
國內(nèi)外學(xué)者聯(lián)合撰寫,ChatGPT技術(shù)路線圖
英文原版:https://franxyao.github.io/blog.html與 彭昊,Tushar Khot
在 艾倫人工智能研究院 (Allen Institute for AI) 共同完成英文原稿
與 劍橋大學(xué)郭志江 共同翻譯為中文
感謝 上海交通大學(xué)何俊賢,加州大學(xué)洛杉磯分校魯盼,達特茅斯學(xué)院劉睿博 對初稿的討論與建議。
感謝 Raj Ammanabrolu (Allen Institute for AI), Peter Liu (Google Brain), Brendan Dolan-Gavitt (New York University), Denny Zhou (Google Brain) 對終稿的討論和建議,他們的建議極大程度上增加了本文的完整度。
正文
最近,OpenAI的預(yù)訓(xùn)練模型ChatGPT給人工智能領(lǐng)域的研究人員留下了深刻的印象和啟發(fā)。毫無疑問,它又強又聰明,且跟它說話很好玩,還會寫代碼。它在多個方面的能力遠遠超過了自然語言處理研究者們的預(yù)期。于是我們自然就有一個問題:ChatGPT 是怎么變得這么強的?它的各種強大的能力到底從何而來?在這篇文章中,我們試圖剖析 ChatGPT 的突現(xiàn)能力(Emergent Ability),追溯這些能力的來源,希望能夠給出一個全面的技術(shù)路線圖,來說明 GPT-3.5 模型系列以及相關(guān)的大型語言模型是如何一步步進化成目前的強大形態(tài)。
-
在國際學(xué)術(shù)界看來,ChatGPT / GPT-3.5 是一種劃時代的產(chǎn)物,它與之前常見的語言模型 (Bert/ Bart/ T5) 的區(qū)別,幾乎是導(dǎo)彈與弓箭的區(qū)別,一定要引起最高程度的重視。 -
在我跟國際同行的交流中,國際上的主流學(xué)術(shù)機構(gòu) (如斯坦福大學(xué),伯克利加州大學(xué)) 和主流業(yè)界研究院(如谷歌大腦,微軟研究院)都已經(jīng)全面擁抱大模型。 -
在當前這個階段,國內(nèi)的技術(shù)水準,學(xué)術(shù)視野,治學(xué)理念和國際前沿的差距似乎并沒有減少,反而正在擴大,如果現(xiàn)狀持續(xù)下去,極有可能出現(xiàn)技術(shù)斷代。 -
此誠危急存亡之秋。
多年以后,面對行刑隊,奧雷里亞諾·布恩迪亞上校將會回想起父親帶他去見識冰塊的那個遙遠的下午。—— 《百年孤獨》 加西亞·馬爾克斯
一、2020 版初代 GPT-3 與大規(guī)模預(yù)訓(xùn)練
初代GPT-3展示了三個重要能力:
-
語言生成:遵循提示詞(prompt),然后生成補全提示詞的句子。這也是今天人類與語言模型最普遍的交互方式。 -
上下文學(xué)習(xí) (in-context learning): 遵循給定任務(wù)的幾個示例,然后為新的測試用例生成解決方案。很重要的一點是,GPT-3雖然是個語言模型,但它的論文幾乎沒有談到“語言建模” (language modeling) —— 作者將他們?nèi)康膶懽骶Χ纪度氲搅藢ι舷挛膶W(xué)習(xí)的愿景上,這才是 GPT-3的真正重點。 -
世界知識:包括事實性知識 (factual knowledge) 和常識 (commonsense)。
那么這些能力從何而來呢?
基本上,以上三種能力都來自于大規(guī)模預(yù)訓(xùn)練:在有3000億單詞的語料上預(yù)訓(xùn)練擁有1750億參數(shù)的模型( 訓(xùn)練語料的60%來自于 2016 - 2019 的 C4 + 22% 來自于 WebText2 + 16% 來自于Books + 3%來自于Wikipedia)。其中:
-
語言生成的能力來自于語言建模的訓(xùn)練目標 (language modeling)。 -
世界知識來自 3000 億單詞的訓(xùn)練語料庫(不然還能是哪兒呢)。 -
模型的 1750 億參數(shù)是為了存儲知識,Liang et al. (2022) 的文章進一步證明了這一點。他們的結(jié)論是,知識密集型任務(wù)的性能與模型大小息息相關(guān)。 -
上下文學(xué)習(xí)的能力來源及為什么上下文學(xué)習(xí)可以泛化,仍然難以溯源。 直覺上,這種能力可能來自于同一個任務(wù)的數(shù)據(jù)點在訓(xùn)練時按順序排列在同一個 batch 中。然而,很少有人研究為什么語言模型預(yù)訓(xùn)練會促使上下文學(xué)習(xí),以及為什么上下文學(xué)習(xí)的行為與微調(diào) (fine-tuning) 如此不同。
令人好奇的是,初代的GPT-3有多強。其實比較難確定初代 GPT-3(在 OpenAI API 中被稱為davinci)到底是“強”還是“弱”。一方面,它合理地回應(yīng)了某些特定的查詢,并在許多數(shù)據(jù)集中達到了還不錯的性能;另一方面,它在許多任務(wù)上的表現(xiàn)還不如 T5 這樣的小模型(參見其原始論文)。在今天(2022 年 12 月)ChatGPT 的標準下,很難說初代的 GPT-3 是“智能的”。Meta 開源的 OPT 模型試圖復(fù)現(xiàn)初代 GPT-3,但它的能力與當今的標準也形成了尖銳的對比。許多測試過 OPT 的人也認為與現(xiàn)在的text-davinci-002相比,該模型確實 “不咋地”。盡管如此,OPT 可能是初代 GPT-3 的一個足夠好的開源的近似模型了(根據(jù) OPT 論文和斯坦福大學(xué)的 HELM 評估)。
雖然初代的 GPT-3 可能表面上看起來很弱,但后來的實驗證明,初代 GPT-3 有著非常強的潛力。這些潛力后來被代碼訓(xùn)練、指令微調(diào) (instruction tuning) 和基于人類反饋的強化學(xué)習(xí) (reinforcement learning with human feedback, RLHF) 解鎖,最終體展示出極為強大的突現(xiàn)能力。
二、從 2020 版 GPT-3 到 2022 版 ChatGPT
從最初的 GPT-3 開始,為了展示 OpenAI 是如何發(fā)展到ChatGPT的,我們看一下 GPT-3.5 的進化樹:
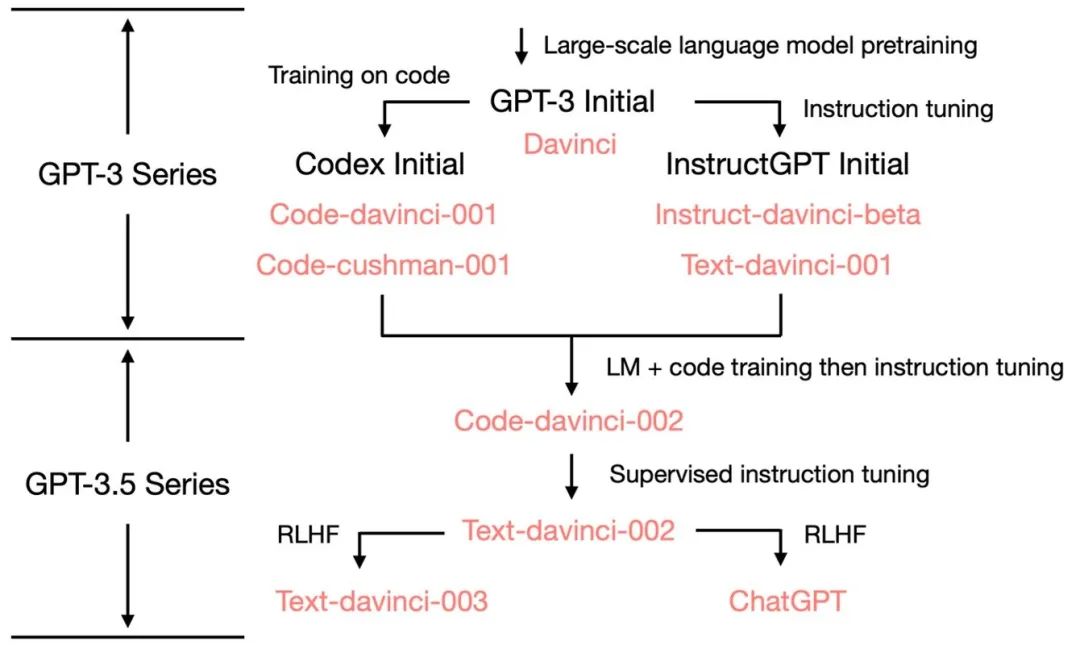
在 2020 年 7 月,OpenAI 發(fā)布了模型索引為的 davinci 的初代 GPT-3 論文,從此它就開始不斷進化。在 2021 年 7 月,Codex 的論文發(fā)布,其中初始的 Codex 是根據(jù)(可能是內(nèi)部的)120 億參數(shù)的 GPT-3 變體進行微調(diào)的。后來這個 120 億參數(shù)的模型演變成 OpenAI API 中的code-cushman-001。在 2022 年 3 月,OpenAI 發(fā)布了指令微調(diào) (instruction tuning) 的論文,其監(jiān)督微調(diào) (supervised instruction tuning) 的部分對應(yīng)了davinci-instruct-beta和text-davinci-001。在 2022 年 4 月至 7 月的,OpenAI 開始對code-davinci-002模型進行 Beta 測試,也稱其為 Codex。然后code-davinci-002、text-davinci-003和ChatGPT 都是從code-davinci-002進行指令微調(diào)得到的。詳細信息請參閱 OpenAI的模型索引文檔。
盡管 Codex 聽著像是一個只管代碼的模型,但code-davinci-002可能是最強大的針對自然語言的GPT-3.5 變體(優(yōu)于 text-davinci-002和 -003)。code-davinci-002很可能在文本和代碼上都經(jīng)過訓(xùn)練,然后根據(jù)指令進行調(diào)整(將在下面解釋)。然后2022 年 5-6 月發(fā)布的text-davinci-002是一個基于code-davinci-002的有監(jiān)督指令微調(diào) (supervised instruction tuned) 模型。在text-davinci-002上面進行指令微調(diào)很可能降低了模型的上下文學(xué)習(xí)能力,但是增強了模型的零樣本能力(將在下面解釋)。然后是text-davinci-003和 ChatGPT,它們都在 2022 年 11 月發(fā)布,是使用的基于人類反饋的強化學(xué)習(xí)的版本指令微調(diào) (instruction tuning with reinforcement learning from human feedback) 模型的兩種不同變體。text-davinci-003 恢復(fù)了(但仍然比code-davinci-002差)一些在text-davinci-002 中丟失的部分上下文學(xué)習(xí)能力(大概是因為它在微調(diào)的時候混入了語言建模) 并進一步改進了零樣本能力(得益于RLHF)。另一方面,ChatGPT 似乎犧牲了幾乎所有的上下文學(xué)習(xí)的能力來換取建模對話歷史的能力。
總的來說,在 2020 - 2021 年期間,在code-davinci-002之前,OpenAI 已經(jīng)投入了大量的精力通過代碼訓(xùn)練和指令微調(diào)來增強GPT-3。當他們完成code-davinci-002時,所有的能力都已經(jīng)存在了。很可能后續(xù)的指令微調(diào),無論是通過有監(jiān)督的版本還是強化學(xué)習(xí)的版本,都會做以下事情(稍后會詳細說明):
-
指令微調(diào)不會為模型注入新的能力 —— 所有的能力都已經(jīng)存在了。指令微調(diào)的作用是解鎖 / 激發(fā)這些能力。這主要是因為指令微調(diào)的數(shù)據(jù)量比預(yù)訓(xùn)練數(shù)據(jù)量少幾個數(shù)量級(基礎(chǔ)的能力是通過預(yù)訓(xùn)練注入的)。 -
指令微調(diào)將 GPT-3.5 的分化到不同的技能樹。有些更擅長上下文學(xué)習(xí)**,如 text-davinci-003,有些更擅長對話,如ChatGPT。 -
指令微調(diào)通過犧牲性能換取與人類的對齊(alignment)。OpenAI 的作者在他們的指令微調(diào)論文中稱其為 “對齊稅” (alignment tax)。許多論文都報道了 code-davinci-002在基準測試中實現(xiàn)了最佳性能(但模型不一定符合人類期望)。在code-davinci-002上進行指令微調(diào)后,模型可以生成更加符合人類期待的反饋(或者說模型與人類對齊),例如:零樣本問答、生成安全和公正的對話回復(fù)、拒絕超出模型它知識范圍的問題。
三、Code-Davinci-002和 Text-Davinci-002,在代碼上訓(xùn)練,在指令上微調(diào)
在code-davinci-002和text-davinci-002之前,有兩個中間模型,分別是 davinci-instruct-beta 和 text-davinci-001。兩者在很多方面都比上述的兩個-002模型差(例如,text-davinci-001 鏈式思維推理能力不強)。所以我們在本節(jié)中重點介紹 -002 型號。
3.1 復(fù)雜推理能力的來源和泛化到新任務(wù)的能力
我們關(guān)注code-davinci-002和text-davinci-002,這兩兄弟是第一版的 GPT3.5 模型,一個用于代碼,另一個用于文本。它們表現(xiàn)出了三種重要能力與初代 GPT-3 不同的能力:
-
響應(yīng)人類指令:以前,GPT-3 的輸出主要訓(xùn)練集中常見的句子。現(xiàn)在的模型會針對指令 / 提示詞生成更合理的答案(而不是相關(guān)但無用的句子)。 -
泛化到?jīng)]有見過的任務(wù):當用于調(diào)整模型的指令數(shù)量超過一定的規(guī)模時,模型就可以自動在從沒見過的新指令上也能生成有效的回答。這種能力對于上線部署至關(guān)重要,因為用戶總會提新的問題,模型得答得出來才行。 -
代碼生成和代碼理解:這個能力很顯然,因為模型用代碼訓(xùn)練過。 -
利用思維鏈 (chain-of-thought) 進行復(fù)雜推理:初代 GPT3 的模型思維鏈推理的能力很弱甚至沒有。code-davinci-002 和 text-davinci-002 是兩個擁有足夠強的思維鏈推理能力的模型。 -
思維鏈推理之所以重要,是因為思維鏈可能是解鎖突現(xiàn)能力和超越縮放法則 (scaling laws) 的關(guān)鍵。請參閱上一篇博文。
這些能力從何而來?
與之前的模型相比,兩個主要區(qū)別是指令微調(diào)和代碼訓(xùn)練。具體來說
-
能夠響應(yīng)人類指令的能力是指令微調(diào)的直接產(chǎn)物。 -
對沒有見過的指令做出反饋的泛化能力是在指令數(shù)量超過一定程度之后自動出現(xiàn)的,T0、Flan 和 FlanPaLM 論文進一步證明了這一點 -
使用思維鏈進行復(fù)雜推理的能力很可能是代碼訓(xùn)練的一個神奇的副產(chǎn)物。對此,我們有以下的事實作為一些支持: -
最初的 GPT-3 沒有接受過代碼訓(xùn)練,它不能做思維鏈。 -
text-davinci-001 模型,雖然經(jīng)過了指令微調(diào),但第一版思維鏈論文報告說,它的它思維鏈推理的能力非常弱 —— 所以指令微調(diào)可能不是思維鏈存在的原因,代碼訓(xùn)練才是模型能做思維鏈推理的最可能原因。 -
PaLM 有 5% 的代碼訓(xùn)練數(shù)據(jù),可以做思維鏈。 -
Codex論文中的代碼數(shù)據(jù)量為 159G ,大約是初代 GPT-3 5700 億訓(xùn)練數(shù)據(jù)的28%。code-davinci-002 及其后續(xù)變體可以做思維鏈推理。 -
在 HELM 測試中,Liang et al. (2022) 對不同模型進行了大規(guī)模評估。他們發(fā)現(xiàn)了針對代碼訓(xùn)練的模型具有很強的語言推理能力,包括 120億參數(shù)的code-cushman-001.。 -
我們在 AI2 的工作也表明,當配備復(fù)雜的思維鏈時,code-davinci-002 在 GSM8K 等重要數(shù)學(xué)基準上是目前表現(xiàn)最好的模型 -
直覺來說,面向過程的編程 (procedure-oriented programming) 跟人類逐步解決任務(wù)的過程很類似,面向?qū)ο缶幊?(object-oriented programming) 跟人類將復(fù)雜任務(wù)分解為多個簡單任務(wù)的過程很類似。 -
以上所有觀察結(jié)果都是代碼與推理能力 / 思維鏈之間的相關(guān)性。代碼和推理能力 / 思維鏈之間的這種相關(guān)性對研究社區(qū)來說是一個非常有趣的問題,但目前仍未得到很好的理解。然而,仍然沒有確鑿的證據(jù)表明代碼訓(xùn)練就是CoT和復(fù)雜推理的原因。 思維鏈的來源仍然是一個開放性的研究問題。 -
此外, 代碼訓(xùn)練另一個可能的副產(chǎn)品是長距離依賴,正如Peter Liu所指出:“語言中的下個詞語預(yù)測通常是非常局部的,而代碼通常需要更長的依賴關(guān)系來做一些事情,比如前后括號的匹配或引用遠處的函數(shù)定義”。這里我想進一步補充的是:由于面向?qū)ο缶幊讨械念惱^承,代碼也可能有助于模型建立編碼層次結(jié)構(gòu)的能力。我們將對這一假設(shè)的檢驗留給未來的工作。
另外還要注意一些細節(jié)差異:
-
text-davinci-002 與 code-davinci-002 -
Code-davinci-002 是基礎(chǔ)模型,text-davinci-002 是指令微調(diào) code-davinci-002 的產(chǎn)物(見 OpenAI 的文檔)。它在以下數(shù)據(jù)上作了微調(diào):(一)人工標注的指令和期待的輸出;(二)由人工標注者選擇的模型輸出。 -
當有上下文示例 (in-context example) 的時候, Code-davinci-002 更擅長上下文學(xué)習(xí);當沒有上下文示例 / 零樣本的時候, text-davinci-002 在零樣本任務(wù)完成方面表現(xiàn)更好。從這個意義上說,text-davinci-002 更符合人類的期待(因為對一個任務(wù)寫上下文示例可能會比較麻煩)。 -
OpenAI 不太可能故意犧牲了上下文學(xué)習(xí)的能力換取零樣本能力 —— 上下文學(xué)習(xí)能力的降低更多是指令學(xué)習(xí)的一個副作用,OpenAI 管這叫對齊稅。 -
001 模型(code-cushman-001 和 text-davinci-001)v.s. 002 模型(code-davinci-002 和 text-davinci-002) -
001 模型主要是為了做純代碼 / 純文本任務(wù);002 模型則深度融合了代碼訓(xùn)練和指令微調(diào),代碼和文本都行。 -
Code-davinci-002 可能是第一個深度融合了代碼訓(xùn)練和指令微調(diào)的模型。證據(jù)有:code-cushman-001 可以進行推理但在純文本上表現(xiàn)不佳,text-davinci-001 在純文本上表現(xiàn)不錯但在推理上不大行。code-davinci-002 則可以同時做到這兩點。
3.2 這些能力是在預(yù)訓(xùn)練之后已經(jīng)存在還是在之后通過微調(diào)注入?
在這個階段,我們已經(jīng)確定了指令微調(diào)和代碼訓(xùn)練的關(guān)鍵作用。一個重要的問題是如何進一步分析代碼訓(xùn)練和指令微調(diào)的影響?具體來說:上述三種能力是否已經(jīng)存在于初代的GPT-3中,只是通過指令和代碼訓(xùn)練觸發(fā) / 解鎖?或者這些能力在初代的 GPT-3 中并不存在,是通過指令和代碼訓(xùn)練注入?如果答案已經(jīng)在初代的 GPT-3 中,那么這些能力也應(yīng)該在 OPT 中。因此,要復(fù)現(xiàn)這些能力,或許可以直接通過指令和代碼調(diào)整 OPT。 但是,code-davinci-002 也可能不是基于最初的 GPT-3 davinci,而是基于比初代 GPT-3 更大的模型。如果是這種情況,可能就沒辦法通過調(diào)整 OPT 來復(fù)現(xiàn)了。研究社區(qū)需要進一步弄清楚 OpenAI 訓(xùn)練了什么樣的模型作為 code-davinci-002 的基礎(chǔ)模型。
我們有以下的假設(shè)和證據(jù):
-
code-davinci-002的基礎(chǔ)模型可能不是初代GPT-3 davinci 模型。以下是證據(jù): -
初代的GPT-3在數(shù)據(jù)集 C4 2016 - 2019 上訓(xùn)練,而 code-davinci-002 訓(xùn)練集則在延長到2021年才結(jié)束。因此 code-davinci-002 有可能在 C4 的 2019-2021 版本上訓(xùn)練。 -
初代的 GPT-3 有一個大小為 2048 個詞的上下文窗口。code-davinci-002 的上下文窗口則為 8192。GPT 系列使用絕對位置嵌入 (absolute positional embedding),直接對絕對位置嵌入進行外推而不經(jīng)過訓(xùn)練是比較難的,并且會嚴重損害模型的性能(參考 Press et al., 2022)。如果 code-davinci-002 是基于初代GPT-3,那OpenAI 是如何擴展上下文窗口的? -
另一方面,無論基礎(chǔ)模型是初代的 GPT-3 還是后來訓(xùn)練的模型, 遵循指令和零樣本泛化的能力都可能已經(jīng)存在于基礎(chǔ)模型中,后來才通過指令微調(diào)來解鎖 (而不是注入) -
這主要是因為 OpenAI 的論文報告的指令數(shù)據(jù)量大小只有 77K,比預(yù)訓(xùn)練數(shù)據(jù)少了幾個數(shù)量級。 -
其他指令微調(diào)論文進一步證明了數(shù)據(jù)集大小對模型性能的對比,例如 Chung et al. (2022) 的工作中, Flan-PaLM 的指令微調(diào)僅為預(yù)訓(xùn)練計算的 0.4%。一般來說,指令數(shù)據(jù)會顯著少于預(yù)訓(xùn)練數(shù)據(jù)。 -
然而 ,模型的復(fù)雜推理能力可能是在預(yù)訓(xùn)練階段通過代碼數(shù)據(jù)注入 -
代碼數(shù)據(jù)集的規(guī)模與上述指令微調(diào)的情況不同。這里的代碼數(shù)據(jù)量足夠大,可以占據(jù)訓(xùn)練數(shù)據(jù)的重要部分(例如,PaLM 有 8% 的代碼訓(xùn)練數(shù)據(jù)) -
如上所述,在 code-davinci-002 之前的模型 text-davinci-001 大概沒有在代碼數(shù)據(jù)上面微調(diào)過,所以它的推理 / 思維鏈能力是非常差的,正如第一版思維鏈論文中所報告的那樣,有時甚至比參數(shù)量更小的 code-cushman-001 還差。 -
區(qū)分代碼訓(xùn)練和指令微調(diào)效果的最好方法可能是比較 code-cushman-001、T5 和 FlanT5 -
因為它們具有相似的模型大小(110億 和 120億),相似的訓(xùn)練數(shù)據(jù)集 (C4),它們最大的區(qū)別就是有沒有在代碼上訓(xùn)練過 / 有沒有做過指令微調(diào)。 -
目前還沒有這樣的比較。我們把這個留給未來的研究。
四、text-davinci-003 和 ChatGPT,基于人類反饋的強化學(xué)習(xí)(Reinforcement Learning from Human Feedback, RLHF) 的威力
在當前階段(2022 年 12 月), text-davinci-002、text-davinci-003 和 ChatGPT之間幾乎沒有嚴格的統(tǒng)計上的比較 ,主要是因為
-
text-davinci-003 和 ChatGPT 在撰寫本文時才發(fā)布不到一個月。 -
ChatGPT 不能通過 OpenAI API 被調(diào)用,所以想要在標準基準上測試它很麻煩。
所以在這些模型之間的比較更多是基于研究社區(qū)的集體經(jīng)驗 (統(tǒng)計上不是很嚴格)。不過,我們相信初步的描述性比較仍然可以揭示模型的機制。
我們首先注意到以下 text-davinci-002,text-davinci-003 和 ChatGPT 之間的比較:
-
所有三個模型都經(jīng)過指令微調(diào)。 -
text-davinci-002 是一個經(jīng)過監(jiān)督學(xué)習(xí)指令微調(diào) (supervised instruction tuning) 的模型 -
text-davinci-003 和 ChatGPT 是基于人類反饋的強化學(xué)習(xí)的指令微調(diào) (Instruction tuning with Reinforcement Learning from Human Feedback RLHF)。這是它們之間最顯著的區(qū)別。
這意味著大多數(shù)新模型的行為都是 RLHF 的產(chǎn)物。
那么讓我們看看 RLHF 觸發(fā)的能力:
-
翔實的回應(yīng):text-davinci-003 的生成通常比 text-davinci-002長。ChatGPT 的回應(yīng)則更加冗長,以至于用戶必須明確要求“用一句話回答我”,才能得到更加簡潔的回答。這是 RLHF 的直接產(chǎn)物。 -
公正的回應(yīng):ChatGPT 通常對涉及多個實體利益的事件(例如政治事件)給出非常平衡的回答。這也是RLHF的產(chǎn)物。 -
拒絕不當問題:這是內(nèi)容過濾器和由 RLHF 觸發(fā)的模型自身能力的結(jié)合,過濾器過濾掉一部分,然后模型再拒絕一部分。 -
拒絕其知識范圍之外的問題:例如,拒絕在2021 年 6 月之后發(fā)生的新事件(因為它沒在這之后的數(shù)據(jù)上訓(xùn)練過)。這是 RLHF 最神奇的部分,因為它使模型能夠隱式地區(qū)分哪些問題在其知識范圍內(nèi),哪些問題不在其知識范圍內(nèi)。
有兩件事情值得注意:
-
所有的能力都是模型本來就有的, 而不是通過RLHF 注入的。RLHF 的作用是觸發(fā) / 解鎖突現(xiàn)能力。這個論點主要來自于數(shù)據(jù)量大小的比較:因為與預(yù)訓(xùn)練的數(shù)據(jù)量相比,RLHF 占用的計算量 / 數(shù)據(jù)量要少得多。 -
模型知道它不知道什么不是通過編寫規(guī)則來實現(xiàn)的, 而是通過RLHF解鎖的。這是一個非常令人驚訝的發(fā)現(xiàn),因為 RLHF 的最初目標是讓模型生成復(fù)合人類期望的回答,這更多是讓模型生成安全的句子,而不是讓模型知道它不知道的內(nèi)容。
幕后發(fā)生的事情可能是:
-
ChatGPT: 通過犧牲上下文學(xué)習(xí)的能力換取建模對話歷史的能力。這是一個基于經(jīng)驗的觀測結(jié)果,因為 ChatGPT 似乎不像 text-davinci-003 那樣受到上下文演示的強烈影響。 -
text-davinci-003:恢復(fù)了 text-davinci-002 所犧牲的上下文學(xué)習(xí)能力, 提高零樣本的能力。我們不確定這是否也是 RLHF 或其他東西的副產(chǎn)品。 根據(jù)instructGPT的論文,這是來自于強化學(xué)習(xí)調(diào)整階段混入了語言建模的目標(而不是 RLHF 本身)。
五、總結(jié)當前階段 GPT-3.5 的進化歷程
到目前為止,我們已經(jīng)仔細檢查了沿著進化樹出現(xiàn)的所有能力,下表總結(jié)了演化路徑:
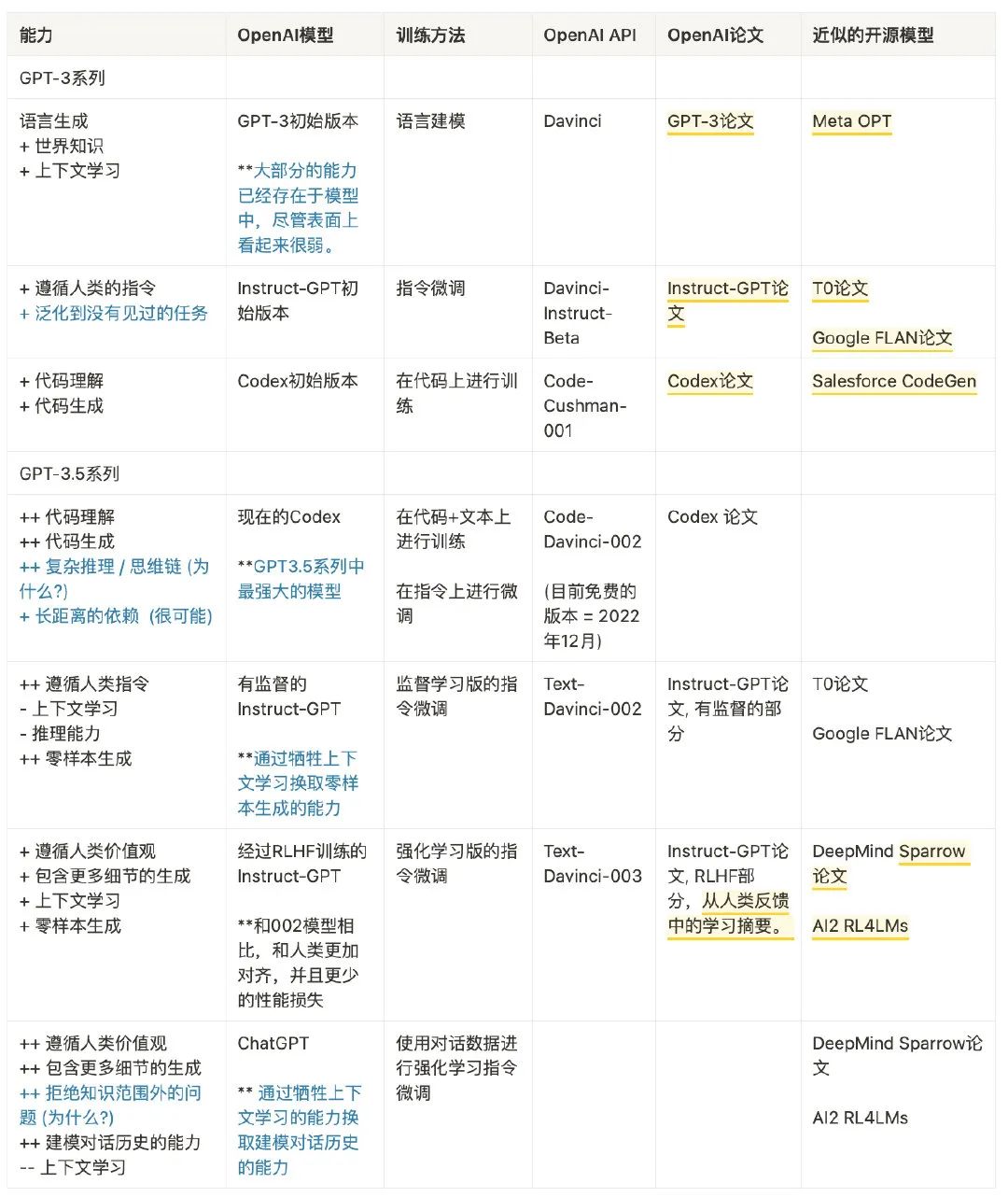
我們可以得出結(jié)論:
-
語言生成能力 + 基礎(chǔ)世界知識 + 上下文學(xué)習(xí)都是來自于預(yù)訓(xùn)練( davinci) -
存儲大量知識的能力來自 1750 億的參數(shù)量。 -
遵循指令和泛化到新任務(wù)的能力來自于擴大指令學(xué)習(xí)中指令的數(shù)量( Davinci-instruct-beta) -
執(zhí)行復(fù)雜推理的能力很可能來自于代碼訓(xùn)練( code-davinci-002) -
生成中立、客觀的能力、安全和翔實的答案來自與人類的對齊。具體來說: -
如果是監(jiān)督學(xué)習(xí)版,得到的模型是 text-davinci-002 -
如果是強化學(xué)習(xí)版 (RLHF) ,得到的模型是 text-davinci-003 -
無論是有監(jiān)督還是 RLHF ,模型在很多任務(wù)的性能都無法超過 code-davinci-002 ,這種因為對齊而造成性能衰退的現(xiàn)象叫做對齊稅。 -
對話能力也來自于 RLHF( ChatGPT),具體來說它犧牲了上下文學(xué)習(xí)的能力,來換取: -
建模對話歷史 -
增加對話信息量 -
拒絕模型知識范圍之外的問題
六、GPT-3.5 目前不能做什么
雖然GPT-3.5是自然語言處理研究中的重要一步,但它并沒有完全包含許多研究人員(包括 AI2)設(shè)想的所有理想屬性。以下是GPT-3.5不具備的某些重要屬性:
-
實時改寫模型的信念:當模型表達對某事的信念時,如果該信念是錯誤的,我們可能很難糾正它: -
我最近遇到的一個例子是:ChatGPT 堅持認為 3599 是一個質(zhì)數(shù),盡管它承認 3599 = 59 * 61。另外,請參閱Reddit上關(guān)于游得最快的海洋哺乳動物的例子。 -
然而,模型信念的強度似乎存在不同的層次。一個例子是即使我告訴它達斯·維達(星球大戰(zhàn)電影中的人物)贏得了2020年大選,模型依舊會認為美國現(xiàn)任總統(tǒng)是拜登。但是如果我將選舉年份改為 2024 年,它就會認為總統(tǒng)是達斯·維達是 2026 年的總統(tǒng)。 -
形式推理:GPT-3.5系列不能在數(shù)學(xué)或一階邏輯等形式嚴格的系統(tǒng)中進行推理: -
一個例子是嚴格的數(shù)學(xué)證明,要求中間步驟中不能跳,不能模糊,不能錯。 -
但這種嚴格推理到底是應(yīng)該讓語言模型做還是讓符號系統(tǒng)做還有待討論。一個例子是,與其努力讓 GPT 做三位數(shù)加法,不如直接調(diào) Python。 -
生成如何做豆腐腦的方法。做豆腐腦的時候,中間很多步驟模糊一點是可以接受的,比如到底是做咸的還是做甜的。只要整體步驟大致正確,做出來的豆腐腦兒就能吃。 -
數(shù)學(xué)定理的證明思路。證明思路是用語言表達的非正式的逐步解法,其中每一步的嚴格推導(dǎo)可以不用太具體。證明思路經(jīng)常被用到數(shù)學(xué)教學(xué):只要老師給一個大致正確的整體步驟,學(xué)生就可以大概明白。然后老師把具體的證明細節(jié)作為作業(yè)布置給學(xué)生,答案略。 -
在自然語言處理的文獻中, “推理” 一詞的定義很多時候不太明確。但如果我們從模糊性的角度來看,例如一些問題 (a) 非常模棱兩可,沒有推理;(b) 有點兒邏輯在里面,但有些地方也可以模糊;(c) 非常嚴謹,不能有任何歧義。那么, -
模型可以很好地進行 (b) 類的帶模糊性的推理,例子有: -
GPT-3.5 不能進行類型 (c) 的推理(推理不能容忍歧義)。 -
從互聯(lián)網(wǎng)進行檢索:GPT-3.5 系列(暫時)不能直接搜索互聯(lián)網(wǎng) -
模型的內(nèi)部知識總是在某個時間被切斷。模型始終需要最新的知識來回答最新的問題。 -
回想一下,我們已經(jīng)討論過 1750 億的參數(shù)大量用于存儲知識。如果我們可以將知識卸載到模型之外,那么模型參數(shù)可能會大大減少,最終它甚至可以在手機上運行(瘋狂的想法,但 ChatGPT 已經(jīng)足夠科幻了,誰知道未來會怎樣呢). -
但是有一篇 WebGPT 論文發(fā)表于2021年12月,里面就讓 GPT 調(diào)用了搜索引擎。所以檢索的能力已經(jīng)在 OpenAI 內(nèi)部進行了測試。 -
這里需要區(qū)分的一點是,GPT-3.5 的兩個重要但不同的能力是 知識 和 推理。一般來說,如果我們能夠 將知識部分卸載到外部的檢索系統(tǒng),讓語言模型只專注于推理,這就很不錯了。 因為:
七、結(jié)論
在這篇博文中,我們仔細檢查了GPT-3.5系列的能力范圍,并追溯了它們所有突現(xiàn)能力的來源。初代GPT-3模型通過預(yù)訓(xùn)練獲得生成能力、世界知識和in-context learning。然后通過instruction tuning的模型分支獲得了遵循指令和能泛化到?jīng)]有見過的任務(wù)的能力。經(jīng)過代碼訓(xùn)練的分支模型則獲得了代碼理解的能力,作為代碼訓(xùn)練的副產(chǎn)品,模型同時潛在地獲得了復(fù)雜推理的能力。結(jié)合這兩個分支,code-davinci-002似乎是具有所有強大能力的最強GPT-3.5模型。接下來通過有監(jiān)督的instruction tuning和 RLHF通過犧牲模型能力換取與人類對齊,即對齊稅。RLHF 使模型能夠生成更翔實和公正的答案,同時拒絕其知識范圍之外的問題。
我們希望這篇文章能夠幫助提供一個清晰的GPT評估圖,并引發(fā)一些關(guān)于語言模型、instruction tuning和code tuning的討論。最重要的是, 我們希望這篇文章可以作為在開源社區(qū)內(nèi)復(fù)現(xiàn)GPT-3.5的路線圖。
“因為山就在那里。”——喬治·馬洛里,珠穆朗瑪峰探險先驅(qū)
常見問題
-
這篇文章中的這些說法更像是假設(shè) (hypothesis) 還是結(jié)論 (conclusion)? -
復(fù)雜推理的能力來自于代碼訓(xùn)練是我們傾向于相信的假設(shè) -
對沒有見過的任務(wù)泛化能力來自大規(guī)模指令學(xué)習(xí) 是至少 4 篇論文的結(jié)論 -
GPT-3.5來自于其他大型基礎(chǔ)模型,而不是1750億參數(shù)的GPT-3 是有根據(jù)的猜測。 -
所有這些能力都已經(jīng)存在了,通過instruction tuning,無論是有監(jiān)督學(xué)習(xí)或強化學(xué)習(xí)的方式來解鎖而不是注入這些能力 是一個強有力的假設(shè),強到你不敢不信。主要是因為instruction tuning數(shù)據(jù)量比預(yù)訓(xùn)練數(shù)據(jù)量少了幾個數(shù)量級 -
結(jié)論 = 許多證據(jù)支持這些說法的正確性;假設(shè) = 有正面證據(jù)但不夠有力;有根據(jù)的猜測 = 沒有確鑿的證據(jù),但某些因素會指向這個方向 -
為什么其他模型(如 OPT 和 BLOOM)沒有那么強大? -
OPT大概是因為訓(xùn)練過程太不穩(wěn)定 -
BLOOM的情況則未知。如果您有更多意見,請與我聯(lián)系
附錄 - 中英術(shù)語對照表
| 英文 | 中文 | 釋義 |
|---|---|---|
| Emergent Ability | 突現(xiàn)能力 | 小模型沒有,只在模型大到一定程度才會出現(xiàn)的能力 |
| Prompt | 提示詞 | 把 prompt 輸入給大模型,大模型給出 completion |
| In-Context Learning | 上下文學(xué)習(xí) | 在 prompt 里面寫幾個例子,模型就可以照著這些例子做生成 |
| Instruction Tuning | 指令微調(diào) | 用 instruction 來 fine-tune 大模型 |
| Code Tuning | 在代碼上微調(diào) | 用代碼來 fine-tune 大模型 |
| Reinforcement Learning with Human Feedback (RLHF) | 基于人類反饋的強化學(xué)習(xí) | 讓人給模型生成的結(jié)果打分,用人打的分來調(diào)整模型 |
| Chain-of-Thought | 思維鏈 | 在寫 prompt 的時候,不僅給出結(jié)果,還要一步一步地寫結(jié)果是怎么推出來的 |
| Scaling Laws | 縮放法則 | 模型的效果的線性增長要求模型的大小指數(shù)增長 |
| Alignment | 與人類對齊 | 讓機器生成復(fù)合人類期望的,復(fù)合人類價值觀的句子 |