
一條 sql 的執(zhí)行過(guò)程詳解

寫(xiě)操作執(zhí)行過(guò)程
如果這條sql是寫(xiě)操作(insert、update、delete),那么大致的過(guò)程如下,其中引擎層是屬于 InnoDB 存儲(chǔ)引擎的,因?yàn)镮nnoDB 是默認(rèn)的存儲(chǔ)引擎,也是主流的,所以這里只說(shuō)明 InnoDB 的引擎層過(guò)程。由于寫(xiě)操作較查詢操作更為復(fù)雜,所以先看一下寫(xiě)操作的執(zhí)行圖。方便后面解析。
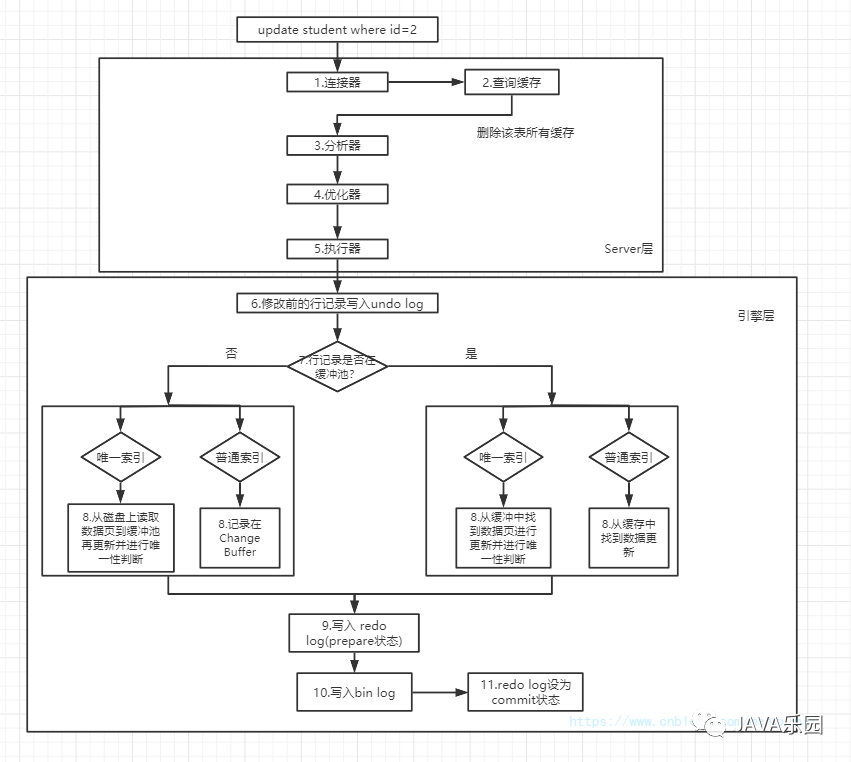
0x01: 組件介紹?
Server層
1、連接器
1)負(fù)責(zé)與客戶端的通信,是半雙工模式,這就意味著某一固定時(shí)刻只能由客戶端向服務(wù)器請(qǐng)求或者服務(wù)器向客戶端發(fā)送數(shù)據(jù),而不能同時(shí)進(jìn)行。
2)驗(yàn)證用戶名和密碼是否正確(數(shù)據(jù)庫(kù)mysql的user表中進(jìn)行驗(yàn)證),如果錯(cuò)誤返回錯(cuò)誤通知(deAcess ?nied ?for ?user ?'root'@'localhost'(using password:YES)),如果正確,則會(huì)去 mysql 的權(quán)限表(mysql中的 user、db、columns_priv、Host 表,分別存儲(chǔ)的是全局級(jí)別、數(shù)據(jù)庫(kù)級(jí)別、表級(jí)別、列級(jí)別、配合 db 的數(shù)據(jù)庫(kù)級(jí)別)查詢當(dāng)前用戶的權(quán)限。
2、緩存(Cache)
也稱為查詢緩存,存儲(chǔ)的數(shù)據(jù)是以鍵值對(duì)的形式進(jìn)行存儲(chǔ),如果開(kāi)啟了緩存,那么在一條查詢sql語(yǔ)句進(jìn)來(lái)時(shí)會(huì)先判斷緩存中是否包含當(dāng)前的sql語(yǔ)句鍵值對(duì),如果存在直接將其對(duì)應(yīng)的結(jié)果返回,如果不存在再執(zhí)行后面一系列操作。如果沒(méi)有開(kāi)啟則直接跳過(guò)。
相關(guān)操作:
查看緩存配置:show ?variables ?like ?'have_query_cache';
查看是否開(kāi)啟:show ?variables ?like ?'query_cache_type';
查看緩存占用大小:show ?variables ?like ?'query_cache_size';
查看緩存狀態(tài)信息:show ?status ?like ?'Qcache%';
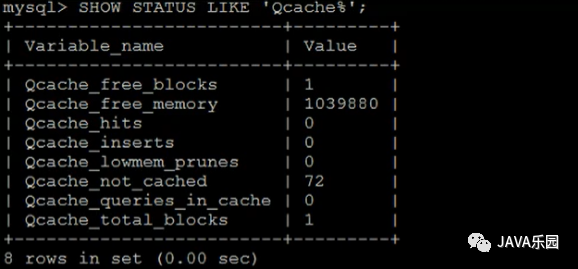
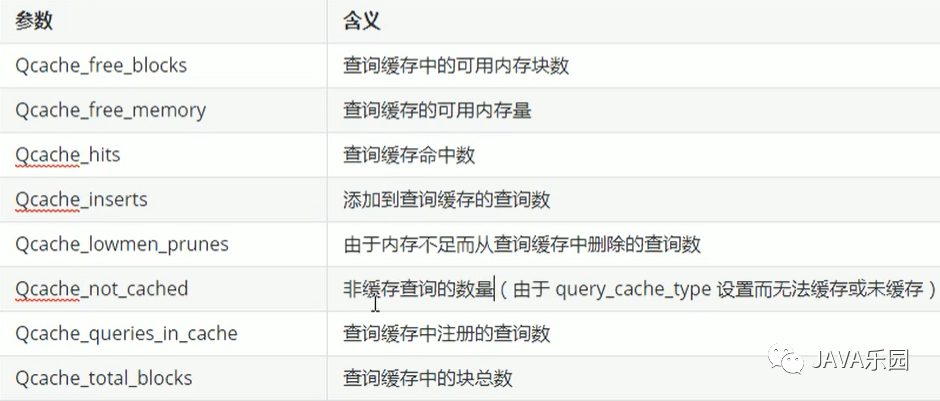
相關(guān)參數(shù)的含義:
?緩存失效場(chǎng)景:
1、查詢語(yǔ)句不一致。前后兩條查詢SQL必須完全一致。
2、查詢語(yǔ)句中含有一些不確定的值時(shí),則不會(huì)緩存。比如 now()、current_date()、curdate()、curtime()、rand()、uuid()等。
3、不使用任何表查詢。如 select 'A';
4、查詢 mysql、information_schema 或 performance_schema 數(shù)據(jù)庫(kù)中的表時(shí),不會(huì)走查詢緩存。
5、在存儲(chǔ)的函數(shù),觸發(fā)器或事件的主體內(nèi)執(zhí)行的查詢。
6、如果表更改,則使用該表的所有高速緩存查詢都變?yōu)闊o(wú)效并從緩存中刪除,這包括使用 MERGE 映射到已更改表的表的查詢。一個(gè)表可以被許多類型的語(yǔ)句改變,如 insert、update、delete、truncate rable、alter table、drop table、drop database。
?
通過(guò)上面的失效場(chǎng)景可以看出緩存是很容易失效的,所以如果不是查詢次數(shù)遠(yuǎn)大于修改次數(shù)的話,使用緩存不僅不能提升查詢效率還會(huì)拉低效率(每次讀取后需要向緩存中保存一份,而緩存又容易被清除)。所以在 MYSQL5.6默認(rèn)是關(guān)閉緩存的,并且在 8.0?直接被移除了。當(dāng)然,如果場(chǎng)景需要用到,還是可以使用的。
開(kāi)啟
在配置文件(linux下是安裝目錄的cnf文件,windows是安裝目錄下的ini文件)中,增加配置:?query_cache_type = 1
關(guān)于 query_type_type 參數(shù)的說(shuō)明:

指定 SQL_NO_CACHE:select ?SQL_NO_CACHE ?*? from ?student ?where age >20;? ? SQL_CACHE 同理。
3、分析器
對(duì)客戶端傳來(lái)的 sql 進(jìn)行分析,這將包括預(yù)處理與解析過(guò)程,并進(jìn)行關(guān)鍵詞的提取、解析,并組成一個(gè)解析樹(shù)。具體的解析詞包括但不局限于 select/update/delete/or/in/where/group by/having/count/limit 等,如果分析到語(yǔ)法錯(cuò)誤,會(huì)直接拋給客戶端異常:ERROR:You have an error in your SQL syntax.
比如:select *? from user where userId =1234;
在分析器中就通過(guò)語(yǔ)義規(guī)則器將select from where這些關(guān)鍵詞提取和匹配出來(lái),mysql會(huì)自動(dòng)判斷關(guān)鍵詞和非關(guān)鍵詞,將用戶的匹配字段和自定義語(yǔ)句識(shí)別出來(lái)。這個(gè)階段也會(huì)做一些校驗(yàn):比如校驗(yàn)當(dāng)前數(shù)據(jù)庫(kù)是否存在user表,同時(shí)假如User表中不存在userId這個(gè)字段同樣會(huì)報(bào)錯(cuò):unknown column in field list.
4、優(yōu)化器
進(jìn)入優(yōu)化器說(shuō)明sql語(yǔ)句是符合標(biāo)準(zhǔn)語(yǔ)義規(guī)則并且可以執(zhí)行。優(yōu)化器會(huì)根據(jù)執(zhí)行計(jì)劃選擇最優(yōu)的選擇,匹配合適的索引,選擇最佳的方案。比如一個(gè)典型的例子是這樣的:
?
表T,對(duì)A、B、C列建立聯(lián)合索引(A,B,C),在進(jìn)行查詢的時(shí)候,當(dāng)sql查詢條件是:select xx where ?B=x and A=x and C=x.很多人會(huì)以為是用不到索引的,但其實(shí)會(huì)用到,雖然索引必須符合最左原則才能使用,但是本質(zhì)上,優(yōu)化器會(huì)自動(dòng)將這條sql優(yōu)化為:where A=x and B=x and C=X,這種優(yōu)化會(huì)為了底層能夠匹配到索引,同時(shí)在這個(gè)階段是自動(dòng)按照?qǐng)?zhí)行計(jì)劃進(jìn)行預(yù)處理,mysql會(huì)計(jì)算各個(gè)執(zhí)行方法的最佳時(shí)間,最終確定一條執(zhí)行的sql交給最后的執(zhí)行器
5、執(zhí)行器
執(zhí)行器會(huì)調(diào)用對(duì)應(yīng)的存儲(chǔ)引擎執(zhí)行 sql。主流的是MyISAM 和 Innodb。
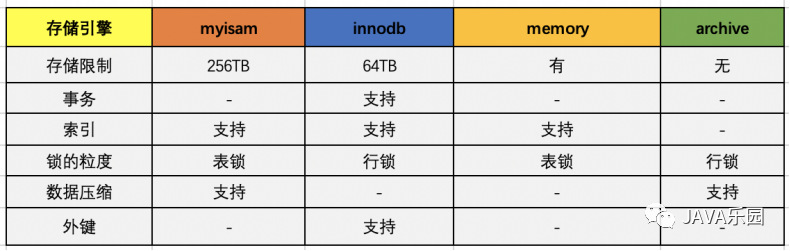
存儲(chǔ)引擎(InnoDB)層
1、undo log?與 MVCC
undo log是 Innodb 引擎專屬的日志,是記錄每行數(shù)據(jù)事務(wù)執(zhí)行前的數(shù)據(jù)。主要作用是用于實(shí)現(xiàn)MVCC版本控制,保證事務(wù)隔離級(jí)別的讀已提交和讀未提交級(jí)別。而 MVCC 相關(guān)的可以參考 MySQL中的事務(wù)原理和鎖機(jī)制。
?
2、redo log?與 Buffer Pool
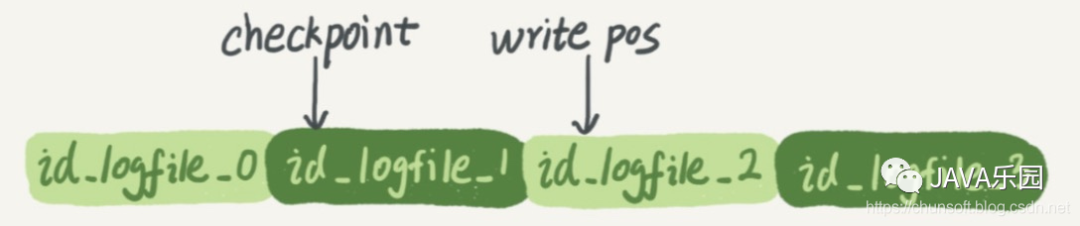
InnoDB 內(nèi)部維護(hù)了一個(gè)緩沖池,用于減少對(duì)磁盤數(shù)據(jù)的直接IO操作,并配合 redo log 來(lái)實(shí)現(xiàn)異步的落盤,保證程序的高效執(zhí)行。redo log 大小固定,采用循環(huán)寫(xiě)
?
?
?write pos 表示當(dāng)前正在記錄的位置,會(huì)向后記錄, checkpoint 表示數(shù)據(jù)落盤的邊界,也就是 checkpoint 與 write pos中間是已記錄的,當(dāng) write pos寫(xiě)完 id_logfile_3后,會(huì)回到id_logfile_0循環(huán)寫(xiě),而追上 checkpomnit 后則需要先等數(shù)據(jù)進(jìn)行落盤,等待 checkponit向后面移動(dòng)一段距離再寫(xiě)。redo log存儲(chǔ)的內(nèi)容個(gè)人認(rèn)為當(dāng)直接更新到數(shù)據(jù)頁(yè)緩存時(shí)記錄的就是數(shù)據(jù)頁(yè)邏輯,如果更新到 Change Buffer 那么就是操作的 sql。
關(guān)于 Buffer Pool詳情可查看博客 InnoDB 中的緩沖池(Buffer Pool)。
?
3、bin log(Server?層)
redo log 因?yàn)榇笮」潭ǎ圆荒艽鎯?chǔ)過(guò)多的數(shù)據(jù),它只能用于未更新的數(shù)據(jù)落盤,而數(shù)據(jù)操作的備份恢復(fù)、以及主從復(fù)制是靠 bin log(如果數(shù)據(jù)庫(kù)誤刪需要還原,那么需要某個(gè)時(shí)間點(diǎn)的數(shù)據(jù)備份以及bin log)。5.7默認(rèn)記錄的是修改后的行記錄。
在更新到數(shù)據(jù)頁(yè)緩存或者 Change Buffer 后,首先進(jìn)行 redo log 的編寫(xiě),此時(shí) redo log 處于 prepare 狀態(tài),隨后再進(jìn)行 bin log 的編寫(xiě),等到 bin log 也編寫(xiě)完成后再將 redo log 設(shè)置為 commit 狀態(tài)。這是為了防止數(shù)據(jù)庫(kù)宕機(jī)導(dǎo)致 bin log 沒(méi)有將修改記錄寫(xiě)入,后面數(shù)據(jù)恢復(fù)、主從復(fù)制時(shí)數(shù)據(jù)不一致。當(dāng)數(shù)據(jù)庫(kù)啟動(dòng)后如果發(fā)現(xiàn) redo log 為 prepare 狀態(tài),那么就會(huì)檢查 bin log 與 redo log 最近的記錄是否對(duì)的上,如果對(duì)的上就提交,對(duì)不上就進(jìn)行事務(wù)回滾。
三種格式:
1、Row(5.7默認(rèn))。記錄被修改后的行記錄。缺點(diǎn)是占空間大。優(yōu)點(diǎn)是能保證數(shù)據(jù)安全,不會(huì)發(fā)生遺漏。
2、Statement。記錄修改的 sql。缺點(diǎn)是在 mysql 集群時(shí)可能會(huì)導(dǎo)致操作不一致從而使得數(shù)據(jù)不一致(比如在操作中加入了Now()函數(shù),主從數(shù)據(jù)庫(kù)操作的時(shí)間不同結(jié)果也不同)。優(yōu)點(diǎn)是占空間小,執(zhí)行快。
3、Mixed。會(huì)針對(duì)于操作的 sql 選擇使用Row 還是 Statement。缺點(diǎn)是還是可能發(fā)生主從不一致的情況。
三個(gè)日志的比較(undo、redo、bin)
1、undo log是用于事務(wù)的回滾、保證事務(wù)隔離級(jí)別讀已提交、可重復(fù)讀實(shí)現(xiàn)的。redo log是用于對(duì)暫不更新到磁盤上的操作進(jìn)行記錄,使得其可以延遲落盤,保證程序的效率。bin log是對(duì)數(shù)據(jù)操作進(jìn)行備份恢復(fù)(并不能依靠 bin log 直接完成數(shù)據(jù)恢復(fù))。
2、undo log 與 redo log 是存儲(chǔ)引擎層的日志,只能在 InnoDB 下使用;而bin log 是 Server 層的日志,可以在任何引擎下使用。
3、redo log 大小有限,超過(guò)后會(huì)循環(huán)寫(xiě);另外兩個(gè)大小不會(huì)。
4、undo log 記錄的是行記錄變化前的數(shù)據(jù);redo log 記錄的是 sql 或者是數(shù)據(jù)頁(yè)修改邏輯或 sql(個(gè)人理解);bin log記錄的是修改后的行記錄(5.7默認(rèn))或者sql語(yǔ)句。
?
0x02: 執(zhí)行過(guò)程
寫(xiě)操作
?通過(guò)上面的分析,可以很容易地了解開(kāi)始的更新執(zhí)行圖。這里就不過(guò)多闡述了。
讀操作
查詢的過(guò)程和更新比較相似,但是有些不同,主要是來(lái)源于他們?cè)诓檎液Y選時(shí)的不同,更新因?yàn)樵诓檎液髸?huì)進(jìn)行更新操作,所以查詢這一行為至始至終都在緩沖池中(使用到索引且緩沖池中包含數(shù)據(jù)對(duì)應(yīng)的數(shù)據(jù)頁(yè))。而查詢則更復(fù)雜一些。
Where?條件的提取
在 MySQL 5.6開(kāi)始,引入了一種索引優(yōu)化策略——索引下推,其本質(zhì)優(yōu)化的就是 Where 條件的提取。Where 提取過(guò)程是怎樣的?用一個(gè)例子來(lái)說(shuō)明,首先進(jìn)行建表,插入記錄。
create?table?tbl_test?(a?int?primary?key,?b?int,?c?int,?d?int,?e?varchar(50));
create?index?idx_bcd?on?tbl_test(b,?c,?d);
insert?into?tbl_test?values?(4,3,1,1,'a');
insert?into?tbl_test?values?(1,1,1,2,'d');
insert?into?tbl_test?values?(8,8,7,8,'h');
insert?into?tbl_test?values?(2,2,1,2,'g');
insert?into?tbl_test?values?(5,2,2,5,'e');
insert?into?tbl_test?values?(3,3,2,1,'c');
insert?into?tbl_test?values?(7,4,0,5,'b');
insert?into?tbl_test?values?(6,5,2,4,'f');
?那么執(zhí)行 select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a';? 在提取時(shí),會(huì)將 Where?條件拆分為?Index Key(First Key & Last Key)、Index Filter 與 Table Filter。
1、Index Key
用于確定 SQL 查詢?cè)谒饕械倪B續(xù)范圍(起始點(diǎn) + 終止點(diǎn))的查詢條件,被稱之為Index Key;由于一個(gè)范圍,至少包含一個(gè)起始條件與一個(gè)終止條件,因此 Index Key 也被拆分為 Index First Key 和 Index Last Key,分別用于定位索引查找的起始點(diǎn)以終止點(diǎn)
Index First Key
用于確定索引查詢范圍的起始點(diǎn);提取規(guī)則:從索引的第一個(gè)鍵值開(kāi)始,檢查其在 where 條件中是否存在,若存在并且條件是 =、>=,則將對(duì)應(yīng)的條件加入Index First Key之中,繼續(xù)讀取索引的下一個(gè)鍵值,使用同樣的提取規(guī)則;若存在并且條件是 >,則將對(duì)應(yīng)的條件加入 Index First Key 中,同時(shí)終止 Index First Key 的提取;若不存在,同樣終止 Index First Key 的提取
針對(duì) SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應(yīng)用這個(gè)提取規(guī)則,提取出來(lái)的 Index First Key 為?b?>=?2, c?>?0?,由于 c 的條件為 >,提取結(jié)束
Index Last Key
用于確定索引查詢范圍的終止點(diǎn),與 Index First Key 正好相反;提取規(guī)則:從索引的第一個(gè)鍵值開(kāi)始,檢查其在 where 條件中是否存在,若存在并且條件是 =、<=,則將對(duì)應(yīng)條件加入到 Index Last Key 中,繼續(xù)提取索引的下一個(gè)鍵值,使用同樣的提取規(guī)則;若存在并且條件是 < ,則將條件加入到 Index Last Key 中,同時(shí)終止提取;若不存在,同樣終止Index Last Key的提取
針對(duì) SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應(yīng)用這個(gè)提取規(guī)則,提取出來(lái)的 Index Last Key為?b?<?7?,由于是 < 符號(hào),提取結(jié)束
2、Index Filter
在完成 Index Key 的提取之后,我們根據(jù) where 條件固定了索引的查詢范圍,那么是不是在范圍內(nèi)的每一個(gè)索引項(xiàng)都滿足 WHERE 條件了 ?很明顯?4,0,5?,?2,1,2?均屬于范圍中,但是又均不滿足SQL 的查詢條件
所以 Index Filter 用于索引范圍確定后,確定 SQL 中還有哪些條件可以使用索引來(lái)過(guò)濾;提取規(guī)則:從索引列的第一列開(kāi)始,檢查其在 where 條件中是否存在,若存在并且 where 條件僅為 =,則跳過(guò)第一列繼續(xù)檢查索引下一列,下一索引列采取與索引第一列同樣的提取規(guī)則;若 where 條件為 >=、>、<、<= 其中的幾種,則跳過(guò)索引第一列,將其余 where 條件中索引相關(guān)列全部加入到 Index Filter 之中;若索引第一列的 where 條件包含 =、>=、>、<、<= 之外的條件,則將此條件以及其余 where 條件中索引相關(guān)列全部加入到 Index Filter 之中;若第一列不包含查詢條件,則將所有索引相關(guān)條件均加入到 Index Filter之中
針對(duì) SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應(yīng)用這個(gè)提取規(guī)則,提取出來(lái)的 Index Filter 為?c?>?0?and?d?!=?2?,因?yàn)樗饕谝涣兄话?>=、< 兩個(gè)條件,因此第一列跳過(guò),將余下的 c、d 兩列加入到 Index Filter 中,提取結(jié)束
3、Table Filter
這個(gè)就比較簡(jiǎn)單了,where 中不能被索引過(guò)濾的條件都?xì)w為此中;提取規(guī)則:所有不屬于索引列的查詢條件,均歸為 Table Filter 之中
針對(duì) SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',應(yīng)用這個(gè)提取規(guī)則,那么 Table Filter 就為??e?!=?'a'?
?
在5.6 之前,是不分 Table Filter 與 Index Filter 的,這兩個(gè)條件都直接分配到 Server 層進(jìn)行篩選。篩選過(guò)程是先根據(jù) Index Key 的條件先在引擎層進(jìn)行初步篩選,然后得到對(duì)應(yīng)的主鍵值進(jìn)行回表查詢得到初篩的行記錄,傳入 Server 層進(jìn)行后續(xù)的篩選,在 Server 層的篩選因?yàn)闆](méi)有用到索引所以會(huì)進(jìn)行全表掃描。而索引下推的優(yōu)化就是將 Index Filter 的條件下推到引擎層,在使用? Index First Key 與 Index Last Key 進(jìn)行篩選時(shí),就帶上 Index Filter 的條件再次篩選,以此來(lái)過(guò)濾掉不符合條件的記錄對(duì)應(yīng)的主鍵值,減少回表的次數(shù),同時(shí)發(fā)給 Server 層的記錄也會(huì)更少,全表掃描篩選的效率也會(huì)變高。下面是未使用索引下推和使用索引下推的示意圖。
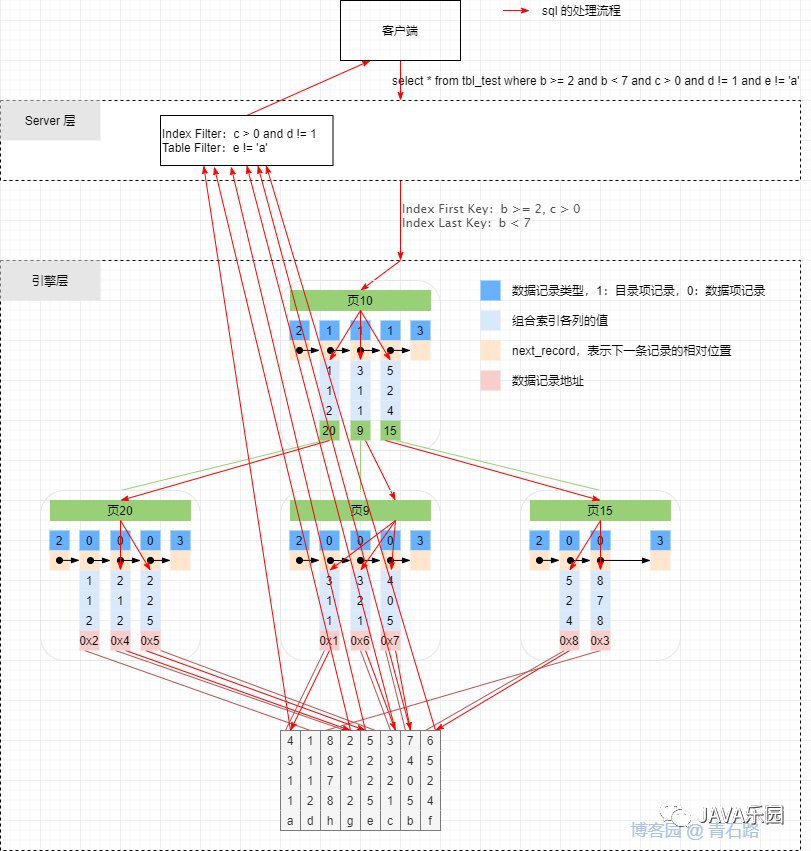
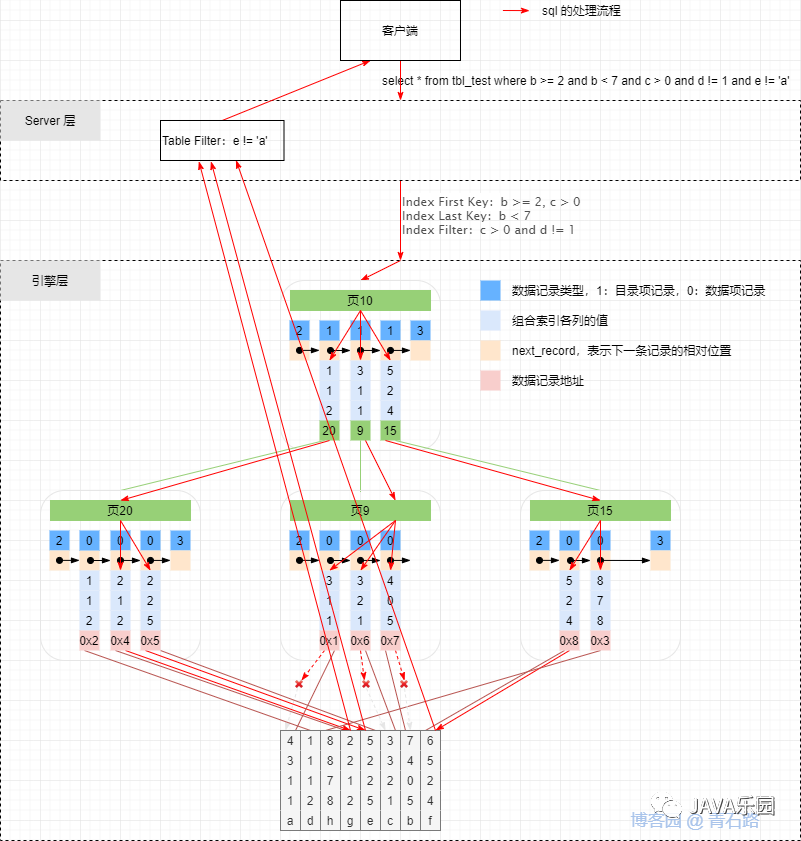
?從上面的分析來(lái)看,查詢的流程圖大致可以用下面這張圖來(lái)概括
?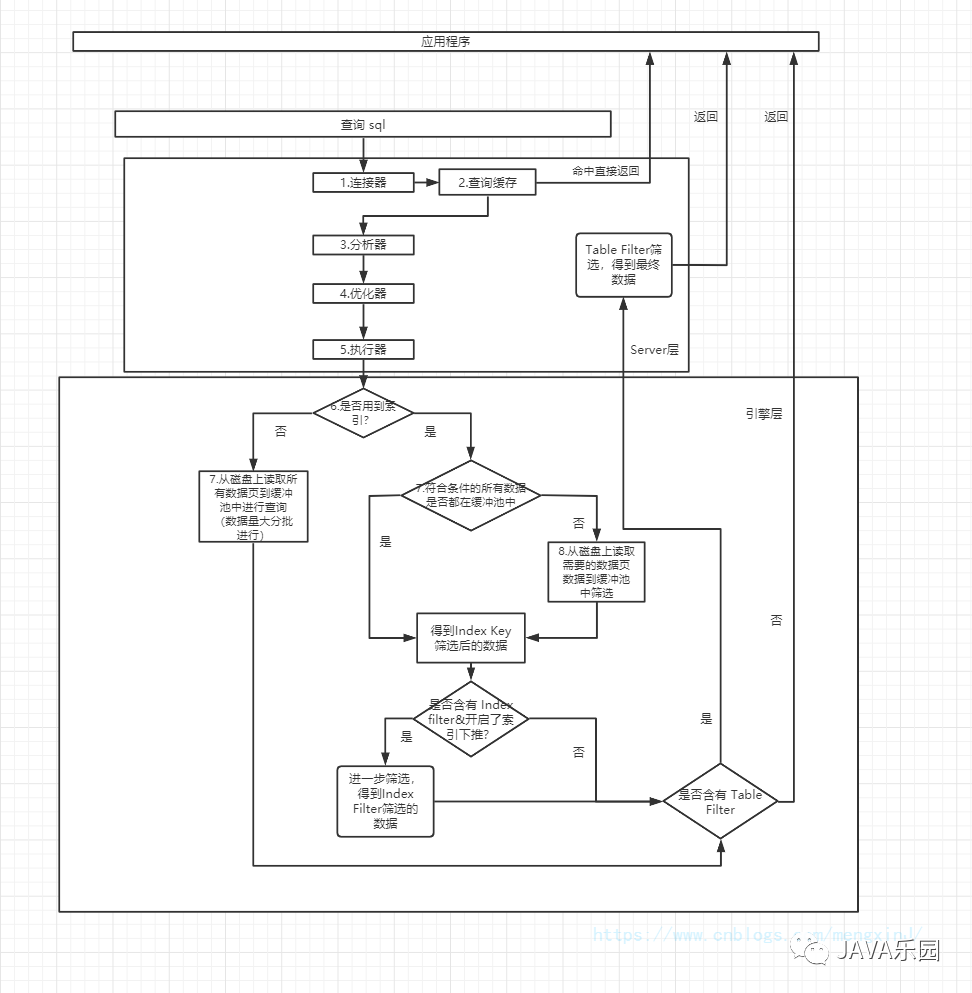
?這里要注意的是如果在一開(kāi)始沒(méi)有用到索引,會(huì)依次將磁盤上的數(shù)據(jù)頁(yè)讀取到緩沖池中進(jìn)行查詢。
source:?https://www.cnblogs.com/mengxinJ/p/14045520.html推薦閱讀:
完全整理 | 365篇高質(zhì)技術(shù)文章目錄整理
專注服務(wù)器后臺(tái)技術(shù)棧知識(shí)總結(jié)分享
歡迎關(guān)注交流共同進(jìn)步