
帶你捋一捋anchor-free的檢測模型:FCOS
AI編輯:我是小將
相比two-stage方法,one-stage的目標檢測算法更受追捧。one-stage的模型目前可以分為兩大類:anchor-based和anchor-free方法。基于anchor-based的檢測模型包括SSD,YOLOv3,RetinaNet等,這些模型需要在每個位置預先定義一系列anchor來預測邊界框,整個訓練和測試階段都依賴anchor。基于anchor-free的模型不需要anchor,主要是通過檢測關鍵點來直接預測邊界框,如CornerNet是檢測物體的左上角和右下角頂點,但是卻需要耗時的分組策略來得到最終的邊界框,還有一類是檢測物體中心點的方法,如CenterNet通過預測物體的中心點和大小來檢測物體,架構上更簡單,速度也更快。這里要介紹的FCOS屬于anchor-free,但是卻不是基于關鍵點檢測的方法,嚴格來看其更接近基于anchor-based的方法,但是不需要anchor并加上特殊的設計卻能夠實現更好的效果。
從anchor說起
對于anchor-based的方法,其在輸出特征圖每個位置放置一系列固定的anchor,這樣做的好處是將目標框和anchor綁定在一起,在訓練過程中只需要計算GT和anchor的IoU并設定閾值條件來定義正負樣本,另外一方面可以通過設定不同大小和寬高比的anchor來適應檢測目標的尺度變化性,以保證召回。雖然基于anchor的檢測算法取得了很好的效果,但是anchor總顯得有點多余。其實YOLOv1并沒有使用anchor,沒有anchor的YOLOv1是直接將目標框和特征圖上的cell綁定在一起,目標框的中心點落在這個cell內,但YOLOv1的recall較低,后面版本都用了anchor。但我們是可以將特征圖上cell和目標框直接關聯(lián)在一起,而不用anchor,這樣目標檢測就和語義分割一樣變成了直接的pixel預測(pixel和cell是等同的)。FCOS就是這樣做的,具體來說就是直接用包含目標的cell來回歸目標,如圖1所示,左圖中橙色框中某個cell直接預測與目標框的4個偏移量,但是如果一個cell包含在多個目標之中,這就出現了沖突:這個cell到底該回歸哪個目標?如右圖所示。FCOS通過一系列設計來解決這個問題,這也是FCOS的核心。

圖1 FCOS整體設計理念
FCOS采用的網絡架構和RetinaNet一樣,都是采用FPN架構,如圖2所示,每個特征圖后是檢測器,檢測器包含3個分支:classification,regression和center-ness。
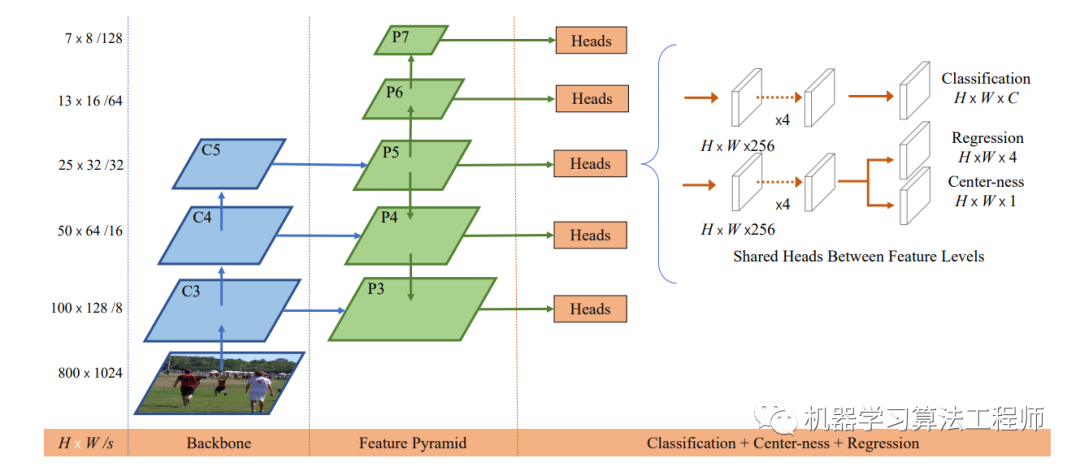
圖2 FCOS整體架構
檢測器
對于特征圖,其相對于輸入圖片的stride定義為,另外記GT為,這里,其中和分別是GT的左上角和右下角頂點坐標,而是GT的類別。對于特征圖上的每個位置,如果其落在任何GT的中心區(qū)域,就認為這個位置為正樣本,并負責預測這個GT。在最早的版本是落在GT之內就算正樣本,不過采用中心區(qū)域策略效果更好(?yqyao/FCOS_PLUS),兩者的區(qū)別如圖3所示。一個中心為的GT,其中心區(qū)域定義為GT框的一個子框,這里是特征圖的stride,而是一個超參數,論文中選用的是1.5,一個要注意的點是在實現中要保證中心區(qū)域不超過GT。盡管采用中心區(qū)域抽樣方法,可以減少前面說的沖突問題,但是無法保證,如果一個位置落在了多個GT的中心區(qū)域,此時就是模糊樣本。FCOS采用的一個策略是選擇面積最小的GT作為target,后面會談到結合FPN,FCOS可以大大減少模糊樣本的出現。
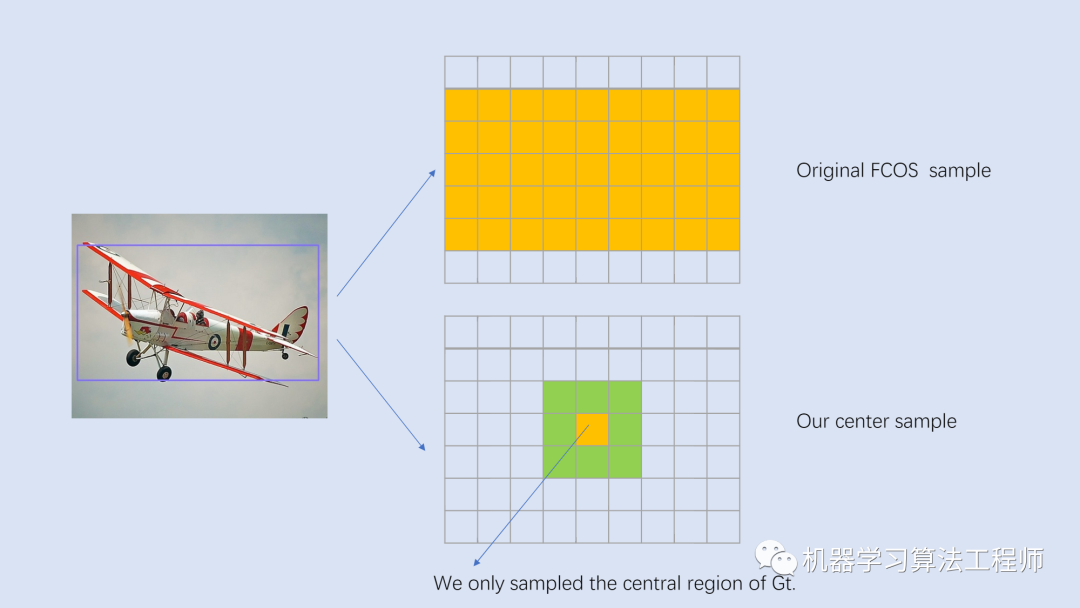
圖3 正負樣本的判定策略
對于classification分支,和RetinaNet一樣采用個二分類,共輸出個預測值,loss采用focal loss。對于regression分支,每個位置預測一個實數向量,其對應的target為當前位置與GT框4個頂點間的距離:
這里用特征圖的stride來對回歸的target進行縮放,以避免訓練過程中的可能出現的梯度爆炸。由于4個回歸值要大于0,最后的輸出采用ReLU來保證回歸值的范圍為。
FCOS在regression分支的末尾添加了一個額外的center-ness分支(最早的版本是放在classification分支,但是放在regression分支效果更好)來抑制那些由那些偏離目標中心的位置所預測的低質量檢測框。center-ness分支只預測一個值:當前位置與要預測的物體中心點之間的歸一化距離,值在[0, 1]之間,圖4給出了可視化效果,其中紅色和藍色值分別1和0,其它顏色介于兩者之間,從物體中心向外,center-ness從1遞減為0。
 圖4 center-ness可視化
圖4 center-ness可視化
給定回歸的,center-ness的target定義為:
由于center-ness值在0~1之間,訓練過程中可以采用BCE損失。在測試階段,最終的置信度為center-ness和分類概率的乘積:
這里的sqrt可以改變置信度的數量級(FCOS的預測框置信度偏低),但是不會影響評測的AP值。實驗證明center-ness的使用可以使FCOS在COCO數據集上的AP值提升1個點左右,另外論文也定量分析了center-ness分支在壓制低質量檢測框的作用,如圖5所示,可以看到未使用center-ness,FCOS會檢出一定量的高置信度但低IoU的邊界框(在IoU閾值下就是FP),而使用center-ness后這部分數量大大減少。
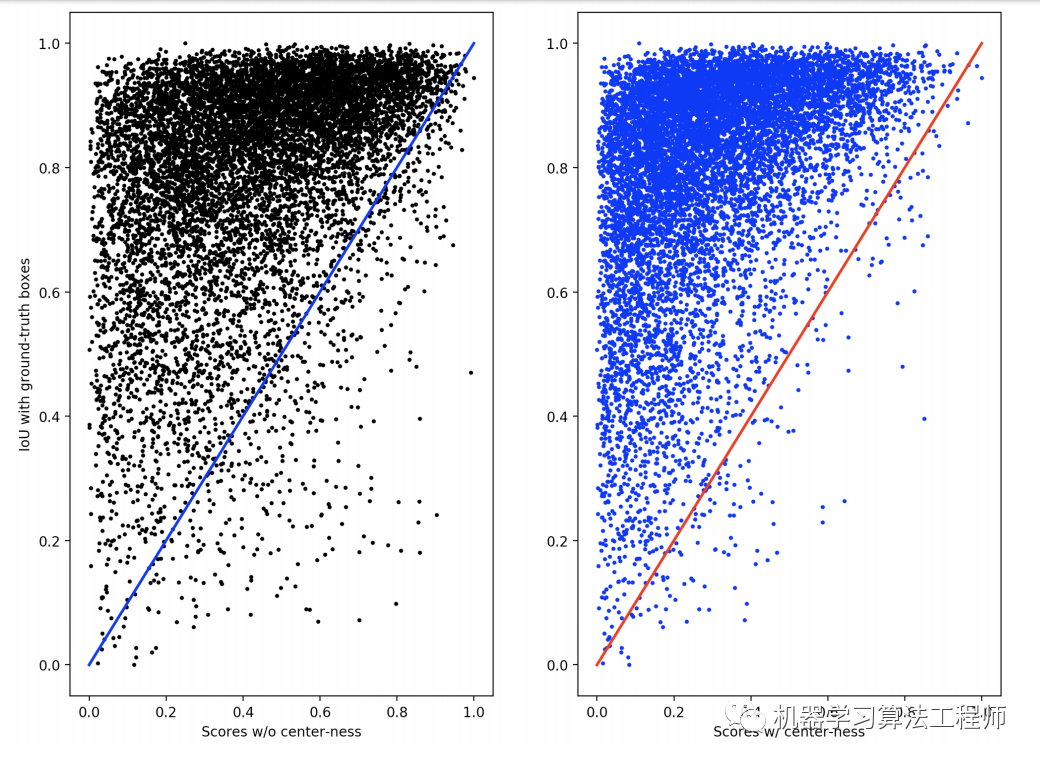 圖5 使用center-ness分支前后的定量分析
圖5 使用center-ness分支前后的定量分析
長久以來,檢測模型的分類和回歸分支是孤立的,這可能導致模型對物體的分類和定位不一致,就像前面所說的分類概率高但定位不準確,如圖6所示,這對于AP值是不利的。類似的工作還有?IoU-aware RetinaNet,在RetinaNet模型的回歸分支增加一個預測IoU的分支,AP值可以提升1~2%。
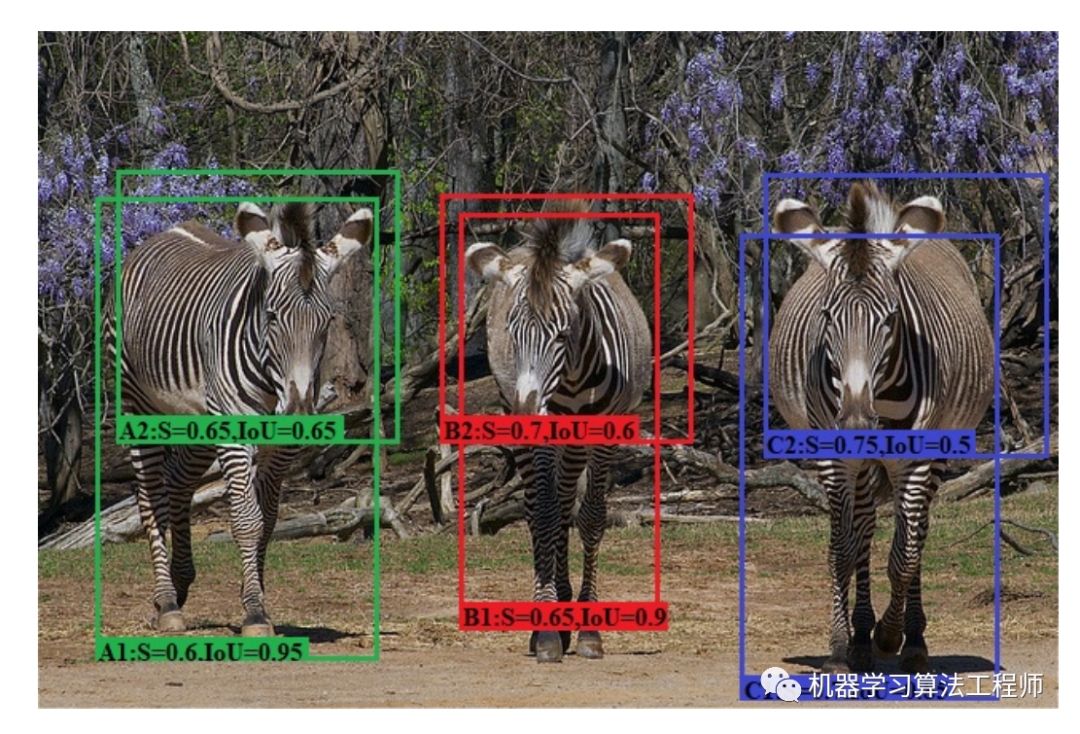 圖6 檢測模型的分類和定位不一致
圖6 檢測模型的分類和定位不一致
另外,最新的論文?Generalized Focal Loss更進一步地將對預測框的定位質量評估和分類分支聯(lián)合在一起訓練,因為FCOS的center-ness分支在訓練時其實是和分類是分開的,只是在測試時結合在一起,這存在一個訓練和測試的不一致。另外論文也指出用IoU比用center-ness評估預測框更好,主要原因在于center-ness的label往往要比IoU要小一些,如下圖所示,這導致有可能一部分樣本比較難召回。
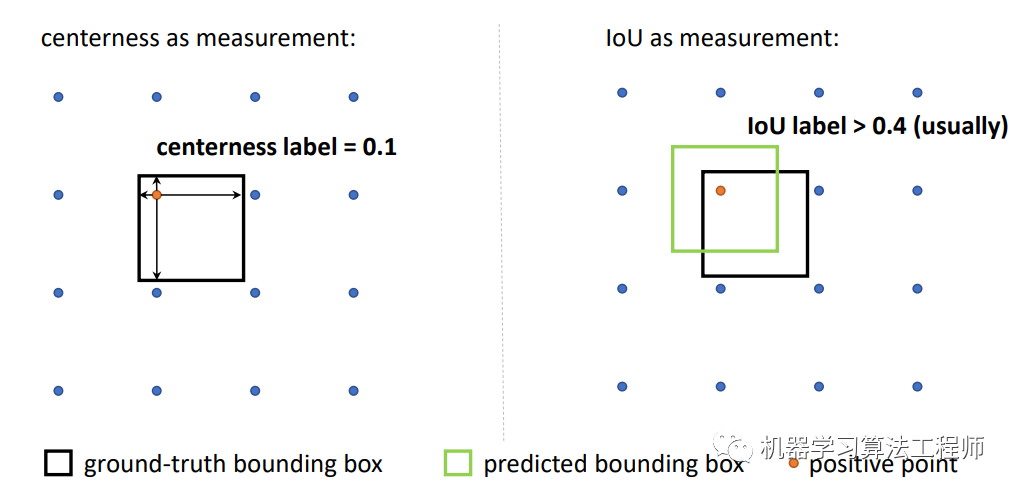 圖7 IoU和center-ness的label對比
圖7 IoU和center-ness的label對比
綜上,FCOS的訓練loss包含三個部分:
這里的當為正樣本時取1,為負樣本時取0,所以和只有正樣本才計算。而為權重系數,在論文中均取1。前面已經說過分類loss采用focal loss,而center-ness采用BCE損失,這里的回歸loss采用GIoU,其效果優(yōu)于IoU。
FPN
對于anchor-based方法,采用FPN時會將不同大小的anchor放置在不同大小的特征圖上,特征圖越小,感受野相應更大,用來檢測更大的物體。同樣地,這種設計理念可以用在FCOS模型上,以解決前面所說的模糊樣本問題。
與RetinaNet一樣,FCOS也采用5個大小不同的特征圖,其對應的stride分別是。與RetinaNet不同的一點是,和在之后加stride為2的3x3卷積得到,而不是來自于,這樣好處是一方面可以減少參數量,另外由于產生的特征圖語義更強而效果更好。
對于anchor-based方法,由于是根據anchor和GT的IoU來進行匹配,所以很自然地將大小不同的GT分配到不同的特征圖。而FCOS直接通過限制不同特征圖上目標回歸值來達到這一目的。具體來說,每個特征圖會設定一個回歸值的下限值和上限值,某個GT在該特征圖上正樣本位置(滿足前面所述的中心區(qū)域內條件)還要滿足目標回歸值大小限制:
這樣就限制了不同特征圖上的回歸距離,從而將不同大小的目標分配到不同特征圖上,因為不同特征圖的感受野不同,通過這種方式可以確保要回歸的物體整個包含在特征圖的感受野內。論文中,分別設定為,那么特征圖覆蓋的是[0,64]之間的目標回歸值,而則是負責512以上的目標回歸值。與RetinaNet一樣,所有的檢測器head在各個特征圖上是共享的,但是由于不同特征圖對應的回歸值范圍差異較大,可能學習成本大,所以最早版本FCOS在regression分支最后輸出是乘以一個可學習的scale值以解決這個問題:
class?Scale(nn.Module):
????def?__init__(self,?init_value=1.0):
????????super(Scale,?self).__init__()
????????self.scale?=?nn.Parameter(torch.FloatTensor([init_value]))
????def?forward(self,?input):
????????return?input?*?self.scale
但是現在的版本中,前面已經提到每個特征圖上的回歸值其實是已經除以特征圖的進行縮放,這樣就和學習一個scale值基本等同,所以加不加這個策略都可以。
模糊樣本的出現大部分是由于物體重疊造成的,但是重疊的物體大部分其大小是不同的,所以FPN的使用可以更一步解決模糊樣本問題。
BPR
FCOS沒有使用anchor,那么一個風險點就是和YOLOv1一樣recall較低,論文中通過計算訓練過程中BPR指標( Best Possible Recall)證明了FCOS的recall上限與RetinaNet基本相差不大。這里的BPR定義為訓練過程中所有GT的最大召回率,如果訓練過程中一個GT被某個anchor或者location匹配上那么就認為被召回了。基于COCO val2017數據集,RetinaNet和FCOS的BPR指標如表1所示,可以看到FCOS使用FPN后BPR可以達到98.95%,僅僅稍低于采用low-quality-matches(指的是允許某個GT匹配給IoU最大的anchor,盡管最大IoU值可能低于閾值)的RetinaNet。從BPR指標來看,FCOS和RetinaNet基本相差無幾。不過BPR還是都沒有達到100%,這主要是因為前面所說的模糊樣本問題,或者說是沖突。
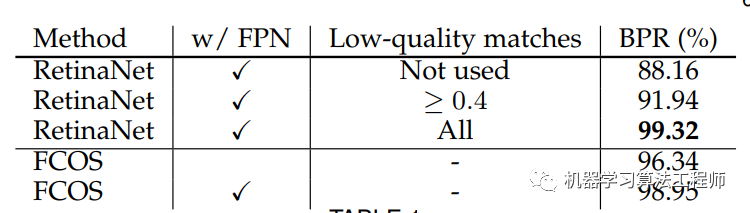 表1 RetinaNet和FCOS的BPR指標對比
表1 RetinaNet和FCOS的BPR指標對比
論文中也統(tǒng)計了模糊樣本占比,如表2所示,這里的1, 2 ?≥ 3表示一個位置被分配給GT的數量,當大于1時這個位置就是模糊樣本。可以看到采用中心抽樣策略和FPN后,FCOS模糊樣本占比只有2.66%。
 表2 FCOS模糊樣本分布統(tǒng)計
表2 FCOS模糊樣本分布統(tǒng)計
模型效果
這里主要關注FCOS和RetinaNet模型在COCO數據集上的效果對比,如表3所示,可以看到FCOS的AP明顯高于原生RetinaNet(38.9 VS 35.9)。但是當RetinaNet也采用FCOS的某些策略(GN,GIoU loss和FPN用P5替代C5來得到P6,P7),RetinaNet模型效果也提升較大,僅和FCOS相差一個點左右。更進一步,如果FCOS去掉center-ness分支,FCOS和RetinaNet效果基本接近了。另外?ATSS也證明了如果RetinaNet如果僅每個位置放置一個anchor,但采用FCOS的所有策略,兩種效果差別也不大。這就說明其實anchor-free和anchor-based的方法實際效果相差并不大,FCOS和RetinaNet的差異僅在于兩者對正負樣本定義策略差異,據此ATSS也提出了效果更好的策略。不過依然致敬FCOS,畢竟也是一個非常扎實的work。

表3 FCOS和RetinaNet對比
FCOS核心實現
目前FCOS官方代碼已經開源在?AdelaiDet,代碼基于detectron2框架。這里主要關注FCOS最核心的部分,就是正負樣本的定義策略,代碼如下:
def?compute_targets_for_locations(self,?locations,?targets,?size_ranges,?num_loc_list):
????"""
????Args:
????????locations:?[N,?2],?所有FPN層cat后的位置
????????targets:?GT,detectron2格式
????????size_ranges:?[N,?2],?各個位置所在FPN層的回歸size限制(min,max)
????????num_loc_list:?list,各個FPN層的位置數
????"""
????labels?=?[]??#?各個位置的類別target
????reg_targets?=?[]?#?各個位置的回歸target
????xs,?ys?=?locations[:,?0],?locations[:,?1]??#?位置x,y坐標
????num_targets?=?0??#?用于索引
????#?for循環(huán)處理各個image
????for?im_i?in?range(len(targets)):
????????targets_per_im?=?targets[im_i]
????????bboxes?=?targets_per_im.gt_boxes.tensor?#?[M,?4]
????????labels_per_im?=?targets_per_im.gt_classes?#?[M]
????????#?無GT,默認target全為負樣本
????????if?bboxes.numel()?==?0:
????????????labels.append(labels_per_im.new_zeros(locations.size(0))?+?self.num_classes)
????????????reg_targets.append(locations.new_zeros((locations.size(0),?4)))
????????????continue
????????area?=?targets_per_im.gt_boxes.area()?#?[M]
????????#?計算每個位置與各個GT的l,t,r,b
????????l?=?xs[:,?None]?-?bboxes[:,?0][None]?#?[N,?M]
????????t?=?ys[:,?None]?-?bboxes[:,?1][None]?#?[N,?M]
????????r?=?bboxes[:,?2][None]?-?xs[:,?None]?#?[N,?M]
????????b?=?bboxes[:,?3][None]?-?ys[:,?None]?#?[N,?M]
????????reg_targets_per_im?=?torch.stack([l,?t,?r,?b],?dim=2)?#?[N,?M,?4]
????????if?self.center_sample:?#?中心采樣
????????????is_in_boxes?=?self.get_sample_region(
????????????????bboxes,?self.strides,?num_loc_list,?xs,?ys,
????????????????bitmasks=None,?radius=self.radius
????????????)?#?[N,?M]
????????else:?#?全部采樣
????????????is_in_boxes?=?reg_targets_per_im.min(dim=2)[0]?>?0?#?[N,?M]
????????max_reg_targets_per_im?=?reg_targets_per_im.max(dim=2)[0]?#?[N,?M]
????????#?限制每個位置所屬FPN的size限制
????????is_cared_in_the_level?=?\
????????????(max_reg_targets_per_im?>=?size_ranges[:,?[0]])?&?\
????????????(max_reg_targets_per_im?<=?size_ranges[:,?[1]])??#?[N,?M]
????????#?GT的面積
????????locations_to_gt_area?=?area[None].repeat(len(locations),?1)?#?[N,?M]
????????locations_to_gt_area[is_in_boxes?==?0]?=?INF??#?排除條件1:GT內或者GT中心區(qū)域
????????locations_to_gt_area[is_cared_in_the_level?==?0]?=?INF?#?排除條件2:FPN size限制
????????#?每個位置可能匹配多個GT,所以要選取最小面積的GT
????????#?locations_to_gt_inds:?[N],?每個位置要回歸的GT?index
????????locations_to_min_area,?locations_to_gt_inds?=?locations_to_gt_area.min(dim=1)
????????#?回歸target
????????reg_targets_per_im?=?reg_targets_per_im[range(len(locations)),?locations_to_gt_inds]
????????#?分類target
????????labels_per_im?=?labels_per_im[locations_to_gt_inds]
????????#?負樣本處理,這里用self.num_classes為負樣本
????????labels_per_im[locations_to_min_area?==?INF]?=?self.num_classes
????????labels.append(labels_per_im)
????????reg_targets.append(reg_targets_per_im)
總體上看,代碼邏輯比RetinaNet的IoU策略更復雜一些,這里只需要計算分類和回歸的target即可,因為center-ness分支的target可以用回歸target計算得到:
def?compute_ctrness_targets(reg_targets):
????if?len(reg_targets)?==?0:
????????return?reg_targets.new_zeros(len(reg_targets))
????left_right?=?reg_targets[:,?[0,?2]]
????top_bottom?=?reg_targets[:,?[1,?3]]
????ctrness?=?(left_right.min(dim=-1)[0]?/?left_right.max(dim=-1)[0])?*?\
?????????????????(top_bottom.min(dim=-1)[0]?/?top_bottom.max(dim=-1)[0])
????return?torch.sqrt(ctrness)
至于上面的中心采樣策略,其實現代碼如下,注意中心區(qū)域要限制在GT內:
def?get_sample_region(self,?boxes,?strides,?num_loc_list,?loc_xs,?loc_ys,?bitmasks=None,?radius=1):
????center_x?=?boxes[...,?[0,?2]].sum(dim=-1)?*?0.5??#?[M,]
????center_y?=?boxes[...,?[1,?3]].sum(dim=-1)?*?0.5??#?[M,]
????num_gts?=?boxes.shape[0]
????K?=?len(loc_xs)
????boxes?=?boxes[None].expand(K,?num_gts,?4)??#?[N,?M,?4]
????center_x?=?center_x[None].expand(K,?num_gts)??#?[N,?M]
????center_y?=?center_y[None].expand(K,?num_gts)??#?[N,?M]
????center_gt?=?boxes.new_zeros(boxes.shape)??#?[N,?M,?4]
????#?無GT
????if?center_x.numel()?==?0?or?center_x[...,?0].sum()?==?0:
????????return?loc_xs.new_zeros(loc_xs.shape,?dtype=torch.uint8)
????beg?=?0
????#?for循環(huán)處理各個FPN層
????for?level,?num_loc?in?enumerate(num_loc_list):
????????end?=?beg?+?num_loc
????????#?計算中心區(qū)域范圍
????????stride?=?strides[level]?*?radius
????????xmin?=?center_x[beg:end]?-?stride
????????ymin?=?center_y[beg:end]?-?stride
????????xmax?=?center_x[beg:end]?+?stride
????????ymax?=?center_y[beg:end]?+?stride
????????#?限制中心區(qū)域不超過GT
????????center_gt[beg:end,?:,?0]?=?torch.where(xmin?>?boxes[beg:end,?:,?0],?xmin,?boxes[beg:end,?:,?0])
????????center_gt[beg:end,?:,?1]?=?torch.where(ymin?>?boxes[beg:end,?:,?1],?ymin,?boxes[beg:end,?:,?1])
????????center_gt[beg:end,?:,?2]?=?torch.where(xmax?>?boxes[beg:end,?:,?2],?boxes[beg:end,?:,?2],?xmax)
????????center_gt[beg:end,?:,?3]?=?torch.where(ymax?>?boxes[beg:end,?:,?3],?boxes[beg:end,?:,?3],?ymax)
????????beg?=?end
????left?=?loc_xs[:,?None]?-?center_gt[...,?0]
????right?=?center_gt[...,?2]?-?loc_xs[:,?None]
????top?=?loc_ys[:,?None]?-?center_gt[...,?1]
????bottom?=?center_gt[...,?3]?-?loc_ys[:,?None]
????center_bbox?=?torch.stack((left,?top,?right,?bottom),?-1)
????inside_gt_bbox_mask?=?center_bbox.min(-1)[0]?>?0??#?位置在GT的中心區(qū)域
????return?inside_gt_bbox_mask
總結
FCOS是一個很特別的基于anchor-free的檢測模型,因為它不是基于關鍵點進行檢測,而是每個位置直接回歸目標,從另外一方面講,FCOS雖沒有anchor,但實際上和RetinaNet非常相似。但是FCOS依然是一個不錯的工作,它讓我們重新思考這種密集anchor的方式其實非常不必要,只要采用更好的正負樣本定義策略,ATSS更進一步強化了這個問題的重要性。
參考
?FCOS: A Simple and Strong Anchor-free Object Detector ?IoU-aware Single-stage Object Detector for Accurate Localization ?Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection ?Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection ?AdelaiDet
如果覺得不錯,請關注一下公眾號,也請為小編點個在看,關注公眾號,回復加群,進群學習交流
推薦閱讀
機器學習算法工程師
? ??? ? ? ? ? ? ? ? ? ? ? ??????????????????一個用心的公眾號
?
