
從零實現(xiàn)一個時序數(shù)據(jù)庫
時序數(shù)據(jù)庫(TSDB: Time Series Database)大多數(shù)時候都是為了滿足監(jiān)控場景的需求,這里先介紹兩個概念:
數(shù)據(jù)點(Point): 時序數(shù)據(jù)的數(shù)據(jù)點是一個包含 (Timestamp:int64, Value:float64) 的二元組。 時間線(Series): 不同標簽(Label)的組合稱為不同的時間線,如
series1: {"__name__": "netspeed", "host": "localhost", "iface": "eth0"}
series2: {"__name__": "netspeed", "host": "localhost", "iface": "eth1"}
Prometheus, InfluxDB, M3, TimescaleDB 都是時下流行的 TSDB。時序數(shù)據(jù)的壓縮算法很大程度上決定了 TSDB 的性能,以上幾個項目的實現(xiàn)都參考了 Fackbook 2015 年發(fā)表的論文《Gorilla: A fast, scalable, in-memory time series database》(http://www.vldb.org/pvldb/vol8/p1816-teller.pdf) 中提到的差值算法,該算法平均可以將 16 字節(jié)的數(shù)據(jù)點壓縮成 1.37 字節(jié)。
Who's mando?
Din Djarin, also known as "the Mandalorian" or simply "Mando," was a human male Mandalorian who worked as a famous bounty hunter during the New Republic Era.

What's mandodb?
mandodb(https://github.com/chenjiandongx/mandodb) 是我在學(xué)習(xí)過程中實現(xiàn)的一個最小化的 TSDB,從概念上來講它還算不上是一個完整的 TSDB,因為它:
沒有實現(xiàn)自己的查詢引擎(實現(xiàn)難度大) 缺少磁盤歸檔文件 Compact 操作(有空的話會實現(xiàn)) 沒有 WAL 作為災(zāi)備保證高可用(心情好的話會實現(xiàn))
mandodb 主要受到了兩個項目的啟發(fā)。本項目僅限于學(xué)習(xí)用途,未經(jīng)生產(chǎn)環(huán)境測試驗證!
nakabonne/tstorage prometheus/prometheus
prometheus 的核心開發(fā)者 Fabian Reinartz 寫了一篇文章 《Writing a Time Series Database from Scratch》(https://fabxc.org/tsdb/) 來介紹 prometheus TSDB 的演變過程,非常值得一讀,強烈推薦。
?? 數(shù)據(jù)模型 & API 文檔
數(shù)據(jù)模型定義
// Point 表示一個數(shù)據(jù)點 (ts, value) 二元組
type Point struct {
Ts int64 // in seconds
Value float64
}
// Label 代表一個標簽組合
type Label struct {
Name string
Value string
}
// Row 一行時序數(shù)據(jù) 包括數(shù)據(jù)點和標簽組合
type Row struct {
Metric string
Labels LabelSet
Point Point
}
// LabelSet 表示 Label 組合
type LabelSet []Label
// LabelMatcher Label 匹配器 支持正則
type LabelMatcher struct {
Name string
Value string
IsRegx bool
}
// LabelMatcherSet 表示 LabelMatcher 組合
type LabelMatcherSet []LabelMatcher
API
// InsertRows 寫數(shù)據(jù)
InsertRows(rows []*Row) error
// QueryRange 查詢時序數(shù)據(jù)點
QueryRange(metric string, lms LabelMatcherSet, start, end int64) ([]MetricRet, error)
// QuerySeries 查詢時序序列組合
QuerySeries(lms LabelMatcherSet, start, end int64) ([]map[string]string, error)
// QueryLabelValues 查詢標簽值
QueryLabelValues(label string, start, end int64) []string
?? 配置選項
配置項在初始化 TSDB 的時候設(shè)置。
// WithMetaSerializerType 設(shè)置 Metadata 數(shù)據(jù)的序列化類型
// 目前只提供了 BinaryMetaSerializer
WithMetaSerializerType(t MetaSerializerType) Option
// WithMetaBytesCompressorType 設(shè)置字節(jié)數(shù)據(jù)的壓縮算法
// 目前提供了
// * 不壓縮: NoopBytesCompressor(默認)
// * ZSTD: ZstdBytesCompressor
// * Snappy: SnappyBytesCompressor
WithMetaBytesCompressorType(t BytesCompressorType) Option
// WithOnlyMemoryMode 設(shè)置是否默認只存儲在內(nèi)存中
// 默認為 false
WithOnlyMemoryMode(memoryMode bool) Option
// WithEnabledOutdated 設(shè)置是否支持亂序?qū)懭?nbsp;此特性會增加資源開銷 但會提升數(shù)據(jù)完整性
// 默認為 true
WithEnabledOutdated(outdated bool) Option
// WithMaxRowsPerSegment 設(shè)置單 Segment 最大允許存儲的點數(shù)
// 默認為 19960412(夾雜私貨 ??)
WithMaxRowsPerSegment(n int64) Option
// WithDataPath 設(shè)置 Segment 持久化存儲文件夾
// 默認為 "."
WithDataPath(d string) Option
// WithRetention 設(shè)置 Segment 持久化數(shù)據(jù)保存時長
// 默認為 7d
WithRetention(t time.Duration) Option
// WithWriteTimeout 設(shè)置寫入超時閾值
// 默認為 30s
WithWriteTimeout(t time.Duration) Option
// WithLoggerConfig 設(shè)置日志配置項
// logger: github.com/chenjiandongx/logger
WithLoggerConfig(opt *logger.Options) Option
?? 用法示例
package main
import (
"fmt"
"time"
"github.com/chenjiandongx/mandodb"
)
func main() {
store := mandodb.OpenTSDB(
mandodb.WithOnlyMemoryMode(true),
mandodb.WithWriteTimeout(10*time.Second),
)
defer store.Close()
// 插入數(shù)據(jù)
_ = store.InsertRows([]*mandodb.Row{
{
Metric: "cpu.busy",
Labels: []mandodb.Label{
{Name: "node", Value: "vm1"},
{Name: "dc", Value: "gz-idc"},
},
Point: mandodb.Point{Ts: 1600000001, Value: 0.1},
},
{
Metric: "cpu.busy",
Labels: []mandodb.Label{
{Name: "node", Value: "vm2"},
{Name: "dc", Value: "sz-idc"},
},
Point: mandodb.Point{Ts: 1600000001, Value: 0.1},
},
})
time.Sleep(time.Millisecond)
// 時序數(shù)據(jù)查詢
data, _ := store.QueryRange("cpu.busy", nil, 1600000000, 1600000002)
fmt.Printf("data: %+v\n", data)
// output:
// data: [{Labels:{__name__="cpu.busy", dc="gz-idc", node="vm1"} Points:[{Ts:1600000001 Value:0.1}]}]
// 查詢 Series
// __name__ 是 metric 名稱在 TSDB 中的 Label Key
ser, _ := store.QuerySeries(
mandodb.LabelMatcherSet{{Name: "__name__", Value: "cpu.busy"}}, 1600000000, 1600000002)
for _, d := range ser {
fmt.Printf("data: %+v\n", d)
}
// output:
// data: map[__name__:cpu.busy dc:gz-idc node:vm1]
// data: map[__name__:cpu.busy dc:sz-idc node:vm2]
// 查詢標簽值
lvs := store.QueryLabelValues("node", 1600000000, 1600000002)
fmt.Printf("data: %+v\n", lvs)
// output:
// data: [vm1 vm2]
}
下面是我對這段時間學(xué)習(xí)內(nèi)容的整理,嘗試完整介紹如何從零開始實現(xiàn)一個小型的 TSDB。

我本身并沒有數(shù)據(jù)庫開發(fā)的背景,某些描述可能并不那么準確,所以歡迎 實名 diss 指正。
?? Gorilla 差值算法
Gorilla 論文 4.1 小節(jié)介紹了壓縮算法,先整體看一下壓縮方案,T/V 是緊挨存儲的,'0'/'10'/'11' 表示控制位。
Figure: Gorilla 壓縮算法
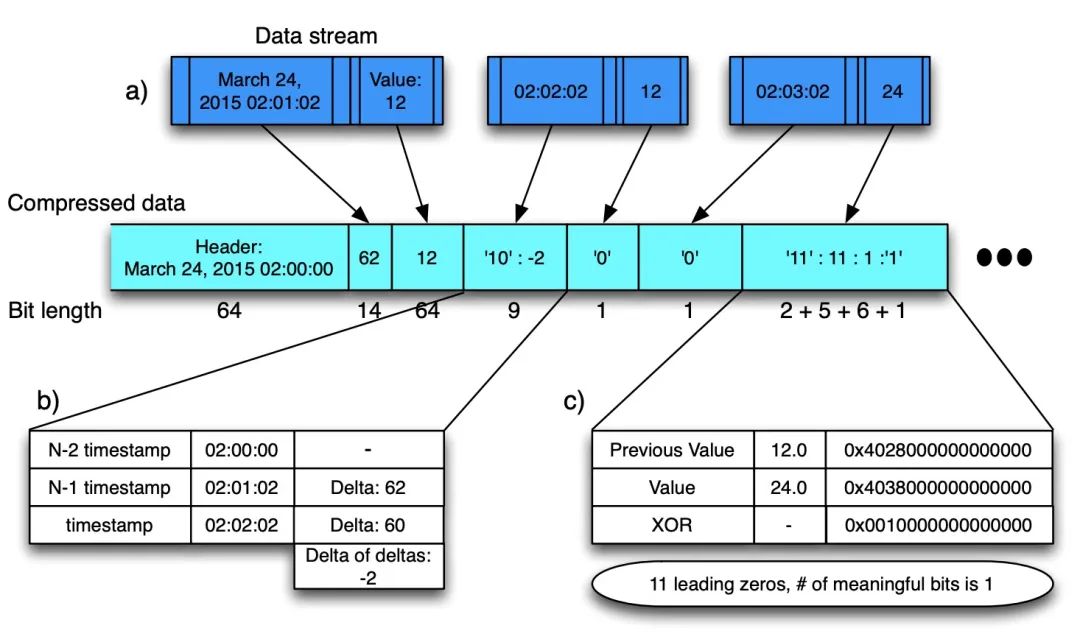
Timestamp DOD 壓縮:
在時序的場景中,每個時序點都有一個對應(yīng)的 Timestamp,一條時序序列中相鄰數(shù)據(jù)點的間隔是有規(guī)律可循的。一般來講,監(jiān)控數(shù)據(jù)的采集都是會以固定的時間間隔進行的,所以就可以用差值來記錄時間間隔,更進一步,我們可以用差值的差值來記錄以此來減少存儲空間。
t1: 1627401800; t2: 1627401810; t3: 1627401820; t4: 1627401830
--------------------------------------------------------------
// 差值:delta
t1: 1627401800; (t2-t1)d1: 10; (t3-t2)d2: 10; (t4-t3)d3: 10;
--------------------------------------------------------------
// 差值的差值:delta of delta
t1: 1627401800; dod1: 0; dod2: 0; dod3: 0;
實際環(huán)境中當然不可能每個間隔都這么均勻,由于網(wǎng)絡(luò)延遲等其他原因,差值會有波動。
Value XOR 壓縮:
Figure: IEEE 浮點數(shù)以及 XOR 計算結(jié)果
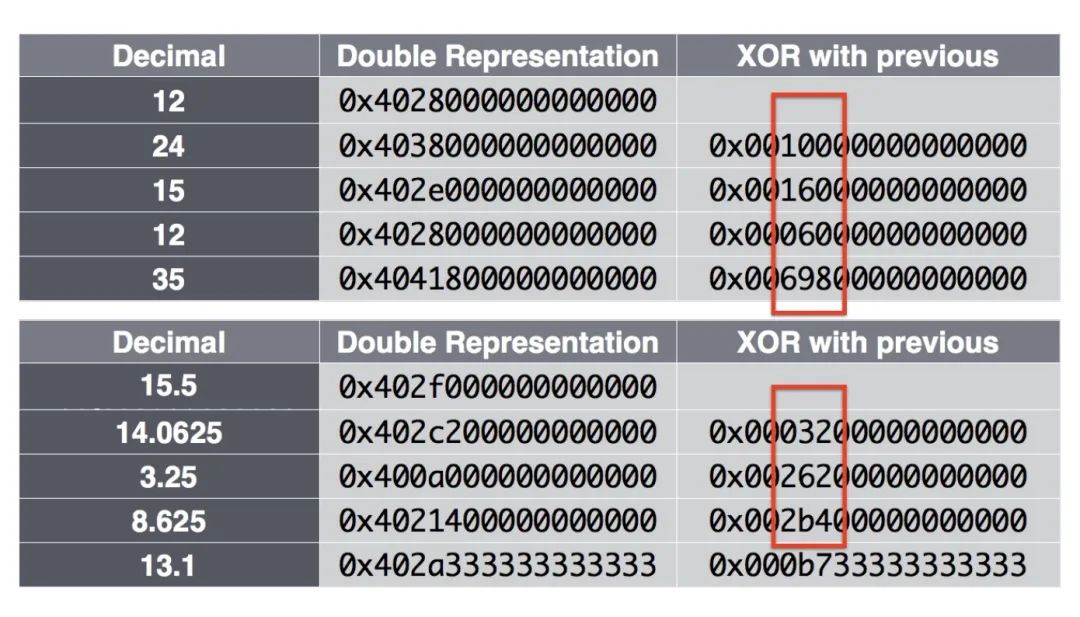
當兩個數(shù)據(jù)點數(shù)值值比較接近的話,通過異或操作計算出來的結(jié)果是比較相似的,利用這點就可以通過記錄前置零和后置零個數(shù)以及數(shù)值部分來達到壓縮空間的目的。
下面通過算法實現(xiàn)來介紹,代碼來自項目 dgryski/go-tsz。代碼完全按照論文中給出的步驟來實現(xiàn)。
// New 初始化 block 這里會將第一個原始時間戳寫入到 block 中
func New(t0 uint32) *Series {
s := Series{
T0: t0,
leading: ^uint8(0),
}
s.bw.writeBits(uint64(t0), 32)
return &s
}
// Push 負責(zé)寫入時序數(shù)據(jù)
func (s *Series) Push(t uint32, v float64) {
// ....
// 如果是第一個數(shù)據(jù)點的話寫入原始數(shù)據(jù)后直接返回
if s.t == 0 {
s.t = t
s.val = v
s.tDelta = t - s.T0 // 實際上這里為 0
// The block header stores the starting time stamp, t-1(前一個時間戳),
// which is aligned to a two hour window; the first time
// stamp, t0, in the block is stored as a delta from t?1 in 14 bits.
// 用 14 個 bit 寫入時間戳差值
s.bw.writeBits(uint64(s.tDelta), 14)
// 原始數(shù)據(jù)點完整寫入
s.bw.writeBits(math.Float64bits(v), 64)
return
}
tDelta := t - s.t
dod := int32(tDelta - s.tDelta) // 計算差值的差值 Detla of Delta
// 下面開始就處理非第一個數(shù)據(jù)點的情況了
switch {
// If D is zero, then store a single ‘0’ bit
// 如果是零的話 那直接用 '0' 一個字節(jié)就可以直接表示
case dod == 0:
s.bw.writeBit(zero)
// If D is between [-63, 64], store ‘10’ followed by the value (7 bits)
case -63 <= dod && dod <= 64:
s.bw.writeBits(0x02, 2) // 控制位 '10'
s.bw.writeBits(uint64(dod), 7) // 7bits 可以表示 [-63, 64] 的范圍
// If D is between [-255, 256], store ‘110’ followed by the value (9 bits)
case -255 <= dod && dod <= 256:
s.bw.writeBits(0x06, 3) // 控制位 '110'
s.bw.writeBits(uint64(dod), 9)
// if D is between [-2047, 2048], store ‘1110’ followed by the value (12 bits)
case -2047 <= dod && dod <= 2048:
s.bw.writeBits(0x0e, 4) // 控制位 '1110'
s.bw.writeBits(uint64(dod), 12)
// Otherwise store ‘1111’ followed by D using 32 bits
default:
s.bw.writeBits(0x0f, 4) // 其余情況控制位均用 '1111'
s.bw.writeBits(uint64(dod), 32)
}
// 到這里 (T, V) 中的時間戳已經(jīng)寫入完畢了 接下來是寫 V 部分
// 先計算兩個值的異或結(jié)果
vDelta := math.Float64bits(v) ^ math.Float64bits(s.val)
// If XOR with the previous is zero (same value), store single ‘0’ bit
// 如果前后兩個值相等的話 直接用 '0' 1 個 bit 就可以表示
// 所以如果上報的時序數(shù)據(jù)是 1 或者 0 這種的話 占用的內(nèi)存會非常少
// zero = '0'; one = '1'
if vDelta == 0 {
s.bw.writeBit(zero)
} else { // 非 0 情況那就要把控制位置為 1
s.bw.writeBit(one)
// 計算前置 0 和后置 0
leading := uint8(bits.LeadingZeros64(vDelta))
trailing := uint8(bits.TrailingZeros64(vDelta))
// clamp number of leading zeros to avoid overflow when encoding
if leading >= 32 {
leading = 31
}
// (Control bit ‘0’) If the block of meaningful bits
// falls within the block of previous meaningful bits,
// i.e., there are at least as many leading zeros and
// as many trailing zeros as with the previous value,
// use that information for the block position and
// just store the meaningful XORed value.
// 如果前置 0 不小于上一個值計算的異或結(jié)果的前置 0 且后置 0 也不小于上一個值計算的異或結(jié)果的后置 0
if s.leading != ^uint8(0) && leading >= s.leading && trailing >= s.trailing { // => 控制位 '10'
s.bw.writeBit(zero)
// 記錄異或值非零部分
s.bw.writeBits(vDelta>>s.trailing, 64-int(s.leading)-int(s.trailing))
} else { // => 控制位 '11'
// (Control bit ‘1’) Store the length of the number
// of leading zeros in the next 5 bits, then store the
// length of the meaningful XORed value in the next
// 6 bits. Finally store the meaningful bits of the XORed value.
s.leading, s.trailing = leading, trailing
// 其他情況控制位置為 1 并用接下來的 5bits 記錄前置 0 個數(shù)
s.bw.writeBit(one)
s.bw.writeBits(uint64(leading), 5)
// 然后用接下來的 6bits 記錄異或差值中的非零部分
sigbits := 64 - leading - trailing
s.bw.writeBits(uint64(sigbits), 6)
s.bw.writeBits(vDelta>>trailing, int(sigbits))
}
}
// 狀態(tài)更新 至此(T, V)均已被壓縮寫入到內(nèi)存中
s.tDelta = tDelta
s.t = t
s.val = v
}
// 每個 block 的結(jié)尾會使用特殊標記用于標識
func finish(w *bstream) {
// write an end-of-stream record
w.writeBits(0x0f, 4)
w.writeBits(0xffffffff, 32)
w.writeBit(zero)
}
論文給出了不同 case 的 buckets 占比分布。
Figure: Timestamp buckets distribution
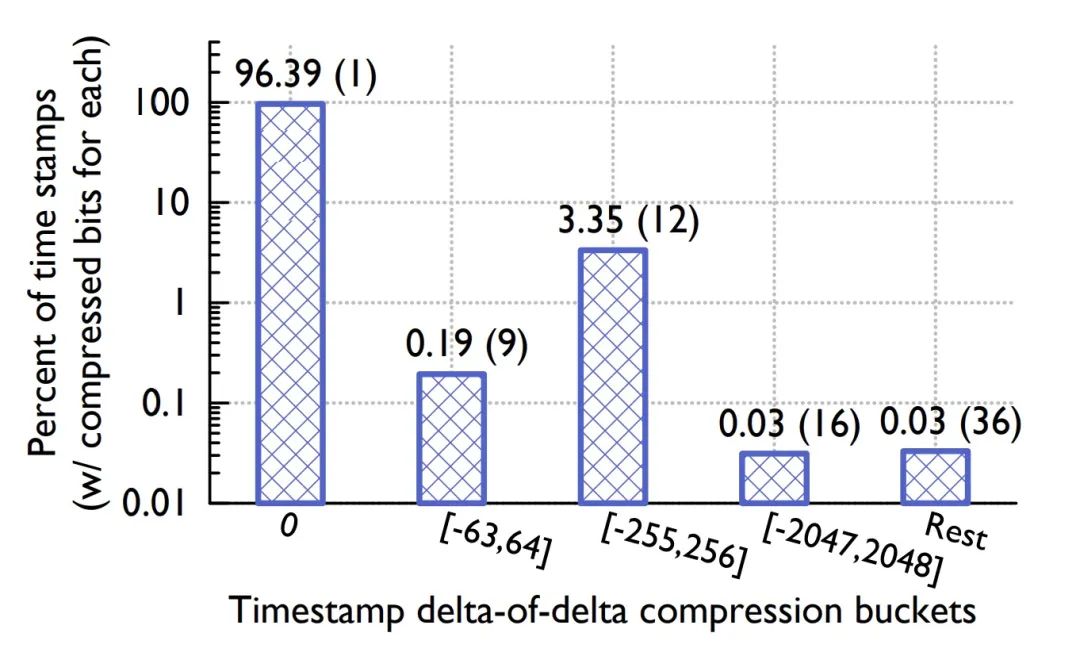
Figure: Value buckets distribution
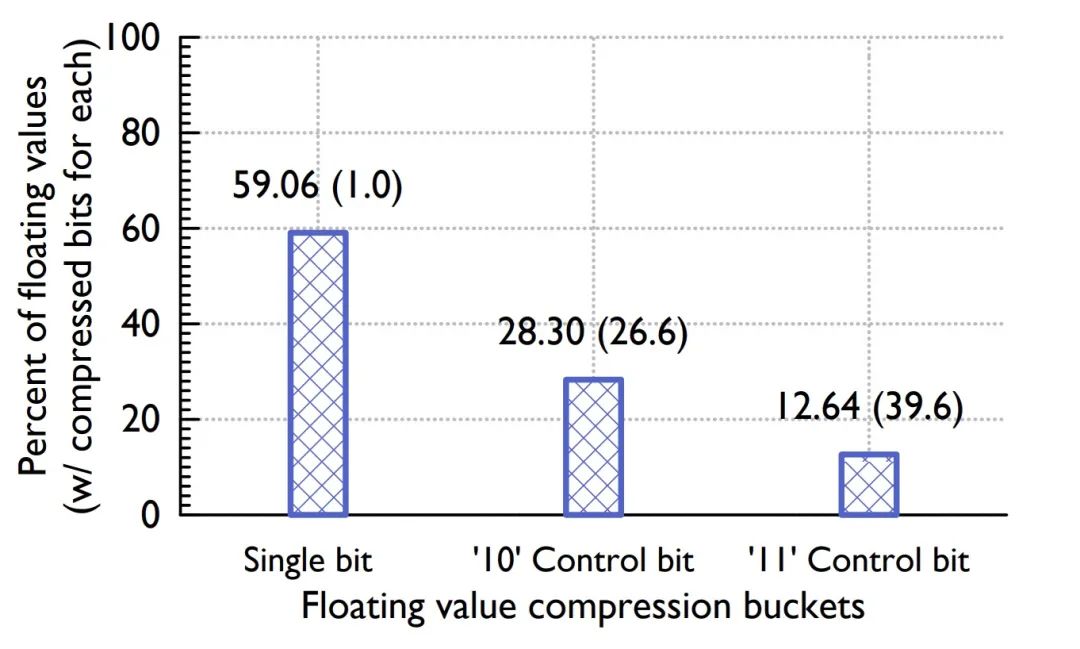
Timestamp buckets 中,前后兩個時間戳差值相同的比例高達 96.39%,而在 Value buckets 中只用一個控制位的占比也達到了 59.06%,可見其壓縮比之高。
論文還給出了一個重要結(jié)論,數(shù)據(jù)壓縮比隨著時間的增長而增長,并在 120 個點的時候開始收斂到一個最佳值。
Figure: 壓縮率曲線
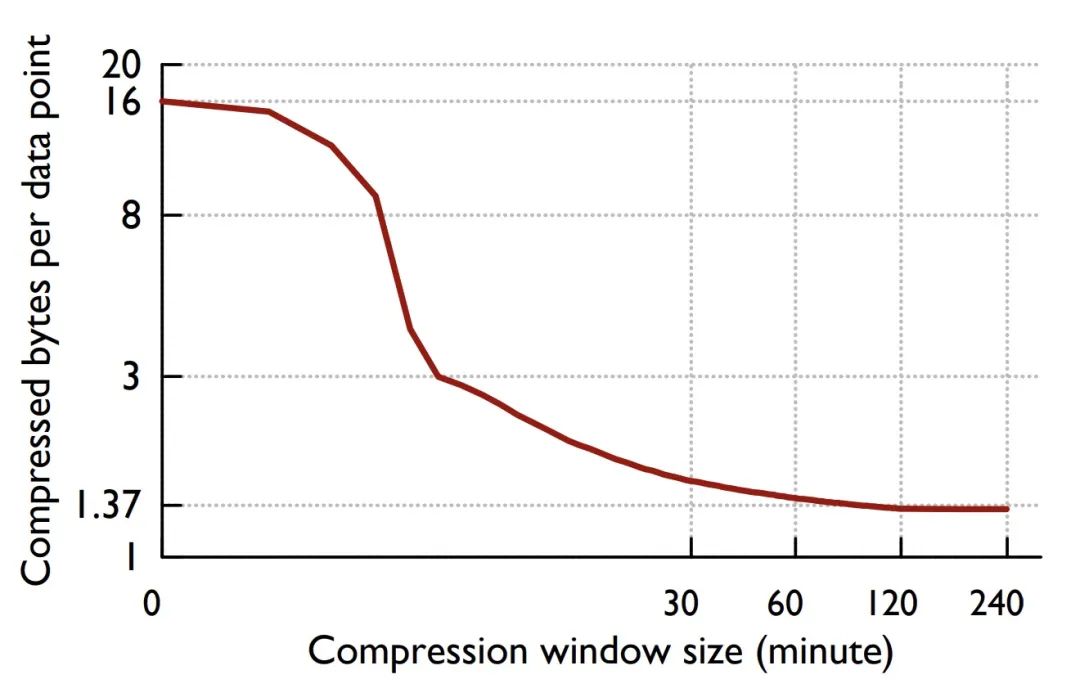
Gorilla 差值算法也應(yīng)用于我的另外一個項目 chenjiandongx/tszlist,一種時序數(shù)據(jù)線程安全鏈表。
?? 數(shù)據(jù)寫入
時序數(shù)據(jù)具有「垂直寫,水平查」的特性,即同一時刻有多條時間線的數(shù)據(jù)不斷被追加。但查詢的時候往往是查某條時間線持續(xù)一段時間內(nèi)的數(shù)據(jù)點。
series
^
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="GET"}
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="POST"}
│ . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . . . {__name__="errors_total", method="POST"}
│ . . . . . . . . . . . . . . . . . {__name__="errors_total", method="GET"}
│ . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . .
v
<-------------------- time --------------------->
時序數(shù)據(jù)跟時間是強相關(guān)的(不然還叫時序數(shù)據(jù)???),即大多數(shù)查詢其實只會查詢最近時刻的數(shù)據(jù),這里的「最近」是個相對概念。所以沒必要維護一條時間線的完整生命周期,特別是在 Kubernetes 這種云原生場景,Pod 隨時有可能會被擴縮容,也就意味著一條時間線的生命周期可能會很短。如果我們一直記錄著所有的時間線的索引信息,那么隨著時間的推移,數(shù)據(jù)庫里的時間線的數(shù)量會呈現(xiàn)一個線性增長的趨勢 ??,會極大地影響查詢效率。
這里引入一個概念「序列分流」,這個概念描述的是一組時間序列變得不活躍,即不再接收數(shù)據(jù)點,取而代之的是有一組新的活躍的序列出現(xiàn)的場景。
series
^
│ . . . . . .
│ . . . . . .
│ . . . . . .
│ . . . . . . .
│ . . . . . . .
│ . . . . . . .
│ . . . . . .
│ . . . . . .
│ . . . . .
│ . . . . .
│ . . . . .
v
<-------------------- time --------------------->
我們將多條時間線的數(shù)據(jù)按一定的時間跨度切割成多個小塊,每個小塊本質(zhì)就是一個獨立小型的數(shù)據(jù)庫,這種做法另外一個優(yōu)勢是清除過期操作的時候非常方便,只要將整個塊給刪了就行 ??(梭哈是一種智慧)。內(nèi)存中保留最近兩個小時的熱數(shù)據(jù)(Memory Segment),其余數(shù)據(jù)持久化到磁盤(Disk Segment)。
Figure: 序列分塊
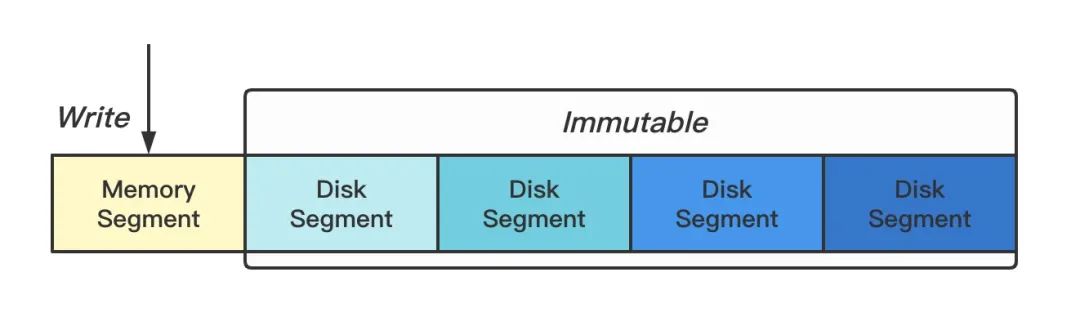
DiskSegment 使用的是 AVL Tree 實現(xiàn)的列表,可在插入時排序。為什么不用更加高大上的紅黑樹?因為不好實現(xiàn)...

當 Memory Segment 達到歸檔條件的時候,會創(chuàng)建一個新的內(nèi)存塊并異步將剛歸檔的塊寫入到磁盤,同時會使用 mmap 將磁盤文件句柄映射到內(nèi)存中。代碼實現(xiàn)如下。
func (tsdb *TSDB) getHeadPartition() (Segment, error) {
tsdb.mut.Lock()
defer tsdb.mut.Unlock()
if tsdb.segs.head.Frozen() {
head := tsdb.segs.head
go func() {
tsdb.wg.Add(1)
defer tsdb.wg.Done()
tsdb.segs.Add(head)
t0 := time.Now()
dn := dirname(head.MinTs(), head.MaxTs())
if err := writeToDisk(head.(*memorySegment)); err != nil {
logger.Errorf("failed to flush data to disk, %v", err)
return
}
fname := path.Join(dn, "data")
mf, err := mmap.OpenMmapFile(fname)
if err != nil {
logger.Errorf("failed to make a mmap file %s, %v", fname, err)
return
}
tsdb.segs.Remove(head)
tsdb.segs.Add(newDiskSegment(mf, dn, head.MinTs(), head.MaxTs()))
logger.Infof("write file %s take: %v", fname, time.Since(t0))
}()
tsdb.segs.head = newMemorySegment()
}
return tsdb.segs.head, nil
}
Figure: Memory Segment 兩部分數(shù)據(jù)

寫入的時候支持數(shù)據(jù)時間回撥,也就是支持有限的亂序數(shù)據(jù)寫入,實現(xiàn)方案是在內(nèi)存中對還沒歸檔的每條時間線維護一個鏈表(同樣使用 AVL Tree 實現(xiàn)),當數(shù)據(jù)點的時間戳不是遞增的時候存儲到鏈表中,查詢的時候會將兩部分數(shù)據(jù)合并查詢,持久化的時候也會將兩者合并寫入。
?? Mmap 內(nèi)存映射
mmap 是一種將磁盤文件映射到進程的虛擬地址空間來實現(xiàn)對文件讀取和修改操作的技術(shù)。
從 Linux 角度來看,操作系統(tǒng)的內(nèi)存空間被分為「內(nèi)核空間」和「用戶空間」兩大部分,其中內(nèi)核空間和用戶空間的空間大小、操作權(quán)限以及核心功能都不相同。這里的內(nèi)核空間是指操作系統(tǒng)本身使用的內(nèi)存空間,而用戶空間則是提供給各個進程使用的內(nèi)存空間。由于用戶進程不具有訪問內(nèi)核資源的權(quán)限,例如訪問硬件資源,因此當一個用戶進程需要使用內(nèi)核資源的時候,就需要通過 系統(tǒng)調(diào)用 來完成。

虛擬內(nèi)存細節(jié)可以閱讀 《虛擬內(nèi)存精粹》 這篇文章。
Figure: 常規(guī)文件操作和 mmap 操作的區(qū)別
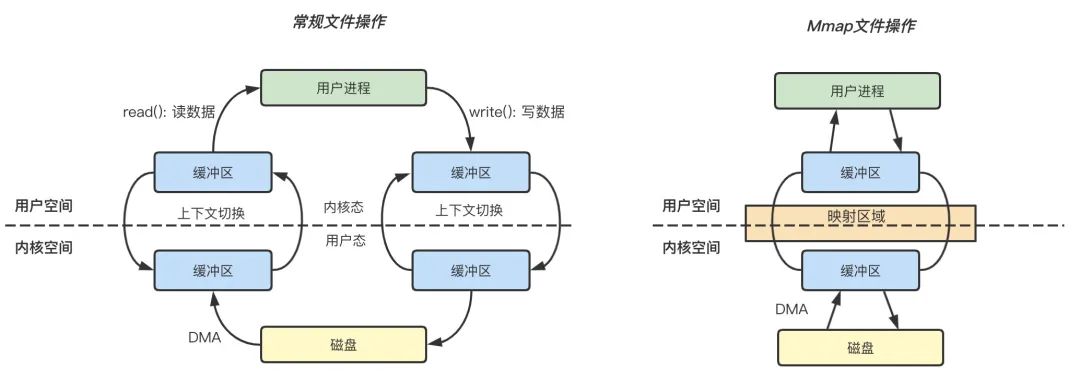
常規(guī)文件操作
讀文件: 用戶進程首先執(zhí)行 read(2) 系統(tǒng)調(diào)用,會進行系統(tǒng)上下文環(huán)境切換,從用戶態(tài)切換到內(nèi)核態(tài),之后由 DMA 將文件數(shù)據(jù)從磁盤讀取到內(nèi)核緩沖區(qū),再將內(nèi)核空間緩沖區(qū)的數(shù)據(jù)復(fù)制到用戶空間的緩沖區(qū)中,最后 read(2) 系統(tǒng)調(diào)用返回,進程從內(nèi)核態(tài)切換到用戶態(tài),整個過程結(jié)束。
寫文件: 用戶進程發(fā)起 write(2) 系統(tǒng)調(diào)用,從用戶態(tài)切換到內(nèi)核態(tài),將數(shù)據(jù)從用戶空間緩沖區(qū)復(fù)制到內(nèi)核空間緩沖區(qū),接著 write(2) 系統(tǒng)調(diào)用返回,同時進程從內(nèi)核態(tài)切換到用戶態(tài),數(shù)據(jù)從內(nèi)核緩沖區(qū)寫入到磁盤,整個過程結(jié)束。
mmap 操作
mmap 內(nèi)存映射的實現(xiàn)過程,總的來說可以分為三個階段:
進程啟動映射過程,并在虛擬地址空間中為映射創(chuàng)建虛擬映射區(qū)域。 執(zhí)行內(nèi)核空間的系統(tǒng)調(diào)用函數(shù) mmap,建立文件物理地址和進程虛擬地址的一一映射關(guān)系。 進程發(fā)起對這片映射空間的訪問,引發(fā)缺頁異常,實現(xiàn)文件內(nèi)容到物理內(nèi)存的拷貝。
?? 小結(jié)
常規(guī)文件操作為了提高讀寫效率和保護磁盤,使用了頁緩存機制。這樣造成讀文件時需要先將文件頁從磁盤拷貝到頁緩存中,由于頁緩存處在內(nèi)核空間,不能被用戶進程直接尋址,所以還需要將頁緩存中數(shù)據(jù)頁再次拷貝到內(nèi)存對應(yīng)的用戶空間中。這樣,通過了兩次數(shù)據(jù)拷貝過程,才能完成進程對文件內(nèi)容的獲取任務(wù)。寫操作也是一樣,待寫入的 buffer 在內(nèi)核空間不能直接訪問,必須要先拷貝至內(nèi)核空間對應(yīng)的主存,再寫回磁盤中(延遲寫回),也是需要兩次數(shù)據(jù)拷貝。
而使用 mmap 操作文件,創(chuàng)建新的虛擬內(nèi)存區(qū)域和建立文件磁盤地址和虛擬內(nèi)存區(qū)域映射這兩步,沒有任何文件拷貝操作。而之后訪問數(shù)據(jù)時發(fā)現(xiàn)內(nèi)存中并無數(shù)據(jù)而發(fā)起的缺頁異常過程,可以通過已經(jīng)建立好的映射關(guān)系,只使用一次數(shù)據(jù)拷貝,就從磁盤中將數(shù)據(jù)傳入內(nèi)存的用戶空間中,供進程使用。

?? 總而言之,常規(guī)文件操作需要從磁盤到頁緩存再到用戶主存的兩次數(shù)據(jù)拷貝。而 mmap 操控文件只需要從磁盤到用戶主存的一次數(shù)據(jù)拷貝過程。mmap 的關(guān)鍵點是實現(xiàn)了「用戶空間」和「內(nèi)核空間」的數(shù)據(jù)直接交互而省去了不同空間數(shù)據(jù)復(fù)制的開銷。
?? 索引設(shè)計
TSDB 的查詢,是通過 Label 組合來鎖定到具體的時間線進而確定分塊偏移檢索出數(shù)據(jù)。
Sid(MetricHash/-/LabelHash) 是一個 Series 的唯一標識。 Label(Name/-/Value) => vm="node1"; vm="node2"; iface="eth0"。
在傳統(tǒng)的關(guān)系型數(shù)據(jù)庫,索引設(shè)計可能是這樣的。
| Sid(主鍵) | Label1 | Label2 | Label3 | Label4 | ... | LabelN |
|---|---|---|---|---|---|---|
| sid1 | × | × | × | ... | × | |
| sid2 | × | × | × | ... | × | |
| sid3 | × | × | × | ... | × | |
| sid4 | × | × | × | ... | × |
時序數(shù)據(jù)是 NoSchema 的,沒辦法提前建表和定義數(shù)據(jù)模型 ??,因為我們要支持用戶上報任意 Label 組合的數(shù)據(jù),這樣的話就沒辦法進行動態(tài)的擴展了。或許你會靈光一現(xiàn) ?,既然這樣,那把 Labels 放一個字段拼接起來不就可以無限擴展啦,比如下面這個樣子。
| Sid(主鍵) | Labels |
|---|---|
| sid1 | label1, label2, label3, ... |
| sid2 | label2, label3, label5, ... |
| sid3 | label4, label6, label9, ... |
| sid4 | label2, label3, label7, ... |
喲嚯,乍一看沒毛病,靚仔竊喜。

不對,有問題 ??,要定位到其中的某條時間線,那我是不是得全表掃描一趟。而且這種設(shè)計還有另外一個弊病,就是會導(dǎo)致內(nèi)存激增,Label 的 Name 和 Value 都可能是特別長的字符串。
那怎么辦呢(?? 靚仔沉默...),剎那間我的腦中閃過一個帥氣的身影,沒錯,就是你,花澤類「只要倒立眼淚就不會流出來」。

我悟了!要學(xué)會逆向思維 ??,把 Label 當做主鍵,Sid 當做其字段不就好了。這其實有點類似于 ElasticSearch 中的倒排索引,主鍵為 Keyword,字段為 DocumentID。索引設(shè)計如下。
| Label(主鍵) | Sids |
|---|---|
| label1: {vm="node1"} | sid1, sid2, sid3, ... |
| label2: {vm="node2"} | sid2, sid3, sid5, ... |
| label3: {iface="eth0"} | sid3, sid5, sid9, ... |
| label4: {iface="eth1"} | sid2, sid3, sid7, ... |
Label 作為主鍵時會建立索引(Hashkey),查找的效率可視為 O(1),再根據(jù)鎖定的 Label 來最終確定想要的 Sid。舉個例子,我們想要查找 {vm="node1", iface="eth0"} 的時間線的話就可以快速定位到 Sids(忽略其他 ... sid)。
sid1; sid2; sid3
sid2; sid3; sid5
兩者求一個交集,就可以得到最終要查詢的 Sid 為 sid2 和 sid3。?? Nice!
假設(shè)我們的查詢只支持相等匹配的話,格局明顯就小了 ??。查詢條件是 {vm=~"node*", iface="eth0"} 腫么辦?對 label1、label2、label3 和 label4 一起求一個并集嗎?顯然不是,因為這樣算的話那結(jié)果就是 sid3。
厘清關(guān)系就不難看出,只要對相同的 Label Name 做并集然后再對不同的 Label Name 求交集就可以了。這樣算的正確結(jié)果就是 sid3 和 sid5。實現(xiàn)的時候用到了 Roaring Bitmap,一種優(yōu)化的位圖算法。
Memory Segment 索引匹配
func (mim *memoryIndexMap) MatchSids(lvs *labelValueSet, lms LabelMatcherSet) []string {
// ...
sids := newMemorySidSet()
var got bool
for i := len(lms) - 1; i >= 0; i-- {
tmp := newMemorySidSet()
vs := lvs.Match(lms[i])
// 對相同的 Label Name 求并集
for _, v := range vs {
midx := mim.idx[joinSeparator(lms[i].Name, v)]
if midx == nil || midx.Size() <= 0 {
continue
}
tmp.Union(midx.Copy())
}
if tmp == nil || tmp.Size() <= 0 {
return nil
}
if !got {
sids = tmp
got = true
continue
}
// 對不同的 Label Name 求交集
sids.Intersection(tmp.Copy())
}
return sids.List()
}
Disk Segment 索引匹配
func (dim *diskIndexMap) MatchSids(lvs *labelValueSet, lms LabelMatcherSet) []uint32 {
// ...
lst := make([]*roaring.Bitmap, 0)
for i := len(lms) - 1; i >= 0; i-- {
tmp := make([]*roaring.Bitmap, 0)
vs := lvs.Match(lms[i])
// 對相同的 Label Name 求并集
for _, v := range vs {
didx := dim.label2sids[joinSeparator(lms[i].Name, v)]
if didx == nil || didx.set.IsEmpty() {
continue
}
tmp = append(tmp, didx.set)
}
union := roaring.ParOr(4, tmp...)
if union.IsEmpty() {
return nil
}
lst = append(lst, union)
}
// 對不同的 Label Name 求交集
return roaring.ParAnd(4, lst...).ToArray()
}
然而,確定相同的 LabelName 也是一個問題,因為 Label 本身就代表著 Name:Value,難不成我還要遍歷所有 label 才能確定嘛,這不就又成了全表掃描???

沒有什么問題是一個索引解決不了的,如果有,那就再增加一個索引。--- 魯迅。

只要我們保存 Label 的 Name 對應(yīng)的 Value 列表的映射關(guān)系即可高效解決這個問題。
| LabelName | LabelValue |
|---|---|
| vm | node1, node2, ... |
| iface | eth0, eth1, ... |
還是上面的 {vm=~"node1|node2", iface="eth0"} 查詢,第一步通過正則匹配確定匹配到 node1, node2,第二步匹配到 eth0,再將 LabelName 和 LabelValue 一拼裝,Label 就出來了,?? 完事!
橋豆麻袋!還有一個精彩的正則匹配優(yōu)化算法沒介紹。

fastRegexMatcher 是一種優(yōu)化的正則匹配器,算法來自 Prometheus。
// 思路就是盡量先執(zhí)行前綴匹配和后綴匹配 能不用正則就不用正則
// 如 label 表達式為 {vm="node*"}
// 而我們此時內(nèi)存中有 vm=node1, vm=node2, vm=foo, vm=bar,那這個時候只需要前綴匹配就能直接把 vm=foo,vm=bar 給過濾了
// 畢竟前綴匹配和后綴匹配的執(zhí)行效率還是比正則高不少的
type fastRegexMatcher struct {
re *regexp.Regexp
prefix string
suffix string
contains string
}
func newFastRegexMatcher(v string) (*fastRegexMatcher, error) {
re, err := regexp.Compile("^(?:" + v + ")$")
if err != nil {
return nil, err
}
parsed, err := syntax.Parse(v, syntax.Perl)
if err != nil {
return nil, err
}
m := &fastRegexMatcher{
re: re,
}
if parsed.Op == syntax.OpConcat {
m.prefix, m.suffix, m.contains = optimizeConcatRegex(parsed)
}
return m, nil
}
// optimizeConcatRegex returns literal prefix/suffix text that can be safely
// checked against the label value before running the regexp matcher.
func optimizeConcatRegex(r *syntax.Regexp) (prefix, suffix, contains string) {
sub := r.Sub
// We can safely remove begin and end text matchers respectively
// at the beginning and end of the regexp.
if len(sub) > 0 && sub[0].Op == syntax.OpBeginText {
sub = sub[1:]
}
if len(sub) > 0 && sub[len(sub)-1].Op == syntax.OpEndText {
sub = sub[:len(sub)-1]
}
if len(sub) == 0 {
return
}
// Given Prometheus regex matchers are always anchored to the begin/end
// of the text, if the first/last operations are literals, we can safely
// treat them as prefix/suffix.
if sub[0].Op == syntax.OpLiteral && (sub[0].Flags&syntax.FoldCase) == 0 {
prefix = string(sub[0].Rune)
}
if last := len(sub) - 1; sub[last].Op == syntax.OpLiteral && (sub[last].Flags&syntax.FoldCase) == 0 {
suffix = string(sub[last].Rune)
}
// If contains any literal which is not a prefix/suffix, we keep the
// 1st one. We do not keep the whole list of literals to simplify the
// fast path.
for i := 1; i < len(sub)-1; i++ {
if sub[i].Op == syntax.OpLiteral && (sub[i].Flags&syntax.FoldCase) == 0 {
contains = string(sub[i].Rune)
break
}
}
return
}
func (m *fastRegexMatcher) MatchString(s string) bool {
if m.prefix != "" && !strings.HasPrefix(s, m.prefix) {
return false
}
if m.suffix != "" && !strings.HasSuffix(s, m.suffix) {
return false
}
if m.contains != "" && !strings.Contains(s, m.contains) {
return false
}
return m.re.MatchString(s)
}
?? 存儲布局
既然是數(shù)據(jù)庫,那么自然少不了數(shù)據(jù)持久化的特性。了解完索引的設(shè)計,再看看落到磁盤的存儲布局就很清晰了。先跑個示例程序?qū)懭胍恍?shù)據(jù)熱熱身。
package main
import (
"fmt"
"math/rand"
"strconv"
"time"
"github.com/chenjiandongx/mandodb"
"github.com/satori/go.uuid"
)
// 模擬一些監(jiān)控指標
var metrics = []string{
"cpu.busy", "cpu.load1", "cpu.load5", "cpu.load15", "cpu.iowait",
"disk.write.ops", "disk.read.ops", "disk.used",
"net.in.bytes", "net.out.bytes", "net.in.packages", "net.out.packages",
"mem.used", "mem.idle", "mem.used.bytes", "mem.total.bytes",
}
// 增加 Label 數(shù)量
var uid1, uid2, uid3 []string
func init() {
for i := 0; i < len(metrics); i++ {
uid1 = append(uid1, uuid.NewV4().String())
uid2 = append(uid2, uuid.NewV4().String())
uid3 = append(uid3, uuid.NewV4().String())
}
}
func genPoints(ts int64, node, dc int) []*mandodb.Row {
points := make([]*mandodb.Row, 0)
for idx, metric := range metrics {
points = append(points, &mandodb.Row{
Metric: metric,
Labels: []mandodb.Label{
{Name: "node", Value: "vm" + strconv.Itoa(node)},
{Name: "dc", Value: strconv.Itoa(dc)},
{Name: "foo", Value: uid1[idx]},
{Name: "bar", Value: uid2[idx]},
{Name: "zoo", Value: uid3[idx]},
},
Point: mandodb.Point{Ts: ts, Value: float64(rand.Int31n(60))},
})
}
return points
}
func main() {
store := mandodb.OpenTSDB()
defer store.Close()
now := time.Now().Unix() - 36000 // 10h ago
for i := 0; i < 720; i++ {
for n := 0; n < 5; n++ {
for j := 0; j < 1024; j++ {
_ = store.InsertRows(genPoints(now, n, j))
}
}
now += 60 //1min
}
fmt.Println("finished")
select {}
}
每個分塊保存在名字為 seg-${mints}-${maxts} 文件夾里,每個文件夾含有 data 和 meta.json 兩個文件。
data: 存儲了一個 Segment 的所有數(shù)據(jù),包括數(shù)據(jù)點和索引信息。 meta.json: 描述了分塊的時間線數(shù)量,數(shù)據(jù)點數(shù)量以及該塊的數(shù)據(jù)時間跨度。
? ?? tree -h seg-*
seg-1627709713-1627716973
├── [ 28M] data
└── [ 110] meta.json
seg-1627716973-1627724233
├── [ 28M] data
└── [ 110] meta.json
seg-1627724233-1627731493
├── [ 28M] data
└── [ 110] meta.json
seg-1627731493-1627738753
├── [ 28M] data
└── [ 110] meta.json
seg-1627738753-1627746013
├── [ 28M] data
└── [ 110] meta.json
0 directories, 10 files
? ?? cat seg-1627709713-1627716973/meta.json -p
{
"seriesCount": 81920,
"dataPointsCount": 9912336,
"maxTs": 1627716973,
"minTs": 1627709713
}
存儲 8 萬條時間線共接近 1 千萬的數(shù)據(jù)點的數(shù)據(jù)塊占用磁盤 28M。實際上在寫入的時候,一條數(shù)據(jù)是這個樣子的。
{__name__="cpu.busy", node="vm0", dc="0", foo="bdac463d-8805-4cbe-bc9a-9bf495f87bab", bar="3689df1d-cbf3-4962-abea-6491861e62d2", zoo="9551010d-9726-4b3b-baf3-77e50655b950"} 1627710454 41
這樣一條數(shù)據(jù)按照 JSON 格式進行網(wǎng)絡(luò)通信的話,大概是 200Byte,初略計算一下。
200 * 9912336 = 1982467200Byte = 1890M
可以選擇 ZSTD 或者 Snappy 算法進行二次壓縮(默認不開啟)。還是上面的示例代碼,不過在 TSDB 啟動的時候指定了壓縮算法。
ZstdBytesCompressor
func main() {
store := mandodb.OpenTSDB(mandodb.WithMetaBytesCompressorType(mandodb.ZstdBytesCompressor))
defer store.Close()
// ...
}
// 壓縮效果 28M -> 25M
? ?? ll seg-1627711905-1627719165
Permissions Size User Date Modified Name
.rwxr-xr-x 25M chenjiandongx 1 Aug 00:13 data
.rwxr-xr-x 110 chenjiandongx 1 Aug 00:13 meta.json
SnappyBytesCompressor
func main() {
store := mandodb.OpenTSDB(mandodb.WithMetaBytesCompressorType(mandodb.SnappyBytesCompressor))
defer store.Close()
// ...
}
// 壓縮效果 28M -> 26M
? ?? ll seg-1627763918-1627771178
Permissions Size User Date Modified Name
.rwxr-xr-x 26M chenjiandongx 1 Aug 14:39 data
.rwxr-xr-x 110 chenjiandongx 1 Aug 14:39 meta.json
多多少少還是有點效果的 ??...

壓縮是有成本的,壓縮體積的同時會增大 CPU 開銷(mbp 可以煎雞蛋了),減緩寫入速率。
敲黑板,接下來就要來好好講講 data 文件到底寫了什么東西。 data 存儲布局如下。
Figure: Segment Stroage
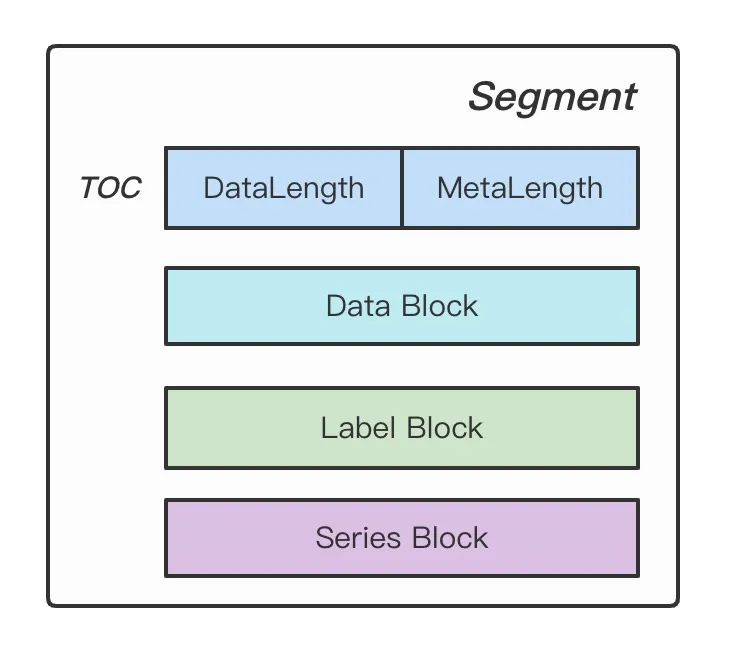
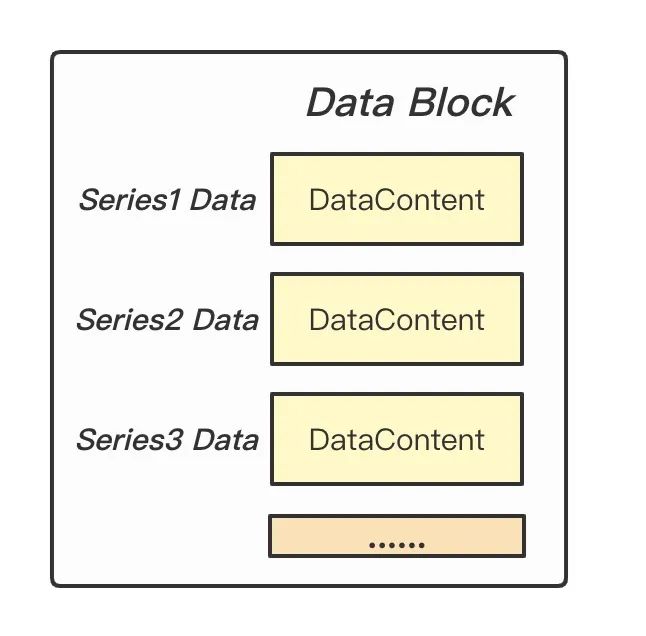
TOC 描述了 Data Block 和 Meta Block(Series Block + Labels Block)的體積,用于后面對 data 進行解析讀取。Data Block 存儲了每條時間線具體的數(shù)據(jù)點,時間線之間數(shù)據(jù)緊挨存儲。DataContent 就是使用 Gorilla 差值算法壓縮的 block。
Figure: Data Block
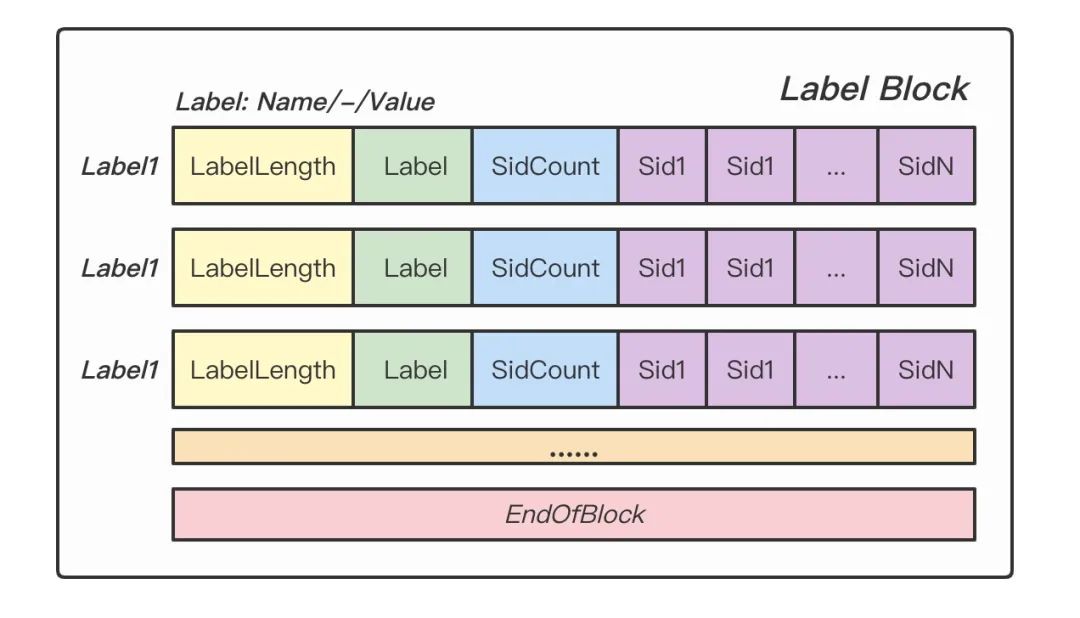
Labels Block 記錄了具體的 Label 值以及對應(yīng) Label 與哪些 Series 相關(guān)聯(lián)。
Figure: Labels Block
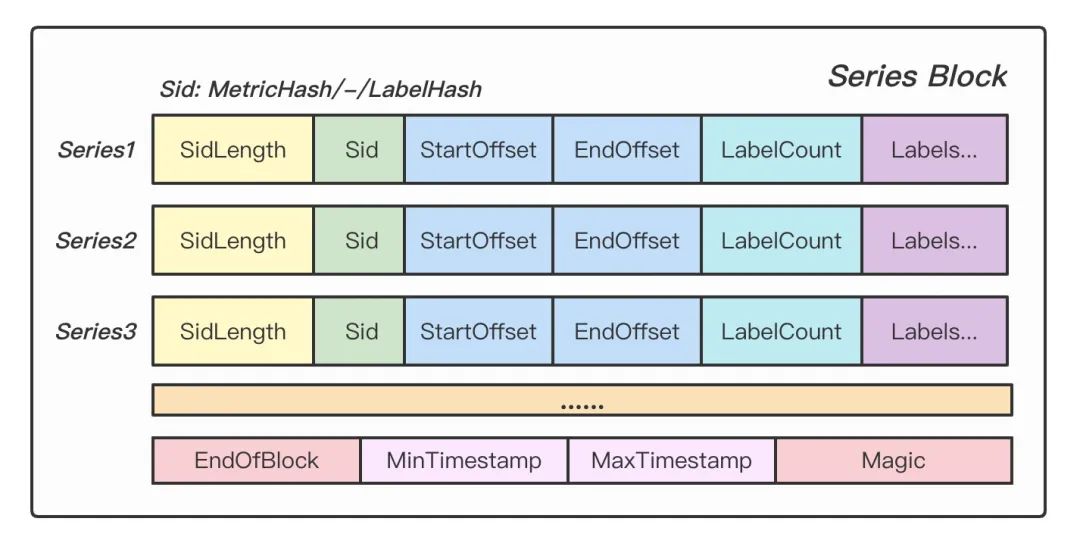
Series Block 記錄了每條時間線的元數(shù)據(jù),字段解釋如下。
SidLength: Sid 的長度。 Sid: 時間線的唯一標識。 StartOffset: 時間線數(shù)據(jù)塊在 Data Block 中的起始偏移。 EndOffset: 時間線數(shù)據(jù)塊在 Data Block 中的終止偏移。 LabelCount: 時間線包含的 Label 數(shù)量。 Labels: 標簽在 Labels Block 中的序號(僅記錄序號,不記錄具體值)。
Figure: Series Block
了解完設(shè)計,再看看 Meta Block 編碼和解編碼的代碼實現(xiàn),binaryMetaSerializer 實現(xiàn)了 MetaSerializer 接口。
type MetaSerializer interface {
Marshal(Metadata) ([]byte, error)
Unmarshal([]byte, *Metadata) error
}
編碼 Metadata
const (
endOfBlock uint16 = 0xffff
uint16Size = 2
uint32Size = 4
uint64Size = 8
magic = "https://github.com/chenjiandongx/mandodb"
)
func (s *binaryMetaSerializer) Marshal(meta Metadata) ([]byte, error) {
encf := newEncbuf()
// labels block
labelOrdered := make(map[string]int)
for idx, row := range meta.Labels {
labelOrdered[row.Name] = idx
encf.MarshalUint16(uint16(len(row.Name)))
encf.MarshalString(row.Name)
encf.MarshalUint32(uint32(len(row.Sids)))
encf.MarshalUint32(row.Sids...)
}
encf.MarshalUint16(endOfBlock)
// series block
for idx, series := range meta.Series {
encf.MarshalUint16(uint16(len(series.Sid)))
encf.MarshalString(series.Sid)
encf.MarshalUint64(series.StartOffset, series.EndOffset)
rl := meta.sidRelatedLabels[idx]
encf.MarshalUint32(uint32(rl.Len()))
lids := make([]uint32, 0, rl.Len())
for _, lb := range rl {
lids = append(lids, uint32(labelOrdered[lb.MarshalName()]))
}
sort.Slice(lids, func(i, j int) bool {
return lids[i] < lids[j]
})
encf.MarshalUint32(lids...)
}
encf.MarshalUint16(endOfBlock)
encf.MarshalUint64(uint64(meta.MinTs))
encf.MarshalUint64(uint64(meta.MaxTs))
encf.MarshalString(magic) // <-- magic here
return ByteCompress(encf.Bytes()), nil
}
解碼 Metadata
func (s *binaryMetaSerializer) Unmarshal(data []byte, meta *Metadata) error {
data, err := ByteDecompress(data)
if err != nil {
return ErrInvalidSize
}
if len(data) < len(magic) {
return ErrInvalidSize
}
decf := newDecbuf()
// 檢驗數(shù)據(jù)完整性
if decf.UnmarshalString(data[len(data)-len(magic):]) != magic {
return ErrInvalidSize
}
// labels block
offset := 0
labels := make([]seriesWithLabel, 0)
for {
var labelName string
labelLen := decf.UnmarshalUint16(data[offset : offset+uint16Size])
offset += uint16Size
if labelLen == endOfBlock {
break
}
labelName = decf.UnmarshalString(data[offset : offset+int(labelLen)])
offset += int(labelLen)
sidCnt := decf.UnmarshalUint32(data[offset : offset+uint32Size])
offset += uint32Size
sidLst := make([]uint32, sidCnt)
for i := 0; i < int(sidCnt); i++ {
sidLst[i] = decf.UnmarshalUint32(data[offset : offset+uint32Size])
offset += uint32Size
}
labels = append(labels, seriesWithLabel{Name: labelName, Sids: sidLst})
}
meta.Labels = labels
// series block
rows := make([]metaSeries, 0)
for {
series := metaSeries{}
sidLen := decf.UnmarshalUint16(data[offset : offset+uint16Size])
offset += uint16Size
if sidLen == endOfBlock {
break
}
series.Sid = decf.UnmarshalString(data[offset : offset+int(sidLen)])
offset += int(sidLen)
series.StartOffset = decf.UnmarshalUint64(data[offset : offset+uint64Size])
offset += uint64Size
series.EndOffset = decf.UnmarshalUint64(data[offset : offset+uint64Size])
offset += uint64Size
labelCnt := decf.UnmarshalUint32(data[offset : offset+uint32Size])
offset += uint32Size
labelLst := make([]uint32, labelCnt)
for i := 0; i < int(labelCnt); i++ {
labelLst[i] = decf.UnmarshalUint32(data[offset : offset+uint32Size])
offset += uint32Size
}
series.Labels = labelLst
rows = append(rows, series)
}
meta.Series = rows
meta.MinTs = int64(decf.UnmarshalUint64(data[offset : offset+uint64Size]))
offset += uint64Size
meta.MaxTs = int64(decf.UnmarshalUint64(data[offset : offset+uint64Size]))
offset += uint64Size
return decf.Err()
}
至此,對 mandodb 的索引和存儲整體設(shè)計是不是就了然于胸。?? 文檔較長,建議 Star 收藏,畢竟來都來了...
項目地址:https://github.com/chenjiandongx/mandodb