推薦系統(tǒng)中模型自適應(yīng)相關(guān)技術(shù)梳理總結(jié)
? 作者|范欣妍
機(jī)構(gòu)|中國人民大學(xué)高瓴人工智能學(xué)院
研究方向|推薦系統(tǒng)
本文介紹的是推薦系統(tǒng)中模型自適應(yīng)的相關(guān)技術(shù)。本文將主要基于近三年已發(fā)表的頂會論文(ICML、ICLR、SIGIR、KDD、WWW、AAAI等),梳理了與模型自適應(yīng)相關(guān)的研究工作,介紹了模型自適應(yīng)常用的技術(shù)以及在推薦系統(tǒng)中的應(yīng)用。這些技術(shù)可能來自其他研究領(lǐng)域,本文也會簡單介紹模型自適應(yīng)在這些領(lǐng)域的應(yīng)用。文章最后列出了一些近期頂會的相關(guān)工作,供大家學(xué)習(xí)參考。
文章也同步發(fā)布在AI Box知乎專欄(知乎搜索 AI Box專欄),歡迎大家在知乎專欄的文章下方評論留言,交流探討!轉(zhuǎn)載本文請注明來源RUC AI Box。
1. 什么是模型自適應(yīng)(Model Adaptation)
模型自適應(yīng)(Model Adaptation,簡稱MA)目前在多個領(lǐng)域已經(jīng)成為研究熱點(diǎn)。它的目標(biāo)是在使用源訓(xùn)練數(shù)據(jù)和目標(biāo)數(shù)據(jù)來最大化目標(biāo)任務(wù)的表現(xiàn)。如下圖所示,我們在豐富的源數(shù)據(jù)/訓(xùn)練數(shù)據(jù)上訓(xùn)練好一個原始模型(Original Model),在應(yīng)用階段用額外的任務(wù)相關(guān)的數(shù)據(jù)調(diào)整模型(Adaptation),得到適應(yīng)后的模型(Adapted Model)來更好的適應(yīng)目標(biāo)任務(wù)/目標(biāo)數(shù)據(jù)。模型自適應(yīng)可以看做遷移學(xué)習(xí)的一種方式。考慮到訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)之間存在分布的不一致,如何利用少量的自適應(yīng)數(shù)據(jù)(Adaptation Data)使源模型泛化到目標(biāo)任務(wù)是一項關(guān)鍵挑戰(zhàn)。

2. 推薦系統(tǒng)中為什么要進(jìn)行Model Adaptation
目前的推薦系統(tǒng)服從“Offline Training”->“Online Serving”的結(jié)構(gòu),這種框架假設(shè)在在線服務(wù)時對于用戶的不同請求的數(shù)據(jù)的分布是穩(wěn)定的,且與線下訓(xùn)練模型時的數(shù)據(jù)分布是一致的。然而這種假設(shè)在現(xiàn)實中并不總是成立的。例如,受時效性的影響,推薦系統(tǒng)中的召回模塊給出的數(shù)據(jù)分布是隨著時間不斷變化的,比如在新聞推薦中,選舉期間召回的政治類新聞?wù)急却螅瑠W運(yùn)會期間則體育類新聞更多;此外用戶的請求也可能來自不同的領(lǐng)域,例如在電商平臺,同一個用戶可能會輸入查詢詞“裙子”或“手機(jī)”,不同的請求下得到的數(shù)據(jù)分布不同,甚至與訓(xùn)練用的數(shù)據(jù)分布也不同。對于推薦系統(tǒng)中的這種動態(tài)服務(wù)(Dynamic Serving)需求,一個解決上述問題的思路就是使用模型自適應(yīng)(MA)。
MA有三個典型的應(yīng)用場景:
跨領(lǐng)域推薦【Cross-Domain Recommendation,包括單一目標(biāo)域(single target domain)的傳統(tǒng)跨領(lǐng)域推薦和多域(multiple domains)的多領(lǐng)域推薦】:目前的大型推薦系統(tǒng)通常服務(wù)于多個不同的域(例如新聞網(wǎng)頁中的「熱門新聞推薦板塊」和「政治新聞欄目」),如果對每個域都訓(xùn)練一個模型代價太大;而且一些域的數(shù)據(jù)很稀疏,無法有效的訓(xùn)練好一個模型。一個好的思路是在混合多個域包含豐富信息的大數(shù)據(jù)集上訓(xùn)練一個模型,然后根據(jù)目標(biāo)域的數(shù)據(jù)做adaptation,自適應(yīng)地應(yīng)用到不同的場景。
在線服務(wù)【Online Service】:線上應(yīng)用線下已經(jīng)訓(xùn)練好的推薦模型進(jìn)行服務(wù)時,往往因為數(shù)據(jù)分布不一致(offline-online inconsistency)導(dǎo)致在線服務(wù)效果不好。頻繁收集線上數(shù)據(jù)并在線下重新訓(xùn)練模型并不是一個高效的辦法。一個比較自然的想法是應(yīng)用模型自適應(yīng),通過捕捉線上數(shù)據(jù)的分布特征,調(diào)整原始模型,來適應(yīng)到線上場景,減輕線上線下數(shù)據(jù)不一致帶來的負(fù)面影響,以達(dá)到更好的線上服務(wù)效果。
用戶冷啟動【Cold-Start】:用戶冷啟動問題是推薦系統(tǒng)中最重要的挑戰(zhàn)之一,它是指向新/冷用戶推薦商品的任務(wù),該用戶的交互記錄在系統(tǒng)中非常少。如何從以往不同的用戶的交互數(shù)據(jù)學(xué)到一個模型,使得面對新的用戶時能夠借助以往學(xué)習(xí)的知識以及少量的樣本快速適應(yīng)到新用戶的推薦任務(wù)中,在初始給出好的推薦來更好地留住用戶,也是模型自適應(yīng)一個重要的應(yīng)用場景。
MA在其他研究領(lǐng)域的一些典型應(yīng)用:
在NLP中,目前一個通用的范式是pre-train+fine-tune。先用大語料訓(xùn)練一個模型,然后使用下游數(shù)據(jù)對預(yù)訓(xùn)練好的語言模型進(jìn)行微調(diào),讓模型適應(yīng)到不同的下游任務(wù)。這種fine-tune的框架也可以看做是一種模型自適應(yīng)。
在CV中,有一項任務(wù)是visual reasoning answer,即看圖回答所給問題。模型需要根據(jù)問題來提取圖片中需要的特征進(jìn)行計算,不同的問題提取的特征應(yīng)該不同。一些研究提出根據(jù)不同的問題,對模型參數(shù)做出自適應(yīng)地調(diào)整,從而做出不同的回答。
在Speech中,自定義語音(Custom voice)是商業(yè)語音平臺中的一種特定文本到語音的服務(wù),該任務(wù)需要使用目標(biāo)用戶的少量語音調(diào)整一個訓(xùn)練好源模型,來自適應(yīng)地合成目標(biāo)說話者的個人語音庫。

3. 相關(guān)工作
3.1 Transfer Learning (TL)
TL針對源任務(wù)訓(xùn)練模型,旨在提高模型在不同但相關(guān)的目標(biāo)域/任務(wù)上的性能。Pre-train+fine-tune是遷移學(xué)習(xí)的常用策略,其中源域和目標(biāo)域具有不同的任務(wù)且目標(biāo)域的數(shù)據(jù)在訓(xùn)練時可以被用到。但是當(dāng)目標(biāo)域數(shù)據(jù)很稀疏時,傳統(tǒng)的pre-train+fine-tune范式容易產(chǎn)生過擬合。后文將介紹的一些高效finetune的MA方法能有效避免這個問題。
3.2 Domain Adaptation(DA)
DA是一種特殊形式的遷移學(xué)習(xí)(直推式遷移學(xué)習(xí)),是在一個包含豐富標(biāo)簽信息的源數(shù)據(jù)上訓(xùn)練一個模型,能夠很好的泛化到目標(biāo)域。在DA中,目標(biāo)域和源域的分布不同;且不一定需要根據(jù)目標(biāo)域?qū)τ?xùn)練好的模型做修改。本文的MA強(qiáng)調(diào)的是根據(jù)目標(biāo)數(shù)據(jù)(可能來自與源數(shù)據(jù)來自同一個域,也可能不同;可能很大,也可能很小,例如冷啟動時的一個用戶)對模型做調(diào)整,適應(yīng)到目標(biāo)任務(wù)。DA可以看做本文MA的一種情況。
3.3 Multi-Task Learning(MTL)
MTL通過同時聯(lián)合訓(xùn)練多個相關(guān)任務(wù)來優(yōu)化模型。由于相關(guān)任務(wù)之間的知識共享,該模型為特定任務(wù)學(xué)習(xí)了更廣闊的視角,可以更好地泛化。多任務(wù)學(xué)習(xí)可以在多個相關(guān)領(lǐng)域進(jìn)行訓(xùn)練,以學(xué)習(xí)對每個原始領(lǐng)域都良好的模型,從而應(yīng)用到多領(lǐng)域?qū)W習(xí)(例如,跨領(lǐng)域推薦),但并不在于增強(qiáng)對新任務(wù)/新數(shù)據(jù)的適應(yīng)能力。
3.4 Online Learning(OL)
OL并不是一種模型,而是一種模型的訓(xùn)練方法,OL要求數(shù)據(jù)以流的方式順序到來,并且能夠根據(jù)線上的反饋數(shù)據(jù),實時快速地進(jìn)行模型調(diào)整,使得模型及時反映線上的變化,提高線上預(yù)測的準(zhǔn)確率。它的流程包括:將模型的預(yù)測結(jié)果展現(xiàn)給用戶,然后收集用戶的反饋數(shù)據(jù),再用來訓(xùn)練模型。與MA不同,OL是一個不斷更新模型的過程,且每次的更新是在獲得真實反饋之后;而MA更強(qiáng)調(diào)如何在將預(yù)測結(jié)果展示給用戶前,根據(jù)目標(biāo)任務(wù)的數(shù)據(jù)對一個已經(jīng)訓(xùn)練好的模型做調(diào)整(adaptation)。
4. 現(xiàn)有技術(shù)
本文梳理了與模型自適應(yīng)相關(guān)的近期的研究工作,目前在推薦領(lǐng)域中涉及到的Model Adaptation的主要技術(shù)大致可以分為以下三類:
Parameter Patch:這類方法的核心是在原始網(wǎng)絡(luò)中插入一些參數(shù)補(bǔ)丁,根據(jù)目標(biāo)域的數(shù)據(jù)訓(xùn)練/調(diào)整補(bǔ)丁的參數(shù),來達(dá)到自適應(yīng)到目標(biāo)任務(wù)的效果;
Feature Modulation:這類方法的假設(shè)是在源域上學(xué)到的表示與目標(biāo)域不在同一個空間,因此他們關(guān)注于如何使用目標(biāo)域的數(shù)據(jù)對原有模型得到的特征表示變換到目標(biāo)域空間中;
Meta Learning:這類方法的目標(biāo)是將task視作樣本,通過對多個task的學(xué)習(xí),以使訓(xùn)練好的模型能夠根據(jù)少量數(shù)據(jù)快速適應(yīng)到新的task,從而做出準(zhǔn)確的學(xué)習(xí)。目前主要應(yīng)用在冷啟動任務(wù)中。
下面將對這三類Adaptation的方法進(jìn)行介紹。
4.1 Parameter Patch
Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. SIGIR 2019.
許多的?推薦系統(tǒng)為用戶項交互序列建模?, 但很少有人嘗試遷移模型來服務(wù)于不同的下游任務(wù)。這篇文章的任務(wù):?在具有豐富序列交互信息的源域上學(xué)習(xí)一個通用的用戶表示模型,并將其遷移到目標(biāo)域上的各種任務(wù)中(在目標(biāo)域中,用戶是冷的或新的)。
pre-train + fine-tune是實現(xiàn)適應(yīng)下游任務(wù)的一個簡單有效的方法,但是作者發(fā)現(xiàn):1)fine-tune每個任務(wù)的附加輸出層,在推薦場景中表現(xiàn)不佳;2)fine-tune最后(幾個)隱藏層?與輸出層一起,表現(xiàn)良好?但是需要需要大量的工作來確定fine-tune哪幾層;3)fine-tune整個網(wǎng)絡(luò)不高效,而且如果目標(biāo)域的數(shù)據(jù)比較稀疏的時候,fine-tune整個網(wǎng)絡(luò)容易產(chǎn)生過擬合現(xiàn)象。
本文提出的高效fine-tune的靈感來自于Adapter-Tuning in NLP,這篇工作的思路是將 Adapter (下圖中黃色方塊,為bottleneck狀的兩層FFN網(wǎng)絡(luò))加入到 Transformer 中,在針對某個下游任務(wù)微調(diào)時,僅僅改變 Adapter 的參數(shù)。
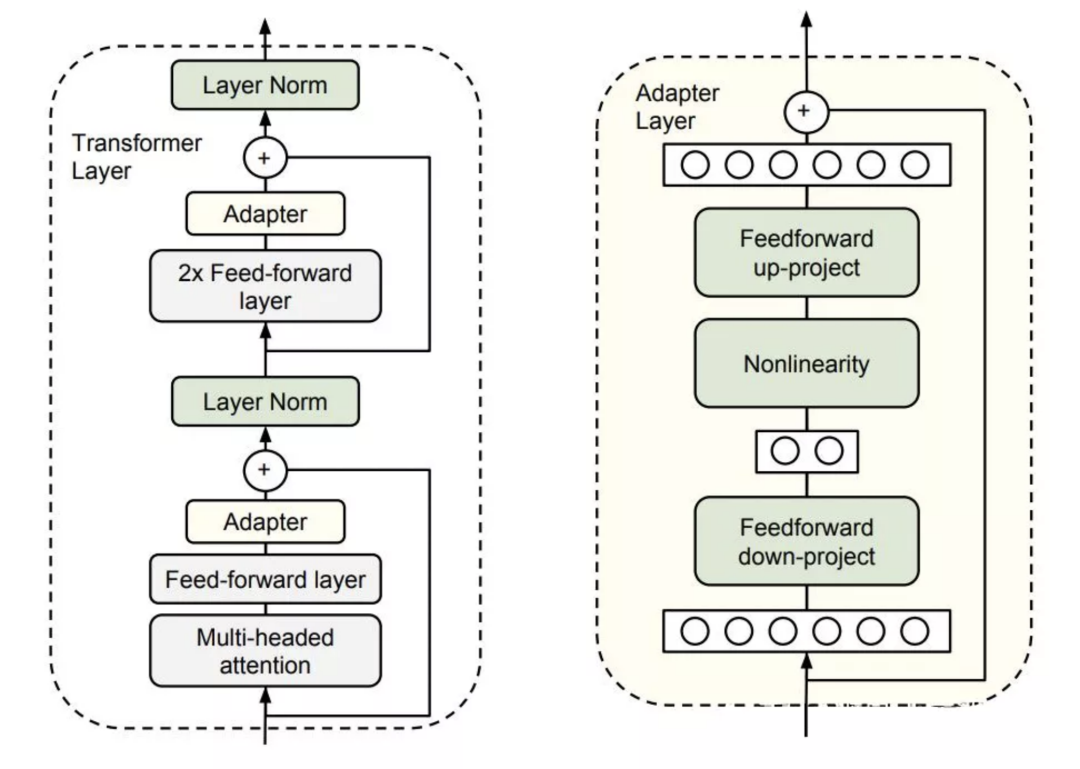
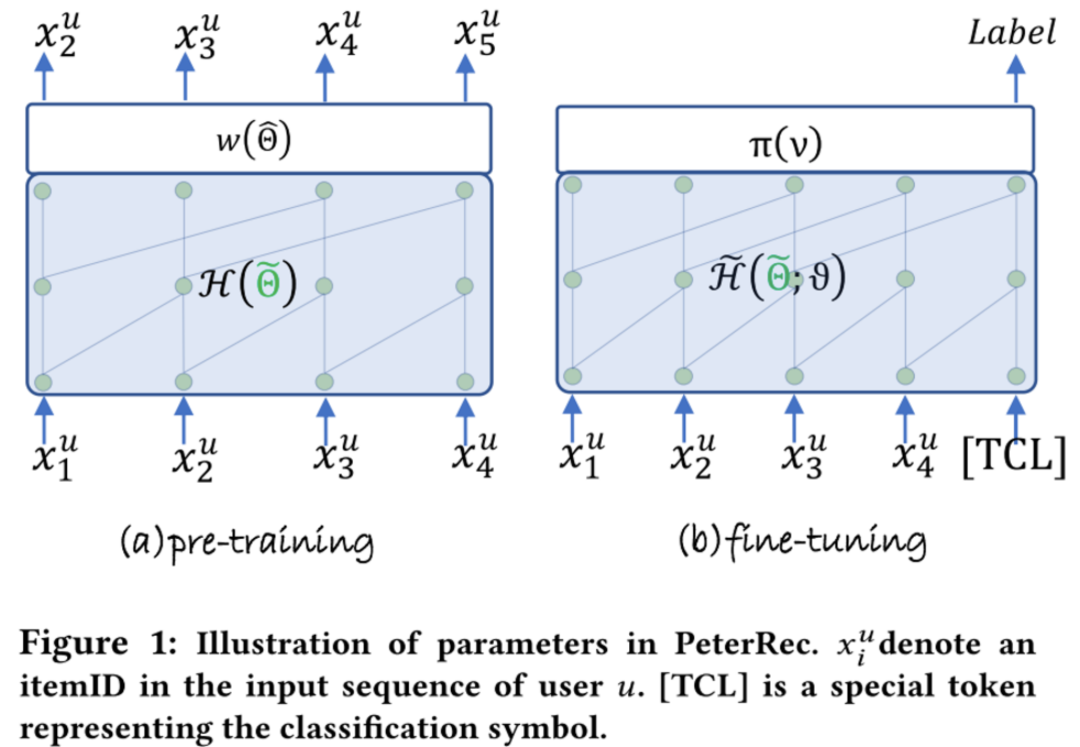
基于此,本文提出了PeterRec,其目標(biāo)是在包含豐富的user-item交互序列的源數(shù)據(jù)集上進(jìn)行pre-train,訓(xùn)練模型網(wǎng)絡(luò)的參數(shù)和輸出層參數(shù);在fine-tune階段,對于目標(biāo)域的任務(wù),固定模型參數(shù),只fine-tune插入在網(wǎng)絡(luò)中的patch的參數(shù)和輸出層參數(shù)。實驗結(jié)果顯示,這種只fine-tune少量參數(shù)的方式不僅可以達(dá)到fine-tune大模型同樣的效果,而且有效避免過擬合。
本文提出了四種不同的Model Patch(MP)的插入方式,分為串行插入和并行插入。
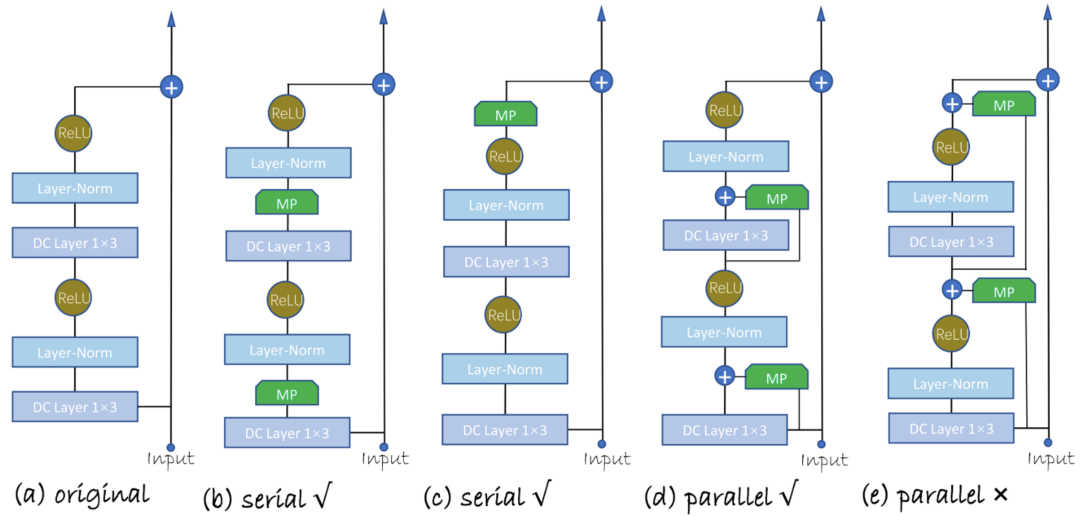
MP的結(jié)構(gòu)與Adapter類似,是一個類似bottleneck的一維卷積網(wǎng)絡(luò)。

One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. CIKM 2021.
傳統(tǒng)的推薦系統(tǒng)通常使用單個域中的數(shù)據(jù)來訓(xùn)練模型,然后服務(wù)于該域的任務(wù)。然而,一個大規(guī)模的推薦系統(tǒng)通常需要服務(wù)于多個域。如果使用共享的大模型(圖(a)),很可能在一些子域表現(xiàn)不好;如果對每一個域單獨(dú)訓(xùn)練一個模型(圖(b)),則開銷太大。因此本文綜合這兩點(diǎn)(圖(c)),既用一個共享的網(wǎng)絡(luò)學(xué)習(xí)全局的信息,又為每一個域各自設(shè)計了一個網(wǎng)絡(luò),來學(xué)習(xí)每個域特有的知識。
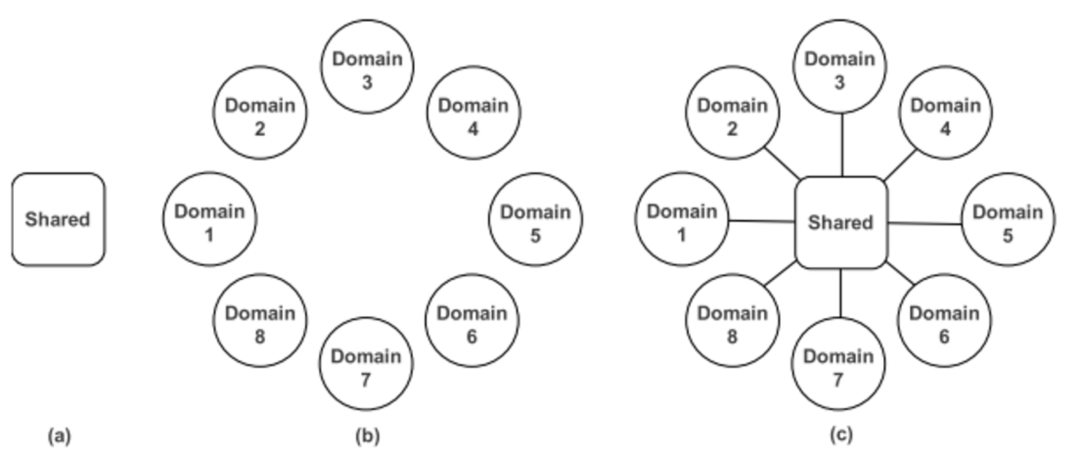
STAR(Star Topology Adaptive Recommender)的出發(fā)點(diǎn)是如何在源數(shù)據(jù)上訓(xùn)練一個大模型,使得其能夠適應(yīng)到不同的域,無論是整體還是在單個域的表現(xiàn)都很好。該任務(wù)也被稱作multi-domain learning。STAR的核心在于提出了一個具有星型拓?fù)浣Y(jié)構(gòu)的全連接層(Star Topology FCN),它具有一個中心的FCN用來共享全局的信息,同時為每一個域單獨(dú)訓(xùn)練一個FCN,作為domain-specific的參數(shù)。
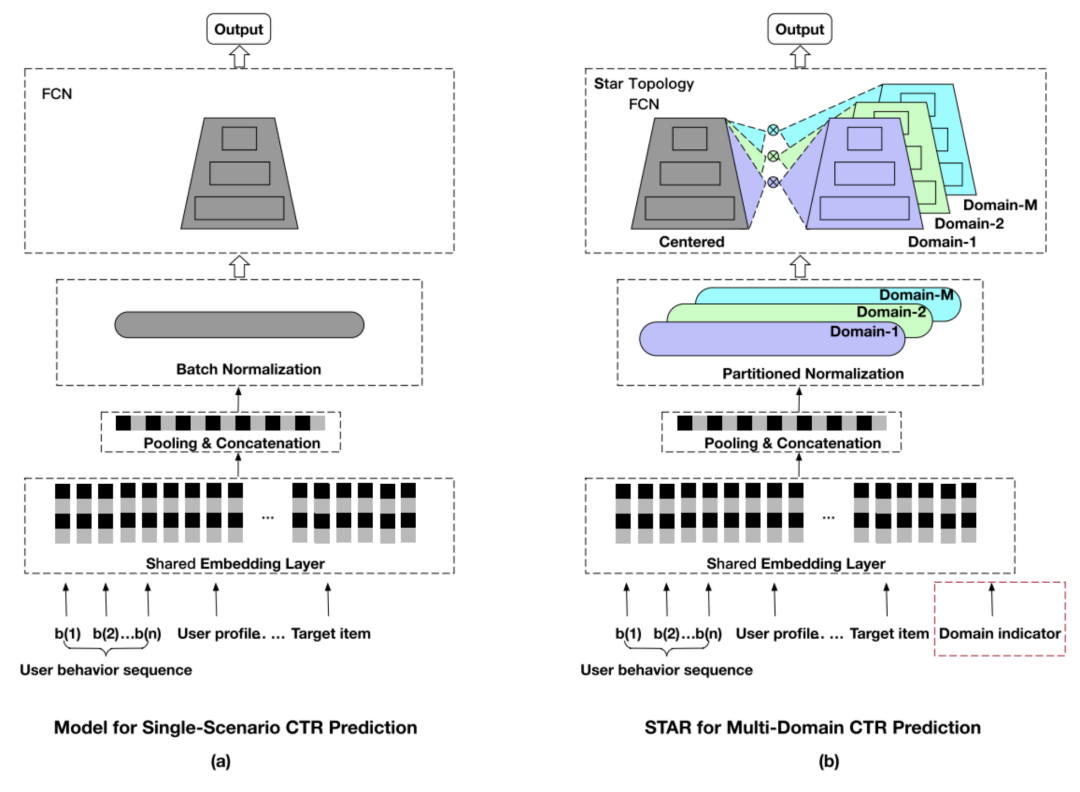
針對某一個域下的CTR任務(wù),模型將shared FCN(參數(shù))和domain-specific FCN(參數(shù))通過下面的公式:
結(jié)合起來,得到最終用于預(yù)測的FCN。
Domain-specific FCN可以看做對單模型的中一種Model Patch,即在原始網(wǎng)絡(luò)中插入針對不同域任務(wù)的網(wǎng)絡(luò),根據(jù)每個域的數(shù)據(jù)訓(xùn)練各自的Patch網(wǎng)絡(luò),從而讓模型達(dá)到在各自域的任務(wù)上以及總體效果都不錯的目的。
其他相關(guān)的工作:
BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. ICML 2019.
K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters. AAAI 2020.
Pretrained Transformers As Universal Computation Engines. 2021.
4.2 Feature Modulation
對于模型中學(xué)到的Feature做Modulation的工作中,主要的技術(shù)可以大概分為對特征做仿射變換(Affine Transformation)和對特征進(jìn)行條件歸一化(Conditional Normalization)。
4.2.1 Affine Transformation
FiLM: Visual Reasoning with a General Conditioning Layer. AAAI 2018.
FiLM學(xué)習(xí)通過基于某些輸入對神經(jīng)網(wǎng)絡(luò)的中間特征應(yīng)用仿射變換,自適應(yīng)地影響神經(jīng)網(wǎng)絡(luò)的輸出。在Visual Reasoning任務(wù)中,模型需要根據(jù)問題自適應(yīng)的調(diào)整CNN捕捉的特征。將問題用GRU編碼后得到的表示作為FiLM的輸入,通過兩個神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)(和)得到縮放和偏差,接著對CNN學(xué)到的中間特征做放射變換。FiLM會插入到每一個ResBlock中,對每一層CNN學(xué)到的特征進(jìn)行modulation。
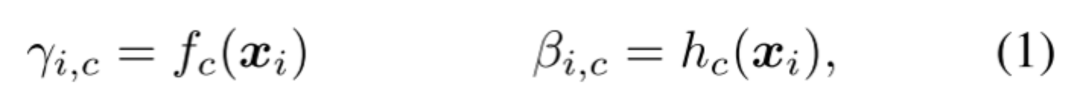
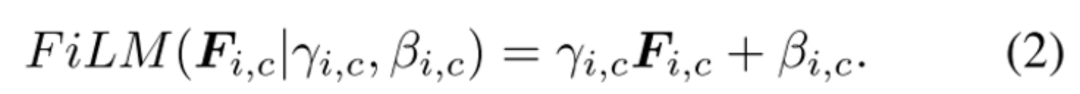
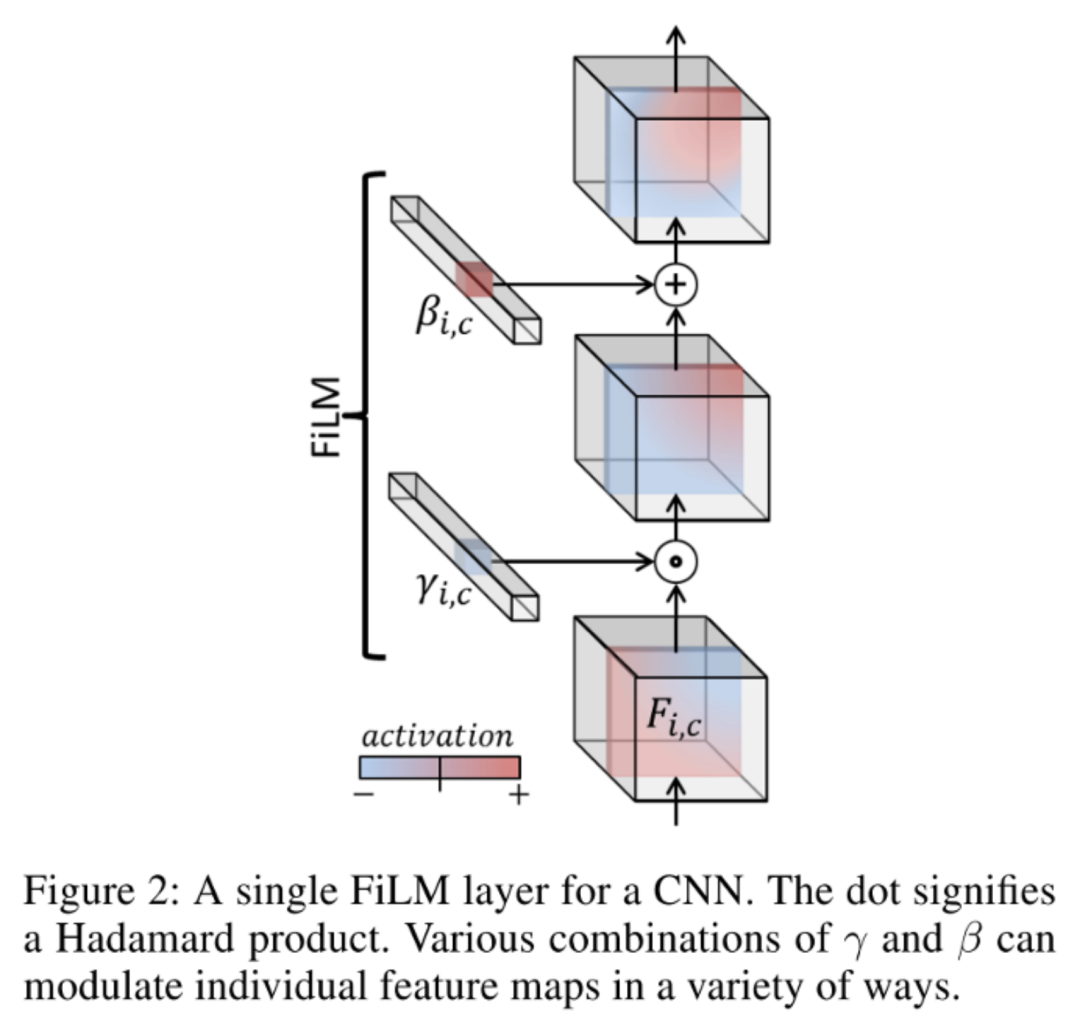

在某種程度上,可以將FiLM視為使用一個網(wǎng)絡(luò)生成另一個網(wǎng)絡(luò)的參數(shù),使其成為超網(wǎng)絡(luò)的一種形式。
Task-adaptive Neural Process for User Cold-Start Recommendation. WWW 2021.
大多數(shù)基于元學(xué)習(xí)的冷啟動推薦模型是基于MAML(本章最后一節(jié)會詳細(xì)介紹),旨在學(xué)習(xí)參數(shù)初始化(全局知識),通過幾步的梯度更新達(dá)到新任務(wù)有良好表現(xiàn)的效果。當(dāng)不同用戶的興趣表現(xiàn)高度相關(guān)時,這些方法表現(xiàn)良好。然而,當(dāng)它們之間的任務(wù)相關(guān)性很弱時,就很難找到一個對所有用戶都最優(yōu)的共享參數(shù)初始化。因此本文的目的是捕獲不同任務(wù)的相關(guān)性,并更有效地將以前任務(wù)中學(xué)到的全局知識適應(yīng)到不同的用戶。
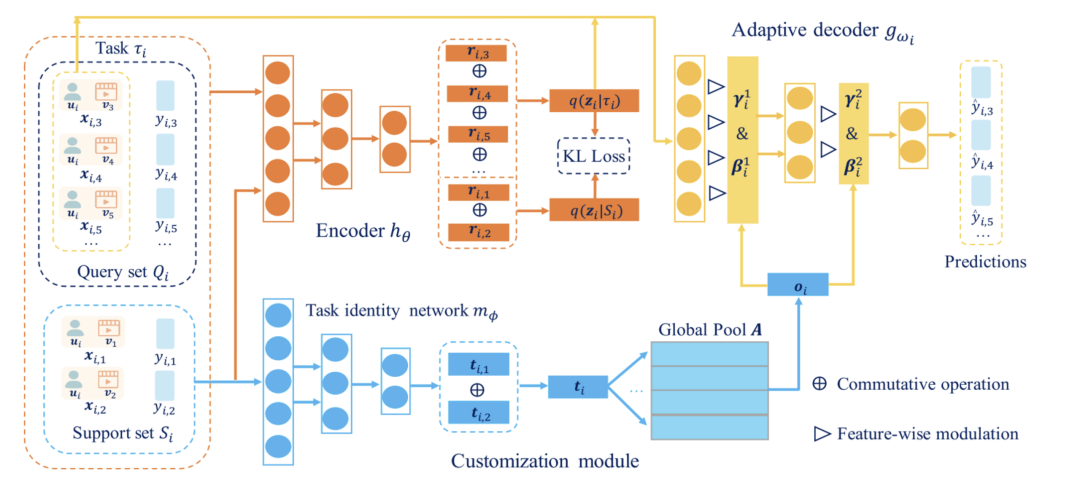
本文提出了TaNP,模型的前兩部分Encoder和Customization Module分別對輸入進(jìn)行編碼以及獲取不同task相關(guān)性的表示。在自適應(yīng)模塊Adaptive Decoder中,TaNP將Customization Module學(xué)到的當(dāng)前user的task embedding作為輸入,使用FiLM兩個生成的參數(shù)來縮放和移動decoder每一層的特征。對于每個用戶的縮放和偏差都不同,以此達(dá)到了自適應(yīng)解碼的目標(biāo):
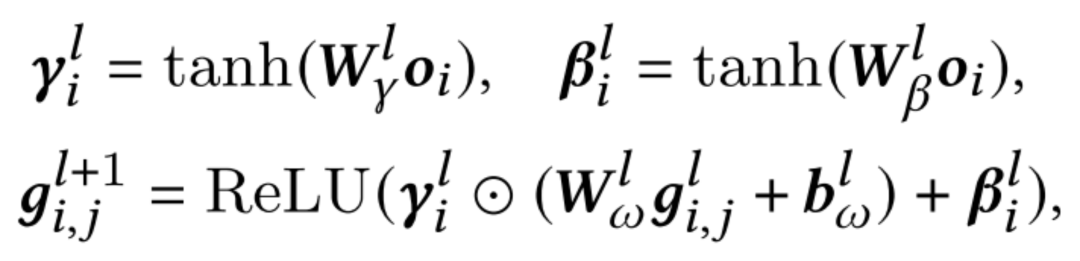
雖然FiLM可以有效地實現(xiàn)Feature Modulation,但一個潛在的問題是這種操作不能過濾一些對學(xué)習(xí)有相反影響的信息。為了緩解這個問題,增強(qiáng)對自適應(yīng)過程中產(chǎn)生相反影響的信息的過濾能力,本文提出了一種更通用的Gating-FiLM,在FiLM的基礎(chǔ)上引入了和,具體公式如下:

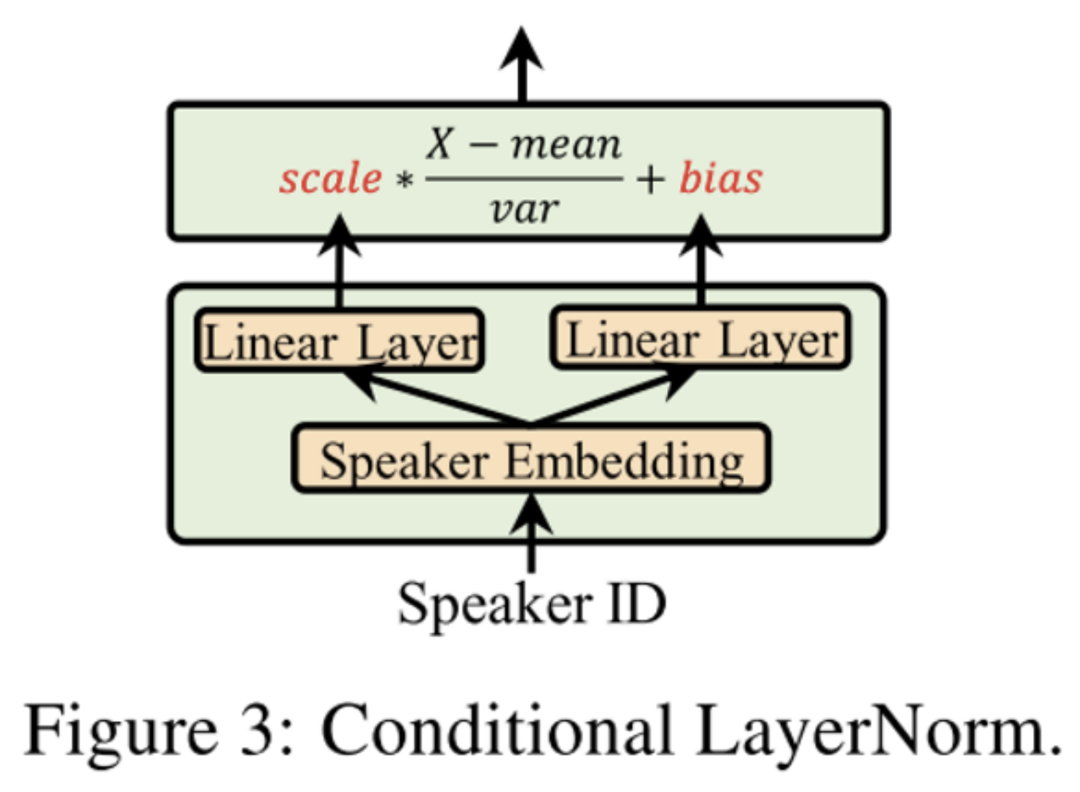
4.2.2 Conditional Normalization
這一類方法假設(shè)一個batch中包含不同類別的訓(xùn)練數(shù)據(jù),放在一起做Normalization不太妥當(dāng),因為不同類別的數(shù)據(jù)理應(yīng)對應(yīng)不同的均值和方差,其歸一化的放縮和偏置也應(yīng)該不同。針對這個問題,一個解決方案是不再考慮整個 batch 的統(tǒng)計特征,而是根據(jù)不同的條件做不同的歸一化。
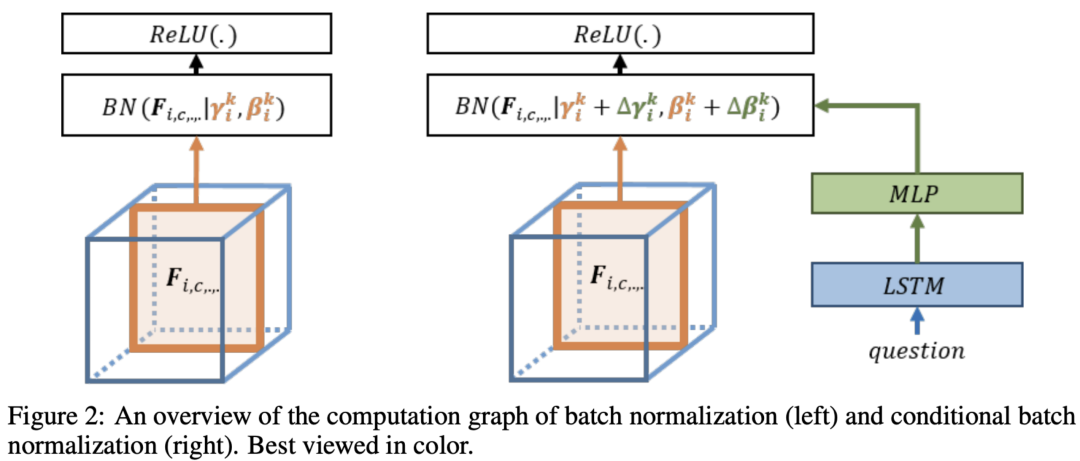
Modulating early visual processing by language. NIPS 2017.
本文最早提出Conditional Batch Normalization。作者提到,ResNet 是預(yù)訓(xùn)練的網(wǎng)絡(luò),用于提取圖片特征,不能輕易修改里面 filter 的參數(shù)。而其中的 BN 層包含兩個參數(shù):縮放和偏差,用于對 feature施加縮放和偏置操作,從圖片含義上講可以解釋為:強(qiáng)調(diào)feature的某部分channel,忽略另外一些channel。而且修改BN的參數(shù)量不大,因此作者決定把問題提取出的特征輸入到MLP中生成和,來修正和,即根據(jù)不同的問題自適應(yīng)地調(diào)整提取圖片的部分信息。
AdaSpeech: Adaptive Text to Speech for Custom Voice. ICLR 2021.
這是一篇Speech領(lǐng)域做自適應(yīng)的工作。語音個性化定制(custom voice)是一項非常重要的文本到語音合成(text to speech, TTS)服務(wù)。其通過使用較少的目標(biāo)說話人的語音數(shù)據(jù),來微調(diào)(適配)一個源 TTS 模型,以合成目標(biāo)說話人的聲音。AdaSpeech做了兩方面的feature級別的自適應(yīng)。
第一,將少量自適應(yīng)數(shù)據(jù)用于個性化語音,通過對不同粒度的聲學(xué)條件進(jìn)行建模(Acoustic Condition Modeling)并融入原有的hidden state中,對網(wǎng)絡(luò)中隱藏的狀態(tài)向量進(jìn)行調(diào)制(modulation),用以支持含有不同類型聲學(xué)條件的語音數(shù)據(jù)。
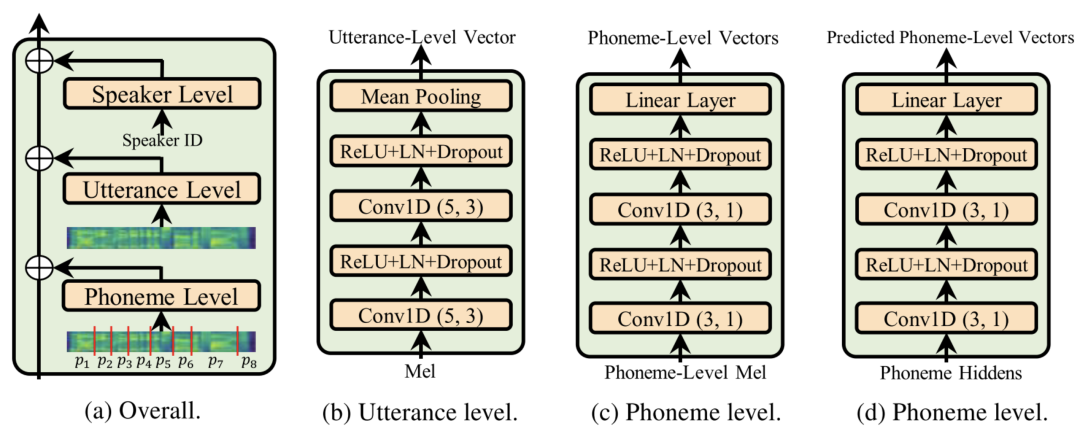
第二,使用了條件層歸一化(Conditional LayerNorm):為了確保自適應(yīng)質(zhì)量的同時fine-tune盡可能少的參數(shù),AdaSpeech在預(yù)訓(xùn)練時修改了解碼器中LayerNorm,使用目標(biāo)speaker的嵌入表示作為條件信息,在層歸一化中直接生成放縮和偏差向量(而不是對原來的參數(shù)做補(bǔ)充)。在fine-tune階段,只調(diào)整與Conditional LayerNorm相關(guān)的參數(shù)。通過這種方式,與fine-tune整個模型相比,可以大大減少自適應(yīng)參數(shù)和計算開銷,更加符合線上應(yīng)用的場景;同時由于Conditional LayerNorm的靈活性,每個speaker的歸一化放縮與偏差都不一樣,模型可以保持高質(zhì)量的自適應(yīng)化語音。
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. CIKM 2021.
STAR提出的Partitioned Normalization(PN),是對BatchNorm做了自適應(yīng)歸一化。在多域CTR預(yù)測中,樣本應(yīng)當(dāng)僅僅假設(shè)為在特定域內(nèi)滿足i.i.d。因此,來自不同領(lǐng)域的數(shù)據(jù)具有不同的歸一化矩,對全部樣本共享BN層是不合理的。為了捕獲每個域中獨(dú)特的數(shù)據(jù)特征,本文提出了分區(qū)規(guī)一化(Partitioned Normalization,PN),它將不同域的規(guī)范化統(tǒng)計數(shù)據(jù)和參數(shù)私有化。具體而言,在訓(xùn)練過程中,為每一個域單獨(dú)訓(xùn)練放縮系數(shù)和偏差,再與全局共享的縮放和偏差結(jié)合。
BN:
PN: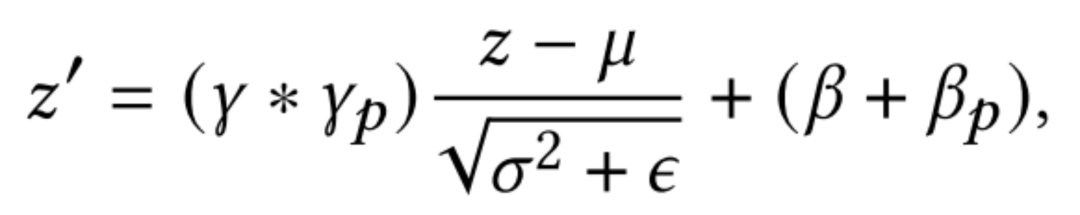
其他相關(guān)的工作:
Dynamic Instance Normalization for Arbitrary Style Transfer. AAAI 2020. (Instance級別的動態(tài)Normalization)
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks. 2021. (借鑒FiLM,通過超網(wǎng)絡(luò)生成Task Conditional Adapter Layers)
4.3 Meta Learning
相對于deep learning在一個task中通過對樣本的學(xué)習(xí)以對新樣本做出判斷,元學(xué)習(xí)的目標(biāo)可以看做是將task視作樣本,通過對多個task的學(xué)習(xí),以使元模型能夠快速適應(yīng)到新的task,做出準(zhǔn)確的學(xué)習(xí)。
MAML:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML 2017.
MAML的設(shè)想是訓(xùn)練一組初始化參數(shù),通過在初始參數(shù)的基礎(chǔ)上進(jìn)行一或多步梯度的調(diào)整,來達(dá)到僅用少量數(shù)據(jù)就能快速適應(yīng)新task的目的。為了達(dá)到這一目的,訓(xùn)練模型需要最大化新task的loss function的參數(shù)敏感度,當(dāng)敏感度提高時,極小的參數(shù)(參數(shù)量)變化也可以對模型帶來較大的改變。MAML算法可以適用于多個領(lǐng)域,不需要通過擴(kuò)充模型的參數(shù)量,無需限制模型結(jié)構(gòu)(如限定RNN網(wǎng)絡(luò)),并且可以根據(jù)不同的問題使用不同的loss函數(shù)。既然希望使用訓(xùn)練好的模型僅通過幾步梯度迭代便可適用于新的task,作者便將目標(biāo)設(shè)定為,通過梯度迭代,找到對于task敏感的參數(shù)。如圖所示,訓(xùn)練完成后的模型具有對新task的學(xué)習(xí)域分布最敏感的參數(shù),因此可以在僅一或多次的梯度迭代中獲得最符合新任務(wù)各自的,達(dá)到較高的準(zhǔn)確率。
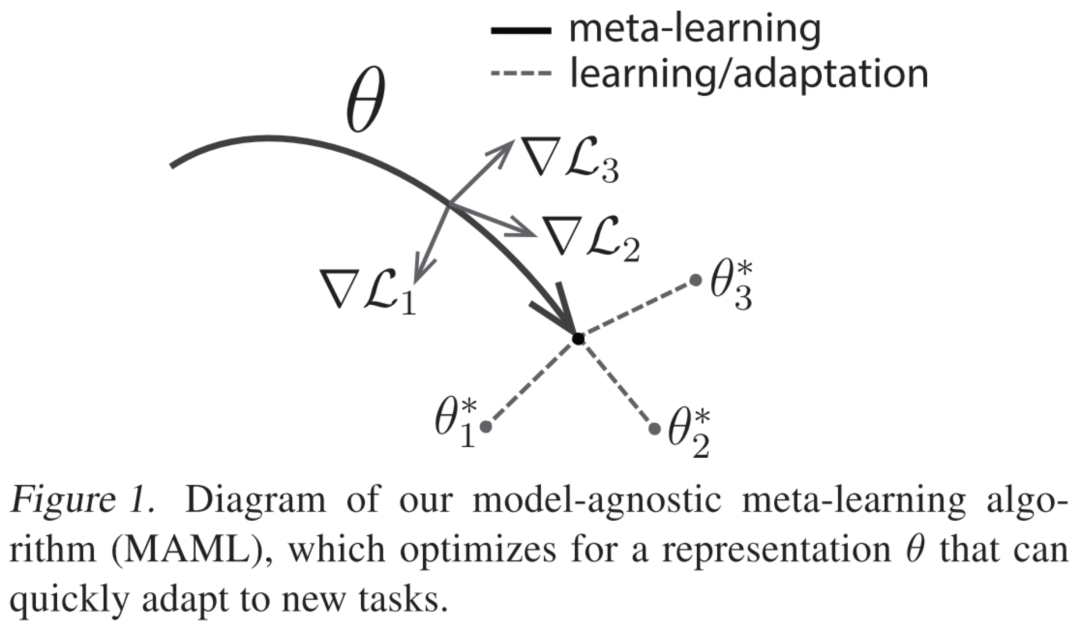
對于少樣本監(jiān)督學(xué)習(xí)(few-shot supervised learning),MAML所做的是對每個task,先取一部分樣本與標(biāo)簽(一般認(rèn)為是support set),將其用于第7行的第一次梯度更新;再取另一部分樣本與標(biāo)簽(query set),統(tǒng)一用第10行的第二次梯度更新,其偽代碼流程圖如下圖所示:

MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation. KDD 2019.
本文主要提出了MeLU模型,使用MAML去解決推薦系統(tǒng)的用戶冷啟動問題。先前的冷啟動推薦研究主要有兩個不足:(1)用戶只有非常少量的物品交互數(shù)據(jù)不足以進(jìn)行很好的推薦;(2)不充分的候選物品被用于識別用戶偏好。本文提出一種基于元學(xué)習(xí)的推薦系統(tǒng)MeLU,可以在很少量的物品條件下估計一個新用戶的偏好。它采用MAML來學(xué)習(xí)一個深度推薦模型共享的初始化參數(shù),然后針對每一個冷啟動用戶,使用有限的交互數(shù)據(jù)來對這個初始化參數(shù)進(jìn)行微調(diào),得到用戶定制化的模型進(jìn)行推薦。
基于元學(xué)習(xí)的推薦任務(wù)有一些通用的設(shè)定:為一個用戶進(jìn)行推薦被視為一項任務(wù)。每個任務(wù)都擁有其支持集(Support Set)和查詢集(Query Set)。在訓(xùn)練階段,模型在支持集上學(xué)習(xí),并在查詢集上更新。在測試階段,根據(jù)支持集中的少量交互推斷冷啟動用戶的偏好。

MeLU在每一輪訓(xùn)練過程中,挑選一定數(shù)量的用戶(相當(dāng)于MAML中的Task)進(jìn)行采樣得到支持集,獲得少量的交互數(shù)據(jù)后,計算在支持集上得到的訓(xùn)練loss,并計算對應(yīng)的梯度實現(xiàn)局部更新。每個用戶進(jìn)行局部更新的目的是,模擬讓模型對新的用戶進(jìn)行學(xué)習(xí)的過程。在全局更新階段則是對所有用戶再次采樣得到的查詢集上進(jìn)行的,每個用戶的查詢集上均可以得到測試loss,并平均后計算梯度。

其他相關(guān)的工作:
Meta-Learning for User Cold-Start Recommendation. IJCNN 2019. (與MeLU類似,使用MAML的框架,但是對local更新參數(shù)時的步長做了限制,步長與global的更新步長有關(guān)。)
Fast Adaptation for Cold-Start Collaborative Filtering with Meta-learning. ICDM 2020. (CF中引入meta learning,同時提出了動態(tài)子圖采樣的方法,對于新用戶能夠自適應(yīng)生成當(dāng)前的任務(wù)表示。)
Personalized Adaptive Meta Learning for Cold-Start User Preference Prediction. AAAI 2021. (當(dāng)用戶偏好差異較大時MAML很難對不同用戶都能做到快速更新,本文提出了一種個性化的自適應(yīng)學(xué)習(xí)速率的元學(xué)習(xí)方法,給每個用戶提供個性化的學(xué)習(xí)率,提高M(jìn)AML的性能)
5. 總結(jié)與展望
模型自適應(yīng)當(dāng)前還是十分火熱的,涉及到的研究領(lǐng)域也非常廣泛。本文梳理了現(xiàn)在推薦系統(tǒng)中常用的一些模型自適應(yīng)的相關(guān)技術(shù),這些技術(shù)的源頭可能來自于NLP、CV、Speech等多種領(lǐng)域,本文也一一做了詳細(xì)的補(bǔ)充和介紹。
本文提到的模型自適應(yīng)技術(shù)包括:1)補(bǔ)充參數(shù)補(bǔ)丁,根據(jù)目標(biāo)域的數(shù)據(jù)訓(xùn)練/調(diào)整補(bǔ)丁的參數(shù),以適應(yīng)到目標(biāo)任務(wù);2)對特征進(jìn)行變換,可以對模型中間的計算特征進(jìn)行仿射變換,也可以對輸入/輸出特征進(jìn)行條件歸一化,讓變換后的特征更加適應(yīng)到目標(biāo)任務(wù);3)使用元學(xué)習(xí),在冷啟動推薦場景中,為每個新用戶快速調(diào)整原模型,得到適應(yīng)后的個性化模型進(jìn)行推薦。
當(dāng)然,模型自適應(yīng)的技術(shù)不僅僅局限于本文所總結(jié)的這些,也有一些工作采用了強(qiáng)化學(xué)習(xí)、模型蒸餾、分布對齊等技術(shù)來完成模型自適應(yīng)。以下列出了一些近期的相關(guān)工作,供大家學(xué)習(xí)參考:
近一年頂會推薦系統(tǒng)adaptation相關(guān)的:
Nonintrusive-Sensing and Reinforcement-Learning Based Adaptive Personalized Music Recommendation. SIGIR 2020. (在音樂推薦系統(tǒng)中使用強(qiáng)化學(xué)習(xí)動態(tài)適應(yīng)當(dāng)前用戶的偏好。) MetaSelector: Meta-Learning for Recommendation with User-Level Adaptive Model Selection. WWW 2021.(使用來自所有用戶的數(shù)據(jù)對一組推薦模型進(jìn)行訓(xùn)練,在此基礎(chǔ)上通過元學(xué)習(xí)對模型選擇器進(jìn)行訓(xùn)練,根據(jù)用戶特定的歷史數(shù)據(jù)為每個用戶適配到最佳的單一模型。) A User-Adaptive Layer Selection Framework for Very Deep Sequential Recommender Models. AAAI 2021. (一個自適應(yīng)的序列化模型推理框架,學(xué)習(xí)為每個用戶自適應(yīng)地跳過原有模型中非活動的隱藏層,每個用戶做推理時保留的參數(shù)是不同的。類似于動態(tài)蒸餾。) Learning Personalized Itemset Mapping for Cross-Domain Recommendation. IJCAI 2020. (使用兩個生成器來構(gòu)建用戶在兩個不同域中的行為隨時間變化的雙向個性化項集映射,并不斷優(yōu)化生成的item集合與實際交互的item集之間的距離,縮小源域和目標(biāo)域的差距。) Personalized Transfer of User Preferences for Cross-domain Recommendation. WSDM 2022. (用輔助源域中的冷啟動用戶之間的交互可以幫助目標(biāo)域中的冷啟動推薦。大多數(shù)現(xiàn)有方法建模一個公共偏好橋接器(preference bridge),為所有用戶遷移偏好。本文則通過元學(xué)習(xí),為每個用戶生成自適應(yīng)的偏好遷移函數(shù),實現(xiàn)每個用戶的個性化偏好轉(zhuǎn)移。) 一些相關(guān)的綜述:
跨域推薦: Cross-Domain Recommendation: Challenges, Progress, and Prospects. A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions. 元學(xué)習(xí): Meta-Learning in Neural Networks: A Survey. 領(lǐng)域自適應(yīng): A Survey of Unsupervised Deep Domain Adaptation. Neural Unsupervised Domain Adaptation in NLP--A Survey. 領(lǐng)域泛化: Generalizing to Unseen Domains: A Survey on Domain Generalization.
專知便捷查看
便捷下載,請關(guān)注專知公眾號(點(diǎn)擊上方藍(lán)色專知關(guān)注)
后臺回復(fù)“推薦系統(tǒng)” 就可以獲取《推薦系統(tǒng)專知資料合集》專知下載鏈接