深度學(xué)習(xí)中的知識蒸餾技術(shù)
本文概覽:
1. 知識蒸餾介紹
1.1 什么是知識蒸餾?
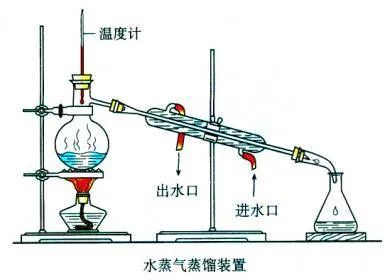
在化學(xué)中,蒸餾是一種有效的分離不同沸點(diǎn)組分的方法,大致步驟是先升溫使低沸點(diǎn)的組分汽化,然后降溫冷凝,達(dá)到分離出目標(biāo)物質(zhì)的目的。化學(xué)蒸餾條件:(1)蒸餾的液體是混合物;(2)各組分沸點(diǎn)不同。
蒸餾的液體是混合物,這個(gè)混合物一定是包含了各種組分,即在我們今天講的知識蒸餾中指原模型包含大量的知識。各組分沸點(diǎn)不同,蒸餾時(shí)要根據(jù)目標(biāo)物質(zhì)的沸點(diǎn)設(shè)置蒸餾溫度,即在我們今天講的知識蒸餾中也有“溫度”的概念,那這個(gè)“溫度“代表了什么,又是如何選取合適的”溫度“?這里先埋下伏筆,在文中給大家揭曉答案。
進(jìn)入我們今天正式的主題,到底什么是知識蒸餾?一般地,大模型往往是單個(gè)復(fù)雜網(wǎng)絡(luò)或者是若干網(wǎng)絡(luò)的集合,擁有良好的性能和泛化能力,而小模型因?yàn)榫W(wǎng)絡(luò)規(guī)模較小,表達(dá)能力有限。因此,可以利用大模型學(xué)習(xí)到的知識去指導(dǎo)小模型訓(xùn)練,使得小模型具有與大模型相當(dāng)?shù)男阅埽菂?shù)數(shù)量大幅降低,從而實(shí)現(xiàn)模型壓縮與加速,這就是知識蒸餾與遷移學(xué)習(xí)在模型優(yōu)化中的應(yīng)用。
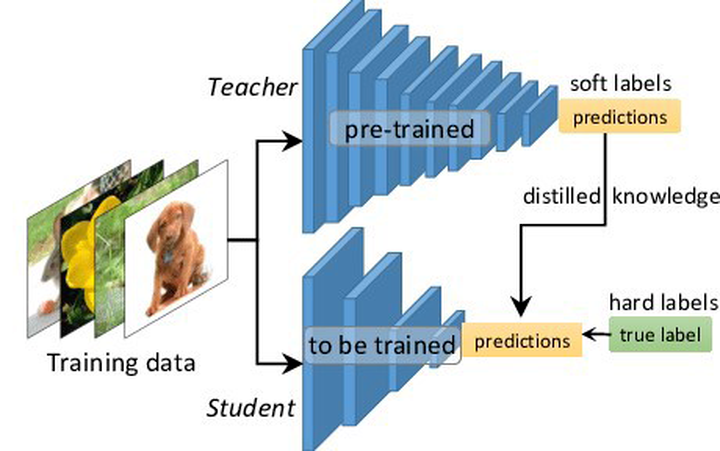
Hinton等人最早在文章《Distilling the Knowledge in a Neural Network》中提出了知識蒸餾這個(gè)概念,其核心思想是先訓(xùn)練一個(gè)復(fù)雜網(wǎng)絡(luò)模型,然后使用這個(gè)復(fù)雜網(wǎng)絡(luò)的輸出和數(shù)據(jù)的真實(shí)標(biāo)簽去訓(xùn)練一個(gè)更小的網(wǎng)絡(luò),因此知識蒸餾框架通常包含了一個(gè)復(fù)雜模型(被稱為Teacher模型)和一個(gè)小模型(被稱為Student模型)。
1.2 為什么要有知識蒸餾?
深度學(xué)習(xí)在計(jì)算機(jī)視覺、語音識別、自然語言處理等內(nèi)的眾多領(lǐng)域中均取得了令人難以置信的性能。但是,大多數(shù)模型在計(jì)算上過于昂貴,無法在移動端或嵌入式設(shè)備上運(yùn)行。因此需要對模型進(jìn)行壓縮,且知識蒸餾是模型壓縮中重要的技術(shù)之一。
1. 提升模型精度
如果對目前的網(wǎng)絡(luò)模型A的精度不是很滿意,那么可以先訓(xùn)練一個(gè)更高精度的teacher模型B(通常參數(shù)量更多,時(shí)延更大),然后用這個(gè)訓(xùn)練好的teacher模型B對student模型A進(jìn)行知識蒸餾,得到一個(gè)更高精度的A模型。
2. 降低模型時(shí)延,壓縮網(wǎng)絡(luò)參數(shù)
如果對目前的網(wǎng)絡(luò)模型A的時(shí)延不滿意,可以先找到一個(gè)時(shí)延更低,參數(shù)量更小的模型B,通常來講,這種模型精度也會比較低,然后通過訓(xùn)練一個(gè)更高精度的teacher模型C來對這個(gè)參數(shù)量小的模型B進(jìn)行知識蒸餾,使得該模型B的精度接近最原始的模型A,從而達(dá)到降低時(shí)延的目的。
3. 標(biāo)簽之間的域遷移
假如使用狗和貓的數(shù)據(jù)集訓(xùn)練了一個(gè)teacher模型A,使用香蕉和蘋果訓(xùn)練了一個(gè)teacher模型B,那么就可以用這兩個(gè)模型同時(shí)蒸餾出一個(gè)可以識別狗、貓、香蕉以及蘋果的模型,將兩個(gè)不同域的數(shù)據(jù)集進(jìn)行集成和遷移。
因此,在工業(yè)界中對知識蒸餾和遷移學(xué)習(xí)也有著非常強(qiáng)烈的需求。
補(bǔ)充模型壓縮的知識
模型壓縮大體上可以分為 5 種:
模型剪枝:即移除對結(jié)果作用較小的組件,如減少 head 的數(shù)量和去除作用較少的層,共享參數(shù)等,ALBERT屬于這種; 量化:比如將 float32 降到 float8; 知識蒸餾:將 teacher 的能力蒸餾到 student上,一般 student 會比 teacher 小。我們可以把一個(gè)大而深的網(wǎng)絡(luò)蒸餾到一個(gè)小的網(wǎng)絡(luò),也可以把集成的網(wǎng)絡(luò)蒸餾到一個(gè)小的網(wǎng)絡(luò)上。 參數(shù)共享:通過共享參數(shù),達(dá)到減少網(wǎng)絡(luò)參數(shù)的目的,如 ALBERT 共享了 Transformer 層; 參數(shù)矩陣近似:通過矩陣的低秩分解或其他方法達(dá)到降低矩陣參數(shù)的目的;
1.3 這與從頭開始訓(xùn)練模型有何不同?
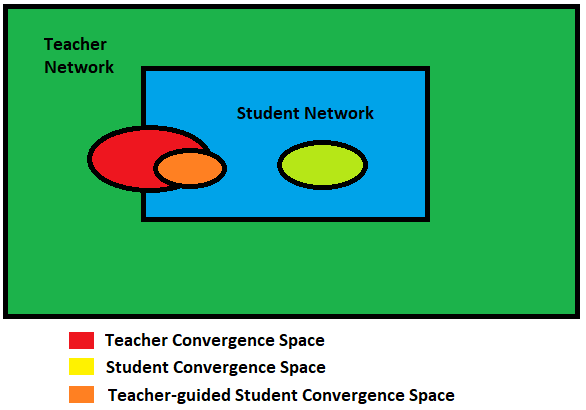
顯然,對于更復(fù)雜的模型,理論搜索空間要大于較小網(wǎng)絡(luò)的搜索空間。但是,如果我們假設(shè)使用較小的網(wǎng)絡(luò)可以實(shí)現(xiàn)相同(甚至相似)的收斂,則教師網(wǎng)絡(luò)的收斂空間應(yīng)與學(xué)生網(wǎng)絡(luò)的解空間重疊。
不幸的是,僅此一項(xiàng)并不能保證學(xué)生網(wǎng)絡(luò)在同一位置收斂。學(xué)生網(wǎng)絡(luò)的收斂可能與教師網(wǎng)絡(luò)的收斂大不相同。但是,如果指導(dǎo)學(xué)生網(wǎng)絡(luò)復(fù)制教師網(wǎng)絡(luò)的行為(教師網(wǎng)絡(luò)已經(jīng)在更大的解空間中進(jìn)行了搜索),則可以預(yù)期其收斂空間與原始教師網(wǎng)絡(luò)收斂空間重疊。
2. 知識蒸餾方式
2.1 知識蒸餾基本框架
知識蒸餾采取Teacher-Student模式:將復(fù)雜且大的模型作為Teacher,Student模型結(jié)構(gòu)較為簡單,用Teacher來輔助Student模型的訓(xùn)練,Teacher學(xué)習(xí)能力強(qiáng),可以將它學(xué)到的知識遷移給學(xué)習(xí)能力相對弱的Student模型,以此來增強(qiáng)Student模型的泛化能力。復(fù)雜笨重但是效果好的Teacher模型不上線,就單純是個(gè)導(dǎo)師角色,真正部署上線進(jìn)行預(yù)測任務(wù)的是靈活輕巧的Student小模型。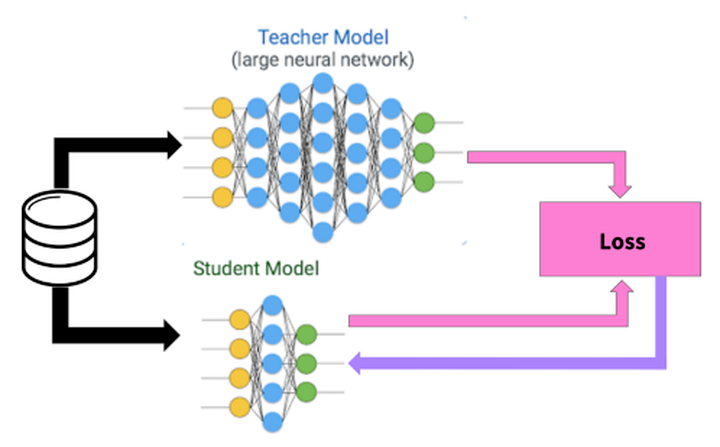
知識蒸餾是對模型的能力進(jìn)行遷移,根據(jù)遷移的方法不同可以簡單分為基于目標(biāo)蒸餾(也稱為Soft-target蒸餾或Logits方法蒸餾)和基于特征蒸餾的算法兩個(gè)大的方向,下面我們對其進(jìn)行介紹。
2.2 目標(biāo)蒸餾-Logits方法
目標(biāo)蒸餾方法中最經(jīng)典的論文就是來自于2015年Hinton發(fā)表的一篇神作《Distilling the Knowledge in a Neural Network》。下面我們以這篇神作為例,給大家講講目標(biāo)蒸餾方法的原理。
在這篇論文中,Hinton將問題限定在分類問題下,分類問題的共同點(diǎn)是模型最后會有一個(gè)softmax層,其輸出值對應(yīng)了相應(yīng)類別的概率值。在知識蒸餾時(shí),由于我們已經(jīng)有了一個(gè)泛化能力較強(qiáng)的Teacher模型,我們在利用Teacher模型來蒸餾訓(xùn)練Student模型時(shí),可以直接讓Student模型去學(xué)習(xí)Teacher模型的泛化能力。一個(gè)很直白且高效的遷移泛化能力的方法就是:使用softmax層輸出的類別的概率來作為“Soft-target” 。
2.2.1 Hard-target 和 Soft-target
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)訓(xùn)練方法是定義一個(gè)損失函數(shù),目標(biāo)是使預(yù)測值盡可能接近于真實(shí)值(Hard- target),損失函數(shù)就是使神經(jīng)網(wǎng)絡(luò)的損失值和盡可能小。這種訓(xùn)練過程是對ground truth求極大似然。在知識蒸餾中,是使用大模型的類別概率作為Soft-target的訓(xùn)練過程。
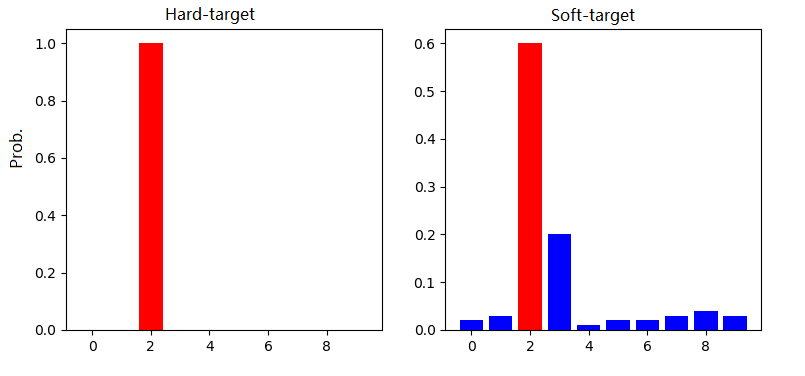
圖:來源于參考文獻(xiàn)2
Hard-target:原始數(shù)據(jù)集標(biāo)注的 one-shot 標(biāo)簽,除了正標(biāo)簽為 1,其他負(fù)標(biāo)簽都是 0。 Soft-target:Teacher模型softmax層輸出的類別概率,每個(gè)類別都分配了概率,正標(biāo)簽的概率最高。
知識蒸餾用Teacher模型預(yù)測的 Soft-target 來輔助 Hard-target 訓(xùn)練 Student模型的方式為什么有效呢?softmax層的輸出,除了正例之外,負(fù)標(biāo)簽也帶有Teacher模型歸納推理的大量信息,比如某些負(fù)標(biāo)簽對應(yīng)的概率遠(yuǎn)遠(yuǎn)大于其他負(fù)標(biāo)簽,則代表 Teacher模型在推理時(shí)認(rèn)為該樣本與該負(fù)標(biāo)簽有一定的相似性。而在傳統(tǒng)的訓(xùn)練過程(Hard-target)中,所有負(fù)標(biāo)簽都被統(tǒng)一對待。也就是說,知識蒸餾的訓(xùn)練方式使得每個(gè)樣本給Student模型帶來的信息量大于傳統(tǒng)的訓(xùn)練方式。
如在MNIST數(shù)據(jù)集中做手寫體數(shù)字識別任務(wù),假設(shè)某個(gè)輸入的“2”更加形似"3",softmax的輸出值中"3"對應(yīng)的概率會比其他負(fù)標(biāo)簽類別高;而另一個(gè)"2"更加形似"7",則這個(gè)樣本分配給"7"對應(yīng)的概率會比其他負(fù)標(biāo)簽類別高。這兩個(gè)"2"對應(yīng)的Hard-target的值是相同的,但是它們的Soft-target卻是不同的,由此我們可見Soft-target蘊(yùn)含著比Hard-target更多的信息。
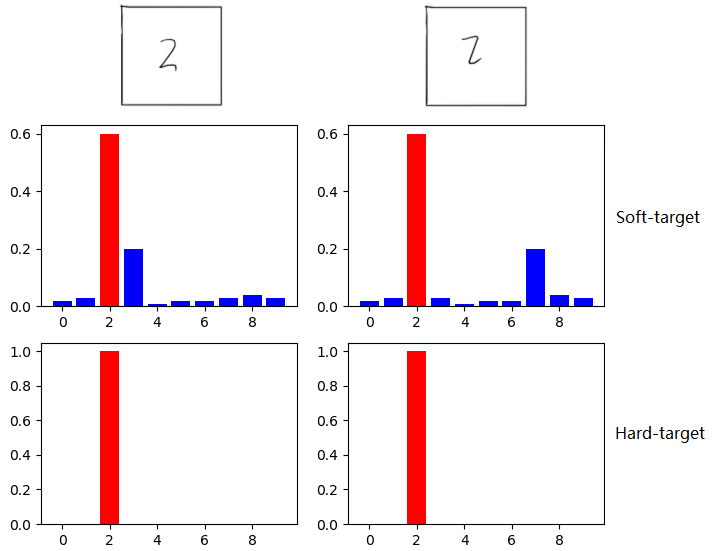
圖:來源于參考文獻(xiàn)2
在使用 Soft-target 訓(xùn)練時(shí),Student模型可以很快學(xué)習(xí)到 Teacher模型的推理過程;而傳統(tǒng)的 Hard-target 的訓(xùn)練方式,所有的負(fù)標(biāo)簽都會被平等對待。因此,Soft-target 給 Student模型帶來的信息量要大于 Hard-target,并且Soft-target分布的熵相對高時(shí),其Soft-target蘊(yùn)含的知識就更豐富。同時(shí),使用 Soft-target 訓(xùn)練時(shí),梯度的方差會更小,訓(xùn)練時(shí)可以使用更大的學(xué)習(xí)率,所需要的樣本也更少。這也解釋了為什么通過蒸餾的方法訓(xùn)練出的Student模型相比使用完全相同的模型結(jié)構(gòu)和訓(xùn)練數(shù)據(jù)只使用Hard-target的訓(xùn)練方法得到的模型,擁有更好的泛化能力。
2.2.2 知識蒸餾的具體方法
在介紹知識蒸餾方法之前,首先得明白什么是Logits。我們知道,對于一般的分類問題,比如圖片分類,輸入一張圖片后,經(jīng)過DNN網(wǎng)絡(luò)各種非線性變換,在網(wǎng)絡(luò)最后Softmax層之前,會得到這張圖片屬于各個(gè)類別的大小數(shù)值 ,某個(gè)類別的 數(shù)值越大,則模型認(rèn)為輸入圖片屬于這個(gè)類別的可能性就越大。什么是Logits? 這些匯總了網(wǎng)絡(luò)內(nèi)部各種信息后,得出的屬于各個(gè)類別的匯總分值 ,就是Logits,i代表第i個(gè)類別, 代表屬于第i類的可能性。因?yàn)長ogits并非概率值,所以一般在Logits數(shù)值上會用Softmax函數(shù)進(jìn)行變換,得出的概率值作為最終分類結(jié)果概率。Softmax一方面把Logits數(shù)值在各類別之間進(jìn)行概率歸一,使得各個(gè)類別歸屬數(shù)值滿足概率分布;另外一方面,它會放大Logits數(shù)值之間的差異,使得Logits得分兩極分化,Logits得分高的得到的概率值更偏大一些,而較低的Logits數(shù)值,得到的概率值則更小。
神經(jīng)網(wǎng)絡(luò)使用 softmax 層來實(shí)現(xiàn) logits 向 probabilities 的轉(zhuǎn)換。原始的softmax函數(shù):
但是直接使用softmax層的輸出值作為soft target,這又會帶來一個(gè)問題: 當(dāng)softmax輸出的概率分布熵相對較小時(shí),負(fù)標(biāo)簽的值都很接近0,對損失函數(shù)的貢獻(xiàn)非常小,小到可以忽略不計(jì)。因此"溫度"這個(gè)變量就派上了用場。下面的公式是加了溫度這個(gè)變量之后的softmax函數(shù):
其中 是每個(gè)類別輸出的概率, 是每個(gè)類別輸出的 logits, 就是溫度。當(dāng)溫度 時(shí),這就是標(biāo)準(zhǔn)的 Softmax 公式。 越高,softmax的output probability distribution越趨于平滑,其分布的熵越大,負(fù)標(biāo)簽攜帶的信息會被相對地放大,模型訓(xùn)練將更加關(guān)注負(fù)標(biāo)簽。
知識蒸餾訓(xùn)練的具體方法如下圖所示,主要包括以下幾個(gè)步驟:
訓(xùn)練好Teacher模型; 利用高溫 產(chǎn)生 Soft-target; 使用 和 同時(shí)訓(xùn)練 Student模型; 設(shè)置溫度 ,Student模型線上做inference。
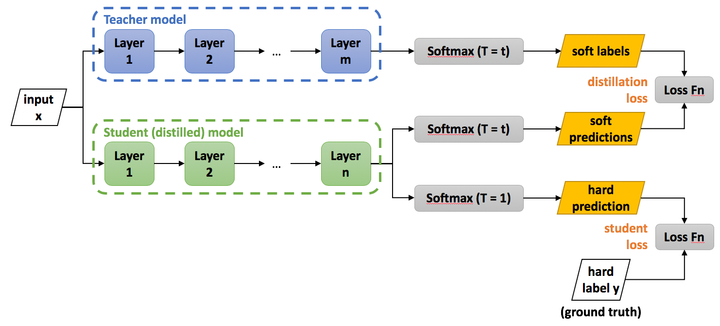
訓(xùn)練Teacher的過程很簡單,我們把第2步和第3步過程統(tǒng)一稱為:高溫蒸餾的過程。高溫蒸餾過程的目標(biāo)函數(shù)由distill loss(對應(yīng)Soft-target)和Student loss(對應(yīng)Hard-target)加權(quán)得到。如下所示:
(1) Teacher模型和Student模型同時(shí)輸入 transfer set (這里可以直接復(fù)用訓(xùn)練Teacher模型用到的training set),用Teacher模型在高溫 下產(chǎn)生的softmax distribution來作為Soft-target,Student模型在相同溫度 條件下的softmax輸出和Soft-target的cross entropy就是Loss函數(shù)的第一部分 ,具體形式如下所示:
其中, 指Teacher模型在溫度等于T的條件下softmax輸出在第 類上的值。 指Student的在溫度等于 的條件下softmax輸出在第 類上的值。公式如下:
其中, 指Teacher模型的logits, 指Student模型的logits, 指總標(biāo)簽數(shù)量。
(2) Student模型在T=1的條件下的softmax輸出和ground truth的cross entropy就是Loss函數(shù)的第二部分 。
其中, 指在第 類上的ground truth值,, 正標(biāo)簽取1,負(fù)標(biāo)簽取0。 形式如下:
第二部分Loss 的必要性其實(shí)很好理解:Teacher模型也有一定的錯(cuò)誤率,使用ground truth可以有效降低錯(cuò)誤被傳播給Student模型的可能性。打個(gè)比喻,老師雖然學(xué)識遠(yuǎn)遠(yuǎn)超過學(xué)生,但是他仍然有出錯(cuò)的可能,而這時(shí)候如果學(xué)生在老師的教授之外,可以同時(shí)參考到標(biāo)準(zhǔn)答案,就可以有效地降低被老師偶爾的錯(cuò)誤“帶偏”的可能性。
最后, 和 是關(guān)于 和 的權(quán)重,實(shí)驗(yàn)發(fā)現(xiàn),當(dāng) 權(quán)重較小時(shí),能產(chǎn)生最好的效果,這是一個(gè)經(jīng)驗(yàn)性的結(jié)論。文章《【經(jīng)典簡讀】知識蒸餾(Knowledge Distillation) 經(jīng)典之作》,地址:https://zhuanlan.zhihu.com/p/102038521 和 文章《【Knowledge Distillation】知識蒸餾學(xué)習(xí)》,地址:https://baihaoran.xyz/2020/05/04/Knowledge-Distillation.html 都進(jìn)行了理論的推導(dǎo),這里我直接給出結(jié)論:由于 貢獻(xiàn)的梯度大約為 的 ,因此在同時(shí)使用Soft-target和Hard-target的時(shí)候,需要在 的權(quán)重上乘以 的系數(shù),這樣才能保證Soft-target和Hard-target貢獻(xiàn)的梯度量基本一致。
2.2.3 蒸餾的一種特殊形式:直接Matching Logits
直接Matching Logits指的是,直接使用softmax層的輸入logits(而不再是輸出)作為Soft- target,需要最小化的目標(biāo)函數(shù)是Teacher模型和Student模型的logits之間的平方差, ,對 求梯度可得:
再看一般蒸餾中 對 求梯度可得:
當(dāng) 時(shí),有 和 ,根據(jù)泰勒公式的一階展開,當(dāng) 時(shí)有 ,則有:
此時(shí),假設(shè) Logits 在每個(gè)樣本上是零均值的,則進(jìn)一步近似:
可見,經(jīng)過Softmax的蒸餾方式和直接Matching Logits的方式,當(dāng)溫度 時(shí)Soft-target損失函數(shù)部分是等價(jià)的,即Matching Logits是一般知識蒸餾方法的一種特殊形式。
2.2.4 關(guān)于溫度
這里消除關(guān)于溫度的伏筆。在知識蒸餾中,需要使用高溫將知識“蒸餾”出來,但是如何調(diào)節(jié)溫度 呢,溫度的變化會產(chǎn)生怎樣的影響呢?
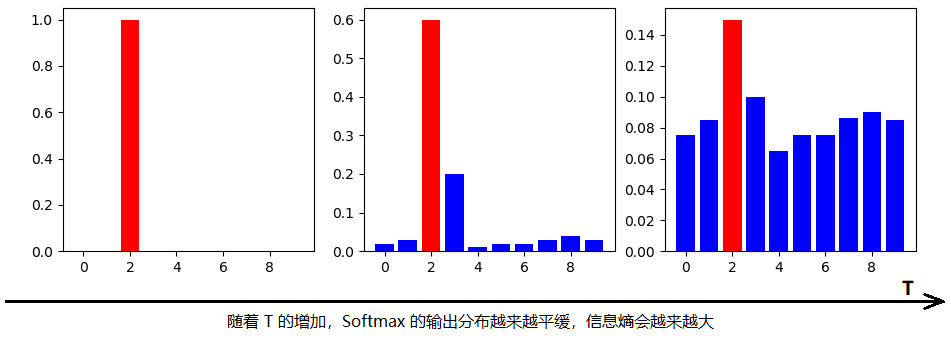
圖:來源于參考文獻(xiàn)2
溫度 有這樣幾個(gè)特點(diǎn):
原始的softmax函數(shù)是 時(shí)的特例;時(shí),概率分布比原始更“陡峭”,也就是說,當(dāng) 時(shí),Softmax 的輸出值會接近于 Hard-target;時(shí),概率分布比原始更“平緩”。 隨著 的增加,Softmax 的輸出分布越來越平緩,信息熵會越來越大。溫度越高,softmax上各個(gè)值的分布就越平均,思考極端情況,當(dāng) ,此時(shí)softmax的值是平均分布的。 不管溫度 怎么取值,Soft-target都有忽略相對較小的 (Teacher模型在溫度為T時(shí)softmax輸出在第 類上的值)攜帶的信息的傾向。
溫度的高低改變的是Student模型訓(xùn)練過程中對負(fù)標(biāo)簽的關(guān)注程度。當(dāng)溫度較低時(shí),對負(fù)標(biāo)簽的關(guān)注,尤其是那些顯著低于平均值的負(fù)標(biāo)簽的關(guān)注較少;而溫度較高時(shí),負(fù)標(biāo)簽相關(guān)的值會相對增大,Student模型會相對更多地關(guān)注到負(fù)標(biāo)簽。
實(shí)際上,負(fù)標(biāo)簽中包含一定的信息,尤其是那些負(fù)標(biāo)簽概率值顯著高于平均值的負(fù)標(biāo)簽。但由于Teacher模型的訓(xùn)練過程決定了負(fù)標(biāo)簽部分概率值都比較小,并且負(fù)標(biāo)簽的值越低,其信息就越不可靠。因此溫度的選取需要進(jìn)行實(shí)際實(shí)驗(yàn)的比較,本質(zhì)上就是在下面兩種情況之中取舍:
當(dāng)想從負(fù)標(biāo)簽中學(xué)到一些信息量的時(shí)候,溫度 應(yīng)調(diào)高一些; 當(dāng)想減少負(fù)標(biāo)簽的干擾的時(shí)候,溫度 應(yīng)調(diào)低一些;
總的來說, 的選擇和Student模型的大小有關(guān),Student模型參數(shù)量比較小的時(shí)候,相對比較低的溫度就可以了。因?yàn)閰?shù)量小的模型不能學(xué)到所有Teacher模型的知識,所以可以適當(dāng)忽略掉一些負(fù)標(biāo)簽的信息。
最后,在整個(gè)知識蒸餾過程中,我們先讓溫度 升高,然后在測試階段恢復(fù)“低溫“( ),從而將原模型中的知識提取出來,因此將其稱為是蒸餾,實(shí)在是妙啊。
2.3 特征蒸餾
另外一種知識蒸餾思路是特征蒸餾方法,如下圖所示。它不像Logits方法那樣,Student只學(xué)習(xí)Teacher的Logits這種結(jié)果知識,而是學(xué)習(xí)Teacher網(wǎng)絡(luò)結(jié)構(gòu)中的中間層特征。最早采用這種模式的工作來自于論文《FITNETS:Hints for Thin Deep Nets》,它強(qiáng)迫Student某些中間層的網(wǎng)絡(luò)響應(yīng),要去逼近Teacher對應(yīng)的中間層的網(wǎng)絡(luò)響應(yīng)。這種情況下,Teacher中間特征層的響應(yīng),就是傳遞給Student的知識。在此之后,出了各種新方法,但是大致思路還是這個(gè)思路,本質(zhì)是Teacher將特征級知識遷移給Student。因此,接下來我們以這篇論文為主,詳細(xì)介紹特征蒸餾方法的原理。
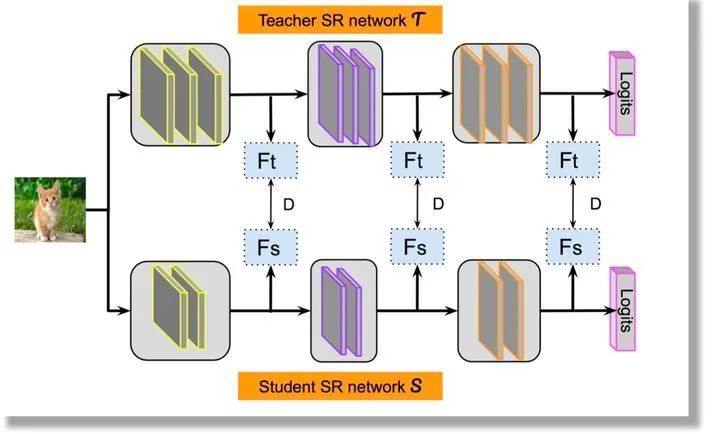
2.3.1 主要解決的問題
這篇論文首先提出一個(gè)案例,既寬又深的模型通常需要大量的乘法運(yùn)算,從而導(dǎo)致對內(nèi)存和計(jì)算的高需求。因此,即使網(wǎng)絡(luò)在準(zhǔn)確性方面是性能最高的模型,其在現(xiàn)實(shí)世界中的應(yīng)用也受到限制。
為了解決這類問題,我們需要通過模型壓縮(也稱為知識蒸餾)將知識從復(fù)雜的模型轉(zhuǎn)移到參數(shù)較少的簡單模型。
到目前為止,知識蒸餾技術(shù)已經(jīng)考慮了Student網(wǎng)絡(luò)與Teacher網(wǎng)絡(luò)有相同或更小的參數(shù)。這里有一個(gè)洞察點(diǎn)是,深度是特征學(xué)習(xí)的基本層面,到目前為止尚未考慮到Student網(wǎng)絡(luò)的深度。一個(gè)具有比Teacher網(wǎng)絡(luò)更多的層但每層具有較少神經(jīng)元數(shù)量的Student網(wǎng)絡(luò)稱為“thin deep network”。
因此,該篇論文主要針對Hinton提出的知識蒸餾法進(jìn)行擴(kuò)展,允許Student網(wǎng)絡(luò)可以比Teacher網(wǎng)絡(luò)更深更窄,使用teacher網(wǎng)絡(luò)的輸出和中間層的特征作為提示,改進(jìn)訓(xùn)練過程和student網(wǎng)絡(luò)的性能。
2.3.2 模型結(jié)構(gòu)
Student網(wǎng)絡(luò)不僅僅擬合Teacher網(wǎng)絡(luò)的Soft-target,而且擬合隱藏層的輸出(Teacher網(wǎng)絡(luò)抽取的特征); 第一階段讓Student網(wǎng)絡(luò)去學(xué)習(xí)Teacher網(wǎng)絡(luò)的隱藏層輸出(特征蒸餾); 第二階段使用Soft-target來訓(xùn)練Student網(wǎng)絡(luò)(目標(biāo)蒸餾)。
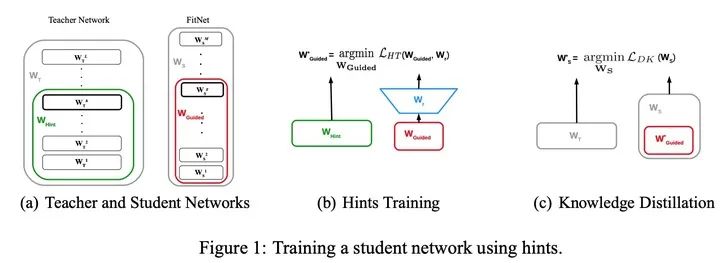
把“寬”且“深”的網(wǎng)絡(luò)蒸餾成“瘦”且“更深”的網(wǎng)絡(luò),需要進(jìn)行兩階段的訓(xùn)練:
第一階段:首先選擇待蒸餾的中間層(即Teacher的Hint layer和Student的Guided layer),如圖中綠框和紅框所示。由于兩者的輸出尺寸可能不同,因此,在Guided layer后另外接一層卷積層,使得輸出尺寸與Teacher的Hint layer匹配。接著通過知識蒸餾的方式訓(xùn)練Student網(wǎng)絡(luò)的Guided layer,使得Student網(wǎng)絡(luò)的中間層學(xué)習(xí)到Teacher的Hint layer的輸出.
就是根據(jù)Teacher模型的損失來指導(dǎo)預(yù)訓(xùn)練Student模型。記Teacher網(wǎng)絡(luò)的前 層作為 ,意為指導(dǎo)的意思。Student網(wǎng)絡(luò)的前 層作為 ,即被指導(dǎo)的意思,在訓(xùn)練之初Student網(wǎng)絡(luò)進(jìn)行隨機(jī)初始化。需要學(xué)習(xí)一個(gè)映射函數(shù) 使得 的維度匹配 ,得到Student模型在下一階段的參數(shù)初始化值,并最小化兩者網(wǎng)絡(luò)輸出的MSE差異作為損失(特征蒸餾),如下:
其中, 是教師網(wǎng)絡(luò)的部分層的參數(shù)(綠框); 是學(xué)生網(wǎng)絡(luò)的部分層的參數(shù)(紅框); 是一個(gè)全連接層,用于將兩個(gè)網(wǎng)絡(luò)輸出的size配齊,因?yàn)閷W(xué)生網(wǎng)絡(luò)隱藏層寬度比教師網(wǎng)絡(luò)窄。
第二階段: 在訓(xùn)練好Guided layer之后,將當(dāng)前的參數(shù)作為網(wǎng)絡(luò)的初始參數(shù),利用知識蒸餾的方式訓(xùn)練Student網(wǎng)絡(luò)的所有層參數(shù),使Student學(xué)習(xí)Teacher的輸出。由于Teacher對于簡單任務(wù)的預(yù)測非常準(zhǔn)確,在分類任務(wù)中近乎one-hot輸出,因此為了弱化預(yù)測輸出,使所含信息更加豐富,作者使用Hinton等人論文《Distilling knowledge in a neural network》中提出的softmax改造方法,即在softmax前引入 縮放因子,將Teacher和Student的pre-softmax輸出均除以 。也就是上面我們講的加了溫度的softmax。此時(shí)的損失函數(shù)為:
其中, 指交叉熵?fù)p失函數(shù); 是一個(gè)可調(diào)整參數(shù),以平衡兩個(gè)交叉熵;第一部分為Student的輸出與Ground-truth的交叉熵?fù)p失;第二部分為Student與Teacher的softmax輸出的交叉熵?fù)p失。
3. 知識蒸餾在NLP/CV中的應(yīng)用
下面給出這兩種蒸餾方式在自然語言處理和計(jì)算機(jī)視覺方面的一些頂會論文,方便大家擴(kuò)展閱讀。
3.1 目標(biāo)蒸餾-Logits方法應(yīng)用
《Distilling the Knowledge in a Neural Network 》,NIPS,2014。 《Deep Mutual Learning》,CVPR,2018。 《Born Again Neural Networks》,CVPR,2018。 《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》,2019。
3.2 特征蒸餾方法應(yīng)用
《FitNets: Hints for Thin Deep Nets》,ICLR,2015。 《Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer》, ICLR,2017。 《A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning》,CVPR,2017。 《Learning Efficient Object Detection Models》,NIPS,2017。
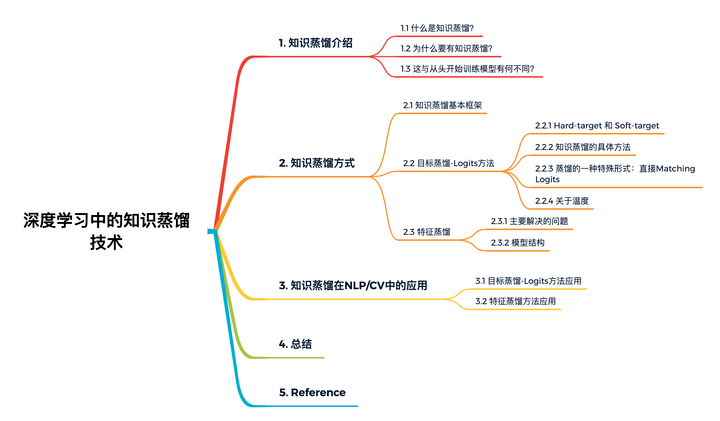
4. 總結(jié)
最近打算系統(tǒng)的學(xué)習(xí)知識蒸餾在自然語言處理、計(jì)算機(jī)視覺和推薦系統(tǒng)方面的理論基礎(chǔ)及實(shí)踐應(yīng)用。學(xué)著學(xué)著發(fā)現(xiàn)相關(guān)知識太多,雖然可以跟大家分享大量的學(xué)習(xí)筆記,但是我時(shí)間有限,且不想本文篇幅太長,因此我會在下篇文章中接著給大家詳細(xì)講解知識蒸餾在推薦系統(tǒng)中的應(yīng)用,這里先給大家放出我的學(xué)習(xí)思維導(dǎo)圖,請大家持續(xù)關(guān)注我哈~