
實(shí)戰(zhàn)總結(jié)!18種接口優(yōu)化方案的總結(jié)

前言
之前工作中,遇到一個(gè)504超時(shí)問(wèn)題。原因是因?yàn)榻涌诤臅r(shí)過(guò)長(zhǎng),超過(guò)nginx配置的10秒。然后 真槍實(shí)彈搞了一次接口性能優(yōu)化,最后接口從11.3s降為170ms。本文將跟小伙伴們分享接口優(yōu)化的一些通用方案。
1. 批量思想:批量操作數(shù)據(jù)庫(kù)
優(yōu)化前:
//for循環(huán)單筆入庫(kù)
for(TransDetail detail:transDetailList){
insert(detail);
}
優(yōu)化后:
batchInsert(transDetailList);
打個(gè)比喻:
打個(gè)比喻:假如你需要搬一萬(wàn)塊磚到樓頂,你有一個(gè)電梯,電梯一次可以放適量的磚(最多放
500), 你可以選擇一次運(yùn)送一塊磚,也可以一次運(yùn)送500,你覺(jué)得哪種方式更方便,時(shí)間消耗更少?
2. 異步思想:耗時(shí)操作,考慮放到異步執(zhí)行
耗時(shí)操作,考慮用異步處理,這樣可以降低接口耗時(shí)。
假設(shè)一個(gè)轉(zhuǎn)賬接口,匹配聯(lián)行號(hào),是同步執(zhí)行的,但是它的操作耗時(shí)有點(diǎn)長(zhǎng),優(yōu)化前的流程:
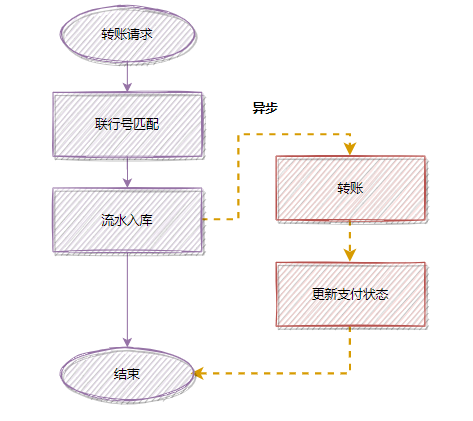
為了降低接口耗時(shí),更快返回,你可以把匹配聯(lián)行號(hào)移到異步處理,優(yōu)化后:
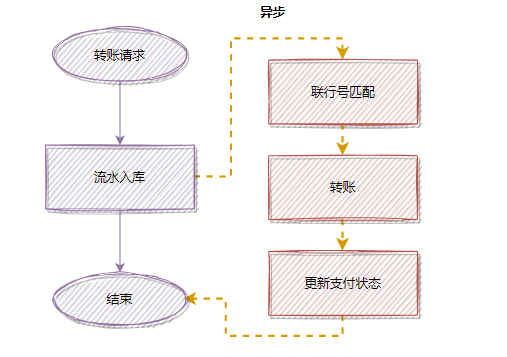
除了轉(zhuǎn)賬這個(gè)例子,日常工作中還有很多這種例子。比如:用戶注冊(cè)成功后,短信郵件通知,也是可以異步處理的~ 至于異步的實(shí)現(xiàn)方式,你可以用線程池,也可以用消息隊(duì)列實(shí)現(xiàn)。
3. 空間換時(shí)間思想:恰當(dāng)使用緩存。
在適當(dāng)?shù)臉I(yè)務(wù)場(chǎng)景,恰當(dāng)?shù)厥褂镁彺妫强梢源蟠筇岣呓涌谛阅艿摹>彺嫫鋵?shí)就是一種空間換時(shí)間的思想,就是你把要查的數(shù)據(jù),提前放好到緩存里面,需要時(shí),直接查緩存,而避免去查數(shù)據(jù)庫(kù)或者計(jì)算的過(guò)程。
這里的緩存包括:Redis緩存,JVM本地緩存,memcached,或者Map等等。我舉個(gè)我工作中,一次使用緩存優(yōu)化的設(shè)計(jì)吧,比較簡(jiǎn)單,但是思路很有借鑒的意義。
那是一次轉(zhuǎn)賬接口的優(yōu)化,老代碼,每次轉(zhuǎn)賬,都會(huì)根據(jù)客戶賬號(hào),查詢數(shù)據(jù)庫(kù),計(jì)算匹配聯(lián)行號(hào)。
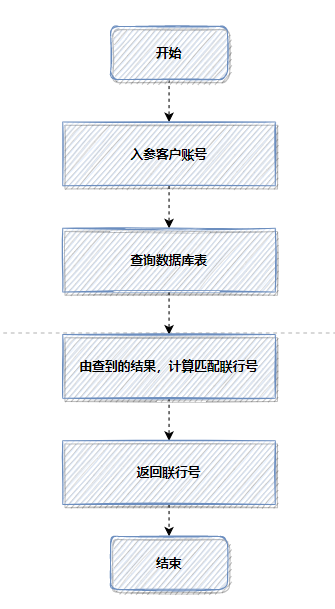
因?yàn)槊看?strong style="outline: 0px;">都查數(shù)據(jù)庫(kù),都計(jì)算匹配,比較耗時(shí),所以使用緩存,優(yōu)化后流程如下:
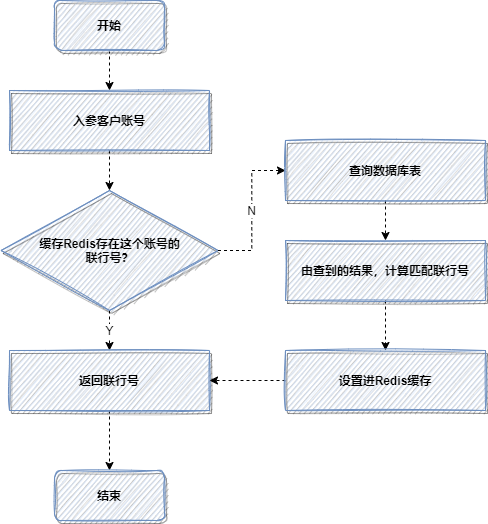
4. 預(yù)取思想:提前初始化到緩存
預(yù)取思想很容易理解,就是提前把要計(jì)算查詢的數(shù)據(jù),初始化到緩存。如果你在未來(lái)某個(gè)時(shí)間需要用到某個(gè)經(jīng)過(guò)復(fù)雜計(jì)算的數(shù)據(jù),才實(shí)時(shí)去計(jì)算的話,可能耗時(shí)比較大。這時(shí)候,我們可以采取預(yù)取思想,提前把將來(lái)可能需要的數(shù)據(jù)計(jì)算好,放到緩存中,等需要的時(shí)候,去緩存取就行。這將大幅度提高接口性能。
我記得以前在第一個(gè)公司做視頻直播的時(shí)候,看到我們的直播列表就是用到這種優(yōu)化方案。就是啟動(dòng)個(gè)任務(wù),提前把直播用戶、積分等相關(guān)信息,初始化到緩存。
5. 池化思想:預(yù)分配與循環(huán)使用
大家應(yīng)該都記得,我們?yōu)槭裁葱枰褂镁€程池?
線程池可以幫我們管理線程,避免增加創(chuàng)建線程和銷毀線程的資源損耗。
如果你每次需要用到線程,都去創(chuàng)建,就會(huì)有增加一定的耗時(shí),而線程池可以重復(fù)利用線程,避免不必要的耗時(shí)。 池化技術(shù)不僅僅指線程池,很多場(chǎng)景都有池化思想的體現(xiàn),它的本質(zhì)就是預(yù)分配與循環(huán)使用。
比如TCP三次握手,大家都很熟悉吧,它為了減少性能損耗,引入了Keep-Alive長(zhǎng)連接,避免頻繁的創(chuàng)建和銷毀連接。當(dāng)然,類似的例子還有很多,如數(shù)據(jù)庫(kù)連接池、HttpClient連接池。
我們寫代碼的過(guò)程中,學(xué)會(huì)池化思想,最直接相關(guān)的就是使用線程池而不是去new一個(gè)線程。
6. 事件回調(diào)思想:拒絕阻塞等待。
如果你調(diào)用一個(gè)系統(tǒng)B的接口,但是它處理業(yè)務(wù)邏輯,耗時(shí)需要10s甚至更多。然后你是一直阻塞等待,直到系統(tǒng)B的下游接口返回,再繼續(xù)你的下一步操作嗎?這樣顯然不合理。
我們參考IO多路復(fù)用模型。即我們不用阻塞等待系統(tǒng)B的接口,而是先去做別的操作。等系統(tǒng)B的接口處理完,通過(guò)事件回調(diào)通知,我們接口收到通知再進(jìn)行對(duì)應(yīng)的業(yè)務(wù)操作即可。
7. 遠(yuǎn)程調(diào)用由串行改為并行
假設(shè)我們?cè)O(shè)計(jì)一個(gè)APP首頁(yè)的接口,它需要查用戶信息、需要查banner信息、需要查彈窗信息等等。如果是串行一個(gè)一個(gè)查,比如查用戶信息200ms,查banner信息100ms、查彈窗信息50ms,那一共就耗時(shí)350ms了,如果還查其他信息,那耗時(shí)就更大了。
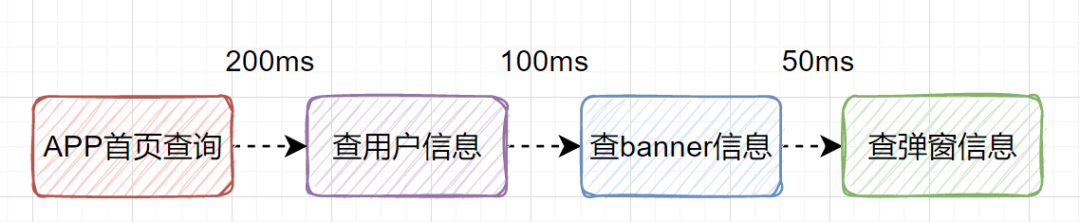
其實(shí)我們可以改為并行調(diào)用,即查用戶信息、查banner信息、查彈窗信息,可以同時(shí)并行發(fā)起。
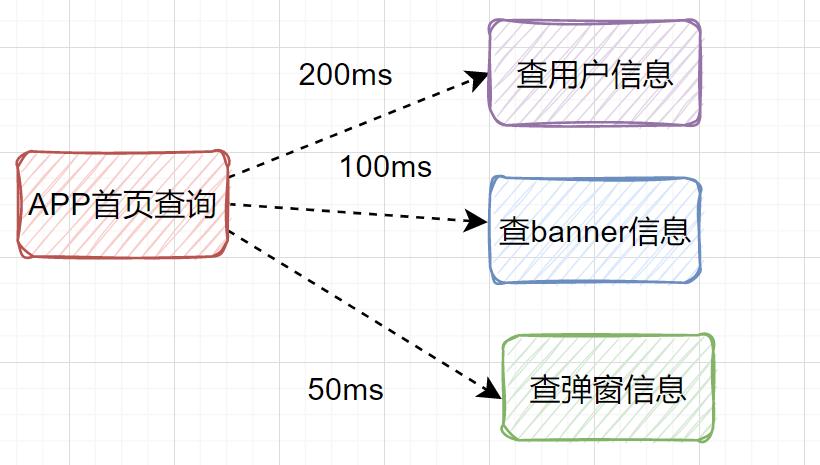
最后接口耗時(shí)將大大降低。有些小伙伴說(shuō),不知道如何使用并行優(yōu)化接口?
8. 鎖粒度避免過(guò)粗
在高并發(fā)場(chǎng)景,為了防止超賣等情況,我們經(jīng)常需要加鎖來(lái)保護(hù)共享資源。但是,如果加鎖的粒度過(guò)粗,是很影響接口性能的。
什么是加鎖粒度呢?
其實(shí)就是就是你要鎖住的范圍是多大。比如你在家上衛(wèi)生間,你只要鎖住衛(wèi)生間就可以了吧,不需要將整個(gè)家都鎖起來(lái)不讓家人進(jìn)門吧,衛(wèi)生間就是你的加鎖粒度。
不管你是synchronized加鎖還是redis分布式鎖,只需要在共享臨界資源加鎖即可,不涉及共享資源的,就不必要加鎖。這就好像你上衛(wèi)生間,不用把整個(gè)家都鎖住,鎖住衛(wèi)生間門就可以了。
比如,在業(yè)務(wù)代碼中,有一個(gè)ArrayList因?yàn)樯婕暗蕉嗑€程操作,所以需要加鎖操作,假設(shè)剛好又有一段比較耗時(shí)的操作(代碼中的slowNotShare方法)不涉及線程安全問(wèn)題。反例加鎖,就是一鍋端,全鎖住:
//不涉及共享資源的慢方法
private void slowNotShare() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
}
}
//錯(cuò)誤的加鎖方法
public int wrong() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
//加鎖粒度太粗了,slowNotShare其實(shí)不涉及共享資源
synchronized (this) {
slowNotShare();
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
正例:
public int right() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
slowNotShare();//可以不加鎖
//只對(duì)List這部分加鎖
synchronized (data) {
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
9. 切換存儲(chǔ)方式:文件中轉(zhuǎn)暫存數(shù)據(jù)
如果數(shù)據(jù)太大,落地?cái)?shù)據(jù)庫(kù)實(shí)在是慢的話,就可以考慮先用文件的方式暫存。先保存文件,再異步下載文件,慢慢保存到數(shù)據(jù)庫(kù)。
這里可能會(huì)有點(diǎn)抽象,給大家分享一個(gè),我之前的一個(gè)真實(shí)的優(yōu)化案例吧。
之前開(kāi)發(fā)了一個(gè)轉(zhuǎn)賬接口。如果是并發(fā)開(kāi)啟,10個(gè)并發(fā)度,每個(gè)批次
1000筆轉(zhuǎn)賬明細(xì)數(shù)據(jù),數(shù)據(jù)庫(kù)插入會(huì)特別耗時(shí),大概6秒左右;這個(gè)跟我們公司的數(shù)據(jù)庫(kù)同步機(jī)制有關(guān),并發(fā)情況下,因?yàn)閮?yōu)先保證同步,所以并行的插入變成串行啦,就很耗時(shí)。
優(yōu)化前,1000筆明細(xì)轉(zhuǎn)賬數(shù)據(jù),先落地DB數(shù)據(jù)庫(kù),返回處理中給用戶,再異步轉(zhuǎn)賬。如圖:
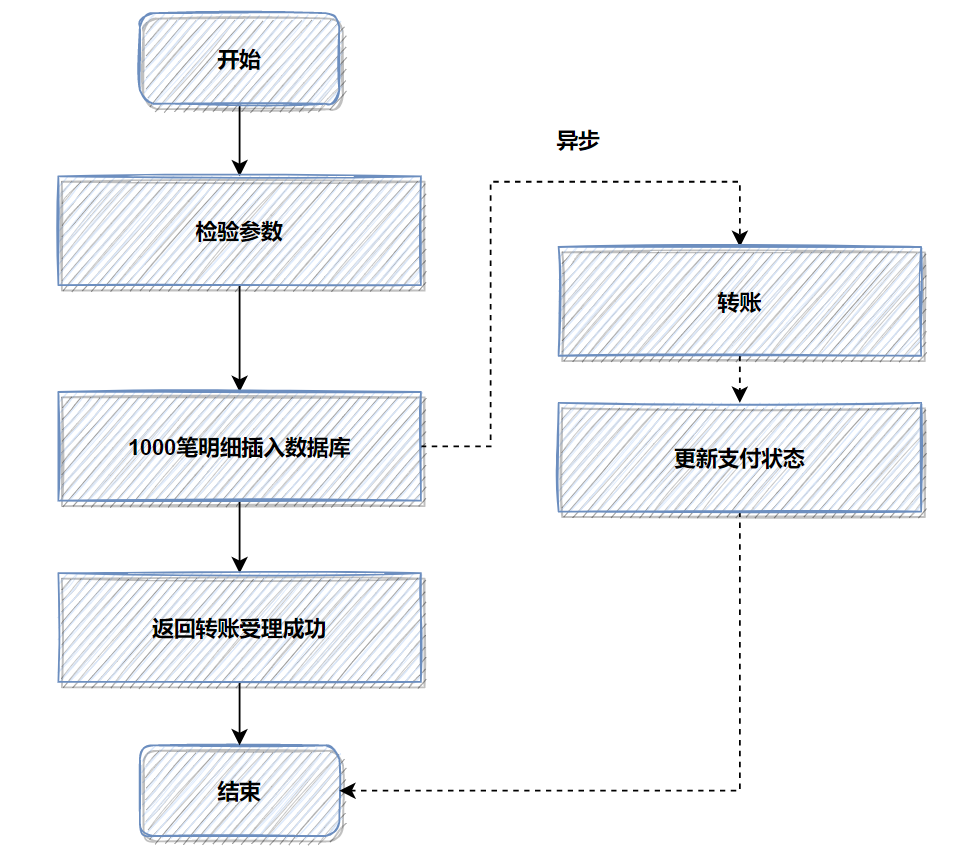
記得當(dāng)時(shí)壓測(cè)的時(shí)候,高并發(fā)情況,這1000筆明細(xì)入庫(kù),耗時(shí)都比較大。所以我轉(zhuǎn)換了一下思路,把批量的明細(xì)轉(zhuǎn)賬記錄保存的文件服務(wù)器,然后記錄一筆轉(zhuǎn)賬總記錄到數(shù)據(jù)庫(kù)即可。接著異步再把明細(xì)下載下來(lái),進(jìn)行轉(zhuǎn)賬和明細(xì)入庫(kù)。最后優(yōu)化后,性能提升了十幾倍。
優(yōu)化后,流程圖如下:
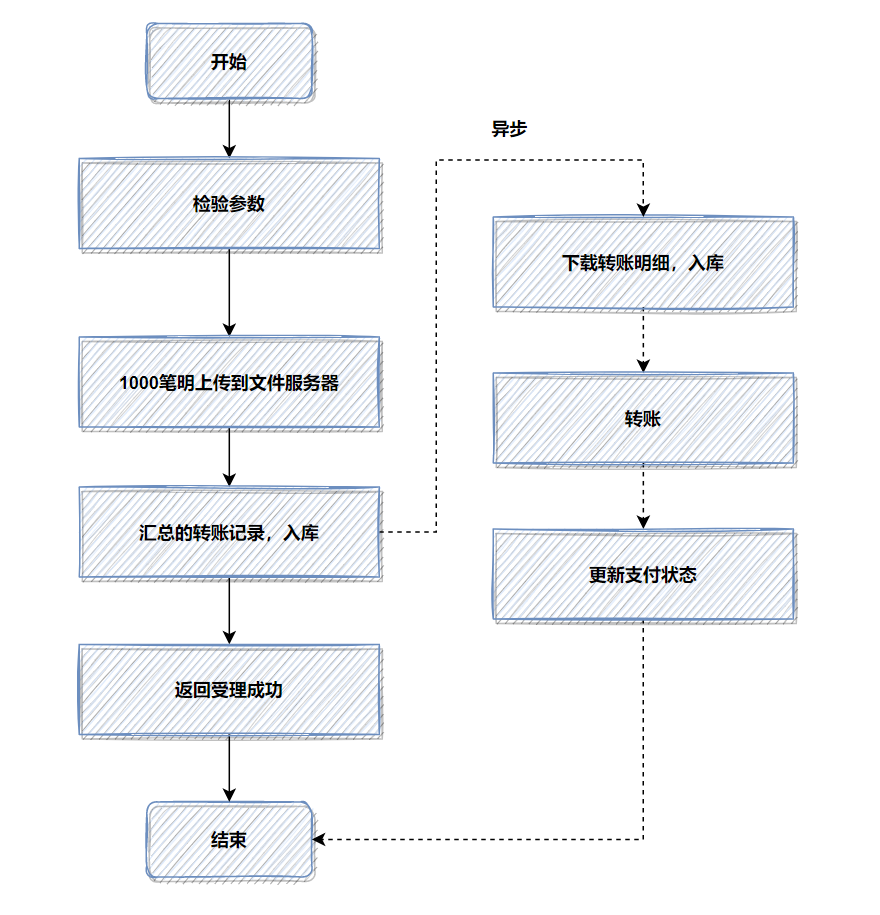
如果你的接口耗時(shí)瓶頸就在數(shù)據(jù)庫(kù)插入操作這里,用來(lái)批量操作等,還是效果還不理想,就可以考慮用文件或者MQ等暫存。有時(shí)候批量數(shù)據(jù)放到文件,會(huì)比插入數(shù)據(jù)庫(kù)效率更高。
10. 索引
提到接口優(yōu)化,很多小伙伴都會(huì)想到添加索引。沒(méi)錯(cuò),添加索引是成本最小的優(yōu)化,而且一般優(yōu)化效果都很不錯(cuò)。
索引優(yōu)化這塊的話,一般從這幾個(gè)維度去思考:
你的SQL加索引了沒(méi)? 你的索引是否真的生效? 你的索引建立是否合理?
10.1 SQL沒(méi)加索引
我們開(kāi)發(fā)的時(shí)候,容易疏忽而忘記給SQL添加索引。所以我們?cè)趯懲?code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">SQL的時(shí)候,就順手查看一下 explain執(zhí)行計(jì)劃。
explain select * from user_info where userId like '%123';
你也可以通過(guò)命令show create table ,整張表的索引情況。
show create table user_info;
如果某個(gè)表忘記添加某個(gè)索引,可以通過(guò)alter table add index命令添加索引
alter table user_info add index idx_name (name);
一般就是:SQL的where條件的字段,或者是order by 、group by后面的字段需需要添加索引。
10.2 索引不生效
有時(shí)候,即使你添加了索引,但是索引會(huì)失效的。田螺哥整理了索引失效的常見(jiàn)原因:
10.3 索引設(shè)計(jì)不合理
我們的索引不是越多越好,需要合理設(shè)計(jì)。比如:
刪除冗余和重復(fù)索引。 索引一般不能超過(guò) 5個(gè)索引不適合建在有大量重復(fù)數(shù)據(jù)的字段上、如性別字段 適當(dāng)使用覆蓋索引 如果需要使用 force index強(qiáng)制走某個(gè)索引,那就需要思考你的索引設(shè)計(jì)是否真的合理了
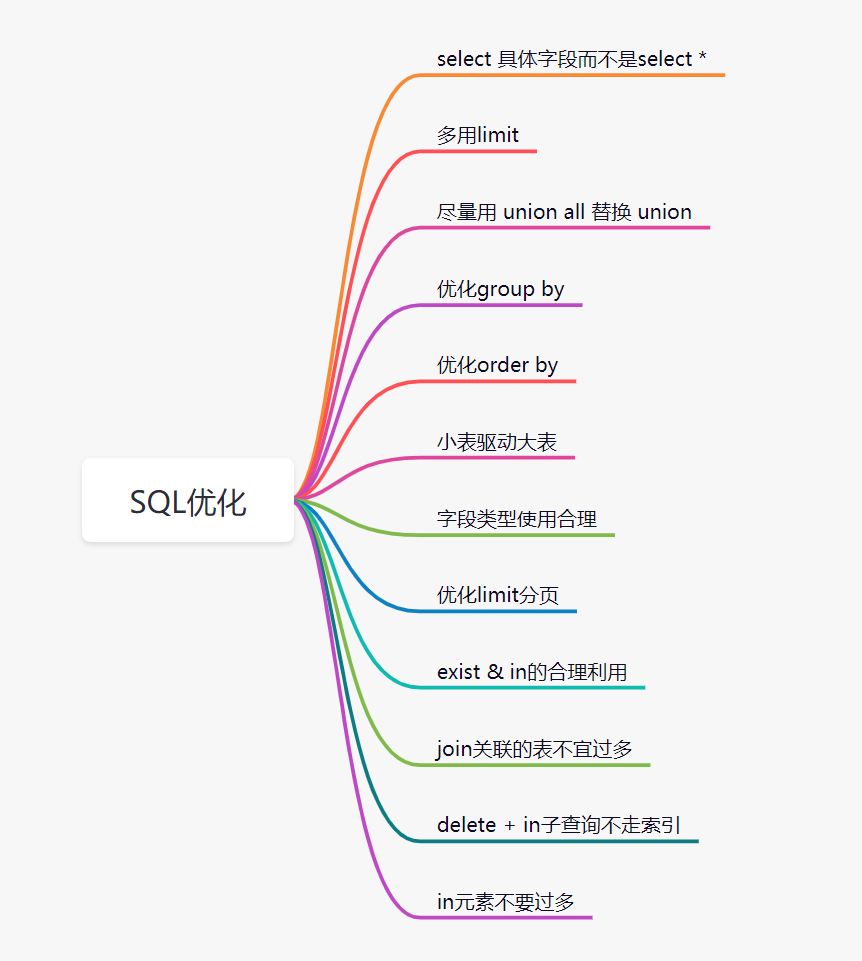
11. 優(yōu)化SQL
處了索引優(yōu)化,其實(shí)SQL還有很多其他有優(yōu)化的空間。比如這些:
12.避免大事務(wù)問(wèn)題
為了保證數(shù)據(jù)庫(kù)數(shù)據(jù)的一致性,在涉及到多個(gè)數(shù)據(jù)庫(kù)修改操作時(shí),我們經(jīng)常需要用到事務(wù)。而使用spring聲明式事務(wù),又非常簡(jiǎn)單,只需要用一個(gè)注解就行@Transactional,如下面的例子:
@Transactional
public int createUser(User user){
//保存用戶信息
userDao.save(user);
passCertDao.updateFlag(user.getPassId());
return user.getUserId();
}
這塊代碼主要邏輯就是創(chuàng)建個(gè)用戶,然后更新一個(gè)通行證pass的標(biāo)記。如果現(xiàn)在新增一個(gè)需求,創(chuàng)建完用戶,調(diào)用遠(yuǎn)程接口發(fā)送一個(gè)email消息通知,很多小伙伴會(huì)這么寫:
@Transactional
public int createUser(User user){
//保存用戶信息
userDao.save(user);
passCertDao.updateFlag(user.getPassId());
sendEmailRpc(user.getEmail());
return user.getUserId();
}
這樣實(shí)現(xiàn)可能會(huì)有坑,事務(wù)中嵌套RPC遠(yuǎn)程調(diào)用,即事務(wù)嵌套了一些非DB操作。如果這些非DB操作耗時(shí)比較大的話,可能會(huì)出現(xiàn)大事務(wù)問(wèn)題。
所謂大事務(wù)問(wèn)題就是,就是運(yùn)行時(shí)間長(zhǎng)的事務(wù)。由于事務(wù)一致不提交,就會(huì)導(dǎo)致數(shù)據(jù)庫(kù)連接被占用,即并發(fā)場(chǎng)景下,數(shù)據(jù)庫(kù)連接池被占滿,影響到別的請(qǐng)求訪問(wèn)數(shù)據(jù)庫(kù),影響別的接口性能。
大事務(wù)引發(fā)的問(wèn)題主要有:接口超時(shí)、死鎖、主從延遲等等。因此,為了優(yōu)化接口,我們要規(guī)避大事務(wù)問(wèn)題。我們可以通過(guò)這些方案來(lái)規(guī)避大事務(wù):
RPC遠(yuǎn)程調(diào)用不要放到事務(wù)里面 一些查詢相關(guān)的操作,盡量放到事務(wù)之外 事務(wù)中避免處理太多數(shù)據(jù)
13. 深分頁(yè)問(wèn)題
在以前公司分析過(guò)幾個(gè)接口耗時(shí)長(zhǎng)的問(wèn)題,最終結(jié)論都是因?yàn)?strong style="outline: 0px;">深分頁(yè)問(wèn)題。
深分頁(yè)問(wèn)題,為什么會(huì)慢?我們看下這個(gè)SQL
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
limit 100000,10意味著會(huì)掃描100010行,丟棄掉前100000行,最后返回10行。即使create_time,也會(huì)回表很多次。
我們可以通過(guò)標(biāo)簽記錄法和延遲關(guān)聯(lián)法來(lái)優(yōu)化深分頁(yè)問(wèn)題。
13.1 標(biāo)簽記錄法
就是標(biāo)記一下上次查詢到哪一條了,下次再來(lái)查的時(shí)候,從該條開(kāi)始往下掃描。就好像看書一樣,上次看到哪里了,你就折疊一下或者夾個(gè)書簽,下次來(lái)看的時(shí)候,直接就翻到啦。
假設(shè)上一次記錄到100000,則SQL可以修改為:
select id,name,balance FROM account where id > 100000 limit 10;
這樣的話,后面無(wú)論翻多少頁(yè),性能都會(huì)不錯(cuò)的,因?yàn)槊辛?code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);">id主鍵索引。但是這種方式有局限性:需要一種類似連續(xù)自增的字段。
13.2 延遲關(guān)聯(lián)法
延遲關(guān)聯(lián)法,就是把條件轉(zhuǎn)移到主鍵索引樹(shù),然后減少回表。優(yōu)化后的SQL如下:
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
優(yōu)化思路就是,先通過(guò)idx_create_time二級(jí)索引樹(shù)查詢到滿足條件的主鍵ID,再與原表通過(guò)主鍵ID內(nèi)連接,這樣后面直接走了主鍵索引了,同時(shí)也減少了回表。
14. 優(yōu)化程序結(jié)構(gòu)
優(yōu)化程序邏輯、程序代碼,是可以節(jié)省耗時(shí)的。比如,你的程序創(chuàng)建多不必要的對(duì)象、或者程序邏輯混亂,多次重復(fù)查數(shù)據(jù)庫(kù)、又或者你的實(shí)現(xiàn)邏輯算法不是最高效的,等等。
我舉個(gè)簡(jiǎn)單的例子:復(fù)雜的邏輯條件,有時(shí)候調(diào)整一下順序,就能讓你的程序更加高效。
假設(shè)業(yè)務(wù)需求是這樣:如果用戶是會(huì)員,第一次登陸時(shí),需要發(fā)一條感謝短信。如果沒(méi)有經(jīng)過(guò)思考,代碼直接這樣寫了
if(isUserVip && isFirstLogin){
sendSmsMsg();
}
假設(shè)有5個(gè)請(qǐng)求過(guò)來(lái),isUserVip判斷通過(guò)的有3個(gè)請(qǐng)求,isFirstLogin通過(guò)的只有1個(gè)請(qǐng)求。那么以上代碼,isUserVip執(zhí)行的次數(shù)為5次,isFirstLogin執(zhí)行的次數(shù)也是3次,如下:

如果調(diào)整一下isUserVip和isFirstLogin的順序:
if(isFirstLogin && isUserVip ){
sendMsg();
}
isFirstLogin執(zhí)行的次數(shù)是5次,isUserVip執(zhí)行的次數(shù)是1次:

醬紫程序是不是變得更高效了呢?
15. 壓縮傳輸內(nèi)容
壓縮傳輸內(nèi)容,傳輸報(bào)文變得更小,因此傳輸會(huì)更快啦。10M帶寬,傳輸10k的報(bào)文,一般比傳輸1M的會(huì)快呀。
打個(gè)比喻,一匹千里馬,它馱著100斤的貨跑得快,還是馱著10斤的貨物跑得快呢?
再舉個(gè)視頻網(wǎng)站的例子:
如果不對(duì)視頻做任何壓縮編碼,因?yàn)閹捰质怯邢薜摹?strong style="outline: 0px;">巨大的數(shù)據(jù)量在網(wǎng)絡(luò)傳輸?shù)暮臅r(shí)會(huì)比編碼壓縮后,慢好多倍。
16. 海量數(shù)據(jù)處理,考慮NoSQL
之前看過(guò)幾個(gè)慢SQL,都是跟深分頁(yè)問(wèn)題有關(guān)的。發(fā)現(xiàn)用來(lái)標(biāo)簽記錄法和延遲關(guān)聯(lián)法,效果不是很明顯,原因是要統(tǒng)計(jì)和模糊搜索,并且統(tǒng)計(jì)的數(shù)據(jù)是真的大。最后跟組長(zhǎng)對(duì)齊方案,就把數(shù)據(jù)同步到Elasticsearch,然后這些模糊搜索需求,都走Elasticsearch去查詢了。
我想表達(dá)的就是,如果數(shù)據(jù)量過(guò)大,一定要用關(guān)系型數(shù)據(jù)庫(kù)存儲(chǔ)的話,就可以分庫(kù)分表。但是有時(shí)候,我們也可以使用NoSQL,如Elasticsearch、Hbase等。
17. 線程池設(shè)計(jì)要合理
我們使用線程池,就是讓任務(wù)并行處理,更高效地完成任務(wù)。但是有時(shí)候,如果線程池設(shè)計(jì)不合理,接口執(zhí)行效率則不太理想。
一般我們需要關(guān)注線程池的這幾個(gè)參數(shù):核心線程、最大線程數(shù)量、阻塞隊(duì)列。
如果核心線程過(guò)小,則達(dá)不到很好的并行效果。 如果阻塞隊(duì)列不合理,不僅僅是阻塞的問(wèn)題,甚至可能會(huì) OOM如果線程池不區(qū)分業(yè)務(wù)隔離,有可能核心業(yè)務(wù)被邊緣業(yè)務(wù)拖垮。
大家可以看下我之前兩篇有關(guān)于線程池的文章:
18.機(jī)器問(wèn)題 (fullGC、線程打滿、太多IO資源沒(méi)關(guān)閉等等)。
有時(shí)候,我們的接口慢,就是機(jī)器處理問(wèn)題。主要有fullGC、線程打滿、太多IO資源沒(méi)關(guān)閉等等。
之前排查過(guò)一個(gè) fullGC問(wèn)題:運(yùn)營(yíng)小姐姐導(dǎo)出60多萬(wàn)的excel的時(shí)候,說(shuō)卡死了,接著我們就收到監(jiān)控告警。后面排查得出,我們老代碼是Apache POI生成的excel,導(dǎo)出excel數(shù)據(jù)量很大時(shí),當(dāng)時(shí)JVM內(nèi)存吃緊會(huì)直接Full GC了。如果線程打滿了,也會(huì)導(dǎo)致接口都在等待了。所以。如果是高并發(fā)場(chǎng)景,我們需要接入限流,把多余的請(qǐng)求拒絕掉。 如果IO資源沒(méi)關(guān)閉,也會(huì)導(dǎo)致耗時(shí)增加。這個(gè)大家可以看下,平時(shí)你的電腦一直打開(kāi)很多很多文件,是不是會(huì)覺(jué)得很卡。