
人臉?biāo)惴ㄏ盗校篗TCNN人臉檢測詳解
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

人臉檢測的概念
人臉檢測是一種在多種應(yīng)用中使用的計(jì)算機(jī)技術(shù),可以識別數(shù)字圖像中的人臉。人臉檢測還指人類在視覺場景中定位人臉的過程。
人臉檢測可以視為目標(biāo)檢測的一種特殊情況。在目標(biāo)檢測中,任務(wù)是查找圖像中給定類的所有對象的位置和大小。例如行人和汽車。

人臉檢測示例
在人臉檢測中應(yīng)用較廣的算法就是MTCNN( Multi-task Cascaded Convolutional Networks的縮寫)。MTCNN算法是一種基于深度學(xué)習(xí)的人臉檢測和人臉對齊方法,它可以同時(shí)完成人臉檢測和人臉對齊的任務(wù),相比于傳統(tǒng)的算法,它的性能更好,檢測速度更快。
本文目的不是為了強(qiáng)調(diào)MTCNN模型的訓(xùn)練,而是如何使用MTCNN提取人臉區(qū)域和特征點(diǎn),為后續(xù)例如人臉識別和人臉圖片預(yù)處理做鋪墊。
接下來介紹MTCNN的使用,讓大家對其有一個(gè)直觀的感受,再深入了解其原理。
MTCNN的使用
Paper地址:https://kpzhang93.github.io/MTCNN_face_detection_alignment/
github鏈接:https://github.com/kpzhang93/MTCNN_face_detection_alignment
其他版本:https://github.com/AITTSMD/MTCNN-Tensorflow
作者是基于caffe實(shí)現(xiàn)的,因?yàn)楸救伺渲昧硕啻危际×耍虼藝L試了其他框架的,采用mxnet框架,當(dāng)然也附上了pytorch版本的。
本次使用的項(xiàng)目鏈接:https://github.com/YYuanAnyVision/mxnet_mtcnn_face_detection
其他參考:
pytorch版本:https://github.com/TropComplique/mtcnn-pytorch
第一步:將項(xiàng)目克隆下來
git clone https://github.com/YYuanAnyVision/mxnet_mtcnn_face_detection當(dāng)然很有可能會(huì)中途失敗,我自己也是嘗試多次都沒搞定,又慢又老是不行。不過之前分享過一個(gè)妙招,如果看過的小伙伴一定知道如何解決。
這里附上文章鏈接:
完美解決Github上下載項(xiàng)目失敗或速度太慢的問題
第二步:配置好所需的環(huán)境
mxnet的安裝非常容易,這里以我的電腦為例安裝GPU版本的mxnet
只需一行代碼即可完成安裝,首先查詢自己所安裝cuda的版本,并輸入對應(yīng)的指令即可
# 例如我的電腦是cuda 9.0的pip install mxnet-cu90
這里有補(bǔ)充說明https://pypi.org/project/mxnet-cu90/,更多內(nèi)容可以百度搜索解決。
第三步:運(yùn)行代碼
該項(xiàng)目已經(jīng)有預(yù)訓(xùn)練模型了,直接運(yùn)行main.py即可。
但是你一運(yùn)行,就會(huì)發(fā)現(xiàn) 哦豁,報(bào)錯(cuò)了。
這是因?yàn)樵擁?xiàng)目是用python2寫的,所以存在一些需要修改的地方。
問題一:ImportError: cannot import name 'izip' (報(bào)錯(cuò)文件 mtcnn_detector.py)
解決方案:python3中的zip就相當(dāng)于 python2 itertools里的izip
因此,只需要做以下修改即可,在mtcnn_detector.py將報(bào)錯(cuò)的from itertools import izip注釋掉,下面加一行試試看。
具體操作,在main.py中找到 from itertools import izip,并修改成下面即可。
#from itertools import izipizip = zip
解決了之后在運(yùn)行一次main.py
問題2:TypeError: 'float' object cannot be interpreted as an integer
類型錯(cuò)誤:“float”對象不能解釋為整數(shù)
解決方法:將報(bào)錯(cuò)的地方存在的 “/” 都修改成 “//” 即可,同類報(bào)錯(cuò),相同的解決方法。
python2和python3中運(yùn)算符的區(qū)別。
python3中 / 運(yùn)算的結(jié)果是含有浮點(diǎn)數(shù)的。而python2中/是等價(jià)于python3中的 // ,python3中// 表示向下取整的除法。
# 舉個(gè)例子在python3中 //print(3/2,3//2) # 輸出 1.5, 1
歷經(jīng)千辛萬苦,最終展示效果:
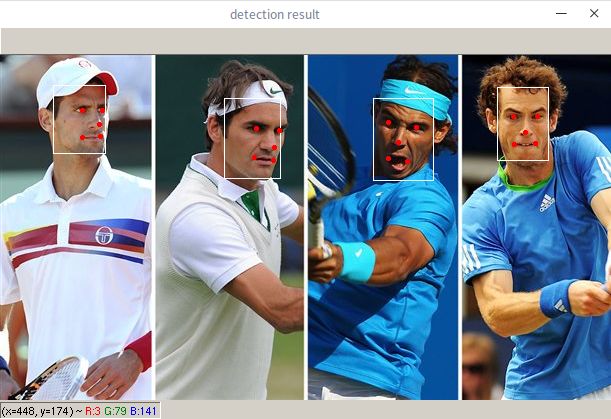
到這里我們已經(jīng)能夠檢測到人臉了,對于自己的圖片,只需要修改main.py中讀入的圖片路徑即可。更多自定義操作,例如批量處理和保存,可以根據(jù)自己的需求來添加。
MTCNN的原理
對于如此經(jīng)典的網(wǎng)絡(luò)僅僅掌握其使用還是不夠的,因此接下來將詳細(xì)的說明一下其內(nèi)在的原理。
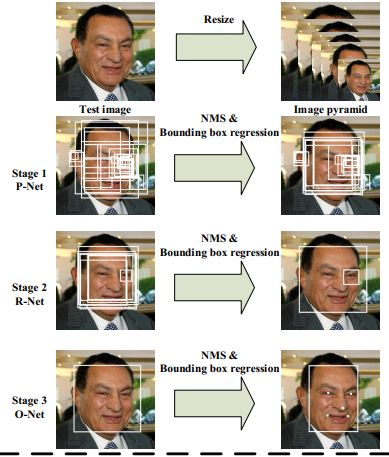
圖片來源與論文原文
從上圖可以知道主要包括四個(gè)操作,三個(gè)步驟。
1、圖像金字塔
對圖片進(jìn)行Resize操作,將原始圖像縮放成不同的尺度,生成圖像金字塔。然后將不同尺度的圖像送入到這三個(gè)子網(wǎng)絡(luò)中進(jìn)行訓(xùn)練,目的是為了可以檢測到不同大小的人臉,從而實(shí)現(xiàn)多尺度目標(biāo)檢測。
圖像金字塔是圖像中多尺度表達(dá)的一種。對于圖像金字塔的具體原理這里不詳細(xì)展開,有興趣可以參考這篇文章:https://zhuanlan.zhihu.com/p/80362140
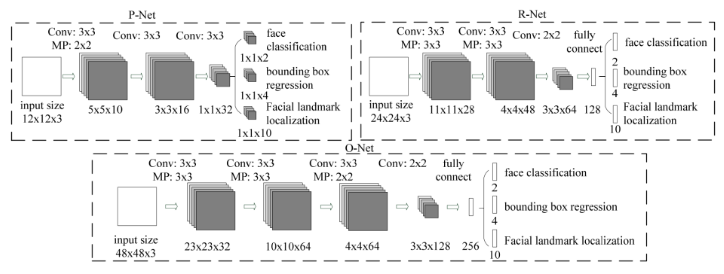
三個(gè)子網(wǎng)絡(luò)圖
2、P-Net(Proposal Network)
論文原文對P-Net的描述:該網(wǎng)絡(luò)結(jié)構(gòu)主要獲得了人臉區(qū)域的候選框和邊界框的回歸向量。然后基于預(yù)測邊界框回歸向量對候選框進(jìn)行矯正。在這之后,我們采用NMS來合并重疊率高的候選框。
P-Net是一個(gè)人臉區(qū)域的候選網(wǎng)絡(luò),該網(wǎng)絡(luò)的輸入一個(gè)12x12x3的圖像,通過3層的卷積之后,判斷這個(gè)12x12的圖像中是否存在人臉,并且給出人臉框的回歸和人臉關(guān)鍵點(diǎn)。
網(wǎng)絡(luò)的第一部分輸出是用來判斷該圖像是否存在人臉,輸出向量大小1x1x2,也就是兩個(gè)值。
網(wǎng)絡(luò)的第二部分給出框的精確位置,一般稱為框回歸。P-Net輸入的12×12的圖像塊可能并不是完美的人臉框的位置,如有的時(shí)候人臉并不正好為方形,有可能12×12的圖像偏左或偏右,因此需要輸出當(dāng)前框位置相對完美的人臉框位置的偏移。這個(gè)偏移大小為1×1×4,即表示框左上角的橫坐標(biāo)的相對偏移,框左上角的縱坐標(biāo)的相對偏移、框的寬度的誤差、框的高度的誤差。
網(wǎng)絡(luò)的第三部分給出人臉的5個(gè)關(guān)鍵點(diǎn)的位置。5個(gè)關(guān)鍵點(diǎn)分別對應(yīng)著左眼的位置、右眼的位置、鼻子的位置、左嘴巴的位置、右嘴巴的位置。每個(gè)關(guān)鍵點(diǎn)需要兩維來表示,因此輸出是向量大小為1×1×10。
3、R-Net(Refine Network)
論文原文對P-Net的描述:P-Net的所有候選框都輸入到R-Net中,該網(wǎng)絡(luò)結(jié)構(gòu)還是通過邊界框回歸和NMS來去掉大量的false-positive區(qū)域。
從網(wǎng)絡(luò)圖可以看到,只是由于該網(wǎng)絡(luò)結(jié)構(gòu)和P-Net網(wǎng)絡(luò)結(jié)構(gòu)有差異,多了一個(gè)全連接層,所以會(huì)取得更好的抑制false-positive的作用。在輸入R-Net之前,都需要縮放到24x24x3,網(wǎng)絡(luò)的輸出與P-Net是相同的,R-Net的目的是為了去除大量的非人臉框。
4、O-Net(Output Network)
論文原文對O-Net的描述:這個(gè)階段類似于第二階段,但是在這個(gè)階段在此階段,我們目的通過更多的監(jiān)督來識別面部區(qū)域。特別是,網(wǎng)絡(luò)將輸出五個(gè)面部關(guān)鍵點(diǎn)的位置。
從網(wǎng)絡(luò)圖可以看到,該層比R-Net層有多了一層卷積層,所以處理的結(jié)果會(huì)更加精細(xì)。輸入的圖像大小48x48x3,輸出包括N個(gè)邊界框的坐標(biāo)信息,score以及關(guān)鍵點(diǎn)位置。
總結(jié):
從P-Net到R-Net,再到最后的O-Net,網(wǎng)絡(luò)輸入的圖像越來越大,卷積層的通道數(shù)越來越多,網(wǎng)絡(luò)的深度(層數(shù))也越來越深,因此識別人臉的準(zhǔn)確率應(yīng)該也是越來越高的。
對各個(gè)網(wǎng)絡(luò)結(jié)果的作用理解之后,我們深入了解一下其所采用的損失函數(shù)。
MTCNN的損失函數(shù)
針對人臉識別問題,直接使用交叉熵代價(jià)函數(shù),對于框回歸和關(guān)鍵點(diǎn)定位,使用L2損失。最后把這三部分的損失各自乘以自身的權(quán)重累加起來,形成最后的總損失。
1、人臉識別損失函數(shù)(cross-entry loss)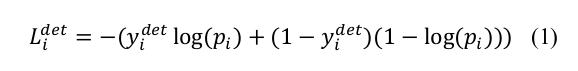
2、回歸框的損失函數(shù) (Euclidean loss)

3、關(guān)鍵點(diǎn)的損失函數(shù) (Euclidean loss)
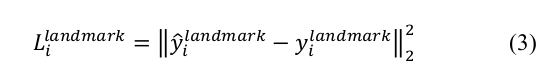
4、總損失
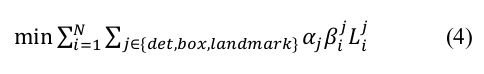
具體的各個(gè)公式的含義,大家應(yīng)該都明白,這里強(qiáng)調(diào)一下,最后的總損失前添加了一個(gè)權(quán)重 α ,即損失函數(shù)所對應(yīng)的權(quán)重是不一致的。詳細(xì)設(shè)置可以參看論文原文。

參考文獻(xiàn):
好消息!
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計(jì)數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會(huì)逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會(huì)請出群,謝謝理解~