
聊聊推薦系統(tǒng)中的偏差
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


文 | 成指導(dǎo)
源 | 知乎
 背景
背景
推薦系統(tǒng)中大量使用用戶行為數(shù)據(jù),作為系統(tǒng)學(xué)習(xí)的標(biāo)簽或者說(shuō)信號(hào)。但用戶行為數(shù)據(jù)天生存在各式各樣的偏差(bias),如果直接作為信號(hào)的話,學(xué)習(xí)出的模型參數(shù)不能準(zhǔn)確表征用戶在推薦系統(tǒng)中的真實(shí)行為意圖,造成推薦效果的下降。
因此,本篇聊一聊推薦系統(tǒng)中常見(jiàn)的偏差,與相應(yīng)的去偏思路與方法。本篇的主要脈絡(luò)依據(jù)中科大何向南教授、合工大汪萌教授聯(lián)合在 TKDE 上的一篇綜述文章展開(kāi):Bias and Debias in Recommender System: A Survey and Future Directions。
推薦的反饋閉環(huán)
推薦系統(tǒng)是由用戶、數(shù)據(jù)、模型,三者互相作用產(chǎn)生的一個(gè)動(dòng)態(tài)的反饋閉環(huán)。閉環(huán)分為三個(gè)階段:
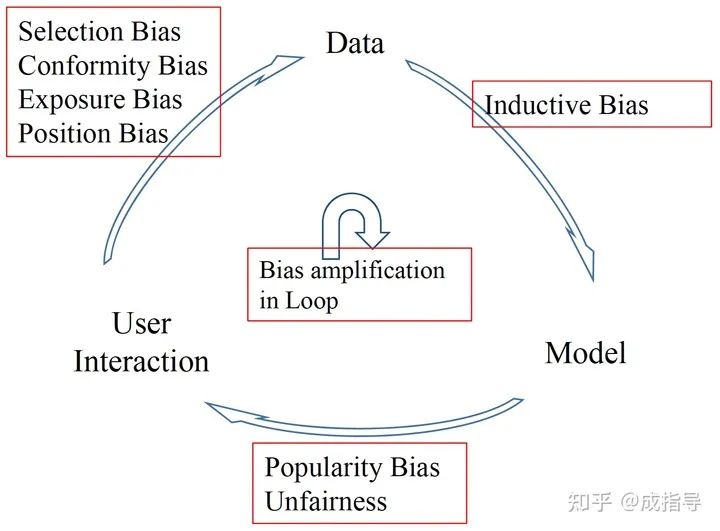
User -> Data
用戶會(huì)產(chǎn)生大量的 user-item(對(duì)抖音是用戶-視頻、對(duì)頭條是用戶-文章)交互數(shù)據(jù),以及各類(lèi)周邊信息包括 user 特征、item 屬性、交互上下文信息等。其中 user-item 交互數(shù)據(jù)中 user 集合被表示成 ,item 集合被表示成 。
user 與 item 兩者間互相作用形成反饋矩陣(feedback matrix),類(lèi)型分為兩種:
隱式反饋:表示為 ,矩陣中元素 是二值化 0、1 取值表示 user u 是否發(fā)生與 item i 的交互行為(bool 類(lèi)型,例如購(gòu)買(mǎi)、點(diǎn)擊、查看等行為) 顯式反饋:表示為 ,矩陣中元素 是 user u 對(duì) item i 的評(píng)分(float 類(lèi)型,例如豆瓣評(píng)分)
Data -> Model
根據(jù)歷史觀測(cè)數(shù)據(jù),訓(xùn)練模型預(yù)測(cè) user 是否采納 item 的程度。
Model -> User
模型返回預(yù)測(cè)推薦結(jié)果給到用戶,進(jìn)一步影響用戶的未來(lái)行為和決策。
三個(gè)階段不斷循環(huán),在閉環(huán)中逐漸加劇各階段的 bias,會(huì)造成更嚴(yán)重的問(wèn)題。
常見(jiàn)偏差
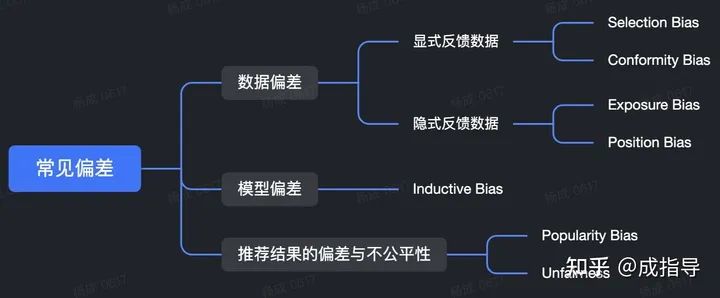
數(shù)據(jù)偏差
顯式反饋數(shù)據(jù) - Selection Bias
定義:當(dāng)用戶可以自由選擇 item 進(jìn)行評(píng)分,可觀測(cè)到的評(píng)分并不是所有評(píng)分的有代表性樣本。換而言之,評(píng)分?jǐn)?shù)據(jù)是“非隨機(jī)缺失”(missing not at random, MNAR)的
這個(gè)偏差的來(lái)源比較好理解,我們也可以想想自己是不是也是這樣:傾向于評(píng)分喜愛(ài)的 item(例如,熱衷粉絲的電影、歌曲等) ,傾向于評(píng)分特別好或者特別差的 item(例如,去看電影很想夸好片,很想噴爛片)
顯式反饋數(shù)據(jù) - Conformity Bias
定義:用戶評(píng)分傾向于與其他人相似,即使是完全基于他們自己的判斷,也會(huì)受到影響
這個(gè)偏差是由從眾心理導(dǎo)致的。對(duì)于大眾一致喜歡/討厭的 item,個(gè)體用戶做判斷時(shí)經(jīng)常會(huì)受到外界聲音的影響
隱式反饋數(shù)據(jù) - Exposure Bias
定義:僅有一部分特定 item 曝光給了用戶,因此沒(méi)有觀測(cè)到的交互行為并不直接等同于是訓(xùn)練中的負(fù)例
可以想一想,對(duì)于沒(méi)有產(chǎn)生交互行為(沒(méi)有點(diǎn)擊、購(gòu)買(mǎi)等行為)的數(shù)據(jù)樣本而言,其實(shí)是由 2 個(gè)原因造成:
用戶的確不喜歡當(dāng)前 item; 當(dāng)前 item 沒(méi)有曝光給用戶(對(duì)于從沒(méi)刷到過(guò)的視頻,我們無(wú)法確定自己是否喜歡)
對(duì)于數(shù)據(jù)曝光問(wèn)題,之前的研究有幾個(gè)角度:
當(dāng)前版本的曝光取決于上一個(gè)推薦系統(tǒng)版本的策略,決定了如何展現(xiàn); 因?yàn)橛脩魰?huì)主動(dòng)搜索或?qū)ふ?strong>感興趣的 item,因此用戶選擇成為了影響曝光的因素,使得高度相關(guān)/吸引力(例如標(biāo)題黨、美女圖片類(lèi)新聞)的 item 更容易被曝光; 用戶的背景關(guān)系是影響曝光的一個(gè)因素,例如好友、社區(qū)、地理位置等因素會(huì)影響曝光; 流行的 item 會(huì)更容易曝光給用戶,因此 Popularity Bias 是另一種形式 Exposure Bias
隱式反饋數(shù)據(jù) - Position Bias
定義:用戶傾向于無(wú)視相關(guān)性地去對(duì)推薦列表中更高位置上的 item 產(chǎn)生交互行為
位置偏差在搜索系統(tǒng)中是一個(gè)經(jīng)典并持續(xù)存在的偏差,同樣在推薦系統(tǒng)中也會(huì)存在,用戶普遍會(huì)對(duì)于頭部觀測(cè)到的 item 產(chǎn)生更多點(diǎn)擊(還沒(méi)有產(chǎn)生審美疲勞?)。尤其會(huì)對(duì)“用戶點(diǎn)擊行為”作為正例信號(hào)進(jìn)行學(xué)習(xí)的模型,位置偏差會(huì)在訓(xùn)練、評(píng)估階段產(chǎn)生錯(cuò)誤影響
模型偏差
Inductive Bias
偏差不一定總是有害的,實(shí)際上一些歸納偏差被故意加入到模型設(shè)計(jì)中為了實(shí)現(xiàn)某些特性
定義:為了模型更好地學(xué)習(xí)目標(biāo)函數(shù)并且泛化到訓(xùn)練數(shù)據(jù)上,會(huì)設(shè)置一些模型假設(shè)。假設(shè)未必都是準(zhǔn)確的,會(huì)產(chǎn)生一些偏差
列舉某些經(jīng)典的假設(shè)(未必造成有害影響):
用戶交互行為可以由向量?jī)?nèi)積表示 Adaptive negative sampler 提出用于增加學(xué)習(xí)速度,即使結(jié)果損失函數(shù)不同于最初分布 CNN 網(wǎng)絡(luò)的局部特征重要性
推薦結(jié)果的偏差與不公平性
Popularity Bias
定義:流行的 item 會(huì)被更頻繁地推薦、產(chǎn)生用戶交互
長(zhǎng)尾效應(yīng)或者說(shuō)二八定律帶來(lái)了這個(gè)偏差,會(huì)降低個(gè)性化層次、用戶對(duì)于平臺(tái)的驚喜體驗(yàn),造成馬太效應(yīng)
Unfairness
定義:整個(gè)系統(tǒng)不公平歧視某些群體用戶
這個(gè)偏差的本質(zhì)原因是數(shù)據(jù)的不平衡性,會(huì)帶來(lái)社會(huì)性問(wèn)題(年齡、性別、種族、社交關(guān)系多少等歧視)。不公平的數(shù)據(jù),會(huì)造成更不公平的用戶體驗(yàn),產(chǎn)生惡循環(huán)
不公平性更多是由于系統(tǒng)數(shù)據(jù)分布不平衡造成的,例如某個(gè)基本由中老年用戶組成的 app 較難對(duì)于年輕用戶的行為進(jìn)行建模,系統(tǒng)推薦出的視頻會(huì)更傾向于有“年代感”
反饋閉環(huán)加劇各類(lèi)偏差
User->Data->Model->User 的不斷循環(huán),會(huì)在已有偏差的基礎(chǔ)上,進(jìn)一步放大偏差
這篇文章簡(jiǎn)單介紹了一些推薦系統(tǒng)中常見(jiàn)的偏差 bias,并進(jìn)行了一些簡(jiǎn)單的分類(lèi)。這里的分類(lèi)體系并非絕對(duì)合理但卻具有一定代表性。
推薦閱讀
國(guó)產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(wàn)(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂(lè)于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!