
偷懶必備!只需一行代碼,就能導(dǎo)入所有的 Python 庫?
大家好,我是安果!
今天給大家介紹一個懶人 Python 庫:Pyforest
使用一行代碼,就能導(dǎo)入所有的 Python 庫(本地已經(jīng)安裝的)
項目地址:https://github.com/8080labs/pyforest
/ 01 / 介紹
Python 因為有著成千上萬個功能強大的開源庫,備受大家的歡迎
目前,通過 PyPl 可以導(dǎo)入超過 23.5 萬個 Python 庫,數(shù)量龐大
在大家平常的實踐當(dāng)中,一般都是需要導(dǎo)入多個庫或者框架來執(zhí)行任務(wù)
而且每當(dāng)新建一個程序文件時,都需要根據(jù)自己的需求導(dǎo)入相關(guān)的庫
如果是相同類型的任務(wù),比如想做一個數(shù)據(jù)可視化的小項目,可能會一直使用到某個庫
如此,反復(fù)編寫同一條 import 語句,就算是復(fù)制粘貼,也會感覺到麻煩,這時 Pyforest 庫就可以上場了
Pyforest 是一個開源的 Python 庫,可以自動導(dǎo)入代碼中使用到的 Python 庫
在進行數(shù)據(jù)可視化的時候,一般都需要導(dǎo)入多個庫,比如 pandas、numpy、matplotlib 等等
使用了 Pyforest,每個程序文件中就不需要導(dǎo)入相同的 Python 庫,而且也不必使用確切的導(dǎo)入語句
比如下面這行代碼,就可以省略掉
from sklearn.ensemble import RandomForestClassifier
在你使用 import 語句導(dǎo)入Pyforest 庫后,你就可以直接使用所有的 Python 庫
import pyforest
df = pd.read_csv('test.csv')
print(df)
你使用的任何庫都不需要使用 import 語句導(dǎo)入,Pyforest 會為你自動導(dǎo)入。
只有在代碼中調(diào)用庫或創(chuàng)建庫的對象后,才會導(dǎo)入庫。如果一個庫沒有被使用或調(diào)用,Pyforest 將不會導(dǎo)入它。
/ 02 / 使用
安裝,使用以下命令安裝 Pyforest
pip install pyforest -i https://pypi.tuna.tsinghua.edu.cn/simple
安裝成功后,使用 import 語句導(dǎo)入它
現(xiàn)在,你可以直接使用相關(guān)的 Python 庫,無需編寫 import 導(dǎo)入
先以 jupiter notebook 為例,我們沒有導(dǎo)入 pandas、seaborn 和 matplotlib 庫,但是我們可以通過導(dǎo)入 Pyforest 庫直接使用它們
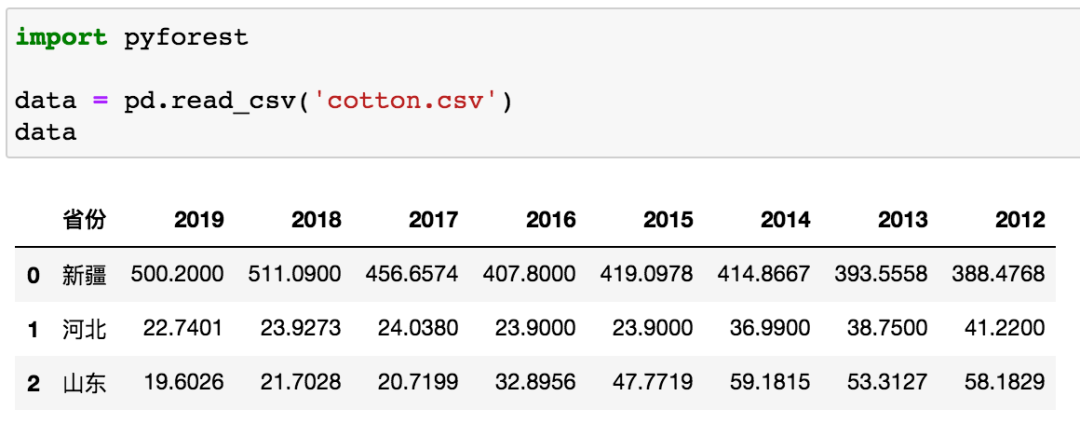
讀取數(shù)據(jù),這個是國內(nèi)棉花產(chǎn)量排行前三的省份,新疆全國第一(數(shù)據(jù)來源:國家統(tǒng)計局)
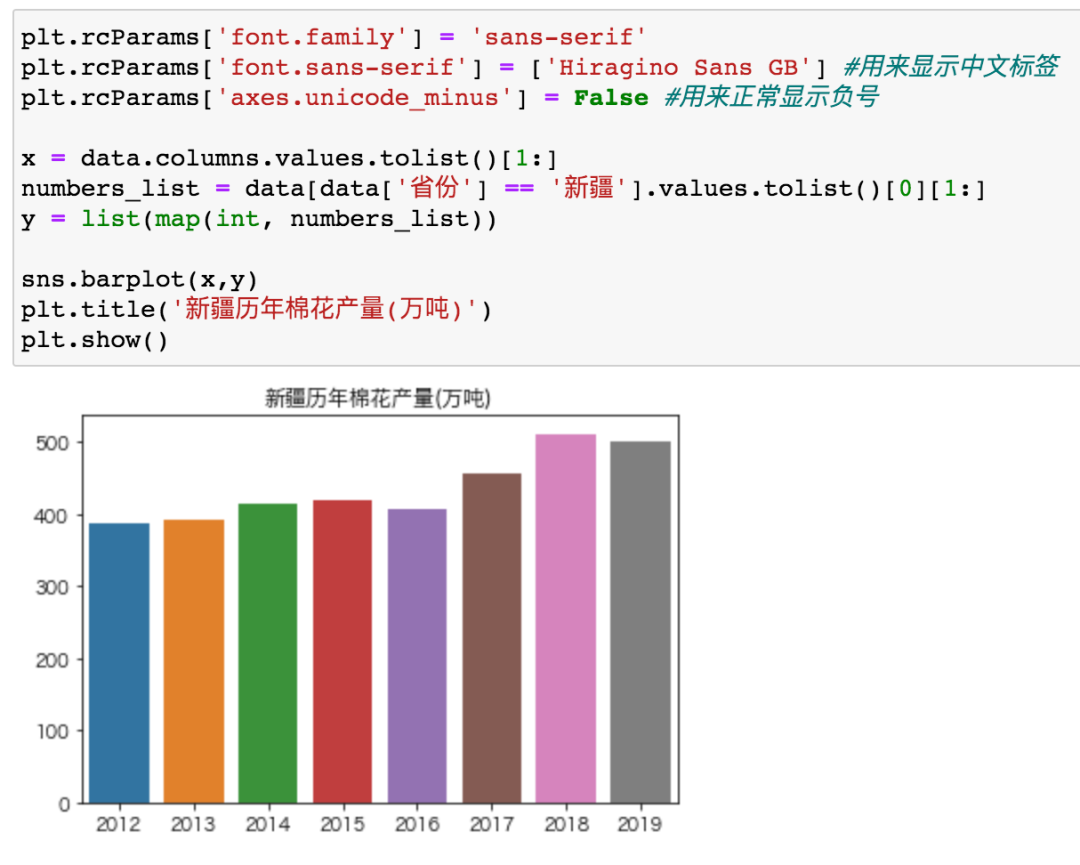
那么 Pyforest 可以導(dǎo)入所有庫嗎?
目前這個包包含了大部分流行的 Python 庫,比如
pandas as pd
NumPy as np
matplotlob.pyplot as plt
seaborn as sns
除了這些庫之外,它還提供了一些輔助的 Python 庫,如 os、tqdm、re 等
如果你想查看庫列表,可以使用 dir(pyforest) 進行查看,內(nèi)置的是 68 個庫
import pyforest
print(len(dir(pyforest)))
for i in dir(pyforest):
print(i)
-------------------------
68
GradientBoostingClassifier
GradientBoostingRegressor
LazyImport
OneHotEncoder
Path
RandomForestClassifier
RandomForestRegressor
SparkContext
TSNE
TfidfVectorizer
...
如果沒有的話,可以進行自定義添加,在主目錄中的文件寫入 import 語句
示例如下
vim ~/.pyforest/user_imports.py
添加語句,此處便能在代碼中使用 requests 這個庫
# Add your imports here, line by line
# e.g
# import pandas as pd
# from pathlib import Path
# import re
import requests as req
~
~
"~/.pyforest/user_imports.py" 7L, 129C
這回我們在 PyCharm 中來實驗一下。
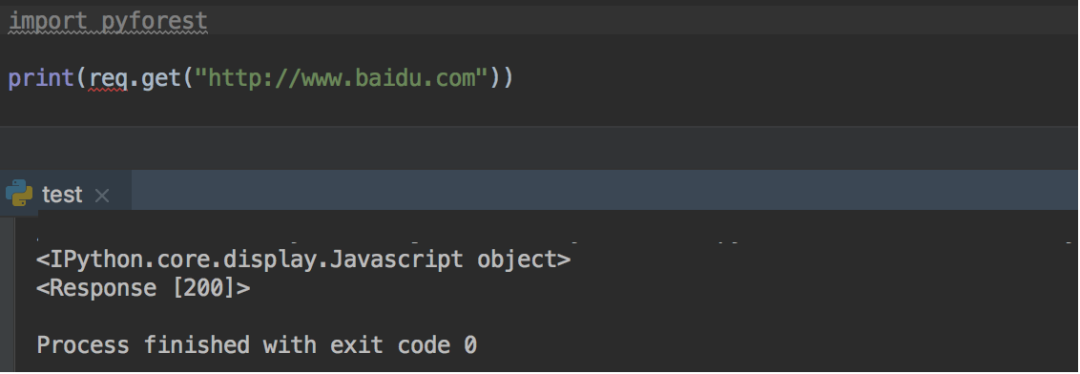
發(fā)現(xiàn) PyCharm 的自動補全的功能失效了,看來這個庫還是比較適合 jupyter notebook(自動補全代碼還可以使用)
除了上面這個地方可以自定義添加,還可以在庫的 _import.py 文件中添加
此處以 Pyechars 為例,縮寫為 chart
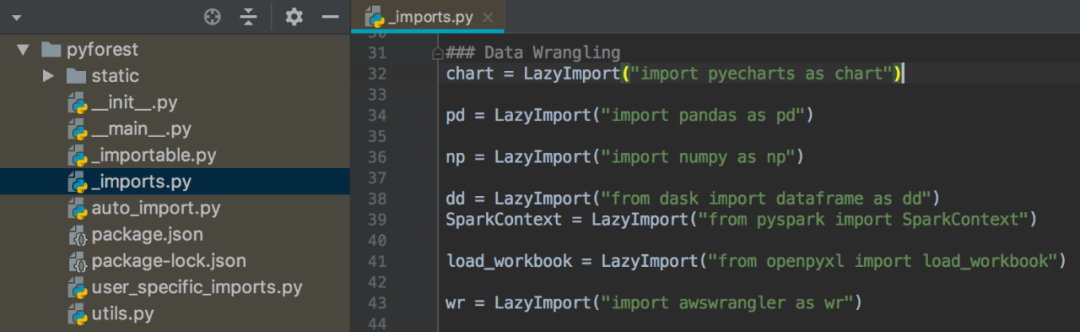
可視化代碼如下
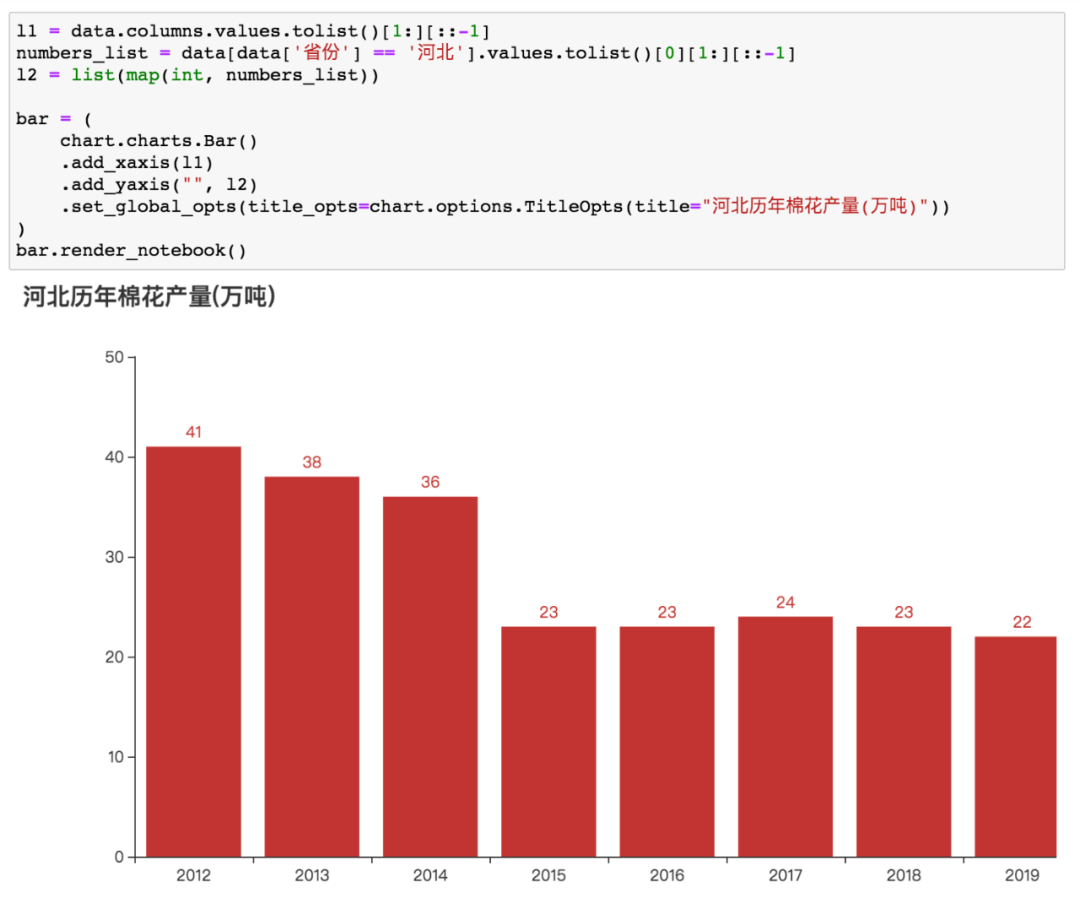
新疆棉花產(chǎn)量年年上升,其它省份年年下降...
最后 Pyforest 還提供了一些函數(shù)來了解庫的使用情況
# 返回已導(dǎo)入并且正在使用的庫列表
print(pyforest.active_imports())
--------------------------------
['import pandas as pd', 'import requests as req', 'import pyg2plot']
# 返回pyforest中所有Python庫的列表
print(pyforest.lazy_imports())
--------------------------------
['import glob', 'import numpy as np', 'import matplotlib.pyplot as plt'...]
只有代碼中有使用到的庫,程序才會 import 進去,否則不會導(dǎo)入的哦!
/ 03 / 總結(jié)
好了,到此本期的分享就結(jié)束了
使用 Pyforest 庫有時候確實是可以節(jié)省一些時間,不過也是有弊端存在的。比如調(diào)試的時候(大型項目),可能會很痛苦,不知道是哪里來的庫
所以建議大家,在一些獨立的腳本程序中使用,效果應(yīng)該還是不錯的
萬水千山總是情,點個 ?? 行不行