
深入淺出 Linux 進(jìn)程管理
1. 基礎(chǔ)知識(shí)
進(jìn)程類(lèi)型
實(shí)時(shí)進(jìn)程
非實(shí)時(shí)進(jìn)程
CPU 資源占用類(lèi)型
CPU 消耗性 (CPU-Bound)
I/O 消耗性 (IO-Bound)
交互進(jìn)程(對(duì)響應(yīng)時(shí)間有要求)
進(jìn)程優(yōu)先級(jí)
靜態(tài)優(yōu)先級(jí) (static_prio)
實(shí)時(shí)進(jìn)程 0 - 99
非實(shí)時(shí)進(jìn)程 100 - 139

非實(shí)時(shí)進(jìn)程靜態(tài)優(yōu)先級(jí)可以通過(guò) nice() 進(jìn)行調(diào)整。?范圍 (-20 - 19)
動(dòng)態(tài)優(yōu)先級(jí) (prio) 保存進(jìn)程的動(dòng)態(tài)優(yōu)先級(jí),通常也是調(diào)度類(lèi)使用的優(yōu)先級(jí),某些情況下在內(nèi)核中會(huì)臨時(shí)調(diào)整該優(yōu)先級(jí),比如實(shí)時(shí)互斥量。
時(shí)間片?(time slice) 表示進(jìn)程被調(diào)度進(jìn)來(lái)和被調(diào)度出去所能持續(xù)的時(shí)間長(zhǎng)度;
進(jìn)程內(nèi)核結(jié)構(gòu)?進(jìn)程在內(nèi)核中數(shù)據(jù)結(jié)構(gòu) PCB(Process Control Block) 為 task_struct 結(jié)構(gòu)。
進(jìn)程運(yùn)行狀態(tài)
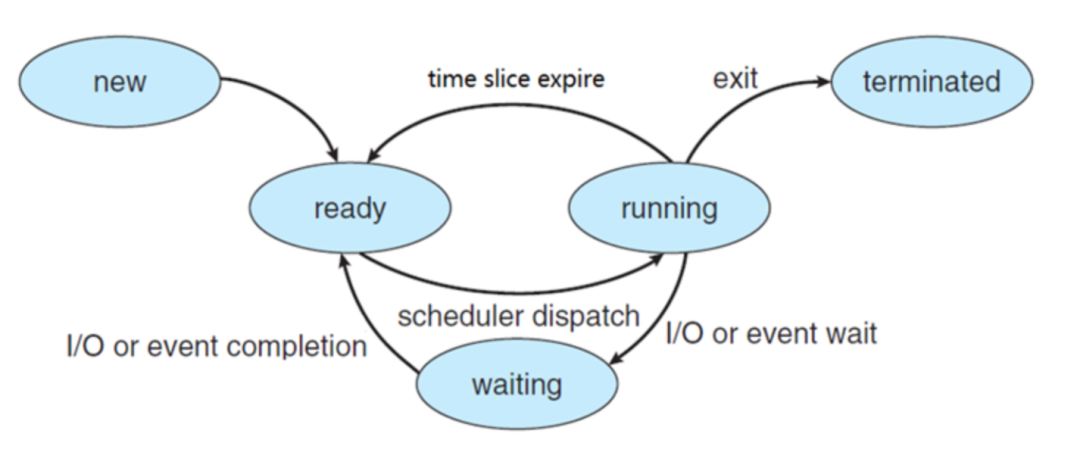
進(jìn)程上下文切換?進(jìn)程的上下文切換不僅包含了虛擬內(nèi)存、棧、全局變量等用戶空間的資源,還包括了內(nèi)核堆棧、寄存器等內(nèi)核空間的資源。
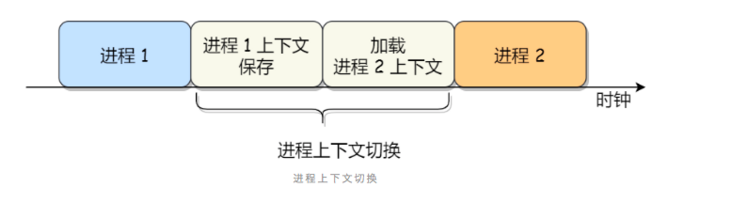
參見(jiàn)?操作系統(tǒng)進(jìn)程知識(shí)總結(jié)
2. Linux 調(diào)度器
2.1 調(diào)度器
調(diào)度器是整個(gè)系統(tǒng)的發(fā)動(dòng)機(jī),負(fù)責(zé)所有就緒進(jìn)程的調(diào)度運(yùn)行,設(shè)計(jì)良好的調(diào)度器需要從以下幾個(gè)方面進(jìn)行考慮:
吞吐量
響應(yīng)時(shí)間
公平性
功耗 (移動(dòng)設(shè)備)
調(diào)度類(lèi)型
主動(dòng)放棄 CPU (由于需要等待或者主動(dòng)進(jìn)入 Sleep)
被動(dòng)放棄 CPU (由于時(shí)間片消耗完或被更高優(yōu)先級(jí)的任務(wù)搶占-如支持搶占)
2.2 Linux 調(diào)度器歷史
O(n) 2.4 內(nèi)核
O(1) 2.6 內(nèi)核
CFS 2.6.23+ (當(dāng)前默認(rèn)調(diào)度器)
2.3 O(n) 調(diào)度算法
調(diào)度數(shù)據(jù)結(jié)構(gòu)
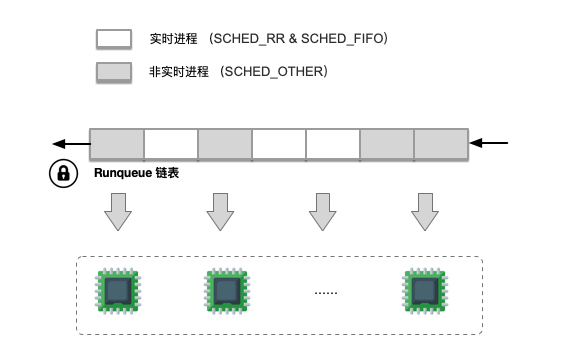
2.3 O(n) 調(diào)度算法
調(diào)度數(shù)據(jù)結(jié)構(gòu)
復(fù)雜度:時(shí)間復(fù)雜度為 O(n), n 代表當(dāng)前就緒狀態(tài)的進(jìn)程數(shù)目。
全局一個(gè)列表隊(duì)列,不區(qū)分實(shí)時(shí)和非實(shí)時(shí)進(jìn)程。CPU 遍歷的時(shí)候都需要加鎖操作,當(dāng)就緒任務(wù)較多時(shí),加鎖周期會(huì)比較長(zhǎng)。
進(jìn)程就緒狀態(tài)加入到 runqueue 隊(duì)列,阻塞或者退出時(shí)候從隊(duì)列移除。
時(shí)間片分配
在運(yùn)行時(shí)動(dòng)態(tài)計(jì)算優(yōu)先級(jí),保證實(shí)時(shí)進(jìn)程的優(yōu)先級(jí)高于非實(shí)時(shí)任務(wù)的動(dòng)態(tài)優(yōu)先級(jí),實(shí)時(shí)進(jìn)程動(dòng)態(tài)優(yōu)先級(jí) (1000 + p->rt_priority); 在計(jì)算動(dòng)態(tài)優(yōu)先級(jí)的時(shí)候會(huì)綜合考慮該任務(wù)的剩余時(shí)間片、歷史執(zhí)行情況等因素。
任務(wù) Nice 越低,剩余時(shí)間片越多,動(dòng)態(tài)優(yōu)先級(jí)越高,越有機(jī)會(huì)獲得運(yùn)行;
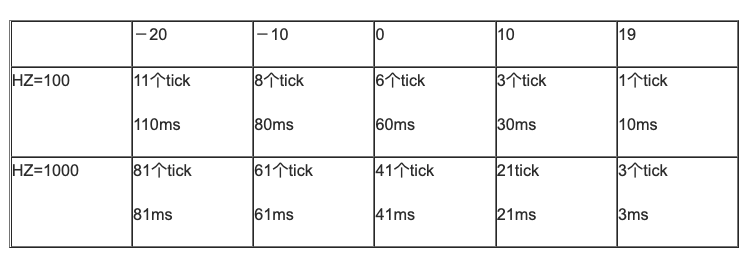
任務(wù)運(yùn)行的最大時(shí)間由動(dòng)態(tài)優(yōu)先級(jí)轉(zhuǎn)變?yōu)楣潭?tick 數(shù)目,tick 的時(shí)間值由系統(tǒng)動(dòng)態(tài)配置的 HZ 時(shí)鐘精度確定。
調(diào)度運(yùn)行
調(diào)度器遍歷整個(gè)就緒隊(duì)列中全部的 n 個(gè)任務(wù),選取?動(dòng)態(tài)優(yōu)先級(jí)?最高的任務(wù)進(jìn)行調(diào)度運(yùn)行。
list_for_each(tmp,?&runqueue_head)?{
??p?=?list_entry(tmp,?struct?task_struct,?run_list);
??if?(can_schedule(p,?this_cpu))?{
???int?weight?=?goodness(p,?this_cpu,?prev->active_mm);
???if?(weight?>?c)
????c?=?weight,?next?=?p;
????}
}
goodness函數(shù)中找出優(yōu)先級(jí)最高的一個(gè)進(jìn)程。
調(diào)度運(yùn)行
tick 中斷:tick 中斷函數(shù)中檢查檢查時(shí)間片是否使用完,使用完畢則進(jìn)行進(jìn)程切換;否則將剩余時(shí)間片的 1/2 追加到動(dòng)態(tài)優(yōu)先級(jí)。
當(dāng)系統(tǒng)無(wú)可運(yùn)行任務(wù)或所有任務(wù)執(zhí)行完時(shí)間片后,調(diào)度器需要將系統(tǒng)中(不是 runqueue 中)所有任務(wù)的重新設(shè)置默認(rèn)時(shí)間片;如果等待隊(duì)列中的進(jìn)程的時(shí)間片仍然有剩余,則會(huì)折半計(jì)入到下一次的時(shí)間片中;
優(yōu)點(diǎn)
實(shí)現(xiàn)邏輯簡(jiǎn)單,在早期運(yùn)行任務(wù)數(shù)量有限的情況下,運(yùn)行良好。
缺點(diǎn)
時(shí)間復(fù)雜度為 O(n),當(dāng)所有調(diào)度任務(wù)完成后,需要對(duì)全部任務(wù)重新初始化,耗時(shí)高;
實(shí)時(shí)進(jìn)程可能不能及時(shí)調(diào)度;
全局只有一個(gè)運(yùn)行隊(duì)列,會(huì)導(dǎo)致 CPU 存在空閑;
SMP 系統(tǒng)中擴(kuò)展問(wèn)題,訪問(wèn)運(yùn)行隊(duì)列需要加鎖,特別是進(jìn)程數(shù)量大時(shí);
進(jìn)程在不同 CPU 上進(jìn)行跳轉(zhuǎn),cache 缺失,性能受到影響;
Linux內(nèi)核中不確定性的 N 可能會(huì)帶來(lái)較大的風(fēng)險(xiǎn)影響。
2.4 O(1) 調(diào)度器
數(shù)據(jù)結(jié)構(gòu)
每個(gè) CPU 一個(gè)優(yōu)先級(jí)隊(duì)列的方式。同時(shí)對(duì)于隊(duì)列設(shè)置一個(gè)按照進(jìn)程優(yōu)先級(jí)的數(shù)組。
分為 active 和 expired 兩個(gè)數(shù)組,分別表示當(dāng)前正常運(yùn)行的隊(duì)列和已經(jīng)過(guò)期的隊(duì)列。
當(dāng) active 隊(duì)列任務(wù)全部完成運(yùn)行后,將 expired 與 active 互換。
為了快速判斷優(yōu)先級(jí)數(shù)組的列表中是否存在任務(wù),使用 bitmap 索引。
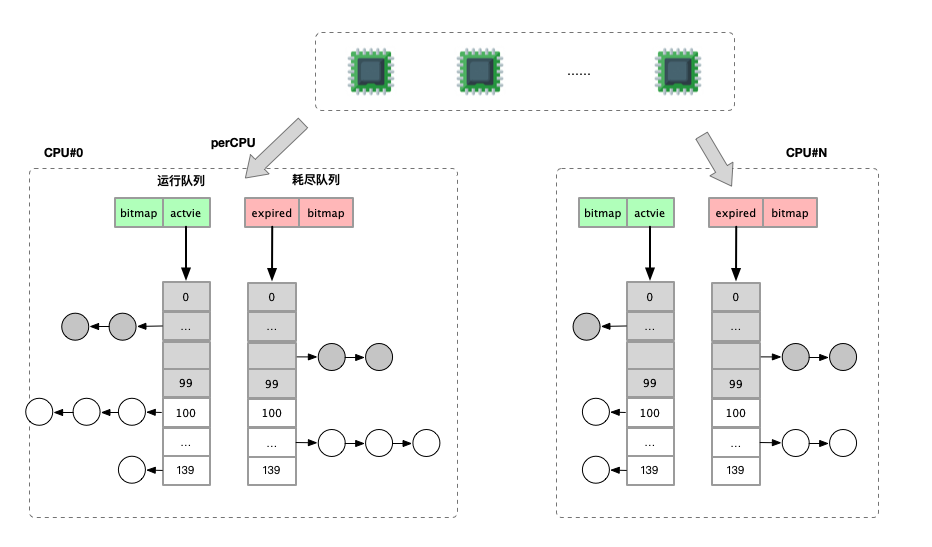
時(shí)間片分配
靜態(tài)優(yōu)先級(jí)為 [ -20 … 0 … 19 ] 的普通進(jìn)程,其缺省時(shí)間片為[800ms … 100ms … 5ms]。
同時(shí)結(jié)合進(jìn)程的實(shí)際運(yùn)行情況,比如在 runqueue 中的等待時(shí)間、睡眠時(shí)間等因素,實(shí)時(shí)調(diào)整動(dòng)態(tài)優(yōu)先級(jí),以期望更好識(shí)別出交互進(jìn)程。
runqueue 中的進(jìn)程優(yōu)先級(jí)為動(dòng)態(tài)優(yōu)先級(jí)。
動(dòng)態(tài)優(yōu)先級(jí)映射為時(shí)間片。
調(diào)度運(yùn)行
schedule 函數(shù)的主要功能是從該 CPU 的 runqueue 找到一個(gè)最合適的進(jìn)程調(diào)度執(zhí)行。其基本的思路就是從 active 優(yōu)先級(jí)隊(duì)列中依次查找,代碼如下:
idx?=?sched_find_first_bit(array->bitmap);
queue?=?array->queue?+?idx;
next?=?lis_entry(queue->next,?task_t,?run_list);當(dāng) active 優(yōu)先級(jí)隊(duì)列中沒(méi)有需要運(yùn)行的任務(wù),則交換 active 與 expired。
不再需要像 O(n) 那樣對(duì)系統(tǒng)中全部任務(wù)重新初始化時(shí)間片。
在 tick 函數(shù)中斷中判斷任務(wù)時(shí)間片是否使用完,如果時(shí)間片使用完畢,正常情況下將任務(wù)從移動(dòng)到 expired 隊(duì)列中,但是如果判斷為交互進(jìn)程,依照交互進(jìn)程指數(shù) TASK_INTERACTIVE ,可能還是會(huì)放入到 actvie 隊(duì)列中;
如果 expired 隊(duì)列中的任務(wù)等待時(shí)間過(guò)長(zhǎng),說(shuō)明調(diào)度其嚴(yán)重不公,這時(shí)候即使判斷出來(lái)時(shí)間片耗盡的進(jìn)程是交互進(jìn)程,仍然會(huì)被放入 expired 隊(duì)列,盡快完成本次調(diào)度;
優(yōu)點(diǎn)
O(1) 調(diào)度器開(kāi)銷(xiāo)比較小,大多數(shù)場(chǎng)景下都有不錯(cuò)的表現(xiàn);
重點(diǎn)關(guān)注交互進(jìn)程,在交互進(jìn)程的響應(yīng)時(shí)間方面得到了很好的改善;
缺點(diǎn)
交互式任務(wù)的判定算法過(guò)于復(fù)雜,參數(shù)硬編碼,代碼可維護(hù)性變差;
靜態(tài)時(shí)間片,任務(wù)增加調(diào)度延時(shí)上升;
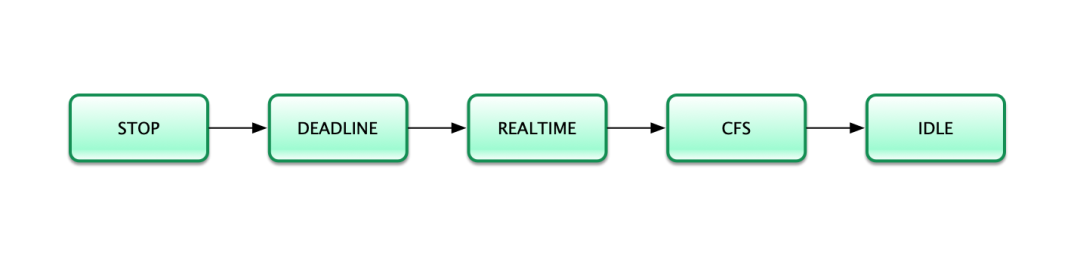
2.5 CFS 調(diào)度器
調(diào)度策略
進(jìn)程調(diào)度依賴于調(diào)度策略,Linux 把相同調(diào)度策略抽象成了調(diào)度類(lèi)(schedule class)。CFS 只負(fù)責(zé)非實(shí)時(shí)進(jìn)程的處理。
優(yōu)先級(jí)按照從高到低的方式進(jìn)行調(diào)度, STOP 最高, IDLE 最低。
進(jìn)程權(quán)重
CFS 調(diào)度器中使用靜態(tài)優(yōu)先級(jí)對(duì)應(yīng)的權(quán)重概念來(lái)對(duì)應(yīng)。權(quán)重的對(duì)應(yīng)關(guān)系 (-20 - 19)。進(jìn)程每降低一個(gè) nice 值,將多獲得 10% CPU 的時(shí)間。
const?int?sched_prio_to_weight[40]?=?{
/*?-20?*/?????88761,?????71755,?????56483,?????46273,?????36291,
/*?-15?*/?????29154,?????23254,?????18705,?????14949,?????11916,
/*?-10?*/??????9548,??????7620,??????6100,??????4904,??????3906,
/*??-5?*/??????3121,??????2501,??????1991,??????1586,??????1277,
/*???0?*/??????1024,???????820,???????655,???????526,???????423,
/*???5?*/???????335,???????272,???????215,???????172,???????137,
/*??10?*/???????110,????????87,????????70,????????56,????????45,
/*??15?*/????????36,????????29,????????23,????????18,????????15,
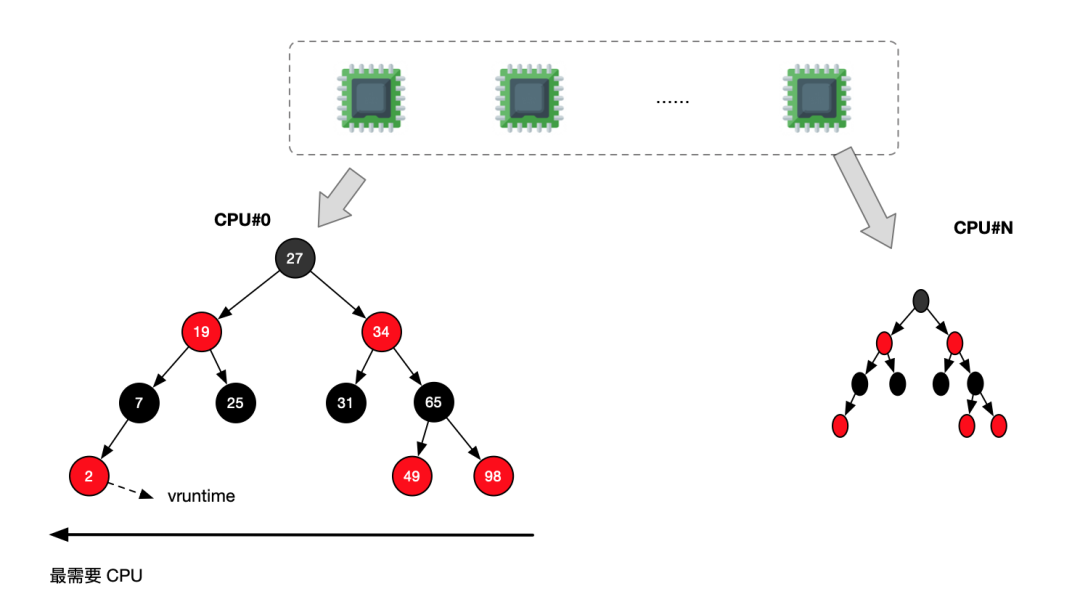
};vruntime(virtual runtime)
表示該進(jìn)程已經(jīng)在 CPU 上運(yùn)行的時(shí)間,值越大被再次調(diào)度概率越低。將不同優(yōu)先級(jí)的進(jìn)程運(yùn)行的時(shí)間作為一個(gè)統(tǒng)一視圖來(lái)進(jìn)程處理。
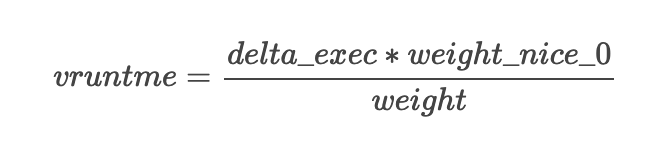
vruntime?虛擬運(yùn)行時(shí)間delta_exec?真實(shí)運(yùn)行時(shí)間nice_0_weight?表示?nice?為 0 的進(jìn)程權(quán)重weight?表示進(jìn)程權(quán)重進(jìn)程的 vruntime 增長(zhǎng)速度取決于其優(yōu)先級(jí)
優(yōu)先級(jí)越低,則 vruntime 增長(zhǎng)越快,因而被再次調(diào)用的可能性就越小
優(yōu)先級(jí)越高,則 vruntime 增長(zhǎng)越慢,因而被再次調(diào)用的可能性就越大
動(dòng)態(tài)時(shí)間片
調(diào)度周期 sched_period,保證一個(gè)調(diào)度周期內(nèi),運(yùn)行隊(duì)列中的所有任務(wù)都會(huì)被調(diào)度一次,最壞情況下,任務(wù)的調(diào)度延時(shí)為一個(gè)調(diào)度周期;
默認(rèn)調(diào)度周期 sched_latency 默認(rèn)為 6 ms;任務(wù)平均時(shí)間片最小值 sched_min_granularity 為 0.75 ms
8 個(gè)以內(nèi)可運(yùn)行時(shí)間設(shè)定為 6ms,否則為 N * sched_min_granularity;
if?sched_latency/nr_running??????sched_period?=?nr_running?*?sched_min_granularity確定好 sched_period 以后,每個(gè)任務(wù)的動(dòng)態(tài)時(shí)間片為:
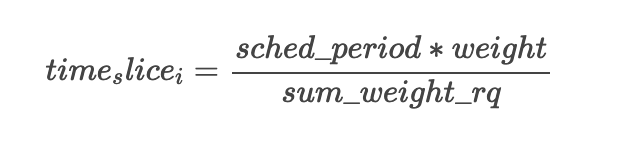
調(diào)度數(shù)據(jù)結(jié)構(gòu)
每個(gè) CPU 對(duì)應(yīng)一個(gè)運(yùn)行隊(duì)列 runqueue,該運(yùn)行隊(duì)列中包含 dl_rq/rt_rq/cfs_rq 等多個(gè)調(diào)度隊(duì)列。CFS 只處理普通進(jìn)程。
使用 vruntime 作為紅黑樹(shù)的索引鍵,使用 sched_entity 作為值。
最小值在最左側(cè),可以 O(1) 進(jìn)行遍歷,插入 O(logN)
調(diào)度運(yùn)行
static?inline?struct?task_struct?*
pick_next_task(struct?rq?*rq,?struct?task_struct?*prev,?struct?rq_flags?*rf)
{
????struct?task_struct?*p;
????if?(likely((prev->sched_class?==?&idle_sched_class?||
????????prev->sched_class?==?&fair_sched_class)?&&
????????rq->nr_running?==?rq->cfs.h_nr_running))?
????{
????????p?=?fair_sched_class.pick_next_task(rq,?prev,?rf);
????}
again:
????for_each_class(class)?{
????????p?=?class->pick_next_task(rq,?prev,?rf);
????}
}pick_next_task_fair
static?struct?task_struct?*
pick_next_task_fair(struct?rq?*rq,?struct?task_struct?*prev,?struct?rq_flags?*rf)
{
????struct?cfs_rq?*cfs_rq?=?&rq->cfs;
????struct?sched_entity?*se;
????struct?task_struct?*p;
????put_prev_task(rq,?prev);??
????do?{
????????se?=?pick_next_entity(cfs_rq,?NULL);
????????set_next_entity(cfs_rq,?se);
????????cfs_rq?=?group_cfs_rq(se);
????}?while?(cfs_rq);
????p?=?task_of(se);
????return?p;
}pick_next_entity 從紅黑樹(shù)上讀取調(diào)度實(shí)體
static?struct?sched_entity?*
pick_next_entity(struct?cfs_rq?*cfs_rq,?struct?sched_entity?*curr)
{
????struct?sched_entity?*left?=?__pick_first_entity(cfs_rq);
????struct?sched_entity?*se;
????se?=?left;?/*?ideally?we?run?the?leftmost?entity?*/
????//?..?搶占/喚醒或者其他判斷
????return?se;
}調(diào)度函數(shù)在各自 CPU 上執(zhí)行,依次運(yùn)行 dl_rq/rt_rq/cfs_rq 隊(duì)列。
運(yùn)行 cfs_rq 隊(duì)列時(shí):
每次調(diào)度程序都選擇紅黑樹(shù)最左側(cè)的節(jié)點(diǎn)運(yùn)行(其 virtual runtime 最小),將其從紅黑樹(shù)中刪除,并調(diào)整紅黑樹(shù)
每隔一段時(shí)間,就更新正在運(yùn)行的進(jìn)程的 vruntime,并將更新后的值與當(dāng)前紅黑樹(shù)中最左側(cè)節(jié)點(diǎn)的 vruntime 相比較
如果小于最左側(cè)節(jié)點(diǎn)的 virtual runtime,則繼續(xù)執(zhí)行當(dāng)前進(jìn)程
如果大于最左側(cè)節(jié)點(diǎn)的 virtual runtime,則搶占式地運(yùn)行最左側(cè)的節(jié)點(diǎn),并將當(dāng)前正在運(yùn)行的進(jìn)程重新放到紅黑樹(shù)中
而且在每一個(gè)調(diào)度周期內(nèi)調(diào)度器會(huì)不斷檢查公平性是否得到了滿足,通過(guò)修訂 vruntme 的值來(lái)進(jìn)行平衡,比如新加入的進(jìn)程和被喚醒的進(jìn)程會(huì)在 vruntme 上進(jìn)行補(bǔ)償。
新進(jìn)程加入及睡眠進(jìn)程喚醒
static?void?place_entity(struct?cfs_rq?*cfs_rq,?struct?sched_entity?*se,?int?initial)
{
? u64?vruntime?=?cfs_rq->min_vruntime;
? if?(initial?&&?sched_feat(START_DEBIT))?//?如果是初始化
?? vruntime?+=?sched_vslice(cfs_rq,?se);?//?計(jì)算新進(jìn)程的?vruntime?添加到?min_vruntime,防止過(guò)度占用
? if?(!initial)?{
?? unsigned?long?thresh?=?sysctl_sched_latency;?//?一個(gè)調(diào)度周期延時(shí)
?? if?(sched_feat(GENTLE_FAIR_SLEEPERS))?
??? thresh?>>=?1;??//?折半處理,防止過(guò)度占用
?? vruntime?-=?thresh;??//?減掉?thresh,讓進(jìn)程獲得盡快調(diào)度
? }
? /*?ensure?we?never?gain?time?by?being?placed?backwards.?*/
? se->vruntime?=?max_vruntime(se->vruntime,?vruntime);
}優(yōu)點(diǎn)
基于優(yōu)先級(jí),兼顧運(yùn)行公平性,默認(rèn)調(diào)度器,經(jīng)受住了時(shí)間的考驗(yàn);
缺點(diǎn)
在 Android 等嵌入式設(shè)備上,仍然需要調(diào)整和優(yōu)化;
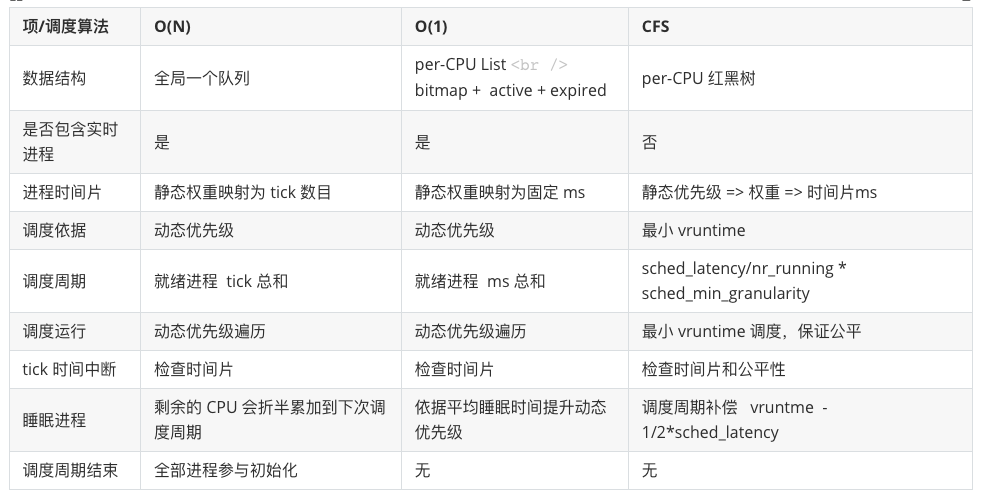
2.6 調(diào)度器綜合對(duì)比
2.7 未來(lái)調(diào)度器
ARM 體系存在 big.LITTLE 模型,存在大小核數(shù)的結(jié)構(gòu)。
HMP 調(diào)度器
EAS 綠色節(jié)省調(diào)度器 (HMP 的優(yōu)化版)
NUMA 調(diào)度器
3. 高階話題
3.1 搶占
觸發(fā)搶占:?給正在CPU上運(yùn)行的當(dāng)前進(jìn)程設(shè)置一個(gè)請(qǐng)求重新調(diào)度的標(biāo)志(TIF_NEED_RESCHED),僅此而已,此時(shí)進(jìn)程并沒(méi)有切換。
觸發(fā)時(shí)機(jī):
周期性的時(shí)鐘中斷:scheduler_tick() 時(shí)間片耗盡
進(jìn)程喚醒:當(dāng)進(jìn)程被喚醒的時(shí)候,優(yōu)先級(jí)高于CPU當(dāng)前進(jìn)程
新進(jìn)程創(chuàng)建
進(jìn)程修改 nice 值
負(fù)載均衡
執(zhí)行搶占:在隨后的某個(gè)時(shí)刻,內(nèi)核會(huì)檢查T(mén)IF_NEED_RESCHED標(biāo)志并調(diào)用 __schedule()執(zhí)行搶占。
搶占如果發(fā)生在進(jìn)程處于用戶態(tài)的時(shí)候,稱為 User Preemption(用戶態(tài)搶占);如果發(fā)生在進(jìn)程處于內(nèi)核態(tài)的時(shí)候,則稱為Kernel Preemption(內(nèi)核態(tài)搶占)。
從系統(tǒng)調(diào)用(syscall)返回用戶態(tài)時(shí)
中斷處理程序返回內(nèi)核空間之前會(huì)檢查T(mén)IF_NEED_RESCHED標(biāo)志,如果置位則調(diào)用preempt_schedule_irq()執(zhí)行搶占。preempt_schedule_irq()是對(duì)schedule()的包裝。
搶占只在某些特定的時(shí)機(jī)發(fā)生,這是內(nèi)核的代碼決定的。
3.2 CPU 負(fù)載計(jì)算方式 PLET
為了讓調(diào)度器更加高效,需要針對(duì)每個(gè)調(diào)度隊(duì)列和每個(gè)調(diào)度實(shí)體的負(fù)載進(jìn)行衡量。?(Per Entity Load Tracking)
時(shí)間(物理時(shí)間,不是虛擬時(shí)間)被分成了 1024us 的序列,在每一個(gè)周期中,一個(gè) Entity 對(duì)系統(tǒng)負(fù)載的貢獻(xiàn)可以根據(jù)該實(shí)體處于 Runnable 狀態(tài)(正在 CPU 上運(yùn)行或者等待 CPU 調(diào)度運(yùn)行)的時(shí)間進(jìn)行計(jì)算。如果在該周期內(nèi),Runnable的時(shí)間是 x,那么對(duì)系統(tǒng)負(fù)載的貢獻(xiàn)就是(x/1024)。
負(fù)載需要考慮歷史周期的影響 y^32 = 0.5, y = 0.97857206
L?=?L0?+?L1?*?y?+?L2?*?y^2?+?L3?*?y^3?+?...?+?Ln?*?y^n當(dāng)前對(duì)于負(fù)載的計(jì)算 上個(gè)周期的負(fù)載貢獻(xiàn)值乘以衰減系數(shù),加上當(dāng)前時(shí)間點(diǎn)的負(fù)載即可。
經(jīng)過(guò) 32 個(gè)周期,負(fù)載降低為 0.5 倍, 經(jīng)過(guò) 2016 個(gè)周期,全部負(fù)載衰減為 0
更新時(shí)機(jī):就緒隊(duì)列添加任務(wù)、刪除任務(wù)和周期性更新
就緒隊(duì)列的 load_avg(包含睡眠進(jìn)程的貢獻(xiàn)) 與 runnable_load_avg(只統(tǒng)計(jì)可運(yùn)行任務(wù)的負(fù)載) 。
3.3 負(fù)載均衡 SMP 和 NUMA
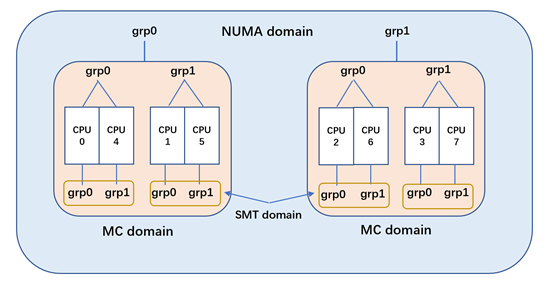
負(fù)載均衡遷移基于 runnable_load_avg 的值。
負(fù)載均衡流程:
判斷當(dāng)前 CPU 是否需要負(fù)載均衡
負(fù)載均衡以當(dāng)前 CPU 開(kāi)始,由下至上調(diào)度域,從最底層的調(diào)度域開(kāi)始做負(fù)載均衡
在調(diào)度域中查找最繁忙的調(diào)度組,更新調(diào)度域和調(diào)度組的相信統(tǒng)計(jì)信息,計(jì)算出該調(diào)度域的不均衡負(fù)載值;
在最繁忙的調(diào)度組中找出最繁忙的 CPU,然后把繁忙的 CPU 中的任務(wù)遷移到當(dāng)前的 CPU,遷移負(fù)載量為不均衡負(fù)載值。
NUMA 類(lèi)似,更是更加復(fù)雜,需要處理跨 NUMA 內(nèi)存和進(jìn)程遷移。
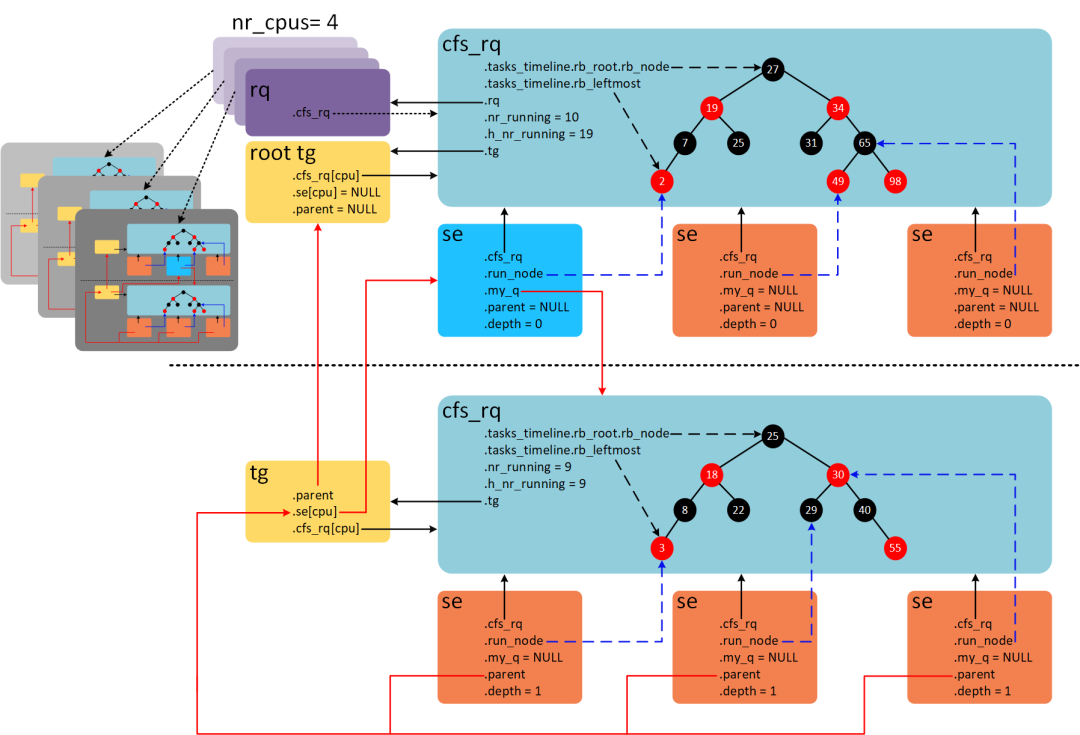
3.4 調(diào)度任務(wù)組
原文鏈接:https://www.ebpf.top/post/linux_process_mgr/