
【推薦系統(tǒng)】多目標(biāo)學(xué)習(xí)在推薦系統(tǒng)中的應(yīng)用
本文概覽:
1. 多目標(biāo)學(xué)習(xí)提出的背景
一般來說在搜索和推薦等信息檢索場景下,最基礎(chǔ)的一個目標(biāo)就是用戶的 CTR,即用戶看見了一篇內(nèi)容之后會不會去點擊閱讀。但其實用戶在產(chǎn)品上的行為是多種多樣的。比如在微信的訂閱號中,用戶可以對某個內(nèi)容進(jìn)行點贊,可以收藏這個內(nèi)容,可以把它分享出去,甚至某篇文章如果他覺得比較符合他的興趣,也可以進(jìn)行留言。
雖然可以對用戶的 CTR 進(jìn)行單個目標(biāo)的優(yōu)化,但是這樣的做法也會帶來負(fù)面影響:靠用戶點擊這個行為推薦出來的內(nèi)容并不一定是用戶非常滿意的內(nèi)容,比如有人可能看到一些熱門的內(nèi)容就會去點擊,或者看到一些閱讀門檻低的內(nèi)容,像一些引發(fā)討論的熱點事件、社會新聞,或者是一些輕松娛樂的內(nèi)容,用戶也會點擊。這樣造成的后果就是:CTR 的指標(biāo)非常高,但是用戶接收到的推薦結(jié)果并不是他們最滿意的。
如果我們深入思考會發(fā)現(xiàn),用戶的每種行為一定程度上都代表了某個內(nèi)容是否能滿足他不同層面的需求。比如說點擊,代表著用戶在這個場景下,想要看這個內(nèi)容;贊同,代表用戶認(rèn)為這個內(nèi)容其實寫的很不錯;收藏,代表這個內(nèi)容對用戶特別有用,要把它收藏起來,要仔細(xì)的去看一看;分享,代表用戶希望其他的人也能看到這個內(nèi)容。
而單目標(biāo) CTR 優(yōu)化到了一個比較高的點之后,用戶的閱讀量雖然上去了,但是其他的各種行為(收藏、點贊、分享等等)是下降的。這個下降代表著:用戶接收到太多的東西是他認(rèn)為不實用的。
于是,推薦系統(tǒng)研究者開始思考:能不能預(yù)估用戶在其他行為上的概率? 這些概率實際上就是模型要學(xué)習(xí)的目標(biāo),多種目標(biāo)綜合起來,包括閱讀、點贊、收藏、分享等等一系列的行為,歸納到一個模型里面進(jìn)行學(xué)習(xí),這就是推薦系統(tǒng)的多目標(biāo)學(xué)習(xí)。
做推薦算法肯定繞不開多目標(biāo)。點擊率模型、時長模型和完播率模型是大部分信息流產(chǎn)品推薦算法團(tuán)隊都會嘗試去做的模型。單獨優(yōu)化點擊率模型容易推出來標(biāo)題黨,單獨優(yōu)化時長模型可能推出來的都是長視頻或長文章,單獨優(yōu)化完播率模型可能短視頻短圖文就容易被推出來,所以多目標(biāo)就應(yīng)運而生。
多目標(biāo)排序問題的解決方案,大概有以下四種:通過改變樣本權(quán)重、多模型分?jǐn)?shù)融合、排序?qū)W習(xí)(Learning To Rank,LTR)、多任務(wù)學(xué)習(xí)(Multi-Task Learning,MTL)。
2. 通過樣本權(quán)重進(jìn)行多目標(biāo)優(yōu)化
如果主目標(biāo)是點擊率,分享功能是我們希望提高的功能。那么點擊和分享都是正樣本(分享是點擊行為的延續(xù)),分享的樣本可以設(shè)置更高的樣本權(quán)重。在模型訓(xùn)練計算梯度更新參數(shù)時,梯度要乘以權(quán)重,對樣本權(quán)重大的樣本給予更大的權(quán)重。
因此,樣本權(quán)重大的樣本,如果預(yù)測錯誤就會帶來更大的損失。通過這種方法能夠在優(yōu)化某個目標(biāo)(點擊率)的基礎(chǔ)上,優(yōu)化其他目標(biāo)(分享率)。實際AB測試會發(fā)現(xiàn),這樣的方法,目標(biāo)A會受到一定的損失換取目標(biāo)B的增長。通過線上AB測試和樣本權(quán)重調(diào)整的聯(lián)動,可以保證在可接受的A目標(biāo)損失下,優(yōu)化目標(biāo)B,實現(xiàn)初級的多目標(biāo)優(yōu)化。
優(yōu)點:
模型簡單,僅在訓(xùn)練時通過梯度上乘樣本權(quán)重實現(xiàn)對某些目標(biāo)的放大或者減弱。 帶有權(quán)重樣本的模型和線上的base模型完全相同,不需要架構(gòu)的額外支持,可以作為多目標(biāo)的第一個模型嘗試。
缺點:
本質(zhì)上并不是對多目標(biāo)的建模,而是將不同的目標(biāo)折算成同一個目標(biāo)。樣本的折算權(quán)重需要根據(jù)AB測試才能確定。比如認(rèn)為一次分享算兩次點擊,在視頻中停留了2分鐘等價于3次對視頻的點擊行為等,這里面的數(shù)字需要根據(jù)線上評估指標(biāo)測試出來。 從原理上講無法達(dá)到最優(yōu),多目標(biāo)問題本質(zhì)上是一個帕累托尋找有效解的過程。
3. 多模型分?jǐn)?shù)融合
剛開始做多目標(biāo)的時候,一般針對每一個目標(biāo)都單獨訓(xùn)練一個模型,單獨部署一套預(yù)估服務(wù),然后將多個目標(biāo)的預(yù)估分融合后排序。這樣能夠比較好的解決推薦過程當(dāng)中的一些負(fù)面case,在各個指標(biāo)之間達(dá)到一個平衡,提升用戶留存。但是同時維護(hù)多個模型成本比較高,首先是硬件上,需要多倍的訓(xùn)練、PS和預(yù)估機(jī)器,這是一筆不小的開銷,然后是各個目標(biāo)的迭代不好協(xié)同,比如新上了一批好用的特征,多個目標(biāo)都需要重新訓(xùn)練實驗和上線,然后就是同時維護(hù)多個目標(biāo)對相關(guān)人員的精力也是一個比較大的消耗。
具體的做法為:假如我們有多個優(yōu)化的目標(biāo),每個優(yōu)化的目標(biāo)都有一個獨立的模型來優(yōu)化。可以根據(jù)優(yōu)化目標(biāo)的不同,采用更匹配的模型。如視頻信息流場景中,我們用分類模型優(yōu)化點擊率,用回歸模型優(yōu)化停留時長。不同的模型得到預(yù)測的score之后,通過一個函數(shù)將多個目標(biāo)融合在一起。最常見的是weighted sum融合多個目標(biāo),給不同的目標(biāo)分配不同的權(quán)重。當(dāng)然,融合的函數(shù)可以有很多,比如連乘或者指數(shù)相關(guān)的函數(shù),這里和業(yè)務(wù)場景和目標(biāo)的含義強(qiáng)相關(guān),可以根據(jù)自己的實際場景探索。這種做法優(yōu)點:模型簡單;缺點是:(1)線上serving部分需要額外的時間開銷,通常我們采用并行的方式請求多個模型進(jìn)行融合。(2)多個模型之間相互獨立,不能互相利用各自訓(xùn)練的部分作為先驗,容易過擬合。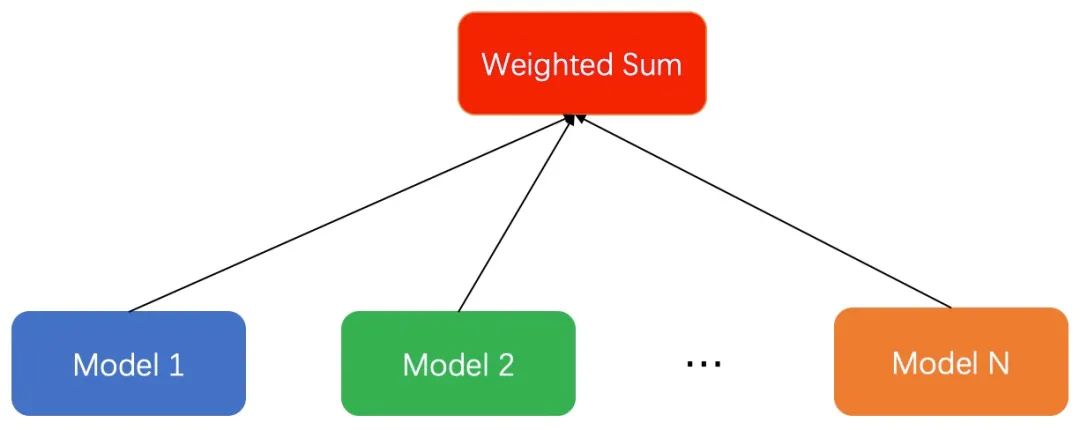
4. 排序?qū)W習(xí)
多模型分?jǐn)?shù)融合通過計算推薦物的綜合得分來排序(point-wise),其目的是為了推薦物品。因此,也可以直接預(yù)測物品兩兩之間相對順序的問題(pair-wise)來解決多目標(biāo)學(xué)習(xí)的問題,常用的算法比如 BPR,還可以預(yù)測物品序列之間的得分情況(list-wise) 來解決多目標(biāo)學(xué)習(xí)的問題。具體可以看看相關(guān)算法的介紹。
舉一個用pair-wise做視頻推薦的例子,用戶觀看很長時間的 視頻,點擊了 視頻,那么我們覺得觀看比點擊重要。用戶 在視頻 和視頻 之間的偏好和其他的視頻無關(guān)。為了便于描述,用 符號表示用戶 的偏好,上面的 可以表示為:
優(yōu)點:
優(yōu)化了目標(biāo)排序,不需要設(shè)計復(fù)雜的超參數(shù),能取得比排序好的效果。 本身就是單個模型有多個目標(biāo),線下好訓(xùn)練,線上服務(wù)壓力小。
缺點:
有些相對順序不好構(gòu)造,訓(xùn)練樣本中沒有的關(guān)系,在預(yù)測時可能存在。 樣本數(shù)量增大,訓(xùn)練速度變慢,需要構(gòu)造的情況多。 樣本的不平衡性會被放大。舉例:有的用戶有十次點擊,有的只有一次,在構(gòu)造的時候十次的會構(gòu)造更多的樣本,一次的就吃虧。
當(dāng)然,通過LTR(Learning To Rank)方法優(yōu)化Item的重要性可以解決多目標(biāo)要解決的問題,但是由于工程實現(xiàn)、推薦框架調(diào)整等方面的困難,相關(guān)方法在實際應(yīng)用中比較少。下面我們重點梳理一下一個模型預(yù)估多個目標(biāo)的多任務(wù)學(xué)習(xí)模型的發(fā)展進(jìn)程。
5. 多任務(wù)學(xué)習(xí)
5.1 共享底層參數(shù)的多塔結(jié)構(gòu)
2017年的這篇綜述文章《An Overview of Multi-Task Learning in Deep Neural Networks》將多目標(biāo)的方法分成了兩類。第一類是Hard parameter sharing的方法,將排序模型底層的全連接層進(jìn)行共享,學(xué)習(xí)共同的模式,上層用一些特定的全連接層學(xué)習(xí)任務(wù)特定的模式。這種方法非常經(jīng)典,效果還是不錯的,美團(tuán)、知乎在18年分享的文章《美團(tuán)“猜你喜歡”深度學(xué)習(xí)排序模型實踐》、《知乎推薦頁Ranking經(jīng)驗分享》中使用的都是這種方法。
【相關(guān)鏈接】
Ruder S. An overview of multi-task learning in deep neural networks[J]. arXiv preprint arXiv:1706.05098, 2017. 美團(tuán)“猜你喜歡”深度學(xué)習(xí)排序模型實踐,地址:https://tech.meituan.com/2018/03/29/recommend-dnn.html 「回顧」知乎推薦頁Ranking經(jīng)驗分享,地址:https://mp.weixin.qq.com/s/GUMz-HfbjQvzdGVQkKz4zA 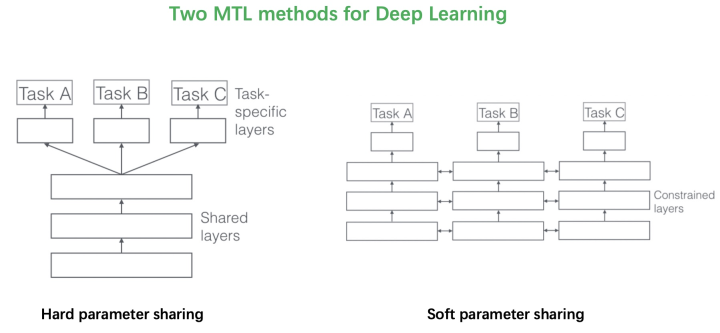
這種方法最大的優(yōu)勢是Task越多,單任務(wù)更加不可能過擬合,劣勢是底層強(qiáng)制shared layers難以學(xué)得適用于所有任務(wù)的表達(dá)。尤其是兩個任務(wù)很不相關(guān)的時候。如下圖中的例子,假設(shè)你的多目標(biāo)預(yù)估是同時做貓狗的分類,那么底層的shared layers學(xué)到的可能是關(guān)于眼睛、耳朵、顏色的一些共同模式。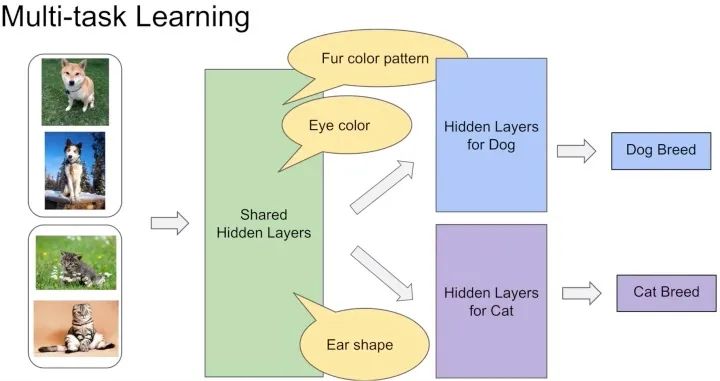 而如果你的任務(wù)是做一個狗的分類,同時做汽車的分類,采用Hard parameter sharing的方法,底層的shared layers很難學(xué)到兩者共同的模式,多目標(biāo)任務(wù)也很難學(xué)好。
而如果你的任務(wù)是做一個狗的分類,同時做汽車的分類,采用Hard parameter sharing的方法,底層的shared layers很難學(xué)到兩者共同的模式,多目標(biāo)任務(wù)也很難學(xué)好。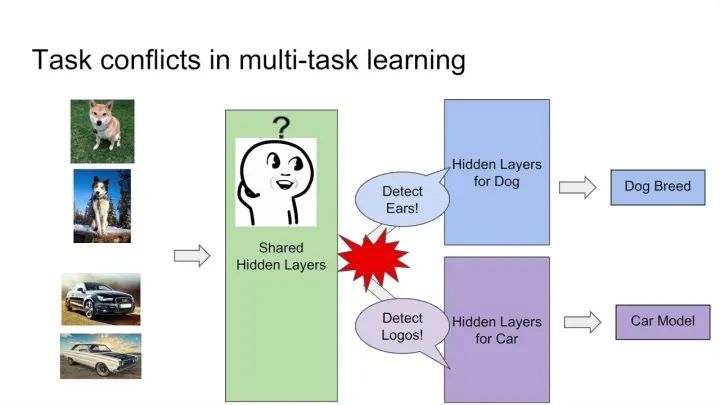 谷歌在MMoE論文中的實驗顯示,任務(wù)相關(guān)性越高,模型的loss可以降到更低。當(dāng)兩個任務(wù)相關(guān)性沒有那么好時(例如,推薦系統(tǒng)排序中的點擊率和互動率、點擊率和停留時長等),Hard parameter sharing 的模式就不是那么適用了,會損害到一些效果。對應(yīng)的,Soft parameter sharing的方式可能更加適合。
谷歌在MMoE論文中的實驗顯示,任務(wù)相關(guān)性越高,模型的loss可以降到更低。當(dāng)兩個任務(wù)相關(guān)性沒有那么好時(例如,推薦系統(tǒng)排序中的點擊率和互動率、點擊率和停留時長等),Hard parameter sharing 的模式就不是那么適用了,會損害到一些效果。對應(yīng)的,Soft parameter sharing的方式可能更加適合。
下圖展示的是在推薦中共享Embedding多塔結(jié)構(gòu)的例子。根據(jù)業(yè)務(wù)目標(biāo),我們把點擊率、時長和完播率拆分出來,形成三個獨立的訓(xùn)練目標(biāo),分別建立各自的Loss Function,作為對模型訓(xùn)練的監(jiān)督和指導(dǎo)。此模型的EMB部分和表示層作為共享層,點擊任務(wù)、時長任務(wù)和完播率任務(wù)共享其表達(dá),并在BP階段根據(jù)三個任務(wù)算出的梯度共同進(jìn)行參數(shù)更新。在表示層的最后一個全連接層進(jìn)行拆分,單獨學(xué)習(xí)對應(yīng)Loss的參數(shù),從而更好地專注于擬合各自Label的分布。線上預(yù)測時,我們將點擊模型的output、時長模型的output和完播率模型的output做一個線性融合。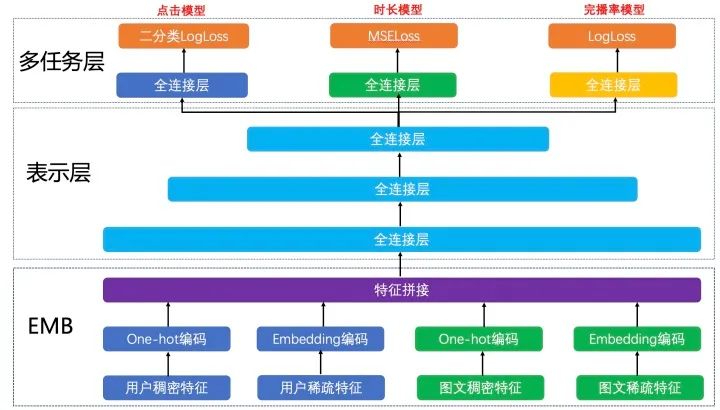 雖然解決了一部分問題,但是把多個模型融合在一起,通過一個模型去學(xué)習(xí)一個目標(biāo)的方式仍然存在問題。首先,目標(biāo)之間的相關(guān)性決定了這個模型學(xué)習(xí)的上限能有多少。比如:如果一個模型中點贊和點擊是完全耦合的,那么這個模型在學(xué)習(xí)點贊的過程中,也就學(xué)習(xí)了點擊。但是對用戶來講,它的意義是不一樣的,這并不是一個完全耦合的系統(tǒng)。在這個學(xué)習(xí)任務(wù)下,如果去共享底層網(wǎng)絡(luò)參數(shù)的話,可能會造成底層的每個目標(biāo)都能學(xué)習(xí)一點,但是每個目標(biāo)學(xué)習(xí)的都不夠充分,這是多目標(biāo)學(xué)習(xí)系統(tǒng)實現(xiàn)的一個難點。
雖然解決了一部分問題,但是把多個模型融合在一起,通過一個模型去學(xué)習(xí)一個目標(biāo)的方式仍然存在問題。首先,目標(biāo)之間的相關(guān)性決定了這個模型學(xué)習(xí)的上限能有多少。比如:如果一個模型中點贊和點擊是完全耦合的,那么這個模型在學(xué)習(xí)點贊的過程中,也就學(xué)習(xí)了點擊。但是對用戶來講,它的意義是不一樣的,這并不是一個完全耦合的系統(tǒng)。在這個學(xué)習(xí)任務(wù)下,如果去共享底層網(wǎng)絡(luò)參數(shù)的話,可能會造成底層的每個目標(biāo)都能學(xué)習(xí)一點,但是每個目標(biāo)學(xué)習(xí)的都不夠充分,這是多目標(biāo)學(xué)習(xí)系統(tǒng)實現(xiàn)的一個難點。
后來,阿里媽媽的Xiao Ma等人發(fā)現(xiàn),在推薦系統(tǒng)中不同任務(wù)之間通常存在一種序列依賴關(guān)系。例如,電商推薦中的多目標(biāo)預(yù)估經(jīng)常是CTR和CVR,其中轉(zhuǎn)化這個行為只有在點擊發(fā)生后才會發(fā)生。這種序列依賴關(guān)系其實可以被利用,來解決一些任務(wù)預(yù)估中存在的樣本選擇偏差(Sample Selection Bias,SSB)和數(shù)據(jù)稀疏性(Data Sparisity,DS)問題。因此提出Entire Space Multi-Task Model(ESMM)。
簡單介紹一下什么是SSB問題和DS問題。SSB問題:后一階段的模型基于上一階段采樣后的樣本子集進(jìn)行訓(xùn)練,但是最終在全樣本空間進(jìn)行推理,帶來嚴(yán)重的泛化性問題。DS問題:后一階段的模型訓(xùn)練樣本通常遠(yuǎn)小于前一階段任務(wù)。
5.2 ESMM-任務(wù)序列依賴關(guān)系建模
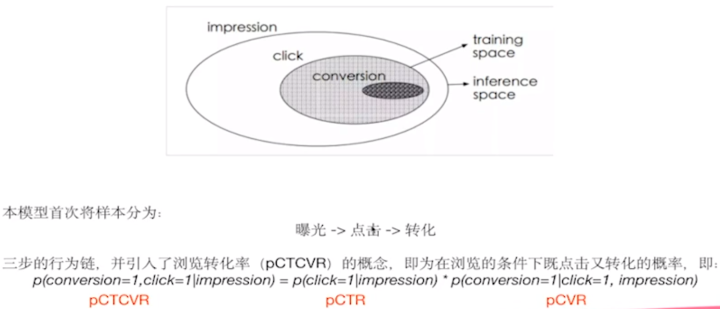
ESMM模型首次把樣本空間分成了三大部分,從曝光到點擊再到轉(zhuǎn)化的三步行為鏈,并引入了瀏覽轉(zhuǎn)化率(pCTCVR)的概念。我們正常做CVR任務(wù)的時候,默認(rèn)只在點擊的空間上來做,認(rèn)為曝光、點擊并轉(zhuǎn)化了就是正樣本,曝光、點擊并未轉(zhuǎn)化為負(fù)樣本。如果這樣想的話,樣本全空間只有點擊的樣本,而沒有考慮到未點擊的樣本。ESMM論文就提出曝光點擊、曝光不點擊以及點擊之后是否轉(zhuǎn)化所有的這些樣本都考慮進(jìn)來,提出三步的行為鏈如下公式:
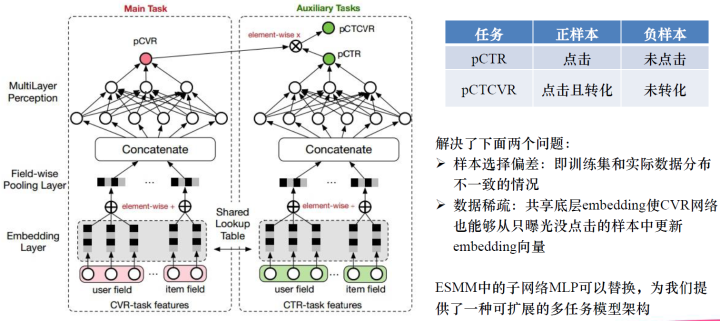 這就是瀏覽轉(zhuǎn)化率公式,并提出了上圖所示的網(wǎng)絡(luò)模型,一個雙塔模型,它們是共享底層Embedding的,只是上面的不一樣,一個用來預(yù)測CVR,這個可以在全樣本空間上進(jìn)行訓(xùn)練,另一個是用來預(yù)測CTR,CTR是一個輔助任務(wù)。最后的pCTCVR可以在全樣本空間中訓(xùn)練。ESMM模型是一個雙塔、雙任務(wù)的模式在全樣本空間上進(jìn)行訓(xùn)練。這樣訓(xùn)練的好處可以解決兩個問題:一是,樣本選擇的問題,CVR是在點擊的基礎(chǔ)上進(jìn)行訓(xùn)練,訓(xùn)練集只有點擊的,實際數(shù)據(jù)可能有曝光點擊和曝光未點擊的數(shù)據(jù),我們往往把曝光未點擊的數(shù)據(jù)給忽略了,這樣就造成了樣本選擇偏差,訓(xùn)練集和實際數(shù)據(jù)分布不一致的情況。二是,解決數(shù)據(jù)稀疏的問題。因為我們現(xiàn)在在全樣本空間上進(jìn)行訓(xùn)練,不是只在點擊的樣本上進(jìn)行訓(xùn)練,所以樣本就多了很多,所有樣本可以進(jìn)行輔助更新CVR網(wǎng)絡(luò)中的Embedding,這樣Embedding向量就會訓(xùn)練的更加充分。ESMM還提出子網(wǎng)絡(luò)MLP可以替換,為我們提供了一種可擴(kuò)展的多任務(wù)模型架構(gòu)。
這就是瀏覽轉(zhuǎn)化率公式,并提出了上圖所示的網(wǎng)絡(luò)模型,一個雙塔模型,它們是共享底層Embedding的,只是上面的不一樣,一個用來預(yù)測CVR,這個可以在全樣本空間上進(jìn)行訓(xùn)練,另一個是用來預(yù)測CTR,CTR是一個輔助任務(wù)。最后的pCTCVR可以在全樣本空間中訓(xùn)練。ESMM模型是一個雙塔、雙任務(wù)的模式在全樣本空間上進(jìn)行訓(xùn)練。這樣訓(xùn)練的好處可以解決兩個問題:一是,樣本選擇的問題,CVR是在點擊的基礎(chǔ)上進(jìn)行訓(xùn)練,訓(xùn)練集只有點擊的,實際數(shù)據(jù)可能有曝光點擊和曝光未點擊的數(shù)據(jù),我們往往把曝光未點擊的數(shù)據(jù)給忽略了,這樣就造成了樣本選擇偏差,訓(xùn)練集和實際數(shù)據(jù)分布不一致的情況。二是,解決數(shù)據(jù)稀疏的問題。因為我們現(xiàn)在在全樣本空間上進(jìn)行訓(xùn)練,不是只在點擊的樣本上進(jìn)行訓(xùn)練,所以樣本就多了很多,所有樣本可以進(jìn)行輔助更新CVR網(wǎng)絡(luò)中的Embedding,這樣Embedding向量就會訓(xùn)練的更加充分。ESMM還提出子網(wǎng)絡(luò)MLP可以替換,為我們提供了一種可擴(kuò)展的多任務(wù)模型架構(gòu)。
ESMM是一種較為通用的任務(wù)序列依賴關(guān)系建模的方法,除此之外,阿里的論文《Deep Bayesian Multi-Target Learning for Recommender Systems》中提出DBMTL模型 、《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》中提出 模型,這些工作都屬于任務(wù)序列依賴這一模式。
5.3 MMoE替換hard parameter sharing
阿里團(tuán)隊提出 ESMM 模型利用多任務(wù)學(xué)習(xí)的方法極大地提升了 CVR 預(yù)估的性能,同時解決了傳統(tǒng) CVR 模型預(yù)估的一些弊病。我們從模型的網(wǎng)絡(luò)結(jié)構(gòu)可以了解到,ESMM 是典型的 share-bottom 結(jié)構(gòu),即底層特征共享方式。這種多任務(wù)學(xué)習(xí)共享結(jié)構(gòu)的一大特點是在任務(wù)之間都比較相似或者相關(guān)性比較大的場景下能帶來很好的效果,而對于任務(wù)間差異比較大的場景,這種多任務(wù)學(xué)習(xí)共享結(jié)構(gòu)就有點捉襟見肘了。
5.3.1 MMoE要解決的問題
說到底,多任務(wù)學(xué)習(xí)的本質(zhì)就是共享表示以及相關(guān)任務(wù)的相互影響。通常,相似的子任務(wù)也擁有比較接近的底層特征,那么在多任務(wù)學(xué)習(xí)中,他們就可以很好地進(jìn)行底層特征共享;而對于不相似的子任務(wù),他們的底層表示差異很大,在進(jìn)行參數(shù)共享時很有可能會互相沖突或噪聲太多,導(dǎo)致多任務(wù)學(xué)習(xí)的模型效果不佳。
實際的應(yīng)用場景中,我們可能不止有像 CTR、CVR 這樣的非常相關(guān)的子任務(wù),還會遇到子任務(wù)間關(guān)系沒那么緊密的多任務(wù)學(xué)習(xí)場景,而且很多情況下,你很難判斷任務(wù)在數(shù)據(jù)層面是否是相似的。所以多任務(wù)學(xué)習(xí)如何在相關(guān)性不高的任務(wù)上獲得好效果是一件很有挑戰(zhàn)性也很有實際意義的事,這也是本小節(jié)所提到的模型 “MMoE” 主要解決的問題。
其實在 MMoE之前,已經(jīng)有一些其他結(jié)構(gòu)來解決這個問題了,比如兩個任務(wù)的參數(shù)不共用,而是對不同任務(wù)的參數(shù)增加 L2 范數(shù)的限制;或者對每個任務(wù)分別學(xué)習(xí)一套隱層然后學(xué)習(xí)所有隱層的組合。這些結(jié)構(gòu)和 Shared-Bottom 結(jié)構(gòu)相比,其構(gòu)成的模型會針對每個任務(wù)添加更多參數(shù)以適應(yīng)任務(wù)間差異,雖然能夠帶來一定的效果提升,但是增加了更多的參數(shù)也就意味著需要更大的數(shù)據(jù)樣本來訓(xùn)練模型,而且這些方法會使模型變得更復(fù)雜,也不利于在真實生產(chǎn)環(huán)境中部署使用。相關(guān)內(nèi)容在MMoE論文中的“2.1 Multi-task Learning in DNNs”小節(jié)中有提到,想詳細(xì)了解可以看論文中給出的引用文章。
MMoE(Multi-gate Mixture-of-Experts) 是 Google 在 2018 年 KDD 上發(fā)表的論文《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》里提出的,它是一種新穎的多任務(wù)學(xué)習(xí)結(jié)構(gòu)。MMoE 模型刻畫了任務(wù)相關(guān)性,基于共享表示來學(xué)習(xí)特定任務(wù)的函數(shù),避免了明顯增加參數(shù)的缺點。廣義上MMoE方法是Soft parameter sharing的一種。在這篇論文發(fā)表前,還有個MoE模型(Mixture-of-Experts),下面先介紹MoE模型。
5.3.2 MoE模型
早在 2017 年,谷歌大腦團(tuán)隊的兩位科學(xué)家:大名鼎鼎的深度學(xué)習(xí)之父 Geoffrey Hinto 和 谷歌首席架構(gòu)師 Jeff Dean 在發(fā)表論文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提出了 “稀疏門控制的混合專家層”(Sparsely-Gated Mixture-of-Experts layer,MoE),這里的 MoE 是一種特殊的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)層,結(jié)合了專家系統(tǒng)和集成思想在里面。
MoE 由許多 “專家” 組成,每個 “專家” 都有一個簡單的前饋神經(jīng)網(wǎng)絡(luò)和一個可訓(xùn)練的門控網(wǎng)絡(luò)(gating network),該門控網(wǎng)絡(luò)選擇 “專家” 的一個稀疏組合來處理每個輸入,它可以實現(xiàn)自動分配參數(shù)以捕獲多個任務(wù)可共享的信息或是特定于某個任務(wù)的信息,而無需為每個任務(wù)添加很多新參數(shù),而且網(wǎng)絡(luò)的所有部分都可以通過反向傳播一起訓(xùn)練。MoE 結(jié)構(gòu)圖如下所示: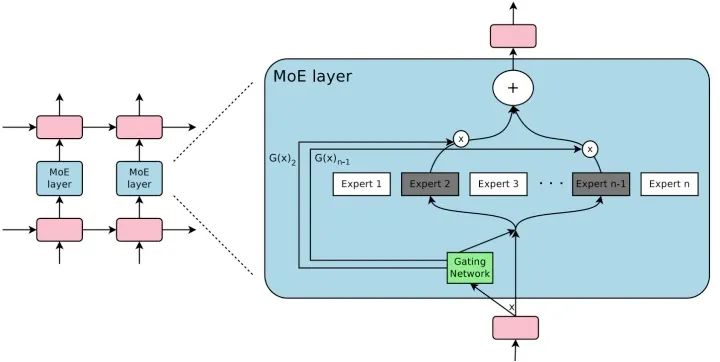 MoE 可以作為一個基本的組成單元,也可以是多個 MoE 結(jié)構(gòu)堆疊在一個大網(wǎng)絡(luò)中。比如一個 MoE 層可以接受上一層 MoE 層的輸出作為輸入,其輸出作為下一層的輸入使用。在谷歌大腦的論文中,MoE 就是作為循環(huán)神經(jīng)網(wǎng)絡(luò)中的一個循環(huán)單元。
MoE 可以作為一個基本的組成單元,也可以是多個 MoE 結(jié)構(gòu)堆疊在一個大網(wǎng)絡(luò)中。比如一個 MoE 層可以接受上一層 MoE 層的輸出作為輸入,其輸出作為下一層的輸入使用。在谷歌大腦的論文中,MoE 就是作為循環(huán)神經(jīng)網(wǎng)絡(luò)中的一個循環(huán)單元。
MoE 神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)有兩個非常明顯的好處:
(1)實現(xiàn)一種多專家集成的效果。
MoE 的思想是訓(xùn)練多個神經(jīng)網(wǎng)絡(luò)(也就是多個專家),每個神經(jīng)網(wǎng)絡(luò)(專家)通過門控網(wǎng)絡(luò)(Gating NetWork)被指定應(yīng)用于數(shù)據(jù)集的不同部分,最后再通過門控網(wǎng)絡(luò)將多個專家的結(jié)果進(jìn)行組合。單個模型往往善于處理一部分?jǐn)?shù)據(jù),不擅長處理另外一部分?jǐn)?shù)據(jù)(在這部分?jǐn)?shù)據(jù)上犯錯多),而多專家系統(tǒng)則很好的解決了這個問題:系統(tǒng)中的每一個神經(jīng)網(wǎng)絡(luò),也就是每一個專家都會有一個擅長的數(shù)據(jù)區(qū)域,在這組區(qū)域上該專家就是 “權(quán)威”,要比其他專家表現(xiàn)得好。因此多專家系統(tǒng)是單一全局模型或者多個局部模型的一個很好的折中,這樣的網(wǎng)絡(luò)結(jié)構(gòu)能夠處理更加復(fù)雜的數(shù)據(jù)分布,在相應(yīng)的任務(wù)中,性能也會有很大的提升。
(2)只需增加很小的計算力,便能高效地提升模型的性能。
神經(jīng)網(wǎng)絡(luò)吸收信息的能力受其參數(shù)數(shù)量的限制。有人在理論上提出了條件計算(conditional computation)的概念,作為大幅提升模型容量而不會大幅增加計算力需求的一種方法。MoE 就是條件計算的一種實現(xiàn),并在論文中證實,這種網(wǎng)絡(luò)結(jié)構(gòu)可實現(xiàn)在計算效率方面只有微小損失情況下,可以顯著提高性能。
5.3.3 MMoE模型
有了以上信息,我們就很容易理解為什么要將 MoE 引入多任務(wù)學(xué)習(xí)中了,因為多專家集成的機(jī)制剛好可以用來解決多任務(wù)間的差異問題,并且還不會帶來很大計算損耗。
Shared-Bottom Multi-task Model 多任務(wù)學(xué)習(xí)(Multi-Task Learning,MTL)中最經(jīng)典的 Shared-Bottom DNN 網(wǎng)絡(luò)結(jié)構(gòu),如下圖所示:
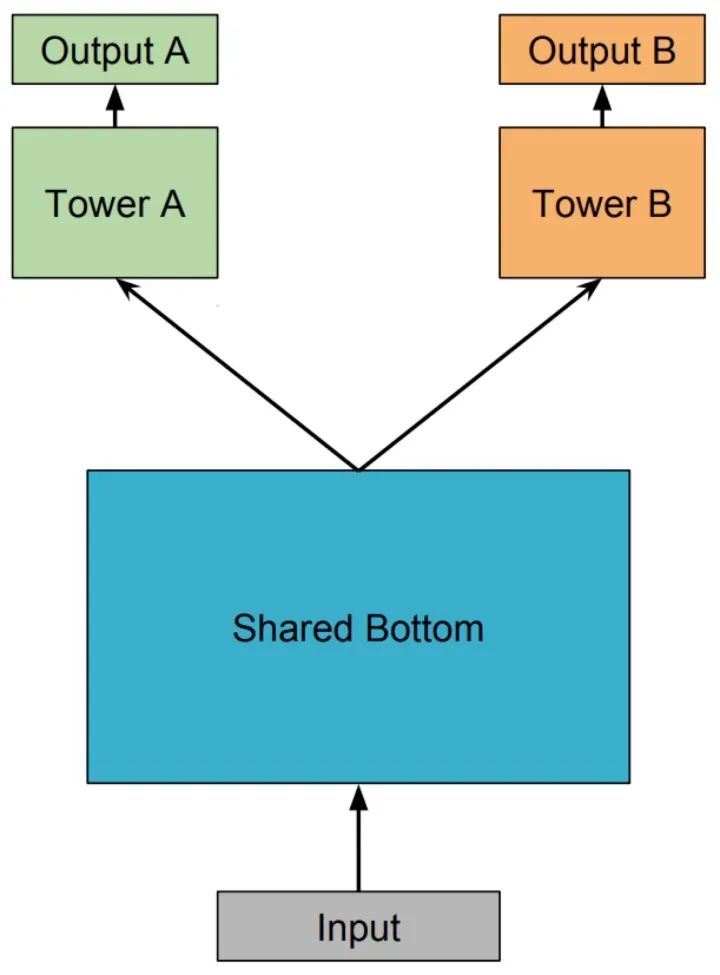
Shared-Bottom 網(wǎng)絡(luò)通常位于底部,表示為函數(shù) ,多個任務(wù)共用這一層。往上,個子任務(wù)分別對應(yīng)一個 tower network,表示為 ,每個子任務(wù)的輸出 。
One-gate MoE model
用一組由專家網(wǎng)絡(luò)(expert network)組成的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)來替換掉 Shared-Bottom 部分(函數(shù) ),這里的每個 “專家” 都是一個前饋神經(jīng)網(wǎng)絡(luò),再加上一個門控網(wǎng)絡(luò),就構(gòu)成了 MoE 結(jié)構(gòu)的 MTL 模型。因為只有一個門網(wǎng)絡(luò),所以在論文中,為了與 MMoE 對應(yīng),也稱這種結(jié)構(gòu)為 OMoE(One-gate Mixture-of-Experts),其結(jié)構(gòu)如下圖所示:
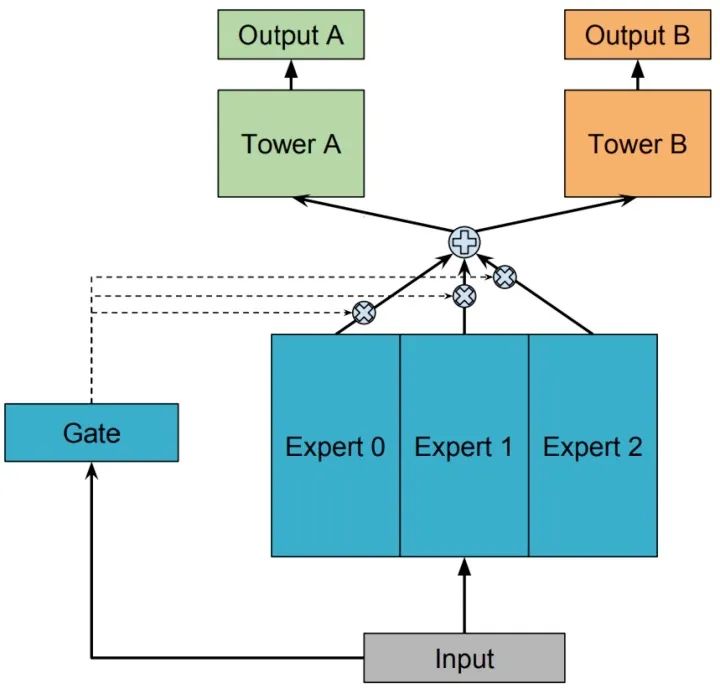
MoE 模型可以形式化表示為:
其中, 是 個expert network(expert network可認(rèn)為是一個神經(jīng)網(wǎng)絡(luò)), 是組合 experts 結(jié)果的門控網(wǎng)絡(luò)(gating network), ,具體來說 產(chǎn)生 個 experts 上的概率分布,最終的輸出是所有 experts 的帶權(quán)加和。顯然,MoE 可看做基于多個獨立模型的集成方法。這里注意MoE只對應(yīng)上圖中的一部分,我們把得到的帶權(quán)結(jié)果 輸入到子任務(wù)分別對應(yīng)的tower network中進(jìn)行學(xué)習(xí)。上文中也提到了有些文章將MoE作為一個基本的組成單元,將多個MoE結(jié)構(gòu)堆疊在一個大網(wǎng)絡(luò)中。比如一個MoE層可以接受上一層MoE層的輸出作為輸入,其輸出作為下一層的輸入使用。
Multi-gate MoE model
知道了 OMoE 結(jié)構(gòu),那么 MMoE(Multi-gate Mixture-of-Experts)的結(jié)構(gòu)就很容易猜出來了,通過名字里的 Multi-gate 很容易想到,MMoE 就是在 OMoE 的基礎(chǔ)上,用了多個門控網(wǎng)絡(luò),其核心思想是將shared-bottom網(wǎng)絡(luò)中的函數(shù) 替換成MoE層,結(jié)構(gòu)如下圖所示:
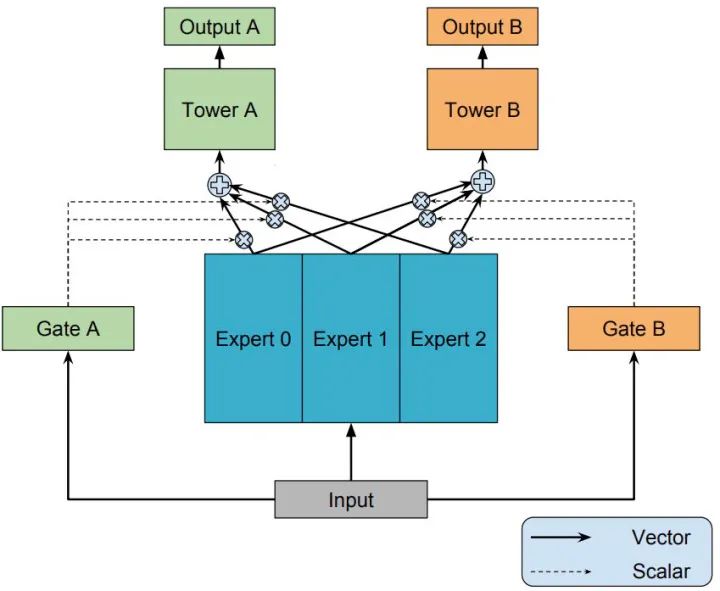
MMoE 可以形式化表達(dá)為:
其中, 是第 個任務(wù)中組合 experts 結(jié)果的門控網(wǎng)絡(luò)(gating network),注意每一個任務(wù)都有一個獨立的門控網(wǎng)絡(luò)。 ,它的輸入是 input feature,輸出就是所有 Experts 上的權(quán)重。 是 個專家(expert)網(wǎng)絡(luò)。
一方面,因為gating networks通常是輕量級的,而且expert networks是所有任務(wù)共用,所以相對于論文中提到的一些baseline方法在計算量和參數(shù)量上具有優(yōu)勢。
另一方面,MMoE 其實是 MoE 針對多任務(wù)學(xué)習(xí)的變種和優(yōu)化,相對于 OMoE 的結(jié)構(gòu)中所有任務(wù)共享一個門控網(wǎng)絡(luò),MMoE 的結(jié)構(gòu)優(yōu)化為每個任務(wù)都單獨使用一個門控網(wǎng)絡(luò)。這樣的改進(jìn)可以針對不同任務(wù)得到不同的 Experts 權(quán)重,從而實現(xiàn)對 Experts 的選擇性利用,不同任務(wù)對應(yīng)的門控網(wǎng)絡(luò)可以學(xué)習(xí)到不同的 Experts 組合模式,因此模型更容易捕捉到子任務(wù)間的相關(guān)性和差異性。
5.3.4 MMoE的應(yīng)用
在2019年的RecSys上,Google又發(fā)表了一篇MMoE的應(yīng)用文章《Recommending What Video to Watch Next: A Multitask Ranking System》。
一般推薦系統(tǒng)排序模塊的進(jìn)化路徑是:CTR任務(wù) -> CTR + 時長 -> MultiTask & Selection Bias。該論文主要聚焦于大規(guī)模視頻推薦中的排序階段,介紹一些比較實在的經(jīng)驗和教訓(xùn),解決 Multitask Learning, Selection Bias 這兩個排序系統(tǒng)的關(guān)鍵點。算法的應(yīng)用離不開其場景,這篇文章應(yīng)用在Youtube視頻推薦的場景中,其優(yōu)化的多目標(biāo)包含:
參與度目標(biāo)(engagement objectives):點擊率、完播率; 滿意度目標(biāo)(satisfaction objectives):喜歡、評分;
有很多不同甚至是沖突的優(yōu)化目標(biāo),比如我們不僅希望用戶觀看,還希望用戶能給出高評價并分享。對于存在潛在沖突的多目標(biāo),通過 MMoE 的結(jié)構(gòu)來解決,通過門結(jié)構(gòu)來選擇性的從輸入獲取信息。
在真實場景中的另一個挑戰(zhàn)是系統(tǒng)中經(jīng)常有一些隱性偏見,比如用戶是因為視頻排得靠前而點擊 & 觀看,而非用戶確實很喜歡。因此用之前模型產(chǎn)生的數(shù)據(jù)會引發(fā) bias,從而形成一個反饋循環(huán),越來越偏。例如在Youtube詳情頁的場景大多都面臨著各種bias問題。包括position bias,user bias,trigger bias等。position bias指的是不同坑位天然的xx率指標(biāo)都不同;user bias表示著不同用戶天然的xx率不同,有的用戶愛點,有的用戶不愛點;trigger bias表示這個內(nèi)容出現(xiàn)在不同的詳情頁下,xx率也并不相同。如何高效有力地解決這些偏差是個尚未解決的問題。
Youtube這篇論文解決的是position bias的問題,下圖以點擊率為例,可以看出Youtube的詳情頁場景的點擊率面臨著嚴(yán)重的position bias問題。
解決這個問題的方式是使用一個shallow tower來建模點擊率的position bias。這個shallow tower的輸入特征只采用一些selection bias特征,結(jié)果加入到user engagement objectives中(Youtube認(rèn)為這些指標(biāo)的position bias比較大)。
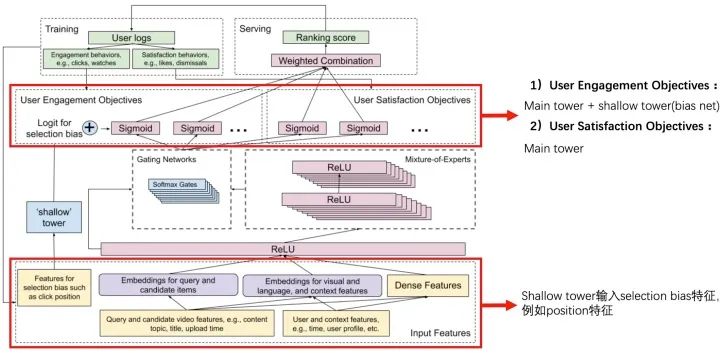
6. MMoE+ESMM結(jié)合
MMoE是使用expert+gate的方式替代hard parameter sharing,讓不相關(guān)的任務(wù)也可以學(xué)習(xí)的很好。ESMM聚焦于尋找多目標(biāo)的任務(wù)中本身就存在的聯(lián)系,來解決SSB和DS等問題,更好的建模。那么這兩類方法能不能結(jié)合呢?是我們后續(xù)需要探索的方向。
7. 其它關(guān)于MTL模型在推薦場景的工作
7.1 阿里 DUPN
對應(yīng)論文:《Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks》
多任務(wù)學(xué)習(xí)的優(yōu)勢:可共享一部分網(wǎng)絡(luò)結(jié)構(gòu),比如多個任務(wù)共享embedding參數(shù)。學(xué)習(xí)到的用戶、商品embedding向量可遷移到其它任務(wù)中。本文提出了一種多任務(wù)模型DUPN:
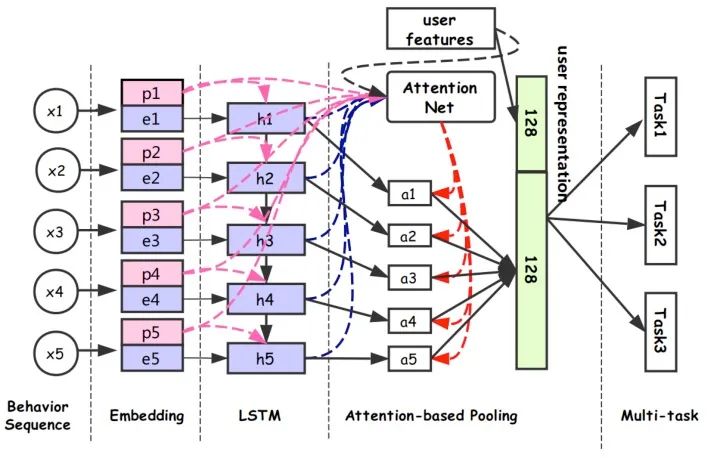
DUPN模型分為行為序列層、Embedding層、LSTM層、Attention層、下游多任務(wù)層。
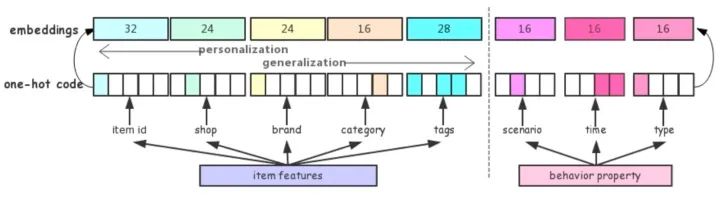
(1)行為序列層:輸入用戶的行為序列 ,其中每個行為都有兩部分組成,分別是item和property項。property項表示此次行為的屬性,比如場景(搜索、推薦等場景)、時間、類型(點擊、購買、加購等)。item包括商品id和一些side-information(比如店鋪id、brand等)。其實很多場景都用了side-information,我理解主要原因有兩點:
side-information的embedding量級要比商品id小很多,這樣用side-information來近似替代item_id,訓(xùn)練起來更容易; 可一定程度上解決商品的冷啟動問題,因為雖然很多時候拿不到item id,但是還是能獲得一些屬性信息的。
(2)Embedding層,主要多item和property的特征做處理。
(3)LSTM層:得到每一個行為的Embedding表示之后,首先通過一個LSTM層,把序列信息考慮進(jìn)來。
(4)Attention層:區(qū)分不同用戶行為的重要程度,經(jīng)過attention層得到128維向量,拼接上128維的用戶向量,最終得到一個256維向量作為用戶的表達(dá)。
(5)下游多任務(wù)層:CTR、L2R(Learning to Rank)、用戶達(dá)人偏好FIFP、用戶購買力度量PPP等。
另外,文中也提到了兩點多任務(wù)模型的使用技巧:
天級更新模型:隨著時間和用戶興趣的變化,ID特征的Embedding需要不斷更新,但每次都全量訓(xùn)練模型的話,需要耗費很長的時間。通常的做法是每天使用前一天的數(shù)據(jù)做增量學(xué)習(xí),這樣一方面能使訓(xùn)練時間大幅下降;另一方面可以讓模型更貼近近期數(shù)據(jù)。 模型拆分:由于CTR任務(wù)是point-wise的,如果有1w個物品的話,需要計算1w次結(jié)果,如果每次都調(diào)用整個模型的話,其耗費是十分巨大的。其實User Reprentation只需要計算一次就好。因此我們會將模型進(jìn)行一個拆解,使得紅色部分只計算一次,而藍(lán)色部分可以反復(fù)調(diào)用紅色部分的結(jié)果進(jìn)行多次計算。
7.2 阿里
對應(yīng)論文:之前論文名字《Conversion Rate Prediction via Post-Click Behaviour Modeling》,現(xiàn)在論文名字 《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》,對應(yīng)的都是一篇論文。
可以看作是ESMM的升級版。ESMM中有兩個子網(wǎng)絡(luò),分別是Main Task用于預(yù)估CVR值,Auxiliary Tasks用于預(yù)估CTR值。兩個網(wǎng)絡(luò)共享Embedding部分。Loss分為兩部分,一是CTR預(yù)估帶來的loss,二是pCTCVR(pCTR * pCVR)帶來的loss。CTCVR是從impression到buy,CTR是從impression到click,所以CTR和CTCVR都可以從整個impression樣本空間進(jìn)行訓(xùn)練,一定程度的消除了樣本選擇偏差。
但對于CVR預(yù)估來說,ESMM模型仍面臨一定的樣本稀疏問題,因為click到buy的樣本非常少。 但其實一個用戶在購買某個商品之前往往會有一些其他的行為,比如將商品加入購物車或者心愿單。如下圖所示:
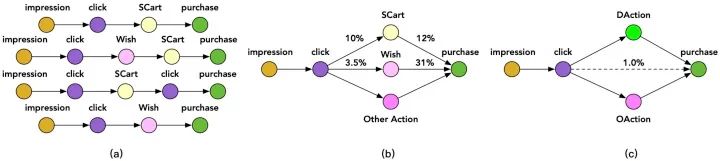
文中把加購物車或者心愿單的行為稱作Deterministic Action (DAction) ,表示購買目的很明確的一類行為。而其他對購買相關(guān)性不是很大的行為稱作Other Action(OAction) 。那原來的 Impression→Click→Buy購物過程就變?yōu)镮mpression→Click→DAction/OAction→Buy過程。
模型結(jié)構(gòu):
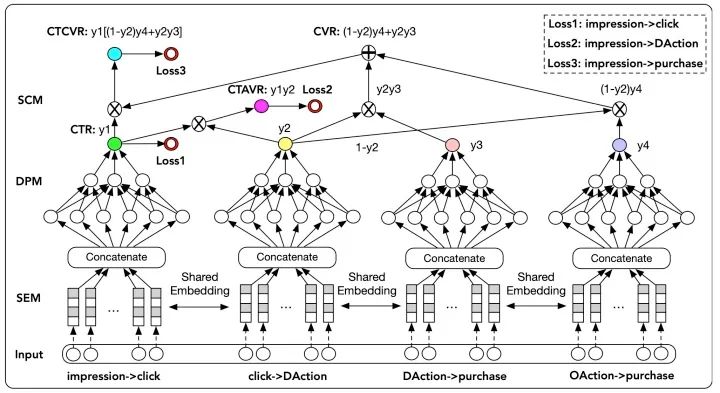
那么該模型的多個任務(wù)分別是:Y1:點擊率 ; Y2:點擊到DAction的概率; Y3:DAction到購買的概率; Y4:OAction到購買的概率。
并且從上圖看出,模型共有3個loss,計算過程分別是:
pCTR:Impression→Click的概率是第一個網(wǎng)絡(luò)的輸出。 pCTAVR:Impression→Click→DAction的概率,pCTAVR = Y1 * Y2,由前兩個網(wǎng)絡(luò)的輸出結(jié)果相乘得到。 pCTCVR:Impression→Click→DAction/OAction→Buy的概率,pCTCVR = CTR * CVR = Y1 * [(1 - Y2) * Y4 + Y2 * Y3],由四個網(wǎng)絡(luò)的輸出共同得到。其中CVR=(1 - Y2) * Y4 + Y2 * Y3。是因為從點擊到DAction和點擊到OAction是對立事件。
隨后通過三個logloss分別計算三部分的損失,最終損失函數(shù)由三部分加權(quán)得到。具體公式我就不再貼了,可以去源論文看一下。
7.3 阿里 DeepMCP
對應(yīng)論文:《Representation Learning-Assisted Click-Through Rate Prediction》
DeepMCP模型是阿里19年提出的一個廣告點擊率預(yù)估,不同于傳統(tǒng)的CTR預(yù)估模型刻畫特征-CTR之間的聯(lián)系,該模型采用多任務(wù)學(xué)習(xí)的方式進(jìn)行聯(lián)合訓(xùn)練進(jìn)一步挖掘用戶-廣告、廣告-廣告之間的信息從而使得系統(tǒng)對于特征-CTR之間聯(lián)系的刻畫更加準(zhǔn)確。該模型主要包括Prediction subnet 、Matching subnet 、Correlation subnet。模型結(jié)構(gòu)如下:
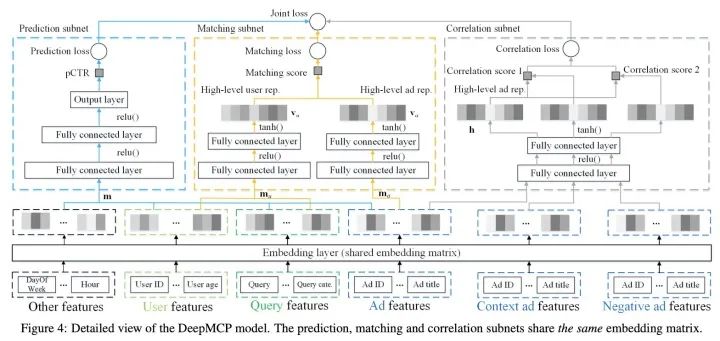
Prediction subnet
這一部分可以換成任意CTR預(yù)估DNN結(jié)構(gòu),本文使用的是簡單的MLP。
Matching subnet
Matching subnet主要是捕捉user-item的關(guān)系,幫助學(xué)習(xí)到更有用的user和item的表示。推薦領(lǐng)域中,傳統(tǒng)矩陣分解方法,通常是通過user id以及item id的隱向量的內(nèi)積得到rating score。而本文使用的是user以及item的全部feature。Matching subnet是一個雙塔結(jié)構(gòu),將user feature以及query feature輸入其中一側(cè)得到高階user表示,另一部分則是item feature得到的表示。值得注意的是,這里最后一層得到的表示,經(jīng)過的激活函數(shù)是tanh而非ReLU,原因是ReLU會導(dǎo)致大量維度為0,從而導(dǎo)致向量點積接近0。本文實驗使用的loss是point-wise的loss,作者說明了同樣可以換成pair-wise。
Correlation subnet
這一部分主要是刻畫item-item關(guān)系。這里使用skip gram形式,同一個時間窗內(nèi)用戶點擊序列認(rèn)為他們之間存在關(guān)系,作為正樣本,不在的則為負(fù)樣本,學(xué)習(xí)表示。
訓(xùn)練及預(yù)測如下圖:
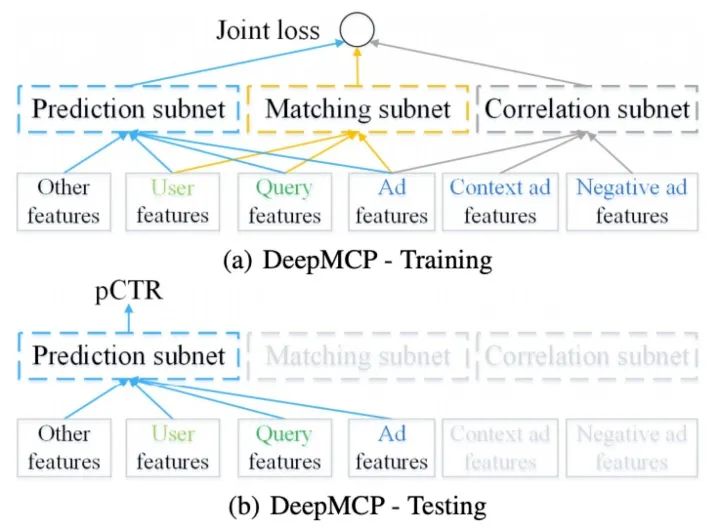
訓(xùn)練過程三部分聯(lián)合訓(xùn)練,共享embedding部分參數(shù)。線上測試部分只需要Prediction subnet,得到結(jié)果。
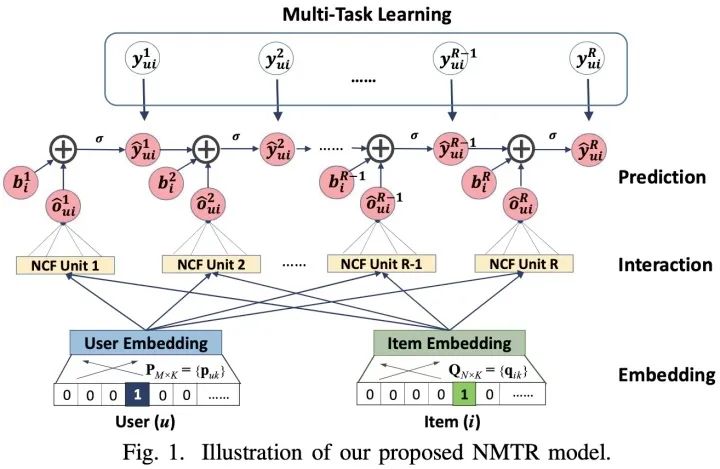
7.4 NMTR
對應(yīng)論文:《Neural Multi-task Recommendation from Multi-behavior Data》
大多數(shù)現(xiàn)有的推薦系統(tǒng)只會用到用戶單一類型的行為數(shù)據(jù),例如在電子商務(wù)中可能只會使用到用戶購買的行為數(shù)據(jù)。但是其他類型的用戶行為數(shù)據(jù)也可以提供非常有價值的信號,例如點擊、加購物車等。對此提出了一種新的解決方案NMTR(Neural Multi-Task Recommendation)來學(xué)習(xí)用戶的多行為數(shù)據(jù)。
在現(xiàn)有的諸多模型中, 大家都嘗試挖掘和利用用戶的其他行為數(shù)據(jù),例如ESMM等,用到了用戶的點擊行為來輔助CVR等任務(wù)的學(xué)習(xí)。這篇文章所述的方法在很多實踐中也都有所驗證,例如Zohar Komarovsky的這篇博客《Deep Multi-Task Learning — 3 Lessons Learned》中也談到了類似的實踐經(jīng)驗。地址:https://towardsdatascience.com/deep-multi-task-learning-3-lessons-learned-7d0193d71fd6
該論文的核心思想就是:
采用MTL的方式從用戶的多行為數(shù)據(jù)中進(jìn)行建模; 為了捕捉用戶的行為關(guān)系,采用級聯(lián)(Cascaded way)的方式進(jìn)行構(gòu)建;
NMTR模型的核心框架如下:
8. 多目標(biāo)預(yù)估中的其它問題
通過多任務(wù)學(xué)習(xí)訓(xùn)練一個模型預(yù)估多個目標(biāo),然后線上融合多個目標(biāo)進(jìn)行排序。多個目標(biāo)融合的時候很多公司都是加權(quán)融合,比如更看重時長可能時長的權(quán)重就大些,更看重分享,分享的權(quán)重就大些,加權(quán)系數(shù)一般通過AB實驗調(diào)整然后固定,這樣帶來的問題就是,當(dāng)模型不斷迭代的時候,這個系數(shù)可能就不合適了,經(jīng)常會出現(xiàn)的問題是加權(quán)系數(shù)影響模型的迭代效率。具體多個目標(biāo)怎么融合,這里面機(jī)制發(fā)揮的空間比較大,當(dāng)然也有一些這方面的研究工作。
(1)最簡單的辦法,我們可以整合不同tasks的loss function,然后簡單求和。這種方法存在一些不足,比如當(dāng)模型收斂時,有一些task的表現(xiàn)比較好,而另外一些task的表現(xiàn)卻慘不忍睹。其背后的原因是不同的損失函數(shù)具有不同的尺度,某些損失函數(shù)的尺度較大,從而影響了尺度較小的損失函數(shù)發(fā)揮作用。這個問題的解決方案是把多任務(wù)損失函數(shù)“簡單求和”替換為“加權(quán)求和”。加權(quán)可以使得每個損失函數(shù)的尺度一致,但也帶來了新的問題:加權(quán)的超參難以確定。幸運的是,有一篇論文《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》通過“不確定性(uncertainty)”來調(diào)整損失函數(shù)中的加權(quán)超參,使得每個任務(wù)中的損失函數(shù)具有相似的尺度。該算法的keras版本實現(xiàn),詳見GitHub地址:yaringal/multi-task-learning-example
(2)最近基于貝葉斯優(yōu)化的自動調(diào)參方法對于多目標(biāo)參數(shù)尋優(yōu)是一個很火熱的討論方向。
(3)還有多目標(biāo)常常存在的問題是,指標(biāo)a的提升常常伴隨著指標(biāo)b的下降。阿里在recsys 2019發(fā)表的文章《A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation》中使用帕累托最優(yōu)的思想,生成多組權(quán)重參數(shù),目的是為了在不損害a指標(biāo)的情況,提升b指標(biāo),感興趣的同學(xué)也可以看一下。
9. 工業(yè)界案例分享
多目標(biāo)排序和多任務(wù)學(xué)習(xí)的應(yīng)用,這兩年在工業(yè)界有很多嘗試,下面是一些經(jīng)典案例:
(1)美團(tuán)
美團(tuán)“猜你喜歡”深度學(xué)習(xí)排序模型實踐,地址:https://mp.weixin.qq.com/s/jdRu-cishwV8qBmGLTFJCA
(2)知乎
進(jìn)擊的下一代推薦系統(tǒng):多目標(biāo)學(xué)習(xí)如何讓知乎用戶互動率提升100%?,地址:https://mp.weixin.qq.com/s/J0j9NwSNhxab6bXqBBzaUw 「回顧」知乎推薦頁Ranking經(jīng)驗分享,地址:https://mp.weixin.qq.com/s/GUMz-HfbjQvzdGVQkKz4zA
(3)美圖
當(dāng)推薦遇到社交:美圖的推薦算法設(shè)計優(yōu)化實踐,地址:https://mp.weixin.qq.com/s/Eih4J51C8Eh-cuZ8vznESg 多任務(wù)學(xué)習(xí)在美圖推薦排序的近期實踐,地址:https://mp.weixin.qq.com/s/-rw2Gecv-QOSW33Q8QTfcA
(4)阿里
阿里淘寶:Multi Task Learning在工業(yè)界如何更勝一籌,地址:https://developer.aliyun.com/article/568166 阿里UC:UC 信息流推薦模型在多目標(biāo)和模型優(yōu)化方面的進(jìn)展,地址:https://mp.weixin.qq.com/s/FXlxT6qSridawZDIdGD1mw 阿里淘系:從谷歌到阿里,談?wù)劰I(yè)界推薦系統(tǒng)多目標(biāo)預(yù)估的兩種范式,地址:https://zhuanlan.zhihu.com/p/125507748 阿里UC:信息流短視頻時長多目標(biāo)優(yōu)化(從技術(shù)角度聊聊,短視頻為何讓人停不下來?),地址:https://mp.weixin.qq.com/s/lb5b-7ImTI0hlFwIBkpqxQ 阿里1688:深度學(xué)習(xí)在阿里B2B電商推薦系統(tǒng)中的實踐,地址:https://mp.weixin.qq.com/s/OU_alEVLPyAKRjVlDv1o-w
(5)YouTube
Youtube 排序系統(tǒng):Recommending What Video to Watch Next,地址:https://zhuanlan.zhihu.com/p/82584437
(6)蘑菇街
電商多目標(biāo)優(yōu)化小結(jié),地址:https://zhuanlan.zhihu.com/p/76413089
(7)騰訊
微信「看一看」 推薦排序技術(shù)揭秘,地址:https://mp.weixin.qq.com/s/_hGIdl9Y7hWuRDeCmZUMmg 詳文解讀微信「看一看」多模型內(nèi)容策略與召回,地址:https://mp.weixin.qq.com/s/s03njUVj1gHTOS0GSVgDLg
(8)花椒直播
深度學(xué)習(xí)在花椒直播中的應(yīng)用——排序算法篇,地址:https://mp.weixin.qq.com/s/e6Spp7smIEUUExJxHzUOFA
(9)微博
機(jī)器學(xué)習(xí)在熱門微博推薦系統(tǒng)的應(yīng)用,地址:https://mp.weixin.qq.com/s/9oguGl72WQqSVRJC7CRvEQ
(10)京東
【技術(shù)分享】京東電商廣告和推薦的機(jī)器學(xué)習(xí)系統(tǒng)實踐,地址:https://mp.weixin.qq.com/s/PYMR97nIzS3yp5-vkyhM_w
(11)BIGO
BIGO | 內(nèi)容流多目標(biāo)排序優(yōu)化,地址:https://mp.weixin.qq.com/s/3AMW-vUr2S9FBSDUr_JhpA
10. Reference
由于參考的文獻(xiàn)較多,我把每篇參考文獻(xiàn)按照自己的學(xué)習(xí)思路,進(jìn)行了詳細(xì)的歸類和標(biāo)注。
推薦系統(tǒng)中多目標(biāo)綜述文章:
推薦系統(tǒng)中的多任務(wù)學(xué)習(xí),地址:https://lumingdong.cn/multi-task-learning-in-recommendation-system.html#dfref-footnote-5 從谷歌到阿里,談?wù)劰I(yè)界推薦系統(tǒng)多目標(biāo)預(yù)估的兩種范式,地址:https://mp.weixin.qq.com/s/NCtTgEh8iRRZGhcrS6Gd8g 推薦系統(tǒng)中的多目標(biāo)學(xué)習(xí) - 奔奔的文章 - 知乎 https://zhuanlan.zhihu.com/p/183760759 多任務(wù)學(xué)習(xí)在推薦算法中的應(yīng)用,地址:https://mp.weixin.qq.com/s/-SHLp26oGDDp9HG-23cetg Multi-task多任務(wù)模型在推薦算法中應(yīng)用總結(jié)1 - 夢想做個翟老師的文章 - 知乎 https://zhuanlan.zhihu.com/p/78762586 Multi-task多任務(wù)學(xué)習(xí)在推薦算法中應(yīng)用(2) - 夢想做個翟老師的文章 - 知乎 https://zhuanlan.zhihu.com/p/91285359 深度總結(jié) | 多任務(wù)學(xué)習(xí)方法在推薦中的演變,地址:https://mp.weixin.qq.com/s/ifTNRW0W7-P_LyfNldtavQ 推薦精排模型之多目標(biāo)模型 - billlee的文章 - 知乎 https://zhuanlan.zhihu.com/p/221738556 推薦系統(tǒng)中如何做多目標(biāo)優(yōu)化,地址:https://mp.weixin.qq.com/s/z7bLfTujt3tP035YgQv_jQ 推薦系統(tǒng)rank模塊-多?標(biāo)排序算法(一) - 邁書傑的文章 - 知乎 https://zhuanlan.zhihu.com/p/65001130
推薦多目標(biāo)工業(yè)界案例:
進(jìn)擊的下一代推薦系統(tǒng):多目標(biāo)學(xué)習(xí)如何讓知乎用戶互動率提升100%?,地址:https://mp.weixin.qq.com/s/J0j9NwSNhxab6bXqBBzaUw UC 信息流推薦模型在多目標(biāo)和模型優(yōu)化方面的進(jìn)展,地址:https://mp.weixin.qq.com/s/FXlxT6qSridawZDIdGD1mw 當(dāng)推薦遇到社交:美圖的推薦算法設(shè)計優(yōu)化實踐,地址:https://mp.weixin.qq.com/s/Eih4J51C8Eh-cuZ8vznESg 多任務(wù)學(xué)習(xí)在美圖推薦排序的近期實踐,地址:https://mp.weixin.qq.com/s/-rw2Gecv-QOSW33Q8QTfcA Multi Task Learning在工業(yè)界如何更勝一籌,地址:https://developer.aliyun.com/article/568166
如何對不同目標(biāo)做加權(quán):
為什么基于貝葉斯優(yōu)化的自動調(diào)參沒有大范圍使用?- 知乎 https://www.zhihu.com/question/33711002 帕累托的角度解推薦系統(tǒng)中的多目標(biāo)優(yōu)化問題,地址:https://mp.weixin.qq.com/s/xqlvFRts3S29DAgzBV3_cA 推薦多目標(biāo)進(jìn)階之自適應(yīng)權(quán)重學(xué)習(xí) - billlee的文章 - 知乎 https://zhuanlan.zhihu.com/p/238125972 多目標(biāo)學(xué)習(xí)之自適應(yīng)權(quán)重學(xué)習(xí)進(jìn)階 - billlee的文章 - 知乎 https://zhuanlan.zhihu.com/p/252986597
多任務(wù)模型學(xué)習(xí):
詳解谷歌之多任務(wù)學(xué)習(xí)模型MMoE(KDD 2018),地址:https://zhuanlan.zhihu.com/p/55752344 多目標(biāo)優(yōu)化概論及基礎(chǔ)算法ESMM與MMOE對比,地址:https://mp.weixin.qq.com/s/8o2CEMH2XLmo6NwNsMX23w Youtube 排序系統(tǒng):Recommending What Video to Watch Next - 魔鬼吊兒郎的文章 - 知乎 https://zhuanlan.zhihu.com/p/82584437 多目標(biāo)學(xué)習(xí)與推薦系統(tǒng) - 雪的味道的文章 - 知乎 https://zhuanlan.zhihu.com/p/144030768 推薦系統(tǒng)多任務(wù)學(xué)習(xí)上分神技!,地址:https://mp.weixin.qq.com/s/8quc62wB4cXTcZaesmR7JQ Deep Multi-Task Learning — 3 Lessons Learned,地址:https://towardsdatascience.com/deep-multi-task-learning-3-lessons-learned-7d0193d71fd6 Multi-task Learning的三個小知識 - mountain blue的文章 - 知乎 https://zhuanlan.zhihu.com/p/56613537
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群請掃碼: