
遷移學(xué)習(xí)理論與實踐
點擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
來源:機器學(xué)習(xí)實驗室
? ? ?在深度學(xué)習(xí)模型日益龐大的今天,并非所有人都能滿足從頭開始訓(xùn)練一個模型的軟硬件條件,稀缺的數(shù)據(jù)和昂貴的計算資源都是我們需要面對的難題。遷移學(xué)習(xí)(Transfer Learning)可以幫助我們緩解在數(shù)據(jù)和計算資源上的尷尬。作為當(dāng)前深度學(xué)習(xí)領(lǐng)域中最重要的方法論之一,遷移學(xué)習(xí)有著自己自身的理論依據(jù)和實際效果驗證。
? ?
遷移學(xué)習(xí):深度學(xué)習(xí)未來五年的驅(qū)動力?
? ? ?作為一門實驗性學(xué)科,深度學(xué)習(xí)通常需要反復(fù)的實驗和結(jié)果論證。在現(xiàn)在和將來,是否有海量的數(shù)據(jù)資源和強大的計算資源,這是決定學(xué)界和業(yè)界深度學(xué)習(xí)和人工智能發(fā)展的關(guān)鍵因素。通常情況下,獲取海量的數(shù)據(jù)資源對于企業(yè)而言并非易事,尤其是對于像醫(yī)療等特定領(lǐng)域,要想做一個基于深度學(xué)習(xí)的醫(yī)學(xué)影像的輔助診斷系統(tǒng),大量且高質(zhì)量的打標(biāo)數(shù)據(jù)非常關(guān)鍵。但通常而言,不要說高質(zhì)量,就是想獲取大量的醫(yī)療數(shù)據(jù)就已困難重重。

圖9.1 吳恩達(dá)說遷移學(xué)習(xí)
? ? ?那怎么辦呢?是不是獲取不了海量的數(shù)據(jù)研究就一定進(jìn)行不下去了?當(dāng)然不是。因為我們有遷移學(xué)習(xí)。那究竟什么是遷移學(xué)習(xí)?顧名思義,遷移學(xué)習(xí)就是利用數(shù)據(jù)、任務(wù)或模型之間的相似性,將在舊的領(lǐng)域?qū)W習(xí)過或訓(xùn)練好的模型,應(yīng)用于新的領(lǐng)域這樣的一個過程。從這段定義里面,我們可以窺見遷移學(xué)習(xí)的關(guān)鍵點所在,即新的任務(wù)與舊的任務(wù)在數(shù)據(jù)、任務(wù)和模型之間的相似性。
? ? ?在很多沒有充分?jǐn)?shù)據(jù)量的特定應(yīng)用上,遷移學(xué)習(xí)會是一個極佳的研究方向。正如圖9.1中吳恩達(dá)所說,遷移學(xué)習(xí)會是機器學(xué)習(xí)在未來五年內(nèi)的下一個驅(qū)動力量。
遷移學(xué)習(xí)的使用場景
? ? ?遷移學(xué)習(xí)到底在什么情況下使用呢?是不是我模型訓(xùn)練不好就可以用遷移學(xué)習(xí)進(jìn)行改進(jìn)?當(dāng)然不是。如前文所言,使用遷移學(xué)習(xí)的主要原因在于數(shù)據(jù)資源的可獲得性和訓(xùn)練任務(wù)的成本。當(dāng)我們有海量的數(shù)據(jù)資源時,自然不需要遷移學(xué)習(xí),機器學(xué)習(xí)系統(tǒng)很容易從海量數(shù)據(jù)中學(xué)習(xí)到一個很穩(wěn)健的模型。但通常情況下,我們需要研究的領(lǐng)域可獲得的數(shù)據(jù)極為有限,僅靠有限的數(shù)據(jù)量進(jìn)行學(xué)習(xí),所習(xí)得的模型必然是不穩(wěn)健、效果差的,通常情況下很容易造成過擬合,在少量的訓(xùn)練樣本上精度極高,但是泛化效果極差。另一個原因在于訓(xùn)練成本,即所依賴的計算資源和耗費的訓(xùn)練時間。通常情況下,很少有人從頭開始訓(xùn)練一整個深度卷積網(wǎng)絡(luò),一個是上面提到的數(shù)據(jù)量的問題,另一個就是時間成本和計算資源的問題,從頭開始訓(xùn)練一個卷積網(wǎng)絡(luò)通常需要較長時間且依賴于強大的GPU計算資源,對于一門實驗性極強的領(lǐng)域而言,花費好幾天乃至一周的時間去訓(xùn)練一個深度神經(jīng)網(wǎng)絡(luò)通常是代價巨大的。
? ? ?所以,遷移學(xué)習(xí)的使用場景如下:假設(shè)有兩個任務(wù)系統(tǒng)A和B,任務(wù)A擁有海量的數(shù)據(jù)資源且已訓(xùn)練好,但并不是我們的目標(biāo)任務(wù),任務(wù)B是我們的目標(biāo)任務(wù),但數(shù)據(jù)量少且極為珍貴,這種場景便是典型的遷移學(xué)習(xí)的應(yīng)用場景。那究竟什么時候使用遷移學(xué)習(xí)是有效的呢?對此我們不敢武斷地下結(jié)論。但必須如前文所言,新的任務(wù)系統(tǒng)和舊的任務(wù)系統(tǒng)必須在數(shù)據(jù)、任務(wù)和模型等方面存在一定的相似性,你將一個訓(xùn)練好的語音識別系統(tǒng)遷移到放射科的圖像識別系統(tǒng)上,恐怕結(jié)果不會太妙。所以,要判斷一個遷移學(xué)習(xí)應(yīng)用是否有效,最基本的原則還是要遵守,即任務(wù)A和任務(wù)B在輸入上有一定的相似性,即兩個任務(wù)的輸入屬于同一性質(zhì),要么同是圖像、要么同是語音或其他,這便是前文所說到的任務(wù)系統(tǒng)的相似性的含義之一。
深度卷積網(wǎng)絡(luò)的可遷移性
? ? ?還有一個值得探討的問題在于,深度卷積網(wǎng)絡(luò)的可遷移性在于什么?為什么說兩個任務(wù)具有同等性質(zhì)的輸入舊具備可遷移性?一切都還得從卷積神經(jīng)網(wǎng)絡(luò)的基本原理說起。由之前的學(xué)習(xí)我們知道,卷積神經(jīng)網(wǎng)絡(luò)具備良好的層次結(jié)構(gòu),通常而言,普通的卷積神經(jīng)網(wǎng)絡(luò)都具備卷積-池化-卷積-池化-全連接這樣的層次結(jié)構(gòu),在深度可觀時,卷積神經(jīng)網(wǎng)絡(luò)可以提取圖像各個level的特征。如圖9.2所示,當(dāng)我們要從圖像中識別一張人臉的時候,通常在一開始我們會檢測到圖像的橫的、豎的等邊緣特征,然后會檢測到臉部的一些曲線特征,再進(jìn)一步會檢測到臉部的鼻子、眼睛和嘴巴等具備明顯識別要素的特征。

圖9.2 CNN人臉特征的逐層提取
? ? ?這便揭示了深度卷積網(wǎng)絡(luò)可遷移性的基本原理和卷積網(wǎng)絡(luò)訓(xùn)練過程的基本事實。具備良好層次的深度卷積網(wǎng)絡(luò)通常都是在最初的前幾層學(xué)習(xí)到圖像的通用特征(General Feature),但隨著網(wǎng)絡(luò)層次的加深,卷積網(wǎng)絡(luò)便逐漸開始檢測到圖像的特定的特征,兩個任務(wù)系統(tǒng)的輸入越相近,深度卷積網(wǎng)絡(luò)檢測到的通用特征越多,遷移學(xué)習(xí)的效果越好。
遷移學(xué)習(xí)的使用方法
? ? ?通常而言,遷移學(xué)習(xí)有兩種使用方式。第一種便是常說的Finetune,即微調(diào),簡單而言就是將別人訓(xùn)練好的網(wǎng)絡(luò)拿來進(jìn)行簡單修改用于自己的學(xué)習(xí)任務(wù)。在實際操作中,通常用預(yù)訓(xùn)練的網(wǎng)絡(luò)權(quán)值對自己網(wǎng)絡(luò)的權(quán)值進(jìn)行初始化,以代替原先的隨機初始化。第二種稱為 Fixed Feature Extractor,即將預(yù)訓(xùn)練的網(wǎng)絡(luò)作為新任務(wù)的特征提取器,在實際操作中通常將網(wǎng)絡(luò)的前幾層進(jìn)行凍結(jié),只訓(xùn)練最后的全連接層,這時候預(yù)訓(xùn)練網(wǎng)絡(luò)便是一個特征提取器。
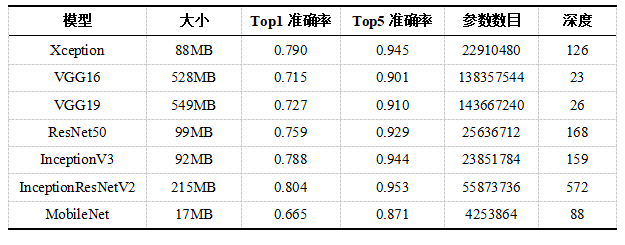
? ? ?Keras為我們提供了經(jīng)典網(wǎng)絡(luò)在ImageNet上為我們訓(xùn)練好的預(yù)訓(xùn)練模型,預(yù)訓(xùn)練模型的基本信息如表1所示。
表1?Keras主要預(yù)訓(xùn)練模型
? ? ?以上是遷移學(xué)習(xí)的基本理論和方法簡介,下面來看一個簡單的示例,來看看遷移學(xué)習(xí)的實際使用方法。
基于ResNet的遷移學(xué)習(xí)實驗
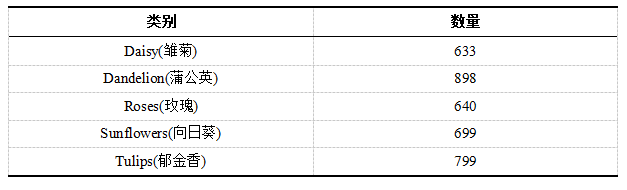
? ? ?我們以一組包含五種類別花朵數(shù)據(jù)為例,使用ResNet50預(yù)訓(xùn)練模型進(jìn)行遷移學(xué)習(xí)嘗試。數(shù)據(jù)地址為https://www.kaggle.com/fleanend/flowers-classification-with-transfer-learning/#data。下載數(shù)據(jù)后解壓可見共有5個文件夾,每個文件夾是一種花類,具體信息如下表2所示。
? ? ?5種花型加起來不過是3669張圖片,數(shù)據(jù)量不算小樣本但也絕對算不上多。所以我們采取遷移學(xué)習(xí)的策略來搭建花朵識別系統(tǒng)。花型圖片大致如圖所示。
圖 flowers數(shù)據(jù)集示例
需要導(dǎo)入的package,如代碼9.1所示。
# 導(dǎo)入相關(guān)模塊import osimport pandas as pdimport numpy as npimport cv2import matplotlib.pyplot as pltfrom PIL import Imagefrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitimport kerasfrom keras.models import Modelfrom keras.layers import Dense, Activation, Flatten, Dropoutfrom keras.utils import np_utilsfrom keras.applications.resnet50 import ResNet50from?tqdm?import?tqdm
提取數(shù)據(jù)標(biāo)簽
數(shù)據(jù)沒有單獨給出標(biāo)簽文件,需要我們自行通過文件夾提取每張圖片的標(biāo)簽,建立標(biāo)簽csv文件,如代碼所示。
def generate_csv(path):labels = pd.DataFrame()# 目錄下每一類別文件夾items = [f for f in os.listdir(path)]# 遍歷每一類別文件夾for i in tqdm(items):# 生成圖片完整路徑images = [path + I + '/' + img for img in os.listdir(path+i)]# 生成兩列:圖像路徑和對應(yīng)標(biāo)簽labels_data = pd.DataFrame({'images': images, ‘labels’: i})# 逐條記錄合并labels = pd.concat((labels, labels_data))# 打亂順序labels = labels.sample(frac=1, random_state=42)return labels# 生成標(biāo)簽并查看前5行labels = generate_csv('./flowers/')labels.head()
標(biāo)簽提取結(jié)果示例如圖9.4所示。

圖9.4 提取標(biāo)簽結(jié)果
圖片預(yù)處理
通過試驗可知每張圖片像素大小并不一致,所以在搭建模型之前,我們需要對圖片進(jìn)行整體縮放為統(tǒng)一尺寸。我們借助opencv的Python庫cv2可以輕松實現(xiàn)圖片縮放,因為后面我們的遷移學(xué)習(xí)策略采用的是ResNet50作為預(yù)訓(xùn)練模型,所以我們這里將圖片縮放大小為 224*224*3。單張圖片的resize示例如下。圖9.5所示是一張玫瑰的原圖展示。

圖9.5 縮放前的原圖
縮放如代碼所示。縮放后的效果和尺寸如圖9.6所示。
# resize縮放img = cv2.resize(img, (224, 224))# 轉(zhuǎn)換成RGB色彩顯示img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.xticks([])plt.yticks([])

圖9.6 縮放后的效果
批量讀取縮放如代碼所示。
# 定義批量讀取并縮放def read_images(df, resize_dim):total = 0images_array = []# 遍歷標(biāo)簽文件中的圖像路徑for i in tqdm(df.images):# 讀取并resizeimg = cv2.imread(i)img_resized = cv2.resize(img, resize_dim)total += 1# 存入圖像數(shù)組中images_array.append(img_resized)'iamges have resized.')return images_array# 批量讀取images_array = read_images(labels, (224, 224))
原始圖片并不復(fù)雜,所以除了對其進(jìn)行縮放處理之外基本無需多做處理。下一步我們需要準(zhǔn)備訓(xùn)練和驗證數(shù)據(jù)。
準(zhǔn)備數(shù)據(jù)
處理好的圖片無法直接拿來訓(xùn)練,我們需要將其轉(zhuǎn)化為Numpy數(shù)組的形式,另外,標(biāo)簽也需要進(jìn)一步的處理,如代碼所示。
# 轉(zhuǎn)化為圖像數(shù)組X = np.array(images_array)# 標(biāo)簽編碼lbl = LabelEncoder().fit(list(labels['labels'].values))labels['code_labels']=pd.DataFrame(lbl.transform(list(labels['labels'].values)))# 分類標(biāo)簽轉(zhuǎn)換y = np_utils.to_categorical(labels.code_labels.values, 5)
轉(zhuǎn)化后的圖像數(shù)組大小為 3669*224*224*3,標(biāo)簽維度為3669*5,跟我們的實際數(shù)據(jù)一致。數(shù)據(jù)的準(zhǔn)備好后,可以用Sklearn劃分一下數(shù)據(jù)集:
# 劃分為訓(xùn)練和驗證集X_train, X_valid, y_train, y_valid =train_test_split(X,y,test_size=0.2, random_state=42)
然后可以用Keras的ImageDataGenerator模塊來按批次生成訓(xùn)練數(shù)據(jù),并對訓(xùn)練集做一些簡單的數(shù)據(jù)增強,如下代碼所示。
# 訓(xùn)練集生成器,中間做一些數(shù)據(jù)增強train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.4,height_shift_range=0.4,shear_range=0.2,zoom_range=0.3,horizontal_flip=True)# 驗證集生成器,無需做數(shù)據(jù)增強val_datagen = ImageDataGenerator(rescale=1./255)# 按批次導(dǎo)入訓(xùn)練數(shù)據(jù)train_generator = train_datagen.flow(X_train,y_train,batch_size=32)# 按批次導(dǎo)入驗證數(shù)據(jù)val_generator = val_datagen.flow(X_valid,y_valid,batch_size=32)
訓(xùn)練和驗證數(shù)據(jù)劃分完畢,現(xiàn)在我們可以利用遷移學(xué)習(xí)模型進(jìn)行訓(xùn)練了。
基于resnet50的遷移學(xué)習(xí)模型
試驗?zāi)P偷幕静呗跃褪鞘褂妙A(yù)訓(xùn)練模型的權(quán)重作為特征提取器,將預(yù)訓(xùn)練的權(quán)重進(jìn)行凍結(jié),只訓(xùn)練全連接層。構(gòu)建模型如下代碼所示。
# 定義模型構(gòu)建函數(shù)def flower_model():base_model=ResNet50(include_top=False,weights='imagenet', input_shape=(224, 224, 3))# 凍結(jié)base_model的層,不參與訓(xùn)練for layers in base_model.layers:layers.trainable = False# base_model的輸出并展平model = Flatten()(base_model.output)# 添加批歸一化層model = BatchNormalization()(model)# 全連接層model=Dense(2048,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批歸一化層model = BatchNormalization()(model)# 全連接層model=Dense(1024,activation='relu', kernel_initializer=he_normal(seed=42))(model)# 添加批歸一化層model = BatchNormalization()(model)# 全連接層并指定分類數(shù)和softmax激活函數(shù)model = Dense(5, activation='softmax')(model)model = Model(inputs=base_model.input, outputs=model)# 指定損失函數(shù)、優(yōu)化器、性能度量標(biāo)準(zhǔn)并編譯model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model
最后執(zhí)行訓(xùn)練:
# 調(diào)用模型model = flower_model()# 使用fit_generator方法執(zhí)行訓(xùn)練flower_model.fit_generator(generator=train_generator,steps_per_epoch=len(train_data)/32,epochs=30,validation_steps=len(val_data)/32,validation_data=val_generator,verbose=2)
訓(xùn)練過程如圖9.7所示。

圖9.7 遷移學(xué)習(xí)訓(xùn)練過程
經(jīng)過20個epoch訓(xùn)練之后,驗證集準(zhǔn)確率會達(dá)到90%以上,讀者朋友們可自行嘗試一些模型改進(jìn)方案來達(dá)到更高的精度。各位讀者可以嘗試分別使用VGG16、Inception v3和Xception來測試本講的花朵識別實驗。

下載1:OpenCV黑魔法
在「AI算法與圖像處理」公眾號后臺回復(fù):OpenCV黑魔法,即可下載小編精心編寫整理的計算機視覺趣味實戰(zhàn)教程
下載2 CVPR2020 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR2020,即可下載1467篇CVPR?2020論文 個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱

覺得有趣就點亮在看吧
