
大型網(wǎng)站技術(shù)架構(gòu):摘要與讀書筆記
來源:xybaby cnblogs.com/xybaby/p/8907880.html
一個網(wǎng)站的進化史 大型網(wǎng)站架構(gòu)模式與核心要素 性能 高可用 伸縮性(Scalability) 可擴展性(Extensibility) Others
花了幾個晚上看完了《大型網(wǎng)站技術(shù)架構(gòu)》(https://book.douban.com/subject/25723064/)這本書,個人感覺這本書的廣度還行,深度還有些欠缺(畢竟只有200頁左右)。但是作為一個缺乏大型網(wǎng)站技術(shù)的IT民工,看完一遍還是很有收獲的,至少對一個網(wǎng)站的技術(shù)演進、需要解決的問題有了一個全面的認識。文中也有一些作者個人的心得、感悟、總結(jié),我覺得還是很中肯的。
在網(wǎng)上一搜,這本書的讀書筆記還是很多的,而我自己還是決定寫一篇讀書筆記,主要是為了避免自己忘得太快。筆記的內(nèi)容并不完全按照原書的內(nèi)容,主要記錄的是我自己感興趣的部分。
一個網(wǎng)站的進化史
作者反復(fù)在文中提到一個觀點:大型網(wǎng)站是根據(jù)業(yè)務(wù)需求逐步演化而來的,而不是設(shè)計出來的。
不得不承認,互聯(lián)網(wǎng)行業(yè)發(fā)展到了今天,大魚吃小魚還是很普遍的,大公司的微創(chuàng)新能力分分鐘就能干死一個小的項目,所以小公司需要足夠快的發(fā)展,不停的快速迭代與試錯。
下面是是一個演化的過程,圖片來自網(wǎng)絡(luò)。
初始階段的網(wǎng)站架構(gòu)
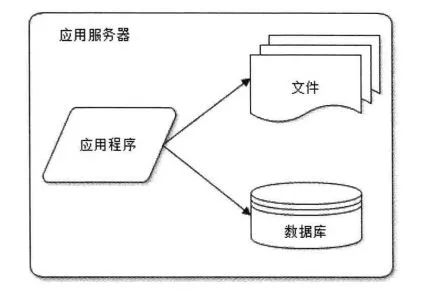
在初始階段,訪問量并不大,所以應(yīng)用程序、數(shù)據(jù)庫、文件等所有的資源都在一臺服務(wù)器上。
應(yīng)用服務(wù)和數(shù)據(jù)服務(wù)分離
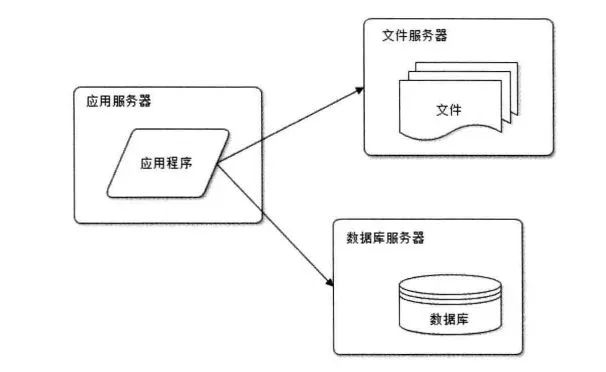
隨著業(yè)務(wù)的發(fā)展,就會發(fā)現(xiàn)一臺服務(wù)器抗不過來了,所以將應(yīng)用服務(wù)器與數(shù)據(jù)(文件、數(shù)據(jù)庫)服務(wù)器分離。三臺服務(wù)器對硬件資源的要求各不相同:應(yīng)用服務(wù)器需要更快的CPU,文件服務(wù)器需要更大的磁盤和帶寬,數(shù)據(jù)庫服務(wù)器需要更快速的磁盤和更大的內(nèi)存。分離之后,三個服務(wù)器各司其職,也方便針對性的優(yōu)化。
使用緩存改善網(wǎng)站性能
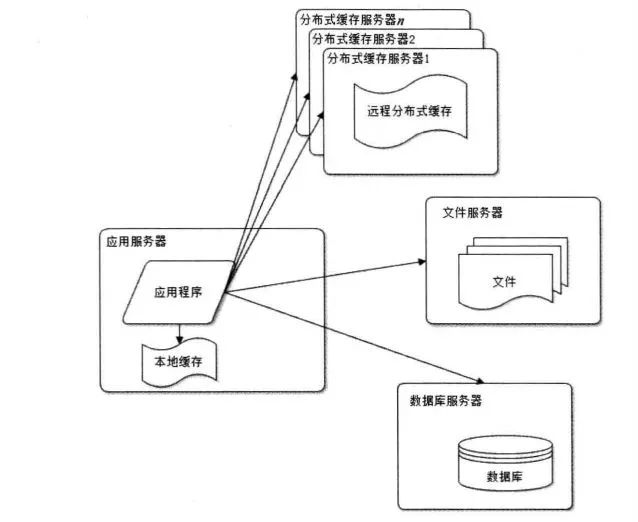
“世界上沒有什么問題是加一級緩存解決不了的,如果有那就再加一級緩存”
緩存的使用無處不在,緩存的根本目的是加快訪問速度。當(dāng)數(shù)據(jù)庫的訪問壓力過大的時候,就可以考慮使用緩存了。網(wǎng)站使用的緩存可以分為兩種: 緩存在應(yīng)用服務(wù)器上的本地緩存和緩存在專門的分布式緩存服務(wù)器上的遠程緩存。
使用應(yīng)用服務(wù)器集群改善網(wǎng)站的并發(fā)處理能力

隨著業(yè)務(wù)的發(fā)展,單個應(yīng)用服務(wù)器一定會成為瓶頸,應(yīng)用服務(wù)器實現(xiàn)集群是網(wǎng)站可伸縮集群架構(gòu)設(shè)計中較為簡單成熟的一種。后面也會提到,將應(yīng)用服務(wù)器設(shè)計為無狀態(tài)的(沒有需要保存的上下文信息),就可以通過增加機器,使用負載均衡來scale out。
數(shù)據(jù)庫讀寫分離
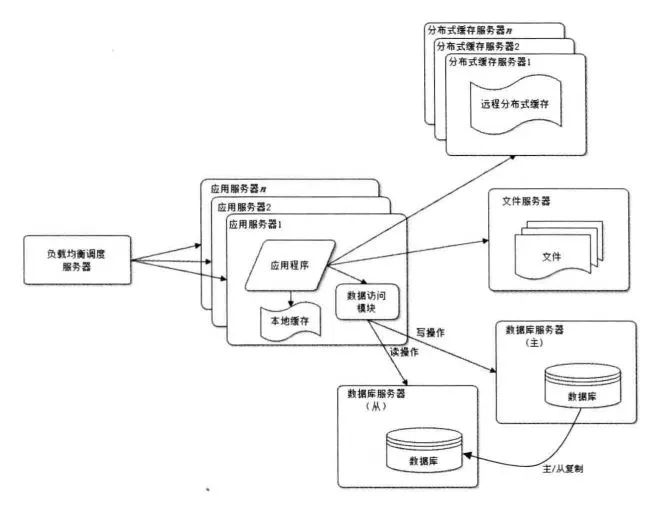
即使使用了緩存,但在緩存未命中、或者緩存服務(wù)時效的情況下,還是需要訪問數(shù)據(jù)庫,這個時候就需要數(shù)據(jù)庫的讀寫分離:主庫提供寫操作,從庫提供讀服務(wù)。注意,在上圖中增加了一個數(shù)據(jù)訪問模塊,可以對應(yīng)用層透明數(shù)據(jù)庫的主從分離信息。
使用反向代理和CDN 加速網(wǎng)站晌應(yīng)
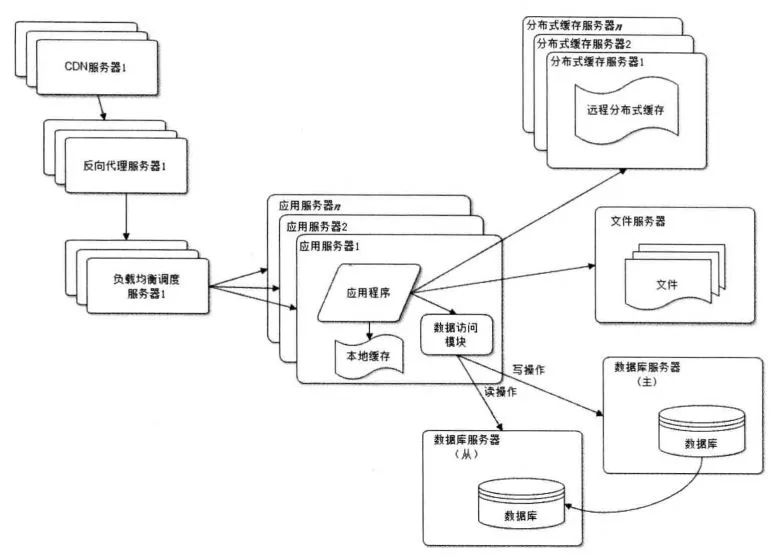
CDN和反向代理其實都是緩存,區(qū)別在于CDN 部署在網(wǎng)絡(luò)提供商的機房;而反向代理則部署在網(wǎng)站的中心機房。使用CDN 和反向代理的目的都是盡旱返回數(shù)據(jù)給用戶, 一方面加快用戶訪問速度,另一方面也減輕后端服務(wù)器的負載壓力。
使用分布式文件系統(tǒng)和分布式數(shù)據(jù)庫系統(tǒng)
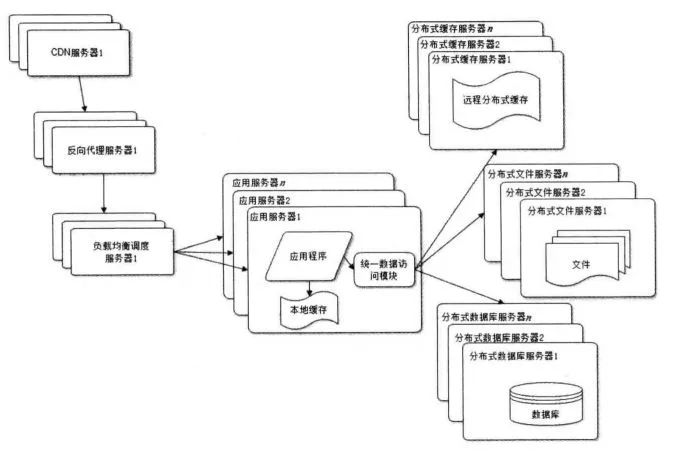
單個物理機的磁盤是有限的,單個關(guān)系數(shù)據(jù)庫的處理能力也是有上限的,所以需要分布式文件存儲與分布式數(shù)據(jù)庫。當(dāng)然,也需要”統(tǒng)一數(shù)據(jù)訪問模塊“,使得應(yīng)用層不用關(guān)心文件、數(shù)據(jù)的具體位置。值得一提的事,關(guān)系型數(shù)據(jù)庫自身并沒有很好的水平擴展方案,因此一般都需要一個數(shù)據(jù)庫代理層,如cobar、mycat。
使用NoSQL 和搜索引擎
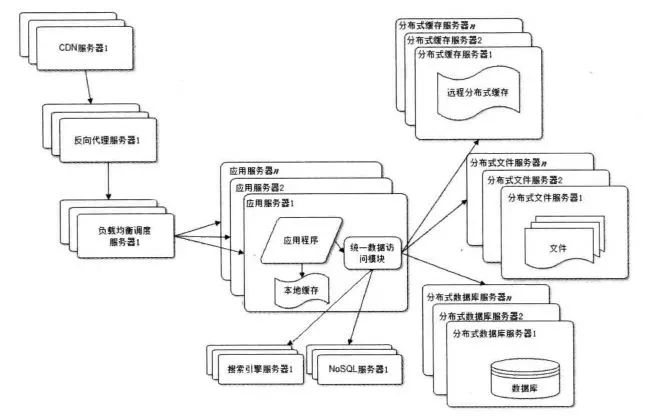
web2.0的很多應(yīng)用并一定適合用關(guān)系數(shù)據(jù)庫存儲,更加靈活的NoSql能更加方便的解決一些問題,而且NoSQL天然就支持分布式。專門的搜索引擎在提供更優(yōu)質(zhì)服務(wù)的同時,也大大減輕了數(shù)據(jù)庫的壓力。
業(yè)務(wù)拆分
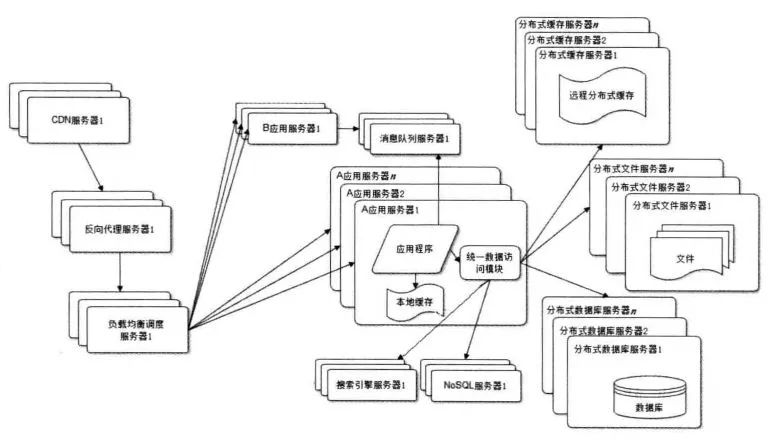
將一個網(wǎng)站拆分成許多不同的應(yīng)用, 每個應(yīng)用獨立部署維護。應(yīng)用之間可以通過一個超鏈接建立關(guān)系(在首頁上的導(dǎo)航鏈接每個都指向不同的應(yīng)用地址) ,也可以通過消息隊列進行數(shù)據(jù)分發(fā), 當(dāng)然最多的還是通過訪問同一個數(shù)據(jù)存儲系統(tǒng)來構(gòu)成一個關(guān)聯(lián)的完整系統(tǒng)
分布式服務(wù)
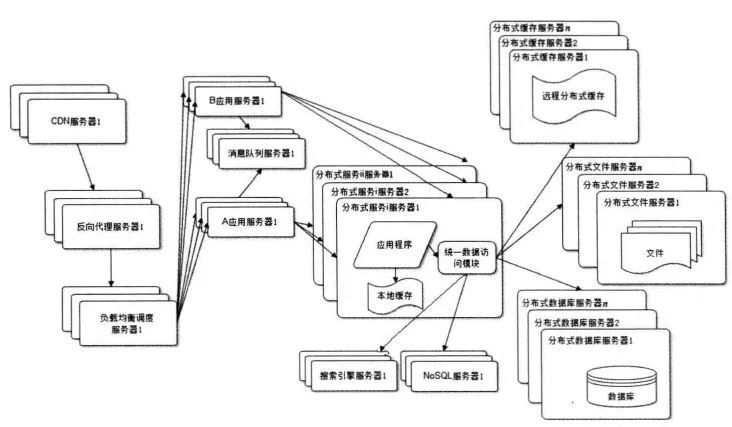
既然每一個應(yīng)用系統(tǒng)都需要執(zhí)行許多相同的業(yè)務(wù)操作, 比如用戶管理、商品管理等,那么可以將這些共用的業(yè)務(wù)提取出來,獨立部署。
通過服務(wù)的分布式,各個應(yīng)用能更好的獨立發(fā)展,實現(xiàn)了從依賴模塊到依賴服務(wù)的過渡。將通用的公共服務(wù)獨立出來,也方便做服務(wù)管控,比如對各個應(yīng)用的服務(wù)請求進行監(jiān)控,在高峰時期限制、關(guān)閉某些應(yīng)用的訪問等。
大型網(wǎng)站架構(gòu)模式與核心要素
這一部分是說大型網(wǎng)站需要解決的核心問題,以及解決這些問題的常規(guī)思路。
核心要素
五個要點:性能,可用性,伸縮性,擴展性,安全
作者指出,很多時候大家都混淆了伸縮性(Scalability)與擴展性(Extensibility)。我以前也是把Scalability稱之為擴展性,不過想想,在我們講代碼質(zhì)量的時候,擴展性也是指Extensibility,以后還是直接說這兩個英文單詞好了。
這幾點后面會詳細介紹。
網(wǎng)站架構(gòu)模式
對模式的定義,書中描述得很好:
" 每一個模式描述了一個在我們周圍不斷重復(fù)發(fā)生的問題及該問題解決方案的核心。這樣, 你就能一次又一次地使用該方案而不必做重復(fù)工作" 。模式的關(guān)鍵在于模式的可重復(fù)性, 問題與場景的可重復(fù)性帶來解決方案的可重復(fù)使用。
用我自己的話來說,模式就是套路。這些模式,都是為了達成上面提到的核心要素。那么,有哪些模式呢
分層
分層是企業(yè)應(yīng)用系統(tǒng)中最常見的一種架構(gòu)模式,將系統(tǒng)在橫向維度上切分成幾個部分,每個部分負責(zé)一部分相對比較單一的職責(zé), 然后通過上層對下層的依賴和調(diào)用組成一個完整的系統(tǒng)。
在大型網(wǎng)站架構(gòu)中也采用分層結(jié)構(gòu),將網(wǎng)主占軟件系統(tǒng)分為應(yīng)用層、服務(wù)層、數(shù)據(jù)層。
分層的好處在于:解耦合,獨立發(fā)展,伸縮性,可擴展性。上面網(wǎng)站的進化史也凸出了分層的重要性。
但是分層架構(gòu)也有一些挑戰(zhàn), 就是必須合理規(guī)劃層次邊界和接口,在開發(fā)過程中,嚴(yán)格遵循分層架構(gòu)的約束, 禁止跨層次的調(diào)用( 應(yīng)用層直接調(diào)用數(shù)據(jù)層)及逆向調(diào)用(數(shù)據(jù)層調(diào)用服務(wù)層, 或者服務(wù)層調(diào)用應(yīng)用層)。
分割
分層強調(diào)的是橫向切分,而分割是縱向切分, 上面網(wǎng)站進化史部分的業(yè)務(wù)拆分就包含了分割。
分割的目標(biāo)是高內(nèi)聚、低耦合的模塊單元
分布式
分層和分割的一個主要目的是分布式部署,但分布式也有自己的問題:網(wǎng)絡(luò)通信帶來的性能問題,可用性,一致性與分布式事務(wù),系統(tǒng)維護管理復(fù)雜度。
集群
一個機器解決不了的問題,就用幾個機器來解決,當(dāng)服務(wù)無狀態(tài)的時候,通過往集群增加機器就能解決大部分問題。對應(yīng)網(wǎng)站進化史中“使用應(yīng)用服務(wù)器集群改善網(wǎng)站的并發(fā)處理能力”
緩存
緩存就是將數(shù)據(jù)存放在距離計算最近的位置以加快處理速度,同時大大減輕了數(shù)據(jù)提供者的壓力
大型網(wǎng)站架構(gòu)設(shè)計在很多方面都使用了緩存設(shè)計:CDN、反向代理、本地緩存、分布式緩存
異步
異步是解耦合的一個重要手段,常見的生產(chǎn)者-消費者模型就是一個異步模式。
出了解耦合,異步還能提高系統(tǒng)可用性、加快響應(yīng)速度、流量削峰
冗余
冗余是系統(tǒng)可用性的重要保障,也是數(shù)據(jù)可靠性的重要手段
自動化
凡人總是會出這樣那樣的錯誤,能自動話的就要自動化。自動化大大解放了程序員、運維人員的生產(chǎn)力!
發(fā)布過程自動化、自動化代碼管理、自動化測試、自動化安全檢測、自動化部署、自動化監(jiān)控、自動化報警、自動化失效轉(zhuǎn)移、自動化失效恢復(fù)、自動化降級。
性能
奧運精神:更快、更高、更強

技術(shù)人員對于性能的追求是無止境的。
性能,站在不同的角度,衡量指標(biāo)是不一樣的:
用戶視角:響應(yīng)時間,優(yōu)化手段:(瀏覽器優(yōu)化,頁面布局,壓縮文件,http長鏈接),CND,反向代理 開發(fā)人員視角:系統(tǒng)延遲、吞吐量、穩(wěn)定性。優(yōu)化手段:緩存,異步,集群,代碼優(yōu)化 運維視角:基礎(chǔ)設(shè)施性能 資源利用率。優(yōu)化手段:定制骨干網(wǎng)絡(luò)、定制服務(wù)器,虛擬化
常見的衡量標(biāo)準(zhǔn)包括:響應(yīng)時間、吞吐量、并發(fā)量。關(guān)于這些衡量標(biāo)準(zhǔn),文中有一個很好的比喻:
系統(tǒng)吞吐量和系統(tǒng)并發(fā)數(shù), 以及響應(yīng)時間的關(guān)系可以形象地理解為高速公路的通行狀況: 吞吐量是每天通過收費站的車輛數(shù)目(可以換算成收費站收取的高速費) , 并發(fā)數(shù)是高速公路上的正在行駛的車輛數(shù)目,響應(yīng)時間是車速。車輛很少時, 車速很快, 但是收到的高速費也相應(yīng)較少; 隨著高速公路上車輛數(shù)目的增多,車速略受影響,但是收到的高速費增加很快; 隨著車輛的繼續(xù)增加,車速變得越來越慢,高速公路越來越堵,收費不增反降; 如果車流量繼續(xù)增加,超過某個極限后,任何偶然因素都會導(dǎo)致高速全部癱瘓, 車走不動,費當(dāng)然也收不著,而高速公路成了停車場(資源耗盡)。
web前端性能優(yōu)化
瀏覽器優(yōu)化:減少http請求,瀏覽器緩存,壓縮。CDN優(yōu)化,反應(yīng)代理
應(yīng)用服務(wù)器性能優(yōu)化
四招:緩存、集群、異步、代碼優(yōu)化
緩存
首先自然是緩存
網(wǎng)站性能優(yōu)化第一定律: 優(yōu)先考慮使用緩存優(yōu)化性能。
使用緩存,需要考慮的是緩存置換與一致性問題,其中緩存一致性問題也是分布式系統(tǒng)中需要解決的一個問題,主要的解決方法有租期和版本號。
并不是所有的場合都適合緩存,如頻繁修改的數(shù)據(jù)、沒有熱點訪問的數(shù)據(jù)。
緩存的可用性:理論上不能完全依靠,但事實上盡可能高可用,否則數(shù)據(jù)庫宕機導(dǎo)致系統(tǒng)不可用。因此緩存服務(wù)器也要納入監(jiān)控,盡量高可用。
緩存穿透:如果因為不恰當(dāng)?shù)臉I(yè)務(wù)、或者惡意攻擊持續(xù)高并發(fā)地請求某個不存在的數(shù)據(jù),由于緩存沒有保存該數(shù)據(jù), 所有的請求都會落到數(shù)據(jù)庫上,會對數(shù)據(jù)庫造成很大壓力,甚至崩橫。一個簡單的對策是將不存在的數(shù)據(jù)也緩存起來(其value 值為null )。
代碼優(yōu)化
多線程
為什么要使用多線程,IO阻塞 與 多核CPU 理想的load 是:即沒有進程(線程)等待,也沒有CPU空閑 啟動線程數(shù)= [任務(wù)執(zhí)行時間/ (任務(wù)執(zhí)行時間-10 等待時間)J xCPU 內(nèi)核數(shù) 資源復(fù)用
這個很常見,各種池(pool):線程池、連接池
高可用
網(wǎng)站年度可用性指標(biāo)= ( 1-網(wǎng)站不可用時間/年度總時間) x lOO%
業(yè)界通常用N個9來衡量系統(tǒng)的可用性。如,2 個9 是基本可用, 網(wǎng)站年度不可用時間小于8 8 小時; 3 個9是較高可用, 網(wǎng)站年度不可用時間小于9 小時; 4 個9 是具有自動恢復(fù)能力的高可用,網(wǎng)站年度不可用時間小于53 分鐘; 5 個9 是極高可用性,網(wǎng)站年度不可用時間小于5 分鐘。
可用性是大型網(wǎng)站的命脈,是否可用,用戶是可以立刻感知到的,短暫的不可用也會帶來巨大的損失。這也是為什么大型網(wǎng)站在面對CAP問題時,更看重A(avalibility)的原因。
高可用架構(gòu)的主要手段是數(shù)據(jù)和服務(wù)的冗余備份及失效轉(zhuǎn)移。
在分層的網(wǎng)絡(luò)架構(gòu)中,通過保證每一層的高可用,就實現(xiàn)了整個系統(tǒng)的高可用。而每一層又有自己的高可用手段
應(yīng)用層高可用
位于應(yīng)用層的服務(wù)器通常為了應(yīng)對高并發(fā)的訪問請求,會通過負載均衡設(shè)備將一組服務(wù)器組成一個集群共同對外提供服務(wù),當(dāng)負載均衡設(shè)備通過心跳檢測等手段監(jiān)控到某臺應(yīng)用服務(wù)器不可用時,就將其從集群列表中剔除,并將請求分發(fā)到集群中其他可用的服務(wù)器上,使整個集群保持可用,從而實現(xiàn)應(yīng)用高可用。
應(yīng)用層的高可用很容易,因為應(yīng)用服務(wù)器很多時候是無狀態(tài)的。
但是也有時候需要有維護的數(shù)據(jù),如session,這樣就不能將一個請求路由到任意的應(yīng)用服務(wù)器。要解決session的問題,有以下幾種方法:
session綁定:利用負載均衡的源地址Hash 算法實現(xiàn),負載均衡服務(wù)器總是將來源于同一IP 的請求分發(fā)到同一臺服務(wù)器上 用cookie記錄session:Cookie是存放在客戶端(瀏覽器)的,在每次訪問的時候帶上cookie里面的信息即可 專門的session服務(wù)器:將應(yīng)用服務(wù)器的狀態(tài)分離, 分為無狀態(tài)的應(yīng)用服務(wù)器和有狀態(tài)的Session。簡單的方法是利用分布式緩存、數(shù)據(jù)庫(redis)來實現(xiàn)Session服務(wù)器的功能
服務(wù)層的高可用
服務(wù)層的高可用也是利用集群,不過需要借助分布式服務(wù)調(diào)用框架。
服務(wù)層的服務(wù)器被應(yīng)用層通過分布式服務(wù)調(diào)用框架訪問,分布式服務(wù)調(diào)用框架會在應(yīng)用層客戶端程序中實現(xiàn)軟件負載均衡, 并通過服務(wù)注冊中心對提供服務(wù)的服務(wù)器進行心跳檢測,發(fā)現(xiàn)有服務(wù)不可用,立即通知客戶端程序修改服務(wù)訪問列表,剔除不可用的服務(wù)器。
為了保證服務(wù)層的高可用,可以采用以下策略:
分層管理 超時設(shè)置 異步調(diào)用 服務(wù)降級,包括:拒絕服務(wù),高峰時段,拒絕低優(yōu)先級應(yīng)用的訪問;關(guān)閉服務(wù),關(guān)閉某些不重要的功能 冪等性設(shè)計,方便失敗時重試
數(shù)據(jù)層的高可用
包括分布式文件系統(tǒng)與分布式數(shù)據(jù)庫,核心都是冗余加失效轉(zhuǎn)移。
冗余(復(fù)制集、replica)需要解決的核心問題是一致性問題
失效轉(zhuǎn)移操作由三部分組成: 失效確認、訪問轉(zhuǎn)移、數(shù)據(jù)恢復(fù)。
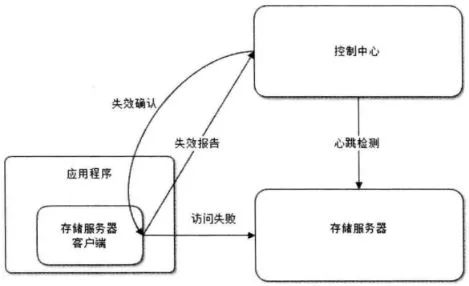
上面描述了失效確認的兩種方法:控制中心通過心跳檢測存儲服務(wù)器的存活性;應(yīng)用在訪問存儲服務(wù)失敗的時候通知控制中心檢測存儲服務(wù)存活性
伸縮性(Scalability)
網(wǎng)站的伸縮性是指不需要改變網(wǎng)站的軟硬件設(shè)計,僅僅通過改變部署的服務(wù)器數(shù)量就可以擴大或者縮小網(wǎng)站的服務(wù)處理能力。
應(yīng)用層的伸縮性
將應(yīng)用層設(shè)計成無狀態(tài),即可利用集群 + 負載均衡來解決伸縮性問題。
關(guān)于負載均衡,我之前也寫過一篇文章《關(guān)于負載均衡的一切:總結(jié)與思考》(http://www.cnblogs.com/xybaby/p/7867735.html)介紹。
緩存的伸縮性
首先,緩存是有狀態(tài)的,分布式緩存服務(wù)器集群中不同服務(wù)器中緩存的數(shù)據(jù)各不相同,緩存訪問請求不可以在緩存服務(wù)器集群中的任意一臺處理,必須先找到緩存有需要數(shù)據(jù)的服務(wù)器,然后才能訪問。
如果緩存訪問被路由到了沒有緩存相關(guān)數(shù)據(jù)的服務(wù)器,那么該訪問請求就會落地到數(shù)據(jù)庫,增加數(shù)據(jù)庫的壓力。因此,必須讓新上線的緩存服務(wù)器對整個分布式緩存集群影響最小,即緩存命中率越高越好。
在這個場景下,最好的負載均衡算法就是一致性hash
數(shù)據(jù)層的伸縮性
關(guān)系型數(shù)據(jù)庫,依賴于分布式數(shù)據(jù)庫代理。而NoSQL數(shù)據(jù)庫產(chǎn)品都放棄了關(guān)系數(shù)據(jù)庫的兩大重要基礎(chǔ): 以關(guān)系代數(shù)為基礎(chǔ)的結(jié)構(gòu)化查詢語言( SQL ) 和事務(wù)一致性保證( AClD )。而強化其他一些大型網(wǎng)站更關(guān)注的特性: 高可用性和可伸縮性。
伸縮性總結(jié):一個具有良好伸縮性架構(gòu)設(shè)計的網(wǎng)站,其設(shè)計總是走在業(yè)務(wù)發(fā)展的前面, 在業(yè)務(wù)需要處理更多訪問和服務(wù)之前,就已經(jīng)做好充足準(zhǔn)備, 當(dāng)業(yè)務(wù)需要時, 只需要購買或者租用服務(wù)器簡單部署實施就可以。
可擴展性(Extensibility)
設(shè)計網(wǎng)站可擴展架構(gòu)的核心思想是模塊化, 并在此基礎(chǔ)之上, 降低模塊間的耦合性,提高模塊的復(fù)用性。
主要有分布式消息隊列和分布式服務(wù)。
分布式消息隊列通過消息對象分解系統(tǒng)耦合性, 不同子系統(tǒng)處理同一個消息。
分布式服務(wù)則通過接口分解系統(tǒng)輯合性, 不同子系統(tǒng)通過相同的接口描述進行服務(wù)調(diào)用。
分布式服務(wù)
縱向拆分:將一個大應(yīng)用拆分為多個小應(yīng)用, 如果新增業(yè)務(wù)較為獨立, 那么就直接將其設(shè)計部署為一個獨立的Web 應(yīng)用系統(tǒng)。
橫向拆分: 將復(fù)用的業(yè)務(wù)拆分出來, 獨立部署為分布式服務(wù), 新增業(yè)務(wù)只需要調(diào)用這些分布式服務(wù), 不需要依賴具體的模塊代碼,即可快速搭建一個應(yīng)用系統(tǒng), 而模塊內(nèi)業(yè)務(wù)邏輯變化的時候, 只要接口保持一致就不會影響業(yè)務(wù)程序和其他模塊。
分布式服務(wù)依賴于分布式服務(wù)治理框架
分布式服務(wù)治理框架
這一塊兒接觸甚少,還需要花點時間專門學(xué)習(xí)學(xué)習(xí)。
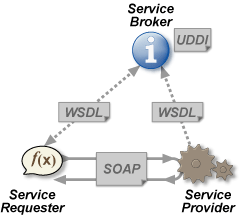
服務(wù)治理框架的功能和特點:
服務(wù)注冊與發(fā)現(xiàn) 服務(wù)調(diào)用 負載均衡 失效轉(zhuǎn)移:分布式服務(wù)框架支持服務(wù)提供者的失效轉(zhuǎn)移機制, 當(dāng)某個服務(wù)實例不可用, 就將訪問切換到其他服務(wù)實例上,以實現(xiàn)服務(wù)整體高可用。 高效遠程通信 整合異構(gòu)系統(tǒng) 對應(yīng)用最小侵入 版本管理:分布式服務(wù)框架需要支持服務(wù)多版本發(fā)布, 服務(wù)提供者先升級接口發(fā)布新版本的服務(wù), 并同時提供舊版本的服務(wù)供請求者調(diào)用, 當(dāng)請求者調(diào)用接口升級后才可以關(guān)閉舊版本服務(wù)。 實時監(jiān)控
Others
所謂問題, 就是體驗一期望,當(dāng)體驗不能滿足期望, 就會覺得出了問題。消除問題有兩種手段:改善休驗或者降低期望。
問題被發(fā)現(xiàn),它只是問題發(fā)現(xiàn)者的問題,而不是問題擁有者的問題,如果想要解決一個問題,就必須提出這個問題,讓問題的擁有者知道問題的存在。
提出問題Tips:
把" 我的問題" 表述成" 我們的問題" 給上司提封閉式問題, 給下屬提開放式問題 指出問題而不是批評人 用贊同的方式提出問題 --》不是說 你這里有問題,而是說,方案不錯,我有一點疑問(建議)