
一個SQL的執(zhí)行過程詳解
鏈接:https://www.jianshu.com/p/e2926d6a808f
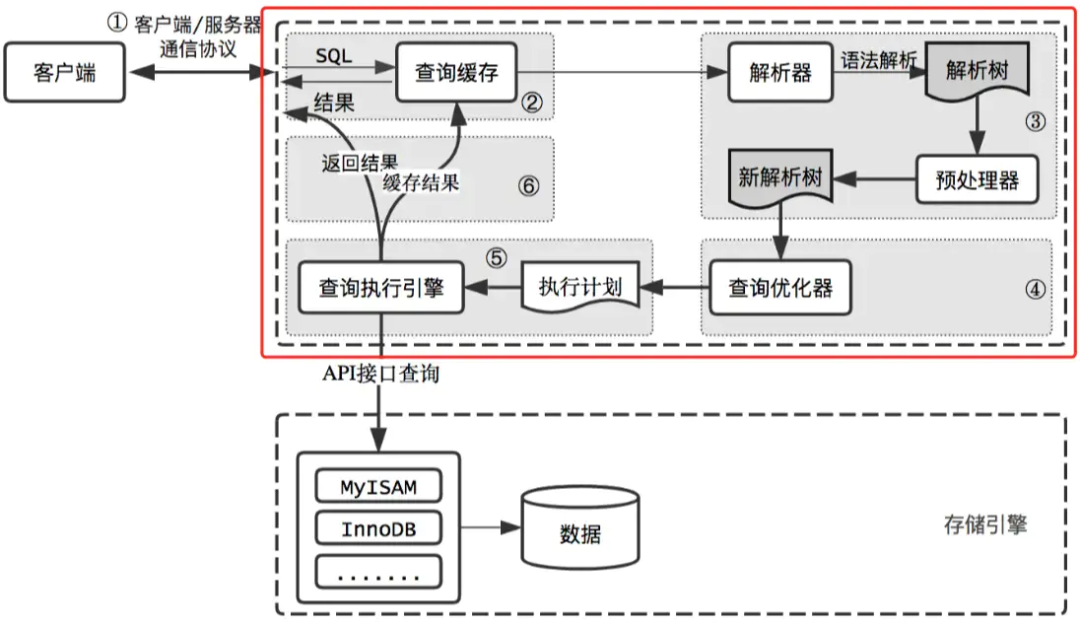
一、 組成部分
客戶端,如:php 的 pdo_mysql擴展。MySQL 服務(wù):
二、 大概流程
MySQL server 層的 連接器對來自客戶端的連接進行驗證,包含:MySQL server 層的 查詢緩存對客戶源原始SQL進行緩存命中檢測:命中則直接返回,未命中則進一步執(zhí)行查詢。MySQL server 層的
解析器對查詢語句進行解析,得到查詢語句的解析樹。MySQL server 層的
預(yù)處理器對解析樹進一步驗證。MySQL server 層的
優(yōu)化器將解析樹轉(zhuǎn)化為執(zhí)行計劃。MySQL server 層的
執(zhí)行器通過 API 與底層的存儲引擎進行交互,執(zhí)行執(zhí)行計劃。MySQL 存儲引擎 層得到執(zhí)行結(jié)果,返回給 MySQL server 層。MySQL server 層將結(jié)果交由
查詢緩存進行緩存,并返回給客戶端
三、 查詢緩存
關(guān)鍵邏輯:
`查詢緩存` 緩存了 `執(zhí)行計劃` 的完整結(jié)果,當(dāng)緩存命中時,直接返回緩存中的結(jié)果,從而跳過了 `解析-優(yōu)化-執(zhí)行` 的過程。
`查詢緩存` 基于不變的表結(jié)構(gòu)和表數(shù)據(jù),`當(dāng)表結(jié)構(gòu)或表數(shù)據(jù)發(fā)生變化時,其表上的所有緩存都將失效`。
`查詢緩存` 可以理解將 `執(zhí)行計劃` 的結(jié)果緩存在 hashtable 中,key 是 `客戶端發(fā)來的原始查詢sql` 的 hash 值,因此:
的 hash 值并不相同。即:`即使同一條SQL,如果大小寫、空格、單引號、雙引號、注釋等不同,都會使用不同的緩存 key`
因為在 `查詢緩存` 階段,還沒有進行 `解析器` 解析的工作,因此:`所有查詢都會嘗試去 get 緩存,但總是不命中`。
相關(guān)配置: 如果查詢結(jié)果比較大,超過了query_cache_min_res_unit的值,MySQL將一邊檢索結(jié)果,一邊進行保存結(jié)果。 根據(jù)自身情況設(shè)置合適的大小:太大會造成大量的 `內(nèi)存碎片`,太小又需要 `頻繁的申請內(nèi)存`。 `have_query_cache`,當(dāng)前的MYSQL版本是否支持“查詢緩存”功能。 `query_cache_limit`,能夠緩存的最大查詢結(jié)果,查詢結(jié)果大于該值時不會被緩存,默認(rèn)值是 1MB `query_cache_min_res_unit`,查詢緩存分配的最小塊(字節(jié))。默認(rèn)值是4096(4KB)。 `query_cache_size`,為緩存查詢結(jié)果分配的總內(nèi)存。 `query_cache_type`,默認(rèn)為on,可以緩存除了以 `select sql_no_cache` 開頭的所有查詢結(jié)果。 `query_cache_wlock_invalidate`,如果該表被鎖住,是否返回緩存中的數(shù)據(jù),默認(rèn)是關(guān)閉的。 優(yōu)缺點: 對于頻繁變動(`修改表結(jié)構(gòu)、新增、刪除、修改數(shù)據(jù)`)的表,由于一旦 `變動` 就會清除該表的所有緩存,導(dǎo)致:命中率極低,每次SQL還增加了 `查詢緩存` 的額外工作。 搜索公眾號互聯(lián)網(wǎng)架構(gòu)師回復(fù)“2T”,送你一份驚喜禮包。 參與 hash 計算的是客戶端發(fā)來的原始SQL,還未經(jīng)過 `解析器` 解析,`完全一樣` 的sql才能命中緩存。 `查詢緩存` 實質(zhì)上是緩存 `SQL的hash值` 和 `該SQL的查詢結(jié)果`,省去了大量重復(fù)SQL查詢的 `解析-優(yōu)化-執(zhí)行` 過程。 優(yōu)點:
四、 `解析器` 和 `預(yù)處理器`
解析器 和 預(yù)處理器 的工作主要包含:對
原始SQL進行語法解析,驗證語法規(guī)則,如:關(guān)鍵字是否正確
得到 `語法解析樹` 進一步驗證 語法解析樹,如:庫、表是否存在
調(diào)用函數(shù)、識別別名等
五、 優(yōu)化器
優(yōu)化器是基于Cost-Based Optimizer模型,預(yù)估每條執(zhí)行方式的成本,選擇成本最小的執(zhí)行方式,轉(zhuǎn)化為執(zhí)行計劃。選擇最優(yōu)的執(zhí)行方式比較好使,優(yōu)化器維護了一個執(zhí)行計劃緩存,當(dāng)緩存命中時,直接使用上次的執(zhí)行計劃。每種執(zhí)行方式的成本 cost預(yù)估包含幾個方面:`io_cost`,對IO操作的成本預(yù)估 `cpu_cost`,對CPU操作的成本預(yù)估 `import_cost`,對遠(yuǎn)程操作的成本預(yù)估 `mem_cost`,對內(nèi)存消耗的成本預(yù)估 Cost-Based Optimizer對復(fù)雜語句的成本預(yù)估會產(chǎn)生偏差,這時候就需要用到我們了,哈哈。
六、 存儲引擎
具體的 執(zhí)行計劃 如何執(zhí)行,依賴于各種不同的 存儲引擎 的索引算法,如:
B-Tree 從根節(jié)點開始,沿著向下的指針,找到存儲了行數(shù)據(jù)位置的葉子節(jié)點,再判斷是否滿足 覆蓋查詢,訪問行數(shù)據(jù)。Hash 則根據(jù)直接計算 hash 值,如果沖突,再遍歷鏈表。
七、 結(jié)果返回客戶端
增量、逐步返回 的過程。即:在查詢生成第一條結(jié)果時,MySQL就可以開始向客戶端逐步返回結(jié)果集了。正文結(jié)束
1.心態(tài)崩了!稅前2萬4,到手1萬4,年終獎扣稅方式1月1日起施行~
2.深圳一普通中學(xué)老師工資單曝光,秒殺程序員,網(wǎng)友:敢問是哪個學(xué)校畢業(yè)的?
3.從零開始搭建創(chuàng)業(yè)公司后臺技術(shù)棧
