
成功上岸阿里,深度學(xué)習(xí)知識考點(diǎn)總結(jié)
點(diǎn)擊上方“Jack Cui”,選擇“加為星標(biāo)”
第一時間關(guān)注技術(shù)干貨!

1
2
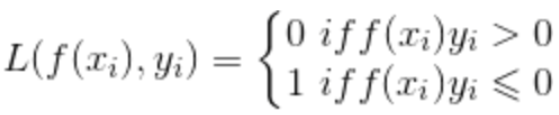
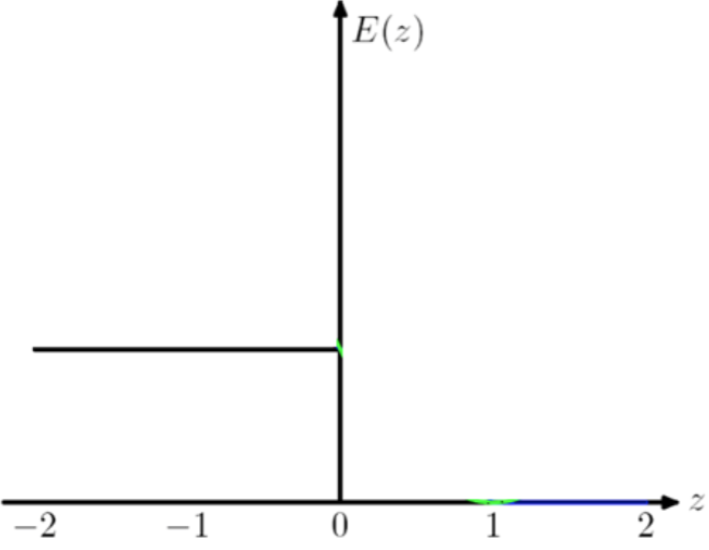
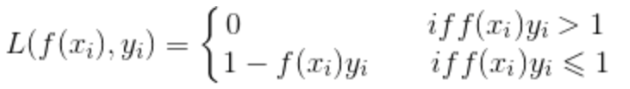
常用于多分類問題,描述了概率分布之間的不同,y是標(biāo)簽,p是預(yù)測概率:
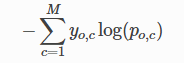
在邏輯回歸也就是二分類問題中,上述公式可以寫成:
![]()
這就是logistic loss。logistic loss 其實(shí)是 cross-entropy loss 的一個特例。
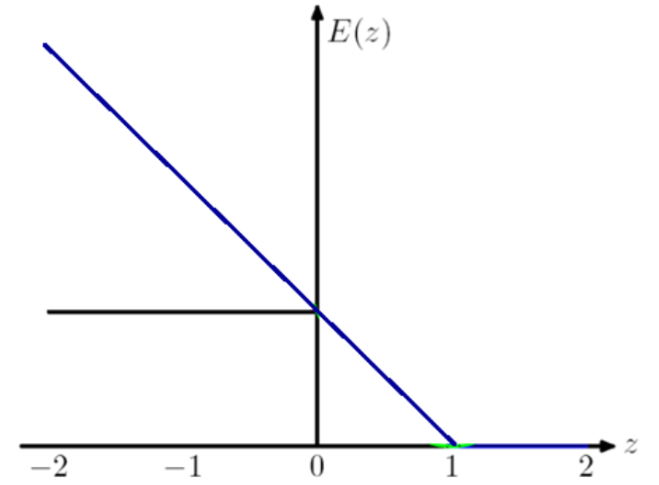
指數(shù)損失函數(shù):
AdaBoost 算法常用的損失函數(shù)。
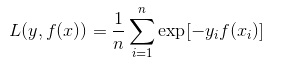
3、訓(xùn)練中出現(xiàn)過擬合的原因?深度學(xué)習(xí)里的正則方法有哪些/如何防止過擬合?
答:1)數(shù)據(jù)集不夠;2)參數(shù)太多,模型過于復(fù)雜,容易過擬合;3)權(quán)值學(xué)習(xí)過程中迭代次數(shù)太多,擬合了訓(xùn)練數(shù)據(jù)中的噪聲和沒有代表性的特征。
Regularization is a technique which makes slight modifications to the learning algorithm such that the model generalizes better. 正則化是一種技術(shù),通過調(diào)整可以讓算法的泛化性更好,控制模型的復(fù)雜度,避免過擬合。1)L1&L2正則化;2)Dropout(指在深度學(xué)習(xí)網(wǎng)絡(luò)的訓(xùn)練過程中,對于神經(jīng)網(wǎng)絡(luò)單元,按照一定的概率將其暫時從網(wǎng)絡(luò)中丟棄。注意是暫時,對于隨機(jī)梯度下降來說,由于是隨機(jī)丟棄,故而每一個mini-batch都在訓(xùn)練不同的網(wǎng)絡(luò));3)數(shù)據(jù)增強(qiáng)、加噪;4)early stopping(提前終止訓(xùn)練);5)多任務(wù)聯(lián)合;6)加BN。
4、l1、l2原理?dropout具體實(shí)現(xiàn)原理,隨機(jī)還是固定,訓(xùn)練過程和測試過程如何控制,是針對sample還是batch?
答:L1 正則化向目標(biāo)函數(shù)添加正則化項(xiàng),以減少參數(shù)的絕對值總和;而 L2 正則化中,添加正則化項(xiàng)的目的在于減少參數(shù)平方的總和。線性回歸的L1正則化通常稱為LASSO(Least Absolute Shrinkage and Selection Operator)回歸。LASSO回歸可以使得一些特征的系數(shù)變小,甚至還有一些絕對值較小的系數(shù)直接變?yōu)?,從而增強(qiáng)模型的泛化能力,因此特別適用于參數(shù)數(shù)目縮減與參數(shù)的選擇,因而用來估計(jì)稀疏參數(shù)的線性模型。
為什么L1正則化相比L2正則化更容易獲得稀疏解?采用L1范數(shù)時平方誤差項(xiàng)等值線與正則化項(xiàng)等值線的交點(diǎn)常出現(xiàn)在坐標(biāo)軸上,即w1或w2為0,而在采用L2范數(shù)時,兩者的交點(diǎn)常出現(xiàn)在某個象限中,即w1或w2均非0。因此,L1范數(shù)比L2范數(shù)更易于得到稀疏解。(周志華機(jī)器學(xué)習(xí))
dropout是指在深度學(xué)習(xí)網(wǎng)絡(luò)的訓(xùn)練過程中,對于神經(jīng)網(wǎng)絡(luò)單元,按照一定的概率將其暫時從網(wǎng)絡(luò)中丟棄。注意是暫時,對于隨機(jī)梯度下降來說,由于是隨機(jī)丟棄,故而每一個mini-batch都在訓(xùn)練不同的網(wǎng)絡(luò)。訓(xùn)練的時候使用dropout,測試的時候不使用。Dropout的思想是訓(xùn)練DNNs的整體然后平均整體的結(jié)果,而不是訓(xùn)練單個DNN。DNNs以概率p丟棄神經(jīng)元,因此保持其它神經(jīng)元概率為q=1-p。當(dāng)一個神經(jīng)元被丟棄時,無論其輸入及相關(guān)的學(xué)習(xí)參數(shù)是多少,其輸出都會被置為0。丟棄的神經(jīng)元在訓(xùn)練階段的前向傳播和后向傳播階段都不起作用:因?yàn)檫@個原因,每當(dāng)一個單一的神經(jīng)元被丟棄時,訓(xùn)練階段就好像是在一個新的神經(jīng)網(wǎng)絡(luò)上完成。大概是sample吧。(我感覺有點(diǎn)像非結(jié)構(gòu)化稀疏剪枝)
5、weight decay和范數(shù)正則有什么關(guān)系?
6、詳細(xì)比較sigmoid、relu、leaky-relu等激活函數(shù)?
?
答:sigmoid公式:
![]()
它輸入實(shí)數(shù)值并將其“擠壓”到0到1范圍內(nèi),適合輸出為概率的情況,但是現(xiàn)在已經(jīng)很少有人在構(gòu)建神經(jīng)網(wǎng)絡(luò)的過程中使用sigmoid。
Sigmoid函數(shù)飽和使梯度消失。當(dāng)神經(jīng)元的激活在接近0或1處時會飽和,在這些區(qū)域梯度幾乎為0,這就會導(dǎo)致梯度消失,幾乎就有沒有信號通過神經(jīng)傳回上一層。
Sigmoid函數(shù)的輸出不是零中心的。因?yàn)槿绻斎肷窠?jīng)元的數(shù)據(jù)總是正數(shù),那么關(guān)于
 的梯度在反向傳播的過程中,將會要么全部是正數(shù),要么全部是負(fù)數(shù),這將會導(dǎo)致梯度下降權(quán)重更新時出現(xiàn)z字型的下降。
的梯度在反向傳播的過程中,將會要么全部是正數(shù),要么全部是負(fù)數(shù),這將會導(dǎo)致梯度下降權(quán)重更新時出現(xiàn)z字型的下降。
tanh公式:
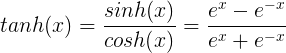
Tanh非線性函數(shù)圖像如下圖所示,它將實(shí)數(shù)值壓縮到[-1,1]之間。
Tanh解決了Sigmoid的輸出是不是零中心的問題,但仍然存在飽和問題。為了防止飽和,現(xiàn)在主流的做法會在激活函數(shù)前多做一步batch normalization,盡可能保證每一層網(wǎng)絡(luò)的輸入具有均值較小的、零中心的分布。
relu公式:
![]()
ReLU非線性函數(shù)圖像如下圖所示。
sigmoid和tanh在求導(dǎo)時含有指數(shù)運(yùn)算,而ReLU求導(dǎo)幾乎不存在任何計(jì)算量。
單側(cè)抑制;
稀疏激活性;
ReLU單元比較脆弱并且可能“死掉”,而且是不可逆的,因此導(dǎo)致了數(shù)據(jù)多樣化的丟失。通過合理設(shè)置學(xué)習(xí)率,會降低神經(jīng)元“死掉”的概率。
Leaky ReLU公式:
![]()
其中α是很小的負(fù)數(shù)梯度值,比如0.01,Leaky ReLU非線性函數(shù)圖像如下圖所示。這樣做目的是使負(fù)軸信息不會全部丟失,解決了ReLU神經(jīng)元“死掉”的問題。
ELU公式:
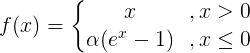
ELU函數(shù)是針對ReLU函數(shù)的一個改進(jìn)型,相比于ReLU函數(shù),在輸入為負(fù)數(shù)的情況下,是有一定的輸出的,而且這部分輸出還具有一定的抗干擾能力。這樣可以消除ReLU死掉的問題,不過還是有梯度飽和和指數(shù)運(yùn)算的問題。
7、說說BN,BN的全稱,BN的作用,為什么能解決梯度爆炸?BN一般放在哪里?
答:Batch Normalization。歸一化的作用,經(jīng)過BN的歸一化消除了尺度的影響,避免了反向傳播時因?yàn)闄?quán)重過大或過小導(dǎo)致的梯度消失或爆炸問題,從而可以加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練。BN一般放在激活函數(shù)后面。
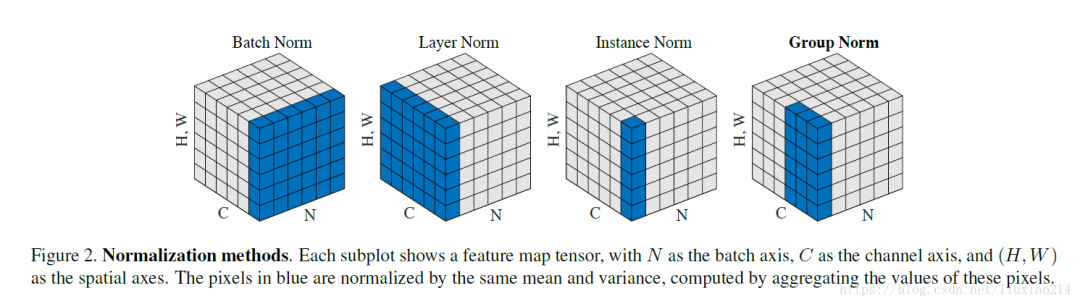
1)BN歸一化的維度是[N,H,W],那么channel維度上(N,H,W方向)的所有值都會減去這個歸一化的值,對小的batch size效果不好;2)LN歸一化的維度是[H,W,C],那么batch維度上(H,W,C方向)的所有值都會減去這個歸一化的值,主要對RNN作用明顯;3)IN歸一化的維度是[H,W],那么H,W方向的所有值都會減去這個歸一化的值,用在風(fēng)格化遷移;4)GN是將通道分成G組,歸一化的維度為[H,W,C//G]。
8、skip connection的作用。
答:防止梯度消失;傳遞淺層信息,比如邊緣、紋理和形狀。CNNs with skip connections have been the main stream for modern network design since it can mitigate the gradient vanishing/exploding issue in ultra deep networks by the help of skip connections.
9、圖像分割領(lǐng)域常見的loss function?
答:第一,softmax+cross entropy loss,比如fcn和u-net。
第二,第一的加權(quán)版本,比如segnet,每個類別的權(quán)重不一樣。
第三,使用adversarial training,加入gan loss。
(第四,sigmoid+dice loss,比如v-net,只適合二分類。
第五,online bootstrapped cross entropy loss,比如FRNN。
第六,類似于第四,sigmoid+jaccard(IoU),只適合二分類,但是可推廣到多類。)
10、BN應(yīng)該放在非線性激活層的前面還是后面?
答:在BN的原始論文中,BN是放在非線性激活層前面的。但是現(xiàn)在目前在實(shí)踐中,傾向于把BN放在ReLU后面,也有評測表明BN放ReLu后面更好。還有一種觀點(diǎn),BN放在非線性函數(shù)前還是后取決于你想要normalize的對象,更像一個超參數(shù)。
11、語義分割和無人駕駛分割的區(qū)別?
答:無人駕駛分割主要用的是視頻語義分割。
視頻語義分割任務(wù)具有低延遲,高時序相關(guān)等要求,因此需要在圖片語義分割的任務(wù)中進(jìn)一步發(fā)展。尤其是在自動駕駛?cè)蝿?wù)中,視頻數(shù)據(jù)量大,車速快,車載計(jì)算能力有限,因此對自動駕駛相關(guān)的計(jì)算機(jī)視覺算法在時間消耗上都有很嚴(yán)格的要求。
如何有效利用視頻幀之間的時序相關(guān)性將對視頻分割結(jié)果產(chǎn)生很大影響,目前主流分為兩派,一類是利用時間連續(xù)性增強(qiáng)語義分割結(jié)果的準(zhǔn)確性,另一種則關(guān)注如何降低計(jì)算成本,以達(dá)到實(shí)時性要求。
12、實(shí)例分割和語義分割的區(qū)別?
答:語義分割:該任務(wù)需要將圖中每一點(diǎn)像素標(biāo)注為某個物體類別。
同一物體的不同實(shí)例不需要單獨(dú)分割出來。比如標(biāo)記出羊,而不需要羊1,羊2,羊3,羊4,羊5。
實(shí)例分割是物體檢測+語義分割的綜合體。相對物體檢測的邊界框,實(shí)例分割可精確到物體的邊緣;相對語義分割,實(shí)例分割可以標(biāo)注出圖上同一物體的不同個體(羊1,羊2,羊3...)。
13、VGGNet的卷積核尺寸是多少?max pooling使用的尺寸?為什么使用3*3的尺寸?
答:VGGNet論文中全部使用了3*3的卷積核和2*2的池化核,通過不斷加深網(wǎng)絡(luò)結(jié)構(gòu)來提升性能。使用3*3的卷積核,既可以保證感受野,又能減少卷積的參數(shù)。兩個3*3的卷積層疊加,等價于一個5*5的卷積核的效果,3個3*3的卷積核的疊加相當(dāng)于一個7*7的卷積核,而且參數(shù)更少,擁有和7*7卷積核一樣的感受視野,三個卷積層的疊加,經(jīng)過了更多次的非線性變換,對特征的學(xué)習(xí)能力更強(qiáng)。
計(jì)算一下5×5卷積核參數(shù),輸入時RGB三通道圖像,輸出channel為2,計(jì)算一共需要多少參數(shù)。其中,25×3×2=150。
14、了解Inception網(wǎng)絡(luò)嗎?
答:v1版本使用了不同大小的卷積核,不同大小的感受野拼接意味著不同尺度特征的融合。增加網(wǎng)絡(luò)寬度的好處,來源于不同尺度的卷積核并聯(lián),從而實(shí)現(xiàn)了對multi-scale特征的利用。卷積核大小采用1、3和5,主要是為了方便對齊。設(shè)定卷積步長stride=1之后,只要分別設(shè)定pad=0、1、2,那么卷積之后便可以得到相同維度的特征,然后這些特征就可以直接拼接在一起了。但是帶來了一個問題,計(jì)算成本大大增加,不僅僅5x5就卷積計(jì)算成本高,concatenate會增加每層feature map的數(shù)量,因此提出了1x1卷積(NIN)用來降維。googlenet就用了inception v1的結(jié)構(gòu),還用到了auxiliary loss,防止梯度消失。
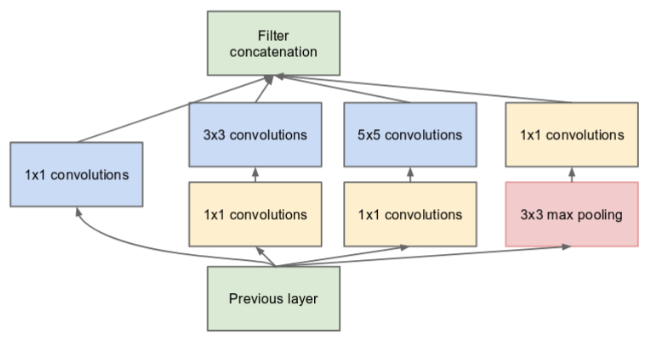
?
v2版本將v1中的5*5卷積替換成了兩個3*3,可以減少參數(shù)。更進(jìn)一步,將3*3卷積替換成了3*1和1*3卷積,可以更進(jìn)一步減少參數(shù)。任意nxn的卷積都可以通過1xn卷積后接nx1卷積來替代。實(shí)際上,作者發(fā)現(xiàn)在網(wǎng)絡(luò)的前期使用這種分解效果并不好,還有在中度大小的feature map上使用效果才會更好。該結(jié)構(gòu)被正式用在GoogLeNet V2中。
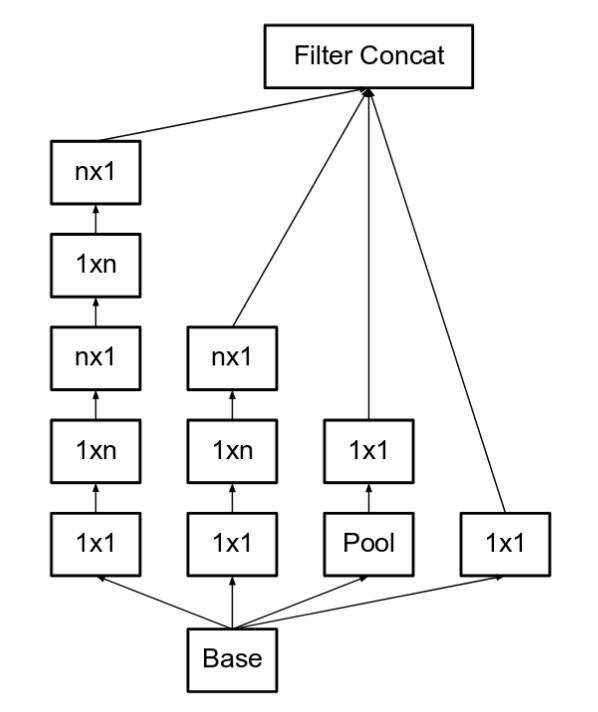
v3版本和v2版本出現(xiàn)在同一篇文章中,Rethinking the Inception Architecture for Computer Vision。v3比v2多的是分解了7*7卷積,輔助分類器使用了 BatchNorm。
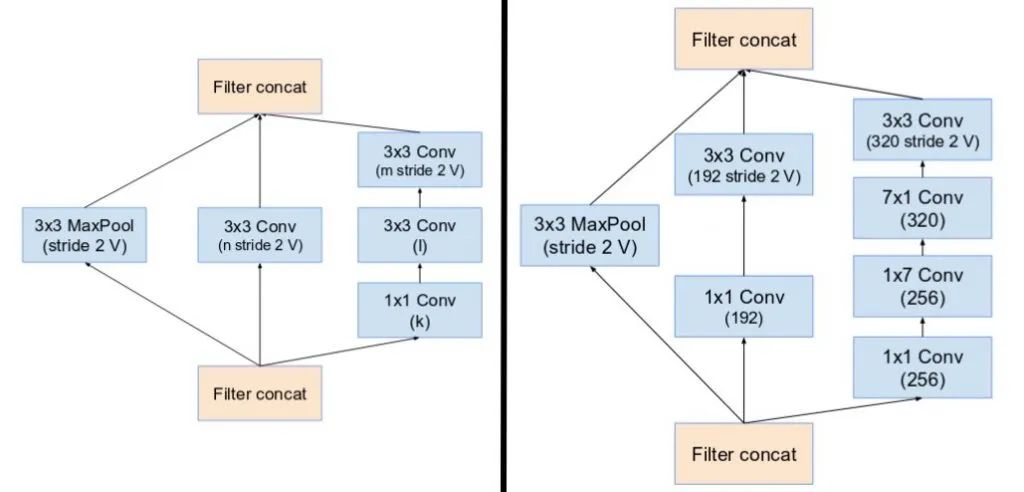
v4版本添加了reduction block,用于改變網(wǎng)格的寬度和高度。
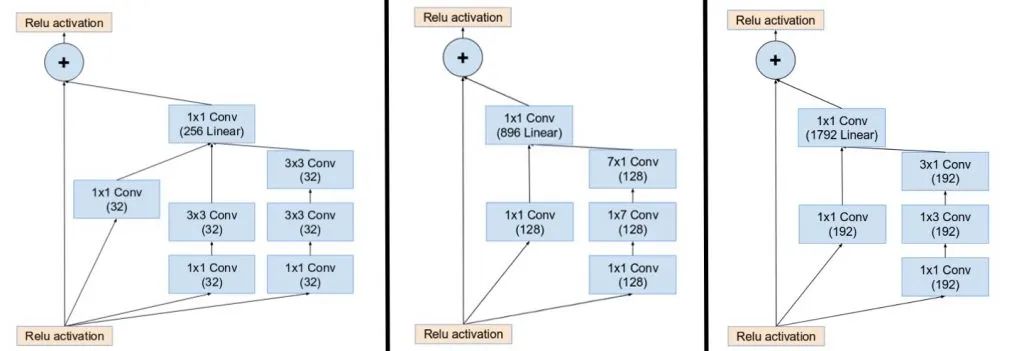
inception-resnet引入殘差連接,將 inception 模塊的卷積運(yùn)算輸出添加到輸入上。
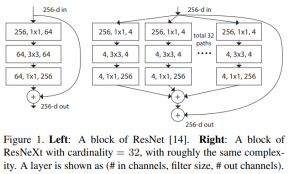
15、了解ResNext網(wǎng)絡(luò)嗎?
答:采用 VGG 堆疊的思想和 Inception 的 split-transform-merge 思想,但是可擴(kuò)展性比較強(qiáng),可以認(rèn)為是在增加準(zhǔn)確率的同時基本不改變或降低模型的復(fù)雜度。本質(zhì)上是引入了group操作同時加寬了網(wǎng)絡(luò)。
16、1×1的卷積核有什么作用?
答:1)可以升維降維;2)卷積參數(shù)少;3)加入非線性;4)在一篇論文中看到的描述,1×1 learns complex cross-channel interactions. 在一個blog看到的描述,?This convolution is used in order to “blend” information among channels.
17、了解幾種常見池化方法?池化怎么反向傳播?
答:1)平均池化,把一個patch中的值求取平均來做pooling,那么反向傳播的過程也就是把某個元素的梯度等分為n份分配給前一層,這樣就保證池化前后的梯度之和保持不變。2)最大池化是把patch中最大的值傳遞給后一層,而其他像素的值直接被舍棄掉。那么反向傳播也就是把梯度直接傳給前一層某一個像素,而其他像素不接受梯度,也就是為0。所以max pooling操作和mean pooling操作不同點(diǎn)在于需要記錄下池化操作時到底哪個像素的值是最大。
18、global average pooling的原理?
答:出自NIN論文,主要是是將最后一層的特征圖進(jìn)行整張圖的一個均值池化,形成一個特征點(diǎn),將這些特征點(diǎn)組成最后的特征向量。
19、FCN網(wǎng)絡(luò)為什么用全卷積層代替全連接層?
答:個人理解。輸入的圖像尺寸可以是動態(tài)的,如果是全連接輸入的圖像尺寸必須是固定的;可以輸出密集的像素級別的預(yù)測,將端到端的卷積網(wǎng)絡(luò)推廣到語義分割中;卷積可以減少參數(shù)量。
20、SegNet的結(jié)構(gòu)原理?
答:SegNet是典型的編碼解碼的過程,Encoder過程中,卷積的作用是提取特征,卷積后不改變圖片大小;在Decoder過程中,同樣使用不改變圖片大小的卷積,卷積的作用是為upsampling變大的圖像豐富信息,使得在Pooling過程中丟失的信息可以通過學(xué)習(xí)在Decoder中得到。decoder不是采用的轉(zhuǎn)置卷積,而是池化+卷積實(shí)現(xiàn)的上采樣。每次Pooling,都會保存通過max選出的權(quán)值在2x2 filter中的相對位置,在Upsamping層中可以得到在Pooling中相對Pooling filter的位置。所以Upsampling中先對輸入的特征圖放大兩倍,然后把輸入特征圖的數(shù)據(jù)根據(jù)Pooling indices放入。
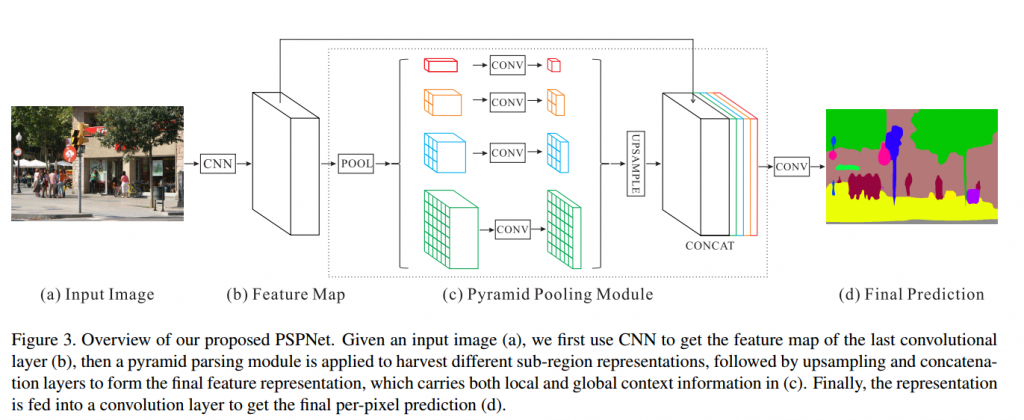
21、pspnet原理?
答:PSPNet的提出是為了聚合不同區(qū)域的上下文信息,從而提高獲取全局信息的能力。比如語義分割結(jié)果的大環(huán)境是一條河,河里的船有可能被識別成車,但是如果有了全局信息,就知道河里是不可能有車的,所以就不會出現(xiàn)這種問題的。encoder部分采用的是ResNet,和普通的resnet不一樣的部分是把7*7卷積換成了3個3*3卷積,我覺得這點(diǎn)就挺有用的,因?yàn)?*7會降低分辨率,損失了很多信息,用3個3*3的卷積感受野沒有變,但是信息損失的相對小了。
而且在resnet中還用到了空洞卷積,空洞卷積的作用就是讓卷積核變得蓬松,在已有的像素上,skip掉一些像素,或者輸入不變,對conv的kernel參數(shù)中插一些0的weight,達(dá)到一次卷積看到的空間范圍變大的目的,所以感受野變大了,同時計(jì)算量不變,更重要的是圖像的分辨率沒有改變不會損失信息。提取特征之后用到了金字塔池化模塊,分別用四個池化等級加卷積提取不同尺度的特征,最終和原提取特征一起用concat操作聚合到了一起。
22、Deeplab的改進(jìn)?Deeplab V3結(jié)構(gòu)原理?Deeplab V3+改進(jìn)?
答:Deeplab-v1是用了含有空洞卷積的VGG加上CRF后處理。
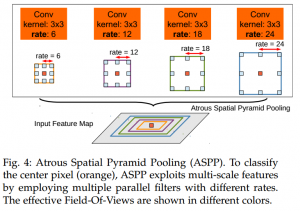
v2是在v1基礎(chǔ)上改進(jìn)的,用的是有空洞卷積的ResNet101,還提出了ASPP模塊,并行的采用多個采樣率的空洞卷積提取特征,再將特征融合。不再使用傳統(tǒng)的CRF方法,而是利用dense CRF的方法,得到較為優(yōu)秀的結(jié)果。
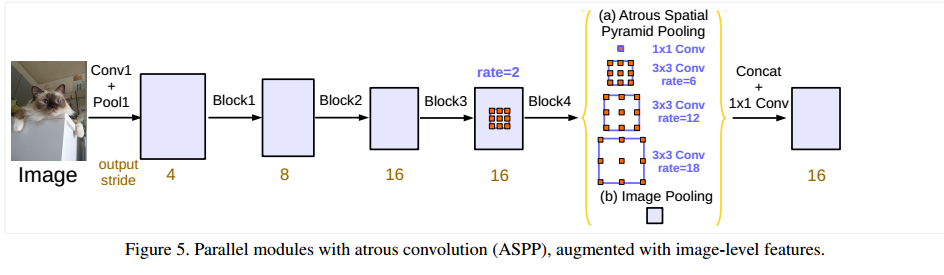
V3之后的文章就沒有用CRF了。相對v2改動不是很大,還是用了空洞卷積,主要改進(jìn)了ASPP模塊,加入了BN和圖像級別特征。另外文章指出了,在訓(xùn)練的時候?qū)T應(yīng)該保持不動,將概率圖插值之后再進(jìn)行計(jì)算loss。
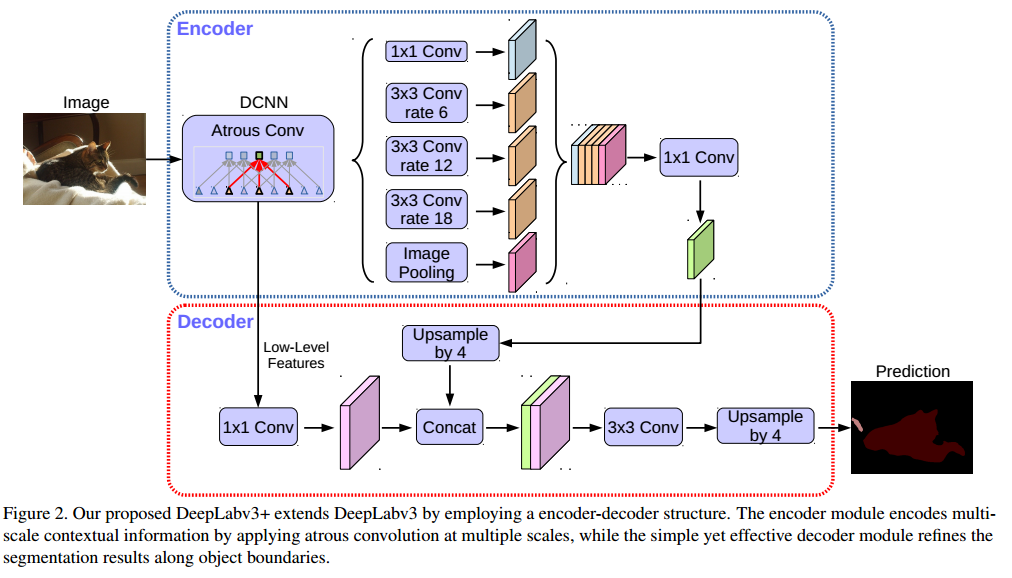
v3+將encoder部分替換成了X-inception,加入了深度可分離卷積,鑒于對最后的概率圖依然使用大倍數(shù)的雙線性插值恢復(fù)到與原圖一樣的大小還是過于簡單,因此在這個版本中,增加了一個恢復(fù)細(xì)節(jié)的解碼器部分。
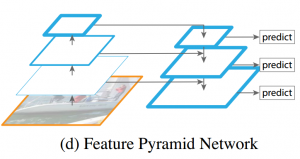
23、特征金字塔FPN?
答:何愷明發(fā)表在CVPR2015的論文Feature Pyramid Networks for Object Detection提到的,既可以在不同分辨率的feature map上檢測對應(yīng)尺度的目標(biāo),同時feature map又具有足夠的特征表達(dá)能力,這是因?yàn)槊繉拥膄eature map來源于當(dāng)前層和更高級層的特征融合。每一級的feature map尺寸都是2倍的關(guān)系,“2x up”采用的是最簡單的最近鄰上采樣。
24、Densenet什么時候比Resnet效果好?
答:數(shù)據(jù)集比較小的時候。因?yàn)閿?shù)據(jù)集小的時候容易產(chǎn)生過擬合,但是DenseNet能很好解決過擬合問題,這一點(diǎn)從DenseNet不做數(shù)據(jù)增強(qiáng)的CIFAR數(shù)據(jù)集上的表現(xiàn)就能看出來,錯誤率明顯下降了。DenseNet抗過擬合的原因有一個很直觀的解釋:神經(jīng)網(wǎng)絡(luò)每一層提取的特征都相當(dāng)于對輸入數(shù)據(jù)的一個非線性變換,而隨著深度的增加,變換的復(fù)雜度也在增加,因?yàn)橛兄嗟姆蔷€性函數(shù)的復(fù)合。相比于一般神經(jīng)網(wǎng)絡(luò)的分類器直接依賴于網(wǎng)絡(luò)最后一層(復(fù)雜度最高)的特征,DenseNet可以綜合利用淺層復(fù)雜度低的特征,因而更容易得到一個光滑的泛化性能好的函數(shù)。
25、data augmentation怎么處理?
答:Color Jittering:對顏色的數(shù)據(jù)增強(qiáng):圖像亮度、飽和度、對比度變化;Random Scale:尺度變換;Random Crop:采用隨機(jī)圖像差值方式,對圖像進(jìn)行裁剪、縮放;Horizontal/Vertical Flip:水平/垂直翻轉(zhuǎn);Shift:平移變換;Rotation/Reflection:旋轉(zhuǎn)/仿射變換;Noise:高斯噪聲、模糊處理。
26、Restnet中各個stage是什么含義,如何串聯(lián)在一起?Resnet50和Resnet101有什么區(qū)別?
答:第一個stage圖像尺寸沒有變,接下來每一個stage圖像尺寸都縮小二倍。resnet50一共有四個stage,分別有3,4,6,3個block。resnet101一共有四個stage,分別有3,4,23,3個block。每個block有3層,resnet101相比resnet50只在第三個stage多了17個block,也就是多了17*3=51層。
27、你覺得ShuffleNet的缺點(diǎn)是什么?
答:根據(jù)shufflenet v2,組卷積使用過多,內(nèi)存訪問量比較大。
28、了解空洞卷積嗎?你覺得空洞卷積有什么樣的問題?
答:空洞卷積是在已有的像素上,skip掉一些像素,或者輸入不變,對conv的kernel參數(shù)中插一些0的weight,達(dá)到一次卷積看到的空間范圍變大的目的。連續(xù)空洞卷積的感受野是指數(shù)級增長。
空洞卷積有兩個問題:1)The Gridding Effect:空洞卷積使卷積核不連續(xù),損失了連續(xù)信息,而且當(dāng)擴(kuò)張率增加的時候,采樣點(diǎn)之間間隔較遠(yuǎn),局部信息丟失,就會產(chǎn)生很差的網(wǎng)格效應(yīng);2)Long-ranged information might be not relevant:我們從 dilated convolution 的設(shè)計(jì)背景來看就能推測出這樣的設(shè)計(jì)是用來獲取 long-ranged information。然而光采用大 dilation rate 的信息或許只對一些大物體分割有效果,不利于小物體分割。如何同時處理不同大小的物體的關(guān)系,則是設(shè)計(jì)好 dilated convolution 網(wǎng)絡(luò)的關(guān)鍵。
解決辦法:1)圖森組的論文Understanding Convolution for Semantic Segmentation設(shè)計(jì)了HDC的結(jié)構(gòu),第一個特性是,疊加卷積的 dilation rate 不能有大于1的公約數(shù)。比如 [2, 4, 6] 則不是一個好的三層卷積,依然會出現(xiàn) gridding effect。第二個特性是,我們將 dilation rate 設(shè)計(jì)成鋸齒狀結(jié)構(gòu),例如 [1, 2, 5, 1, 2, 5] 循環(huán)結(jié)構(gòu)。第三個特性是,我們需要滿足一下這個式子:
![]()
一個簡單的例子: dilation rate [1, 2, 5] with 3 x 3 kernel (可行的方案),而這樣的鋸齒狀本身的性質(zhì)就比較好的來同時滿足小物體大物體的分割要求(小dilation rate來關(guān)心近距離信息,大dilation rate 來關(guān)心遠(yuǎn)距離信息)。
2)Atrous Spatial Pyramid Pooling (ASPP):ASPP 則在網(wǎng)絡(luò) decoder 上對于不同尺度上用不同大小的 dilation rate 來抓去多尺度信息,每個尺度則為一個獨(dú)立的分支,在網(wǎng)絡(luò)最后把他合并起來再接一個卷積層輸出預(yù)測 label。這樣的設(shè)計(jì)則有效避免了在 encoder 上冗余的信息的獲取,直接關(guān)注與物體之間之內(nèi)的相關(guān)性。
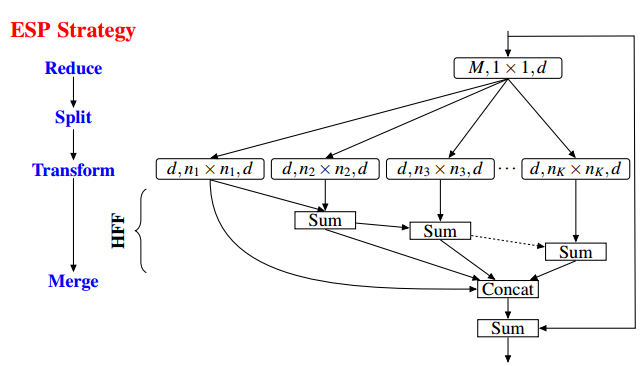
3)在ECCV2018的論文ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation中說明ASPP仍會存在gridding artifacts的情況,所以他們提出用級聯(lián)特征融合的方法改善這種情況。
29、為什么牛頓法不常用?
答:牛頓法雖然收斂速度很快,但是需要計(jì)算梯度和二階導(dǎo)數(shù),也就是一個Hessian矩陣:1)有些時候,損失函數(shù)的顯式方程不好求;2)輸入向量的維度N較大時,H矩陣的大小是N*N,計(jì)算量很大而且內(nèi)存需求也很大;3)牛頓法的步長是通過導(dǎo)數(shù)計(jì)算得來的,所以當(dāng)臨近鞍點(diǎn)的時候,步長會越來越小,這樣牛頓法就很容易陷入鞍點(diǎn)之中。而sgd的步長是預(yù)設(shè)的固定值,相對容易跨過一些鞍點(diǎn)。
神經(jīng)網(wǎng)絡(luò)優(yōu)化問題中的鞍點(diǎn)即一個維度向上傾斜且另一維度向下傾斜的點(diǎn)。鞍點(diǎn)和局部極小值相同的是,在該點(diǎn)處的梯度都等于0,不同在于在鞍點(diǎn)附近Hessian矩陣是不定的(行列式小于0),而在局部極值附近的Hessian矩陣是正定的。鞍點(diǎn)處的梯度為零,鞍點(diǎn)通常被相同誤差值的平面所包圍(這個平面又叫Plateaus,Plateaus是梯度接近于零的平緩區(qū)域,會降低神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)速度),在高維的情形,這個鞍點(diǎn)附近的平坦區(qū)域范圍可能非常大,這使得SGD算法很難脫離區(qū)域,即可能會長時間卡在該點(diǎn)附近(因?yàn)樘荻仍谒芯S度上接近于零)。(f(x)=x^3 中的(0,0)就是鞍點(diǎn))
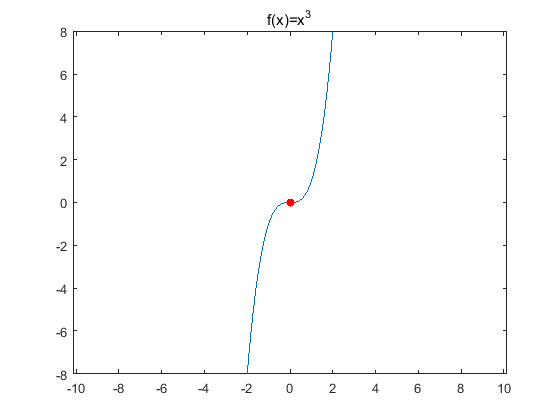
在鞍點(diǎn)數(shù)目極大的時候,這個問題會變得非常嚴(yán)重。高維非凸優(yōu)化問題之所以困難,是因?yàn)楦呔S參數(shù)空間存在大量的鞍點(diǎn)。
30、深度學(xué)習(xí)優(yōu)化算法比較
目標(biāo)函數(shù)關(guān)于參數(shù)的梯度:
![]()
根據(jù)歷史梯度計(jì)算一階和二階動量:
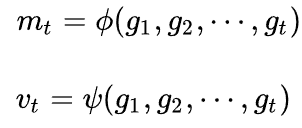
更新模型參數(shù):
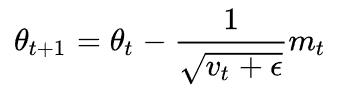
vanilla SGD:樸素SGD最為簡單,沒有動量的概念,?η是學(xué)習(xí)率,更新步驟是:
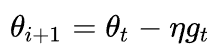
SGD的缺點(diǎn)在于收斂速度慢,可能在鞍點(diǎn)處震蕩。并且,如何合理的選擇學(xué)習(xí)率是SGD的一大難點(diǎn)。
Momentum:SGD 在遇到溝壑時容易陷入震蕩。為此,可以為其引入動量 Momentum,加速 SGD 在正確方向的下降并抑制震蕩。
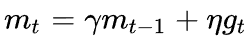
SGD-M在原步長之上,增加了與上一時刻步長相關(guān)的一階動量γmt-1,γ通常取0.9左右。這意味著參數(shù)更新方向不僅由當(dāng)前的梯度決定,也與此前累積的下降方向有關(guān)。這使得參數(shù)中那些梯度方向變化不大的維度可以加速更新,并減少梯度方向變化較大的維度上的更新幅度。由此產(chǎn)生了加速收斂和減小震蕩的效果。
SGD 還有一個問題是困在局部最優(yōu)的溝壑里面震蕩。想象一下你走到一個盆地,四周都是略高的小山,你覺得沒有下坡的方向,那就只能待在這里了。可是如果你爬上高地,就會發(fā)現(xiàn)外面的世界還很廣闊。因此,我們不能停留在當(dāng)前位置去觀察未來的方向,而要向前一步、多看一步、看遠(yuǎn)一些。因此有了NAG。
Nesterov Accelerated Gradient:是在SGD、SGD-M的基礎(chǔ)上的進(jìn)一步改進(jìn)。改進(jìn)點(diǎn)在于步驟1。我們知道在時刻t的主要下降方向是由累積動量決定的,自己的梯度方向說了也不算,那與其看當(dāng)前梯度方向,不如先看看如果跟著累積動量走了一步,那個時候再怎么走。因此,NAG在步驟1,不計(jì)算當(dāng)前位置的梯度方向,而是計(jì)算如果按照累積動量走了一步,那個時候的下降方向:
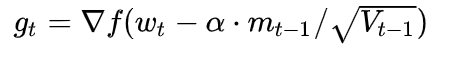
然后用下一個點(diǎn)的梯度方向,與歷史累積動量相結(jié)合,計(jì)算步驟2中當(dāng)前時刻的累積動量。
SGD、SGD-M 和 NAG 均是以相同的學(xué)習(xí)率去更新θ的各個分量,此前我們都沒有用到二階動量。二階動量的出現(xiàn),才意味著“自適應(yīng)學(xué)習(xí)率”優(yōu)化算法時代的到來。SGD及其變種以同樣的學(xué)習(xí)率更新每個參數(shù),但深度神經(jīng)網(wǎng)絡(luò)往往包含大量的參數(shù),這些參數(shù)并不是總會用得到(想想大規(guī)模的embedding)。對于經(jīng)常更新的參數(shù),我們已經(jīng)積累了大量關(guān)于它的知識,不希望被單個樣本影響太大,希望學(xué)習(xí)速率慢一些;對于偶爾更新的參數(shù),我們了解的信息太少,希望能從每個偶然出現(xiàn)的樣本身上多學(xué)一些,即學(xué)習(xí)速率大一些。
Adagrad:二階動量vt是迄今為止所有梯度值的平方和,學(xué)習(xí)率等效成:
![]()
對于此前頻繁更新過的參數(shù),其二階動量的對應(yīng)分量較大,學(xué)習(xí)率就較小。這一方法在稀疏數(shù)據(jù)的場景下表現(xiàn)很好。但是需要手動設(shè)置一個全局的學(xué)習(xí)率。
Adadelta:在Adagrad中, vt是單調(diào)遞增的,使得學(xué)習(xí)率逐漸遞減至 0,可能導(dǎo)致訓(xùn)練過程提前結(jié)束。為了改進(jìn)這一缺點(diǎn),可以考慮在計(jì)算二階動量時不累積全部歷史梯度,而只關(guān)注最近某一時間窗口內(nèi)的下降梯度。
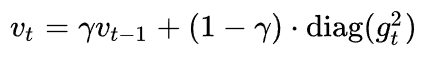
其二階動量采用指數(shù)移動平均公式計(jì)算,這樣即可避免二階動量持續(xù)累積的問題。和SGD-M中的參數(shù)類似,γ通常取0.9左右。不依賴于全局學(xué)習(xí)率。
RMSprop:可以看做為Adadalta的一個特例,Adadalta中的某個參數(shù)取0.5再求根的時候就變成RMS,對于變化較大的值方向能夠抑制變化,較小的值方向加速變化,消除擺動加速收斂,但依賴全局學(xué)習(xí)率。
Adam:是RMSprop和momentum的結(jié)合。和 RMSprop 對二階動量使用指數(shù)移動平均類似,Adam中對一階動量也是用指數(shù)移動平均計(jì)算。
NAdam:在 Adam之上融合了 NAG的思想。
目前看過一些論文,感覺主流還是SGD或者是adam,resnet用的就是adam。據(jù)大多數(shù)文章來看,Adam收斂更快,但是調(diào)參的參數(shù)更好的話sgd準(zhǔn)確率比adam要高。這個我也深有體會,曾經(jīng)用adam和sgd同時訓(xùn)練一個任務(wù),sgd的效果更好。
6
