
手把手帶你爬蟲 | 爬取起點(diǎn)小說(shuō)網(wǎng)
很多同學(xué)都喜歡看小說(shuō),尤其是程序員群體,對(duì)武俠小說(shuō),科幻小說(shuō)都很著迷,最近的修仙的小說(shuō)也很多,比如凡人修仙傳,武動(dòng)乾坤,斗破蒼穹等等,今天分享一個(gè)用Python來(lái)爬取小說(shuō)的小腳本!
目標(biāo)
爬取一本仙俠類的小說(shuō)下載并保存為txt文件到本地。本例為“大周仙吏”。

項(xiàng)目準(zhǔn)備
軟件:Pycharm
第三方庫(kù):requests,fake_useragent,lxml
網(wǎng)站地址:https://book.qidian.com
網(wǎng)站分析
打開網(wǎng)址:

網(wǎng)址變?yōu)椋?/span>https://book.qidian.com/info/1020580616#Catalog
判斷是否為靜態(tài)加載網(wǎng)頁(yè),Ctrl+U打開源代碼,Ctrl+F打開搜索框,輸入:第一章。

在這里是可以找到的,判定為靜態(tài)加載。
反爬分析
同一個(gè)ip地址去多次訪問(wèn)會(huì)面臨被封掉的風(fēng)險(xiǎn),這里采用fake_useragent,產(chǎn)生隨機(jī)的User-Agent請(qǐng)求頭進(jìn)行訪問(wèn)。
代碼實(shí)現(xiàn)
1.導(dǎo)入相對(duì)應(yīng)的第三方庫(kù),定義一個(gè)class類繼承object,定義init方法繼承self,主函數(shù)main繼承self。
import??requests
from?fake_useragent?import?UserAgent
from?lxml?import?etree
class?photo_spider(object):
????def?__init__(self):
????????self.url?=?'https://book.qidian.com/info/1020580616#Catalog'
????????ua?=?UserAgent(verify_ssl=False)
????????#隨機(jī)產(chǎn)生user-agent
????????for?i?in?range(1,?100):
????????????self.headers?=?{
????????????????'User-Agent':?ua.random
????????????}
????def?mian(self):
?????pass
if?__name__?==?'__main__':
????spider?=?qidian()
????spider.main()
2.發(fā)送請(qǐng)求,獲取網(wǎng)頁(yè)。
????def?get_html(self,url):
????????response=requests.get(url,headers=self.headers)
????????html=response.content.decode('utf-8')
????????return?html
3.獲取圖片的鏈接地址。
import?requests
from?lxml?import?etree
from?fake_useragent?import?UserAgent
class?qidian(object):
????def?__init__(self):
????????self.url?=?'https://book.qidian.com/info/1020580616#Catalog'
????????ua?=?UserAgent(verify_ssl=False)
????????for?i?in?range(1,?100):
????????????self.headers?=?{
????????????????'User-Agent':?ua.random
????????????}
????def?get_html(self,url):
????????response=requests.get(url,headers=self.headers)
????????html=response.content.decode('utf-8')
????????return?html
????def?parse_html(self,html):
????????target=etree.HTML(html)
????????links=target.xpath('//ul[@class="cf"]/li/a/@href')#獲取鏈接
????????names=target.xpath('//ul[@class="cf"]/li/a/text()')#獲取每一章的名字
????????for?link,name?in?zip(links,names):
????????????print(name+'\t'+'https:'+link)
????def?main(self):
????????url=self.url
????????html=self.get_html(url)
????????self.parse_html(html)
if?__name__?==?'__main__':
????spider=qidian()
????spider.main()
打印結(jié)果:
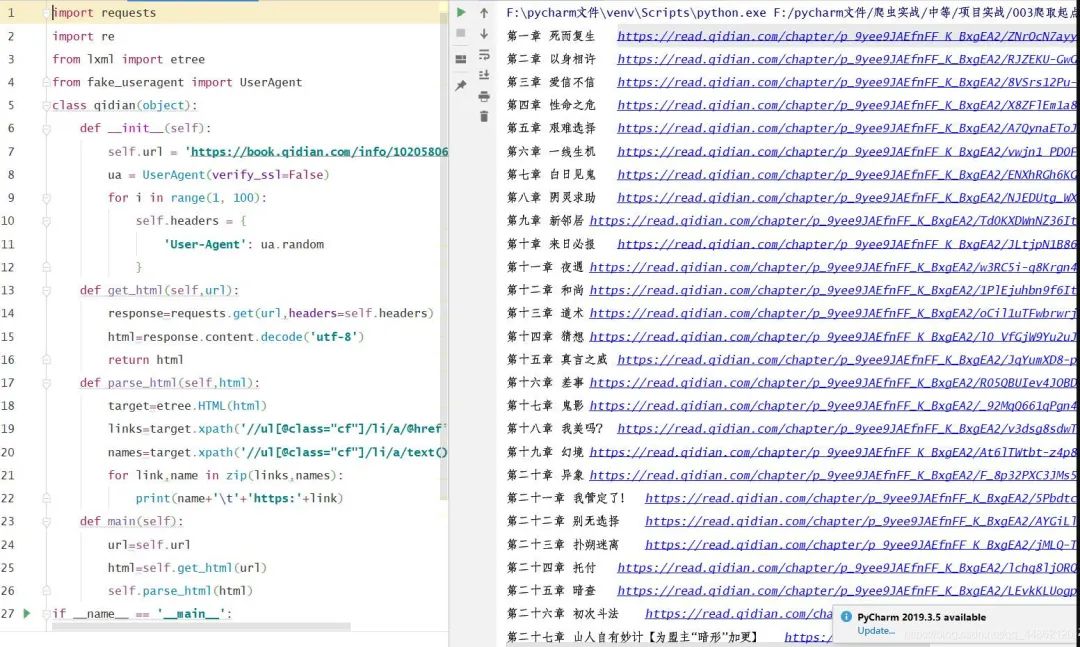
4.解析鏈接,獲取每一章內(nèi)容。
????def?parse_html(self,html):
????????target=etree.HTML(html)
????????links=target.xpath('//ul[@class="cf"]/li/a/@href')
????????for?link?in?links:
????????????host='https:'+link
????????????#解析鏈接地址
????????????res=requests.get(host,headers=self.headers)
????????????c=res.content.decode('utf-8')
????????????target=etree.HTML(c)
????????????names=target.xpath('//span[@class="content-wrap"]/text()')
????????????results=target.xpath('//div[@class="read-content?j_readContent"]/p/text()')
????????????for?name?in?names:
????????????????print(name)
????????????for?result?in?results:
????????????????print(result)
打印結(jié)果:(下面內(nèi)容過(guò)多,只貼出一部分。)

5.保存為txt文件到本地。
?with?open('F:/pycharm文件/document/'?+?name?+?'.txt',?'a')?as?f:
??????for?result?in?results:
??????????#print(result)
??????????f.write(result+'\n')
效果顯示:
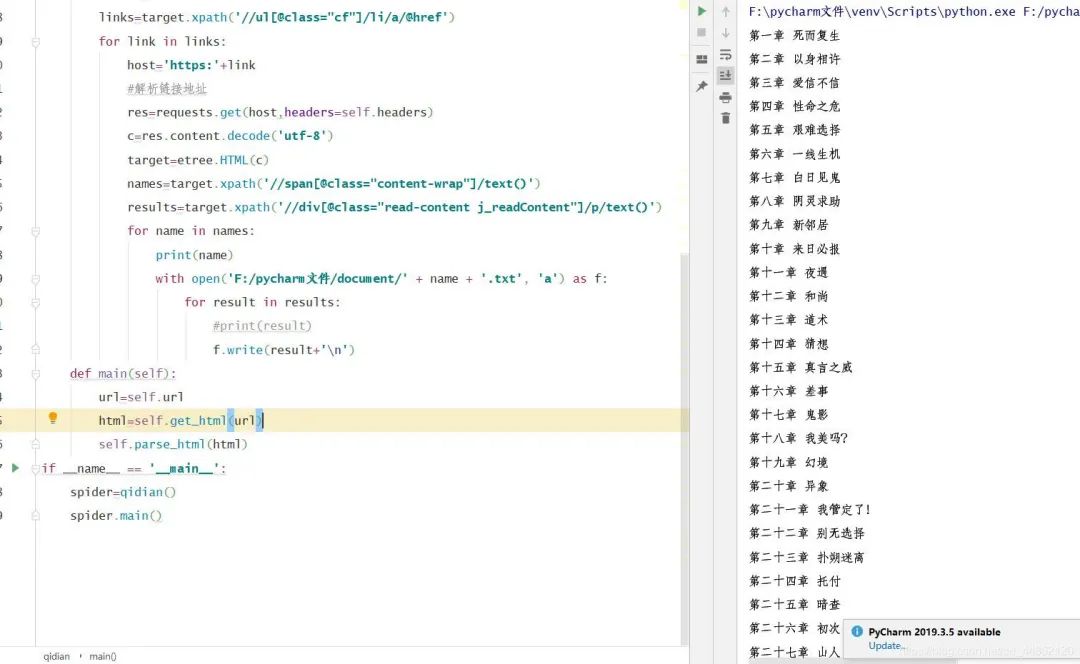
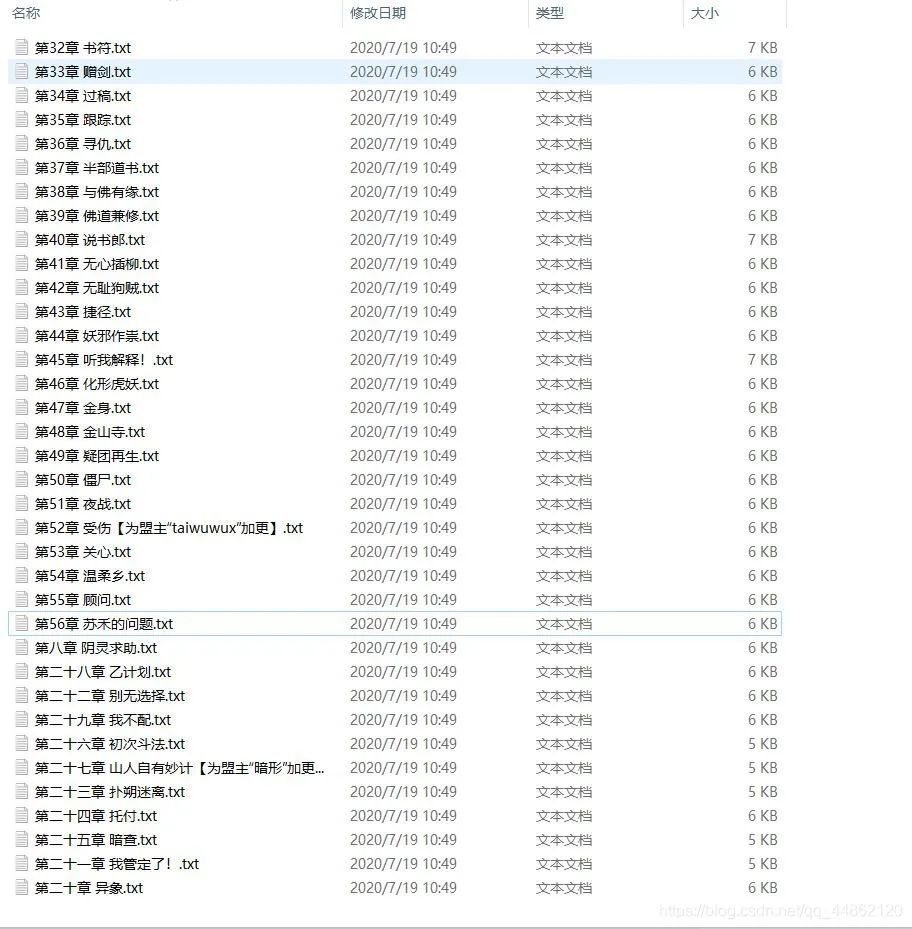
打開文件目錄:
完整代碼
import?requests
from?lxml?import?etree
from?fake_useragent?import?UserAgent
class?qidian(object):
????def?__init__(self):
????????self.url?=?'https://book.qidian.com/info/1020580616#Catalog'
????????ua?=?UserAgent(verify_ssl=False)
????????for?i?in?range(1,?100):
????????????self.headers?=?{
????????????????'User-Agent':?ua.random
????????????}
????def?get_html(self,url):
????????response=requests.get(url,headers=self.headers)
????????html=response.content.decode('utf-8')
????????return?html
????def?parse_html(self,html):
????????target=etree.HTML(html)
????????links=target.xpath('//ul[@class="cf"]/li/a/@href')
????????for?link?in?links:
????????????host='https:'+link
????????????#解析鏈接地址
????????????res=requests.get(host,headers=self.headers)
????????????c=res.content.decode('utf-8')
????????????target=etree.HTML(c)
????????????names=target.xpath('//span[@class="content-wrap"]/text()')
????????????results=target.xpath('//div[@class="read-content?j_readContent"]/p/text()')
????????????for?name?in?names:
????????????????print(name)
????????????????with?open('F:/pycharm文件/document/'?+?name?+?'.txt',?'a')?as?f:
????????????????????for?result?in?results:
????????????????????????#print(result)
????????????????????????f.write(result+'\n')
????def?main(self):
????????url=self.url
????????html=self.get_html(url)
????????self.parse_html(html)
if?__name__?==?'__main__':
????spider=qidian()
????spider.main()
程序員GitHub,現(xiàn)已正式上線! 接下來(lái)我們將會(huì)在該公眾號(hào)上,專注為大家分享GitHub上有趣的開源庫(kù)包括Python,Java,Go,前端開發(fā)等優(yōu)質(zhì)的學(xué)習(xí)資源和技術(shù),分享一些程序員圈的新鮮趣事。
推薦閱讀:
這個(gè)GitHub 1400星的Git魔法書火了,斯坦福校友出品丨有中文版 賊 TM 好用的 Java 工具類庫(kù) 超全Python IDE武器庫(kù)大總結(jié),優(yōu)缺點(diǎn)一目了然! 秋招來(lái)襲!GitHub28.5顆星!這個(gè)匯聚阿里,騰訊,百度,美團(tuán),頭條的面試題庫(kù)必須安利! 收獲10400顆星!這個(gè)Python庫(kù)有點(diǎn)黑科技,竟然可以偽造很多'假'的數(shù)據(jù)! 牛掰了!這個(gè)Python庫(kù)有點(diǎn)逆天了,竟然能把圖片,視頻無(wú)損清晰放大!
點(diǎn)這里,獲取一大波福利


評(píng)論
圖片
表情