
【深度學(xué)習(xí)】深度學(xué)習(xí)中的知識(shí)蒸餾技術(shù)(下)
本文概覽:
寫在前面:
這是一篇介紹知識(shí)蒸餾在推薦系統(tǒng)中應(yīng)用的文章,關(guān)于知識(shí)蒸餾理論基礎(chǔ)的詳細(xì)介紹,請(qǐng)看我的這篇文章:
1. 背景介紹
1.1 簡(jiǎn)述推薦系統(tǒng)架構(gòu)
如果從傳統(tǒng)角度來看實(shí)際的工業(yè)推薦系統(tǒng),粗略地可以分為兩個(gè)階段。首先是召回階段,主要根據(jù)用戶部分特征,從海量的物品庫(kù)里,快速找回一小部分用戶潛在感興趣的物品,然后交給排序環(huán)節(jié)。其次是排序階段,排序階段可以融入較多特征,使用復(fù)雜模型,來精準(zhǔn)地做個(gè)性化推薦。召回強(qiáng)調(diào)快且相關(guān)性,即快速地召回一批與用戶興趣點(diǎn)相關(guān)的物品;排序強(qiáng)調(diào)準(zhǔn)且符合推薦系統(tǒng)的終極目標(biāo),即根據(jù)推薦系統(tǒng)的終極目標(biāo)(DAU、時(shí)長(zhǎng)、留存等)利用大規(guī)模特征做精準(zhǔn)的個(gè)性化排序。最近一兩年,推薦系統(tǒng)的終極目標(biāo)也在逐步下沉到召回和粗排階段,比如在召回和粗排階段設(shè)計(jì)的多目標(biāo)與精排多目標(biāo)對(duì)齊。
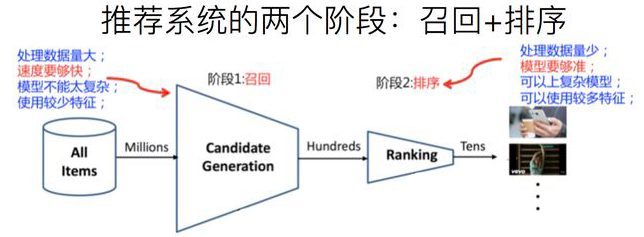
但是,如果我們更細(xì)致地看實(shí)用的工業(yè)級(jí)推薦系統(tǒng),一般會(huì)有四個(gè)環(huán)節(jié),如下圖所示:
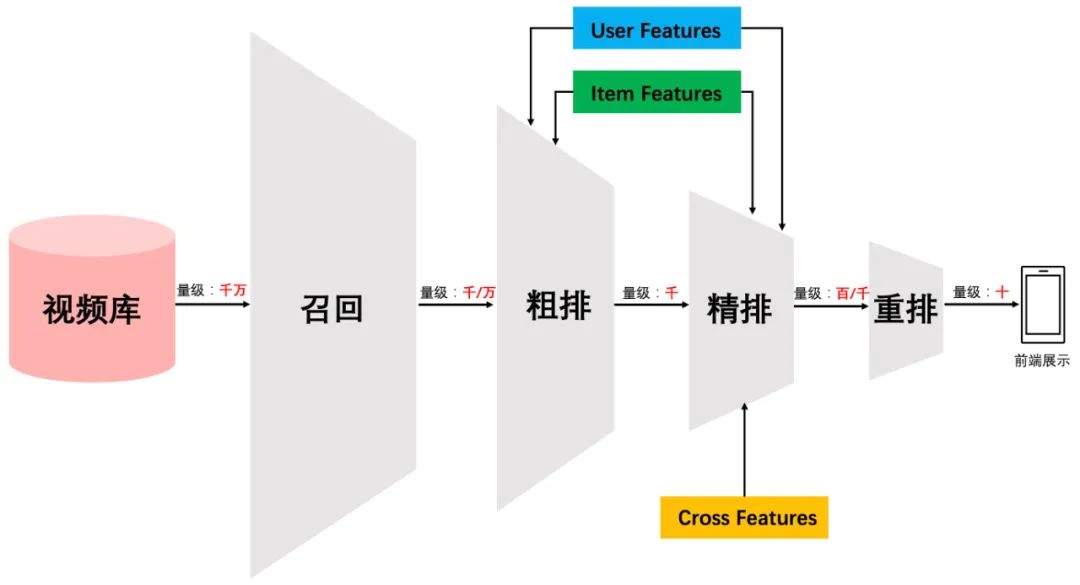
四個(gè)環(huán)節(jié)分別是:召回、粗排、精排和重排。召回目的如上所述。有時(shí)候因?yàn)槊總€(gè)用戶召回環(huán)節(jié)都有多路召回算法,這會(huì)產(chǎn)生兩個(gè)問題:
這些召回算法每路召回多少物品難以確定,因此需要加一層粗排對(duì)每路召回的結(jié)果進(jìn)行統(tǒng)一的打分排序,把Top K 的結(jié)果送入精排中; 總體召回環(huán)節(jié)返回的物品數(shù)量太多,排序環(huán)節(jié)需要占用大量的機(jī)器資源且影響排序速度,所以可以在召回和精排之間加入一個(gè)粗排環(huán)節(jié);
粗排一般通過少量用戶和物品特征,利用簡(jiǎn)單模型,來對(duì)召回的結(jié)果進(jìn)行粗略的排序,在保證一定精準(zhǔn)的前提下,進(jìn)一步減少往后傳送的物品數(shù)量。粗排往往是可選擇的,可用可不用,跟場(chǎng)景有關(guān)。之后,是精排環(huán)節(jié),使用你能想到的任何特征,可以上你能承受速度極限的復(fù)雜模型,盡量精準(zhǔn)地對(duì)物品進(jìn)行個(gè)性化排序。排序完成后,傳給重排環(huán)節(jié),傳統(tǒng)地看,這里往往會(huì)上各種技術(shù)及業(yè)務(wù)策略,比如曝光去重、打散、多樣性保證、固定類型物品插入等等,主要是技術(shù)產(chǎn)品策略主導(dǎo)或者為了改進(jìn)用戶體驗(yàn)。
1.2 為什么要把知識(shí)蒸餾引入推薦系統(tǒng)中?
隨著深度學(xué)習(xí)的快速發(fā)展,優(yōu)秀的模型層出不窮,比如圖像領(lǐng)域的ResNet、自然語(yǔ)言處理領(lǐng)域的Bert,這些革命性的新技術(shù)使得模型精度快速提升。但是,先進(jìn)的深度學(xué)習(xí)模型正在變得越來越復(fù)雜,網(wǎng)絡(luò)深度越來越深,模型參數(shù)量也在變得越來越多。而這會(huì)帶來一個(gè)現(xiàn)實(shí)應(yīng)用的問題:將這些復(fù)雜模型推上線,模型響應(yīng)速度太慢,當(dāng)流量大的時(shí)候撐不住。因此知識(shí)蒸餾就是目前一種比較流行的解決此類問題的技術(shù)方向。
一般知識(shí)蒸餾采取Teacher-Student模式:將復(fù)雜模型作為Teacher,Student模型結(jié)構(gòu)較為簡(jiǎn)單,用Teacher來輔助Student模型的訓(xùn)練,Teacher學(xué)習(xí)能力強(qiáng),可以將它學(xué)到的知識(shí)遷移給學(xué)習(xí)能力相對(duì)弱的Student模型,以此來增強(qiáng)Student模型的泛化能力。復(fù)雜笨重但是效果好的Teacher模型不上線,就單純是個(gè)導(dǎo)師角色,真正上線撐流量的是靈活輕巧的Student小模型。
結(jié)合知識(shí)蒸餾與推薦系統(tǒng)的特點(diǎn),將知識(shí)蒸餾與推薦系統(tǒng)結(jié)合會(huì)有哪些優(yōu)勢(shì)呢?
在推薦系統(tǒng)的各個(gè)階段都高度要求模型性能。受限于網(wǎng)絡(luò)延時(shí)和性能的要求,可以用復(fù)雜模型(如帶有高階特征交叉的模型,xDeepFM等)蒸餾的知識(shí)指導(dǎo)簡(jiǎn)單一些的模型進(jìn)行學(xué)習(xí)。 相對(duì)于精排模型而言,粗排和召回模型本身就很簡(jiǎn)單。粗排或召回階段,在優(yōu)化ground-truth目標(biāo)時(shí),是否可以用精排(Teacher網(wǎng)絡(luò))輸出的知識(shí)指導(dǎo)粗排或者召回模型的訓(xùn)練呢?
2. 知識(shí)蒸餾與推薦系統(tǒng)
在含有召回、粗排、精排的串行級(jí)聯(lián)推薦體系中,知識(shí)蒸餾可以應(yīng)用在哪個(gè)環(huán)節(jié)呢?假設(shè)我們?cè)谡倩丨h(huán)節(jié)采用模型排序(YouTube DNN/DSSM雙塔等模型),那么知識(shí)蒸餾在這三個(gè)環(huán)節(jié)都可以采用,進(jìn)而優(yōu)化現(xiàn)有推薦系統(tǒng)的線上服務(wù)響應(yīng)時(shí)間及推薦質(zhì)量。
2.1 精排環(huán)節(jié)采用知識(shí)蒸餾
為何在精排環(huán)節(jié)采用知識(shí)蒸餾?我們知道,精排環(huán)節(jié)注重精準(zhǔn)排序,所以采用盡量多的特征和復(fù)雜模型,以期待獲得優(yōu)質(zhì)的個(gè)性化推薦結(jié)果。但是,這同時(shí)也意味著復(fù)雜模型的在線服務(wù)響應(yīng)變慢。若承載相同的流量,需要增加在線服務(wù)并行程度,也就意味著增加機(jī)器資源和成本。因此,如何在精準(zhǔn)排序和機(jī)器資源之間做均衡呢?我們可以通過在精排環(huán)節(jié)采用知識(shí)蒸餾技術(shù)實(shí)現(xiàn)一個(gè)既有較好的推薦質(zhì)量,又能有快速推理能力的模型。
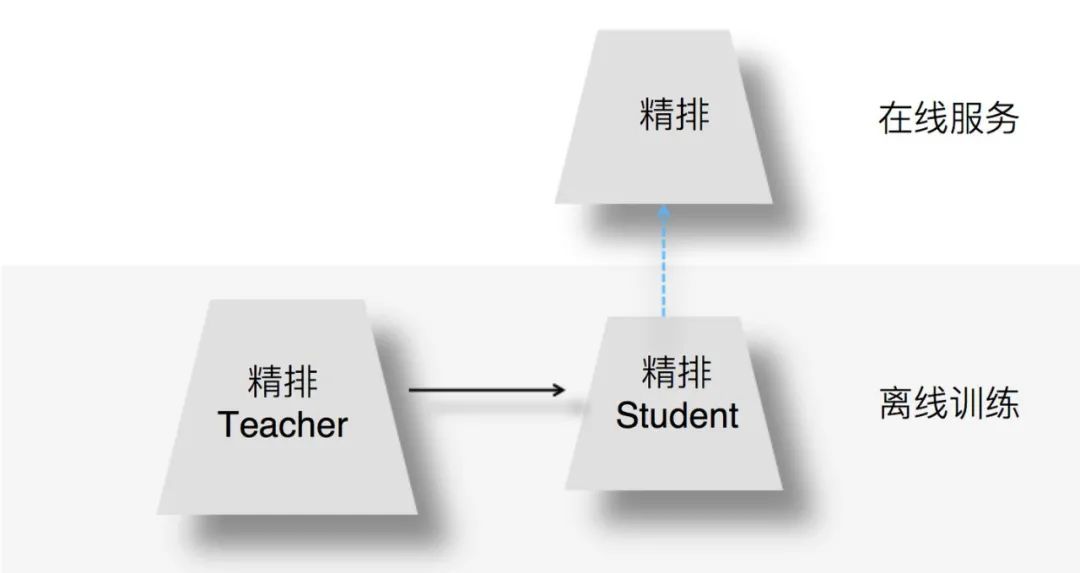
圖:來源于參考文獻(xiàn)2
上圖展示了如何在精排環(huán)節(jié)應(yīng)用知識(shí)蒸餾:我們?cè)陔x線訓(xùn)練的時(shí)候,可以訓(xùn)練一個(gè)復(fù)雜精排模型作為Teacher,一個(gè)結(jié)構(gòu)較簡(jiǎn)單的DNN排序模型作為Student。因?yàn)镾tudent結(jié)構(gòu)簡(jiǎn)單,所以模型表達(dá)能力弱,于是,我們可以在Student訓(xùn)練的時(shí)候,除了采用常規(guī)的Ground Truth訓(xùn)練數(shù)據(jù)外,Teacher也輔助Student的訓(xùn)練,將Teacher復(fù)雜模型學(xué)到的一些知識(shí)遷移給Student,增強(qiáng)其模型表達(dá)能力,以此加強(qiáng)其推薦效果。在模型上線服務(wù)的時(shí)候,并不用那個(gè)復(fù)雜的Teacher模型,而是使用小的Student作為線上精排模型,進(jìn)行在線推理。小的Student模型優(yōu)勢(shì)如下:
Student結(jié)構(gòu)較為簡(jiǎn)單,所以在線推理速度會(huì)大大快于復(fù)雜模型; Teacher將一些知識(shí)遷移給Student,所以經(jīng)過知識(shí)蒸餾的Student推薦質(zhì)量也比單純Student自己訓(xùn)練質(zhì)量要高。
以上就是典型的在精排環(huán)節(jié)采用知識(shí)蒸餾的思路。
2.2 模型召回/粗排環(huán)節(jié)采用知識(shí)蒸餾
由于模型召回或者粗排環(huán)節(jié),作為精排的前置環(huán)節(jié),需要在準(zhǔn)確性和速度方面找到一個(gè)平衡點(diǎn),在保證一定推薦精準(zhǔn)性的前提下,對(duì)物品進(jìn)行粗篩,減小精排環(huán)節(jié)壓力。所以,這兩個(gè)環(huán)節(jié)本身,從其定位來說,并不追求最高的推薦精度,就算模型效果比精排差些,這也是完全可以接受的,畢竟在這兩個(gè)環(huán)節(jié),如果準(zhǔn)確性不足可以靠返回物品數(shù)量多來彌補(bǔ)。而模型小,速度快則是模型召回及粗排的重要目標(biāo)之一。這就和知識(shí)蒸餾本身的特點(diǎn)對(duì)上了,所以在這里用特別合適。
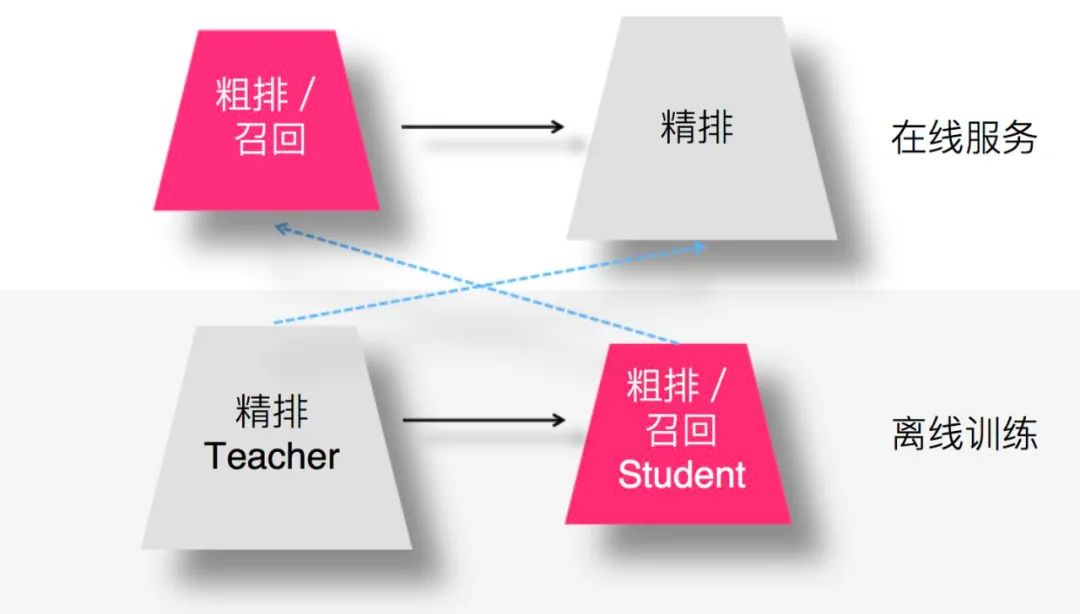
圖:來源于參考文獻(xiàn)2
那么,召回或者粗排怎么用蒸餾呢?如上圖所示,用復(fù)雜的精排模型作為Teacher,召回或粗排模型作為小的Student,比如雙塔DNN模型等,Student模型模擬精排環(huán)節(jié)的排序結(jié)果,以此來指導(dǎo)召回或粗排Student模型的優(yōu)化過程。這樣,我們可以獲得滿足如下特性的召回或者粗排模型:
首先,推薦效果好,因?yàn)镾tudent經(jīng)過復(fù)雜精排模型的知識(shí)蒸餾,推薦效果可以非常接近于精排模型效果; 其次,Student模型結(jié)構(gòu)簡(jiǎn)單,所以速度快,滿足召回、粗排環(huán)節(jié)對(duì)于速度的要求; 最后,通過Student模型模擬精排模型的排序結(jié)果,可以使得召回、粗排這兩個(gè)環(huán)節(jié)的優(yōu)化目標(biāo)和精排環(huán)節(jié)的優(yōu)化目標(biāo)保持一致,即與推薦任務(wù)的最終優(yōu)化目標(biāo)保持一致。
在推薦系統(tǒng)中,召回、粗排環(huán)節(jié)優(yōu)化目標(biāo)保持和精排優(yōu)化目標(biāo)一致,其實(shí)是很重要的,但是這點(diǎn)往往在實(shí)際中容易被忽略,或者因?yàn)闂l件所限無(wú)法考慮這一因素,比如非模型召回,從機(jī)制上是沒辦法考慮這點(diǎn)的。這里需要注意的一點(diǎn)是:如果召回模型或者粗排模型的優(yōu)化目標(biāo)已經(jīng)是多目標(biāo)的,對(duì)于新增的模型蒸餾來說,可以作為多目標(biāo)任務(wù)中新加入的一個(gè)目標(biāo),當(dāng)然,也可以只保留單獨(dú)的蒸餾模型,完全替換掉之前的多目標(biāo)模型,貌似這兩種思路應(yīng)該都是可以的,需要根據(jù)具體情況進(jìn)行斟酌選擇。
以上就是知識(shí)蒸餾技術(shù)在推薦系統(tǒng)的召回、粗排、精排環(huán)節(jié)的大概應(yīng)用思路。下面,我們根據(jù)工業(yè)界公開的相關(guān)論文和資料,詳細(xì)地了解在推薦系統(tǒng)的各個(gè)環(huán)節(jié)里,采用知識(shí)蒸餾的具體方法。
3. 知識(shí)蒸餾在推薦系統(tǒng)中的研究進(jìn)展
3.1 精排環(huán)節(jié)應(yīng)用知識(shí)蒸餾
3.1.1 《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》
這是阿里媽媽的一篇將“目標(biāo)蒸餾-logits方法“應(yīng)用到推薦系統(tǒng)領(lǐng)域的論文。 該論文提出的背景是:響應(yīng)時(shí)間直接決定在線響應(yīng)系統(tǒng)的效果和用戶體驗(yàn)。比如在線展示廣告系統(tǒng)中,針對(duì)一個(gè)用戶,需要在幾ms內(nèi),對(duì)上百個(gè)候選廣告的點(diǎn)擊率進(jìn)行預(yù)估。因此,如何在嚴(yán)苛的響應(yīng)時(shí)間內(nèi),提高模型的在線預(yù)測(cè)效果,是工業(yè)界面臨的一個(gè)巨大問題。此外,簡(jiǎn)單的網(wǎng)絡(luò)速度快,但精度不如復(fù)雜的網(wǎng)絡(luò)好;復(fù)雜的網(wǎng)絡(luò)精度好,但是計(jì)算量大,訓(xùn)練和線上推理速度都很慢。如何能結(jié)合小網(wǎng)絡(luò)的速度和大網(wǎng)絡(luò)的精度也是一個(gè)很難、很重要的問題。
為了解決上述問題,阿里巴巴在2018年AAAI上的論文《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》中提出了一個(gè)新型框架:訓(xùn)練階段,同時(shí)訓(xùn)練“復(fù)雜”和“簡(jiǎn)單”兩個(gè)復(fù)雜度有明顯差異的網(wǎng)絡(luò),簡(jiǎn)單的網(wǎng)絡(luò)稱為輕量網(wǎng)絡(luò)(Light Net),復(fù)雜的網(wǎng)絡(luò)稱為助推器網(wǎng)絡(luò)(Booster Net),它相比前者有更強(qiáng)的學(xué)習(xí)能力。兩網(wǎng)絡(luò)共享部分參數(shù),分別學(xué)習(xí)類別標(biāo)記(Label)。此外,輕量網(wǎng)絡(luò)通過學(xué)習(xí)助推器的soft target來模仿助推器的學(xué)習(xí)過程,從而得到更好的訓(xùn)練效果。測(cè)試階段,僅采用輕量網(wǎng)絡(luò)進(jìn)行預(yù)測(cè)。
火箭發(fā)射過程中,初始階段,助推器和飛行器一同前行,第二階段,助推器剝離,飛行器獨(dú)自前進(jìn)。在該論文的框架中,訓(xùn)練階段,有繁簡(jiǎn)兩個(gè)網(wǎng)絡(luò)一同訓(xùn)練,復(fù)雜的網(wǎng)絡(luò)起到助推器的作用,通過參數(shù)共享和信息提供推動(dòng)輕量網(wǎng)絡(luò)更好的訓(xùn)練;在預(yù)測(cè)階段,助推器網(wǎng)絡(luò)脫離系統(tǒng),輕量網(wǎng)絡(luò)獨(dú)自發(fā)揮作用,從而在不增加預(yù)測(cè)開銷的情況下,提高預(yù)測(cè)效果。整個(gè)過程與火箭發(fā)射類似,所以命名該系統(tǒng)為“火箭發(fā)射”。整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)如下:
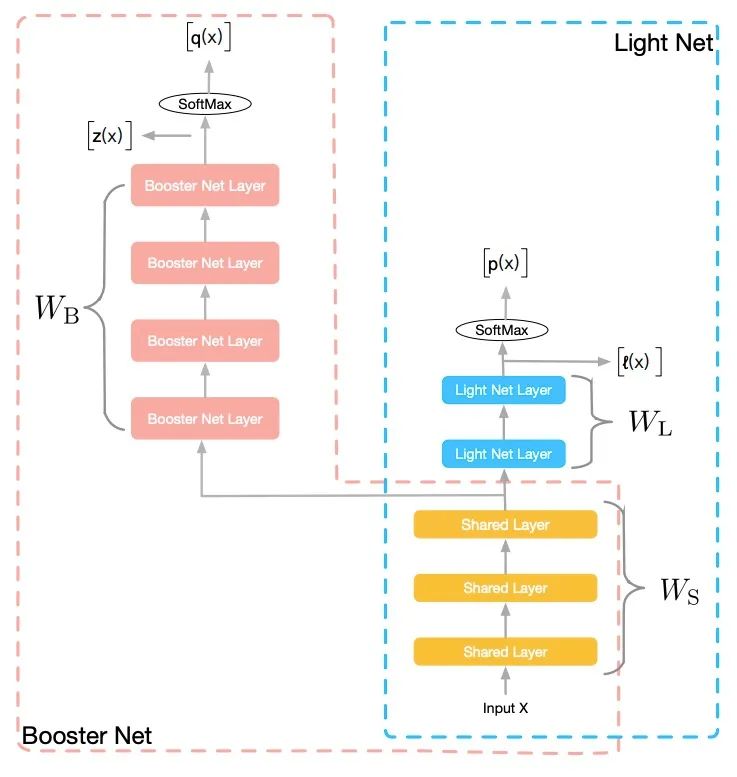
助推器網(wǎng)絡(luò)和輕量網(wǎng)絡(luò)共享部分層的參數(shù),共享的參數(shù)可以根據(jù)網(wǎng)絡(luò)結(jié)構(gòu)的變化而變化。在神經(jīng)網(wǎng)絡(luò)中,低層可以用來學(xué)習(xí)信息表示,低層網(wǎng)絡(luò)的共享,可以幫助輕量網(wǎng)絡(luò)獲得更好的信息表示能力。如上圖所示,訓(xùn)練階段,我們同時(shí)學(xué)習(xí)兩個(gè)網(wǎng)絡(luò):Light Net 和Booster Net,兩個(gè)網(wǎng)絡(luò)共享部分信息。我們把大部分的模型理解為表示層學(xué)習(xí)和判別層學(xué)習(xí)、 ,表示層學(xué)習(xí)的是對(duì)輸入信息做一些高階處理,而判別層則是和當(dāng)前子任務(wù)目標(biāo)相關(guān)的學(xué)習(xí)。表示層的學(xué)習(xí)是可以共享的,共享的信息為底層參數(shù),這些底層參數(shù)能一定程度上反應(yīng)了對(duì)輸入信息的基本刻畫。在整個(gè)訓(xùn)練過程中,網(wǎng)絡(luò)的Loss如下:
Loss包含三部分:第一項(xiàng),為L(zhǎng)ight Net對(duì)Ground Truth的學(xué)習(xí);第二項(xiàng),為Booster Net對(duì)Ground Truth的學(xué)習(xí);第三項(xiàng),為兩個(gè)網(wǎng)絡(luò)Softmax之前的logits的均方誤差(MSE),該項(xiàng)作為hint loss,用來使兩個(gè)網(wǎng)絡(luò)學(xué)習(xí)得到的logits盡量相似。
與傳統(tǒng)的知識(shí)蒸餾相比,該論文提出的新型框架的創(chuàng)新點(diǎn)和優(yōu)勢(shì)在于:
復(fù)雜和簡(jiǎn)單兩個(gè)網(wǎng)絡(luò)同時(shí)訓(xùn)練。 一方面, 縮短總的訓(xùn)練時(shí)間。相比傳統(tǒng)teacer-student范式中,先訓(xùn)練一個(gè)復(fù)雜網(wǎng)絡(luò),然后用其訓(xùn)練一個(gè)簡(jiǎn)單網(wǎng)絡(luò)。這里同時(shí)訓(xùn)練復(fù)雜和簡(jiǎn)單兩個(gè)網(wǎng)絡(luò)縮短了總的訓(xùn)練時(shí)間。另一方面, 助推器網(wǎng)絡(luò)全程提供soft target信息給輕量網(wǎng)絡(luò),從而達(dá)到指導(dǎo)輕量網(wǎng)絡(luò)整個(gè)求解過程的目的。這與一般的teacher-student 范式下,學(xué)習(xí)好大模型,僅用大模型固定的輸出作為soft target來監(jiān)督小網(wǎng)絡(luò)的學(xué)習(xí)有著明顯區(qū)別,因?yàn)锽ooster Net的每一次迭代輸出雖然不能保證對(duì)應(yīng)一個(gè)和Label非常接近的預(yù)測(cè)值,但是到達(dá)這個(gè)解之后有利于找到最終收斂的解。相比傳統(tǒng)方法,同時(shí)訓(xùn)練獲得了更多的指導(dǎo)信息,從而取得更好的效果。 采用梯度固定技術(shù)。 訓(xùn)練階段,兩網(wǎng)絡(luò)soft target的loss(hint loss)只用于輕量網(wǎng)絡(luò)的梯度更新,而不更新助推器網(wǎng)絡(luò),從而使得助推器網(wǎng)絡(luò)不受輕量網(wǎng)絡(luò)的影響,只從真實(shí)標(biāo)記中學(xué)習(xí)信息。由于助推器網(wǎng)絡(luò)有更多的參數(shù),有更強(qiáng)的擬合能力,我們需要給它更大的自由度來學(xué)習(xí),盡量減少輕量網(wǎng)絡(luò)對(duì)它的拖累。梯度固定技術(shù)的目的是,在hint loss進(jìn)行梯度回傳時(shí),我們固定助推器網(wǎng)絡(luò)獨(dú)有的參數(shù) 不更新,讓該時(shí)刻的助推器網(wǎng)絡(luò)前向傳遞得到的 監(jiān)督輕量網(wǎng)絡(luò)的學(xué)習(xí),從而使得小網(wǎng)絡(luò)向大網(wǎng)絡(luò)靠近。這一技術(shù),使得助推器網(wǎng)絡(luò)擁有更強(qiáng)的自由度來學(xué)習(xí)更好的模型,而助推器網(wǎng)絡(luò)效果的提升,也會(huì)提升輕量網(wǎng)絡(luò)的訓(xùn)練效果。
在線響應(yīng)時(shí)間對(duì)在線系統(tǒng)至關(guān)重要。該論文提出的火箭發(fā)射式訓(xùn)練框架,在不提高預(yù)測(cè)時(shí)間的前提下,提高了模型的預(yù)測(cè)效果,為提高線上模型效果提供了新思路。目前Rocket Launching的框架為在線CTR預(yù)估系統(tǒng)弱化在線響應(yīng)時(shí)間限制和模型結(jié)構(gòu)復(fù)雜化的矛盾提供了可靠的解決方案,該技術(shù)可以做到在線計(jì)算被壓縮倍的情況下性能不變。在阿里真實(shí)的應(yīng)用場(chǎng)景中,日常可以減少在線服務(wù)機(jī)器資源消耗,雙十一這種高峰流量場(chǎng)景更是保障算法技術(shù)不降級(jí)的可靠方案。
【相關(guān)文章】
Zhou G, Fan Y, Cui R, et al. Rocket launching: A universal and efficient framework for training well-performing light net[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
3.1.2 《Privileged Features Distillation at Taobao Recommendations》
這篇同樣是阿里的一篇將“目標(biāo)蒸餾-logits方法“應(yīng)用到推薦系統(tǒng)領(lǐng)域的論文,被KDD 2020所接收。 論文《Privileged Features Distillation at Taobao Recommendations》提出的蒸餾技術(shù)是我在工業(yè)界見過的知識(shí)蒸餾用在推薦系統(tǒng)領(lǐng)域最廣泛的技術(shù)之一,整篇文章思路比較樸素,對(duì)于工業(yè)應(yīng)用具有非常大的借鑒意義。因此,我會(huì)詳細(xì)重點(diǎn)介紹這篇論文。
(1)推薦中的優(yōu)勢(shì)特征
在推薦系統(tǒng)的粗排階段,主要的任務(wù)是預(yù)估召回階段返回的候選集中每個(gè)物品的點(diǎn)擊率,然后選擇排序分最高的一些物品進(jìn)入精排階段。粗排階段輸入的特征主要有用戶的行為特征(如用戶的歷史點(diǎn)擊/購(gòu)買行為)、用戶屬性特征(如用戶id、性別、年齡等)、物品特征(如物品id、類別、品牌等)。在粗排階段,由于要在毫秒內(nèi)給成千上萬(wàn)的候選物品打分,因此模型的復(fù)雜度受到了很大的限制,工業(yè)界傳統(tǒng)的做法是使用內(nèi)積模型,把用戶側(cè)和物品側(cè)作為雙塔,在請(qǐng)求時(shí),把用戶側(cè)的向量和候選物品向量進(jìn)行內(nèi)積運(yùn)算,從而對(duì)物品池做粗篩。有一些交叉特征對(duì)粗排效果有明顯的提升,比如用戶在過去小時(shí)內(nèi)在待預(yù)估商品類目下的點(diǎn)擊次數(shù)、用戶過去小時(shí)內(nèi)在待預(yù)估商品所在店鋪中的點(diǎn)擊次數(shù)等。對(duì)于這些交叉特征,如果放到用戶側(cè),那么針對(duì)每個(gè)物品都需要計(jì)算一次用戶側(cè)的塔;如果放到物品側(cè),同樣針對(duì)每個(gè)物品都需要計(jì)算一次物品側(cè)的塔,這會(huì)大大加大計(jì)算復(fù)雜度,增加線上的推理延時(shí)。因此,這些交叉特征對(duì)于粗排階段的模型來說,通常在線上無(wú)法應(yīng)用,我們就稱它們?yōu)榇峙臗TR預(yù)估中的Privileged Features。
在精排階段,我們不僅要預(yù)估CTR,還要預(yù)估CVR,即用戶點(diǎn)擊跳轉(zhuǎn)到商品頁(yè)后購(gòu)買該商品的概率。在電商領(lǐng)域的推薦,主要目標(biāo)是最大化GMV,即 GMV = CTR * CVR * Price 。一旦預(yù)估了所有商品的CTR和CVR,我們就可以根據(jù)預(yù)期的GMV對(duì)它們進(jìn)行排名,使得GMV最大化。在CVR的定義下,很明顯用戶在商品頁(yè)的行為特征對(duì)于CVR預(yù)估會(huì)非常有幫助,比如說用戶在商品頁(yè)停留的時(shí)長(zhǎng)、是否查看評(píng)論、是否與商家溝通等。但是,這些特征在線上預(yù)估階段是無(wú)法獲取的,商品在被用戶點(diǎn)擊之前就需要估計(jì)CVR以進(jìn)行排序。所以對(duì)于CVR預(yù)估來說,用戶在點(diǎn)擊后進(jìn)入到商品頁(yè)的一些特征(比如停留時(shí)長(zhǎng)、是否查看評(píng)論、是否與商家溝通等)同樣是Privileged Features。
再比如,在短視頻粗排或精排階段要做多目標(biāo)預(yù)估,即不僅要預(yù)估點(diǎn)擊率還要預(yù)估該視頻的點(diǎn)贊、評(píng)論、分享轉(zhuǎn)發(fā)、進(jìn)入個(gè)人主頁(yè)、收藏、下載等互動(dòng)目標(biāo)。如果此時(shí),用戶點(diǎn)擊該視頻,并對(duì)該視頻進(jìn)行了觀看。那么,用戶的視頻觀看時(shí)長(zhǎng)特征,對(duì)于互動(dòng)目標(biāo)的預(yù)估顯的很重要,但是在線上推理時(shí),我們需要在預(yù)估點(diǎn)擊率之前就要估計(jì)互動(dòng)目標(biāo),并不能獲取到視頻觀看時(shí)長(zhǎng)這一重要特征。因此,我們可以把用戶觀看視頻時(shí)長(zhǎng)特征作為Privileged Features。
使用這些Privileged Features,可以提升模型的預(yù)測(cè)精度。因此本論文借鑒模型蒸餾的思想,讓粗排階段的CTR模型或者是精排階段的CVR模型,都能夠?qū)W習(xí)到一些Privileged Features的信息。
(2)優(yōu)勢(shì)特征蒸餾
直觀來看,使用多任務(wù)學(xué)習(xí)(Multi-Task Learning,簡(jiǎn)稱MTL)來預(yù)測(cè)優(yōu)勢(shì)特征是一個(gè)不錯(cuò)的選擇。然而,在多任務(wù)學(xué)習(xí)中,每個(gè)子任務(wù)往往很難滿足對(duì)其他任務(wù)的無(wú)害準(zhǔn)則(No-harm Guarantee),換句話說,預(yù)測(cè)優(yōu)勢(shì)特征的任務(wù)可能會(huì)對(duì)原始的預(yù)測(cè)任務(wù)造成負(fù)面影響,尤其是預(yù)測(cè)優(yōu)勢(shì)特征的任務(wù)比原始任務(wù)來得更有挑戰(zhàn)性時(shí)。從實(shí)踐的角度來看,如果同時(shí)預(yù)測(cè)許多優(yōu)勢(shì)特征,如何平衡各個(gè)任務(wù)的權(quán)重也會(huì)非常困難。
為了更優(yōu)雅地利用優(yōu)勢(shì)特征,本論文提出優(yōu)勢(shì)特征蒸餾(Privileged Features Distillation,簡(jiǎn)稱PFD)。在離線環(huán)境下,我們會(huì)同時(shí)訓(xùn)練兩個(gè)模型:一個(gè)學(xué)生模型以及一個(gè)教師模型。其中學(xué)生模型和原始模型完全相同,而教師模型額外利用了優(yōu)勢(shì)特征, 其準(zhǔn)確率也因此更高。 通過將教師模型蒸餾出的知識(shí)(Knowledge,論文中特指教師模型中最后一層的輸出)傳遞給學(xué)生模型,可以輔助其訓(xùn)練并進(jìn)一步提升準(zhǔn)確率。在線上服務(wù)時(shí),我們只抽取學(xué)生模型進(jìn)行部署,因?yàn)檩斎氩灰蕾囉趦?yōu)勢(shì)特征,離線、在線的一致性得以保證。在PFD中,所有的優(yōu)勢(shì)特征都被統(tǒng)一到教師模型作為輸入,加入更多的優(yōu)勢(shì)特征往往能帶來模型更高的準(zhǔn)確度。相反,在MTL中,預(yù)測(cè)更多的優(yōu)勢(shì)特征反而可能損害原始模型。更進(jìn)一步,相比原始目標(biāo)函數(shù),PFD只引入額外一項(xiàng)蒸餾誤差,因此更容易與原始損失函數(shù)平衡。
上面的損失函數(shù)被分為兩部分,兩部分都是計(jì)算交叉熵。損失的第一部分是可以稱為hard loss,其label是或者;第二部分可以稱為soft loss或distillation loss,其label是Teacher網(wǎng)絡(luò)的Softmax輸出,是概率值,如(的概率點(diǎn)擊,的概率不點(diǎn)擊)。其中,表示普通的輸入特征,表示優(yōu)勢(shì)特征,表示Label,表示模型的輸出,表示損失函數(shù),其中下標(biāo) 指代student,指代distillation,指代teacher。是平衡兩個(gè)損失函數(shù)之間的超參數(shù)。值得注意的是,在教師模型中,除了輸入優(yōu)勢(shì)特征以外,我們還將普通特征輸入到教師模型中去。如上述公式中所示,教師模型的參數(shù)需要預(yù)先學(xué)好,這直接導(dǎo)致模型的訓(xùn)練時(shí)間加倍。
PFD不同于常見的模型蒸餾(Model Distillation,簡(jiǎn)稱MD)。在MD中,教師模型和學(xué)生模型處理同樣的輸入特征,其中教師模型會(huì)比學(xué)生模型更為復(fù)雜,比如,教師模型會(huì)用更深的網(wǎng)絡(luò)結(jié)構(gòu)來指導(dǎo)使用淺層網(wǎng)絡(luò)的學(xué)生模型進(jìn)行學(xué)習(xí)。在PFD中,教師和學(xué)生模型會(huì)使用相同網(wǎng)絡(luò)結(jié)構(gòu),而處理不同的輸入特征。在下圖中,我們給出了優(yōu)勢(shì)特征蒸餾和模型蒸餾的網(wǎng)絡(luò)結(jié)構(gòu)區(qū)別。
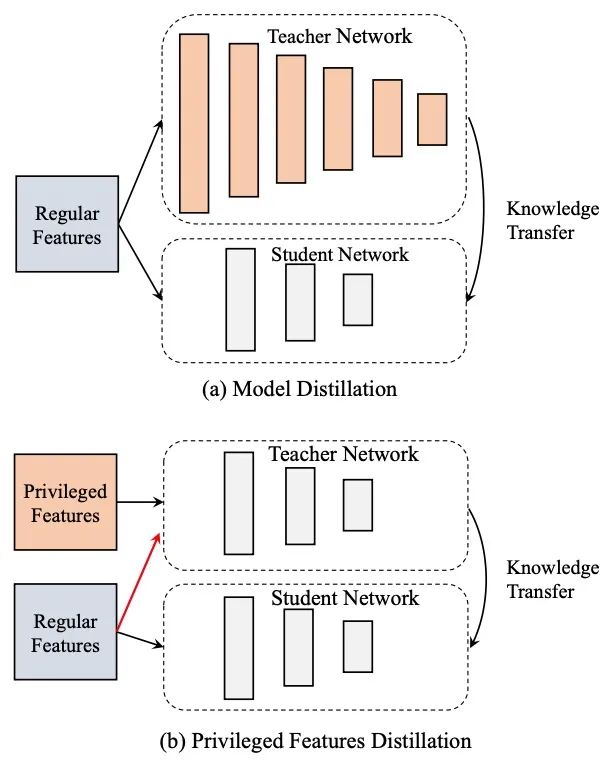
如上述損失函數(shù)的公式所示,教師模型的參數(shù)需要預(yù)先學(xué)好,這直接導(dǎo)致模型的訓(xùn)練時(shí)間加倍。一種更直接的方式是同步更新學(xué)生和教師模型,因此目標(biāo)函數(shù)變成如下形式:
盡管同步更新能顯著縮短訓(xùn)練時(shí)間,但也會(huì)導(dǎo)致訓(xùn)練不穩(wěn)定的問題。尤其在訓(xùn)練初期,教師模型還處于欠擬合的情況下,學(xué)生模型直接學(xué)習(xí)教師模型的輸出會(huì)有一定的概率導(dǎo)致訓(xùn)練偏離正常。解決這個(gè)問題的方法也非常簡(jiǎn)單,只需要在開始階段將設(shè)定為,然后在預(yù)設(shè)的迭代步將其設(shè)為固定值。具體步驟可以參見下圖算法1。值得一提的是,我們讓蒸餾誤差項(xiàng)只影響學(xué)生網(wǎng)絡(luò)的參數(shù)的更新,而對(duì)教師網(wǎng)絡(luò)的參數(shù)不做梯度回傳,從而避免學(xué)生網(wǎng)絡(luò)和教師網(wǎng)絡(luò)相互適應(yīng)(co-adaption)而損失精度。

(3)優(yōu)勢(shì)特征蒸餾+模型蒸餾
在上圖中,我們比較了模型蒸餾和優(yōu)勢(shì)特征蒸餾的異同,既然兩者都能提升學(xué)生模型的效果且互補(bǔ),一個(gè)直觀的想法就是將這兩種技巧結(jié)合在一起以進(jìn)一步提升效果。
這里我們嘗試在粗排CTR模型中使用這種PFD+MD技巧。在粗排中,我們使用內(nèi)積運(yùn)算對(duì)候選商品集合進(jìn)行打分。事實(shí)上,無(wú)論采用何種映射表征用戶或者商品,模型最終都會(huì)受限于頂層雙線性(Bi-Linear)內(nèi)積運(yùn)算的表達(dá)能力。內(nèi)積粗排模型可以看成是廣義的矩陣分解,不過與常規(guī)的分解不同的是,這里額外融合了各種輔助信息(side information)。按照神經(jīng)網(wǎng)絡(luò)的萬(wàn)有逼近定理,非線性(Non-Linear)MLP,有著比雙線性內(nèi)積運(yùn)算更強(qiáng)的表達(dá)能力,在這里很自然地被選為更強(qiáng)的教師模型。下圖給出了粗排PFD+MD蒸餾框架示意圖。事實(shí)上,圖中加了優(yōu)勢(shì)特征的教師模型就是我們線上精排CTR模型,所以這里的蒸餾技巧也可以看成粗排反向?qū)W習(xí)精排的打分結(jié)果。
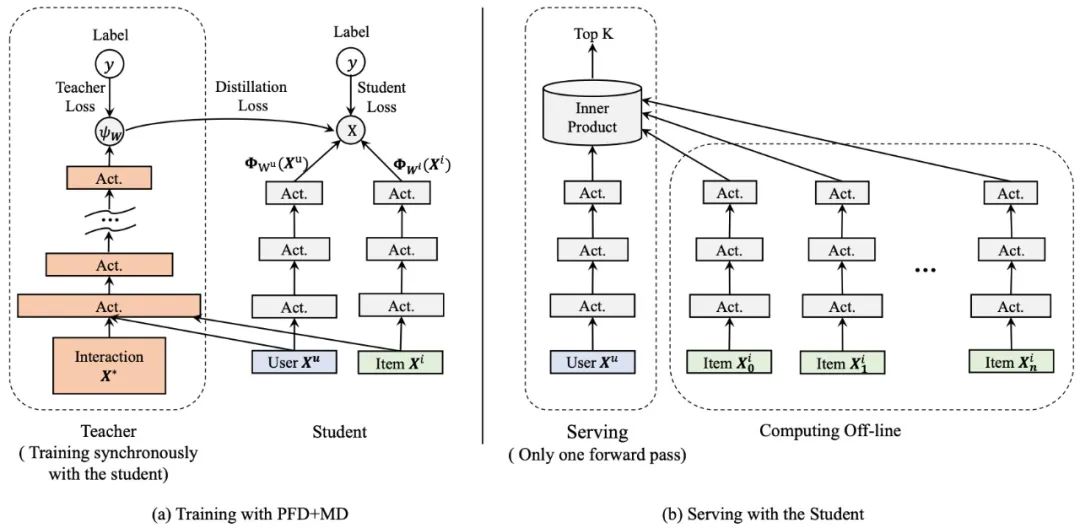
(4)實(shí)驗(yàn)結(jié)論
在手淘信息流的兩個(gè)基礎(chǔ)預(yù)測(cè)任務(wù)上進(jìn)行PFD實(shí)驗(yàn)。在粗排CTR模型中,通過蒸餾交叉特征(在線構(gòu)造特征以及模型推理延時(shí)過高,在粗排上無(wú)法直接使用)以及蒸餾表達(dá)能力更強(qiáng)的MLP模型,即通過MD+PFD可以在線提升%的點(diǎn)擊指標(biāo)(同時(shí)保證成交指標(biāo)不降)。在精排CVR模型上,通過蒸餾停留時(shí)長(zhǎng)等后驗(yàn)特征,只對(duì)PFD做測(cè)試,對(duì)比Baseline,PFD提升%的成交指標(biāo)(并且點(diǎn)擊指標(biāo)不降)。
【相關(guān)文章】
Xu C, Li Q, Ge J, et al. Privileged Features Distillation at Taobao Recommendations[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2590-2598.
3.1.3 《Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System》
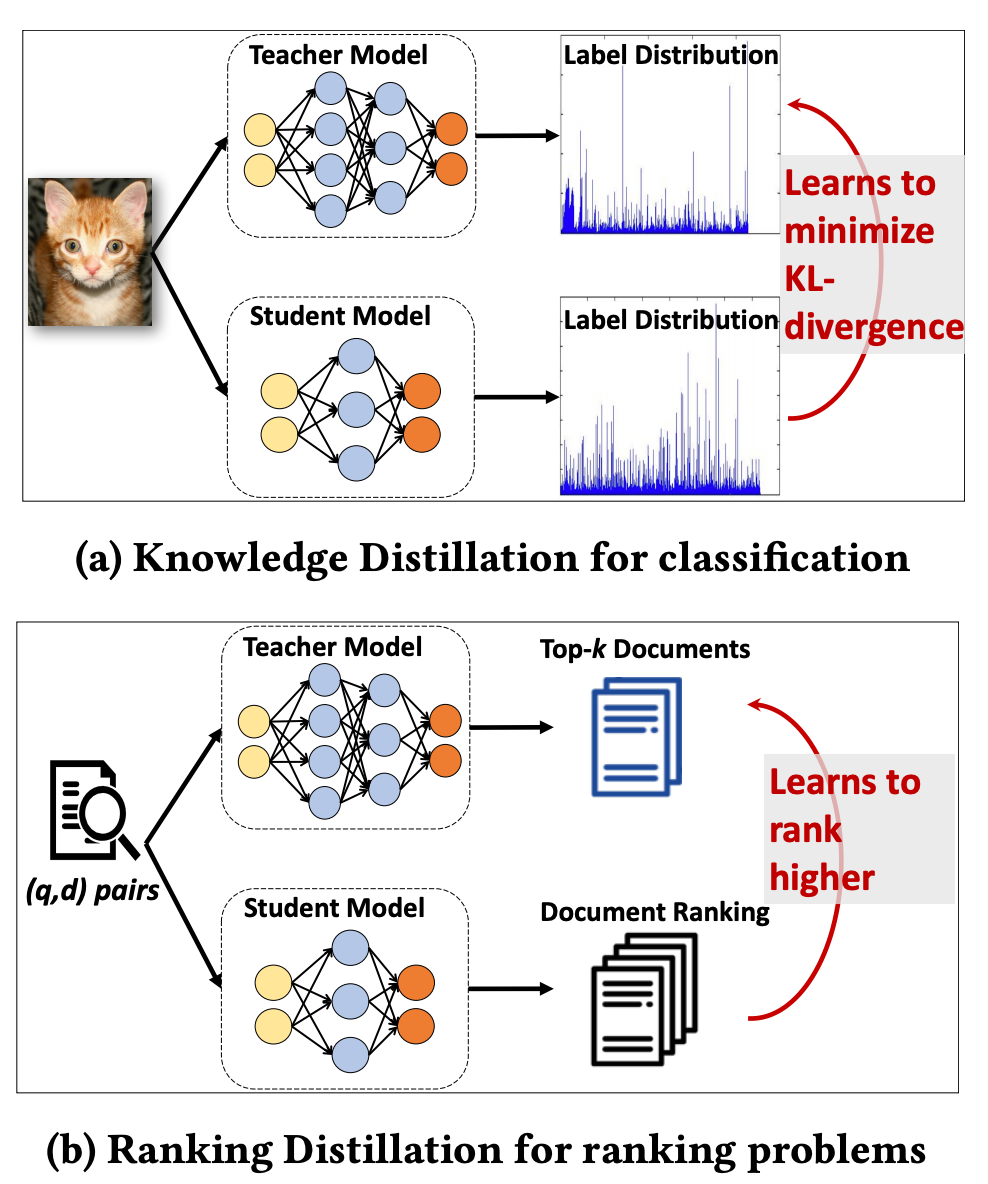
這篇論文是將“目標(biāo)蒸餾-logits方法“應(yīng)用到推薦系統(tǒng)領(lǐng)域的論文,被KDD 2018所接收。 因?yàn)槭峭扑]和信息檢索相關(guān)的論文,有一定的借鑒價(jià)值,因此也在這里給大家介紹一下。本論文提出的背景是:(1)檢索系統(tǒng)或推薦系統(tǒng)中模型龐大,可以用蒸餾網(wǎng)絡(luò)的方式提升工程效率;(2)目標(biāo)是給一個(gè)query,預(yù)測(cè)檢索系統(tǒng)的Top K相關(guān)的documents。知識(shí)蒸餾是指:給定一個(gè)輸入,學(xué)生模型學(xué)習(xí)最小化Label和教師模型Soft-target的KL散度;排序蒸餾是指:給定一個(gè)query,學(xué)生模型將因其教師模型的前K個(gè)文檔排名而獲得更高的排名;兩者區(qū)別如下圖所示。
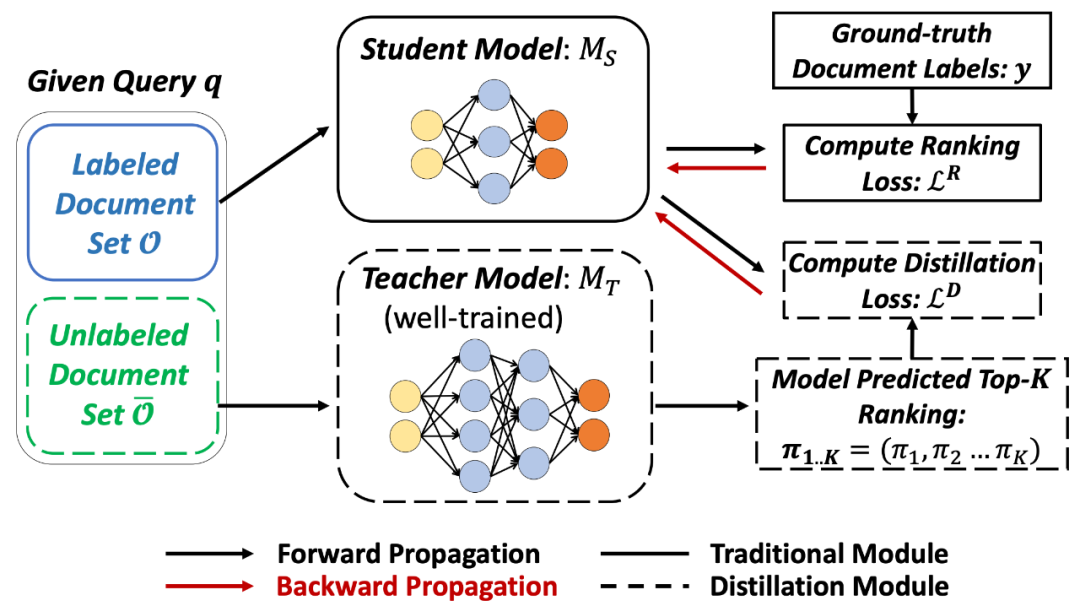
排序蒸餾的過程如下圖所示。第一階段訓(xùn)練教師網(wǎng)絡(luò),對(duì)于每個(gè)query預(yù)測(cè)Top K相關(guān)documents,補(bǔ)充為學(xué)生網(wǎng)絡(luò)的Ground truth信息;第二階段教師網(wǎng)絡(luò)的Top K作為正例加到學(xué)生網(wǎng)絡(luò)中一起進(jìn)行訓(xùn)練,使得學(xué)生網(wǎng)絡(luò)和教師網(wǎng)絡(luò)的預(yù)測(cè)結(jié)果更像。
排序蒸餾的損失函數(shù)如下:
其中,Loss的第一部分為交叉熵Loss, 為真實(shí)標(biāo)簽, 為學(xué)生網(wǎng)絡(luò)的預(yù)測(cè)結(jié)果。第二部分為蒸餾損失,教師網(wǎng)絡(luò)對(duì)無(wú)標(biāo)簽數(shù)據(jù)排序出的Top K作為正樣本指導(dǎo)學(xué)生模型學(xué)習(xí)。第二部分Top K 損失的具體公式為:
其中,為每條教師網(wǎng)絡(luò)中預(yù)測(cè)的樣本的權(quán)重,有兩種方式生成:
對(duì)位置進(jìn)行加權(quán)(即,Top 1到K的順序); 對(duì)排序相關(guān)性進(jìn)行加權(quán)(考慮教師網(wǎng)絡(luò)預(yù)測(cè)的documents與query的相關(guān)性程度)。
【相關(guān)文章】
Tang J, Wang K. Ranking distillation: Learning compact ranking models with high performance for recommender system[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2289-2298.
3.1.4 《Ensembled CTR Prediction via Knowledge Distillation》
這是華為發(fā)表的一篇將“目標(biāo)蒸餾-logits方法“和“特征蒸餾(即學(xué)習(xí)Teacher模型的中間層特征)”應(yīng)用到推薦系統(tǒng)領(lǐng)域的論文,被CIKM 2020所接收。 當(dāng)前對(duì)于CTR預(yù)估的研究大致集中在兩個(gè)方面,一種是嘗試更為復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)來更好的捕捉特征之間的交叉信息以及用戶的動(dòng)態(tài)行為信息,如引入卷積神經(jīng)網(wǎng)絡(luò)、循環(huán)神經(jīng)網(wǎng)絡(luò)、注意力機(jī)制和圖神經(jīng)網(wǎng)絡(luò)等;另一種趨勢(shì)是沿用Wide & Deep的思路,嘗試將多個(gè)子模塊進(jìn)行融合,如DeepFM、DCN、XDeepFM、AutoInt等。盡管這些研究帶來了點(diǎn)擊率預(yù)估效果的提升,但是隨著模型結(jié)構(gòu)變得更加復(fù)雜,在實(shí)際工業(yè)界使用這些模型耗時(shí)會(huì)越來越高,往往難以真正在線上進(jìn)行部署。那么如何既能保持多模型融合的效果,同時(shí)又能夠使得模型更加輕量化呢?知識(shí)蒸餾的方式是一種不錯(cuò)的選擇。
(1)單教師網(wǎng)絡(luò)知識(shí)蒸餾
首先來看一下單教師網(wǎng)絡(luò)知識(shí)蒸餾的框架:
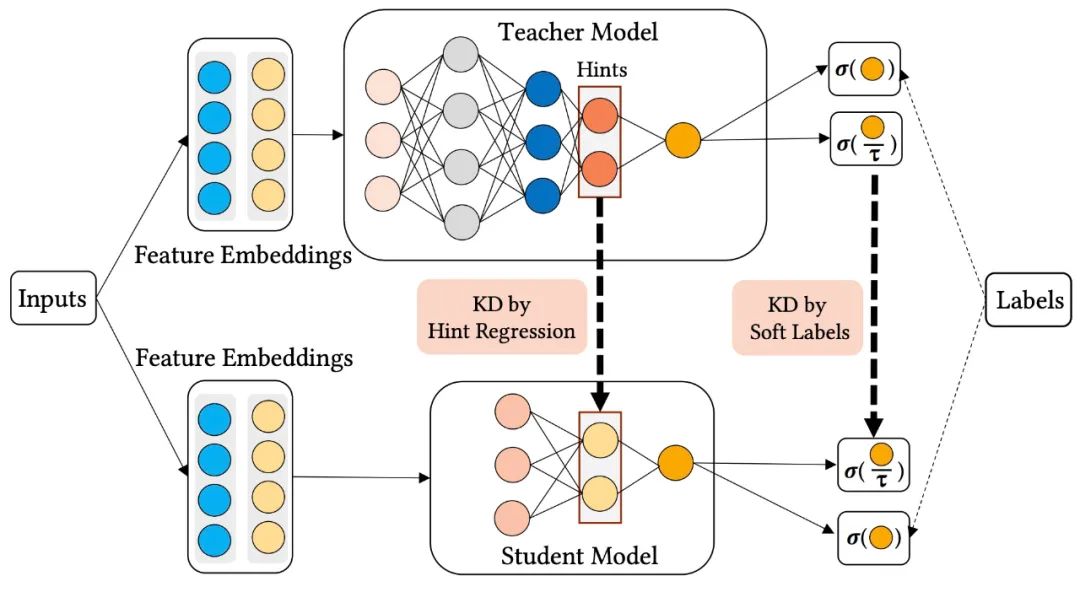
從上圖中可以看到,用同樣的特征分別輸入到teacher網(wǎng)絡(luò)和student網(wǎng)絡(luò)中,得到teacher網(wǎng)絡(luò)的輸出為 ,得到student網(wǎng)絡(luò)的輸出為 ,那么在訓(xùn)練時(shí)teacher網(wǎng)絡(luò)和student網(wǎng)絡(luò)的損失分別為:
其中, 表示交叉熵?fù)p失, 表示蒸餾損失。 表示teacher網(wǎng)絡(luò)的損失,它只有交叉熵?fù)p失。 表示student網(wǎng)絡(luò)的損失,它不僅包含交叉熵?fù)p失,還包括一項(xiàng)蒸餾損失。為了使知識(shí)從教師模型轉(zhuǎn)移到學(xué)生模型,在論文中,使用兩種最常用的蒸餾方法:soft label(目標(biāo)蒸餾-logits方法)和hint regression(學(xué)習(xí)Teacher模型的中間層特征)。
soft label蒸餾損失如下所示:
其中, 表示交叉熵?fù)p失,表示教師模型最后softmax層輸出的類別概率,表示學(xué)生模型最后softmax層輸出的類別概率,就是溫度。關(guān)于soft label蒸餾、hint regression蒸餾和溫度參數(shù)作用,可以看我的這篇文章:深度學(xué)習(xí)中的知識(shí)蒸餾技術(shù)
hint regression蒸餾損失函數(shù)如下:
hint regression的目的是引導(dǎo)student網(wǎng)絡(luò)學(xué)習(xí)teacher網(wǎng)絡(luò)的中間層表示。這里代表teacher網(wǎng)絡(luò)的中間層表示,代表student網(wǎng)絡(luò)中被指導(dǎo)的層的輸出。通過矩陣進(jìn)行變換,期望二者的距離越近越好。
(2)多教師網(wǎng)絡(luò)知識(shí)蒸餾
模型融合能夠有效提升CTR預(yù)估的效果,但會(huì)帶來耗時(shí)的增加。因此,可以通過知識(shí)蒸餾的方式,讓student網(wǎng)絡(luò)從多個(gè)模型中進(jìn)行學(xué)習(xí),來達(dá)到近似或比模型融合更佳的效果。因此,論文提出了多教師網(wǎng)絡(luò)知識(shí)蒸餾,其結(jié)構(gòu)如下圖所示:
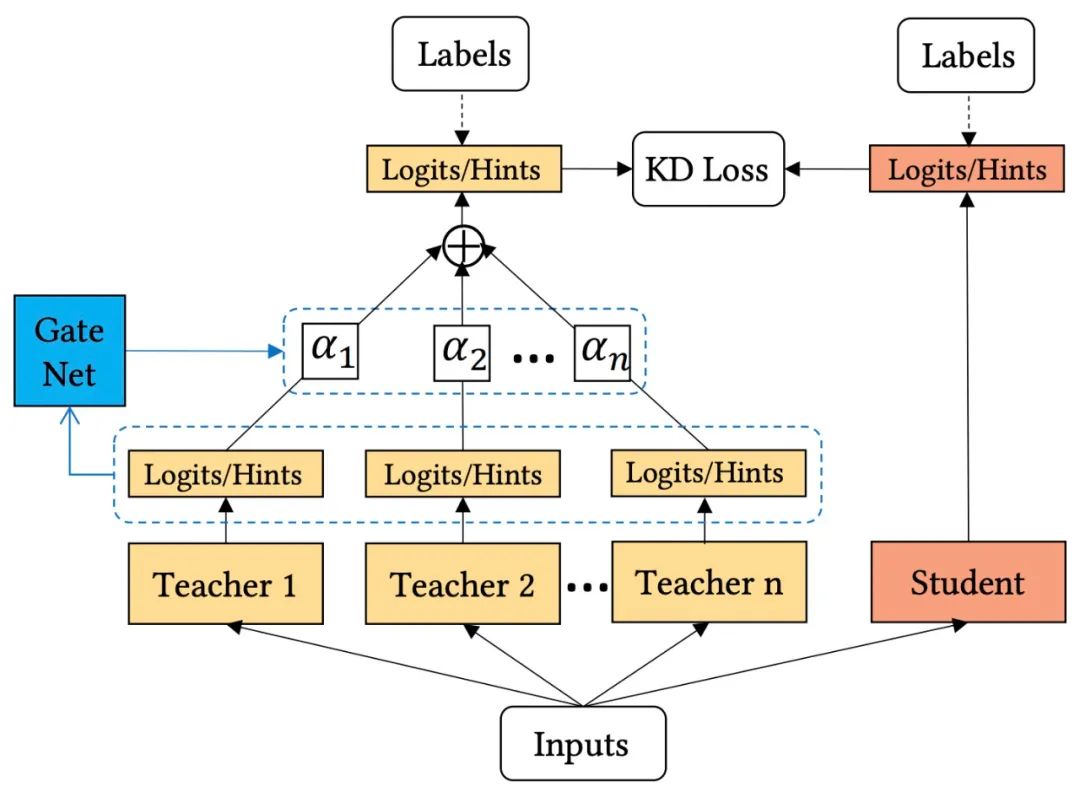
這里的主要問題是,多個(gè)teacher網(wǎng)絡(luò)如何向student網(wǎng)絡(luò)傳遞知識(shí)?最簡(jiǎn)單的方式就是對(duì)所有teacher模型的輸出進(jìn)行平均,從而使問題簡(jiǎn)化為向單個(gè)教師學(xué)習(xí)。這種做法實(shí)現(xiàn)簡(jiǎn)單,但是不同teacher的模型結(jié)構(gòu)和訓(xùn)練框架都不同,因此并非所有的教師模型都可以在每個(gè)樣本上提供同等重要的知識(shí)。效率低下的教師模型甚至可能會(huì)誤導(dǎo)學(xué)生模型的學(xué)習(xí)。為了從多個(gè)教師模型那里獲得有效的知識(shí),論文提出了一種自適應(yīng)的集成蒸餾框架,如上圖所示,可以動(dòng)態(tài)地調(diào)整每個(gè)教師模型的貢獻(xiàn)。因此有了如下式所示的自適應(yīng)蒸餾損失函數(shù):
為了實(shí)現(xiàn)動(dòng)態(tài)學(xué)習(xí)權(quán)重和自適應(yīng)不同的訓(xùn)練樣本,作者提出了一個(gè)教師門控網(wǎng)絡(luò)(Teacher gating network)來調(diào)整教師模型的重要性權(quán)重,從而實(shí)現(xiàn)按樣本進(jìn)行教師模型選擇。更具體地說,采用softmax函數(shù)作為門控函數(shù),計(jì)算方式如下:
(3)網(wǎng)絡(luò)訓(xùn)練
知識(shí)蒸餾一般有兩種訓(xùn)練方式,pre-train方式和co-train方式。pre-train方式是預(yù)先訓(xùn)練teacher網(wǎng)絡(luò),然后再訓(xùn)練student網(wǎng)絡(luò);co-train方式則是通過上述介紹的損失對(duì)teacher網(wǎng)絡(luò)和student網(wǎng)絡(luò)進(jìn)行聯(lián)合訓(xùn)練。co-train方式往往訓(xùn)練速度更快,但所需的GPU資源也會(huì)更多。論文的實(shí)驗(yàn)部分也對(duì)這兩種訓(xùn)練方式進(jìn)行了比較,感興趣的同學(xué)可以閱讀一下論文原文。
【相關(guān)文章】
Zhu J, Liu J, Li W, et al. Ensembled CTR Prediction via Knowledge Distillation[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2941-2958.
3.1.5 百度CTR 3.0 雙DNN聯(lián)合訓(xùn)練
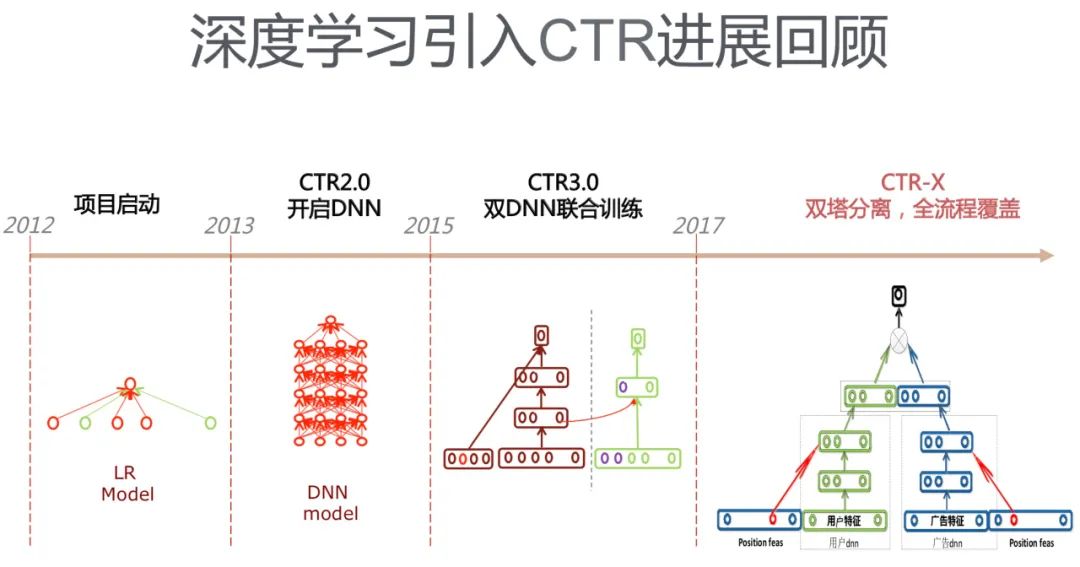
這是2017年百度當(dāng)時(shí)商務(wù)搜索智能交互部負(fù)責(zé)人劉斌新在其PPT《AI筑巢:機(jī)器學(xué)習(xí)在百度鳳巢的深度應(yīng)用》中提到的類似知識(shí)蒸餾的技術(shù)。由于百度極少對(duì)外公開自己的技術(shù),放在這里是想讓大家了解一下,百度廣告CTR模型的發(fā)展歷史。
百度廣告CTR模型的發(fā)展歷程如下圖所示,CTR-X是一個(gè)用于粗排階段的DSSM,其中CTR3.0與知識(shí)蒸餾的工作比較相似,類似于將“特征蒸餾(即學(xué)習(xí)Teacher模型的中間層特征)”應(yīng)用在CTR模型中, 也是用于精排階段,但是訓(xùn)練兩個(gè)結(jié)構(gòu)差不多的DNN需要運(yùn)用類似于特征遷移的方法,左側(cè)DNN主要用來學(xué)習(xí)稀疏特征embedding向量,右側(cè)DNN使用左側(cè)訓(xùn)練得到的embedding向量和其它特征作為輸入訓(xùn)練CTR模型。
3.1.6 愛奇藝在排序階段提出了雙DNN排序模型
近年來隨著人工智能的發(fā)展,深度學(xué)習(xí)開始在工業(yè)界不同場(chǎng)景落地。深度學(xué)習(xí)跟以前的機(jī)器學(xué)習(xí)模型相比,其中很重要的特點(diǎn)就是能在模型側(cè)自動(dòng)構(gòu)建特征,實(shí)現(xiàn)端到端學(xué)習(xí),效果也有明顯提升,但新的問題如模型效果和推理效率的沖突也開始凸顯。愛奇藝提出了新的在線知識(shí)蒸餾方法來平衡模型效果和推理效率,在推薦場(chǎng)景上獲得了明顯的效果。愛奇藝在探索升級(jí)排序模型的過程中提出的雙DNN排序模型,這是一個(gè)將“目標(biāo)蒸餾-logits方法“和“特征蒸餾(即學(xué)習(xí)Teacher模型的中間層特征)”結(jié)合,應(yīng)用到推薦系統(tǒng)領(lǐng)域的實(shí)踐。
愛奇藝嘗試了一些復(fù)雜模型來取代改進(jìn)版的Wide & Deep模型,如DCN, xDeepFM等,但發(fā)現(xiàn)需要平衡large model 的模型效果和推理性能是有待解決的比較關(guān)鍵的問題。xDeepFM比較難落地主要有以下兩點(diǎn)原因:
推理性能:同等情況下,在CPU上推理,xDeepFM與改進(jìn)版的Wide & Deep模型相比,耗時(shí)是其~倍; 使用GPU時(shí),只有在大batch下,xDeepFM推理性能才符合要求。
通過實(shí)踐,愛奇藝提出了一種新的排序模型框架: 雙DNN排序模型,其核心在于提出了新的聯(lián)合訓(xùn)練方法,從而解決了高性能復(fù)雜模型的上線問題,該框架的特點(diǎn)和優(yōu)勢(shì)總結(jié)如下:
(1)雙DNN
左側(cè)DNN-Teacher網(wǎng)絡(luò)(紅框):模型性能更好的復(fù)雜模型,推理性能差; 右側(cè)DNN-Student網(wǎng)絡(luò)(黃框):模型性能一般的簡(jiǎn)單模型,推理性能佳;
(2) Fine-Tune
Teacher網(wǎng)絡(luò)(紅框)和Student網(wǎng)絡(luò)(黃框)share底層特征參數(shù)(藍(lán)框),teacher網(wǎng)絡(luò)多了Feature Interaction Layer層(該層是teacher網(wǎng)絡(luò)的核心,可以容納各種特征交互)。
(3)聯(lián)合訓(xùn)練
教師網(wǎng)絡(luò)監(jiān)督指導(dǎo)學(xué)生網(wǎng)絡(luò)的學(xué)習(xí); 學(xué)生網(wǎng)絡(luò)學(xué)習(xí)教師網(wǎng)絡(luò)的隱層輸出和Logits輸出(特征遷移 + 輸出遷移); Teacher網(wǎng)絡(luò)和Student網(wǎng)絡(luò)同時(shí)進(jìn)行訓(xùn)練; 訓(xùn)練穩(wěn)定,大網(wǎng)絡(luò)性能天花板不受小網(wǎng)絡(luò)影響;
排序模型結(jié)構(gòu)如下:
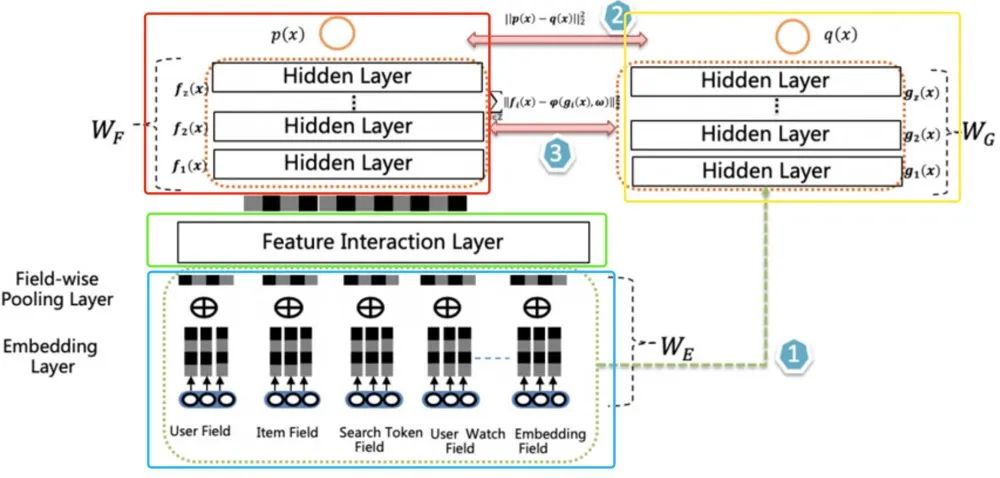
雙DNN排序模型由兩個(gè)DNN CTR模型組成,左側(cè)是Teacher,右側(cè)是Student,Student 模型是最終用于上線推理的CTR 模型。兩者共享特征輸入和表示,但是左側(cè)相比右側(cè)多了Feature Interaction Layer。左側(cè)和右側(cè)有各自獨(dú)立的MLP , 其包含多層Hidden Layer。主要Layer的介紹如下:
Embedding Layer: 輸入表示層,不同特征按Field組織,稀疏Field ID embedding化后通過average pooling得到field的embedding表示; Feature Interaction Layer: 這是左側(cè)模型核心,其可以容納各種形式的特征組合組件,二階或高階特征組合都可以放置在其中; Classifier Layer: 兩個(gè)DNN CTR模型的Classifier,一般是多層DNN;
【相關(guān)文章】
雙DNN排序模型:在線知識(shí)蒸餾在愛奇藝推薦的實(shí)踐,地址:https://mp.weixin.qq.com/s/ZNjC30F28uX2lBkHBAAU3g
3.2 粗排環(huán)節(jié)應(yīng)用知識(shí)蒸餾
3.2.1 騰訊-全民K歌粗排雙塔模型實(shí)踐
這是一個(gè)將“目標(biāo)蒸餾-logits方法“應(yīng)用到推薦系統(tǒng)領(lǐng)域的實(shí)踐。 粗排夾在召回跟精排之間,它的定位是什么?相比于召回,粗排更強(qiáng)調(diào)排序性,也就是更強(qiáng)調(diào)topk內(nèi)部的排序關(guān)系;相對(duì)于精排,粗排更強(qiáng)調(diào)性能,因?yàn)榫磐ǔS蟹浅?fù)雜的網(wǎng)絡(luò)結(jié)構(gòu),非常大的參數(shù)量,這也意味著它在實(shí)際應(yīng)用的過程中比較難去處理一個(gè)較大規(guī)模量級(jí)的候選集的打分,這時(shí)粗排就必須要解決這個(gè)問題,所以它在性能上會(huì)相較于精排有更多的要求。
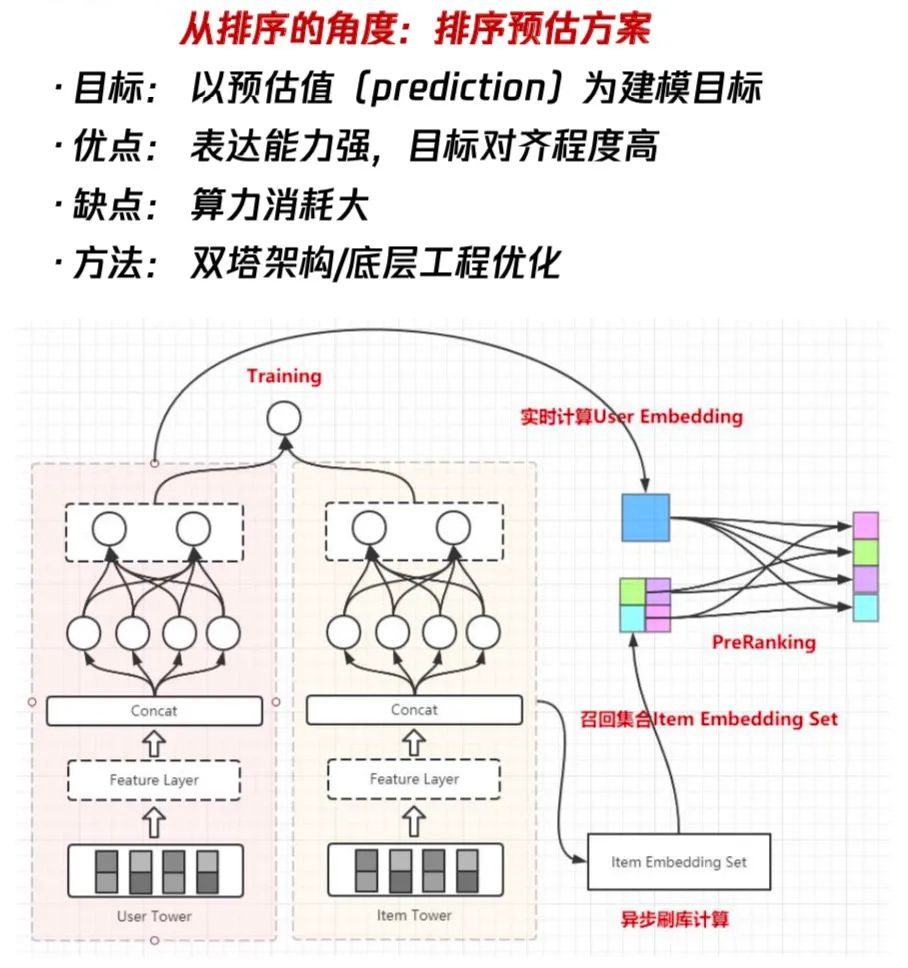
從精排的角度,把粗排當(dāng)成是精排的遷移或壓縮,也就是說從粗排到精排這是一條排序的路線,它的建模目標(biāo)是預(yù)估值。這種粗排建模方法的好處是它的表達(dá)能力很強(qiáng),因?yàn)橥ǔ?huì)用到一些比較復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu),而且它跟精排的聯(lián)動(dòng)性是更好的,可以讓粗排跟精排的目標(biāo)保持某種程度上的一致性。同時(shí),它的缺點(diǎn)也凸顯出來了,就是我們用到了復(fù)雜的方法,算力的消耗一定也會(huì)相應(yīng)的提升。因此,需要著重解決的是如何在有限的算力下盡可能地突破表達(dá)能力上限。在這種路線下,我們通常會(huì)在架構(gòu)選擇上選擇雙塔結(jié)構(gòu)模型,如上圖所示。
我們通過把user和item的feature進(jìn)行結(jié)構(gòu)解耦與分開建模,然后完成整個(gè)架構(gòu)的設(shè)計(jì),在模型訓(xùn)練完畢之后,我們會(huì)通過user serving實(shí)時(shí)的產(chǎn)出user embedding,再通過索引服務(wù)把該用戶所有的候選集合的ID給取出來,最后在user embedding跟item embedding之間做內(nèi)積的運(yùn)算,得到一個(gè)粗排的預(yù)估值,作為整個(gè)粗排階段的排序依據(jù)。
這么做的優(yōu)勢(shì)是user和item的結(jié)構(gòu)是解耦的,內(nèi)積計(jì)算的算力消耗小。同時(shí),它的缺點(diǎn)也非常的明顯:
第一個(gè)是它在特征表達(dá)上是缺失的,因?yàn)閡ser跟item解耦之后,很難使用一些交叉特征,一旦用了交叉特征,有多少item就得進(jìn)行多少次預(yù)估,這違背了我們使用雙塔模型的初衷。 第二個(gè)是雙塔模型在結(jié)構(gòu)上也是有缺陷的,從上面這幅框架圖中可以看到,user跟item的交互非常少,這會(huì)限制模型的表達(dá)能力的上限。
如果選擇了雙塔結(jié)構(gòu)模型,我們可以保障它的性能,但是需要進(jìn)一步的考慮如何避免這種簡(jiǎn)易的結(jié)構(gòu)所帶來的效果上的損失。在這種情況下,我們通常會(huì)使用一些模型蒸餾的方式。
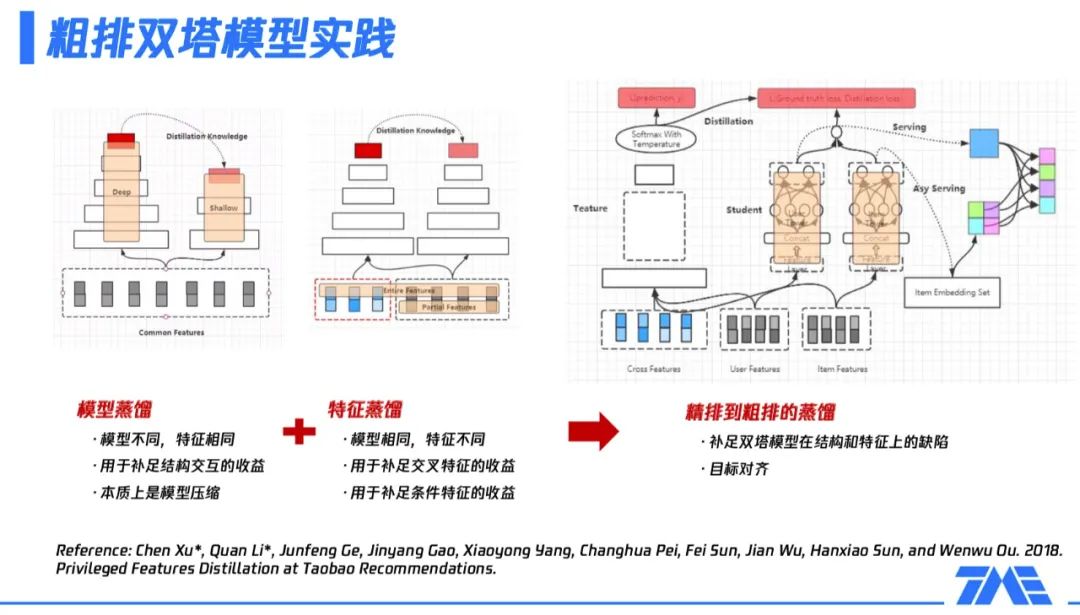
具體的,我們來看看全民K歌算法團(tuán)隊(duì)如何做粗排模塊的蒸餾,主要是分為兩個(gè)大的方向:
模型蒸餾,主要適用于模型不同但特征相同的情況,比如,包含多個(gè)場(chǎng)景的框架里,某些場(chǎng)景對(duì)性能有要求;由于有一些額外的外部限制,使某場(chǎng)景無(wú)法用很復(fù)雜參數(shù)量非常大的模型,可以用一個(gè)子模型使用全部特征。此時(shí),模型蒸餾主要是彌補(bǔ)子模型缺少?gòu)?fù)雜結(jié)構(gòu)或交互結(jié)構(gòu)導(dǎo)致的部分收益損失,本質(zhì)上是一種模型壓縮方案。 特征蒸餾,主要適用于模型相同但特征不同的情況,比如,在某些場(chǎng)景,無(wú)法使用全量特征 ( 如交叉特征 ) 或部分特征必須是剪裁過的,即特征沒被完全利用,存在一部分損失。這時(shí),通過一個(gè)更大的teacher模型學(xué)習(xí)全量特征,再把學(xué)到的知識(shí)遷移到子模型,即彌補(bǔ)了上述的部分特征損失。
基于以上描述可知,粗排模塊可以通過蒸餾的方式,補(bǔ)足雙塔模型在結(jié)構(gòu)和特征上的缺陷。接下來的問題就是如何找到一個(gè)合適的teacher模型?精排模型通常是一個(gè)被充分訓(xùn)練的、參數(shù)量很大、表達(dá)能力很強(qiáng)的模型,如果通過蒸餾精排模型獲取粗排模型,那么目標(biāo)的一致性和學(xué)習(xí)能力的上限都符合我們的預(yù)期。具體操作方式如上圖右側(cè)所示:
左側(cè)的teacher模型是精排模型,該模型使用全量的特征,包括三大類,即user側(cè)特征、item側(cè)特征及它們的交叉特征;虛線框里是一些復(fù)雜的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu);最后的softmax with temperature就是整個(gè)精排模型的輸出內(nèi)容,后續(xù)會(huì)給到粗排模型進(jìn)行蒸餾。 中間的粗排模型,user tower只用user features,item tower只用item features,即整體上看,模型未使用交叉特征。在user tower和item tower交互后,加上精排模型傳遞過來的logits信息,共同構(gòu)成了粗排模型的優(yōu)化目標(biāo)。整個(gè)粗排模型的優(yōu)化目標(biāo),同時(shí)對(duì)真實(shí)樣本和teacher信息進(jìn)行了擬合。 右側(cè)展示的是訓(xùn)練完粗排模型后,在線上產(chǎn)出user serving,通過user serving產(chǎn)出user embedding,再與item embedding做內(nèi)積運(yùn)算,完成整個(gè)排序的過程。上述流程即實(shí)現(xiàn)了粗排和精排的聯(lián)動(dòng)過程,并且訓(xùn)練完粗排模型就可以進(jìn)行一個(gè)非常高效的serving,進(jìn)行粗排排序。業(yè)界也有相關(guān)的一些工作,上圖最下方給出了一篇阿里在這方面的論文。
實(shí)踐中,粗排模型訓(xùn)練時(shí),依賴的精排輸出結(jié)果來自上報(bào)精排日志。如果在離線重新對(duì)樣本進(jìn)行預(yù)估再輸出,其實(shí)是對(duì)線下資源的浪費(fèi),所以通常在線上精排預(yù)估時(shí),就把一些結(jié)果作為日志進(jìn)行上報(bào)。以我個(gè)人的猜測(cè),這里精排日志應(yīng)該是精排模型最后一層或倒數(shù)第二層的輸出結(jié)果,通常是logits或softmax形式的soft labels,比如是否點(diǎn)擊,那soft labels就是,表示點(diǎn)擊的概率,表示不點(diǎn)擊的概率;是否完播,那soft labels就是,表示完播的概率,表示不完播的概率。粗排模型異步訓(xùn)練,產(chǎn)出模型提供給Serving。
最后,全民K歌推薦算法團(tuán)隊(duì)給出了知識(shí)蒸餾的進(jìn)一步優(yōu)化方向:
首先,上述粗排蒸餾過程本質(zhì)上是pointwise,但通過上報(bào)精排日志可以拿到精排模型給出的完整推薦列表,用pairwise學(xué)習(xí)精排排出來的序,可以進(jìn)一步逼近精排結(jié)果,能更多的提取精排傳遞出的信息。 其次,前面雖然不斷地用teacher模型和student模型描述整個(gè)過程,但實(shí)際效果上student模型不一定低于teacher模型。換一個(gè)角度,student模型其實(shí)是基于teacher模型做進(jìn)一步訓(xùn)練,所以student模型的表征能力有可能超過teacher模型。事實(shí)上,如何讓student模型通過反復(fù)的蒸餾,效果超過teacher模型,在模型蒸餾領(lǐng)域也有許多相關(guān)方法。
【相關(guān)文章】
騰訊音樂:全民K歌推薦系統(tǒng)架構(gòu)及粗排設(shè)計(jì),地址:https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA
3.2.2 愛奇藝短視頻推薦之粗排模型蒸餾優(yōu)化
這是一個(gè)將“目標(biāo)蒸餾-logits方法“應(yīng)用到推薦系統(tǒng)領(lǐng)域的實(shí)踐。 粗排模型發(fā)揮的主要作用是統(tǒng)一計(jì)算和過濾召回結(jié)果,在盡量保證推薦準(zhǔn)確性的前提下減輕精排模型的計(jì)算壓力。這里主要介紹愛奇藝隨刻基礎(chǔ)推薦團(tuán)隊(duì)在短視頻推薦業(yè)務(wù)的粗排模型優(yōu)化上通過知識(shí)蒸餾技術(shù)提升鏈路目標(biāo)的一致性。
愛奇藝團(tuán)隊(duì)也是選擇了目前主流的雙塔DNN模型作為粗排模型。用戶側(cè)和Item側(cè)分別構(gòu)建三層全聯(lián)接DNN模型,最后分別輸出一個(gè)多維(512)的embedding向量,作為用戶側(cè)和視頻側(cè)的低維表征。粗排雙塔DNN模型如下圖所示:
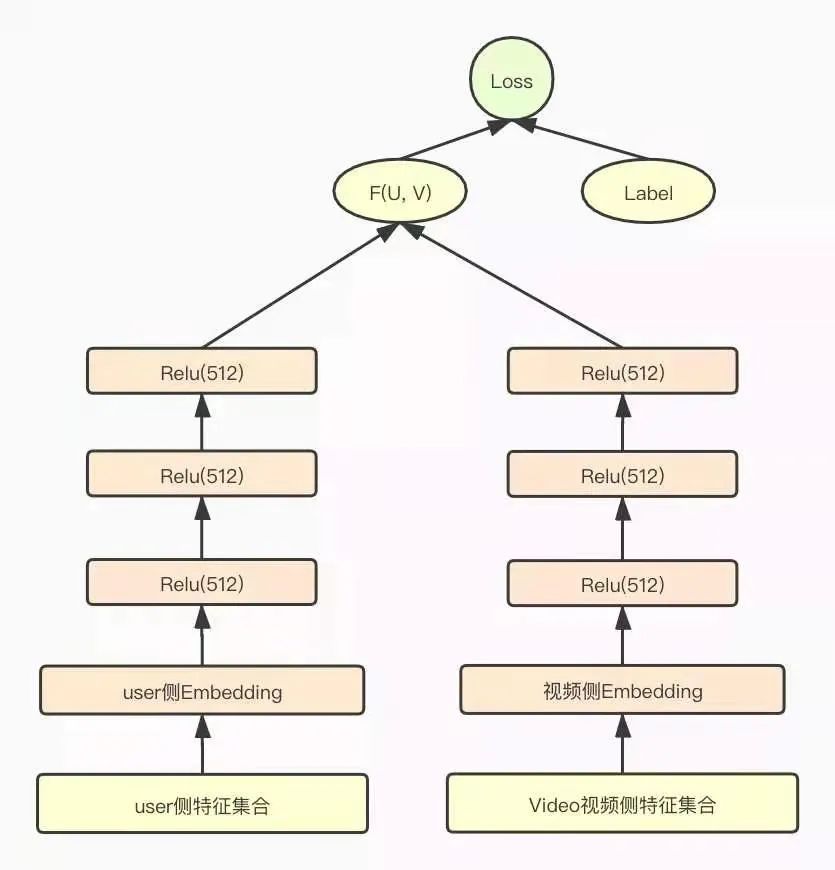
在構(gòu)建粗排模型特征集合時(shí),為了控制粗排模型參數(shù)的復(fù)雜度,他們對(duì)粗排的特征集合做了大量的裁剪,用戶側(cè)和視頻側(cè)都只采用了少部分精排模型的特征子集。
其中,用戶側(cè)特征主要選取了下面幾維特征:
用戶基礎(chǔ)畫像特征、上下文特征如手機(jī)系統(tǒng)、型號(hào)、地域等; 用戶的歷史行為特征,如用戶觀看的視頻ID、up主ID,以及觀看視頻的關(guān)鍵詞tag等,以及用戶session內(nèi)的行為特征等。
視頻側(cè)特征只保留了三維:視頻ID、 up主ID、視頻標(biāo)簽。
這里,我插入一些自己的想法。如果粗排模型是雙塔DNN模型,精排模型為wide&deep模型,那么對(duì)粗排模型和精排模型的預(yù)估結(jié)果做詳細(xì)的統(tǒng)計(jì)和分析,就會(huì)發(fā)現(xiàn)粗排模型預(yù)估為Top-K的頭部視頻和精排模型預(yù)估的頭部視頻有很大的差異。這也是目前工業(yè)界大多數(shù)推薦系統(tǒng)的弊端,歸咎原因主要是以下兩方面的原因:
特征集合的差異: 粗排層到精排層相當(dāng)于是一個(gè)承上啟下的作用,它會(huì)把我們召回到的一些萬(wàn)量級(jí)的視頻進(jìn)一步篩選到千量級(jí),既要考慮打分的性能問題,又要考慮粗排精準(zhǔn)度的問題。因此,粗排模型的特征只會(huì)采用少部分精排模型的特征子集。 模型結(jié)構(gòu)的差異: 雙塔DNN模型和精排模型(wide&deep、MMoE等模型)的優(yōu)化和擬合數(shù)據(jù)時(shí)的側(cè)重點(diǎn)還是有很大的差異的。
綜合以上分析,為了盡量彌補(bǔ)粗排模型和精排模型的Gap,縮小粗排模型和精排模型預(yù)估結(jié)果的差異性;為了彌補(bǔ)特征裁剪帶來的損失,保證裁剪后粗排模型的精度;且粗排從GBDT升級(jí)為雙塔DNN模型,使得復(fù)雜度和參數(shù)量級(jí)有了爆炸性增長(zhǎng),為了不損失粗排模型的精度同時(shí)滿足上線的性能指標(biāo)要求,我們?cè)谟?xùn)練粗排模型時(shí),采用了模型壓縮常用的方法-知識(shí)蒸餾來訓(xùn)練粗排模型。
知識(shí)蒸餾是一種模型壓縮常見方法,在teacher-student框架中,將復(fù)雜、學(xué)習(xí)能力強(qiáng)的網(wǎng)絡(luò)學(xué)到的特征表示“知識(shí)蒸餾”出來,傳遞給參數(shù)量小、學(xué)習(xí)能力弱的網(wǎng)絡(luò)。從而我們會(huì)得到一個(gè)速度快,能力強(qiáng)的網(wǎng)絡(luò)。將粗排模型和精排模型放到知識(shí)蒸餾的teacher-student框架中,以蒸餾訓(xùn)練的方式來訓(xùn)練粗排模型,以精排模型為teacher來指導(dǎo)粗排模型的訓(xùn)練,從而得到一個(gè)結(jié)構(gòu)簡(jiǎn)單,參數(shù)量小,但表達(dá)力不弱的粗排模型,蒸餾訓(xùn)練示意圖如下圖所示:
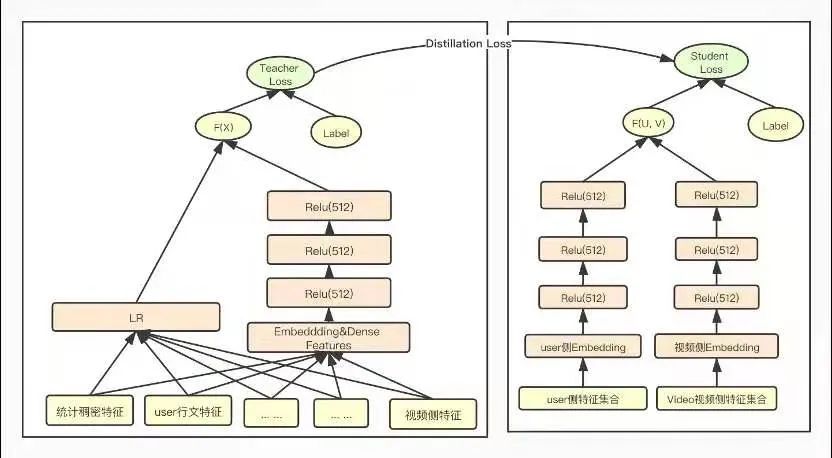
在蒸餾訓(xùn)練的過程中,為了使粗排模型輸出的logits和精排模型輸出的logits分布盡量對(duì)齊,訓(xùn)練優(yōu)化的目標(biāo)從原來單一的粗排模型的logloss調(diào)整為如下式所示的三部分loss的加和,包括student loss(粗排模型loss)、蒸餾loss 和teacher loss(精排模型loss)三部分組成。
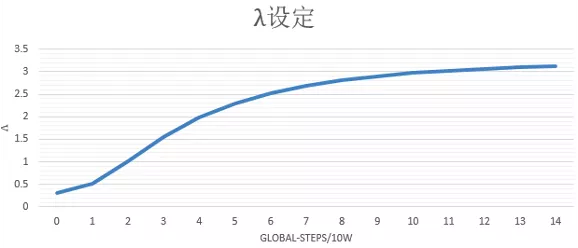
其中蒸餾loss,我們線上采用的是粗排模型輸出和精排模型輸出的最小平方誤差,為了調(diào)節(jié)蒸餾loss的影響,我們?cè)谠擁?xiàng)loss前又加了一維超參lamda,我們?cè)O(shè)置超參lamda隨著訓(xùn)練步數(shù)迭代逐漸增大,增強(qiáng)蒸餾loss的影響,在訓(xùn)練后期使得粗排模型預(yù)估值盡量向精排模型對(duì)齊,lamda隨著訓(xùn)練step的變化趨勢(shì)如下圖所示:
【相關(guān)文章】
如何提升鏈路目標(biāo)一致性?愛奇藝短視頻推薦之粗排模型優(yōu)化歷程,地址:https://mp.weixin.qq.com/s/LZlskUK4dmOd5fLTZIATnQ
4. 總結(jié)
從整個(gè)推薦系統(tǒng)的工作流程和業(yè)界的實(shí)踐來看,在精排和粗排中,知識(shí)蒸餾的效果已經(jīng)得到了驗(yàn)證。但是在召回中,還鮮有提及。如何打破推薦不同環(huán)節(jié)之間的信息壁壘,提升推薦系統(tǒng)的整個(gè)鏈路目標(biāo)一致性,知識(shí)蒸餾在這方面是有價(jià)值的。
時(shí)間已經(jīng)來到了2021年,推薦系統(tǒng)中的模型知識(shí)蒸餾技術(shù),已經(jīng)得到了工業(yè)界的廣泛使用。但是,在互聯(lián)網(wǎng)的浪潮下,深度學(xué)在CTR預(yù)估問題上又有了許多新的發(fā)展,比如使用新的特征交互方式、CTR模型統(tǒng)一的benchmark、用戶行為序列建模和用戶的多興趣建模、多任務(wù)學(xué)習(xí)、CTR模型的增量訓(xùn)練、CTR模型debias、多模態(tài)學(xué)習(xí)與對(duì)抗、跨域遷移CTR建模、隱式反饋數(shù)據(jù)建模、NAS在CTR上應(yīng)用等。在推薦領(lǐng)域中,這些新的技術(shù)和方向?qū)映霾桓F,我們需要及時(shí)的follow業(yè)界前沿知識(shí),才能不斷的成長(zhǎng),變得更強(qiáng)~
5. Reference
【1】推薦系統(tǒng)技術(shù)演進(jìn)趨勢(shì):從召回到排序再到重排 - 張俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/100019681
【2】知識(shí)蒸餾在推薦系統(tǒng)的應(yīng)用 - 張俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/143155437
【3】知識(shí)蒸餾與推薦系統(tǒng) - 涼爽的安迪的文章 - 知乎 https://zhuanlan.zhihu.com/p/163477538
【4】火箭發(fā)射:阿里巴巴的輕量網(wǎng)絡(luò)訓(xùn)練方法,地址:https://github.com/Captain1986/CaptainBlackboard/blob/master/D%230034-%E7%81%AB%E7%AE%AD%E5%8F%91%E5%B0%84%EF%BC%9A%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E7%9A%84%E8%BD%BB%E9%87%8F%E7%BD%91%E7%BB%9C%E8%AE%AD%E7%BB%83%E6%96%B9%E6%B3%95/D%230034.md
【5】火箭發(fā)射:點(diǎn)擊率預(yù)估界的“神算子”是如何煉成的?,地址:https://mp.weixin.qq.com/s/_qZNxBDUwXZVj4hGpV6ilA
【6】KDD 2020 | 優(yōu)勢(shì)特征蒸餾在淘寶推薦中的應(yīng)用,地址:https://mp.weixin.qq.com/s/3zpri6pfVtp-3-5_004B1Q
【7】RS Meet DL(62)-[阿里]電商推薦中的特殊特征蒸餾,地址:https://mp.weixin.qq.com/s/W309FtLGTjj6y1hFwdueHQ
【8】?jī)?yōu)勢(shì)特征蒸餾(Privileged Features Distillation)在手淘信息流推薦中的應(yīng)用 | KDD論文解讀,地址:https://developer.aliyun.com/article/768970
【9】推薦系統(tǒng)遇上深度學(xué)習(xí)(九十九)-[華為]多教師網(wǎng)絡(luò)知識(shí)蒸餾來提升點(diǎn)擊率預(yù)估效果,地址:https://mp.weixin.qq.com/s/09O4Izf8_752db45FJ3znQ
【10】AI筑巢:機(jī)器學(xué)習(xí)在百度鳳巢的深度應(yīng)用。https://myslide.cn/slides/763
【11】雙DNN排序模型:在線知識(shí)蒸餾在愛奇藝推薦的實(shí)踐,地址:https://mp.weixin.qq.com/s/ZNjC30F28uX2lBkHBAAU3g
【12】騰訊音樂:全民K歌推薦系統(tǒng)架構(gòu)及粗排設(shè)計(jì),地址:https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA
【13】如何提升鏈路目標(biāo)一致性?愛奇藝短視頻推薦之粗排模型優(yōu)化歷程,地址:https://mp.weixin.qq.com/s/LZlskUK4dmOd5fLTZIATnQ
【14】筆記︱模型壓縮:knowledge distillation知識(shí)蒸餾(一),地址:https://mp.weixin.qq.com/s/u82_7jYvfHXQaGMM_UQFBw
【15】2020年精排模型調(diào)研 - Ruhjkg的文章 - 知乎 https://zhuanlan.zhihu.com/p/335781101
【16】DSSM在召回和粗排的應(yīng)用舉例 - arachis的文章 - 知乎 https://zhuanlan.zhihu.com/p/350206643
【17】Instagram 推薦系統(tǒng):每秒預(yù)測(cè) 9000 萬(wàn)個(gè)模型是怎么做到的?地址:https://mp.weixin.qq.com/s/xJ9DNxamcYAQEzaYkoSNwA
往期精彩回顧
適合初學(xué)者入門人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請(qǐng)掃碼