
谷歌發(fā)布萬億參數(shù)語言模型,語言模型何時超越人類語言能力?

??新智元報道?
??新智元報道?
來源:venturebeat
編輯:keyu
【新智元導(dǎo)讀】處理過程更加復(fù)雜的人類語言模型在近幾年得到了迅速發(fā)展,近日Google提出萬億參數(shù)語言模型Switch Transformer,進一步提高了語言模型可以達到的頂峰。這一切都表明,語言模型領(lǐng)域正處于「快速升溫」的階段,未來如何,我們拭目以待。
在短短幾年時間里,深度學(xué)習(xí)算法經(jīng)過了飛速的進化,已經(jīng)具有了可以打敗世界最頂尖棋手的水平,并能以不低于人類識別的準(zhǔn)確度來精確地識別人臉。
?
但事實證明,掌握獨特而復(fù)雜的人類語言,是人工智能面臨的最艱巨挑戰(zhàn)之一。
?
這種現(xiàn)狀會被改變嗎?
?
如果計算機可以具有有效理解所有人類語言的能力,那么這將會徹底改變世界各地的品牌、企業(yè)和組織之間打交道的方式。
可媲美人類的視覺識別模型「率先登場」
?
直到2015年,能夠以與人類相當(dāng)?shù)臏?zhǔn)確率識別人臉的算法才出現(xiàn):臉書DeepFace的準(zhǔn)確率為97.4%,略低于人類的97.5%。
?
而作為參考,F(xiàn)BI的面部識別算法僅達到85%的準(zhǔn)確率,這意味著仍然有超過七分之一的情況是錯誤的。
?
FBI的算法是由一組工程師手工設(shè)計的:每個功能,比如鼻子的大小和眼睛的相對位置,都是手動編程的。
?
而Facebook的算法則主要處理學(xué)習(xí)到的特征,它使用了一種特殊的深度學(xué)習(xí)架構(gòu),稱為卷積神經(jīng)網(wǎng)絡(luò),這個網(wǎng)絡(luò)模仿了我們視覺皮層不同層次處理圖像的方式。
Facebook之所以能夠做到如此高的準(zhǔn)確率,是因為它恰當(dāng)?shù)睦昧丝梢詫崿F(xiàn)學(xué)習(xí)功能的架構(gòu)和數(shù)百萬用戶在分享的照片中標(biāo)記好友的高質(zhì)量數(shù)據(jù),這兩個元素成為了訓(xùn)練好的視覺模型可以達到人類識別水平的關(guān)鍵。
多語種高精度語言模型「姍姍來遲」
相比起視覺問題,語言似乎要復(fù)雜得多——據(jù)我們所知,人類是目前唯一使用復(fù)雜語言交流的物種。
?
不到十年前,如果要理解文本是什么,人工智能算法只會計算特定單詞出現(xiàn)的頻率。但這種方法顯然忽略了一個事實 : 單詞有同義詞,而且只有在特定的上下文中才有意義。
?
2013年,Tomas Mikolov和他在谷歌的團隊發(fā)現(xiàn)了如何創(chuàng)建一個能夠?qū)W習(xí)單詞含義的結(jié)構(gòu):
?
他們的word2vec算法可以將同義詞之間彼此映射,并且能夠?qū)νx詞的大小、性別、速度進行建模,甚至還可以學(xué)習(xí)到諸如國家和首都等函數(shù)的關(guān)系。

然而,仍有很重要的一部分沒有得到處理——語境(上下文關(guān)系)。
?
這一領(lǐng)域的真正突破出現(xiàn)在2018年,當(dāng)時,谷歌重磅引入了BERT模型:
?
Jacob Devlin和他的團隊利用了一種典型的用于機器翻譯的架構(gòu),并使其學(xué)習(xí)與句子上下文相關(guān)的單詞的含義。通過教會這個模型去填補維基百科文章中缺失的單詞,這個團隊能夠?qū)⒄Z言結(jié)構(gòu)嵌入到BERT模型中。
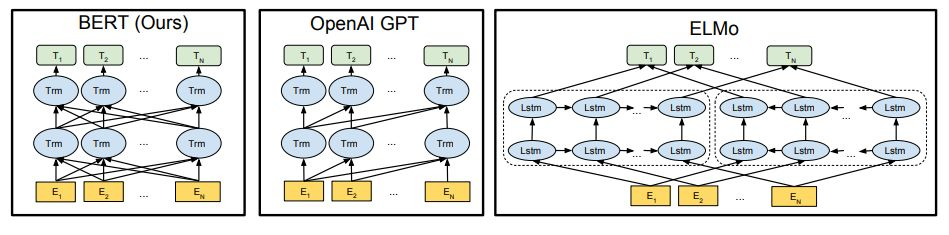
僅用有限數(shù)量的高質(zhì)量標(biāo)記數(shù)據(jù),他們就能讓BERT適應(yīng)多種任務(wù),包括找到問題的正確答案以及真正理解一個句子是關(guān)于什么的。
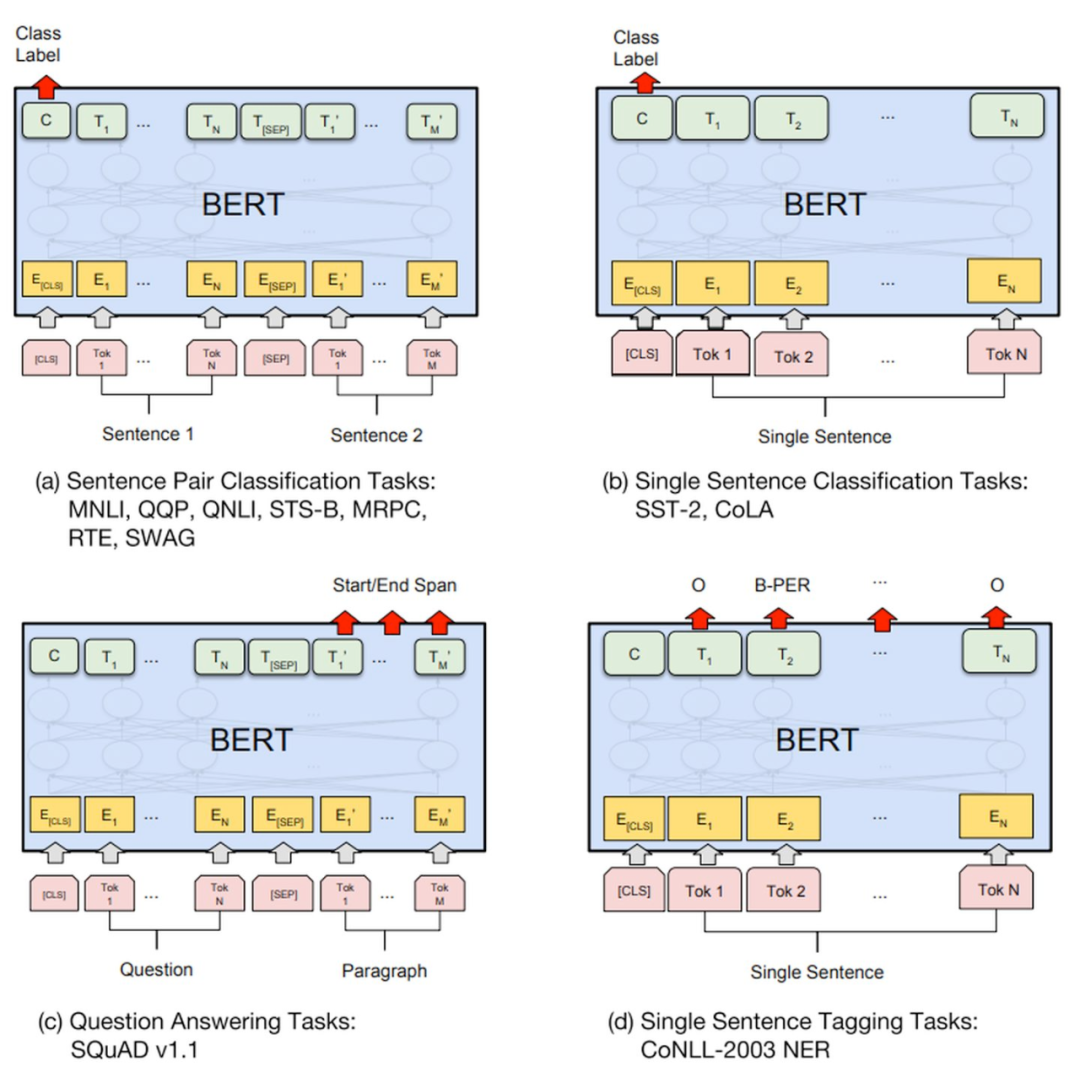
因此,他們成為了第一個真正把握語言理解的兩要素的人:正確的架構(gòu)和大量高質(zhì)量的數(shù)據(jù)。
?
2019年,臉書的研究人員將這一研究進行了進一步的推進:
?
他們訓(xùn)練了一個從BERT衍生出的模型,令其同時學(xué)習(xí)100多種語言。訓(xùn)練的結(jié)果是,該模型能夠?qū)W習(xí)一種語言的任務(wù),例如英語,并使用它來完成其他任何語言的相同任務(wù),如阿拉伯語、漢語和印地語。

這個語言無關(guān)模型在語言上可以與BERT有相同的表現(xiàn),此外,在該模型中,語言轉(zhuǎn)換過程中的一些干擾的影響是非常有限的。
?
在2020年初,Google的研究人員終于能夠在廣泛的語言理解任務(wù)中擊敗人類:
?
谷歌通過在更多數(shù)據(jù)上訓(xùn)練更大的網(wǎng)絡(luò),將BERT架構(gòu)推向了極限——現(xiàn)在,這種T5模型在標(biāo)注句子和找到問題的正確答案方面可以比人類表現(xiàn)得更好。
?
而10月份發(fā)布的語言無關(guān)的mT5模型,在從一種語言切換到另一種語言的能力方面,幾乎可以與雙語者一樣出色。同時,它在處理語言種類方面有著不可思議的效果——它可以同時處理100多種語言。

本周公布的萬億參數(shù)模型Switch Transformer使語言模型變得更龐大,效果也變得更強大。
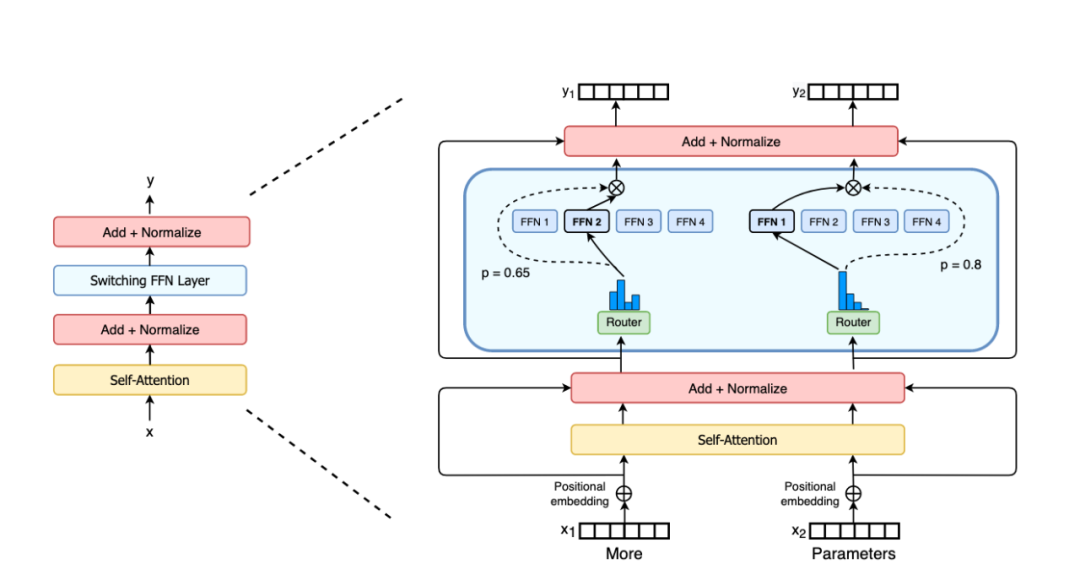
圖:Switch Transformer編碼塊
暢想未來,語言模型潛力巨大
想象一下,聊天機器人可以理解你的任何想法:
?
他們會真正理解語境并記住過去的對話。而你會得到的答案不再是泛泛的回答,而是正切主題的。
?
搜索引擎將能夠理解你的任何問題:
?
你甚至不需要使用正確的關(guān)鍵字,他們也會給出正確的答案。
?
你將得到一個了解你公司所有程序的「AI同事」:
?
如果你知道正確的「行話」,就不用再問其他同事問題了。當(dāng)然,也不再會有同事和你說:「為什么不把公司所有文件都看一遍再問我?」。
?
數(shù)據(jù)庫的新時代即將到來:
?
跟結(jié)構(gòu)化數(shù)據(jù)的繁瑣工作說再見吧。任何備忘錄,電子郵件,報告等,將得到自動解釋,存儲和索引。你將不再需要IT部門運行查詢來創(chuàng)建報告,只需要和數(shù)據(jù)庫說一下就行了。
?
而這,還只是冰山一角——
?
任何目前仍需要人類去理解語言的過程,都正處于被破壞或被自動化的邊緣。
Talk isn’t cheap:龐大語言模型耗費巨大
在構(gòu)建宏偉藍圖的同時,別忘了,還有個「陷阱」在這里:
?
為什么這些算法不是隨處可見?
?
一般情況下,訓(xùn)練這些模型大概率要花費極其昂貴的價格。舉個例子,訓(xùn)練T5算法的云計算成本約為130萬美元。
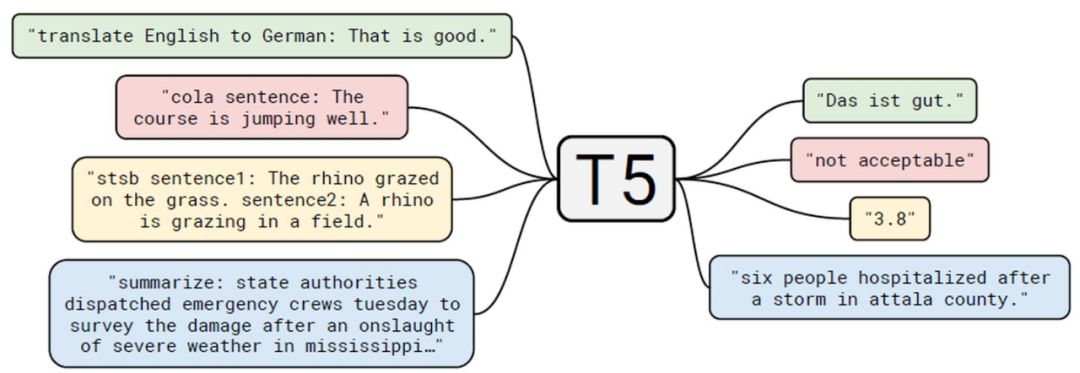
雖然谷歌的研究人員非常友好地分享了這些模型,但是,針對當(dāng)前的特定任務(wù),如果不對它們進行微調(diào),那么這些模型在具體任務(wù)中很可能就無法使用。
?
因此,即使大公司開源了這些模型,對于其他人來說,直接拿來使用也是一件代價高昂的事情。
?
而且,一旦使用者針對特定的問題優(yōu)化了這些模型,執(zhí)行的過程中仍然需要大量的計算能力和超長的時間消耗。
?
隨著時間的推移,隨著各大公司在微調(diào)上的投入,我們將看到新的的應(yīng)用出現(xiàn)。
?
而且,如果大家相信摩爾定律,我們可以在大約五年內(nèi)看到更復(fù)雜的應(yīng)用。此外,可以超越T5算法的新的模型也將會出現(xiàn)。
?
2021年初,我們距離人工智能最重大的突破以及由此帶來的無限可能,僅僅只有一步之遙。
?
參考鏈接:
https://venturebeat.com/2021/01/17/language-ai-is-really-heating-up/
