
讀書筆記 之《軟件架構(gòu)設(shè)計(jì): 大型網(wǎng)站技術(shù)架構(gòu)與業(yè)務(wù)架構(gòu)融合之道》
大家好呀,我是小菜~
帥哥美女,知道你們時(shí)間寶貴,那么就由小菜為你讀好一本書,讀一本好書,取其精華,與你共享~!
本文主要分享
《軟件架構(gòu)設(shè)計(jì):大型網(wǎng)站技術(shù)架構(gòu)與業(yè)務(wù)架構(gòu)融合之道》如有需要,可以參考
如有幫助,不忘 點(diǎn)贊 ?
微信公眾號已開啟,菜農(nóng)曰,沒關(guān)注的同學(xué)們記得關(guān)注哦!
今天帶來的是 《軟件架構(gòu)設(shè)計(jì):大型網(wǎng)站技術(shù)架構(gòu)與業(yè)務(wù)架構(gòu)融合之道》 的讀書筆記
(文中使用到的例子貼圖均出于原書)
在正式進(jìn)入分享之前,我們想看下這本樹的目錄架構(gòu)
軟件架構(gòu)設(shè)計(jì):大型網(wǎng)站技術(shù)架構(gòu)與業(yè)務(wù)架構(gòu)融合之道

這本書總共分為 五個(gè)部分,共計(jì) 17 章 ,總體來說內(nèi)容還是挺多的。內(nèi)容相對全面,但并沒有面面俱到,還是比較推薦閱讀的一本書,話不多說,進(jìn)入正文!
第一部分:什么是架構(gòu)

第一部分由兩個(gè)章節(jié)組成,簡單的介紹了下什么是架構(gòu)
第一章:五花八門的架構(gòu)師職業(yè)
1.1 架構(gòu)師職業(yè)分類
現(xiàn)在隨便找一個(gè)招聘網(wǎng)站或獵頭發(fā)布的招聘廣告,我們都能看到各式各樣的架構(gòu)師頭銜,比如有:Java 架構(gòu)師,前端架構(gòu)師,后端架構(gòu)師,數(shù)據(jù)架構(gòu)師,中間件架構(gòu)師... 等等,而且年限的要求也各不一,3~5年,8~10年。
但是從這些崗位的需求我們可以看出,“架構(gòu)師”中的架構(gòu)是一個(gè)很虛的詞,不同領(lǐng)域和行業(yè)對員工要求的能力和工作經(jīng)驗(yàn)差異很大。
現(xiàn)在問起很多開發(fā)者的發(fā)展路線都不約而同的是要成為一名架構(gòu)師,那么對架構(gòu)師的定義是怎么樣的?架構(gòu)師在項(xiàng)目體系和團(tuán)隊(duì)結(jié)構(gòu)中應(yīng)當(dāng)著一個(gè)怎么樣的角色?如何成為一名架構(gòu)師?這些你是否都有一個(gè)明確的答案,是否也為之目標(biāo)而努力前行著!
1.2 架構(gòu)的分類
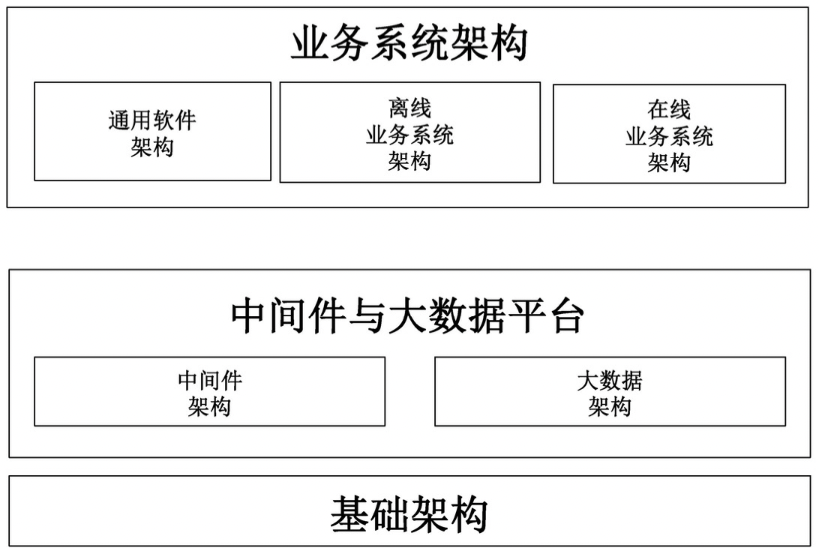
單純以技術(shù)的角度來看,軟件系統(tǒng)自底向上可以分為三層
第一層:基礎(chǔ)架構(gòu)
基礎(chǔ)架構(gòu)是指云平臺、操作系統(tǒng)、網(wǎng)絡(luò)、存儲這些構(gòu)成,一些中小公司大多會選擇使用大公司研發(fā)的云計(jì)算平臺,研發(fā)成本低,穩(wěn)定有保障
第二層:中間件與大數(shù)據(jù)層
中間件屬于公司中必有的,類似消息中間件,數(shù)據(jù)庫中間件,緩存中間件,而大數(shù)據(jù)層對于中小公司來說比較少有沉淀,類似開源的 Hadoop 生態(tài)體系,Hive、Spark、Storm、Fink等
第三層:業(yè)務(wù)系統(tǒng)架構(gòu)
對于第三層的劃分并不是絕對,圖中體現(xiàn)了三種架構(gòu)類型:通用軟件架構(gòu)、離線業(yè)務(wù)系統(tǒng)架構(gòu)、在線業(yè)務(wù)系統(tǒng)架構(gòu),但由于現(xiàn)實(shí)中軟件的種類過多,比如還存在嵌入式系統(tǒng)。這里簡單描述下圖中第三種具備的類種:
通用軟件架構(gòu):常用的辦公軟件、瀏覽器、播放器等 離線業(yè)務(wù)系統(tǒng): 基于大數(shù)據(jù)的 BI(商業(yè)智能) 分析、數(shù)據(jù)挖掘、報(bào)表與可視化等 在線業(yè)務(wù)系統(tǒng)架構(gòu): 搜索、推薦、即時(shí)通信、電商、游戲、廣告、企業(yè)ERP或CRM等
第二章:架構(gòu)的道與術(shù)
2.1 何為道,何為術(shù)
不禁感嘆這年頭聊架構(gòu),這可以上道與術(shù)的層面了。

這張圖是大多數(shù)項(xiàng)目的基本架構(gòu)圖,可以將每層映射到你們的項(xiàng)目中,是不是不會覺得很陌生。
那么實(shí)際中這張圖能夠反映出架構(gòu)抉擇嗎,架構(gòu)師的任務(wù)是否就是簡單的劃分層級結(jié)構(gòu),然后就可以埋頭進(jìn)行開發(fā)了?
我們依賴這張圖將問題進(jìn)行擴(kuò)展:
如何拆分微服務(wù)? 如何組織服務(wù)與服務(wù)之間的層級關(guān)系? 如何設(shè)計(jì)接口? 如何保證高可用?如何分庫分表?如何保證數(shù)據(jù)一致性?...
想要表達(dá)的問題實(shí)在是太多了,由此可見架構(gòu)師的任務(wù)并不簡單。
2.2 道與術(shù)的辯證關(guān)系
問題那么復(fù)雜,我們就以道與術(shù)來理解。假如你要成為一名武林高手,那么花里胡哨的招式對于某些人來說很重要,因?yàn)橐非蠛每矗^的花架子,而招式我們便可理解為術(shù),那么追求高手的層面,我們是否要修煉內(nèi)功心法,底子扎實(shí),才能成為頂級高手。
那么道重要還是術(shù)重要,這是個(gè)公說公有理婆說婆有理的問題,段譽(yù)的內(nèi)功厲害,但使不出招式可能也有些徒然,招式好看,卻沒有內(nèi)功支撐,也只能成為花架子的笑談,而道術(shù)兼?zhèn)洌侥茼敿墶?/p>
第二部分:計(jì)算機(jī)功底

這部分的內(nèi)容頗多,重在道的修煉
第三章:語言
語言是在是太多了,忍不住吐槽~ 盡管語言如此之多,市面上還是不斷地推陳出新,我們面對語言的不斷迭代要追求潮流還是巋然不動?在我看來,我們要追求道,底層掌握結(jié)實(shí),管它日轉(zhuǎn)星移,我亦坦然相對。
語言再多再繁雜,都具備共同的典型特性,無外乎一些語法糖使用熟練與否
第四章:操作系統(tǒng)
I/O是繞不過去的一個(gè)基本問題。從文件I/O到網(wǎng)絡(luò)I/O,存在著各式各樣的概念和I/O模型
4.1 緩存I/O 和 直接I/O
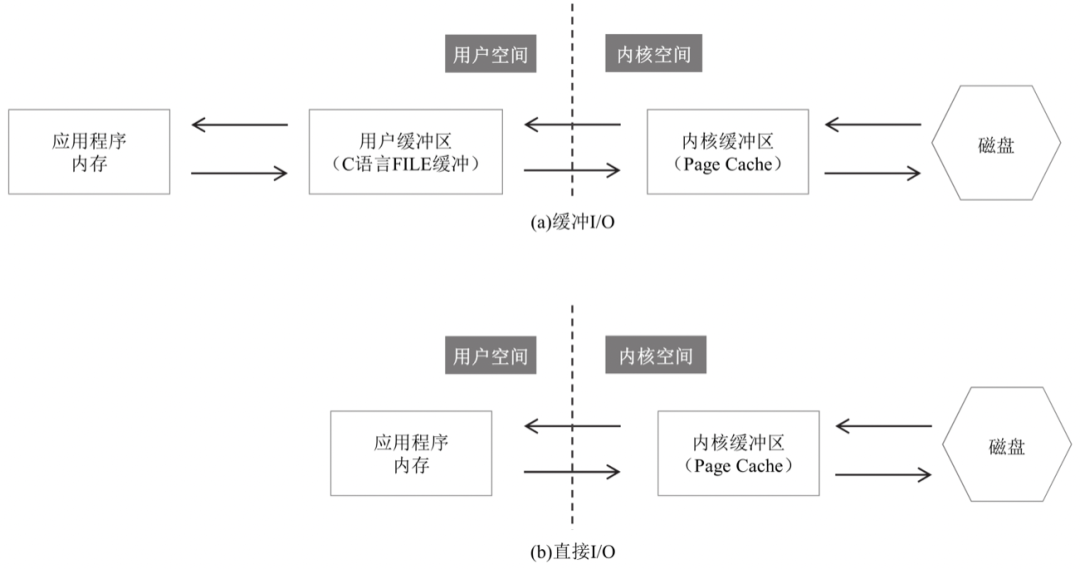
在了解兩個(gè)原理之前,我們先清楚幾個(gè)概念:
應(yīng)用程序內(nèi)存: 通常寫代碼用 malloc/free、new/delete 等分配出來的內(nèi)存 用戶緩沖區(qū): 位于用戶空間中緩沖區(qū),如 C語言FILE 結(jié)構(gòu)體里面的 Buffer 內(nèi)核緩沖區(qū): Linux 操作系統(tǒng)的 Page Cache。一個(gè) Page 的大小一般為 4K
以上三個(gè)概念了解后,我們繼續(xù)看 I/O 操作
緩沖I/O
讀:磁盤 -> 內(nèi)核緩沖區(qū) -> 用戶緩沖區(qū) -> 應(yīng)用程序
寫: 應(yīng)用程序 -> 用戶緩沖區(qū) -> 內(nèi)核緩沖區(qū) -> 磁盤
對于緩沖I/O,一個(gè)讀操作會有3次數(shù)據(jù)拷貝,一個(gè)寫操作會有反向的3次數(shù)據(jù)拷貝
直接I/O
讀: 磁盤 -> 內(nèi)核緩沖區(qū) -> 應(yīng)用程序
寫: 應(yīng)用程序 -> 內(nèi)核緩沖區(qū) -> 磁盤
對于直接I/O,一個(gè)讀操作會有3次數(shù)據(jù)拷貝,一個(gè)寫操作會有返現(xiàn)的2次數(shù)據(jù)拷貝
總結(jié):直接I/O 并不是沒有緩沖,而是沒有用戶級的緩沖,對于操作系統(tǒng)本身的緩沖還是有的
4.2 內(nèi)存映射文件與零拷貝
1)內(nèi)存映射文件
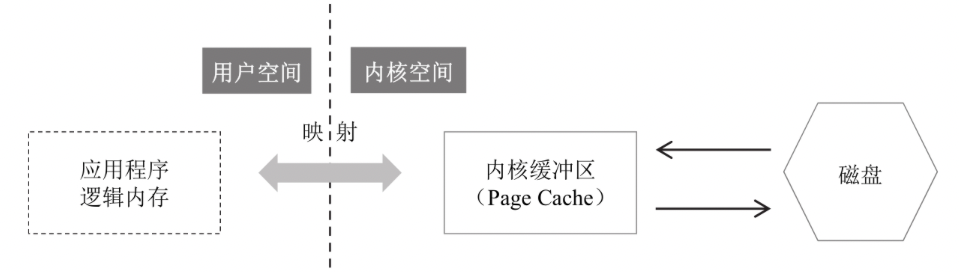
從緩沖I/O到直接I/O,讀寫操作從3次的數(shù)據(jù)拷貝縮減到2次數(shù)據(jù)拷貝。而到了內(nèi)存映射文件,讀寫操作再次縮減到了1次數(shù)據(jù)拷貝,也就是:
讀:磁盤 -> 內(nèi)核緩沖區(qū) 寫: 內(nèi)核緩沖區(qū) -> 磁盤
應(yīng)用程序雖然讀寫的是自己的內(nèi)存,但這個(gè)內(nèi)存只是一個(gè) "邏輯地址",實(shí)際讀寫的是 內(nèi)核緩沖區(qū)
2)零拷貝
零拷貝(Zero Copy)又是提升 I/O 效率的一大利器,在平時(shí)有問到 Kafka 是如何做到讀寫那么快的時(shí)候,其中一個(gè)很大的原因便是 Kafka 用到了零拷貝技術(shù)。
這是一個(gè)利用直接I/O進(jìn)行收發(fā)文件的過程
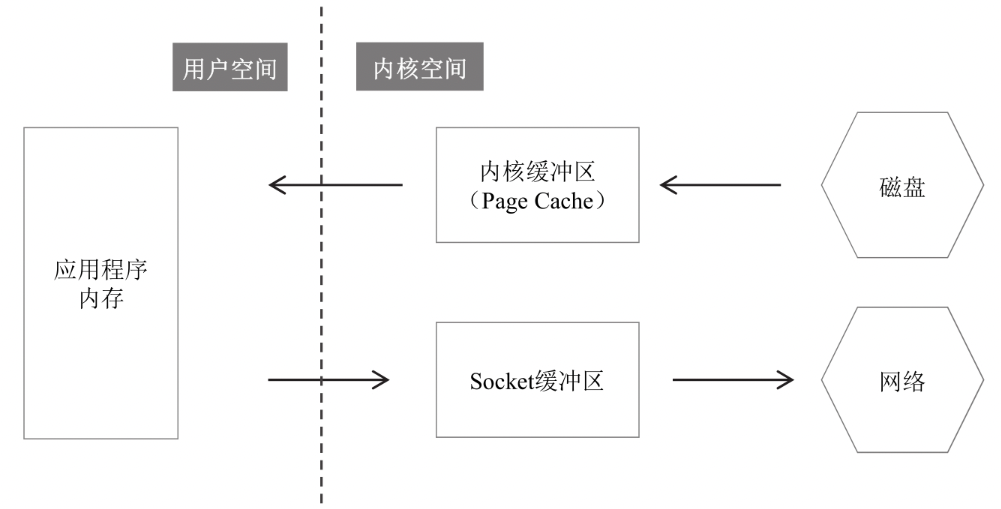
這是一個(gè)利用內(nèi)存映射文件進(jìn)行收發(fā)文件的過程
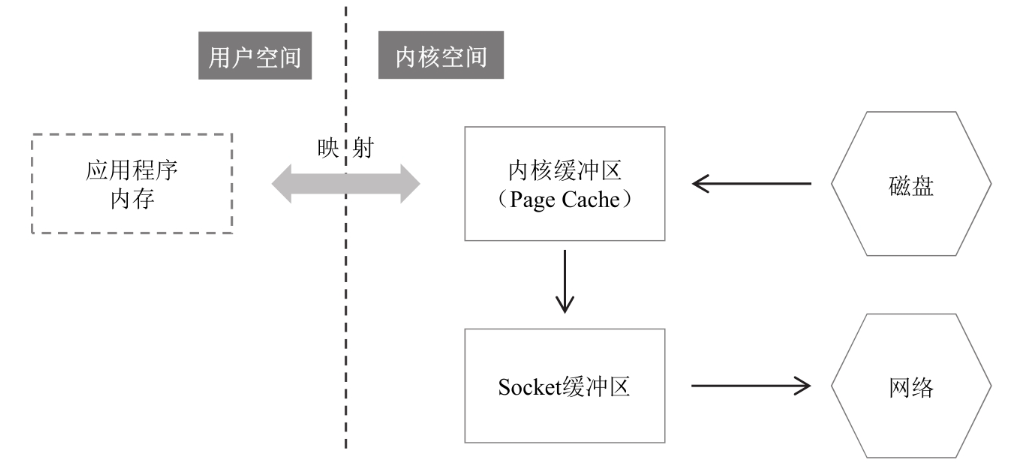
整個(gè)過程從4次的數(shù)據(jù)拷貝降低到了3次,不再經(jīng)過應(yīng)用程序內(nèi)存,直接在內(nèi)核空間中從內(nèi)核緩沖區(qū)拷貝到 Socket 緩沖區(qū)
這是一個(gè)利用零拷貝進(jìn)行收發(fā)文件的過程
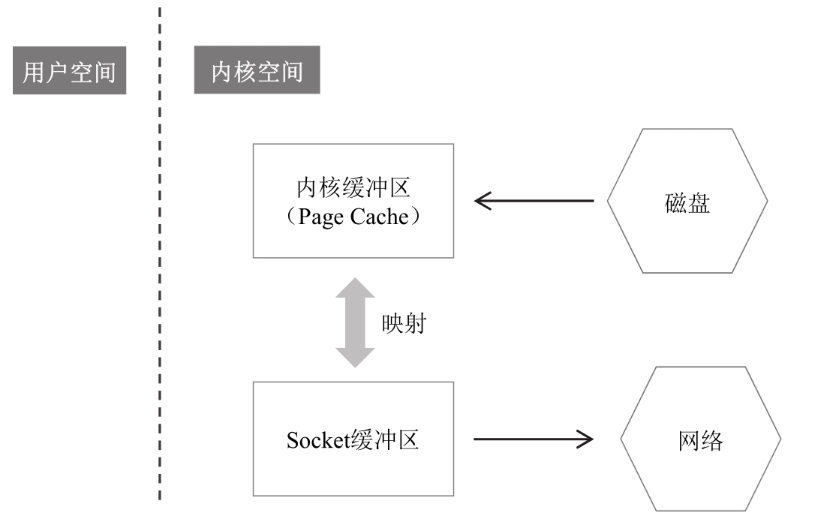
利用零拷貝的話,連內(nèi)存緩沖區(qū)到Socket緩沖區(qū)的數(shù)據(jù)拷貝步驟都可以省略。在內(nèi)核緩沖區(qū)和 Socket 緩沖區(qū)之間并沒有做數(shù)據(jù)拷貝,只是一個(gè)地址的映射,底層的網(wǎng)卡驅(qū)動程序要讀取數(shù)據(jù)并發(fā)送到網(wǎng)絡(luò)的時(shí)候,看似讀的是Socket緩沖區(qū)中的數(shù)據(jù),實(shí)際上讀得是內(nèi)核緩沖區(qū)的數(shù)據(jù)。
總結(jié):為什么稱之為零拷貝呢,因?yàn)閺膬?nèi)存的角度上看,數(shù)據(jù)在內(nèi)存中沒有發(fā)生數(shù)據(jù)拷貝,只在內(nèi)存與I/O之間傳輸。利用的還是 內(nèi)核緩沖區(qū) 與 Socket緩沖區(qū)之間的映射,數(shù)據(jù)本身只有一份
4.3 網(wǎng)絡(luò) I/O 模型
網(wǎng)絡(luò) I/O 模型也是一個(gè)極易混淆的概念,至今為止我們聽過幾種網(wǎng)絡(luò)I/O模型呢
網(wǎng)絡(luò)阻塞 I/O 網(wǎng)絡(luò)非阻塞 I/O I/O 多路復(fù)用 異步 I/O
很多時(shí)候我們?nèi)菀谆煜母拍钍?非阻塞 和 異步
1)網(wǎng)絡(luò)模型
1. 網(wǎng)絡(luò)阻塞 I/O
這種模型很好理解,就是調(diào)用的時(shí)候會被阻塞,直到數(shù)據(jù)讀取完成或?qū)懭氤晒?/p>
2. 網(wǎng)絡(luò)非阻塞 I/O
和上述相反,但沒有數(shù)據(jù)的時(shí)候會立即返回,不會阻塞,然后通過輪詢的方式不斷查詢直到獲取到數(shù)據(jù)
如果只有幾十乃至上百個(gè)連接的時(shí)候,上面兩種 I/O 模型處理的方式問題都不大,當(dāng)連接數(shù)達(dá)到幾十萬乃至上百萬時(shí),那問題就很嚴(yán)重了
3. I/O 多路復(fù)用
該方式也是阻塞調(diào)用,一次性將所有的連接請求傳進(jìn)來,當(dāng)某個(gè)連接請求具備條件后,會立即將結(jié)果放回,告知應(yīng)用程序有哪些連接可讀或可寫。常用的 I/O 多路復(fù)用的方法有:select、poll、epoll、Java的NIO,其中 epoll 的效率最高,也是目前最主流的。
epoll
整個(gè) epoll 分為三個(gè)步驟
事件注冊 輪詢查詢是否就緒 事件就緒后進(jìn)行讀寫
其中又可分為兩種模式:LT(水平觸發(fā)/條件觸發(fā)) 和 ET(邊緣觸發(fā)/狀態(tài)觸發(fā))
LT 水平觸發(fā):只要讀緩沖區(qū)不空就會一直觸發(fā)讀事件;寫緩沖區(qū)不滿,就會一直觸發(fā)寫事件 ET 邊緣觸發(fā):讀緩沖區(qū)的狀態(tài)從空轉(zhuǎn)為非空的時(shí)候觸發(fā)一次;寫緩沖區(qū)的狀態(tài)從滿轉(zhuǎn)為非滿的時(shí)候觸發(fā)一次
總結(jié):實(shí)際的開發(fā)中,大家一般傾向于 LT(默認(rèn)模式)。但使用的時(shí)候需要避免 "寫死循環(huán)"的問題,因?yàn)閷懢彌_區(qū)為滿的概率很小,會一直觸發(fā)寫事件
4. 異步 I/O
異步 I/O 是指所有的讀寫操作都由操作系統(tǒng)完成,當(dāng)處理結(jié)束后,將結(jié)果通過指定的回調(diào)函數(shù)或其他機(jī)制告知應(yīng)用程序
總結(jié): 阻塞和非阻塞是從函數(shù)調(diào)用的角度來說,而同步和非同步是從 "讀寫是由誰來完成" 的角度來說
2)設(shè)計(jì)模式
除了上面幾種網(wǎng)絡(luò)I/O模型,我們還經(jīng)常聽到 Reactor 模式與 Proactor 模型,這兩種并不是網(wǎng)絡(luò)I/O模型。而是網(wǎng)絡(luò)框架中的兩種設(shè)計(jì)模式,無論操作系統(tǒng)的網(wǎng)絡(luò) I/O 模型的設(shè)計(jì),還是上層網(wǎng)絡(luò)框架的網(wǎng)絡(luò) I/O 模型的設(shè)計(jì),用的都是這兩中設(shè)計(jì)模型之一
1. Reactor 模式
這是一種主動模式。應(yīng)用程序會不斷地輪詢,詢問操作系統(tǒng)或網(wǎng)絡(luò)框架、I/O 是否就緒。select、poll、epoll、Java中的NIO 就屬于這種主動模式。
2. Proactor 模式
這是一種被動模式。應(yīng)用程序會將所有的讀寫操作都交給操作系統(tǒng)完成,完成后再將結(jié)果通過一定的通知機(jī)制告知應(yīng)用程序
4.4 進(jìn)程、線程和協(xié)程
不同語言有不同的使用習(xí)慣。如 Java 一般是寫 單進(jìn)程多線程 ,C++ 一般是 單進(jìn)程多線程 或 多進(jìn)程單線程
1)為什么要使用多線程?
提高 CPU 使用率 提高 I/O 吞吐
2)多線程會帶來的問題?
鎖(悲觀鎖、樂觀鎖、互斥鎖、讀寫鎖、自旋鎖、公平/非公平鎖等) Wait 與 Signal 操作 Condition
3)為什么需要多進(jìn)程?
線程間鎖的存在,會導(dǎo)致并發(fā)效率下降,同時(shí)增加編碼難度 線程上下文切換需要時(shí)間,過多的切換會導(dǎo)致效率低下 多進(jìn)程相互獨(dú)立,其中一個(gè)崩潰后,其他進(jìn)程可以繼續(xù)運(yùn)行,提高可靠性
不要通過共享內(nèi)存來實(shí)現(xiàn)通信,而應(yīng)通過通信實(shí)現(xiàn)共享內(nèi)存
通俗理解:盡可能通過消息通信, 而不是共享內(nèi)存來實(shí)現(xiàn)進(jìn)程或線程之間的同步
4)為什么需要協(xié)程?
更好地利用CPU,協(xié)程可以由應(yīng)用程序自己調(diào)度,而線程不行 更好地利用內(nèi)存,協(xié)程的堆棧大小不是固定的,用多少申請多少
4.5 無鎖(內(nèi)存屏障與CAS)
1)內(nèi)存屏障
讀可以多線程、寫必須單線程,如果多線程寫,則做不到無鎖
基于內(nèi)存屏障(防止代碼重排序),有了Java中的volatile關(guān)鍵字,再加上單線程寫的原則,就有了Java中的無鎖并發(fā)框架
2)CAS
如果是多線程寫,內(nèi)存屏障并不適用,這是就需要用到 CAS。CAS是在CPU層面提供的一個(gè)硬件原子指令,實(shí)現(xiàn)對同一個(gè)值的Compare和Set 兩個(gè)操作的原子化。
第五章:網(wǎng)絡(luò)
網(wǎng)絡(luò)的具體認(rèn)知可以空降:掌握《網(wǎng)絡(luò)》,見微才能知著
第六章:數(shù)據(jù)庫
6.1 范式與反范式
第一范式:每個(gè)字段都是原子的,不能再分解。(反例:某個(gè)字段是 JSON 串,或數(shù)組) 第二范式:表必須有主鍵,主鍵可以是單個(gè)屬性或幾個(gè)屬性的組合,非主屬性必須完全依賴,而不能部分依賴(反例:有張好友關(guān)系表,主鍵是 關(guān)注人ID+被關(guān)注人ID,但該表中還存儲了名字、頭像等字段,這些字段只依賴組合主鍵中其中一個(gè)字段(關(guān)注人ID),而不是完全依賴主鍵) 第三范式:沒有傳遞依賴,非主屬性必須直接依賴主鍵,而不能間接依賴主鍵(反例:有張員工表,有個(gè)字段是部門ID,還有其他部門字段,比如部門名稱,部門描述等,這些字段直接依賴部門ID,而不是員工ID,不應(yīng)該在員工表中存在)
看了三大范式不禁有些汗顏,實(shí)際開發(fā)中為了性能或便于開發(fā),違背范式的設(shè)計(jì)比比皆是,但也無可厚非,雖然范式不一定要遵守,但還是需要仔細(xì)權(quán)衡。
6.2 分庫分表
分庫分表使分布式系統(tǒng)設(shè)計(jì)中一個(gè)非常普遍的問題。
1)分庫分表的目的
業(yè)務(wù)拆分。通過業(yè)務(wù)拆分我們可以把一個(gè)大的復(fù)雜系統(tǒng)拆成多個(gè)業(yè)務(wù)子系統(tǒng),系統(tǒng)與系統(tǒng)之間可以通過 RPC 或消息中間件的方式通信。應(yīng)對高并發(fā)。高并發(fā)我們可以具體分為是讀多寫少還是讀少寫多的并發(fā)場景。讀多我們可以利用緩存中間件減少壓力,而寫多我們就需要考慮是否要進(jìn)行分庫分表數(shù)據(jù)隔離。核心業(yè)務(wù)區(qū)分開來,區(qū)別對待,投入的開發(fā)和運(yùn)維成本也可以側(cè)重點(diǎn)偏移
2)拆分維度的選擇
按照 Id 維度拆分:根據(jù) Id % 64 取模拆成 0~63 的64張表 固定位拆分:取 Id 指定二位,例如倒數(shù) 2 ,3位組成 00~99 張表 hash值拆分:將 Id 取 hash 值,然后 % 表數(shù) range 拆分:按照 userId 指定范圍拆分,0 - 1千萬一張表,這種用的比較少,容易產(chǎn)生熱點(diǎn)數(shù)據(jù)問題 業(yè)務(wù)域拆分:把不同業(yè)務(wù)域的表拆分到不同庫中,例如訂單相關(guān)的表,用戶信息相關(guān)的表,營銷相關(guān)的表分開在不同庫 把不常用的字段單獨(dú)拿出來存儲到一張表中
3)面對 JOIN 問題
拆分成多個(gè)單表查詢,在代碼層做邏輯拼裝 做寬表(JOIN 好的表),重寫輕讀 利用搜索引擎,例如 Elasticsearch
6.3 B+樹
B+ 樹具備了哪些查詢特性:
范圍查詢 前綴匹配模糊查詢 排序和分頁
1)邏輯結(jié)構(gòu)
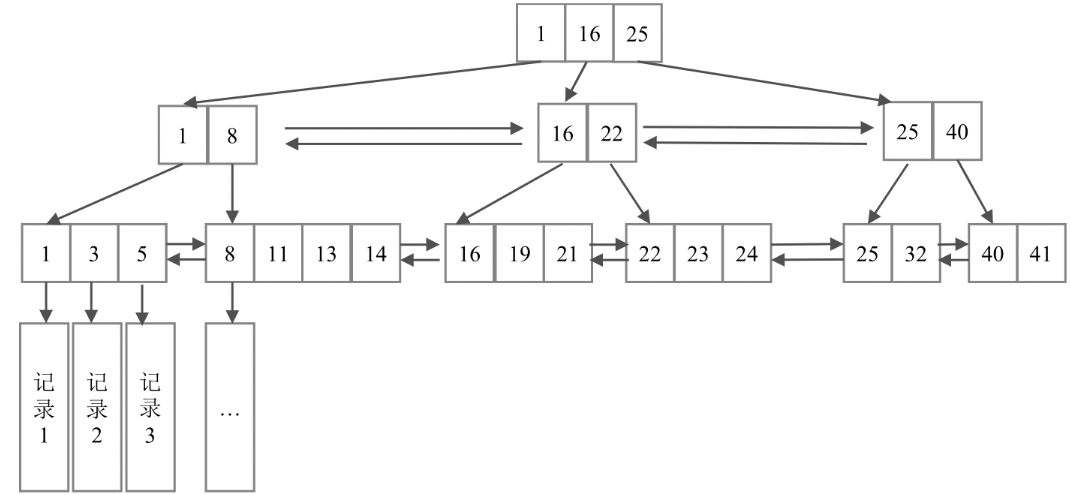
這個(gè)是一個(gè) B+ 樹結(jié)構(gòu),相對來說比較抽象,我們提取下其中的幾個(gè)關(guān)鍵特征:
葉子節(jié)點(diǎn)之間所有記錄的主鍵,并按照 從小到大的順序排列,形成一個(gè)雙向鏈表。葉子節(jié)點(diǎn)的每一個(gè)key都指向一條記錄非葉子節(jié)點(diǎn)取的是葉子節(jié)點(diǎn)里面key的最小值。同層的非葉子節(jié)點(diǎn)也相互串聯(lián),形成一個(gè)雙向鏈表
為什么只支持前綴匹配模糊查詢 - like abc%
前綴匹配模糊查詢可以轉(zhuǎn)換為范圍查詢,例如 abc% 可以轉(zhuǎn)換為 key in [abc, abcz],而如果是全模糊查詢是沒有辦法轉(zhuǎn)換的
2)物理結(jié)構(gòu)
上面描述的樹只是一個(gè)邏輯結(jié)構(gòu),而不是實(shí)際上的物理結(jié)構(gòu),因?yàn)閿?shù)據(jù)最終都是要存儲到磁盤上的。
磁盤都是以 塊 為單位
在 InnoDB 引擎中默認(rèn)的塊大小是 16 KB(可通過 innodb_page_size參數(shù)指定),這里的塊,指的是邏輯單位,而不是磁盤扇區(qū)的物理塊,塊是 InnoDB 讀寫磁盤的基本單位,InnoDB 每次進(jìn)行磁盤I/O讀取的都是 16 KB的整數(shù)倍,無論是葉子節(jié)點(diǎn)還是非葉子節(jié)點(diǎn)都是裝在 Page 里面
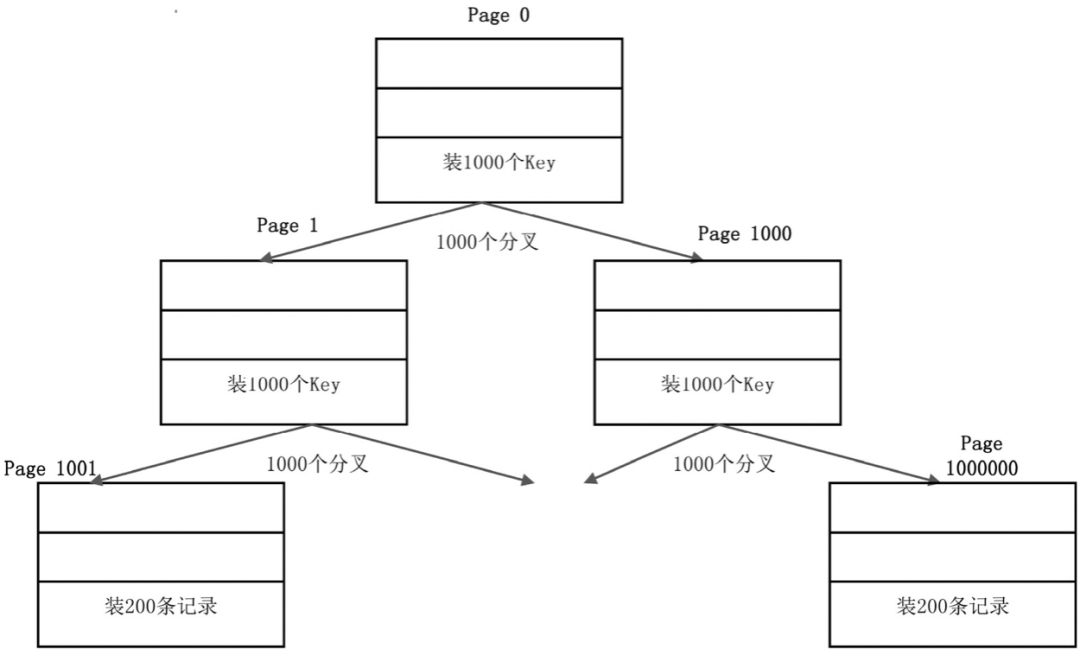
一個(gè)Page大概可以裝1000個(gè)key(意味著B+樹有1000個(gè)分叉),每個(gè)Page大概可以裝200條記錄(葉子節(jié)點(diǎn)),那么三層結(jié)構(gòu)可以裝多少?1000 * 1000 * 200 = 2億條,約16GB的數(shù)據(jù),這就是 B+ 數(shù)的強(qiáng)大之處
3)非主鍵索引
每一個(gè)非主鍵索引都對應(yīng)一個(gè) B+ 樹,與主鍵索引不同的是非主鍵索引每個(gè)葉子節(jié)點(diǎn)存儲的是主鍵的值而不是記錄的指針。也就是說對于非主鍵索引的查詢,會先查到主鍵的值,再拿主鍵的值去查詢主鍵的B+數(shù),這就需要兩次 B+ 樹的查詢操作,也就我們常說的 回表查詢
6.4 事務(wù)與鎖
1)事務(wù)的隔離級別
什么事務(wù)?事務(wù)就是一個(gè)"代碼塊"(一條船的螞蚱),要么都不執(zhí)行,要么都執(zhí)行。多個(gè)事務(wù)之間,為了想完成任務(wù),那么它們之間就很容易發(fā)生沖突,沖突產(chǎn)生就容易帶來問題,比如:有兩個(gè)事務(wù)分別是 小王 和 小李
臟讀:小王 讀取了 小李 不想要的東西,給 小王 帶來了臟數(shù)據(jù) 不可重復(fù)讀: 小王兩次讀取同一個(gè)記錄,發(fā)現(xiàn)兩次都不一樣,原來是小李在搞鬼,一直在更新數(shù)據(jù) 幻讀: 小王兩次讀取數(shù)據(jù),發(fā)現(xiàn)讀出來的條數(shù)都不一樣,原來是小李在搞鬼,一直在增加/刪除數(shù)據(jù) 丟失更新:小王正在將一條數(shù)據(jù)的值修改為 5,沒想到小李也在修改這條數(shù)據(jù)修改為4,在小李修改結(jié)束之前,小王先修改完成了,小李才結(jié)束修改,這是小王發(fā)現(xiàn)數(shù)據(jù)怎么變成了 4
看了上面的 4 個(gè)問題,我們都覺得小李實(shí)在是太壞了,那有沒有什么方法可以幫助到小王?
RU(Read Uncommited):徒有其名,什么都沒做,什么問題都沒解決 RC(Read Commited):可以解決 臟讀 問題 RR(Repeatable Read):可以解決 臟讀、不可重復(fù)讀、幻讀 問題 Serialization(串行化):解決所有問題
盡管串行化可以解決所有問題,但所有操作都是串行的,性能無法結(jié)局,所以常用的隔離級別是 RC 和 RR(默認(rèn))。RR 可以解決 臟讀、不可重復(fù)讀、幻讀 問題,那最后一個(gè) 丟失更新 我們就要另外想方法解決了
2)悲觀鎖
悲觀心態(tài),認(rèn)為數(shù)據(jù)發(fā)生沖突的概率很大,在讀之前就直接上鎖,可以利用 select xxx for update 語句。但會存在拿到鎖之后一直沒釋放的問題,在高并發(fā)場景下會造成大量請求阻塞
3)樂觀鎖
樂觀心態(tài),認(rèn)為數(shù)據(jù)發(fā)生沖突的概率很小,讀之前不上鎖,寫的時(shí)候才判斷原有的數(shù)據(jù)是否被其他事務(wù)修改了,也就是常說的 CAS。
CAS的核心思想是:數(shù)據(jù)讀出來的時(shí)候有一個(gè)版本v1,然后在內(nèi)存里面修改,當(dāng)再寫回去的時(shí)候,如果發(fā)現(xiàn)數(shù)據(jù)庫中的版本不是v1(比v1大),說明在修改的期間內(nèi)別的事務(wù)也在修改,則放棄更新,把數(shù)據(jù)重新讀出來,重新計(jì)算邏輯,再重新寫回去,如此不斷地重試。
6.5 事務(wù)實(shí)現(xiàn)原理之1:Redo Log
事務(wù)的四大核心屬性:
原子性: 事務(wù)要么不執(zhí)行,要么完全執(zhí)行。如果執(zhí)行一半,宕機(jī)重啟,已執(zhí)行的一半要回滾回去 一致性:事務(wù)的執(zhí)行使得數(shù)據(jù)庫從一種正確狀態(tài)轉(zhuǎn)換成另外一種正確狀態(tài) 隔離性:在事務(wù)正確提交之前,不允許把該事務(wù)對數(shù)據(jù)的任何改變提供給其他事務(wù) 持久性:一旦事務(wù)提交,數(shù)據(jù)就不能丟
1)Write-Ahead
一個(gè)事務(wù)存在修改多張表的多條記錄,而多條記錄又可分布在不同的 Page 里面,對應(yīng)著磁盤的不同文職。如果每個(gè)事務(wù)都直接寫磁盤,性能勢必達(dá)不到要求。
解決的方式就是在內(nèi)存中進(jìn)行事務(wù)提交,然后通過后臺線程異步地把內(nèi)存中的數(shù)據(jù)寫入到磁盤中。但這個(gè)時(shí)候又會有個(gè)問題,那就是如果發(fā)生宕機(jī),內(nèi)存中的數(shù)據(jù)沒來得及刷盤就丟失了。
而這個(gè)時(shí)候 Redo Log 就是用來解決這種問題
一樣是先在內(nèi)存中提交事務(wù),然后寫日志(Redo Log),然后后臺任務(wù)把內(nèi)存中的數(shù)據(jù)異步刷到磁盤中。日志是順序的記錄在尾部,這樣就可以避免一個(gè)事務(wù)發(fā)生多次磁盤隨機(jī)I/O 問題。
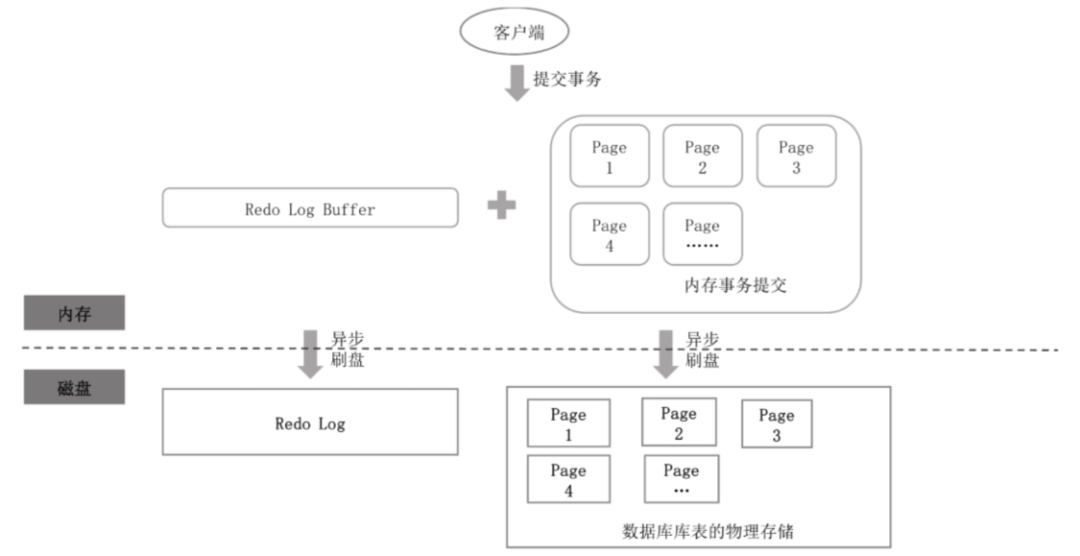
從圖中我們可以看到,在事務(wù)提交之后,Redo Log先寫入到內(nèi)存中的 Redo Log Buffer 中,然后異步地刷到磁盤的 Redo Log。因此不光光事務(wù)修改的操作是異步刷盤的,Redo Log 的寫入也是異步刷盤的。
既然都是先寫到內(nèi)存中,那么發(fā)生宕機(jī)還是會出現(xiàn)丟失數(shù)據(jù)的問題,因此 InnoDB 有個(gè)參數(shù) innodb_flush_log_at_trx_commit 可以控制刷盤策略:
0: 每秒刷一次,默認(rèn)的策略 1: 每提交一個(gè)事務(wù),就刷一次(最安全) 2: 不刷盤。然后根據(jù)參數(shù)innodb_flush_log_at_timeout設(shè)置的值決定刷盤頻率。
總結(jié):0 和 2 都可能丟失數(shù)據(jù),1 是最安全的,但是性能是最差的
2)日志結(jié)構(gòu)
從物理結(jié)構(gòu)上來看,日志是一個(gè)永不結(jié)束的字節(jié)流,但從邏輯結(jié)構(gòu)上看,日志不可能是一個(gè)永不結(jié)束的字節(jié)流


因此在 Redo Log 中存在一個(gè) LSN(Log Sequence Number)的編號(按照時(shí)間順序),在一定時(shí)間后之前的歷史日志就會歸檔,并從頭開始循環(huán)使用
在 Redo Log 中會采用邏輯和物理的方式總和記錄,先以 Page 為單位記錄日志,然后每個(gè) Page 中在采用邏輯記法(記錄 Page 里面的哪一行被修改了),這種記法也稱為 Physiological Logging
3)崩潰后恢復(fù)
不同事務(wù)的日志在Redo Log 中是交叉存在的,也就意味著未提交的事務(wù)也在 Redo Log 中。而崩潰后恢復(fù)就會用到一個(gè)名為 ARIES 算法,不管事務(wù)有沒有提交,日志都會記錄到 Redo Log 中,當(dāng)崩潰再恢復(fù)的時(shí)候就會把 Redo Log 全部重放一遍,提交和未提交的事務(wù)都會重放,從而讓數(shù)據(jù)庫回到宕機(jī)之前的狀態(tài),稱之為 Repeating History 。重放結(jié)束后再把宕機(jī)之前未完成的事務(wù)找出來,然后逐一利用 Undo Log 進(jìn)行回滾。
4)總結(jié)
一個(gè)事務(wù)對應(yīng)多條 Redo Log,并且是不連續(xù)存儲的 Redo Log 只保證事務(wù)的持久性,而無關(guān)原子性 未提交的事務(wù)回滾是通過 Checkpoint 記錄的 “活躍事務(wù)表” + 每個(gè)事務(wù)日志的開始/結(jié)束標(biāo)識 + Undo Log實(shí)現(xiàn)的 Redo Log 具有冪等性,通過 LSN 實(shí)現(xiàn) 無論是提交的、還是未提交的事務(wù),其對應(yīng)的 Page 數(shù)據(jù)都可能被刷到了磁盤中。未提交的事務(wù)對應(yīng)的Page數(shù)據(jù),在宕機(jī)重啟后會回滾。
6.6 事務(wù)實(shí)現(xiàn)原理值2: Undo Log
上面說到進(jìn)行 Redo Log 宕機(jī)回滾的時(shí)候,如果 Redo Log 中存在未提交的事務(wù),那么就需要借助 Undo Log進(jìn)行輔助,換言之,如果 Redo Log 里面記錄的都是已經(jīng)提交的事務(wù),那么回滾的時(shí)候也就不需要 Undo Log 的幫助
那么 Undo Log 除了在宕機(jī)恢復(fù)時(shí)對未提交的事務(wù)進(jìn)行回滾,還具備以下兩個(gè)核心作用:
實(shí)現(xiàn) 隔離性 高并發(fā)
在多線程的場景中應(yīng)對并發(fā)問題的策略通常有三種:
互斥鎖: 一個(gè)數(shù)據(jù)對象上面只有一個(gè)鎖,先到先得。(寫寫互斥,讀寫互斥,讀讀互斥) 讀寫鎖: 一個(gè)數(shù)據(jù)對象一個(gè)鎖,兩個(gè)視圖。(寫寫互斥,讀寫互斥,讀讀并發(fā)) CopyOnWrite: 寫時(shí)復(fù)制,寫完之后再把數(shù)據(jù)對象的指針一次性賦值回去(寫寫并發(fā),讀寫并發(fā),讀讀并發(fā))
Undo Log 的作用就是在 CopyOnWrite 部分。每個(gè)事務(wù)修改記錄之前,都會先把記錄拷貝一份出來,拷貝出來的那個(gè)備份就是存在Undo Log 里面。每個(gè)事務(wù)都有唯一的編號,ID從小到大遞增,每一次修改就是一個(gè)版本,因此Undo Log負(fù)責(zé)的就是維護(hù)數(shù)據(jù)從舊到新的每個(gè)版本,各個(gè)版本之間的記錄通過鏈表串聯(lián)
為了不能讓事務(wù)讀取到正在修改的數(shù)據(jù),只能讀取歷史版本,這就實(shí)現(xiàn)了隔離性
Undo Log 不是 log 而是數(shù)據(jù),因?yàn)?Undo Log 只是臨時(shí)記錄,當(dāng)事務(wù)提交之后,對應(yīng)的 Undo Log 文件就可以刪除了,因此 Undo Log 成為記錄的備份數(shù)據(jù)更為準(zhǔn)確
正是有了 MVCC 這種特性,通常的 select 語句都是不加鎖的,讀取的全部是數(shù)據(jù)的歷史版本,從而支撐高并發(fā)的查詢,也就是所謂的 快照讀,與之相對應(yīng)的是 當(dāng)前讀
快照讀/當(dāng)前讀
讀取歷史數(shù)據(jù)的方式就叫做快照讀,而讀取數(shù)據(jù)庫最新版本數(shù)據(jù)的方式叫做 當(dāng)前讀
快照讀
當(dāng)執(zhí)行 select 操作時(shí),InnoDB 默認(rèn)會執(zhí)行快照讀,會記錄下這次 select 后的結(jié)果,之后 select 的時(shí)候就會返回這次快照的數(shù)據(jù),即使其他事務(wù)提交了不會影響當(dāng)前 select 的數(shù)據(jù),這就實(shí)現(xiàn)了可重復(fù)讀。
快照的生成當(dāng)在第一次執(zhí)行 select 的時(shí)候,也就是說假設(shè)當(dāng) A 開啟了事務(wù),然后沒有執(zhí)行任何操作,這時(shí)候 B insert 了一條數(shù)據(jù)然后 commit,這時(shí) A 執(zhí)行 select,那么返回的數(shù)據(jù)中就會有 B 添加的那條數(shù)據(jù)。之后無論再有其他事務(wù) commit 都沒有關(guān)系,因?yàn)榭煺找呀?jīng)生成了,后面的 select 都是根據(jù)快照來的。
當(dāng)前讀
對于會對數(shù)據(jù)修改的操作(update、insert、delete)都是采用 當(dāng)前讀 的模式。在執(zhí)行這幾個(gè)操作時(shí)會讀取最新的版本號記錄,寫操作后會把版本號改為當(dāng)前事務(wù)的版本號,所以即使是別的事務(wù)提交的數(shù)據(jù)也可以查詢到。
假設(shè)要 update 一條記錄,但是在另一個(gè)事務(wù)中已經(jīng) delete 掉這條數(shù)據(jù)并且 commit 了,如果 update 就會產(chǎn)生沖突,也正是因?yàn)檫@樣所以會產(chǎn)生幻讀,所以在 update 的時(shí)候需要知道最新的記錄。
6.7 Binlog 與主從復(fù)制
Binlog 稱之為記錄日志,它與 Redo Log 和 Undo Log 不同之處在于,后兩者是 InnoDB 引擎層面的,而 Binlog 是Mysql 層面的,它的主要作用是用來做主從復(fù)制,它同樣具有刷盤機(jī)制:
0: 事務(wù)提交之后不主動刷盤,依靠操作系統(tǒng)自身的刷盤機(jī)制 1: 每提交一個(gè)事務(wù),刷一次磁盤 n: 每提交 n 個(gè)事務(wù),刷一次磁盤
總結(jié):0 和 n 都是不安全的,為了不丟失數(shù)據(jù),一般都是建議雙 1 保證,即 sync_binlog 和 innodb_flush_log_at_trx_commit 的值都是 1
1)Binlog 與 Redo Log的區(qū)別
Redo Log 和 Binlog 的產(chǎn)生方式不同。redo log是在物理存儲引擎產(chǎn)生,而Binlog是在 mysql 數(shù)據(jù)庫的 server 層產(chǎn)生。并且 Binlog不僅針對 InnDB 存儲引擎,MySQL 數(shù)據(jù)庫中的任何存儲引擎對數(shù)據(jù)庫的更改都會產(chǎn)生 Binlog Redo Log 和 binlog 記錄的方式不同。Binlog 記錄的是一種邏輯日志,即通過 sql 語句的方式來記錄數(shù)據(jù)庫的修改;而 InnoDB層產(chǎn)生的Redo Log 是一種物理格式的日志,記錄磁盤中每一個(gè)數(shù)據(jù)頁的修改 Redo Log 和 Binlog 記錄的時(shí)間點(diǎn)不同。Binlog只是在事務(wù)提交完成后進(jìn)行一次寫入,而 Redo Log 則是在事務(wù)進(jìn)行中不斷寫入,Redo Log 并不是隨著事務(wù)提交的順序進(jìn)行寫入的,這也就是說在 Redo Log 中針對一個(gè)事務(wù)會有多個(gè)不連續(xù)的記錄日志
2)主從復(fù)制
Mysql 有三種主從復(fù)制的方式
同步復(fù)制: 所有的 Slave 都接受完 Binlog 才認(rèn)為事務(wù)提交成功,便返回成功的結(jié)果 異步復(fù)制: 只要 Master 事務(wù)提交成功,就對客戶端返回成功,然后通過后臺線程的方式把 Binlog 同步給 Slave(可能會丟數(shù)據(jù)) 半同步復(fù)制: Master 事務(wù)提交,同時(shí)把 Binlog 同步給 Slave,只要部分 Slave 接收到了 Binlog(數(shù)量可設(shè)置),就認(rèn)為事務(wù)提交成功,返回成功結(jié)果
總結(jié):無論異步復(fù)制,還是半異步復(fù)制(可能退化為異步復(fù)制),都可能在主從切換的時(shí)候丟數(shù)據(jù)。業(yè)務(wù)一般的做法是犧牲一致性來換取高可用性,即在Master宕機(jī)后切換到Slave,忍受少量的數(shù)據(jù)丟失,后續(xù)再人工修復(fù)
3)并行復(fù)制
原生的 MySQL 主從復(fù)制都是單線程的,將 Master 的 Binlog 發(fā)送到 Slave 上后生成 RelayLog 文件,Slave 再對 RelayLog 文件進(jìn)行重放

而所謂的并行復(fù)制實(shí)際上是并行回放,傳輸還是單線程,但是回放是使多線程

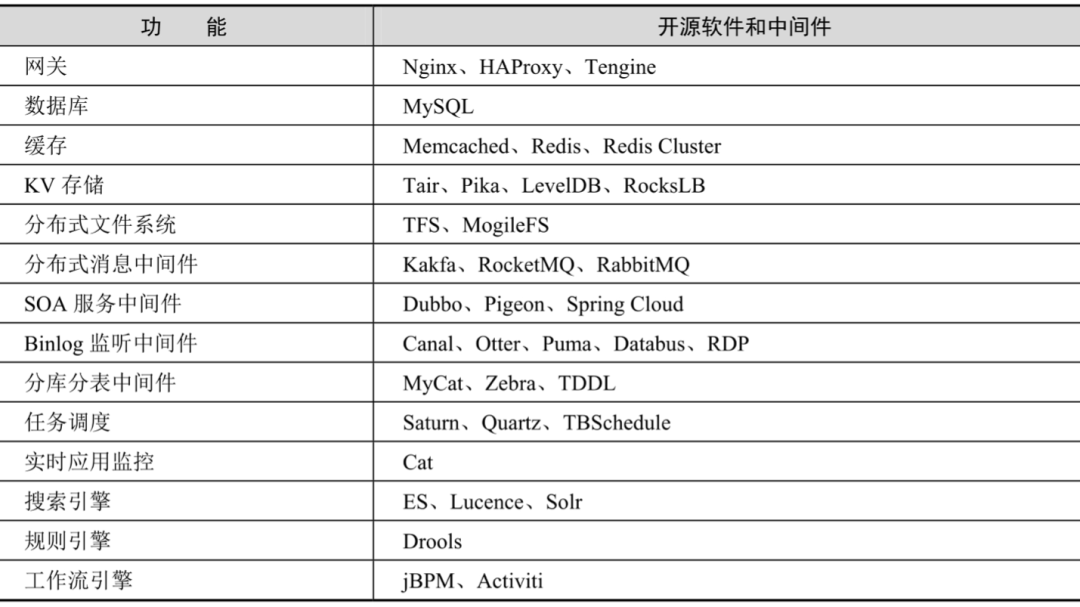
第七章:框架、軟件與中間件
開源運(yùn)行的興起,最不缺的便是開發(fā)框架,現(xiàn)市面上有各種各樣的輪子
第三部分:技術(shù)架構(gòu)之道
第八章:高并發(fā)問題
任何問題都是速途同歸,到最后只能通過兩種操作:讀和寫。
8.1 高并發(fā)讀
1. 加緩存
緩存可分為 本地緩存 和 集中式緩存 。使用緩存的同時(shí)我們需要思考緩存的更新策略:
主動更新: 當(dāng)數(shù)據(jù)庫中的數(shù)據(jù)發(fā)生變更的時(shí)候,主動刪除或更新緩存中的數(shù)據(jù) 被動更新: 當(dāng)用戶查詢請求到來時(shí),再對緩存進(jìn)行更新
同樣使用緩存可能會面臨的幾個(gè)問題:
緩存雪崩: 即緩存的高可用問題。如果緩存宕機(jī)/過期,所有請求會瞬間壓垮數(shù)據(jù)庫 緩存穿透: 查詢緩存中不存在的數(shù)據(jù),導(dǎo)致短時(shí)間內(nèi)大量請求寫入并壓垮數(shù)據(jù)庫 緩存擊穿: 緩存中熱點(diǎn)數(shù)據(jù)過期,直接訪問數(shù)據(jù)庫,導(dǎo)致數(shù)據(jù)庫被壓垮
那么緩存的使用無外乎都是對數(shù)據(jù)進(jìn)行冗余,達(dá)到空間換時(shí)間的效果
2. 并發(fā)讀
單線程不行,通常就會使用多線程。這種明顯治標(biāo)不指標(biāo),容易達(dá)到性能瓶頸
3. 重寫輕讀
當(dāng)微博這種大流量的平臺,查看關(guān)注人和自己發(fā)布的微博列表看似很簡單需求,通常只需要兩張表,一個(gè)是 關(guān)注關(guān)系表 ,一個(gè)是 微博發(fā)布表。但是對于高并發(fā)查詢的時(shí)候很容易將數(shù)據(jù)庫打崩。
那我們就需要改成 重寫輕讀 的方式,不是查詢的時(shí)候才聚合,,而是提前為每個(gè) userId 準(zhǔn)備一個(gè) 收件箱
當(dāng)某個(gè)被關(guān)注的用戶發(fā)布微博時(shí),只需要將這條微博發(fā)送給所有關(guān)注自己每個(gè)用戶的收件箱中,這樣用戶查詢的時(shí)候只需要查看自己的收件箱即可。
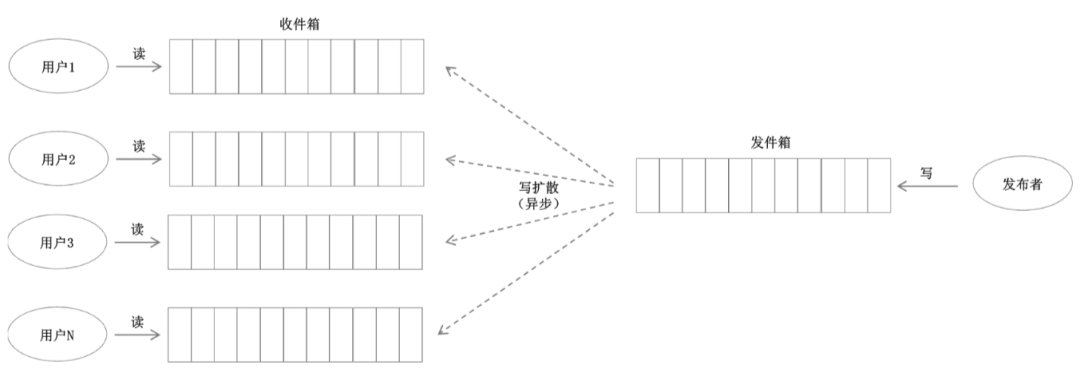
但通過使用 重寫輕讀 容易帶來一個(gè)問題,那就是如果一個(gè)人擁有了 500 萬粉絲,那就意味著他需要往 500 萬個(gè)收件箱中推送,這對系統(tǒng)來說同樣是個(gè)不小的挑戰(zhàn),那這個(gè)時(shí)候就需要采用 推拉結(jié)合 的方式
對于粉絲量少的用戶(設(shè)個(gè)閾值),發(fā)送微博后可以直接推送到用戶的收件箱,對于粉絲較多的用戶,只推送給在線的用戶,對于讀的一端,用戶有些可以通過收件箱獲取,有些需要自己手動去拉,這種就是推拉結(jié)合的方式
8.2 高并發(fā)寫
1. 數(shù)據(jù)分片
常見的有: 分庫分表、Java的ConcurrentHashMap、Kafka的partition
2. 任務(wù)分片
數(shù)據(jù)分片是對要處理的數(shù)據(jù)(或請求)進(jìn)行分片,任務(wù)分片是對處理程序本身進(jìn)行分片。
常見的有:CPU 的指令流水線、Map/Reduce、Tomcat 的1+N+M網(wǎng)絡(luò)模型
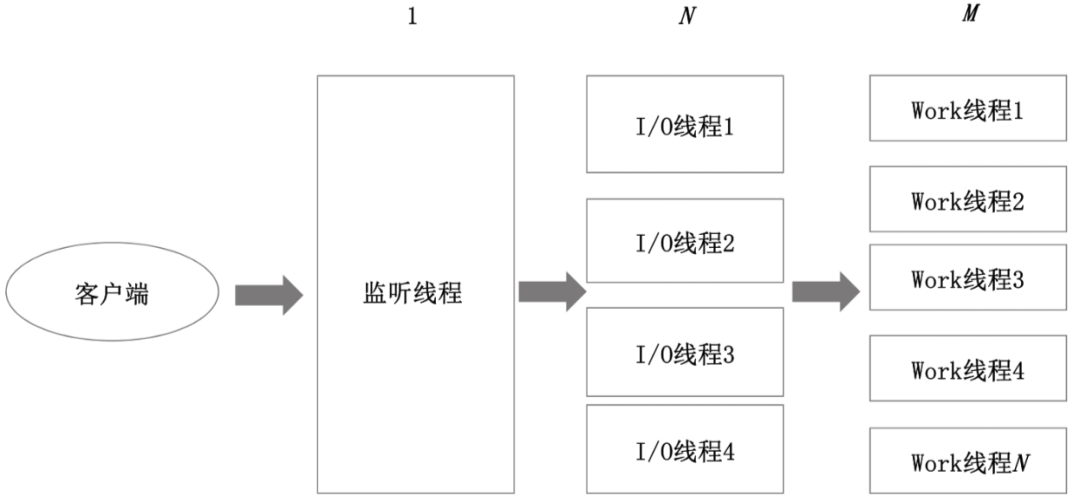
3. 異步化
通過消息中間件,分流處理
4. 批量處理
不管是Mysql、Redis、Kafka 通常上都不會將數(shù)據(jù)一條一條的進(jìn)行處理,而是多條合并成一條,一次性寫入
8.3 容量規(guī)劃
高并發(fā)讀寫是一種定性分析,而壓力測試和容量規(guī)劃就是一種定量分析
1)吞吐量、響應(yīng)時(shí)間與并發(fā)數(shù)
這三個(gè)概念都是比較常見的
吞吐量:單位時(shí)間內(nèi)處理的請求數(shù),例如 QPS、TPS 等指標(biāo) 響應(yīng)時(shí)間:處理每個(gè)請求需要的事件 并發(fā)數(shù):服務(wù)器同時(shí)并行處理的請求個(gè)數(shù)
三者關(guān)系:吞吐量 * 響應(yīng)時(shí)間 = 并發(fā)數(shù)
關(guān)鍵點(diǎn)說明:談?wù)撏掏铝浚≦PS)的時(shí)候,一定需要談對應(yīng)的響應(yīng)時(shí)間是多少,隨著QPS的增加,響應(yīng)時(shí)間也在增加,雖然 QPS 提上來了,但用戶端的響應(yīng)時(shí)間卻變長了,客戶端的超時(shí)率增加,用戶體驗(yàn)變差,所以這兩者需要權(quán)衡,不能一昧地提升 QPS,而不顧及響應(yīng)時(shí)間
2)壓力測試與容量評估
容量評估的基本思路:
機(jī)器數(shù) = 預(yù)估總流量/單機(jī)流量
其中分子是一個(gè)預(yù)估的值(通過歷史數(shù)據(jù)預(yù)估),分母通過壓力測試得到
在計(jì)算的時(shí)候需要使用峰值測算,而不能使用均值。盡管有時(shí)候峰值持續(xù)的時(shí)間很短,但不容忽視。
壓力測試方法:
線上壓力測試對比測試環(huán)境壓力測試 讀接口壓力測試對比寫接口壓力測試 單機(jī)壓力測試對比全鏈路壓力測試
第九章:高可用與穩(wěn)定性
高并發(fā)使系統(tǒng)更有效率,高可用使系統(tǒng)更可靠
9.1 多副本
不要把所有雞蛋放到一個(gè)籃子里
1)本地緩存多副本
利用消息中間(發(fā)布/訂閱機(jī)制),一條消息發(fā)出,多臺機(jī)器收到后更新自己的本地緩存
2)Redis多副本
Redis Cluster 提供了 Master - Slave 之間的復(fù)制機(jī)制,當(dāng) Master 宕機(jī)后可以切換到 Slave。
3)MySQL 多副本
MySQL 之間可以用到異步復(fù)制或半異步復(fù)制,同步復(fù)制性能較差,比較少用
4)消息中間件多副本
對于Kafka類的消息中間件,一個(gè)Partition通常至少會指定三個(gè)副本,為此Kafka專門設(shè)計(jì)了一種稱為ISR的算法,在多個(gè)副本之間做消息的同步
9.2 隔離、限流、熔斷和降級
1)隔離
隔離是指將系統(tǒng)或資源分割開,在系統(tǒng)發(fā)生故障時(shí)能限定傳播范圍和影響范圍,即發(fā)生故障后不會出現(xiàn)滾雪球的效應(yīng)
數(shù)據(jù)隔離 機(jī)器隔離 線程池隔離:核心業(yè)務(wù)的線程池需要和非核心業(yè)務(wù)的線程池隔離開 信號量隔離
信號量隔離是 Hystrix 提出的一種隔離方式,比線程池隔離更要輕量,由于線程池太多會導(dǎo)致線程過多從而導(dǎo)致切換的開銷大,而使用信號量隔離不會額外增加線程池,只在調(diào)用線程內(nèi)部執(zhí)行。信號量本質(zhì)上是一個(gè)數(shù)字,記錄當(dāng)前訪問某個(gè)資源的并發(fā)線程數(shù),在線程訪問資源之前獲取信號量,訪問結(jié)束時(shí)釋放信號量,一旦信號量達(dá)到閾值,便申請不到信號量,會直接 丟棄請求,而不是阻塞等待
2)限流
限流可以分為技術(shù)層面的限流和業(yè)務(wù)層面的限流。技術(shù)層面的限流比較通用,各種業(yè)務(wù)場景都可以用到;業(yè)務(wù)層面的限流需要根據(jù)具體的業(yè)務(wù)場景做開發(fā)。
具體操作可以空降:《餐廳小故事》| 服務(wù)限流的實(shí)施
3)熔斷
根據(jù)請求失敗率做熔斷 根據(jù)請求響應(yīng)做熔斷
注意點(diǎn): 限流是服務(wù)端,根據(jù)其能力上限設(shè)置一個(gè)過載保護(hù);而熔斷是調(diào)用方對自己的一個(gè)保護(hù)。能熔斷的服務(wù)肯定不是核心鏈路上的必選服務(wù),如果是的話,則服務(wù)超時(shí)或者宕機(jī),前端就不能用了,而不是熔斷。熔斷其實(shí)也是降級的一種方式
4)降級
降級是一種兜底方案,是在系統(tǒng)出故障之后的一個(gè)盡力而為的措施,比較偏向業(yè)務(wù)層面
9.3 灰度發(fā)布與回滾
頻繁進(jìn)行系統(tǒng)變更是個(gè)風(fēng)險(xiǎn)較高的操作。灰度與回滾可以使該操作變的相對可靠穩(wěn)定
1)新功能上線的灰度
當(dāng)一個(gè)新的功能上線時(shí),可以將一部分流量導(dǎo)入到這個(gè)新的功能,如果驗(yàn)證功能沒有問題,再一點(diǎn)點(diǎn)增加流量,最終讓所有流量都切換到這個(gè)新功能上。
按 userId 進(jìn)行流量劃分 固定位數(shù)進(jìn)行流量劃分 屬性或標(biāo)簽進(jìn)行流量劃分
2)舊系統(tǒng)重構(gòu)的灰度
如果舊的系統(tǒng)被重構(gòu)了,我們不可能在一瞬間把所有舊的系統(tǒng)下線,完全變成新的系統(tǒng),一般會持續(xù)一段時(shí)間,新舊系統(tǒng)同時(shí)共存,就需要增加流量分配機(jī)制。
3)回滾
回滾的方式:
安裝包回滾: 這種方式最簡單,不需要開發(fā)額外的代碼,發(fā)現(xiàn)線上有問題直接重新部署之前的安裝版本 功能回滾: 在開發(fā)新功能的時(shí)候,可以配置相應(yīng)的配置開關(guān),一旦發(fā)現(xiàn)新功能有問題,則關(guān)閉開關(guān),讓所有流量進(jìn)入老系統(tǒng)
第十章:事務(wù)一致性
分布式解決方案
1)2 PC 理論
2 PC 中有兩個(gè)角色:事務(wù)協(xié)調(diào)者與事務(wù)參與者
每一個(gè)數(shù)據(jù)庫就是一個(gè)參與者,調(diào)用方也就是協(xié)調(diào)者,2 PC 將事務(wù)的提交分為兩個(gè)階段:
階段一:協(xié)調(diào)者向所有參與者詢問是否可以提交事務(wù),并等待回復(fù),各參與者執(zhí)行事務(wù)操作,將 undo 和 redo 日志計(jì)入事務(wù)日志中,執(zhí)行成功后給協(xié)調(diào)者反饋 ack 階段二:如果階段一成功,則通知參與者提交事務(wù),否則利用 undo 日志進(jìn)行回滾
這種方式也存在了許多問題:
性能問題:所有參與者在事務(wù)比較階段處于同步阻塞狀態(tài),容易導(dǎo)致性能瓶頸 可靠性問題:如果協(xié)調(diào)者出現(xiàn)問題,那么會一直處于鎖定狀態(tài) 數(shù)據(jù)一致性問題:在階段2中如果協(xié)調(diào)者和參與者都掛了,有可能導(dǎo)致數(shù)據(jù)不一致
2)3PC 理論
解決了 2PC 同時(shí)掛掉的問題,將 2PC 的準(zhǔn)備階段再次一分為二
階段一:協(xié)調(diào)者向所有參與者發(fā)出包含事務(wù)內(nèi)容的 canCommit 請求,詢問是否可以提交事務(wù) 階段二:如果階段一成功,協(xié)調(diào)者會再次發(fā)出 preCommit 請求,進(jìn)入準(zhǔn)備階段,參與者將 undo 和redo 日志計(jì)入事務(wù)日志中。如果階段一失敗,協(xié)調(diào)者則發(fā)出 abort 請求,參與者便會中斷事務(wù) 階段三:如果階段二成功,協(xié)調(diào)者發(fā)出 doCommit 請求,參與者便會真正提交事務(wù)。如果失敗,便會發(fā)出 rollback 請求,參與者會利用 undo 事務(wù)進(jìn)行回滾,并結(jié)束事務(wù)
該方式依然會造成數(shù)據(jù)不一致問題:如果 preCommit 階段存在部分節(jié)點(diǎn)返回 nack,那么協(xié)調(diào)者剛要中斷事務(wù)便掛掉了,一定時(shí)間后參與者便會繼續(xù)提交事務(wù),造成數(shù)據(jù)不一致問題
3)補(bǔ)償事務(wù) TCC
TCC(try-confirm-cancel)是服務(wù)化的二階段編程模型,核心思想是:針對每個(gè)操作都要注冊一個(gè)與其對應(yīng)的確認(rèn)和補(bǔ)償(撤銷操作)。他同樣也是分為三個(gè)步驟
try 階段:主要是對業(yè)務(wù)系統(tǒng)做檢測及資源預(yù)留 confirm 階段:主要是對業(yè)務(wù)系統(tǒng)做確認(rèn)提交。try 階段執(zhí)行成功并開始執(zhí)行 confirm 階段,默認(rèn)情況下 try 成功,confirm 一定會成功 cancel 階段:主要是業(yè)務(wù)執(zhí)行錯(cuò)誤,執(zhí)行回滾,將預(yù)留的資源釋放
例子:轉(zhuǎn)賬操作,第一步在 try 階段,首先調(diào)用遠(yuǎn)程接口把自己和對方的錢凍結(jié)起來,第二步在 confirm 階段,執(zhí)行轉(zhuǎn)賬操作,如果成功則進(jìn)行解凍,否則執(zhí)行 cancel
它解決了數(shù)據(jù)最終一致性的問題,通過 confirm 和 cancel 的冪等性,保證數(shù)據(jù)一致性
4)最終一致性(消息中間件)
可以基于 RocketMQ 實(shí)現(xiàn)最終一致性。為了能通過消息中間件解決該問題,同時(shí)又不和業(yè)務(wù)耦合,RocketMQ提出了“事務(wù)消息”的概念
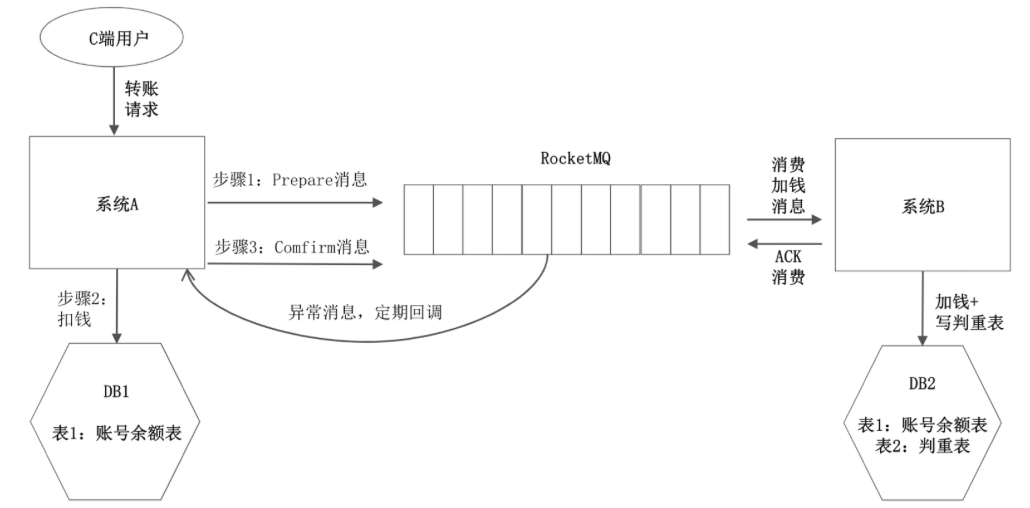
步驟1:系統(tǒng)A調(diào)用Prepare接口,預(yù)發(fā)送消息。此時(shí)消息保存在消息中間件里,但消息中間件不會把消息給消費(fèi)方消費(fèi),消息只是暫存在那。 步驟2:系統(tǒng)A更新數(shù)據(jù)庫,進(jìn)行扣錢操作。 步驟3:系統(tǒng)A調(diào)用Comfirm接口,確認(rèn)發(fā)送消息。此時(shí)消息中間件才會把消息給消費(fèi)方進(jìn)行消費(fèi)。
RocketMQ會定期(默認(rèn)是1min)掃描所有的預(yù)發(fā)送但還沒有確認(rèn)的消息,回調(diào)給發(fā)送方,詢問這條消息是要發(fā)出去,還是取消。發(fā)送方根據(jù)自己的業(yè)務(wù)數(shù)據(jù),判斷這條消息是應(yīng)該發(fā)出去(DB更新成功了),還是應(yīng)該取消(DB更新失敗)
第十一章:多副本一致性
無論是 MySQL的 Master/Slave,還是 Redis 的 Master/Slave,或是Kafka的多副本復(fù)制,都是通過犧牲一致性來換取高可用性的。
本章主要對 Paxos、Zab、Raft 三種算法進(jìn)行解析。做出的筆記內(nèi)容較多,保證本篇篇幅的情況下,考慮單獨(dú)抽出講解,有興趣的小伙伴可以后續(xù)關(guān)注~!
第十二章:CAP理論
強(qiáng)一致性 Consistency:是指所有節(jié)點(diǎn)同時(shí)看到相同的數(shù)據(jù)。可用性 Availability:任何時(shí)候,讀寫操作都是成功的,保證服務(wù)一直可用分區(qū)容錯(cuò)性 Partition tolerance:當(dāng)部分節(jié)點(diǎn)出現(xiàn)消息丟失或分區(qū)故障的時(shí)候,分布式系統(tǒng)仍然能夠運(yùn)行
CP的系統(tǒng)追求強(qiáng)一致性,比如Zookeeper,但犧牲了一定的性能
AP的系統(tǒng)追求高可用,犧牲了一定的一致性,比如數(shù)據(jù)庫的主從復(fù)制、Kafka的主從復(fù)制
1)分布式鎖
1. 基于 Zookeeper 實(shí)現(xiàn)
可以利用 Zookeeper 的 瞬時(shí)節(jié)點(diǎn) 的特性。每次加鎖都是創(chuàng)建一個(gè)瞬時(shí)節(jié)點(diǎn),釋放鎖則刪除瞬時(shí)節(jié)點(diǎn)。因?yàn)?Zookeeper 和客戶端之間通過心跳探測客戶端是否宕機(jī),如果宕機(jī),則 Zookeeper 檢測到后自動刪除瞬時(shí)節(jié)點(diǎn),從而釋放鎖。
2. 基于 Redis 實(shí)現(xiàn)
Redis的性能比Zookeeper更好,所以通常用來實(shí)現(xiàn)分布式鎖。但 Redis 相對 Zookeeper 也存在些許問題
沒有強(qiáng)一致性的Zab協(xié)議。如果Master 宕機(jī),Slave會丟失部分?jǐn)?shù)據(jù),造成多個(gè)進(jìn)程拿到同一把鎖 沒有心跳檢測。在釋放鎖之前宕機(jī),會導(dǎo)致鎖永遠(yuǎn)不會釋放
第四部分:業(yè)務(wù)架構(gòu)知道
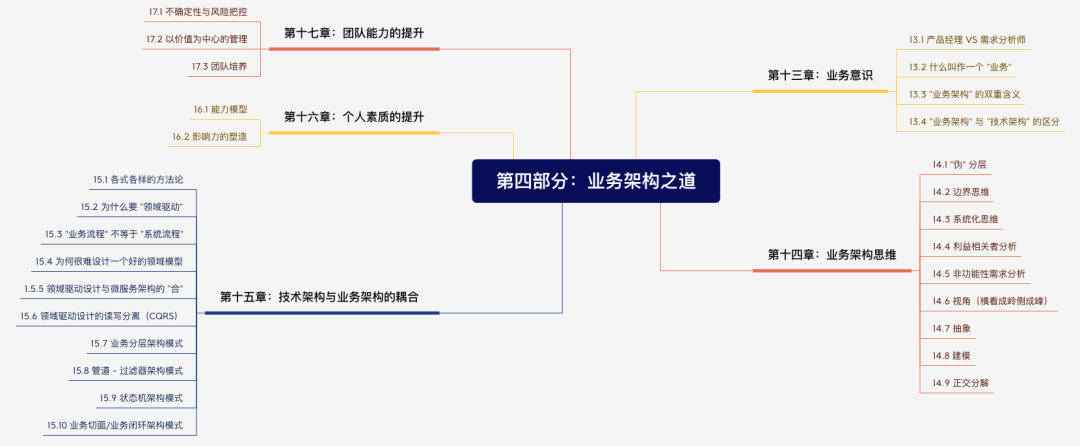
第十三章:業(yè)務(wù)意識
1) 產(chǎn)品經(jīng)理與需求分析師
產(chǎn)品經(jīng)理從某種意義上來說就稱之為需求分析師。作為一個(gè)技術(shù)人員,不需要像產(chǎn)品經(jīng)理或需求分析師那樣對需求了如指掌,但具有良好的業(yè)務(wù)意識確是做業(yè)務(wù)架構(gòu)的基本條件
那么什么業(yè)務(wù)意識?
了解需求來自何處
有時(shí)需求來自何處,技術(shù)為誰而坐,往往和公司的基因、盈利模式緊密掛鉤,公司本身決定了需求從什么地方來
判斷是真需求還是假需求
很多原因都會導(dǎo)致偽需求,比如老板的決定,面向 KPI 的需求。而其中存在一個(gè)因素便是:信息傳播的遞減效應(yīng)
當(dāng)發(fā)生一個(gè)事件時(shí),第一個(gè)人 A 看到事件的全過程,掌握 100 的信息量,描述給 B 的時(shí)候,受制于記憶力、表達(dá)力等因素只能描述出 90 的信息,往下遞推,到 D 的時(shí)候可能只剩 60 的信息。
所以,作為一個(gè)技術(shù)人員,當(dāng)從產(chǎn)品經(jīng)理接到需求的時(shí)候,一定要回溯,明確需求是在什么背景下提出的,究竟要解決用戶的什么問題。
需求的優(yōu)先級
人力資源和時(shí)間資源是有限的。如何合理分配尤為重要
2)業(yè)務(wù)是什么
一個(gè)內(nèi)容能稱為一個(gè)業(yè)務(wù),往往具備一個(gè)特點(diǎn),就是閉環(huán)。
什么是閉環(huán)?
團(tuán)隊(duì)閉環(huán):有自己的產(chǎn)品、技術(shù)、運(yùn)營和銷售聯(lián)合作戰(zhàn) 產(chǎn)品閉環(huán):從內(nèi)容的生成到消費(fèi),整條鏈路把控 商業(yè)閉環(huán):具備自負(fù)盈虧的能力 縱向閉環(huán):某個(gè)垂直領(lǐng)域,涵蓋從前到后 橫向閉環(huán):平臺模式,橫向覆蓋某個(gè)橫切面
3)業(yè)務(wù)架構(gòu)的雙重含義
業(yè)務(wù)架構(gòu)既關(guān)乎組織架構(gòu),也關(guān)乎技術(shù)架構(gòu)
從理論上講,合理的團(tuán)隊(duì)的組織架構(gòu)應(yīng)該是根據(jù)業(yè)務(wù)的發(fā)展來決定的,不同的公司在不同的發(fā)展階段會根據(jù)業(yè)務(wù)的發(fā)展情況,將壯大的業(yè)務(wù)拆分,萎靡的業(yè)務(wù)合并 支持業(yè)務(wù)的技術(shù)架構(gòu),業(yè)務(wù)架構(gòu)和計(jì)數(shù)架構(gòu)會相互作用,相互影響
第十四章:業(yè)務(wù)架構(gòu)思維
1)偽分層
不管是業(yè)務(wù)架構(gòu)還是技術(shù)架構(gòu),C端業(yè)務(wù)還是B端業(yè)務(wù),我們都會用到分層技術(shù)
偽分層的特征
底層調(diào)用上層:設(shè)計(jì)分層的時(shí)候應(yīng)深入思考 DIP(依賴反轉(zhuǎn))原則 同層之間,服務(wù)之間各種雙向調(diào)用: 這個(gè)很容易造成循環(huán)依賴問題,考慮是否要抽取 Middle 層來作為中間層 層之間沒有隔離,參數(shù)層層透傳,一直穿透到最低層,導(dǎo)致底層系統(tǒng)經(jīng)常變動
總結(jié)
越底層的系統(tǒng)越單一、越簡單、越固化 越上層的系統(tǒng)花樣越多、越容易變化。要做到這一點(diǎn),需要層與層之間有很好的隔離和抽象。 層與層之間的關(guān)系應(yīng)該嚴(yán)格遵守上層調(diào)用下層的準(zhǔn)則
2)邊界思維
1. 對象層面(SOLID 原則)
一個(gè)函數(shù)、一個(gè)類、一個(gè)模塊只做一件事,不要把不同的職責(zé)糅在一起,這就是邊界思維的一種體現(xiàn)
2. 接口層面
首先想到的不是如何實(shí)現(xiàn),而是把系統(tǒng)當(dāng)做一個(gè)黑盒,看系統(tǒng)對外提供的接口是什么,接口也就是系統(tǒng)的邊界,定義了系統(tǒng)可以支持什么、不支持什么。所以接口的設(shè)計(jì)往往比接口的實(shí)現(xiàn)更重要!
3. 產(chǎn)品層面
內(nèi)部實(shí)現(xiàn)很復(fù)雜,用戶界面很簡單,把復(fù)雜留給自己,把簡單留給用戶
4. 組織結(jié)構(gòu)層面
總結(jié): 邊界思維的重點(diǎn)在于約束,是一個(gè) "負(fù)方法" 的思維方式。架構(gòu)強(qiáng)調(diào)的不是系統(tǒng)能支持什么,而是系統(tǒng)的“約束”是什么,不管是業(yè)務(wù)約束,還是技術(shù)約束。沒有“約束”,就沒有架構(gòu)。一個(gè)設(shè)計(jì)或系統(tǒng),如果“無所不能”
3)系統(tǒng)化思維
系統(tǒng)化系統(tǒng)不在于頭痛醫(yī)頭腳痛醫(yī)腳,而是追溯源頭,關(guān)注整體上的影響,把不同的東西串在一起考慮,而不是割裂后分開來看
4)利益相關(guān)者分析
當(dāng)談到系統(tǒng)的時(shí)候,首先要確定的是系統(tǒng)為哪幾類人服務(wù),同哪幾個(gè)外部系統(tǒng)交互,也就確定了系統(tǒng)的邊界。
5)非功能性需求分析(以終為始)
軟件有功能需求和非功能需求,非功能性需求有:
并發(fā)性:關(guān)注點(diǎn)在于系統(tǒng)能抵抗多大的流量 一致性:數(shù)據(jù)一致性問題 可用性:是否保證服務(wù)一直處于可用狀態(tài) 可維護(hù)性:關(guān)注點(diǎn)在于代碼的可理解性 可擴(kuò)展性: 系統(tǒng)功能是否能夠靈活擴(kuò)展,而不會遇到一個(gè)需求就需要大刀闊斧地修改 可重用性: 開發(fā)新的需求,舊的功能模塊可以拿過來直接用
6)抽象
語言只是對現(xiàn)實(shí)中我們所注意到的事務(wù)特征的一種抽象,每一次命名,都是一個(gè)抽象化的過程,這個(gè)過程會忽略掉現(xiàn)實(shí)事務(wù)的許多特征。但是抽象的目的是為了交流提供便利,而不是給交流帶來負(fù)擔(dān),因此我們需要對自己的每一次抽象負(fù)責(zé),不能抽象到最后自己都不明白抽象的含義是什么。
抽象的幾種特征:
越抽象的詞,在詞典中個(gè)數(shù)越少;越具象的詞,在詞典中個(gè)數(shù)越多。
越抽象的詞,本身所表達(dá)的特征越少;越具象的詞,特征越豐富。
越抽象的詞,意義越容易被多重解讀;越具象的詞,意義越明確
7)建模
建模的本質(zhì):把重要的東西進(jìn)行顯性化,進(jìn)而把這些顯性化的構(gòu)造塊互相串聯(lián)起來,組成一個(gè)體系
8)正交分解
分解是一個(gè)很樸素的思維方式,把一個(gè)大的東西分成幾個(gè)部分。比分解更為嚴(yán)謹(jǐn),更為系統(tǒng)的是 正交分解,需要保證兩個(gè)原則:
分清:同一層次的多個(gè)部分之間要相互獨(dú)立,無重疊 分凈:完全窮盡,無遺漏
第十五章:技術(shù)架構(gòu)與業(yè)務(wù)架構(gòu)的融合
該章節(jié)主要是對 DDD(領(lǐng)域驅(qū)動模型) 做出解釋,比較泛化,這里推薦一本好書 《實(shí)現(xiàn)領(lǐng)域驅(qū)動設(shè)計(jì)》 ,書中對 DDD 解說的相對具體,這本書小菜最近也在啃讀中,后續(xù)會出相應(yīng)的讀書筆記,請伙伴們點(diǎn)點(diǎn)關(guān)注,后續(xù)不會迷路!
第十六章:個(gè)人素質(zhì)的替身
1)能力模型
對于程序員來說,我們是干技術(shù),很純粹,技術(shù)很好表示你能力越強(qiáng)。但是當(dāng)你慢慢職位上漲的時(shí)候,會發(fā)現(xiàn)技術(shù)不能代表你的全部。
1. 格局
打開格局,打開格局,平時(shí)常說的一句調(diào)侃的話卻格外重要。
做技術(shù)我們需要開闊視野打開格局,我們才能了解更多的技術(shù)棧,更好的運(yùn)用到項(xiàng)目中。
做產(chǎn)品我們需要開闊視野打開格局,我們才能了解市面上的競品是什么樣子,更好的借鑒到自己的項(xiàng)目中。
2. 歷史觀
格局 是從 空間 的角度看待問題,而 歷史觀 則是從 時(shí)間的角度看待問題。任何一種技術(shù),都不是憑空想出來的,任何一個(gè)需求,都不是憑空捏造的,我們需要進(jìn)行回溯,了解它誕生的背景,才能知其所以然。
3. 抽象能力
有些人抽象出來的事物可以讓別人一眼貫通,有些人抽象出來的事物卻連自己的看不懂。這就是抽象能力的表現(xiàn)。
很多寫代碼的人習(xí)慣利用 自底向上 的思維解決問題,討論需求的時(shí)候首先想到的是這個(gè)需求如何實(shí)現(xiàn),而不是這個(gè)需求本身合不合理,對于很多新人來說 需求的合不合理,依賴于需求好不好實(shí)現(xiàn),這樣的方式很容易導(dǎo)致 只見樹木,不見森林,最后淹沒在各種錯(cuò)綜復(fù)雜的細(xì)節(jié)中。
4. 深入思考的能力
深入思考的能力主要考察技術(shù)的深度
深度并不表示要在所有領(lǐng)域都很精通,而是專注于某個(gè)領(lǐng)域,對于專家和全棧工程師的區(qū)別,想想哪個(gè)職位的薪資可能會更高
5. 落地能力
落地能力值的就是執(zhí)行力,有空頭畫大餅的能力,卻無落地去實(shí)現(xiàn)的能力,只會阻礙項(xiàng)目的正常前行。這大概就是技術(shù)不喜銷售的原因吧
2)影響力的塑造
進(jìn)入職場的前幾年尤為關(guān)鍵,有的人平步青云,有的人卻止步不前。那就是沒能很好的塑造自己的影響力。影響力該如何塑造?
1. 關(guān)鍵時(shí)候能頂上
最怕的是 事不關(guān)己高高掛起 的心態(tài),如果下次攤上事的是你如何?如果當(dāng)團(tuán)隊(duì)中遇到問題,這個(gè)時(shí)候能夠迎上,絕對可以讓人知道還有你這一號人物(當(dāng)然要斟酌抗下的風(fēng)險(xiǎn),迎難而上并不意味著逞強(qiáng))
2. 打工思維和老板思維
雖然我們常說自己是打工人,但有的時(shí)候何不把自己當(dāng)成合伙人?
打工的思維,安排的事需要干一件,絕不多一點(diǎn),只管好自己的一畝三分地
老板的思維,這個(gè)產(chǎn)品的價(jià)值在哪?這個(gè)產(chǎn)品存在哪些問題,需要如何改進(jìn)?為何用戶一直投訴的事,還沒及時(shí)處理?
3. 空杯心態(tài)
術(shù)業(yè)有專攻,水平再高的人都需要謹(jǐn)記山外有山人外有人,否則就會一直待在自己的舒適圈中,剛愎自用
4. 建言獻(xiàn)策
不必害怕自己的回答是否正確,而瞻前顧后不敢發(fā)言,充分發(fā)揮 圓桌文化, 有建議有想法大膽提出,不然你是想留給自己的蛔蟲知道嗎
第十七章:團(tuán)隊(duì)能力的提升
1)不確定性與風(fēng)險(xiǎn)把控
技術(shù)管理的首要任務(wù)就是項(xiàng)目管理,通常存在以下幾種不確定性
1. 需求的不確定性
由于各種外部條件,導(dǎo)致需求提議的想法不是很成熟(可能只是頭腦風(fēng)暴),處于需要不斷優(yōu)化的階段,那么這個(gè)時(shí)候過早的進(jìn)行開發(fā)容易浪費(fèi)資源。作為技術(shù)負(fù)責(zé)人就需要和產(chǎn)品經(jīng)理以及相關(guān)的業(yè)務(wù)方進(jìn)行廣泛的頭痛,需要達(dá)成共識的情況,才能投入。
2. 技術(shù)的不確定性
啟動新項(xiàng)目的時(shí),最怕的就是一開始技術(shù)沒有很好的選型,到中間開發(fā)階段時(shí)候再進(jìn)行替換,這種勞民傷財(cái)?shù)氖虑檫€是盡量避免發(fā)生。必須在項(xiàng)目早期的時(shí)候就進(jìn)行過多的調(diào)研和測試。
3. 人員的不確定性
現(xiàn)在的大多數(shù)職員都是面向金線開發(fā),大多數(shù)在職情況并不是那么穩(wěn)定,而將項(xiàng)目的大多權(quán)限與業(yè)務(wù)集中在一名成員上是個(gè)不明智的選擇,能夠進(jìn)行 AB崗位開發(fā)是個(gè)不錯(cuò)的選擇,兩人之間的業(yè)務(wù)相互熟悉,哪怕是因?yàn)檎埣俚脑蛞材芎芸斓倪M(jìn)行替代補(bǔ)充
4. 組織的不確定性
公司越大,業(yè)務(wù)越復(fù)雜,部門越多。隨便做一個(gè)項(xiàng)目,都可能與好幾個(gè)業(yè)務(wù)部門打交道。這些部門可能還在異地,平時(shí)只能即時(shí)通信,或者遠(yuǎn)程電話溝通。對于這種情況,在項(xiàng)目前期必須要做盡可能多的溝通,調(diào)研對方提供的業(yè)務(wù)能力,哪些目前有,哪些還在開發(fā)中,哪些還沒有開發(fā)。在充分溝通的基礎(chǔ)上,和對方敲定排期表,不定期地同步進(jìn)度,保證對方的進(jìn)度和自己在一個(gè)節(jié)奏上。