
漫談千億級數(shù)據(jù)優(yōu)化實(shí)踐:數(shù)據(jù)傾斜
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




0x00 前言
數(shù)據(jù)傾斜是大數(shù)據(jù)領(lǐng)域繞不開的攔路虎,當(dāng)你所需處理的數(shù)據(jù)量到達(dá)了上億甚至是千億條的時(shí)候,數(shù)據(jù)傾斜將是橫在你面前一道巨大的坎。
邁的過去,將會海闊天空!邁不過去,就要做好準(zhǔn)備:很可能有幾周甚至幾月都要頭疼于數(shù)據(jù)傾斜導(dǎo)致的各類詭異的問題。
鄭重聲明:
話題比較大,技術(shù)要求也比較高,筆者盡最大的能力來寫出自己的理解,寫的不對和不好的地方大家一起交流。
有些例子不是特別嚴(yán)謹(jǐn),一些小細(xì)節(jié)對文章理解沒有影響,不要太在意。(比如我在算機(jī)器內(nèi)存的時(shí)候,就不把Hadoop自身的進(jìn)程算到使用內(nèi)存中)
文章結(jié)構(gòu)
先大致解釋一下什么是數(shù)據(jù)傾斜
再根據(jù)幾個(gè)場景來描述一下數(shù)據(jù)傾斜產(chǎn)生的情況
詳細(xì)分析一下在Hadoop和Spark中產(chǎn)生數(shù)據(jù)傾斜的原因
如何解決(優(yōu)化)數(shù)據(jù)傾斜問題?
簡單的講,數(shù)據(jù)傾斜就是我們在計(jì)算數(shù)據(jù)的時(shí)候,數(shù)據(jù)的分散度不夠,導(dǎo)致大量的數(shù)據(jù)集中到了一臺或者幾臺機(jī)器上計(jì)算,這些數(shù)據(jù)的計(jì)算速度遠(yuǎn)遠(yuǎn)低于平均計(jì)算速度,導(dǎo)致整個(gè)計(jì)算過程過慢。
一、關(guān)鍵字:數(shù)據(jù)傾斜
相信大部分做數(shù)據(jù)的童鞋們都會遇到數(shù)據(jù)傾斜,數(shù)據(jù)傾斜會發(fā)生在數(shù)據(jù)開發(fā)的各個(gè)環(huán)節(jié)中,比如:
用Hive算數(shù)據(jù)的時(shí)候reduce階段卡在99.99%
用SparkStreaming做實(shí)時(shí)算法時(shí)候,一直會有executor出現(xiàn)OOM的錯(cuò)誤,但是其余的executor內(nèi)存使用率卻很低。
這些問題經(jīng)常會困擾我們,辛辛苦苦等了幾個(gè)小時(shí)的數(shù)據(jù)就是跑不出來,心里多難過啊。
例子很多,這里先隨便舉兩個(gè),后文會詳細(xì)的說明。
二、關(guān)鍵字:千億級
為什么要突出這么大數(shù)據(jù)量?先說一下筆者自己最初對數(shù)據(jù)量的理解:
數(shù)據(jù)量大就了不起了?數(shù)據(jù)量少,機(jī)器也少,計(jì)算能力也是有限的,因此難度也是一樣的。憑什么數(shù)據(jù)量大就會有數(shù)據(jù)傾斜,數(shù)據(jù)量小就沒有?
這樣理解也有道理,但是比較片面,舉兩個(gè)場景來對比:
公司一:總用戶量1000萬,5臺64G內(nèi)存的的服務(wù)器。
公司二:總用戶量10億,1000臺64G內(nèi)存的服務(wù)器。
兩個(gè)公司都部署了Hadoop集群。假設(shè)現(xiàn)在遇到了數(shù)據(jù)傾斜,發(fā)生什么?
公司一的數(shù)據(jù)分時(shí)童鞋在做join的時(shí)候發(fā)生了數(shù)據(jù)傾斜,會導(dǎo)致有幾百萬用戶的相關(guān)數(shù)據(jù)集中到了一臺服務(wù)器上,幾百萬的用戶數(shù)據(jù),說大也不大,正常字段量的數(shù)據(jù)的話64G還是能輕松處理掉的。
公司二的數(shù)據(jù)分時(shí)童鞋在做join的時(shí)候也發(fā)生了數(shù)據(jù)傾斜,可能會有1個(gè)億的用戶相關(guān)數(shù)據(jù)集中到了一臺機(jī)器上了(相信我,這很常見),這時(shí)候一臺機(jī)器就很難搞定了,最后會很難算出結(jié)果。
0x02 數(shù)據(jù)傾斜長什么樣
筆者大部分的數(shù)據(jù)傾斜問題都解決了,而且也不想重新運(yùn)行任務(wù)來截圖,下面會分幾個(gè)場景來描述一下數(shù)據(jù)傾斜的特征,方便讀者辨別。
由于Hadoop和Spark是最常見的兩個(gè)計(jì)算平臺,下面就以這兩個(gè)平臺說明:
一、Hadoop中的數(shù)據(jù)傾斜
Hadoop中直接貼近用戶使用使用的時(shí)Mapreduce程序和Hive程序,雖說Hive最后也是用MR來執(zhí)行(至少目前Hive內(nèi)存計(jì)算并不普及),但是畢竟寫的內(nèi)容邏輯區(qū)別很大,一個(gè)是程序,一個(gè)是Sql,因此這里稍作區(qū)分。
Hadoop中的數(shù)據(jù)傾斜主要表現(xiàn)在、ruduce階段卡在99.99%,一直99.99%不能結(jié)束。
這里如果詳細(xì)的看日志或者和監(jiān)控界面的話會發(fā)現(xiàn):
有一個(gè)多幾個(gè)reduce卡住
各種container報(bào)錯(cuò)OOM
讀寫的數(shù)據(jù)量極大,至少遠(yuǎn)遠(yuǎn)超過其它正常的reduce
伴隨著數(shù)據(jù)傾斜,會出現(xiàn)任務(wù)被kill等各種詭異的表現(xiàn)。
經(jīng)驗(yàn):Hive的數(shù)據(jù)傾斜,一般都發(fā)生在Sql中Group和On上,而且和數(shù)據(jù)邏輯綁定比較深。
二、Spark中的數(shù)據(jù)傾斜
Spark中的數(shù)據(jù)傾斜也很常見,這里包括Spark Streaming和Spark Sql,表現(xiàn)主要有下面幾種:
Executor lost,OOM,Shuffle過程出錯(cuò)
Driver OOM
單個(gè)Executor執(zhí)行時(shí)間特別久,整體任務(wù)卡在某個(gè)階段不能結(jié)束
正常運(yùn)行的任務(wù)突然失敗
補(bǔ)充一下,在Spark streaming程序中,數(shù)據(jù)傾斜更容易出現(xiàn),特別是在程序中包含一些類似sql的join、group這種操作的時(shí)候。因?yàn)镾park Streaming程序在運(yùn)行的時(shí)候,我們一般不會分配特別多的內(nèi)存,因此一旦在這個(gè)過程中出現(xiàn)一些數(shù)據(jù)傾斜,就十分容易造成OOM。
0x03 數(shù)據(jù)傾斜的原理
一、數(shù)據(jù)傾斜產(chǎn)生的原因
我們以Spark和Hive的使用場景為例。他們在做數(shù)據(jù)運(yùn)算的時(shí)候會設(shè)計(jì)到,countdistinct、group by、join等操作,這些都會觸發(fā)Shuffle動作,一旦觸發(fā),所有相同key的值就會拉到一個(gè)或幾個(gè)節(jié)點(diǎn)上,就容易發(fā)生單點(diǎn)問題。
二、萬惡的shuffle
Shuffle是一個(gè)能產(chǎn)生奇跡的地方,不管是在Spark還是Hadoop中,它們的作用都是至關(guān)重要的。關(guān)于Shuffle的原理,這里不再講述,看看Hadoop相關(guān)的論文或者文章理解一下就ok。這里主要針對,在Shuffle如何產(chǎn)生了數(shù)據(jù)傾斜。
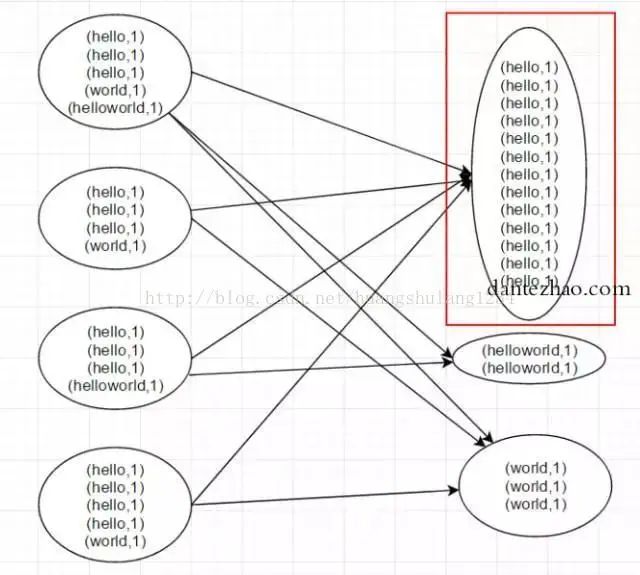
Hadoop和Spark在Shuffle過程中產(chǎn)生數(shù)據(jù)傾斜的原理基本類似。如下圖。
大部分?jǐn)?shù)據(jù)傾斜的原理就類似于下圖,很明了,因?yàn)閿?shù)據(jù)分布不均勻,導(dǎo)致大量的數(shù)據(jù)分配到了一個(gè)節(jié)點(diǎn)。
三、從數(shù)據(jù)角度來理解數(shù)據(jù)傾斜
我們舉一個(gè)例子,就說數(shù)據(jù)默認(rèn)值的設(shè)計(jì)吧,假設(shè)我們有兩張表:
user(用戶信息表):userid,register_ip
ip(IP表):ip,register_user_cnt
這可能是兩個(gè)不同的人開發(fā)的數(shù)據(jù)表,如果我們的數(shù)據(jù)規(guī)范不太完善的話,會出現(xiàn)一種情況,user表中的register_ip字段,如果獲取不到這個(gè)信息,我們默認(rèn)為null,但是在ip表中,我們在統(tǒng)計(jì)這個(gè)值的時(shí)候,為了方便,我們把獲取不到ip的用戶,統(tǒng)一認(rèn)為他們的ip為0。
兩邊其實(shí)都沒有錯(cuò)的,但是一旦我們做關(guān)聯(lián)了會出現(xiàn)什么情況,這個(gè)任務(wù)會在做關(guān)聯(lián)的階段,也就是sql的on的階段卡死。
四、從業(yè)務(wù)計(jì)角度來理解數(shù)據(jù)傾斜
數(shù)據(jù)往往和業(yè)務(wù)是強(qiáng)相關(guān)的,業(yè)務(wù)的場景直接影響到了數(shù)據(jù)的分布。
再舉一個(gè)例子,比如就說訂單場景吧,我們在某一天在北京和上海兩個(gè)城市多了強(qiáng)力的推廣,結(jié)果可能是這兩個(gè)城市的訂單量增長了10000%,其余城市的數(shù)據(jù)量不變。
然后我們要統(tǒng)計(jì)不同城市的訂單情況,這樣,一做group操作,可能直接就數(shù)據(jù)傾斜了。
0x04 如何解決
數(shù)據(jù)傾斜的產(chǎn)生是有一些討論的,解決它們也是有一些討論的,本章會先給出幾個(gè)解決數(shù)據(jù)傾斜的思路,然后對Hadoop和Spark分別給出一些解決數(shù)據(jù)傾斜的方案。
注意:?很多數(shù)據(jù)傾斜的問題,都可以用和平臺無關(guān)的方式解決,比如更好的數(shù)據(jù)預(yù)處理, 異常值的過濾等,因此筆者認(rèn)為,解決數(shù)據(jù)傾斜的重點(diǎn)在于對數(shù)據(jù)設(shè)計(jì)和業(yè)務(wù)的理解,這兩個(gè)搞清楚了,數(shù)據(jù)傾斜就解決了大部分了。
一、幾個(gè)思路
解決數(shù)據(jù)傾斜有這幾個(gè)思路:
業(yè)務(wù)邏輯,我們從業(yè)務(wù)邏輯的層面上來優(yōu)化數(shù)據(jù)傾斜,比如上面的例子,我們單獨(dú)對這兩個(gè)城市來做count,最后和其它城市做整合。
程序?qū)用妫热缯f在Hive中,經(jīng)常遇到
count(distinct)操作,這樣會導(dǎo)致最終只有一個(gè)reduce,我們可以先group 再在外面包一層count,就可以了。調(diào)參方面,Hadoop和Spark都自帶了很多的參數(shù)和機(jī)制來調(diào)節(jié)數(shù)據(jù)傾斜,合理利用它們就能解決大部分問題。
二、從業(yè)務(wù)和數(shù)據(jù)上解決數(shù)據(jù)傾斜
很多數(shù)據(jù)傾斜都是在數(shù)據(jù)的使用上造成的。我們舉幾個(gè)場景,并分別給出它們的解決方案。
數(shù)據(jù)分布不均勻:
前面提到的“從數(shù)據(jù)角度來理解數(shù)據(jù)傾斜”和“從業(yè)務(wù)計(jì)角度來理解數(shù)據(jù)傾斜”中的例子,其實(shí)都是數(shù)據(jù)分布不均勻的類型,這種情況和計(jì)算平臺無關(guān),我們能通過設(shè)計(jì)的角度嘗試解決它。
有損的方法:
找到異常數(shù)據(jù),比如ip為0的數(shù)據(jù),過濾掉
無損的方法:
對分布不均勻的數(shù)據(jù),單獨(dú)計(jì)算
先對key做一層hash,先將數(shù)據(jù)打散讓它的并行度變大,再匯集
數(shù)據(jù)預(yù)處理
三、Hadoop平臺的優(yōu)化方法
列出來一些方法和思路,具體的參數(shù)和用法在官網(wǎng)看就行了。
mapjoin方式
count distinct的操作,先轉(zhuǎn)成group,再count
萬能膏藥:hive.groupby.skewindata=true
left semi jioin的使用
設(shè)置map端輸出、中間結(jié)果壓縮。(不完全是解決數(shù)據(jù)傾斜的問題,但是減少了IO讀寫和網(wǎng)絡(luò)傳輸,能提高很多效率)
四、Spark平臺的優(yōu)化方法
列出來一些方法和思路,具體的參數(shù)和用法在官網(wǎng)看就行了。
mapjoin方式
設(shè)置rdd壓縮
合理設(shè)置driver的內(nèi)存
Spark Sql中的優(yōu)化和Hive類似,可以參考Hive
0xFF 總結(jié)
數(shù)據(jù)傾斜的坑還是很大的,如何處理數(shù)據(jù)傾斜是一個(gè)長期的過程,希望本文的一些思路能提供幫助。
文中一些內(nèi)容沒有細(xì)講,比如Hive Sql的優(yōu)化,數(shù)據(jù)清洗中的各種坑,這些留待后面單獨(dú)的分享,會有很多的內(nèi)容。
另外千億級別的數(shù)據(jù)還會有更多的難點(diǎn),不僅僅是數(shù)據(jù)傾斜的問題,這一點(diǎn)在后面也會有專門的分享。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??