
老司機總結的12條 SQL 優(yōu)化方案(非常實用)
減少 try-catch ,這樣做才叫優(yōu)雅! 讓人上癮的新一代開發(fā)神器,徹底告別Controller、Service、Dao等方法 SpringBoot實現(xiàn)人臉識別功能 相信我,使用 Stream 真的可以讓代碼更優(yōu)雅! 全網(wǎng)最詳細的線程池 ThreadPoolExecutor 解讀! 利用多線程批量拆分 List 導入數(shù)據(jù)庫,效率杠杠的!
文章目錄
一、SQL語句及索引的優(yōu)化
SQL語句的優(yōu)化
盡量避免使用子查詢 用IN來替換OR 讀取適當?shù)挠涗汱IMIT M,N,而不要讀多余的記錄 禁止不必要的Order By排序 總和查詢可以禁止排重用union all 避免隨機取記錄 將多次插入換成批量Insert插入 只返回必要的列,用具體的字段列表代替 select * 語句 區(qū)分in和exists 優(yōu)化Group By語句 盡量使用數(shù)字型字段 優(yōu)化Join語句
索引的優(yōu)化/如何避免索引失效
二、數(shù)據(jù)庫表結構的優(yōu)化:使得數(shù)據(jù)庫結構符合三大范式與BCNF
三、系統(tǒng)配置的優(yōu)化
四、硬件的優(yōu)化
在開始介紹如何優(yōu)化sql前,先附上mysql內部邏輯圖讓大家有所了解
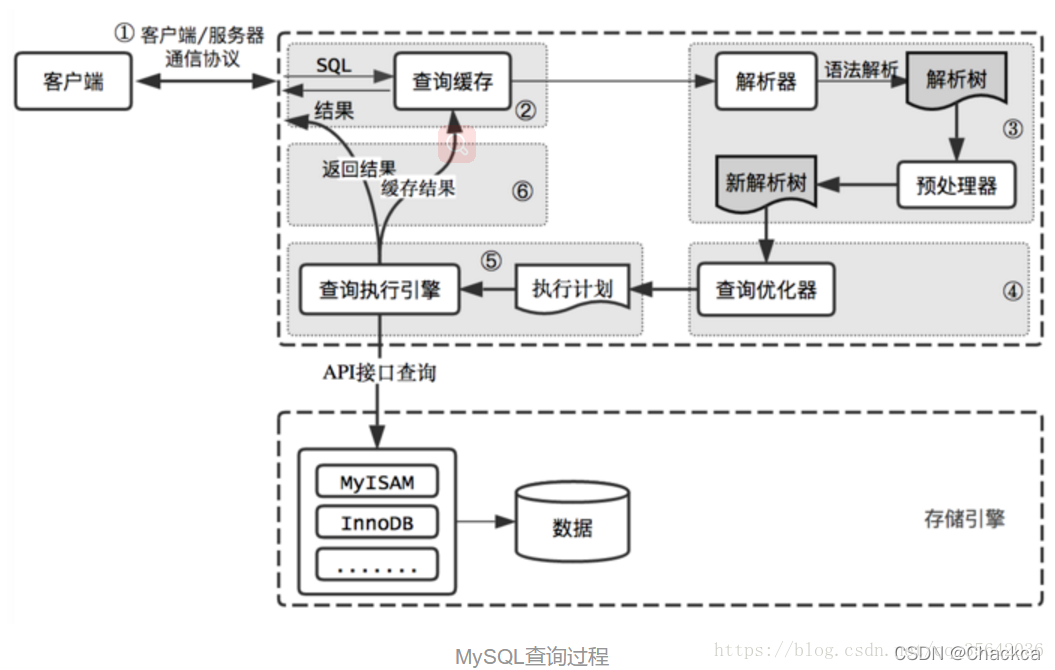
(1)連接器: 主要負責跟客戶端建立連接、獲取權限、維持和管理連接
(2)查詢緩存: 優(yōu)先在緩存中進行查詢,如果查到了則直接返回,如果緩存中查詢不到,在去數(shù)據(jù)庫中查詢。
MySQL緩存是默認關閉的,也就是說不推薦使用緩存,并且在MySQL8.0 版本已經(jīng)將查詢緩存的整塊功能刪掉了。這主要是它的使用場景限制造成的:
先說下緩存中數(shù)據(jù)存儲格式:key(sql語句)- value(數(shù)據(jù)值),所以如果SQL語句(key)只要存在一點不同之處就會直接進行數(shù)據(jù)庫查詢了; 由于表中的數(shù)據(jù)不是一成不變的,大多數(shù)是經(jīng)常變化的,而當數(shù)據(jù)庫中的數(shù)據(jù)變化了,那么相應的與此表相關的緩存數(shù)據(jù)就需要移除掉;
(3)解析器/分析器: 分析器的工作主要是對要執(zhí)行的SQL語句進行詞法解析、語法解析,最終得到抽象語法樹,然后再使用預處理器對抽象語法樹進行語義校驗,判斷抽象語法樹中的表是否存在,如果存在的話,在接著判斷select投影列字段是否在表中存在等。
(4)優(yōu)化器: 主要將SQL經(jīng)過詞法解析、語法解析后得到的語法樹,通過數(shù)據(jù)字典和統(tǒng)計信息的內容,再經(jīng)過一系列運算 ,最終得出一個執(zhí)行計劃,包括選擇使用哪個索引
在分析是否走索引查詢時,是通過進行動態(tài)數(shù)據(jù)采樣統(tǒng)計分析出來;只要是統(tǒng)計分析出來的,那就可能會存在分析錯誤的情況,所以在SQL執(zhí)行不走索引時,也要考慮到這方面的因素
(5)執(zhí)行器: 根據(jù)一系列的執(zhí)行計劃去調用存儲引擎提供的API接口去調用操作數(shù)據(jù),完成SQL的執(zhí)行。
一、SQL語句及索引的優(yōu)化
SQL語句的優(yōu)化
1. 盡量避免使用子查詢
例:
SELECT * FROM t1 WHERE id (SELECT id FROM t2 WHERE name = 'chackca');
其子查詢在Mysql5.5版本里,內部執(zhí)行計劃是這樣:先查外表再匹配內表,而不是先查內表t2,當外表的數(shù)據(jù)很大時,查詢速度會非常慢。
在MariaDB10/Mysql5.6版本里,采用join關聯(lián)方式對其進行了優(yōu)化,這條SQL語句會自動轉換為:SELECT t1.* FROM t1 JOIN t2 on t1.id = t2.id
但請注意的是:優(yōu)化只針對SELECT有效,對UPDATE/DELETE子查詢無效,固生產環(huán)境應避免使用子查詢
由于MySQL的優(yōu)化器對于子查詢的處理能力比較弱,所以不建議使用子查詢,可以改寫成Inner Join,之所以 join 連接效率更高,是因為 MySQL不需要在內存中創(chuàng)建臨時表
2. 用IN來替換OR
低效查詢: SELECT * FROM t WHERE id = 10 OR id = 20 OR id = 30;高效查詢:S ELECT * FROM t WHERE id IN (10,20,30);
另外,MySQL對于IN做了相應的優(yōu)化,即將IN中的常量全部存儲在一個數(shù)組里面,而且這個數(shù)組是排好序的。但是如果數(shù)值較多,產生的消耗也是比較大的。再例如:select id from table_name where num in(1,2,3) 對于連續(xù)的數(shù)值,能用 between 就不要用 in 了;再或者使用連接來替換。
3. 讀取適當?shù)挠涗汱IMIT M,N,而不要讀多余的記錄
select id,name from t limit 866613, 20
使用上述sql語句做分頁的時候,可能有人會發(fā)現(xiàn),隨著表數(shù)據(jù)量的增加,直接使用limit分頁查詢會越來越慢。
對于 limit m, n 的分頁查詢,越往后面翻頁(即m越大的情況下)SQL的耗時會越來越長,對于這種應該先取出主鍵id,然后通過主鍵id跟原表進行Join關聯(lián)查詢。因為MySQL 并不是跳過 offset 行,而是取 offset+N 行,然后放棄前 offset 行,返回 N 行,那當 offset 特別大的時候,效率就非常的低下,要么控制返回的總頁數(shù),要么對超過特定閾值的頁數(shù)進行 SQL 改寫。
優(yōu)化的方法如下:可以取前一頁的最大行數(shù)的id(將上次遍歷到的最末尾的數(shù)據(jù)ID傳給數(shù)據(jù)庫,然后直接定位到該ID處,再往后面遍歷數(shù)據(jù)),然后根據(jù)這個最大的id來限制下一頁的起點。比如此列中,上一頁最大的id是866612。sql可以采用如下的寫法:
select id,name from table_name where id> 866612 limit 20
4. 禁止不必要的Order By排序
如果我們對結果沒有排序的要求,就盡量少用排序;
如果排序字段沒有用到索引,也盡量少用排序;
另外,分組統(tǒng)計查詢時可以禁止其默認排序
SELECT goods_id,count(*) FROM t GROUP BY goods_id;
默認情況下,Mysql會對所有的GROUP BT col1,col2…的字段進行排序,也就是說上述會對 goods_id進行排序,如果想要避免排序結果的消耗,可以指定ORDER BY NULL禁止排序:
SELECT goods_id,count(*) FROM t GROUP BY goods_id ORDER BY NULL
5. 總和查詢可以禁止排重用union all
union和union all的差異主要是前者需要將結果集合并后再進行唯一性過濾操作,這就會涉及到排序,增加大量的CPU運算,加大資源消耗及延遲。
當然,union all的前提條件是兩個結果集沒有重復數(shù)據(jù)。所以一般是我們明確知道不會出現(xiàn)重復數(shù)據(jù)的時候才建議使用 union all 提高速度。
6. 避免隨機取記錄
SELECT * FROM t1 WHERE 1 = 1 ORDER BY RAND() LIMIT 4;
SELECT * FROM t1 WHERE id >= CEIL(RAND()*1000) LIMIT 4;
以上兩個語句都無法用到索引
7. 將多次插入換成批量Insert插入
INSERT INTO t(id, name) VALUES(1, 'aaa');
INSERT INTO t(id, name) VALUES(2, 'bbb');
INSERT INTO t(id, name) VALUES(3, 'ccc');
—>
INSERT INTO t(id, name) VALUES(1, 'aaa'),(2, 'bbb'),(3, 'ccc');
8. 只返回必要的列,用具體的字段列表代替 select * 語句
SELECT * 會增加很多不必要的消耗(cpu、io、內存、網(wǎng)絡帶寬);增加了使用覆蓋索引的可能性;當表結構發(fā)生改變時,前者也需要經(jīng)常更新。所以要求直接在select后面接上字段名。
MySQL數(shù)據(jù)庫是按照行的方式存儲,而數(shù)據(jù)存取操作都是以一個頁大小進行IO操作的,每個IO單元中存儲了多行,每行都是存儲了該行的所有字段。所以無論取一個字段還是多個字段,實際上數(shù)據(jù)庫在表中需要訪問的數(shù)據(jù)量其實是一樣的。
但是如果查詢的字段都在索引中,也就是覆蓋索引,那么可以直接從索引中獲取對應的內容直接返回,不需要進行回表,減少IO操作。除此之外,當存在 order by 操作的時候,select 子句中的字段多少會在很大程度上影響到我們的排序效率。
9. 區(qū)分in和exists
select * from 表A where id in (select id from 表B)
上面的語句相當于:
select * from 表A where exists(select * from 表B where 表B.id=表A.id)
區(qū)分in和exists主要是造成了驅動順序的改變(這是性能變化的關鍵),如果是exists,那么以外層表為驅動表,先被訪問,如果是IN,那么先執(zhí)行子查詢。所以IN適合于外表大而內表小的情況;EXISTS適合于外表小而內表大的情況。
另外,in查詢在某些情況下有可能會查詢返回錯誤的結果,因此,通常是建議在確定且有限的集合時,可以使用in。如 IN (0,1,2)。
10. 優(yōu)化Group By語句
如果對group by語句的結果沒有排序要求,要在語句后面加 order by null(group 默認會排序);
盡量讓group by過程用上表的索引,確認方法是explain結果里沒有Using temporary 和 Using filesort;
如果group by需要統(tǒng)計的數(shù)據(jù)量不大,盡量只使用內存臨時表;也可以通過適當調大tmp_table_size參數(shù),來避免用到磁盤臨時表;
如果數(shù)據(jù)量實在太大,使用 SQL_BIG_RESULT這個提示,來告訴優(yōu)化器直接使用排序算法(直接用磁盤臨時表)得到group by的結果。
使用where子句替換Having子句:避免使用having子句,having只會在檢索出所有記錄之后才會對結果集進行過濾,這個處理需要排序分組,如果能通過where子句提前過濾查詢的數(shù)目,就可以減少這方面的開銷。
低效: SELECT JOB, AVG(SAL) FROM EMP GROUP by JOB HAVING JOB = ‘PRESIDENT’ OR JOB = ‘MANAGER’高效: SELECT JOB, AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT’ OR JOB = ‘MANAGER’ GROUP by JOB
11. 盡量使用數(shù)字型字段
若只含數(shù)值信息的字段盡量不要設計為字符型,這會降低查詢和連接的性能。引擎在處理查詢和連接時會逐個比較字符串中每一個字符,而對于數(shù)字型而言只需要比較一次就夠了。
12. 優(yōu)化Join語句
當我們執(zhí)行兩個表的Join的時候,就會有一個比較的過程,逐條比較兩個表的語句是比較慢的,因此可以把兩個表中數(shù)據(jù)依次讀進一個內存塊中,在Mysql中執(zhí)行:show variables like ‘join_buffer_size’,可以看到join在內存中的緩存池大小,其大小將會影響join語句的性能。在執(zhí)行join的時候,數(shù)據(jù)庫會選擇一個表把他要返回以及需要進行和其他表進行比較的數(shù)據(jù)放進join_buffer。
什么是驅動表,什么是被驅動表,這兩個概念在查詢中有時容易讓人搞混,有下面幾種情況,大家需要了解。
1.當連接查詢沒有where條件時
left join 前面的表是驅動表,后面的表是被驅動表 right join 后面的表是驅動表,前面的表是被驅動表 inner join / join 會自動選擇表數(shù)據(jù)比較少的作為驅動表 straight_join(≈join) 直接選擇左邊的表作為驅動表(語義上與join類似,但去除了join自動選擇小表作為驅動表的特性)
2.當連接查詢有where條件時,帶where條件的表是驅動表,否則是被驅動表
假設有表如右邊:t1與t2表完全一樣,a字段有索引,b無索引,t1有100條數(shù)據(jù),t2有1000條數(shù)據(jù)
若被驅動表有索引,那么其執(zhí)行算法為:Index Nested-Loop Join(NLJ),示例如下:
1.執(zhí)行語句:select * from t1 straight_join t2 on (t1.a=t2.a);由于被驅動表t2.a是有索引的,其執(zhí)行邏輯如下:
從表t1中讀入一行數(shù)據(jù) R; 從數(shù)據(jù)行R中,取出a字段到表t2里去查找; 取出表t2中滿足條件的行,跟R組成一行,作為結果集的一部分; 重復執(zhí)行步驟1到3,直到表t1的末尾循環(huán)結束。 如果一條join語句的Extra字段什么都沒寫的話,就表示使用的是NLJ算法

若被驅動表無索引,那么其執(zhí)行算法為:Block Nested-Loop Join(BLJ)(Block 塊,每次都會取一塊數(shù)據(jù)到內存以減少I/O的開銷),示例如下:
2.執(zhí)行語句:select * from t1 straight_join t2 on (t1.a=t2.b);由于被驅動表t2.b是沒有索引的,其執(zhí)行邏輯如下:
把驅動表t1的數(shù)據(jù)讀入線程內存 join_buffer(無序數(shù)組)中,由于我們這個語句中寫的是select *,因此是把整個表t1放入了內存;順序遍歷表t2,把表t2中的每一行取出來,跟 join_buffer中的數(shù)據(jù)做對比,滿足join條件的,作為結果集的一部分返回。

3.另外還有一種算法為Simple Nested-Loop Join(SLJ),其邏輯為:順序取出驅動表中的每一行數(shù)據(jù),到被驅動表去做全表掃描匹配,匹配成功則作為結果集的一部分返回。
另外,Innodb會為每個數(shù)據(jù)表分配一個存儲在磁盤的 表名.ibd 文件,若關聯(lián)的表過多,將會導致查詢的時候磁盤的磁頭移動次數(shù)過多,從而影響性能
所以實踐中,盡可能減少Join語句中的NestedLoop的循環(huán)次數(shù):“永遠用小結果集驅動大的結果集”
用小結果集驅動大結果集,將篩選結果小的表(在決定哪個表做驅動表的時候,應該是兩個表按照各自的條件過濾,過濾完成之后,計算參與join的各個字段的總數(shù)據(jù)量,數(shù)據(jù)量小的那個表,就是“小表”)首先連接,再去連接結果集比較大的表,盡量減少join語句中的Nested Loop的循環(huán)總次數(shù)
優(yōu)先優(yōu)化Nested Loop的內層循環(huán)(也就是最外層的Join連接),因為內層循環(huán)是循環(huán)中執(zhí)行次數(shù)最多的,每次循環(huán)提升很小的性能都能在整個循環(huán)中提升很大的性能;
對被驅動表的join字段上建立索引;
當被驅動表的join字段上無法建立索引的時候,設置足夠的Join Buffer Size。
盡量用inner join(因為其會自動選擇小表去驅動大表).避免 LEFT JOIN (一般我們使用Left Join的場景是大表驅動小表)和NULL,那么如何優(yōu)化Left Join呢?
條件中盡量能夠過濾一些行將驅動表變得小一點,用小表去驅動大表 右表的條件列一定要加上索引(主鍵、唯一索引、前綴索引等),最好能夠使type達到range及以上(ref,eq_ref,const,system) 適當?shù)卦诒砝锩嫣砑尤哂嘈畔頊p少join的次數(shù)
使用更快的固態(tài)硬盤
性能優(yōu)化,left join 是由左邊決定的,左邊一定都有,所以右邊是我們的關鍵點,建立索引要建在右邊。當然如果索引是在左邊的,我們可以考慮使用右連接,如下
select * from atable left join btable on atable.aid=btable.bid;
-- 最好在bid上建索引
Tips:Join左連接在右邊建立索引;組合索引則盡量將數(shù)據(jù)量大的放在左邊,在左邊建立索引
索引的優(yōu)化/如何避免索引失效
1.最佳左前綴法則
如果索引了多列,要遵守最左前綴法則,指的是查詢從索引的最左前列開始并且不跳過索引中的列。Mysql查詢優(yōu)化器會對查詢的字段進行改進,判斷查詢的字段以哪種形式組合能使得查詢更快,所有比如創(chuàng)建的是(a,b)索引,查詢的是(b,a),查詢優(yōu)化器會修改成(a,b)后使用索引查詢。
2.不在索引列上做任何操作
1.計算:對索引進行表達式計算會導致索引失效,如 where id + 1 = 10,可以轉換成 where id = 10 -1,這樣就可以走索引
2.函數(shù):select * from t_user where length(name)=6; 此語句對字段使用到了函數(shù),會導致索引失效
從 MySQL 8.0 開始,索引特性增加了函數(shù)索引,即可以針對函數(shù)計算后的值建立一個索引,也就是說該索引的值是函數(shù)計算后的值,所以就可以通過掃描索引來查詢數(shù)據(jù)。
alter table t_user add key idx_name_length ((length(name)));
(自動/手動)類型轉換
(字符串類型必須帶''引號才能使索引生效)字段是varchar,用整型進行查詢時,無法走索引,如 select * from user where phone = 13030303030;
Mysql 在執(zhí)行上述語句時,會把字段轉換為數(shù)字再進行比較,所以上面那條語句就相當于:select * from user where CAST(phone AS signed int) = 13030303030; CAST 函數(shù)是作用在了 phone 字段,而 phone 字段是索引,也就是對索引使用了函數(shù)!所以索引失效
字段是int,用string進行查詢時,mysql會自動轉化,可以走索引,如: select * from user where id = '1';
MySQL 在遇到字符串和數(shù)字比較的時候,會自動把字符串轉為數(shù)字,然后再進行比較。以上這條語句相當于:select * from user where id = CAST(“1” AS signed int),索引字段并沒有用任何函數(shù),CAST 函數(shù)是用在了輸入?yún)?shù),因此是可以走索引掃描的。
3.存儲引擎不能使用索引中范圍條件右邊的列。
如這樣的sql: select * from user where username='123' and age>20 and phone='1390012345',其中username, age, phone都有索引,只有username和age會生效,phone的索引沒有用到。
4.盡量使用覆蓋索引(只訪問索引的查詢(索引列和查詢列一致))
如select age from user,減少select *
5.mysql在使用負向查詢條件(!=、<>、not in、not exists、not like)的時候無法使用索引會導致全表掃描。
你可以想象一下,對于一棵B+樹,根節(jié)點是40,如果你的條件是等于20,就去左面查,你的條件等于50,就去右面查,但是你的條件是不等于66,索引應該咋辦?還不是遍歷一遍才知道。
6.is null, is not null 也無法使用索引,在實際中盡量不要使用null(避免在 where 子句中對字段進行 null 值判斷) 不過在mysql的高版本已經(jīng)做了優(yōu)化,允許使用索引
對于null的判斷會導致引擎放棄使用索引而進行全表掃描。
7.like 以通配符開頭(%abc..)時,mysql索引失效會變成全表掃描的操作。
所以最好用右邊like ‘abc%’。如果兩邊都要用,可以用select username from user where username like '%abc%',其中username是必須是索引列,才可讓索引生效
假如index(a,b,c), where a=3 and b like ‘abc%’ and c=4,a能用,b能用,c不能用,類似于不能使用范圍條件右邊的列的索引
對于一棵B+樹索引來講,如果根節(jié)點是字符def,假如查詢條件的通配符在后面,例如abc%,則其知道應該搜索左子樹,假如傳入為efg%,則應該搜索右子樹,如果通配符在前面%abc,則數(shù)據(jù)庫不知道應該走哪一面,就都掃描一遍了。
8.少用or,在 WHERE 子句中,如果在 OR 前的條件列是索引列,而在 OR 后的條件列不是索引列,那么索引會失效。
select * from t_user where id = 1 or age = 18;
-- id有索引,name沒有,此時沒法走索引
因為 OR 的含義就是兩個只要滿足一個即可,因此只有一個條件列是索引列是沒有意義的,只要有條件列不是索引列,就會進行全表掃描。
必須要or前后的字段都有索引,查詢才能使用上索引(分別使用,最后合并結果type = index_merge)

9.在組合/聯(lián)合索引中,將有區(qū)分度的索引放在前面
如果沒有區(qū)分度,例如用性別,相當于把整個大表分成兩部分,查找數(shù)據(jù)還是需要遍歷半個表才能找到,使得索引失去了意義。
10.使用前綴索引
短索引不僅可以提高查詢性能而且可以節(jié)省磁盤空間和I/O操作,減少索引文件的維護開銷,但缺點是不能用于 ORDER BY 和 GROUP BY 操作,也不能用于覆蓋索引。
比如有一個varchar(255)的列,如果該列在前10個或20個字符內,可以做到既使前綴索引的區(qū)分度接近全列索引,那么就不要對整個列進行索引。為了減少key_len,可以考慮創(chuàng)建前綴索引,即指定一個前綴長度,可以使用count(distinct leftIndex(列名, 索引長度))/count(*) 來計算前綴索引的區(qū)分度。
11.SQL 性能優(yōu)化 explain 中的 type:至少要達到 range 級別,要求是 ref 級別,如果可以是 consts 最好。
consts:單表中最多只有一個匹配行(主鍵或者唯一索引),在優(yōu)化階段即可讀取到數(shù)據(jù)。 ref:使用普通的索引 range:對索引進行范圍檢索。
當 type=index 時,索引物理文件全掃,速度非常慢。
二、數(shù)據(jù)庫表結構的優(yōu)化:使得數(shù)據(jù)庫結構符合三大范式與BCNF
https://blog.csdn.net/qq_35642036/article/details/82809974