
數(shù)據(jù)傾斜了怎么辦?以應(yīng)屆生 20K Offer 為例

數(shù)據(jù)傾斜,技術(shù)黑話中最成功的的一個詞。發(fā)明這個詞兒的人,一定是天才,它在數(shù)據(jù)量和復(fù)雜度上,一箭雙雕。
早期,我在看《Oracle Concepts》及各類 Oracle Performance Tunning 相關(guān)的技術(shù)書時,書中提到最多的術(shù)語是“數(shù)據(jù)分布”,比如用 statistics 統(tǒng)計每列的散值。這里的散值,又稱單值,或“唯一值”,代表每列的基數(shù) (Cardinality).
比如全世界就兩種性別,男和女。無論男女?dāng)?shù)量多么不平衡,就性別來說,只有“男”,“女”兩個單值,用數(shù)據(jù)庫行話說,Cardinality 為 2.
那么知道每列的基數(shù),有什么用呢,研究數(shù)據(jù)傾斜又有啥用?這種凡事先問有啥用的精致利己的心態(tài),從求學(xué)時代,就與我糾纏不清。
所以,到底為什么要研究數(shù)據(jù)傾斜這個話題呢,我先放幾張圖,做個引子:
第一張圖,為艾瑞咨詢繪制的中國 IT服務(wù)行業(yè),畢業(yè)生薪資流向的分布圖。這張圖的實(shí)際薪資曲線,符合正態(tài)分布
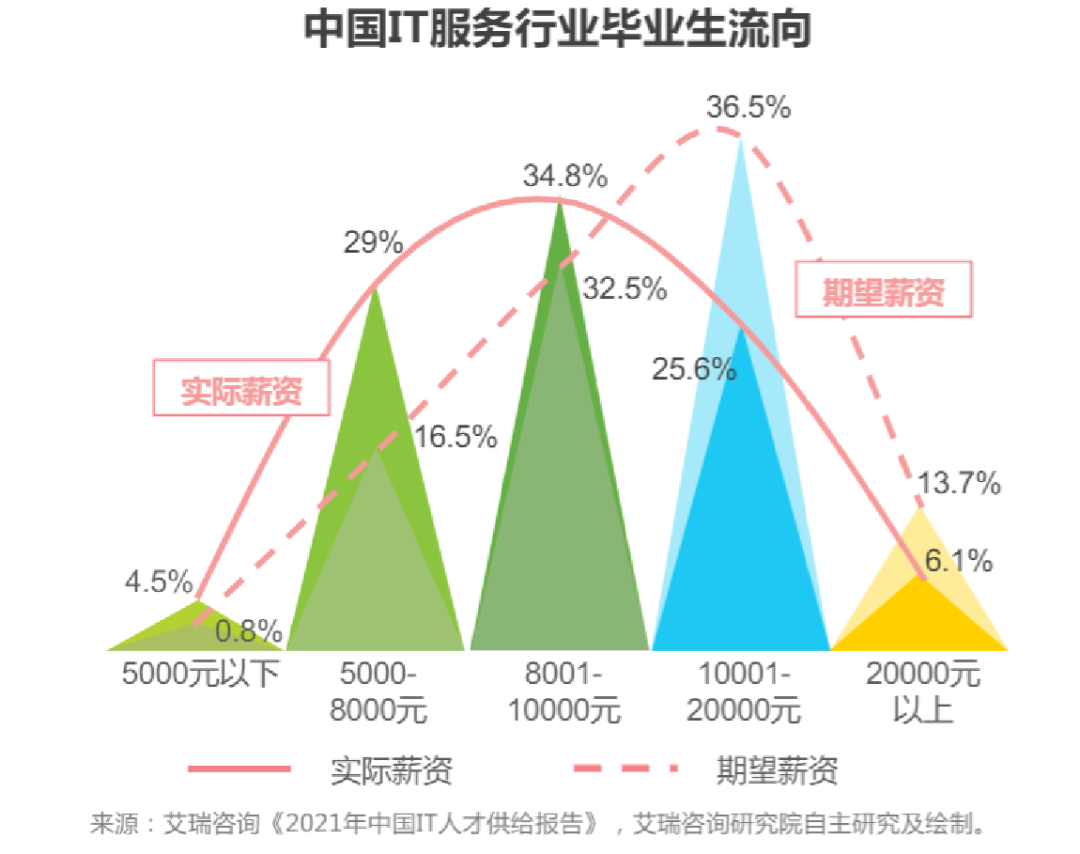
薪資區(qū)間,分別從左往右以 4.5%, 29%, 34.8%,25.6%,6.1% 的占比存在,可見大多數(shù)畢業(yè)生(29% + 34.8% + 25.6% =89.4%),初次入職時,薪資在 5K - 20K 之間。
假設(shè),有 1000人參與了這次調(diào)查,那么你作為老板,要招個有 1 年經(jīng)驗(yàn),還能出活的勞動力,而且預(yù)算不能超過 5K,只要去 45 個人里面招,就能快速招到你要的人。
如果作為老板的你,愿意開出有競爭力的工資,比如 20K,你可以從 894 個人里面招,但如此巨大的規(guī)模,也增加了面試的時間成本。
考慮到社會的毒打,人的潛能被充分發(fā)揮,經(jīng)過一定時間沉淀,社會人的薪酬,就不像應(yīng)屆生排列得那么符合正態(tài)分布了
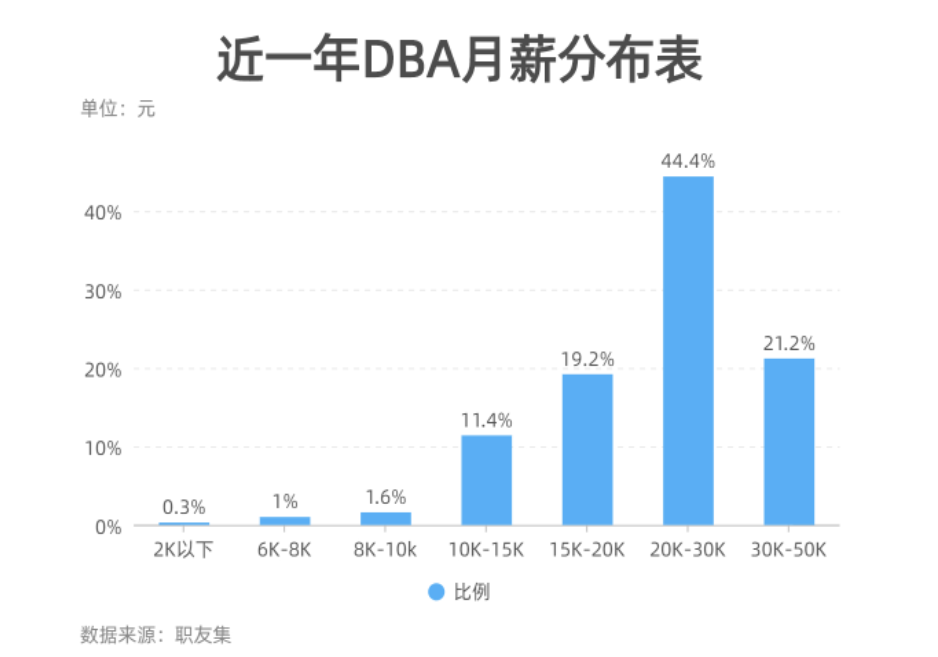
以 20K 為分水嶺,DBA 薪資往 20K 以上傾斜,這個范圍的占比為 44.4%+ 21.2% = 65.6%.?
同樣以 1000人為調(diào)查基數(shù),意味著以 50K 去招人,面試者可能會超過 656 人,面試時間成本太高。而 6K 去招人,則只需面試 30人,快則 2 天,人就到位。
此時,我們可以得到一個經(jīng)驗(yàn):數(shù)據(jù)發(fā)生傾斜是必然,極端的數(shù)據(jù)非常好找,但落到正態(tài)分布的中間位置,找起來就復(fù)雜了,所以得同時配備其他屬性,才能更好定位到相關(guān)數(shù)據(jù)。
既然 20K-50K 的 DBA 人數(shù)那么多,怎樣才能更快地招到人呢。有一個辦法是,從低價格的地方挖人。
比如:
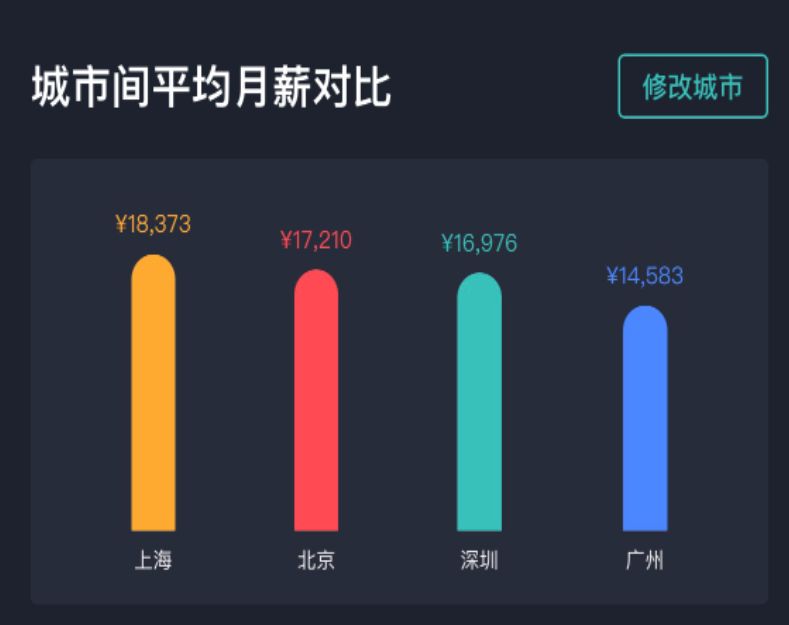
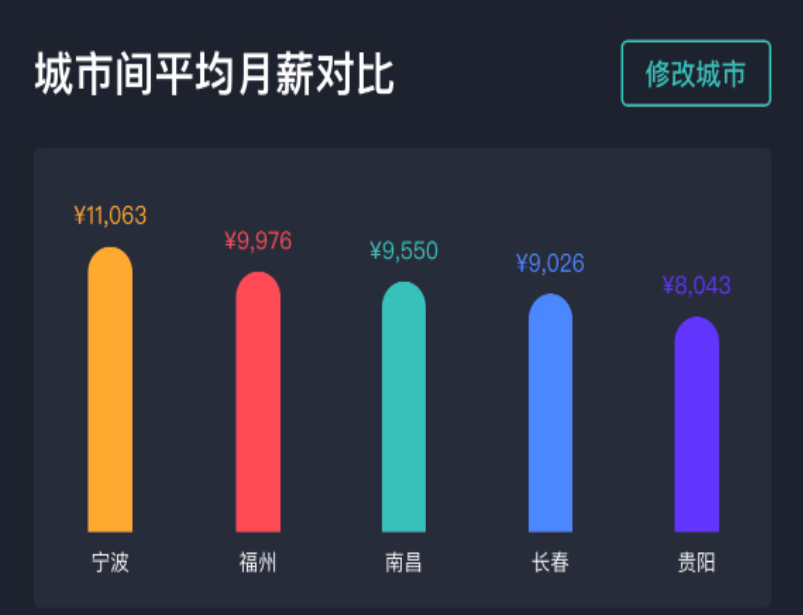
對比發(fā)現(xiàn),貴陽地區(qū)以 8K 為平均數(shù),那么直接以 20K 的價格,則可以很快招到人。
你看,加一維數(shù)據(jù)量就變小了。這就是處理數(shù)據(jù)傾斜的一個有效方法,以薪酬水平加地區(qū),極大地減少樣本數(shù)量,提高了篩選效率。
細(xì)看數(shù)據(jù)傾斜的解決方法,本質(zhì)是判斷怎么建索引更有效。最為關(guān)鍵的一步,是計算列組合的數(shù)據(jù)量占總數(shù)的比例,越低越有效。
那么,怎么計算列組合產(chǎn)生的基數(shù)高低呢,總不能每次全表掃描,做一遍排列組合計算吧?
接下來說兩個常用的事前策略:
第一,是直覺。作為設(shè)計者,對業(yè)務(wù)數(shù)據(jù)的分布,一定會有意識。比如做零售,按照日期和門店做索引,肯定訂單量分散更低;
第二,是做 Hash 索引。假設(shè)你在日期上裝了索引,但查詢里面,基本不按日期搜索,索引白建。于是,找兩個或多個常用判斷字段,做 Hash 索引。這樣,就碎化了組合查詢的密度,提高了效率
以上的策略,主要考量命中率。怎么分析命中率,這屬于優(yōu)化界的秘密武器,每個數(shù)據(jù)庫廠商都有自己的數(shù)據(jù)字典,需要有好奇心的讀者,慢慢摸索。原理都相通!
舉個例子, SQL Server 中,有一種叫做 Statistics 的東西。它就是用來統(tǒng)計基數(shù)以及命中率的對象。
它通過統(tǒng)計每列或列組合的單值總數(shù),計算在表總數(shù)據(jù)量上的占比。由此計算出這列的命中率,繼而判斷是否適合做索引。
使用以下命令即可查詢每列或列組合的單值總數(shù):
?
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail', IX_SalesOrderDetail_ProductID)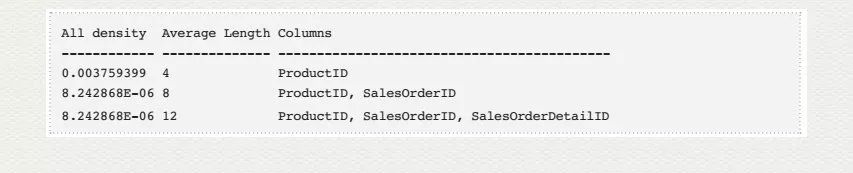
這就是索引?IX_SalesOrderDetail_ProductID 的密度(Density).?密度越低,查詢的命中率就越高,效率就越高
當(dāng)然,用密度來預(yù)判命中率,也有一定的缺陷,需要注意很多地方,比如和柱狀圖的連用等等。詳細(xì)的技術(shù)實(shí)戰(zhàn)參考這篇文章:
點(diǎn)擊上方鏈接直達(dá),為你詳細(xì)解釋 statistics 的查詢,創(chuàng)建和效率優(yōu)勢,包括:
Statistics 分別有哪些查詢方法
Statistics 分別有哪些創(chuàng)建方法
Statistics 在查詢中的效率優(yōu)勢
好了,分享就到這里。最近魔都發(fā)生了些事,大家都知道了。作息,情緒都有些影響,所以更新頻率有些慢,各位多擔(dān)待。
往期精彩: