
小白都看得懂的BERT原理圖解
0.導語
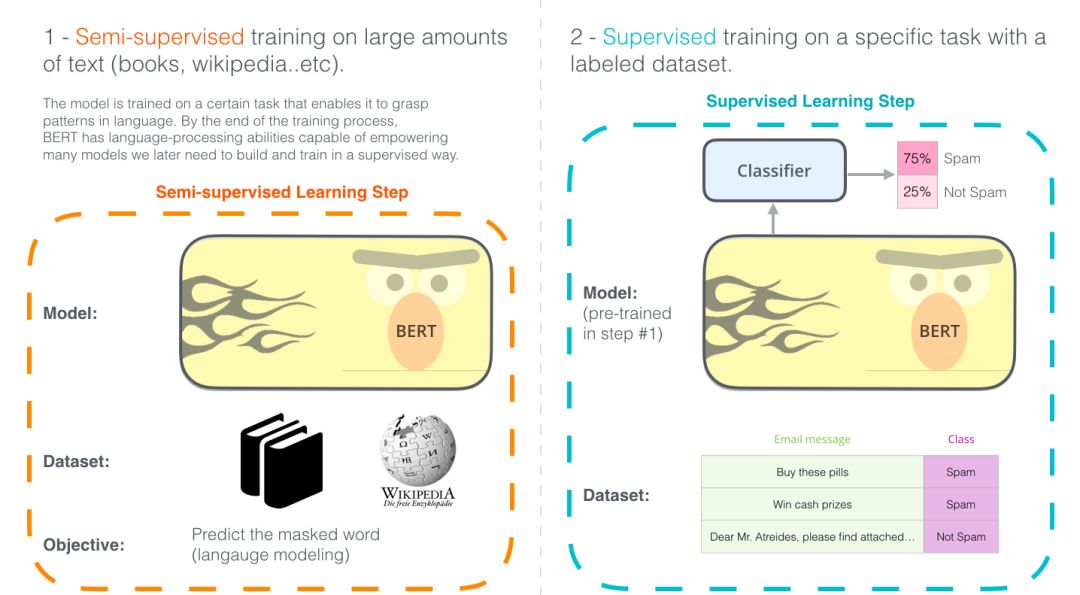
自google在2018年10月底公布BERT在11項nlp任務中的卓越表現(xiàn)后,BERT(Bidirectional Encoder Representation from Transformers)就成為NLP領域大火,在本文中,我們將研究BERT模型,理解它的工作原理,這個是NLP(自然語言處理)的非常重要的部分。
備注:前面的文章講了transformer的原理
作者:jinjiajia95
出處:https://blog.csdn.net/weixin_40746796/article/details/89951967
原作者:Jay Alammar
原鏈接:https://jalammar.github.io/illustrated-bert/
正文開始
前言
2018年可謂是自然語言處理(NLP)的元年,在我們?nèi)绾我宰钅?strong style="visibility: visible;">捕捉潛在語義關系的方式 ?來輔助計算機對的句子概念性的理解 這方面取得了極大的發(fā)展進步。此外, NLP領域的一些開源社區(qū)已經(jīng)發(fā)布了很多強大的組件,我們可以在自己的模型訓練過程中免費的下載使用。(可以說今年是NLP的ImageNet時刻,因為這和幾年前計算機視覺的發(fā)展很相似)
 上圖中,最新發(fā)布的BERT是一個NLP任務的里程碑式模型,它的發(fā)布勢必會帶來一個NLP的新時代。BERT是一個算法模型,它的出現(xiàn)打破了大量的自然語言處理任務的記錄。在BERT的論文發(fā)布不久后,Google的研發(fā)團隊還開放了該模型的代碼,并提供了一些在大量數(shù)據(jù)集上預訓練好的算法模型下載方式。Goole開源這個模型,并提供預訓練好的模型,這使得所有人都可以通過它來構建一個涉及NLP的算法模型,節(jié)約了大量訓練語言模型所需的時間,精力,知識和資源。
上圖中,最新發(fā)布的BERT是一個NLP任務的里程碑式模型,它的發(fā)布勢必會帶來一個NLP的新時代。BERT是一個算法模型,它的出現(xiàn)打破了大量的自然語言處理任務的記錄。在BERT的論文發(fā)布不久后,Google的研發(fā)團隊還開放了該模型的代碼,并提供了一些在大量數(shù)據(jù)集上預訓練好的算法模型下載方式。Goole開源這個模型,并提供預訓練好的模型,這使得所有人都可以通過它來構建一個涉及NLP的算法模型,節(jié)約了大量訓練語言模型所需的時間,精力,知識和資源。
 BERT集成了最近一段時間內(nèi)NLP領域中的一些頂尖的思想,包括但不限于 Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), and the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (Vaswani et al).。
BERT集成了最近一段時間內(nèi)NLP領域中的一些頂尖的思想,包括但不限于 Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), and the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (Vaswani et al).。
你需要注意一些事情才能恰當?shù)睦斫釨ERT的內(nèi)容,不過,在介紹模型涉及的概念之前可以使用BERT的方法。
示例:句子分類
使用BERT最簡單的方法就是做一個文本分類模型,這樣的模型結構如下圖所示:
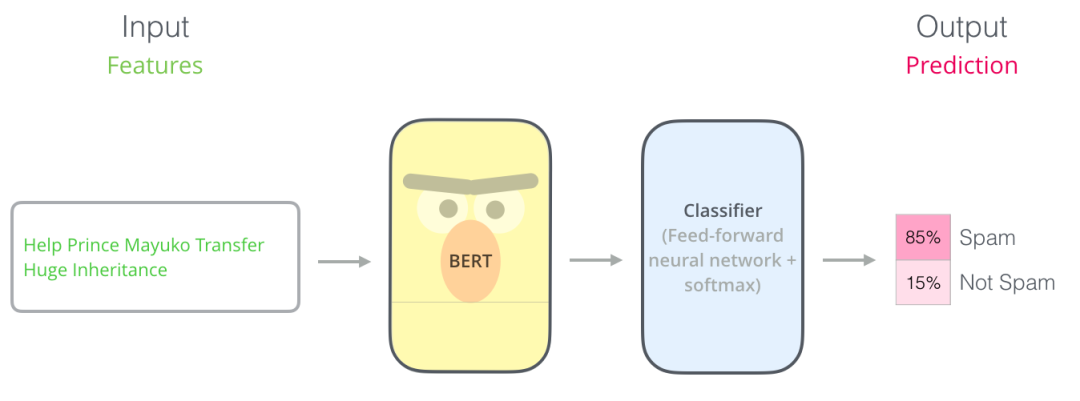
為了訓練一個這樣的模型,(主要是訓練一個分類器),在訓練階段BERT模型發(fā)生的變化很小。該訓練過程稱為微調(diào),并且源于 Semi-supervised Sequence Learning 和 ULMFiT.。
為了更方便理解,我們下面舉一個分類器的例子。分類器是屬于監(jiān)督學習領域的,這意味著你需要一些標記的數(shù)據(jù)來訓練這些模型。對于垃圾郵件分類器的示例,標記的數(shù)據(jù)集由郵件的內(nèi)容和郵件的類別2部分組成(類別分為“垃圾郵件”或“非垃圾郵件”)。
 這種用例的其他示例包括:
這種用例的其他示例包括:
情感分析
輸入:電影/產(chǎn)品評論。輸出:評論是正面還是負面?
示例數(shù)據(jù)集:SST
事實查證
輸入:句子。輸出:“索賠”或“不索賠”
更雄心勃勃/未來主義的例子:
輸入:句子。輸出:“真”或“假”
模型架構
現(xiàn)在您已經(jīng)了解了如何使用BERT的示例,讓我們仔細了解一下他的工作原理。

BERT的論文中介紹了2種版本:
BERT BASE - 與OpenAI Transformer的尺寸相當,以便比較性能
BERT LARGE - 一個非常龐大的模型,它完成了本文介紹的最先進的結果。
BERT的基礎集成單元是Transformer的Encoder。關于Transformer的介紹可以閱讀作者之前的文章:The Illustrated Transformer,該文章解釋了Transformer模型 - BERT的基本概念以及我們接下來要討論的概念。
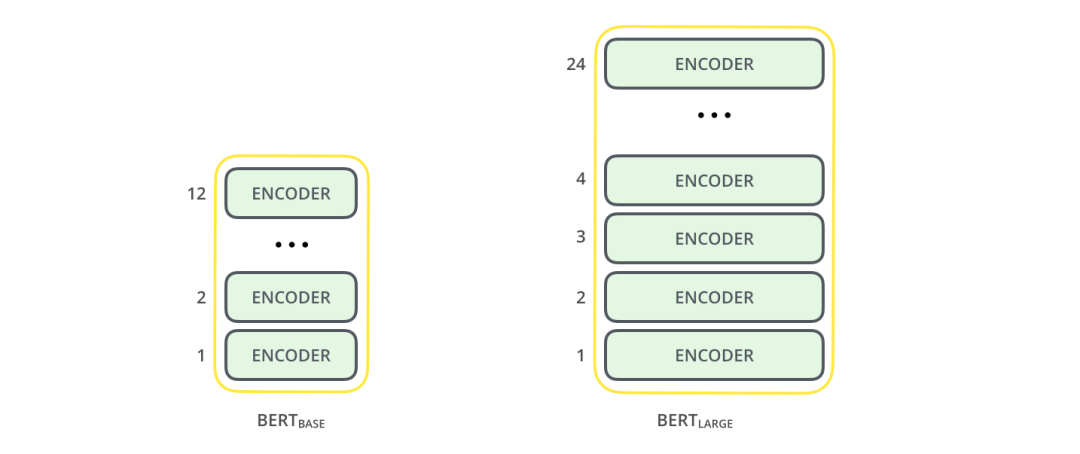
2個BERT的模型都有一個很大的編碼器層數(shù),(論文里面將此稱為Transformer Blocks) - 基礎版本就有12層,進階版本有24層。同時它也有很大的前饋神經(jīng)網(wǎng)絡( 768和1024個隱藏層神經(jīng)元),還有很多attention heads(12-16個)。這超過了Transformer論文中的參考配置參數(shù)(6個編碼器層,512個隱藏層單元,和8個注意頭)
模型輸入
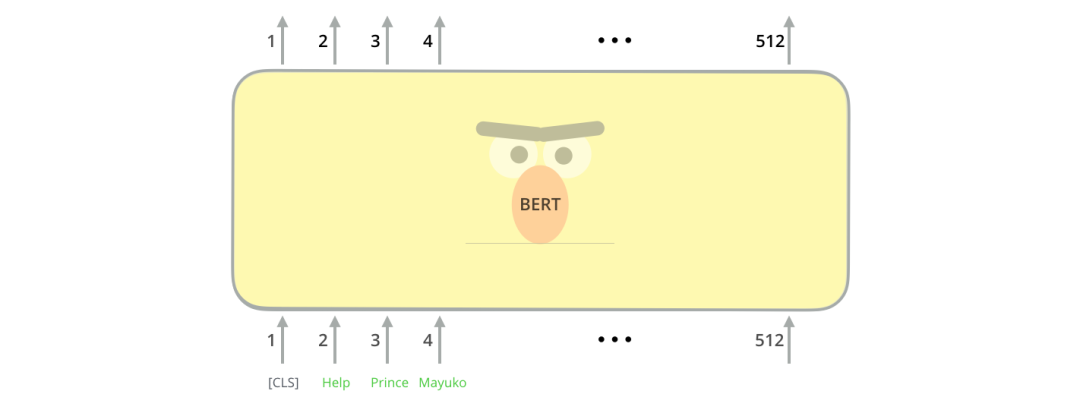
輸入的第一個字符為[CLS],在這里字符[CLS]表達的意思很簡單 - Classification (分類)。
BERT與Transformer 的編碼方式一樣。將固定長度的字符串作為輸入,數(shù)據(jù)由下而上傳遞計算,每一層都用到了self attention,并通過前饋神經(jīng)網(wǎng)絡傳遞其結果,將其交給下一個編碼器。
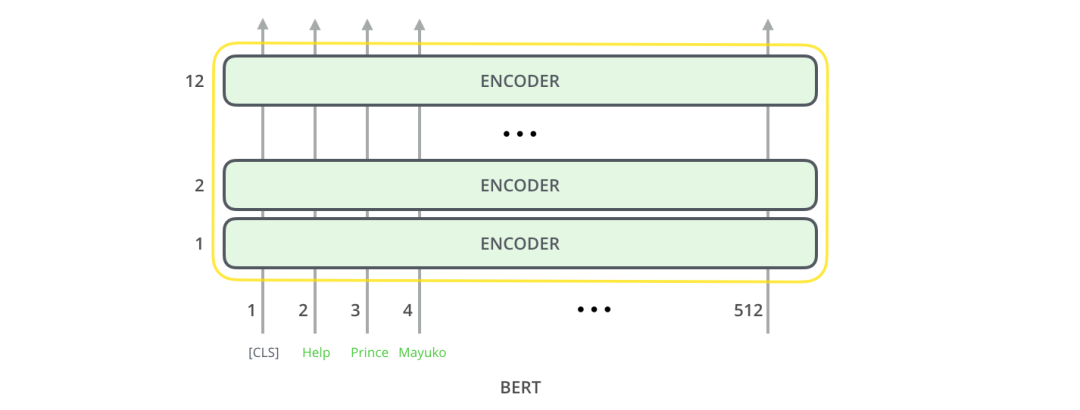
這樣的架構,似乎是沿用了Transformer 的架構(除了層數(shù),不過這是我們可以設置的參數(shù))。那么BERT與Transformer 不同之處在哪里呢?可能在模型的輸出上,我們可以發(fā)現(xiàn)一些端倪。
模型輸出
每個位置返回的輸出都是一個隱藏層大小的向量(基本版本BERT為768)。以文本分類為例,我們重點關注第一個位置上的輸出(第一個位置是分類標識[CLS]) 。如下圖
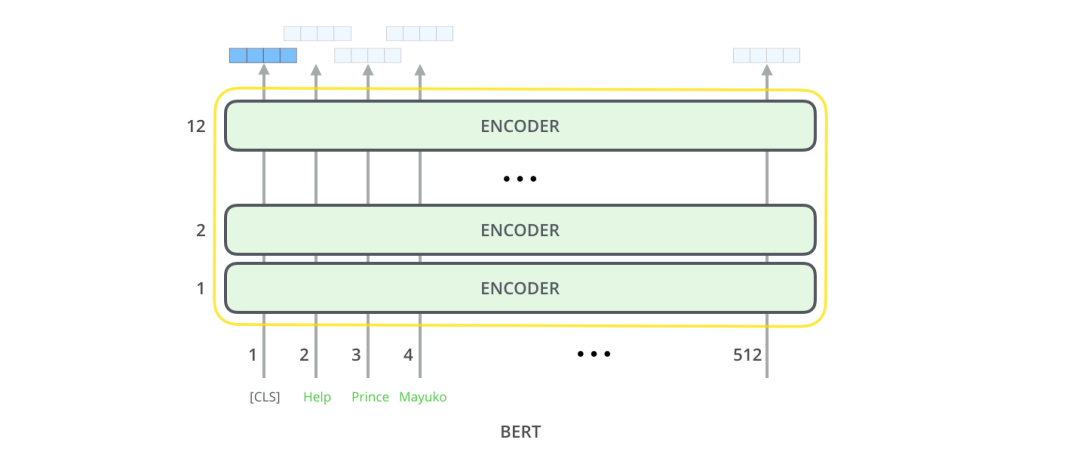
該向量現(xiàn)在可以用作我們選擇的分類器的輸入,在論文中指出使用單層神經(jīng)網(wǎng)絡作為分類器就可以取得很好的效果。原理如下。:
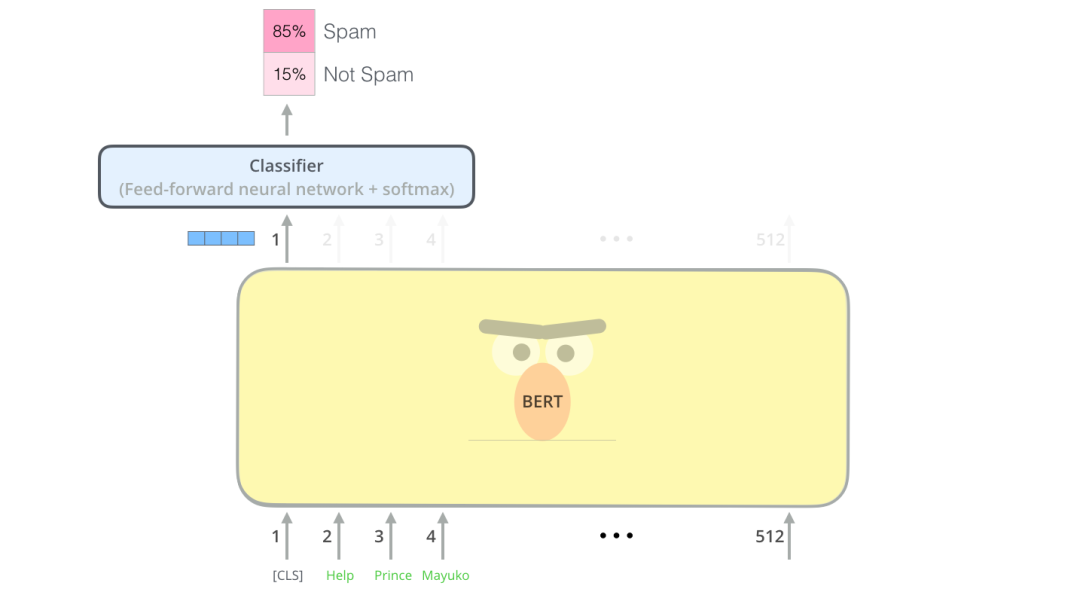
例子中只有垃圾郵件和非垃圾郵件,如果你有更多的label,你只需要增加輸出神經(jīng)元的個數(shù)即可,另外把最后的激活函數(shù)換成softmax即可。
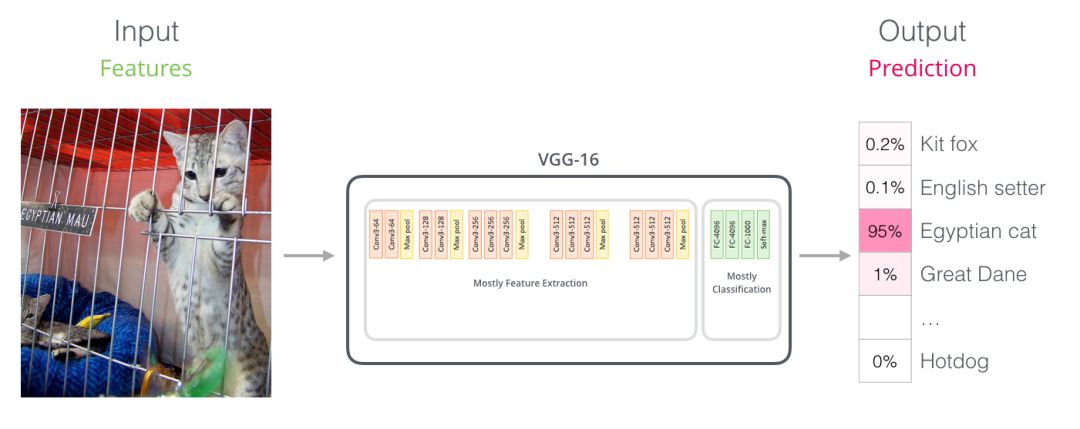
Parallels with Convolutional Nets(BERT VS卷積神經(jīng)網(wǎng)絡)
對于那些具有計算機視覺背景的人來說,這個矢量切換應該讓人聯(lián)想到VGGNet等網(wǎng)絡的卷積部分與網(wǎng)絡末端的完全連接的分類部分之間發(fā)生的事情。你可以這樣理解,實質(zhì)上這樣理解也很方便。
詞嵌入的新時代?
BERT的開源隨之而來的是一種詞嵌入的更新。到目前為止,詞嵌入已經(jīng)成為NLP模型處理自然語言的主要組成部分。諸如Word2vec和Glove 等方法已經(jīng)廣泛的用于處理這些問題,在我們使用新的詞嵌入之前,我們有必要回顧一下其發(fā)展。
詞嵌入的回顧
為了讓機器可以學習到文本的特征屬性,我們需要一些將文本數(shù)值化的表示的方式。Word2vec算法通過使用一組固定維度的向量來表示單詞,計算其方式可以捕獲到單詞的語義及單詞與單詞之間的關系。使用Word2vec的向量化表示方式可以用于判斷單詞是否相似,對立,或者說判斷“男人‘與’女人”的關系就如同“國王”與“王后”。(這些話是不是聽膩了? emmm水文必備)。另外還能捕獲到一些語法的關系,這個在英語中很實用。例如“had”與“has”的關系如同“was”與“is”的關系。
這樣的做法,我們可以使用大量的文本數(shù)據(jù)來預訓練一個詞嵌入模型,而這個詞嵌入模型可以廣泛用于其他NLP的任務,這是個好主意,這使得一些初創(chuàng)公司或者計算資源不足的公司,也能通過下載已經(jīng)開源的詞嵌入模型來完成NLP的任務。
ELMo:語境問題
上面介紹的詞嵌入方式有一個很明顯的問題,因為使用預訓練好的詞向量模型,那么無論上下文的語境關系如何,每個單詞都只有一個唯一的且已經(jīng)固定保存的向量化形式。“Wait a minute “ - 出自(Peters et. al., 2017, McCann et. al., 2017, and yet again Peters et. al., 2018 in the ELMo paper )
這和中文的同音字其實也類似,用這個舉一個例子吧, ‘長’ 這個字,在 ‘長度’ 這個詞中表示度量,在 ‘長高’ 這個詞中表示增加。那么為什么我們不通過”長’周圍是度或者是高來判斷它的讀音或者它的語義呢?嗖嘎,這個問題就派生出語境化的詞嵌入模型。
EMLo改變Word2vec類的將單詞固定為指定長度的向量的處理方式,它是在為每個單詞分配詞向量之前先查看整個句子,然后使用bi-LSTM來訓練它對應的詞向量。
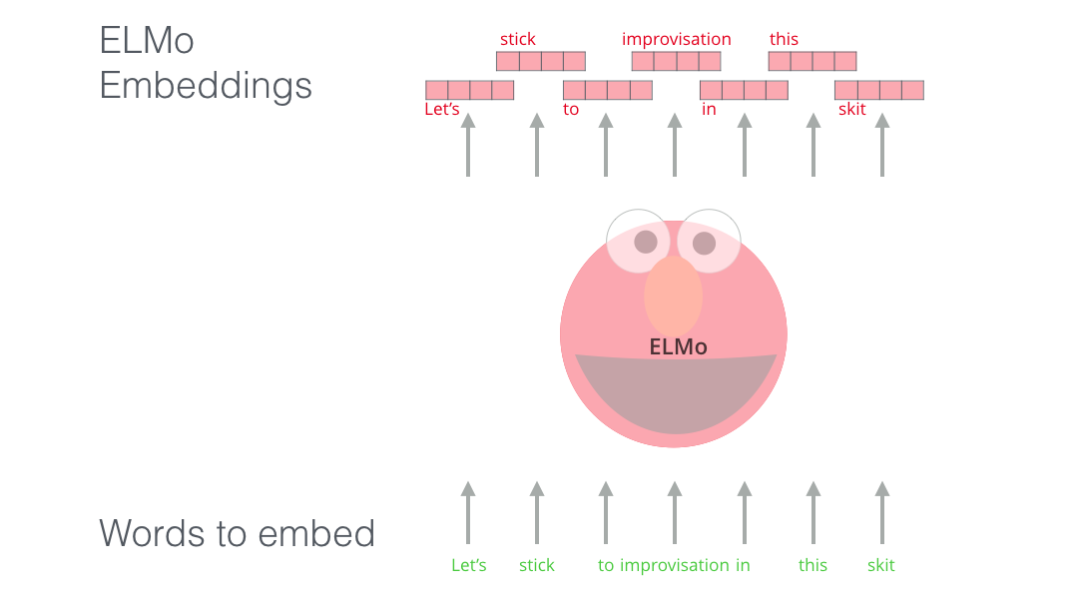 ELMo為解決NLP的語境問題作出了重要的貢獻,它的LSTM可以使用與我們?nèi)蝿障嚓P的大量文本數(shù)據(jù)來進行訓練,然后將訓練好的模型用作其他NLP任務的詞向量的基準。
ELMo為解決NLP的語境問題作出了重要的貢獻,它的LSTM可以使用與我們?nèi)蝿障嚓P的大量文本數(shù)據(jù)來進行訓練,然后將訓練好的模型用作其他NLP任務的詞向量的基準。
ELMo的秘密是什么?
ELMo會訓練一個模型,這個模型接受一個句子或者單詞的輸入,輸出最有可能出現(xiàn)在后面的一個單詞。想想輸入法,對啦,就是這樣的道理。這個在NLP中我們也稱作Language Modeling。這樣的模型很容易實現(xiàn),因為我們擁有大量的文本數(shù)據(jù)且我們可以在不需要標簽的情況下去學習。
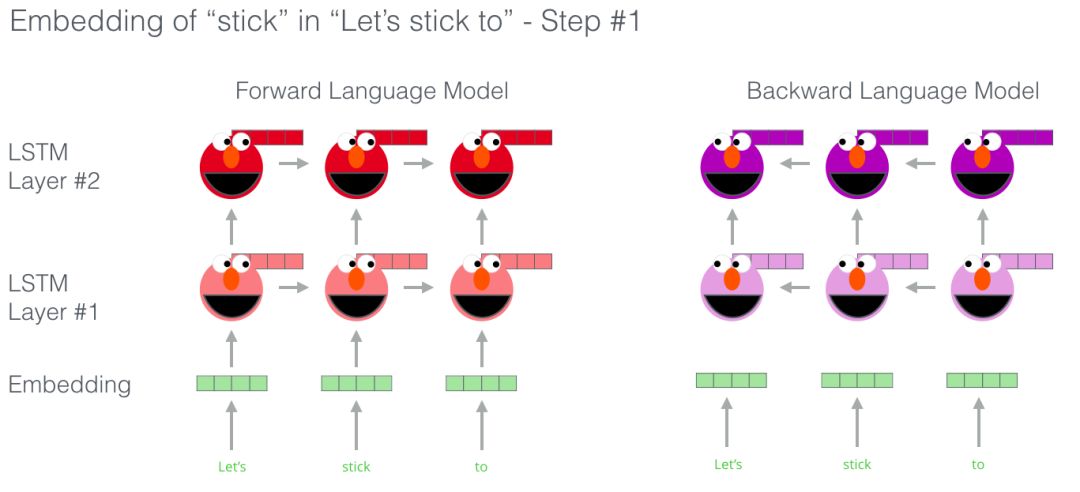
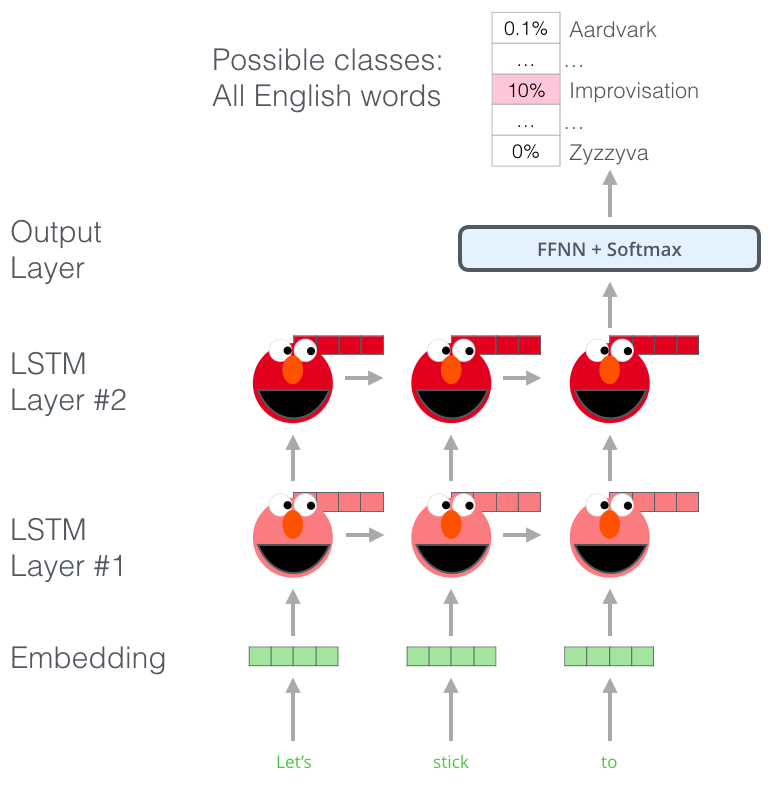 上圖介紹了ELMo預訓練的過程的步驟的一部分:我們需要完成一個這樣的任務:輸入“Lets stick to”,預測下一個最可能出現(xiàn)的單詞,如果在訓練階段使用大量的數(shù)據(jù)集進行訓練,那么在預測階段我們可能準確的預測出我們期待的下一個單詞。比如輸入“機器”,在‘’學習‘和‘買菜’中它最有可能的輸出會是‘學習’而不是‘買菜’。
上圖介紹了ELMo預訓練的過程的步驟的一部分:我們需要完成一個這樣的任務:輸入“Lets stick to”,預測下一個最可能出現(xiàn)的單詞,如果在訓練階段使用大量的數(shù)據(jù)集進行訓練,那么在預測階段我們可能準確的預測出我們期待的下一個單詞。比如輸入“機器”,在‘’學習‘和‘買菜’中它最有可能的輸出會是‘學習’而不是‘買菜’。
從上圖可以發(fā)現(xiàn),每個展開的LSTM都在最后一步完成預測。
對了真正的ELMo會更進一步,它不僅能判斷下一個詞,還能預測前一個詞。(Bi-Lstm)
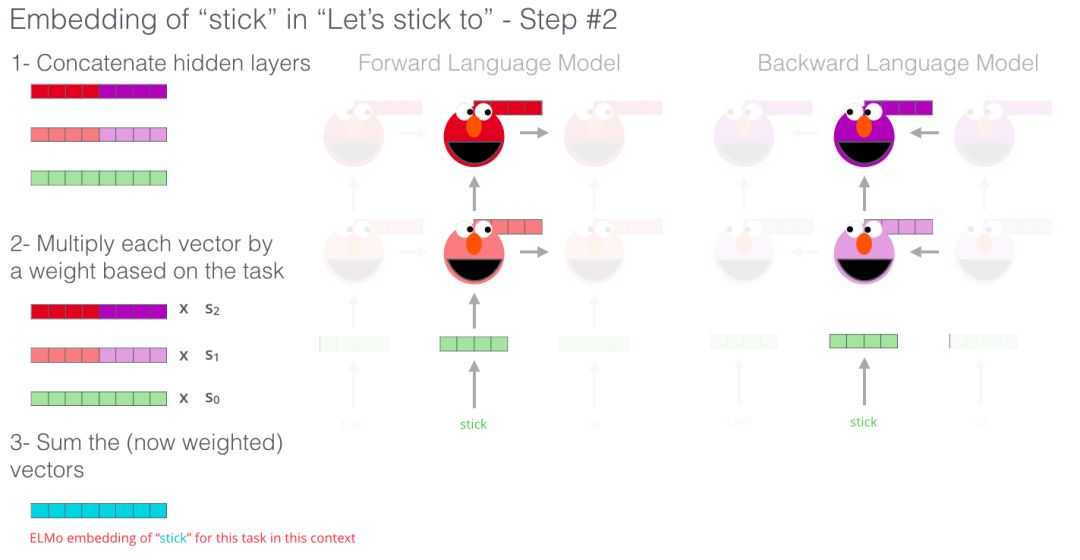
ELMo通過下圖的方式將hidden states(的初始的嵌入)組合咋子一起來提煉出具有語境意義的詞嵌入方式(全連接后加權求和)
ULM-FiT:NLP領域應用遷移學習
ULM-FiT機制讓模型的預訓練參數(shù)得到更好的利用。所利用的參數(shù)不僅限于embeddings,也不僅限于語境embedding,ULM-FiT引入了Language Model和一個有效微調(diào)該Language Model來執(zhí)行各種NLP任務的流程。這使得NLP任務也能像計算機視覺一樣方便的使用遷移學習。
The Transformer:超越LSTM的結構
Transformer論文和代碼的發(fā)布,以及其在機器翻譯等任務上取得的優(yōu)異成果,讓一些研究人員認為它是LSTM的替代品,事實上卻是Transformer比LSTM更好的處理long-term dependancies(長程依賴)問題。Transformer Encoding和Decoding的結構非常適合機器翻譯,但是怎么利用他來做文本分類的任務呢?實際上你只用使用它來預訓練可以針對其他任務微調(diào)的語言模型即可。
OpenAI Transformer:用于語言模型的Transformer解碼器預訓練
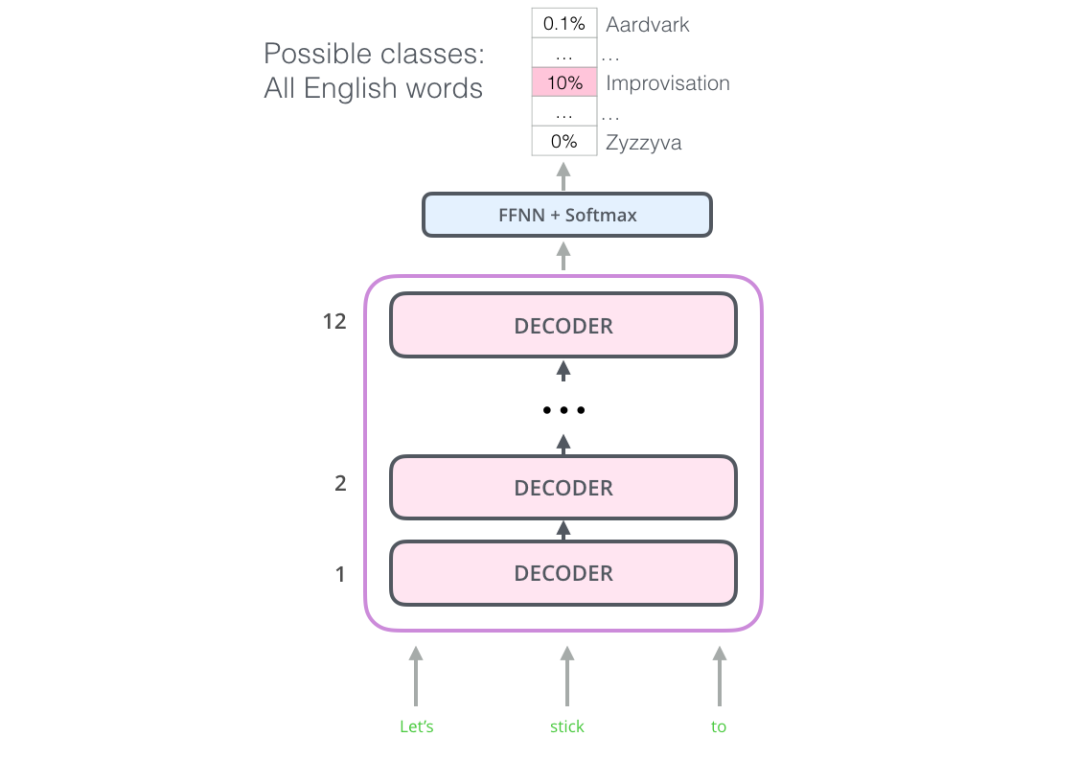
事實證明,我們并不需要一個完整的transformer結構來使用遷移學習和一個很好的語言模型來處理NLP任務。我們只需要Transformer的解碼器就行了。The decoder is a good choice because it’s a natural choice for language modeling (predicting the next word) since it’s built to mask future tokens – a valuable feature when it’s generating a translation word by word. 該模型堆疊了十二個Decoder層。由于在該設置中沒有Encoder,因此這些Decoder將不具有Transformer Decoder層具有的Encoder - Decoder attention層。然而,取而代之的是一個self attention層(masked so it doesn’t peak at future tokens)。
該模型堆疊了十二個Decoder層。由于在該設置中沒有Encoder,因此這些Decoder將不具有Transformer Decoder層具有的Encoder - Decoder attention層。然而,取而代之的是一個self attention層(masked so it doesn’t peak at future tokens)。
通過這種結構調(diào)整,我們可以繼續(xù)在相似的語言模型任務上訓練模型:使用大量的未標記數(shù)據(jù)集訓練,來預測下一個單詞。舉個列子:你那7000本書喂給你的模型,(書籍是極好的訓練樣本~比博客和推文好很多。)訓練框架如下:
Transfer Learning to Downstream Tasks
通過OpenAI的transformer的預訓練和一些微調(diào)后,我們就可以將訓練好的模型,用于其他下游NLP任務啦。(比如訓練一個語言模型,然后拿他的hidden state來做分類。),下面就介紹一下這個騷操作。(還是如上面例子:分為垃圾郵件和非垃圾郵件)
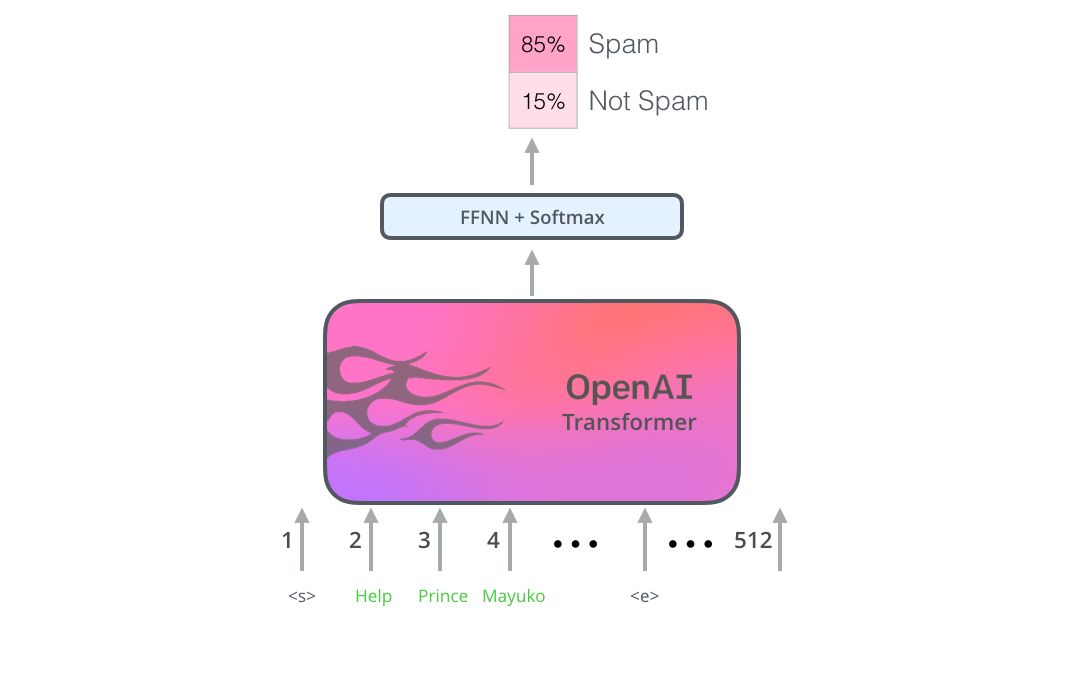
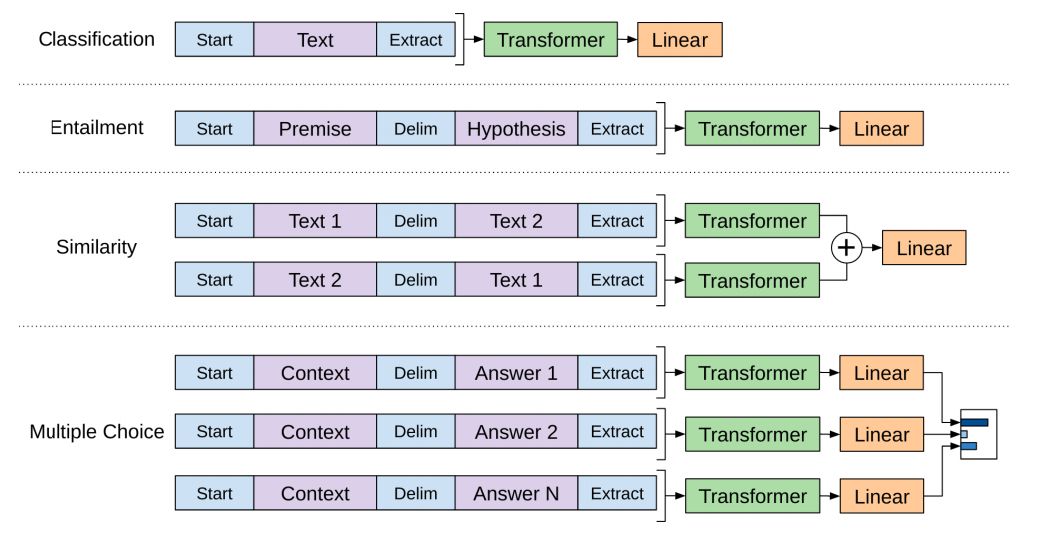
OpenAI論文概述了許多Transformer使用遷移學習來處理不同類型NLP任務的例子。如下圖例子所示:
BERT: From Decoders to Encoders
OpenAI transformer為我們提供了基于Transformer的精密的預訓練模型。但是從LSTM到Transformer的過渡中,我們發(fā)現(xiàn)少了些東西。ELMo的語言模型是雙向的,但是OpenAI的transformer是前向訓練的語言模型。我們能否讓我們的Transformer模型也具有Bi-Lstm的特性呢?
R-BERT:“Hold my beer”
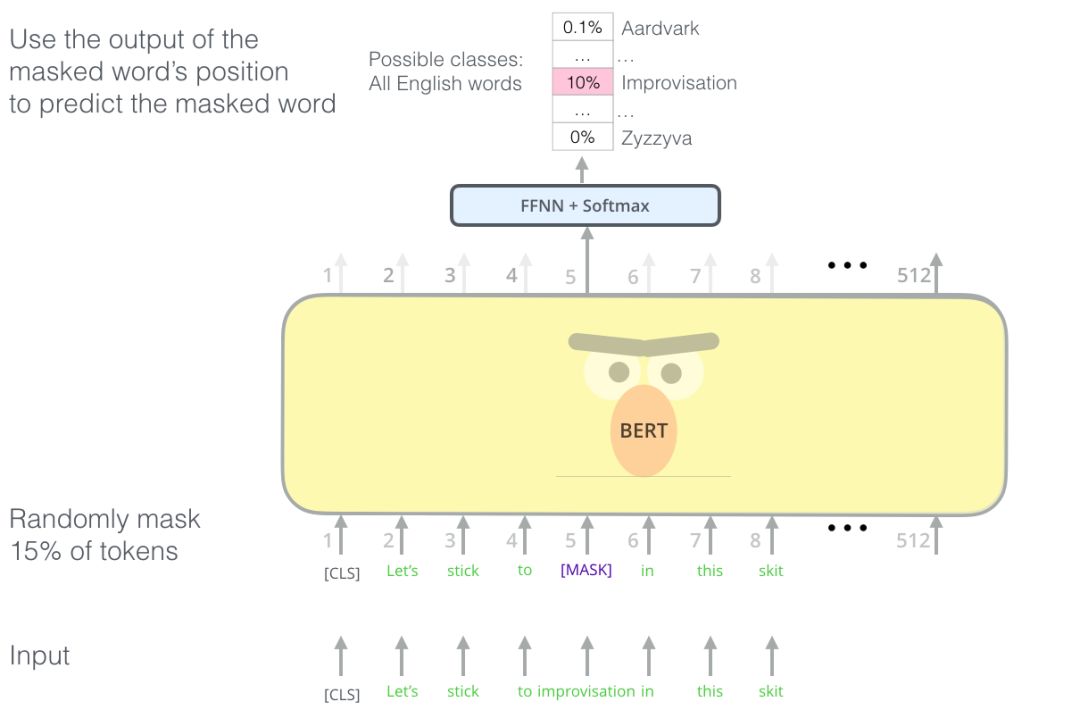
Masked Language Model
BERT說:“我要用 transformer 的 encoders”
Ernie不屑道:“呵呵,你不能像Bi-Lstm一樣考慮文章”
BERT自信回答道:“我們會用masks”
解釋一下Mask:
語言模型會根據(jù)前面單詞來預測下一個單詞,但是self-attention的注意力只會放在自己身上,那么這樣100%預測到自己,毫無意義,所以用Mask,把需要預測的詞給擋住。
如下圖:
Two-sentence Tasks
我們回顧一下OpenAI transformer處理不同任務的輸入轉(zhuǎn)換,你會發(fā)現(xiàn)在某些任務上我們需要2個句子作為輸入,并做一些更為智能的判斷,比如是否相似,比如 給出一個維基百科的內(nèi)容作為輸入,同時在放入一條針對該條目的問題,那么我們的算法模型能夠處理這個問題嗎?
為了使BERT更好的處理2個句子之間的關系,預訓練的過程還有一個額外的任務:給定2個句子(A和B),A與B是否相似?(0或者1)

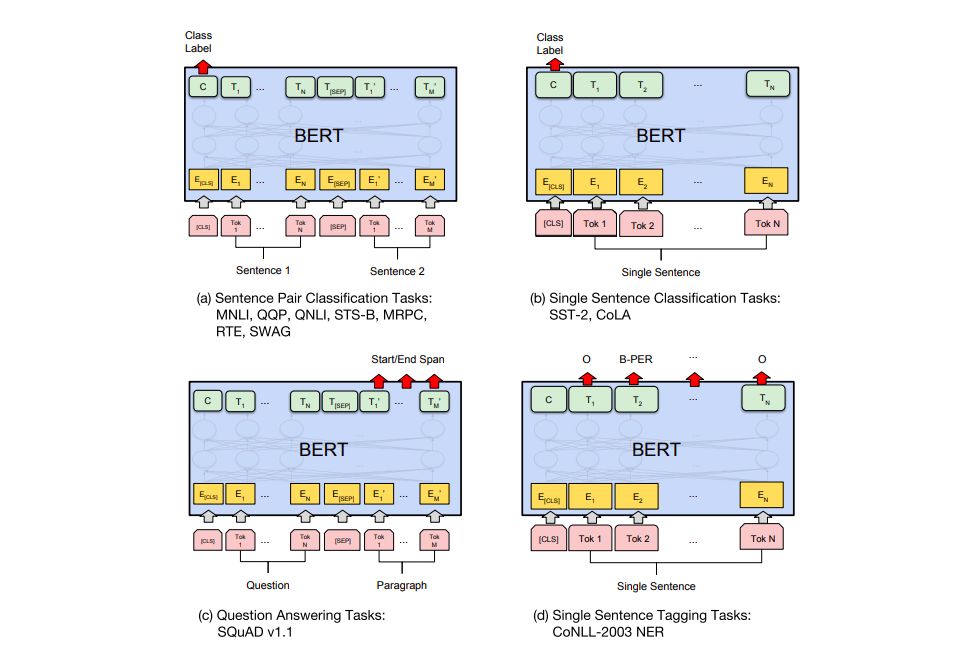
特殊NLP任務
BERT的論文為我們介紹了幾種BERT可以處理的NLP任務:
短文本相似
文本分類
QA機器人
語義標注
BERT用做特征提取
微調(diào)方法并不是使用BERT的唯一方法,就像ELMo一樣,你可以使用預選訓練好的BERT來創(chuàng)建語境化詞嵌入。然后你可以將這些嵌入提供給現(xiàn)有的模型。
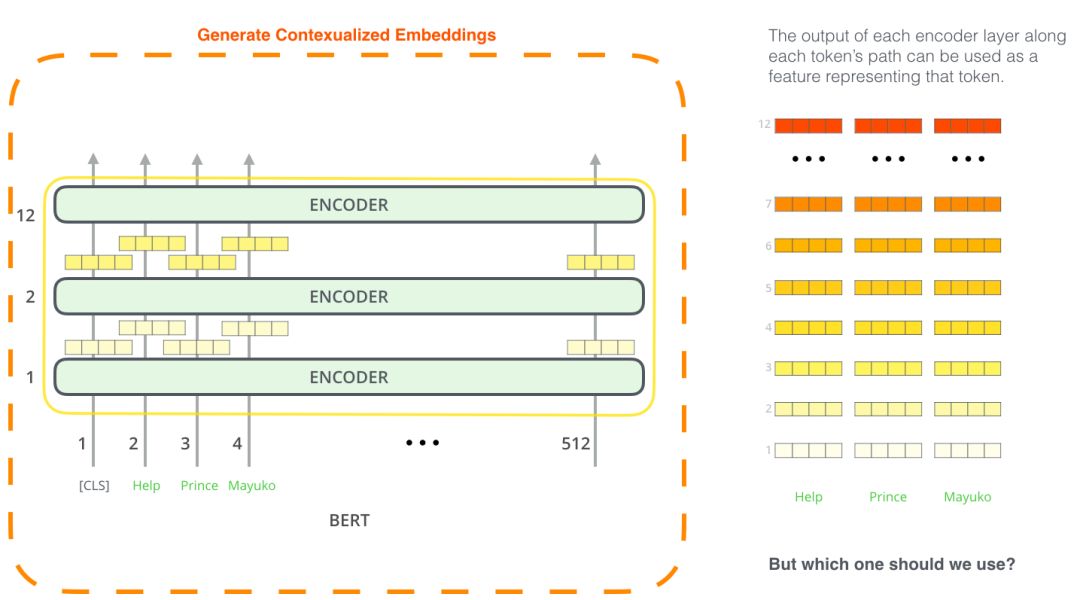
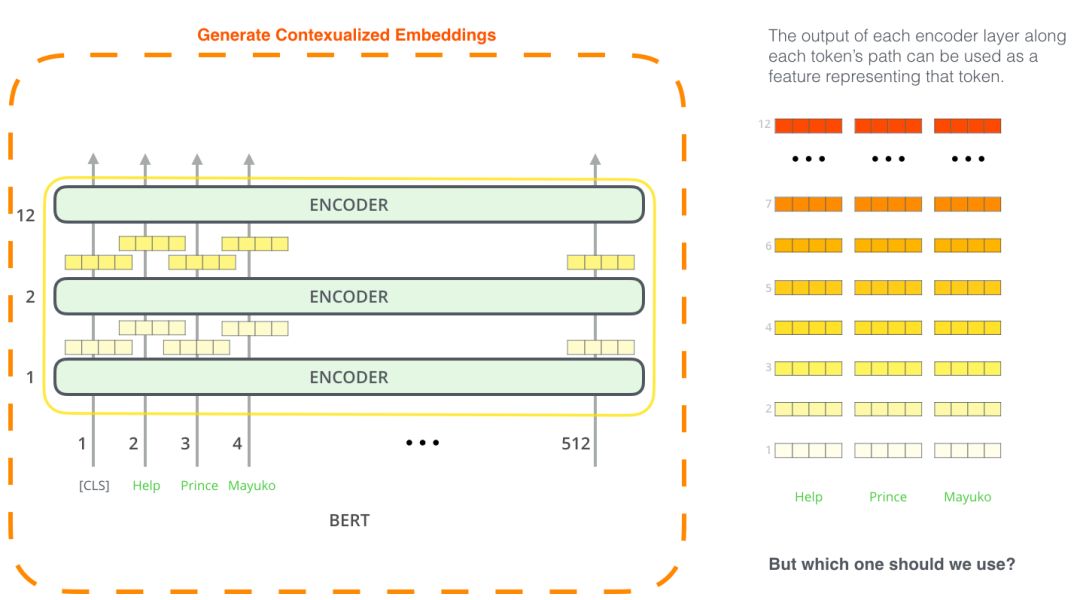
哪個向量最適合作為上下文嵌入?我認為這取決于任務。本文考察了六種選擇(與微調(diào)模型相比,得分為96.4):
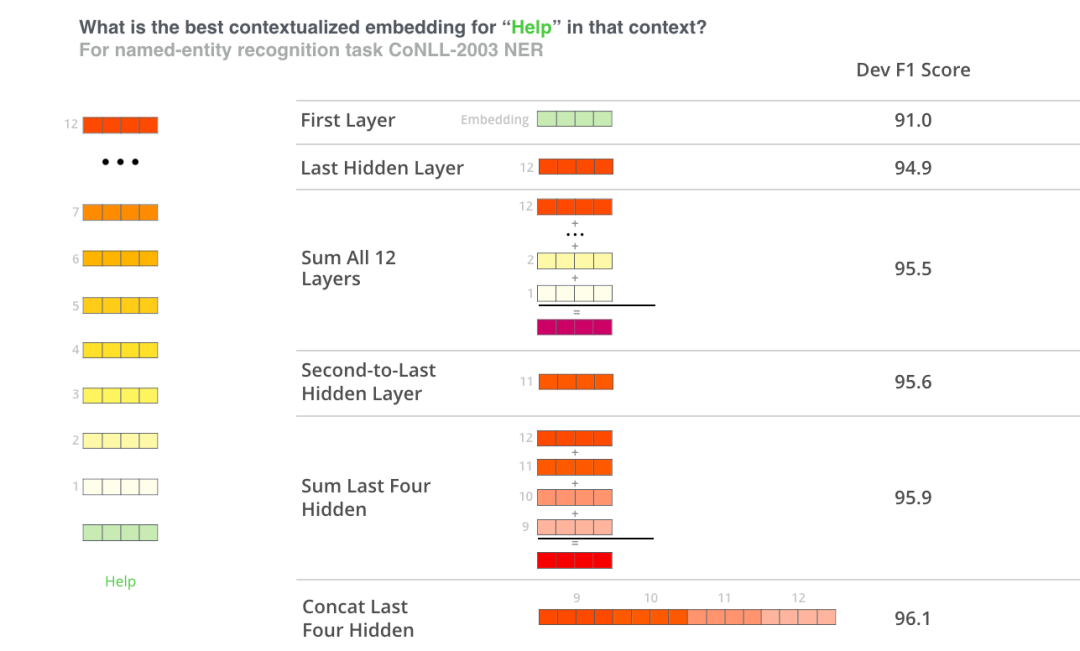
如何使用BERT
使用BERT的最佳方式是通過 BERT FineTuning with Cloud TPUs 谷歌云上托管的筆記
(https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb)。
如果你未使用過谷歌云TPU可以試試看,這是個不錯的嘗試。另外BERT也適用于TPU,CPU和GPU
下一步是查看BERT倉庫中的代碼:
該模型在modeling.py ?(BertModel類)中構建,與vanilla Transformer編碼器完全相同。
(https://github.com/google-research/bert/blob/master/modeling.py)
run_classifier.py是微調(diào)過程的一個示例。
它還構建了監(jiān)督模型的分類層。
(https://github.com/google-research/bert/blob/master/run_classifier.py)
如果要構建自己的分類器,請查看該文件中的create_model()方法。
可以下載幾種預先訓練的模型。
涵蓋102種語言的多語言模型,這些語言都是在維基百科的數(shù)據(jù)基礎上訓練而成的。
BERT不會將單詞視為tokens。相反,它注重WordPieces。
tokenization.py是將你的單詞轉(zhuǎn)換為適合BERT的wordPieces的tokensizer。
(https://github.com/google-research/bert/blob/master/tokenization.py)
您還可以查看BERT的PyTorch實現(xiàn)。
(https://github.com/huggingface/pytorch-pretrained-BERT)
AllenNLP庫使用此實現(xiàn)允許將BERT嵌入與任何模型一起使用。
(https://github.com/allenai/allennlp)
(https://github.com/allenai/allennlp/pull/2067)? ? ? ??