
6000字!SQL窗口函數(shù)詳解。
今天想重提窗口函數(shù)。原因是前幾天在群里提起了這個名字,忘了是什么緣由提起的,但令我吃驚的是,竟還有同學(xué)想從事數(shù)據(jù)分析卻不知道窗口函數(shù)!那感覺就仿佛用勺子吃面條不知道有筷子這種好東西一樣。
他問:“有沒有大佬簡單說下窗口函數(shù)是個什么東西?”
胖里:不減少原表行數(shù)情況下,對數(shù)據(jù)進(jìn)行分組排序。
阿鑫:在SQL中窗口函數(shù)可以對數(shù)據(jù)進(jìn)行同步處理,where和group by處理后進(jìn)行操作,只能寫在select子句中。
其他:百度吧,知乎看一下。
然后我去翻了翻公眾號之前關(guān)于窗口函數(shù)的文章,我以為自己對這部分內(nèi)容已經(jīng)了解和解釋的挺清楚了,無論是用法還是實(shí)例。但我翻完才發(fā)現(xiàn),好像并沒有對窗口函數(shù)下定義,其他人的很多文章也大都沒對窗口函數(shù)的定義進(jìn)行描述,都從窗口函數(shù)有什么用,怎么用,舉例子開始。
窗口函數(shù)到底是什么呢?
01
窗口函數(shù)是什么
我拿這個問題去問交流群里的小伙伴,得到了如下一些回答。
A:處理分析的函數(shù),類似于聚合函數(shù)?
B:用于解決組內(nèi)排序、聚合等運(yùn)算且只能寫在select字句中的函數(shù)。
C:窗口函數(shù)可以切分小組,并在小組內(nèi)實(shí)現(xiàn)排序、聚合等數(shù)據(jù)處理操作。
D:窗口函數(shù)的含義就像它的名字,開一個窗子,在不影響房屋原來結(jié)構(gòu)的基礎(chǔ)上從自己想要的角度觀察內(nèi)部關(guān)系。
E:窗口函數(shù)類似于聚合函數(shù)。區(qū)別是聚合函數(shù)對每組只返回一個值,窗口函數(shù)返回多個值,也就是說對組里的每條記錄都會產(chǎn)生返回值~
每個人都講出了自己的理解,每個人理解的也都沒什么問題。在我看來,窗口函數(shù)無非就是一種略高級的操作,能劃分范圍(組),對這一范圍內(nèi)的數(shù)據(jù)進(jìn)行某種處理,可以是聚合,可以是排序、也可以是求第一個記錄、最后一個記錄等。它有其高級之處,也有用法上的某些限制。
窗口函數(shù),也稱為OLAP(Online Analytical Processing)函數(shù),之所以叫窗口函數(shù)是為了便于形成直觀印象,易于理解(雖然可能對一些同學(xué)而言,并沒有那么容易理解。)
如上便是窗口函數(shù)的定義,要想理解窗口函數(shù)從定義上是遠(yuǎn)遠(yuǎn)不夠的,最好能從窗口函數(shù)的語法及其實(shí)例來理解。
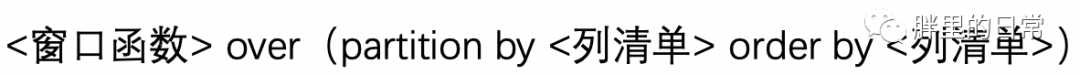
上圖便是窗口函數(shù)的語法了,你可以將其看作一種固定搭配,填充進(jìn)去不同的窗口函數(shù)、指定列,即可實(shí)現(xiàn)對應(yīng)函數(shù)能實(shí)現(xiàn)的操作。
這其中最重要的關(guān)鍵字便是partition by和order by,partition by用來圈定所要進(jìn)行操作的對象的范圍,order by用來指定按照哪列、何種順序進(jìn)行排序。通過partition by分組后的記錄集合叫做窗口,此處的窗口表示范圍,這也是窗口函數(shù)名字的由來。
但partition by并非必需,不使用partition by也可正常使用窗口函數(shù),只不過此時等于不分組,將整張表作為一個大窗口而已。
02
窗口函數(shù)的分類
說完窗口函數(shù)的語法,不妨來看看常用/常見的一些窗口函數(shù)及其分類。
下圖中羅列了三種窗口函數(shù)的分類,其實(shí)分類這種東西,都是主觀上按照某些客觀規(guī)則劃分的,劃分的人不一樣也就形成了不同或不同粒度的規(guī)則。
窗口函數(shù)可歸為兩大類,聚合類窗口函數(shù)和非聚合類窗口函數(shù)(也可稱為專用窗口函數(shù))。聚合類窗口函數(shù)是將我們常用的聚合函數(shù)作為窗口函數(shù)使用,非聚合類窗口函數(shù)指一些規(guī)定好的窗口函數(shù),按照其不同的功能進(jìn)行定義和劃分,如常見的排序函數(shù)、分布函數(shù)和偏移函數(shù)。
注意,有的窗口函數(shù)是帶參數(shù)的,有的不帶參數(shù),如sum(amt)、lead(time)、rank()、row_number()。
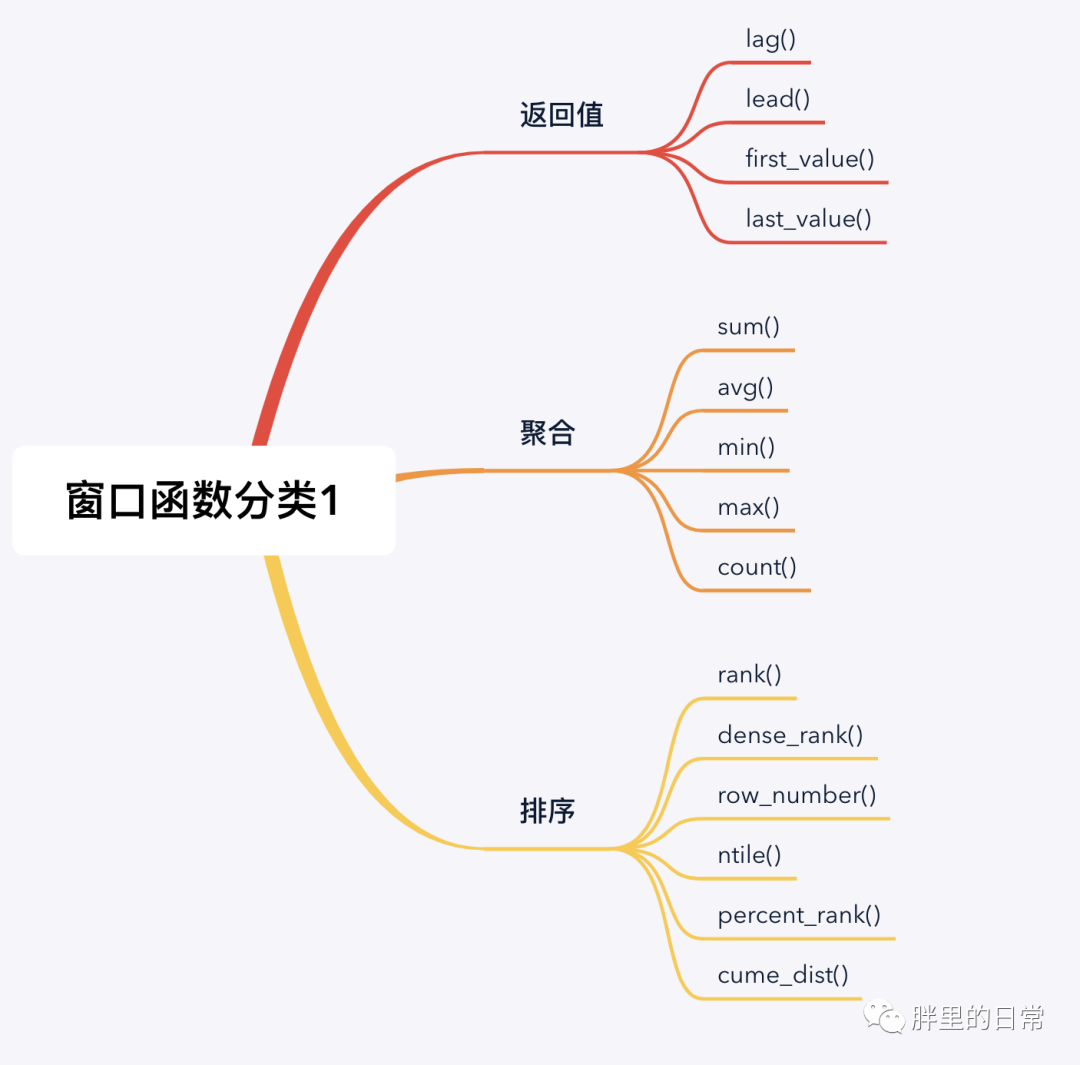
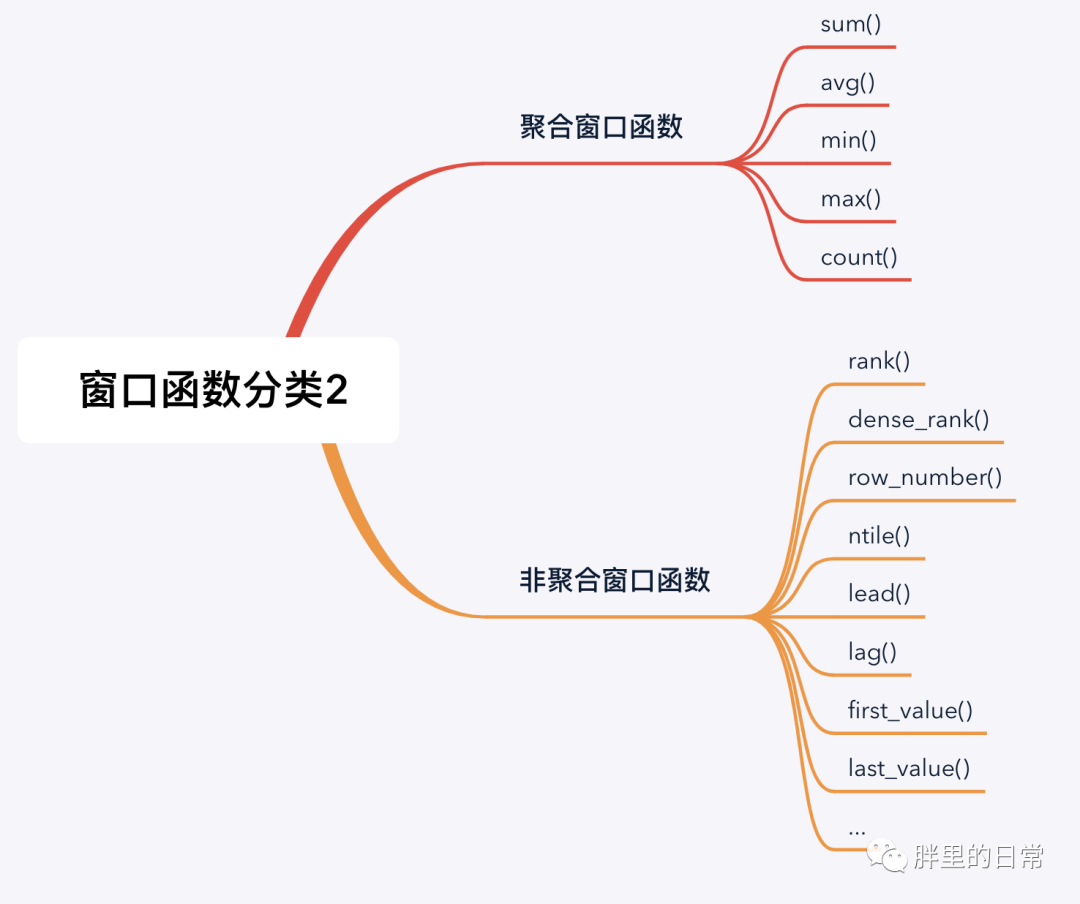
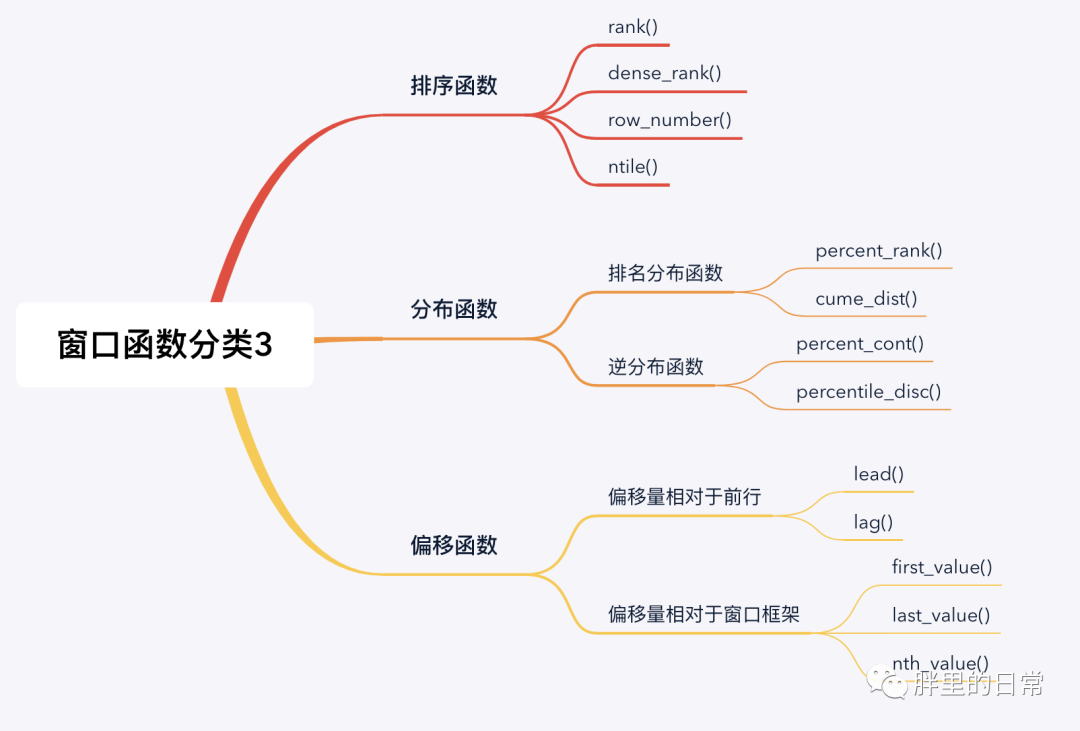
其實(shí)我們可能并不需要知道所有的窗口函數(shù),我這水平目前也只知道聚合、排序、返回值的幾個函數(shù),一些是因?yàn)槊嬖嚦?妓麄兊南嗤筒煌c(diǎn),一些是業(yè)務(wù)或筆試題中會用得到。這些函數(shù)基本懂一部分就夠用了,其他需要的可以根據(jù)需求再進(jìn)行查詢、學(xué)習(xí)和使用。
03
窗口函數(shù)的應(yīng)用
籠統(tǒng)地介紹完一些常見的窗口函數(shù),還是好好說說其中一些函數(shù)的用法吧。
先來幾個簡單的示例,初步了解下窗口函數(shù)的使用。
下表為某公司在各地區(qū)不同月份的銷售額記錄表,sales_table(虛構(gòu)數(shù)據(jù))。
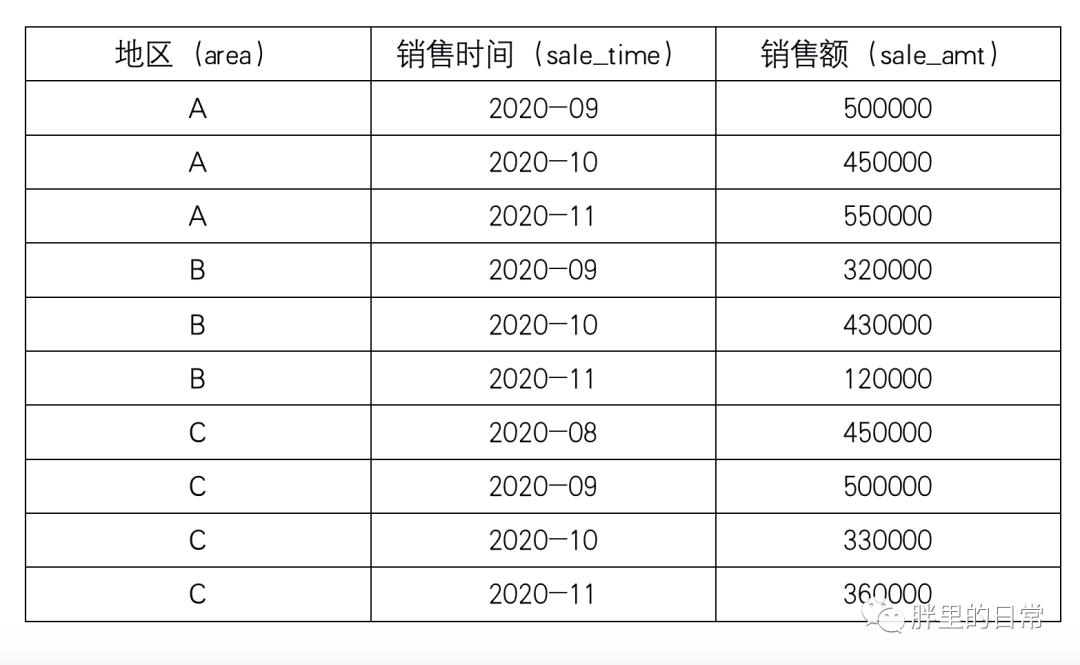
題目1:求取每個地區(qū)的銷售額(以表內(nèi)所示月份為例)
select?area,sum(sale_amt)?--?每地區(qū)總銷售額from?sales_tablegroup?by?area;
這個題目算是在學(xué)習(xí)SQL基礎(chǔ)的時候比較簡單且常見的題目了吧,毫無難度的那種,求某個分組的和,group by,sum()一下就OK了。
題目2:求每個地區(qū)每月銷售額占比,以及月累積銷售額占比
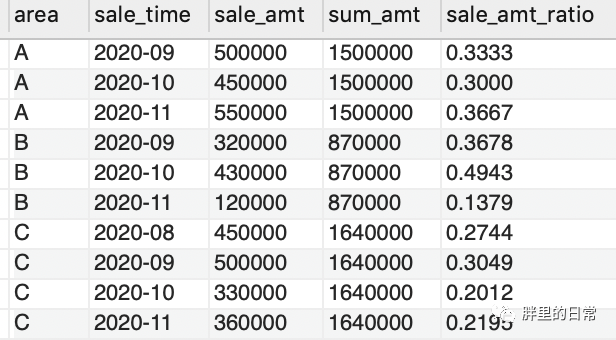
按之前分組求sum(),只能得到每個地區(qū)對應(yīng)的總銷售額,分別為1500000、870000、1640000,而每個地區(qū)每月銷售額占比就得實(shí)現(xiàn)500000/1500000,450000/1500000等操作了,此結(jié)果也可通過先求每地區(qū)的總銷售額然后表關(guān)聯(lián)進(jìn)行字段間的除法操作,不過有了窗口函數(shù),一切便變得簡單了些。
select?*,sale_amt/sum_amt?as?sale_amt_ratio?--?每地區(qū)每月銷售額占比from(??select?*,sum(sale_amt)?over(partition?by?area?order?by?area)?as?sum_amt???from?sales_table)as?t?
用sum()聚合函數(shù)作為窗口函數(shù),使用partition by area將地區(qū)作為分組,在地區(qū)內(nèi)求得每個地區(qū)的總銷售額,此處order by由于語法原因,不可缺,但由于分組后的地區(qū)只有自己本身這個地區(qū),所以此處的order by無實(shí)際意義。
結(jié)果如下所示,求得了每個地區(qū)每月銷售額占比:
那累積銷售額占比呢?還是可以用sum()聚合函數(shù)做窗口函數(shù),分組依舊是按照地區(qū)進(jìn)行分組,但累積銷售額就牽扯到時間先后了,因此要學(xué)會善用order by對日期進(jìn)行排序,才能求得真正時間順序上的累積銷售額。
select?*,agg_amt/sum_amt?as?agg_sale_amt_ratio?--?每地區(qū)月累積銷售額占比from(??select?*????,sum(sale_amt)?over(partition?by?area?order?by?sale_time)?as?agg_amt?--?每地區(qū)月累積銷售額????,sum(sale_amt)?over(partition?by?area?order?by?area)?as?sum_amt?--?每地區(qū)總銷售額??from?sales_table)as t
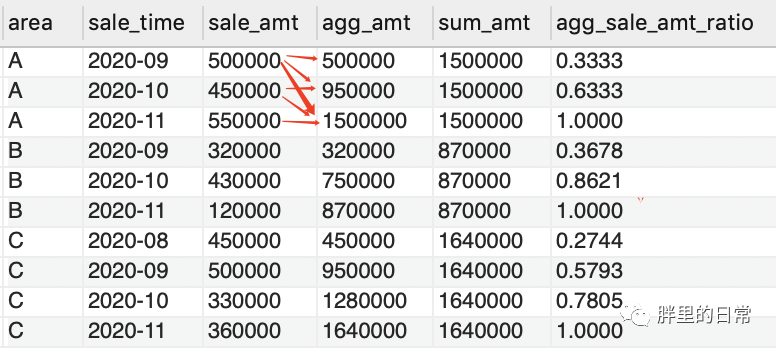
經(jīng)過上述這番操作,應(yīng)該初步認(rèn)識到窗口函數(shù)所謂的高級及實(shí)用之處了吧,無非就是將原先需要各種分別求取再join的操作,通過窗口函數(shù)的應(yīng)用在多個子查詢中實(shí)現(xiàn)。上述的兩個sum()窗口函數(shù)能同時求取,放在一個子查詢內(nèi),也就是說一個select子句中可有多個窗口函數(shù)。
注意:求累積的時候不僅可以實(shí)現(xiàn)上述的按月累積,也可實(shí)現(xiàn)限定的按前/后/前后幾個月累積,畢竟有時候有些需求是從頭到尾累積,而有的是要求前后共三個月的累積。
這時候用來在窗口中指定更加詳細(xì)匯總范圍的功能便出現(xiàn)了,此功能中的匯總范圍叫做框架,使用方法就是在order by子句后使用用來指定范圍的關(guān)鍵字following和preceding。
舉個小例子。
select?*????,sum(sale_amt)?over(partition?by?area?order?by?sale_time?rows?between?1?preceding?and?1?following)?as?agg_amt?--?當(dāng)前行及其前一行和后一行from?sales_table;select?*????,sum(sale_amt)?over(partition?by?area?order?by?sale_time?rows?1?preceding)?as?agg_amt?--?當(dāng)前行及其前一行from?sales_table;--?mysql單獨(dú)運(yùn)行following時報錯,未解,但可使用rows between 0 preceding and 1 following來替代select?*????,sum(sale_amt)?over(partition?by?area?order?by?sale_time?rows?1?following)?as?agg_amt?--?當(dāng)前行及其后一行from?sales_table;
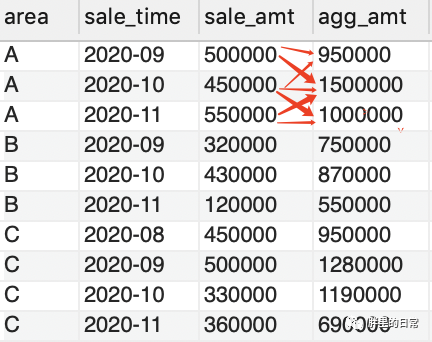
上述例子即為指定更詳細(xì)的匯總范圍了,preceding指前多少行,following指后多少行,然后再加上當(dāng)前的行,如rows between 1 preceding and 1 following 表示前一行、后一行加當(dāng)前行,共三行。
題目3:求每個地區(qū)各個月銷售額排名情況
說到排名,應(yīng)該能想到排序吧,如果沒接觸過窗口函數(shù)想要比較大小,你們都會用什么方法呢?對于排序,我首先想到的就是order by了,order by不就是用來排序的嗎?能實(shí)現(xiàn)順序排列,但只是不打標(biāo),記錄數(shù)太多可能就不知道有多少名了,除此之外我滿腦子都是各種表的關(guān)聯(lián)、對比。
不想那么復(fù)雜的話,就試試窗口函數(shù)中用于排序的函數(shù)吧。說到排序的窗口函數(shù),不少人應(yīng)該都知道rank(),dense_rank(),row_number(),除了在筆試題中考到用他們來排序,面試也常問這三者的區(qū)別是什么。
select?*,row_number()?over(partition?by?area?order?by?sale_amt?desc)?as?rnk?from?sales_table;
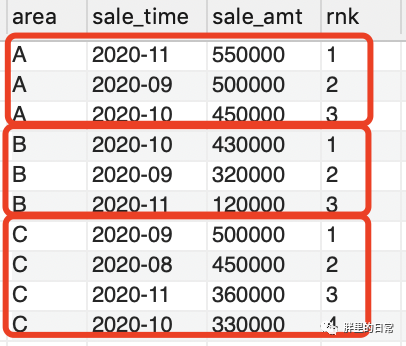
使用窗口函數(shù),輕松實(shí)現(xiàn)按地區(qū)分組,對每個月的銷售額進(jìn)行排序打標(biāo),一目了然,不僅可以排序,設(shè)想一下這種情況,你們公司的數(shù)據(jù)庫表里不僅只有這10條數(shù)據(jù),而是有成百上千甚至上萬條數(shù)據(jù),老板讓你看看每個地區(qū)銷售額最高的2個月份是哪兩個,你總不至于分別求取吧,一個排序窗口函數(shù)就能解決的問題,何樂而不為?
此處我只用了我最常用的row_number()來實(shí)現(xiàn),針對不同的排序要求,可選擇不一樣的排序函數(shù),這三種排序函數(shù)不太清楚的自己回去反思吧。
有一張表log_table,其中包括用戶id(user_id)及訪問時間(visit_time)兩個字段。
題目4:每天隨機(jī)取1000個用戶
select?user_id,visit_timefrom(??select?user_id,visit_time,row_number() over(partition by visit_time order by rand()) as rnk??from?log_table?)as twhere?rnk?<=?1000;
當(dāng)然,這個題目,不使用窗口函數(shù)依舊也可以通過order by rand()實(shí)現(xiàn)。
題目5:每天隨機(jī)取10%個用戶
select?user_id,visit_timefrom(??select?user_id,visit_time????????,percent_rank()?over(partition?by?visit_time?order?by?rand())?as?rnk_ratio??from?log_table?)as twhere rnk_ratio?<=?0.1;
當(dāng)然,這個題目也可以不用窗口函數(shù),通過計算用戶總數(shù),再隨機(jī)取用戶總數(shù)的10%。
不盡興的話,可以再來一張用戶表user_table,里面存儲了某平臺某天的活躍用戶user_id,且不重復(fù)。
題目6:將用戶隨機(jī)分成10組,每組取1000個用戶。
select?user_id?from(??select?user_id,n_rnk????????,row_number()?over(partition?by?n_rnk?order?by?rand())?as?rnkfrom(????select?user_id???????????,ntile(10)?over(order?by?rand())?as?n_rnk?????from?user_table??)as?t1?)as t2where?rnk?<=?1000;
隨機(jī)分十組,用窗口函數(shù)的ntile()可以實(shí)現(xiàn)分桶(分組功能),再使用一次排序,隨機(jī)從每組中選出1000個用戶。
題目7:將用戶隨機(jī)分成100組,每組取10%個用戶
這個題目的答案就顯而易見了吧。
上述幾個簡單的示例是為了說明窗口函數(shù)的用法及其意義所在,使用窗口函數(shù)可能會使解決問題的過程變得更簡單,對窗口函數(shù)的熟悉和理解可以幫助我們在之后遇到問題的時候,雖然是取數(shù),但可以更有針對性、更高效地取數(shù)。
除上述一些簡單示例外,筆面試中常考的需要用窗口函數(shù)解決的問題一般包括topn問題、連續(xù)登錄問題。這兩種題目面試中問到的頻率特別高,前幾天群里有個小伙伴就說被問到了,但一時想不出如何解。
想來還是對窗口函數(shù)不熟悉吧,哪一類的問題涉及到什么關(guān)鍵字,應(yīng)該用哪種函數(shù)解決,這些雖然在各種文章中頻被提及,但你如何理解,是否真正理解且能應(yīng)用,就是個人的問題了。
這些題目我就不多提了,之前轉(zhuǎn)的寶器的這篇文章中早就講過一遍了,文章在這:解一下TMD幾道熱門數(shù)據(jù)分析面試題。

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」