
PatchTST: 基于Transformer的長(zhǎng)時(shí)間序列預(yù)測(cè)
本文中了 2023 ICLR。PatchTST 作為 Transformer-based 預(yù)測(cè)模型,它是和計(jì)算機(jī)視覺中的 ViT 最相似的一篇論文(文章標(biāo)題也很像)。
它成功超過了 DLinear,也證明了 DLinear 中 Transformer可能不適合于序列預(yù)測(cè)任務(wù)的聲明是值得商榷的。

論文標(biāo)題:
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
論文鏈接:https://arxiv.org/pdf/2211.14730.pdf
代碼鏈接:https://github.com/yuqinie98/patchtst
建議先看一下下面關(guān)于 DLinear 的回答和 DLinear 論文:
https://www.zhihu.com/question/493821601/answer/2506641761
https://arxiv.org/pdf/2205.13504.pdf
1.1 Patching
本文的核心思想就是 Patching,這和 Preformer 中的核心思想很相似,只不過效果要比 Preformer 好不少。具體來說,它們都是將時(shí)間序列分成若干個(gè)時(shí)間段(Preformer 里用的術(shù)語是 segment,本文用的是 patch,實(shí)際上是差不多的),每一個(gè)時(shí)間段視為一個(gè) token(這不同于很多 Transformer-based 模型將每一個(gè)時(shí)間點(diǎn)視為一個(gè)token)。
Preformer 的論文和詳細(xì)解析如下:
https://arxiv.org/pdf/2202.11356.pdf
https://zhuanlan.zhihu.com/p/536398013
分 patch 的結(jié)構(gòu)如下圖所示。對(duì)于一個(gè)單變量序列(為什么是單變量,可以看下一小節(jié) Channel-independence 中的介紹),將其劃分為 個(gè) patch(可以是有重疊的,也可以是無重疊的,無重疊的情況就相當(dāng)于 Preformer 中的均勻分段),每個(gè) patch 的長(zhǎng)度為 。
然后將每個(gè) patch 視為一個(gè) token,進(jìn)行 embedding 以及加上位置編碼,即可直接輸入到普通的 Transformer 中(圖中的 Transformer Encoder)。最后將向量展平之后輸入到一個(gè)預(yù)測(cè)頭(Linear Head),得到預(yù)測(cè)的單變量輸出序列。
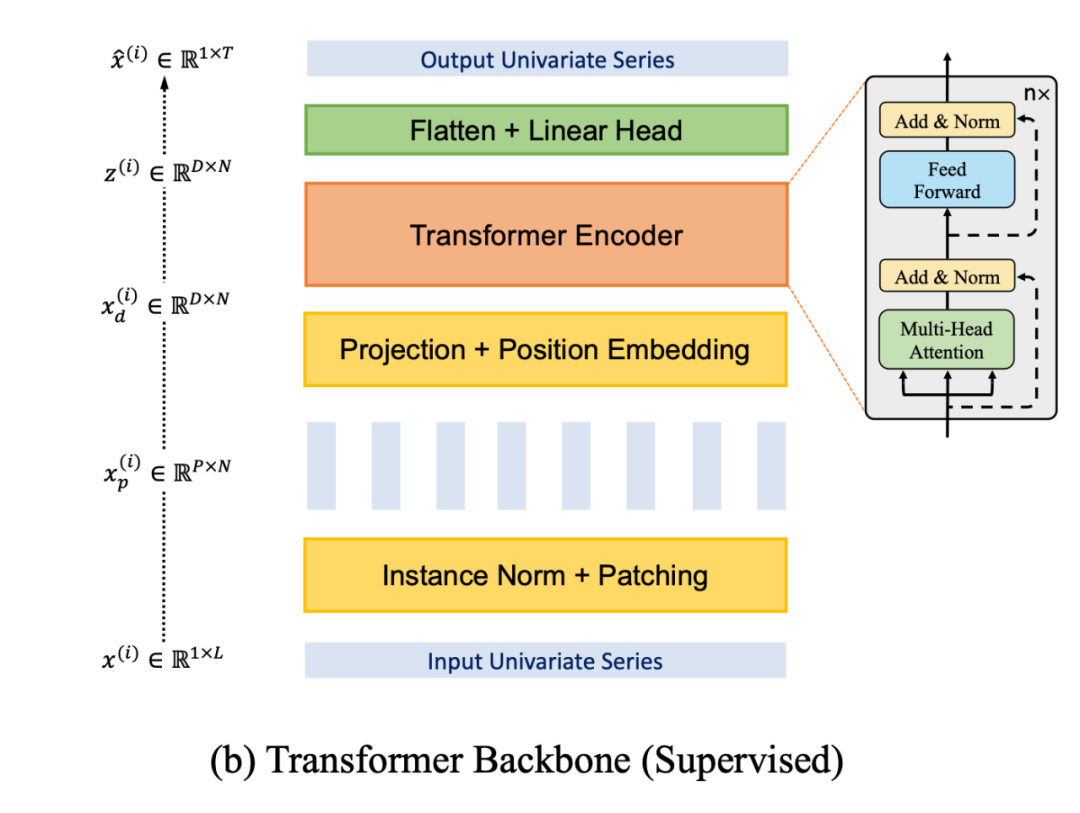
分 patch(時(shí)間段)的好處主要有四點(diǎn):
1. 降低復(fù)雜度,因?yàn)?Attention 的復(fù)雜度是和 token 數(shù)量成二次方關(guān)系。如果每一個(gè) patch 代表一個(gè) token,而不是每一個(gè)時(shí)間點(diǎn)代表一個(gè) token,這顯然降低了 token 的數(shù)量。
2. 保持時(shí)間序列的局部性,因?yàn)闀r(shí)間序列具有很強(qiáng)的局部性,相鄰的時(shí)刻值很接近,以一個(gè) patch 為 Attention 計(jì)算的最小單位顯然更合理。
3. 方便之后的自監(jiān)督表示學(xué)習(xí),即 Mask 隨機(jī) patch 后重建。
4. 分 patch 還可以減小預(yù)測(cè)頭(Linear Head)的參數(shù)量。如果不分 patch 的話,Linear Head 的大小會(huì)是 , 是輸入序列長(zhǎng)度, 是序列個(gè)數(shù), 是預(yù)測(cè)序列長(zhǎng)度;如果分 patch 的話,Linear Head 的大小是 , 是 patch 個(gè)數(shù)要遠(yuǎn)小于 。因此,分 patch 之后,Linear Head 參數(shù)量大大減小,可以防止過擬合。
1.2 Channel-independence
很多 Transformer-based 模型采用了 channel-mixing 的方式,指的是,對(duì)于 多元時(shí)間序列(相當(dāng)于多通道信號(hào)) ,直接將時(shí)間序列的所有維度形成的向量投影到嵌入空間以混合多個(gè)通道的信息。Channel-independence 意味著每個(gè)輸入 token 只包含來自單個(gè)通道的信息。本文就采用了 Channel-independence,DLinear 中也采用了這種方式。
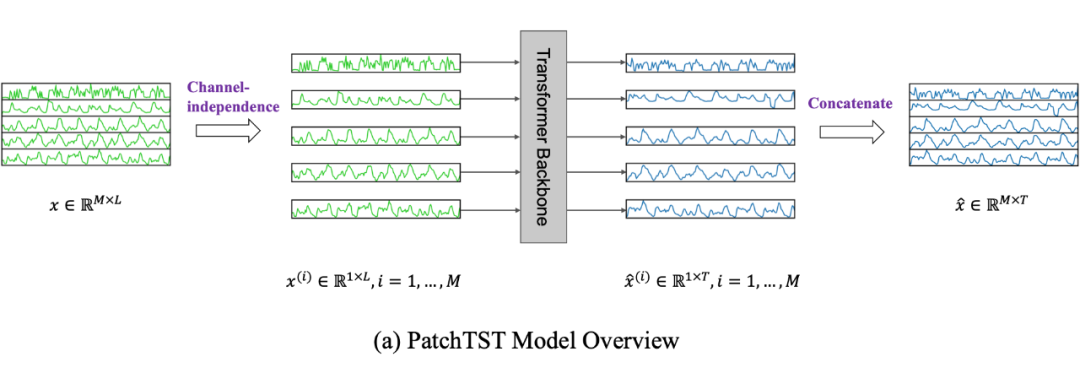
如上圖,本文將多元時(shí)間序列(維度為 )中每一維單獨(dú)進(jìn)行處理,即將每一維分別輸入到 Transformer Backbone 中,將所得預(yù)測(cè)結(jié)果再沿維度方向拼接起來。這相當(dāng)于將不同維度視為獨(dú)立的,但 embedding 和 Transformer 的權(quán)重在各個(gè)維度是共享的。 這樣的話,每個(gè) Transformer Backbone 只需要處理單變量序列。
1.3 自監(jiān)督表示學(xué)習(xí)
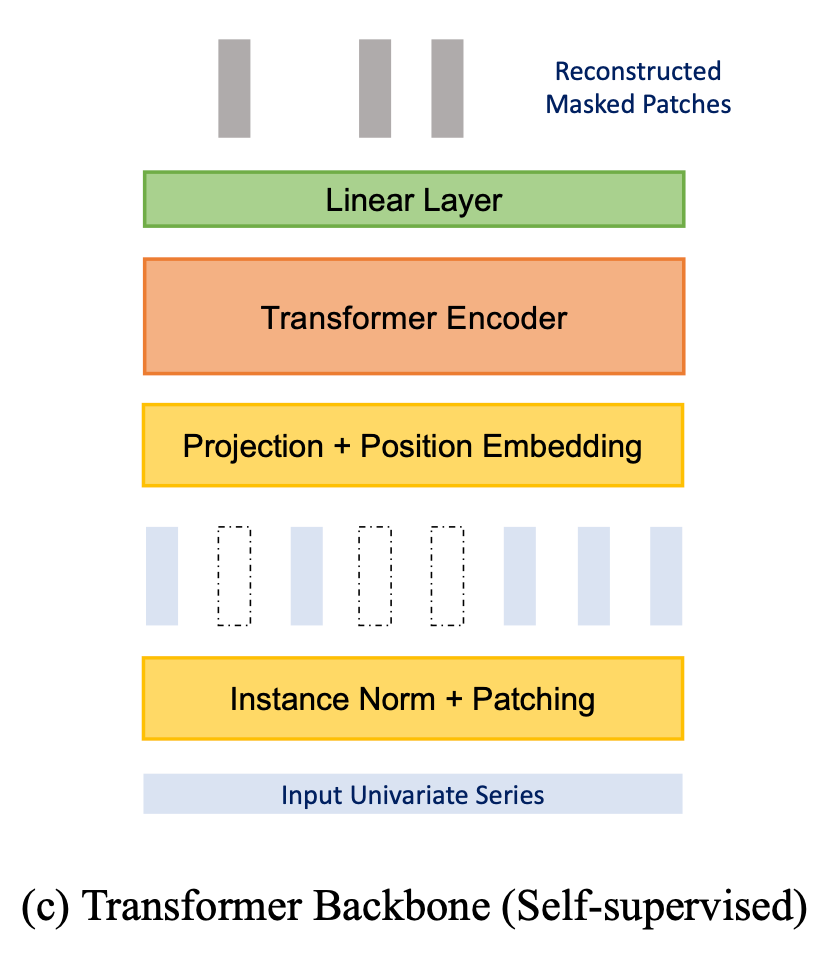
這就很直觀了,直接 mask 掉一些 patch 然后進(jìn)行重建即可。對(duì)于每一個(gè) token(patch),它通過 Transformer Encoder 后輸出維度是 ,由于該 patch 本身的長(zhǎng)度是 ,因此要重建它的話,再加上一個(gè) 的 Linear 層即可。作者還說明了分 patch 對(duì) mask 重建來進(jìn)行自監(jiān)督學(xué)習(xí)的好處: mask 一個(gè)時(shí)間點(diǎn)的話,直接根據(jù)相鄰點(diǎn)插值就可以重建,這就完全沒必要學(xué)習(xí)了,而 mask 一個(gè) patch 來重建的話則更有意義更有難度。
先進(jìn)行自監(jiān)督訓(xùn)練再微調(diào)下游預(yù)測(cè)任務(wù),效果會(huì)比直接訓(xùn)練下游預(yù)測(cè)任務(wù)要好。
實(shí)驗(yàn)結(jié)果
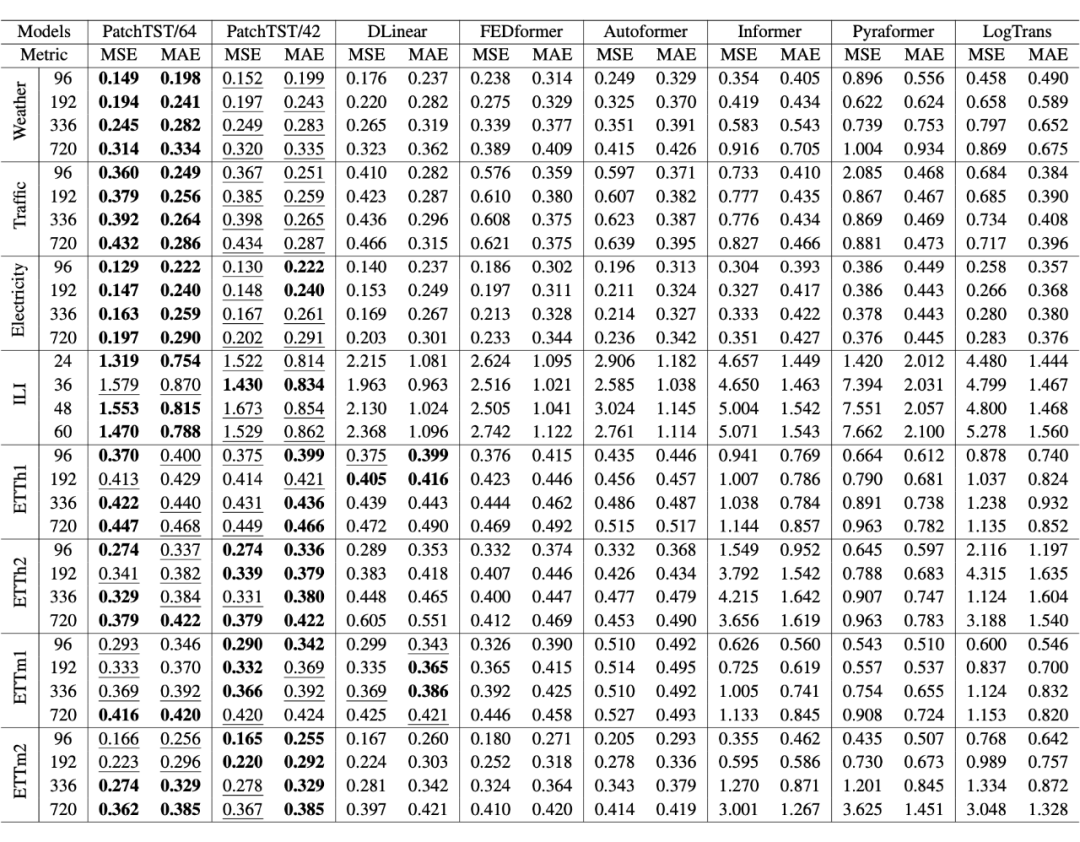
可以看到 PatchTST 的效果超過了 DLinear 以及其它的 Transformer-based 模型。
總結(jié)
論文最核心的兩點(diǎn), 分 patch、通道獨(dú)立、以及自監(jiān)督 mask 重建 的做法在之前的時(shí)間序列相關(guān)論文中都已經(jīng)存在了,所以我認(rèn)為創(chuàng)新性并不是很強(qiáng),但是效果不錯(cuò)。
評(píng)論
圖片
表情