
面試官:為什么 HashMap 的加載因子是0.75?徹底懵逼了。。

閱讀本文大概需要 7 分鐘。
來自:blog.csdn.net/NYfor2017/article/details/105454097
-
為什么HashMap需要加載因子? -
解決沖突有什么方法? -
1.開放定址法 -
2.再哈希法 -
3.建立一個公共溢出區(qū) -
4.鏈地址法(拉鏈法) -
為什么HashMap加載因子一定是0.75?而不是0.8,0.6? -
那么為什么不可以是0.8或者0.6呢?
-
為什么HashMap需要加載因子? -
解決沖突有什么方法? -
為什么加載因子一定是0.75?而不是0.8,0.6?
為什么HashMap需要加載因子?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// AbstractMap
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext())
h += i.next().hashCode();
return h;
}
加載因子 = 填入表中的元素個數 / 散列表的長度
-
散列函數是否可以將哈希表中的數據均勻地散列? -
怎么處理沖突? -
哈希表的加載因子怎么選擇?
解決沖突有什么方法?
1. 開放定址法
Hi = (H(key) + di) MOD m,其中i=1,2,…,k(k<=m-1)
1.1 線性探查法(Linear Probing):di = 1,2,3,…,m-1
1.2 平方探測法(Quadratic Probing):di = ±12, ±22,±32,…,±k2(k≤m/2)
1.3 偽隨機探測法:di = 偽隨機數序列
-
這種方法建立起來的哈希表,當沖突多的時候數據容易堆集在一起,這時候對查找不友好; -
刪除結點的時候不能簡單將結點的空間置空,否則將截斷在它填入散列表之后的同義詞結點查找路徑。因此如果要刪除結點,只能在被刪結點上添加刪除標記,而不能真正刪除結點; -
如果哈希表的空間已經滿了,還需要建立一個溢出表,來存入多出來的元素。
2. 再哈希法
Hi = RHi(key), 其中i=1,2,…,k
3. 建立一個公共溢出區(qū)
4. 鏈地址法(拉鏈法)
-
處理沖突的方式簡單,且無堆集現(xiàn)象,非同義詞絕不會發(fā)生沖突,因此平均查找長度較短; -
由于拉鏈法中各鏈表上的結點空間是動態(tài)申請的,所以它更適合造表前無法確定表長的情況; -
刪除結點操作易于實現(xiàn),只要簡單地刪除鏈表上的相應的結點即可。

為什么HashMap加載因子一定是0.75?而不是0.8,0.6?
臨界值 = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR
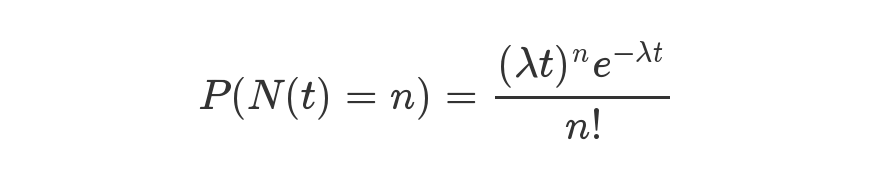
* Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million

0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
那么為什么不可以是0.8或者0.6呢?
對于開放定址法,加載因子是特別重要因素,應嚴格限制在0.7-0.8以下。超過0.8,查表時的CPU緩存不命中(cache missing)按照指數曲線上升。因此,一些采用開放定址法的hash庫,如Java的系統(tǒng)庫限制了加載因子為0.75,超過此值將resize散列表。
推薦閱讀:
SpringBoot 運行內存及內存參數設置:助力高效應用部署與優(yōu)化
互聯(lián)網初中高級大廠面試題(9個G) 內容包含Java基礎、JavaWeb、MySQL性能優(yōu)化、JVM、鎖、百萬并發(fā)、消息隊列、高性能緩存、反射、Spring全家桶原理、微服務、Zookeeper......等技術棧!
?戳閱讀原文領取! 朕已閱
