的過程(dynamic decoding),decoder從前一個(gè)狀態(tài)計(jì)算一個(gè)新的隱藏狀態(tài)以及第步的輸出,然后對(duì)個(gè)序列進(jìn)行預(yù)測; 輸入表示:為了增強(qiáng)時(shí)間序列輸入的全局位置上下文和局部時(shí)間上下文,給出了統(tǒng)一的輸入表示。
03 方法
現(xiàn)有時(shí)序方案預(yù)測可以被大致分為兩類:
高效的Self-Attention機(jī)制
傳統(tǒng)的self-attention主要由(query,key,value)組成,,其中;第個(gè)attention被定義為核平滑的概率形式:
self-attention需要的內(nèi)存以及二次的點(diǎn)積計(jì)算代價(jià),這是預(yù)測能力的主要缺點(diǎn)。我們首先對(duì)典型自我注意的學(xué)習(xí)注意模式進(jìn)行定性評(píng)估。“稀疏性” self-attention得分形成長尾分布,即少數(shù)點(diǎn)積對(duì)主要注意有貢獻(xiàn),其他點(diǎn)積對(duì)可以忽略。那么,下一個(gè)問題是如何區(qū)分它們?
Query Sparsity評(píng)估
我們定義第個(gè)query sparsity第評(píng)估為:
第一項(xiàng)是在所有keys的Log-Sum-Exp(LSE),第二項(xiàng)是arithmetic均值。
ProbSparse Self-attention
其中是和q相同size的稀疏矩陣,它僅包含稀疏評(píng)估下下Top-u的queries,由采樣factor 所控制,我們令, 這么做self-attention對(duì)于每個(gè)query-key lookup就只需要計(jì)算的內(nèi)積,內(nèi)存的使用包含,但是我們計(jì)算的時(shí)候需要計(jì)算沒對(duì)的dot-product,即,,同時(shí)LSE還會(huì)帶來潛在的數(shù)值問題,受此影響,本文提出了query sparsity 評(píng)估的近似,即:
這么做可以將時(shí)間和空間復(fù)雜度控制到
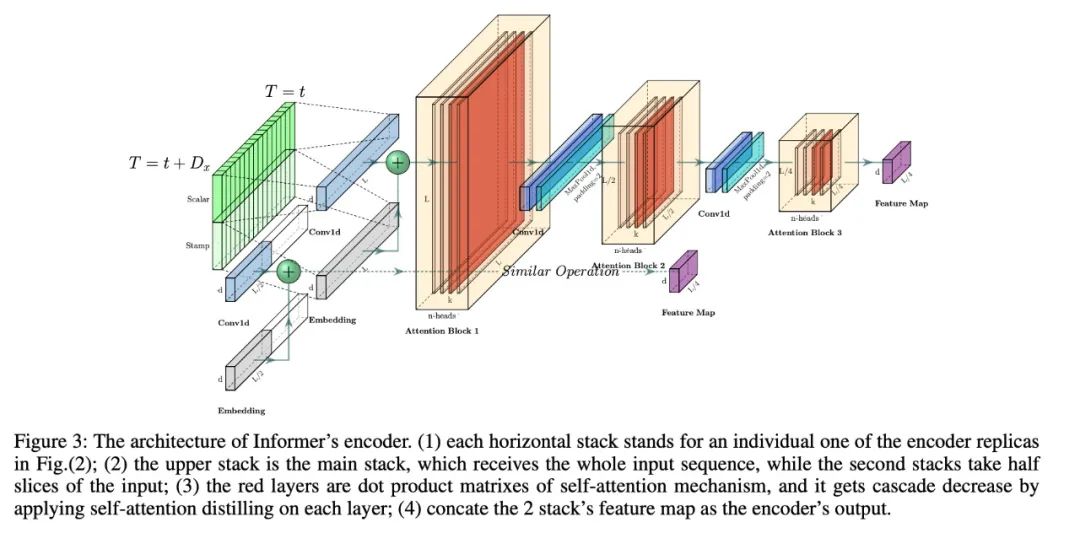
04 方法Encoder + Decoder
1. Encoder: Allowing for processing longer sequential inputs under the memory usage limitation
encoder被設(shè)計(jì)用來抽取魯棒的長序列輸入的long-range依賴,在第個(gè)序列輸入被轉(zhuǎn)為矩陣
Self-attention Distilling
作為ProbSparse Self-attention的自然結(jié)果,encoder的特征映射會(huì)帶來值的冗余組合,利用distilling對(duì)具有支配特征的優(yōu)勢特征進(jìn)行特權(quán)化,并在下一層生成focus self-attention特征映射。它對(duì)輸入的時(shí)間維度進(jìn)行了銳利的修剪,如上圖所示,n個(gè)頭部權(quán)重矩陣(重疊的紅色方塊)。受擴(kuò)展卷積的啟發(fā),我們的“distilling”過程從第j層往推進(jìn):
其中包含Multi-Head ProbSparse self-attention以及重要的attention block的操作。為了增強(qiáng)distilling操作的魯棒性,我們構(gòu)建了halving replicas,并通過一次刪除一層(如上圖)來逐步減少自關(guān)注提取層的數(shù)量,從而使它們的輸出維度對(duì)齊。因此,我們將所有堆棧的輸出串聯(lián)起來,并得到encoder的最終隱藏表示。
2. Decoder: Generating long sequential outputs through one forward procedure
此處使用標(biāo)準(zhǔn)的decoder結(jié)構(gòu),由2個(gè)一樣的multihead attention層,但是,生成的inference被用來緩解速度瓶頸,我們使用下面的向量喂入decoder:
其中,是start tocken, ?~~是一個(gè)placeholder,將Masked multi-head attention應(yīng)用于ProbSparse self-attention,將mask的點(diǎn)積設(shè)置為。它可以防止每個(gè)位置都關(guān)注未來的位置,從而避免了自回歸。一個(gè)完全連接的層獲得最終的輸出,它的超大小取決于我們是在執(zhí)行單變量預(yù)測還是在執(zhí)行多變量預(yù)測。
Generative Inference
我們從長序列中采樣一個(gè),這是在輸出序列之前的slice。以圖中預(yù)測168個(gè)點(diǎn)為例(7天溫度預(yù)測),我們將目標(biāo)序列已知的前5天的值作為“start token”,并將,輸入生成式推理解碼器。包含目標(biāo)序列的時(shí)間戳,即目標(biāo)周的上下文。注意,我們提出的decoder通過一個(gè)前向過程預(yù)測所有輸出,并且不存在耗時(shí)的“dynamic decoding”。
Loss Function
此處選用MSE 損失函數(shù)作為最終的Loss。
05 實(shí)驗(yàn)
1. 實(shí)驗(yàn)效果

從上表中,我們發(fā)現(xiàn):
所提出的模型Informer極大地提高了所有數(shù)據(jù)集的推理效果(最后一列的獲勝計(jì)數(shù)),并且在不斷增長的預(yù)測范圍內(nèi),它們的預(yù)測誤差平穩(wěn)而緩慢地上升。 query sparsity假設(shè)在很多數(shù)據(jù)集上是成立的; Informer在很多數(shù)據(jù)集上遠(yuǎn)好于LSTM和ERNN
2. 參數(shù)敏感性
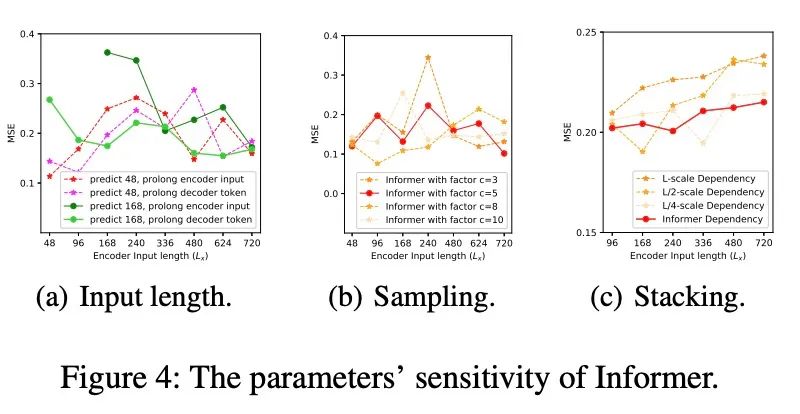
從上圖中,我們發(fā)現(xiàn):
Input Length:當(dāng)預(yù)測短序列(如48)時(shí),最初增加編碼器/解碼器的輸入長度會(huì)降低性能,但進(jìn)一步增加會(huì)導(dǎo)致MSE下降,因?yàn)樗鼤?huì)帶來重復(fù)的短期模式。然而,在預(yù)測中,輸入時(shí)間越長,平均誤差越低:信息者的參數(shù)敏感性。長序列(如168)。因?yàn)檩^長的編碼器輸入可能包含更多的依賴項(xiàng); Sampling Factor:我們驗(yàn)證了冗余點(diǎn)積的查詢稀疏性假設(shè);實(shí)踐中,我們把sample factor設(shè)置為5即可,即; Number of Layer Stacking:Longer stack對(duì)輸入更敏感,部分原因是接收到的長期信息較多
3. 解耦實(shí)驗(yàn)
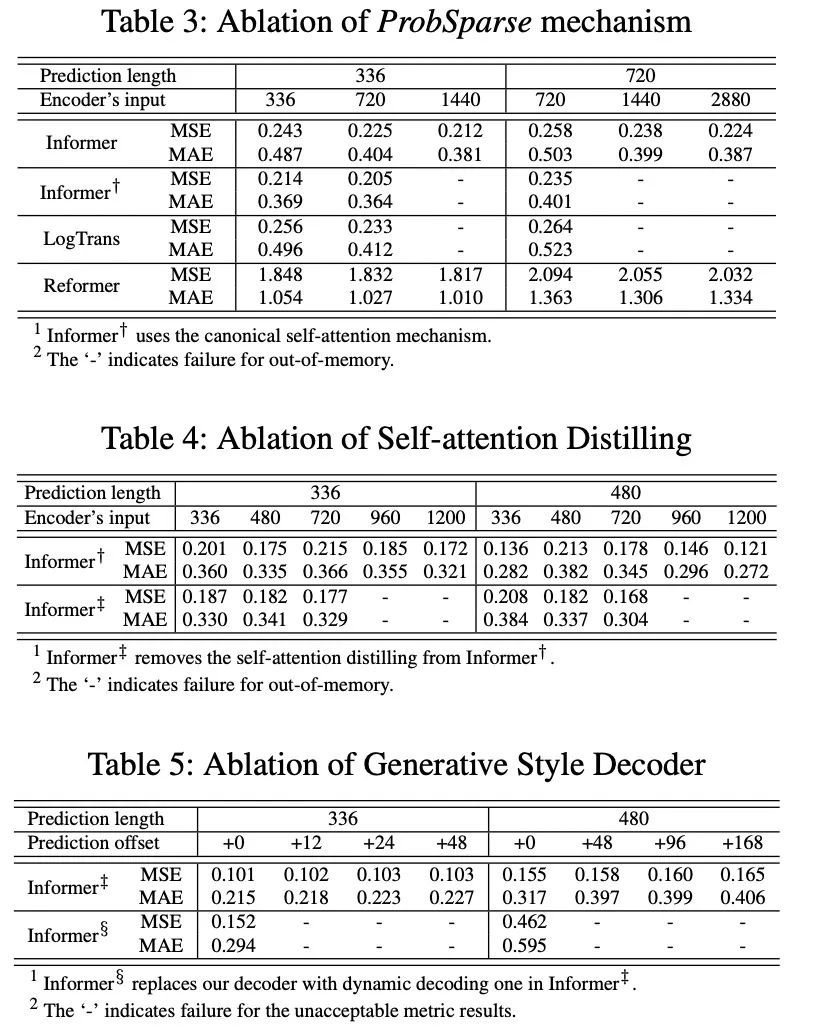
從上表中我們發(fā)現(xiàn),
ProbSparse self-attention機(jī)制的效果:ProbSparse self-attention的效果更好,而且可以節(jié)省很多內(nèi)存消耗; self-attention distilling:是值得使用的,尤其是對(duì)長序列進(jìn)行預(yù)測的時(shí)候; generative stype decoderL:它證明了decoder能夠捕獲任意輸出之間的長依賴關(guān)系,避免了誤差的積累;
4. 計(jì)算高效性
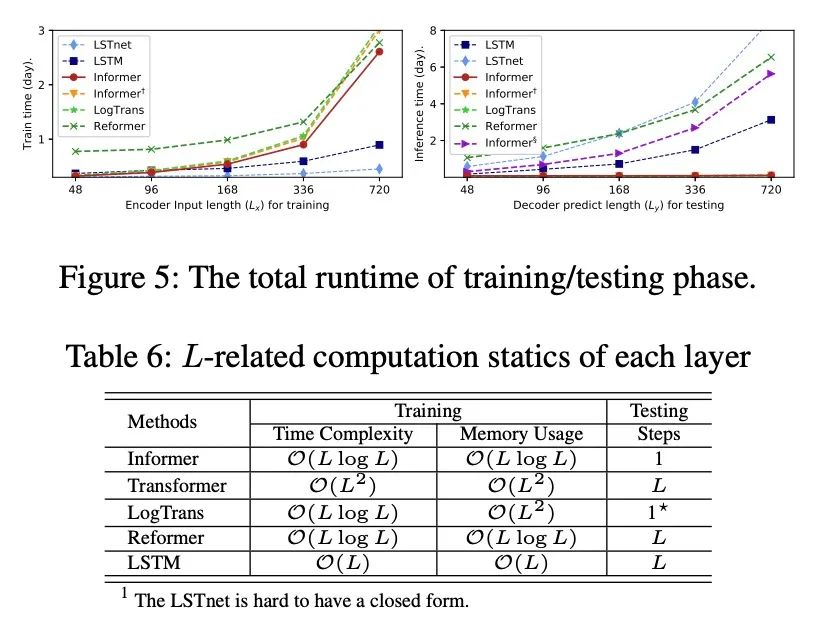
在訓(xùn)練階段,在基于Transformer的方法中,Informer獲得了最佳的訓(xùn)練效率。 在測試階段,我們的方法比其他生成式decoder方法要快得多。
06 小結(jié)
本文研究了長序列時(shí)間序列預(yù)測問題,提出了長序列預(yù)測的Informer方法。具體地:
設(shè)計(jì)了ProbSparse self-attention和提取操作來處理vanilla Transformer中二次時(shí)間復(fù)雜度和二次內(nèi)存使用的挑戰(zhàn)。 generative decoder緩解了傳統(tǒng)編解碼結(jié)構(gòu)的局限性。 通過對(duì)真實(shí)數(shù)據(jù)的實(shí)驗(yàn),驗(yàn)證了Informer對(duì)提高預(yù)測能力的有效性
參考文獻(xiàn):Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting:https://arxiv.org/pdf/2012.07436.pdf
推薦閱讀
