
百億日志收集架構(gòu)設(shè)計(jì)之 Filebeat
?此系列文章一共分為三部分,分為 filebeat、logstash 以及 es 三部分。這里會按照每天幾百億條的數(shù)據(jù)量來考慮,去設(shè)計(jì)、部署、優(yōu)化這個(gè)日志系統(tǒng),來最大限度的利用資源,并達(dá)到一個(gè)最優(yōu)的性能。本篇主要講解
filebeat這一塊。
介紹
版本:filebeat-7.12.0
在此用 Filebeat 做 k8s 的日志采集,部署方式是采用DaemonSet的方式,采集時(shí)按照 k8s 集群的namespace進(jìn)行分類,然后根據(jù)namespace的名稱創(chuàng)建不同的topic到 kafka 中。
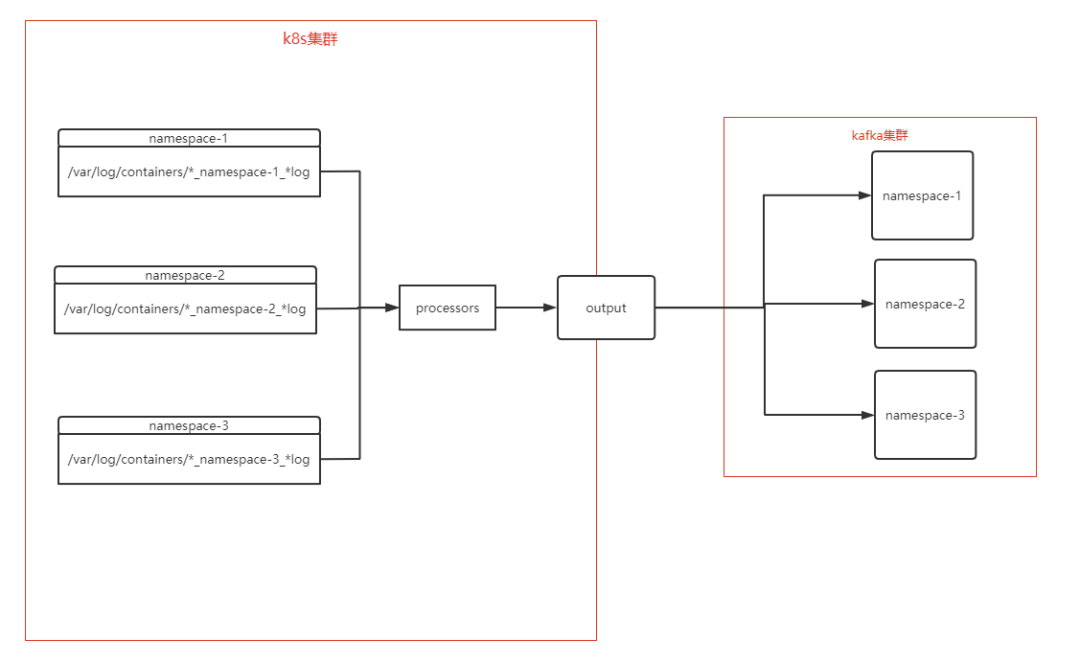
k8s 日志文件說明
一般情況下,容器中的日志在輸出到標(biāo)準(zhǔn)輸出(stdout)時(shí),會以*-json.log的命名方式保存在/var/lib/docker/containers目錄中,當(dāng)然如果修改了docker的數(shù)據(jù)目錄,那就是在修改后的數(shù)據(jù)目錄中了,例如:
# tree /data/docker/containers
/data/docker/containers
├── 009227c00e48b051b6f5cb65128fd58412b845e0c6d2bec5904f977ef0ec604d
│ ├── 009227c00e48b051b6f5cb65128fd58412b845e0c6d2bec5904f977ef0ec604d-json.log
│ ├── checkpoints
│ ├── config.v2.json
│ ├── hostconfig.json
│ └── mounts
這里能看到,有這么個(gè)文件:/data/docker/containers/container id/*-json.log,然后 k8s 默認(rèn)會在/var/log/containers和/var/log/pods目錄中會生成這些日志文件的軟鏈接,如下所示:
cattle-node-agent-tvhlq_cattle-system_agent-8accba2d42cbc907a412be9ea3a628a90624fb8ef0b9aa2bc6ff10eab21cf702.log
etcd-k8s-master01_kube-system_etcd-248e250c64d89ee6b03e4ca28ba364385a443cc220af2863014b923e7f982800.log
然后,會看到這個(gè)目錄下存在了此宿主機(jī)上的所有容器日志,文件的命名方式為:
[podName]_[nameSpace]_[depoymentName]-[containerId].log
上面這個(gè)是deployment的命名方式,其他的會有些不同,例如:DaemonSet,StatefulSet等,不過所有的都有一個(gè)共同點(diǎn),就是
*_[nameSpace]_*.log
到這里,知道這個(gè)特性,就可以往下來看Filebeat的部署和配置了。
filebeat 部署
部署采用的DaemonSet方式進(jìn)行,這里沒有啥可說的,參照官方文檔直接部署即可
---
apiVersion: v1
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*_test-1_*log
fields:
namespace: test-1
env: dev
k8s: cluster-dev
- type: container
enabled: true
paths:
- /var/log/containers/*_test-2_*log
fields:
namespace: test-2
env: dev
k8s: cluster-dev
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.kafka:
hosts: ["10.0.105.74:9092","10.0.105.76:9092","10.0.105.96:9092"]
topic: '%{[fields.k8s]}-%{[fields.namespace]}'
partition.round_robin:
reachable_only: true
kind: ConfigMap
metadata:
name: filebeat-daemonset-config-test
namespace: default
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.12.0
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
啟動的話直接kubectl apply -f啟動即可,部署不是本篇的重點(diǎn),這里不做過多介紹。
官方部署參考:https://raw.githubusercontent.com/elastic/beats/7.12/deploy/kubernetes/filebeat-kubernetes.yaml
filebeat 配置簡單介紹
這里先簡單介紹下filebeat的配置結(jié)構(gòu)
filebeat.inputs:
filebeat.config.modules:
processors:
output.xxxxx:
結(jié)構(gòu)大概是這么個(gè)結(jié)構(gòu),完整的數(shù)據(jù)流向簡單來說就是下面這個(gè)圖:
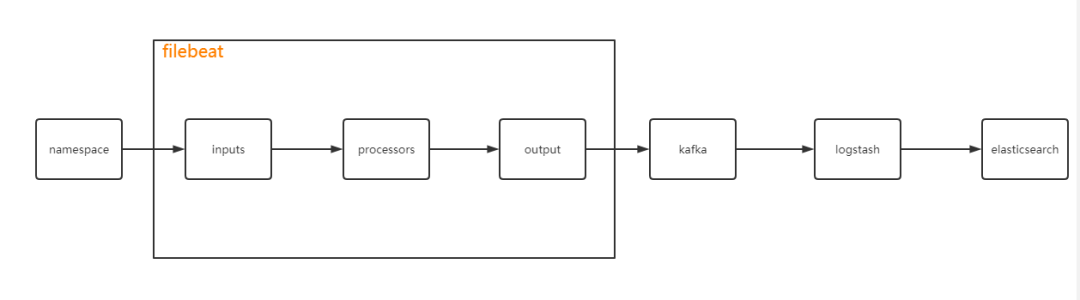
前面也說了,我是根據(jù)根據(jù)命名空間做分類,每一個(gè)命名空間就是一個(gè) topic,如果要收集多個(gè)集群,同樣也是使用命名空間做分類,只不過 topic 的命名就需要加個(gè) k8s 的集群名,這樣方便去區(qū)分了,那既然是通過命名空間來獲取日志,那么在配置inputs的時(shí)候就需要通過寫正則將指定命名空間下的日志文件取出,然后讀取,例如:
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*_test-1_*log
fields:
namespace: test-1
env: dev
k8s: cluster-dev
這里我的命名空間為bim5d-basic,然后通過正則*_test-1_*log來獲取帶有此命名空間名的日志文件,隨后又加了個(gè)自定義字段,方便下面創(chuàng)建topic時(shí)使用。
這里是寫了一個(gè)命名空間,如果有多個(gè),就排開寫就行了,如下所示:
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*_test-1_*log
fields:
namespace: test-1
env: dev
k8s: cluster-dev
- type: container
enabled: true
paths:
- /var/log/containers/*_test-2_*log
fields:
namespace: test-2
env: dev
k8s: cluster-dev
這種寫法有一個(gè)不好的地方就是,如果命名空間比較多,那么整個(gè)配置就比較多,不要著急,文章下面有更簡潔的寫法
?注意: 日志的類型,要設(shè)置成
container
上面說了通過命名空間創(chuàng)建topic,我這里加了一個(gè)自定義的字段namespace,就是后面的topic的名稱,但是這里有很多的命名空間,那在輸出的時(shí)候,如何動態(tài)去創(chuàng)建呢?
output.kafka:
hosts: ["127.0.0.1:9092","127.0.0.2:9092","127.0.0.3:9092"]
topic: '%{[fields.namespace]}'
partition.round_robin:
reachable_only: true
注意這里的寫法:%{[fields.namespace]}
那么完整的配置如下所示:
apiVersion: v1
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*_test-1_*log
fields:
namespace: test-1
env: dev
k8s: cluster-dev
- type: container
enabled: true
paths:
- /var/log/containers/*_test-2_*log
fields:
namespace: test-2
env: dev
k8s: cluster-dev
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.kafka:
hosts: ["127.0.0.1:9092","127.0.0.2:9092","127.0.0.3:9092"]
topic: '%{[fields.k8s]}-%{[fields.namespace]}'
partition.round_robin:
reachable_only: true
kind: ConfigMap
metadata:
name: filebeat-daemonset-config-test
namespace: default
如果是不對日志做任何處理,到這里就結(jié)束了,但是這樣又視乎在查看日志的時(shí)候少了點(diǎn)什么?沒錯(cuò)!到這里你僅僅知道日志內(nèi)容,和該日志來自于哪個(gè)命名空間,但是你不知道該日志屬于哪個(gè)服務(wù),哪個(gè) pod,甚至說想查看該服務(wù)的鏡像地址等,但是這些信息在我們上面的配置方式中是沒有的,所以需要進(jìn)一步的添磚加瓦。
這個(gè)時(shí)候就用到了一個(gè)配置項(xiàng),叫做: processors, 看下官方的解釋
?You can define processors in your configuration to process events before they are sent to the configured output
簡單來說就是處理日志
下面來重點(diǎn)講一下這個(gè)地方,非常有用和重要
filebeat 的 processors 使用介紹
添加 K8s 的基本信息
在采集 k8s 的日志時(shí),如果按照上面那種配置方式,是沒有關(guān)于 pod 的一些信息的,例如:
Pod Name Pod UID Namespace Labels 等等等等
那么如果想添加這些信息,就要使用processors中的一個(gè)工具,叫做: add_kubernetes_metadata, 字面意思就是添加 k8s 的一些元數(shù)據(jù)信息,使用方法可以先來看一段示例:
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
host: 指定要對 filebeat 起作用的節(jié)點(diǎn),防止無法準(zhǔn)確檢測到它,比如在主機(jī)網(wǎng)絡(luò)模式下運(yùn)行 filebeatmatchers: 匹配器用于構(gòu)造與索引創(chuàng)建的標(biāo)識符相匹配的查找鍵logs_path: 容器日志的基本路徑,如果未指定,則使用 Filebeat 運(yùn)行的平臺的默認(rèn)日志路徑
加上這個(gè) k8s 的元數(shù)據(jù)信息之后,就可以在日志里面看到 k8s 的信息了,看一下添加 k8s 信息后的日志格式:
{
"@timestamp": "2021-04-19T07:07:36.065Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.11.2"
},
"log": {
"offset": 377708,
"file": {
"path": "/var/log/containers/test-server-85545c868b-6nsvc_test-1_test-server-885412c0a8af6bfa7b3d7a341c3a9cb79a85986965e363e87529b31cb650aec4.log"
}
},
"fields": {
"env": "dev",
"k8s": "cluster-dev"
"namespace": "test-1"
},
"host": {
"name": "filebeat-fv484"
},
"agent": {
"id": "7afbca43-3ec1-4cee-b5cb-1de1e955b717",
"name": "filebeat-fv484",
"type": "filebeat",
"version": "7.11.2",
"hostname": "filebeat-fv484",
"ephemeral_id": "8fd29dee-da50-4c88-88d5-ebb6bbf20772"
},
"ecs": {
"version": "1.6.0"
},
"stream": "stdout",
"message": "2021-04-19 15:07:36.065 INFO 23 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration",
"input": {
"type": "container"
},
"container": {
"image": {
"name": "hub.test.com/test/test-server:3.3.1-ent-release-SNAPSHOT.20210402191241_87c9b1f841c"
},
"id": "885412c0a8af6bfa7b3d7a341c3a9cb79a85986965e363e87529b31cb650aec4",
"runtime": "docker"
},
"kubernetes": {
"labels": {
"pod-template-hash": "85545c868b",
"app": "gateway-test"
},
"container": {
"name": "test-server",
"image": "hub.test.com/test/test-server:3.3.1-ent-release-SNAPSHOT.20210402191241_87c9b1f841c"
},
"node": {
"uid": "511d9dc1-a84e-4948-b6c8-26d3f1ba2e61",
"labels": {
"kubernetes_io/hostname": "k8s-node-09",
"kubernetes_io/os": "linux",
"beta_kubernetes_io/arch": "amd64",
"beta_kubernetes_io/os": "linux",
"cloudt-global": "true",
"kubernetes_io/arch": "amd64"
},
"hostname": "k8s-node-09",
"name": "k8s-node-09"
},
"namespace_uid": "4fbea846-44b8-4d4a-b03b-56e43cff2754",
"namespace_labels": {
"field_cattle_io/projectId": "p-lgxhz",
"cattle_io/creator": "norman"
},
"pod": {
"name": "test-server-85545c868b-6nsvc",
"uid": "1e678b63-fb3c-40b5-8aad-892596c5bd4d"
},
"namespace": "test-1",
"replicaset": {
"name": "test-server-85545c868b"
}
}
}
可以看到 kubernetes 這個(gè) key 的 value 有關(guān)于 pod 的信息,還有 node 的一些信息,還有 namespace 信息等,基本上關(guān)于 k8s 的一些關(guān)鍵信息都包含了,非常的多和全。
但是,問題又來了,這一條日志信息有點(diǎn)太多了,有一半多不是我們想要的信息,所以,我們需要去掉一些對于我們沒有用的字段
刪除不必要的字段
processors:
- drop_fields:
#刪除的多余字段
fields:
- host
- ecs
- log
- agent
- input
- stream
- container
ignore_missing: true
?元信息:@metadata 是不能刪除的
添加日志時(shí)間
通過上面的日志信息,可以看到是沒有單獨(dú)的一個(gè)關(guān)于日志時(shí)間的字段的,雖然里面有一個(gè)@timestamp,但不是北京時(shí)間,而我們要的是日志的時(shí)間,message里面倒是有時(shí)間,但是怎么能把它取到并單獨(dú)添加一個(gè)字段呢,這個(gè)時(shí)候就需要用到script了,需要寫一個(gè) js 腳本來替換。
processors:
- script:
lang: javascript
id: format_time
tag: enable
source: >
function process(event) {
var str=event.Get("message");
var time=str.split(" ").slice(0, 2).join(" ");
event.Put("time", time);
}
- timestamp:
field: time
timezone: Asia/Shanghai
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
添加完成后,會多一個(gè)time的字段,在后面使用的時(shí)候,就可以使用這個(gè)字段了。
重新拼接 k8s 源信息
實(shí)際上,到這個(gè)程度就已經(jīng)完成了我們的所有需求了,但是添加完 k8s 的信息之后,多了很多無用的字段,而我們?nèi)绻肴サ裟切]用的字段用drop_fields也可以,例如下面這種寫法:
processors:
- drop_fields:
#刪除的多余字段
fields:
- kubernetes.pod.uid
- kubernetes.namespace_uid
- kubernetes.namespace_labels
- kubernetes.node.uid
- kubernetes.node.labels
- kubernetes.replicaset
- kubernetes.labels
- kubernetes.node.name
ignore_missing: true
這樣寫也可以把無用的字段去掉,但是結(jié)構(gòu)層級沒有變化,嵌套了很多層,最終結(jié)果可能變成這個(gè)樣子
{
"@timestamp": "2021-04-19T07:07:36.065Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.11.2"
},
"fields": {
"env": "dev",
"k8s": "cluster-dev"
"namespace": "test-1"
},
"message": "2021-04-19 15:07:36.065 INFO 23 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration",
"kubernetes": {
"container": {
"name": "test-server",
"image": "hub.test.com/test/test-server:3.3.1-ent-release-SNAPSHOT.20210402191241_87c9b1f841c"
},
"node": {
"hostname": "k8s-node-09"
},
"pod": {
"name": "test-server-85545c868b-6nsvc"
},
"namespace": "test-1"
}
}
這樣在后面使用 es 創(chuàng)建 template 的時(shí)候,就會嵌套好多層,查詢起來也很不方便,既然這樣那我們就優(yōu)化下這個(gè)層級結(jié)構(gòu),繼續(xù)script這個(gè)插件
processors:
- script:
lang: javascript
id: format_k8s
tag: enable
source: >
function process(event) {
var k8s=event.Get("kubernetes");
var newK8s = {
podName: k8s.pod.name,
nameSpace: k8s.namespace,
imageAddr: k8s.container.name,
hostName: k8s.node.hostname
}
event.Put("k8s", newK8s);
}
這里單獨(dú)創(chuàng)建了一個(gè)字段k8s,字段里包含:podName, nameSpace, imageAddr, hostName等關(guān)鍵信息,最后再把kubernetes這個(gè)字段 drop 掉就可以了。最終結(jié)果如下:
{
"@timestamp": "2021-04-19T07:07:36.065Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.11.2"
},
"fields": {
"env": "dev",
"k8s": "cluster-dev"
"namespace": "test-1"
},
"time": "2021-04-19 15:07:36.065",
"message": "2021-04-19 15:07:36.065 INFO 23 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration",
"k8s": {
"podName": "test-server-85545c868b-6nsvc",
"nameSpace": "test-1",
"imageAddr": "hub.test.com/test/test-server:3.3.1-ent-release-SNAPSHOT.20210402191241_87c9b1f841c",
"hostName": "k8s-node-09"
}
}
這樣看起來就非常清爽了。但是還是有些繁瑣,因?yàn)槿绻竺嬉有碌拿臻g,那么每加一次就需要再改一次配置,這樣也是非常的繁瑣,那么還有沒有更好的方式呢?答案是有的。
最終優(yōu)化
既然通過output.kafka來創(chuàng)建topic的時(shí)候,可以通過指定字段,那么利用這一點(diǎn),我們就可以這樣設(shè)置:
output.kafka:
hosts: ["127.0.0.1:9092","127.0.0.2:9092","127.0.0.3:9092"]
topic: '%{[fields.k8s]}-%{[k8s.nameSpace]}' # 通過往日志里注入k8s的元信息來獲取命名空間
partition.round_robin:
reachable_only: true
之前還在fields下面創(chuàng)建了一個(gè)k8s的字段,用來區(qū)分來自不通的 k8s 集群,那么這樣,我們就可以把這個(gè)配置文件優(yōu)化成最終這個(gè)樣子
apiVersion: v1
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*.log
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}|^[1-9]\d*\.[1-9]\d*\.[1-9]\d*\.[1-9]\d*'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- drop_event.when.regexp:
or:
kubernetes.pod.name: "filebeat.*"
kubernetes.pod.name: "external-dns.*"
kubernetes.pod.name: "coredns.*"
kubernetes.pod.name: "eureka.*"
kubernetes.pod.name: "zookeeper.*"
- script:
lang: javascript
id: format_time
tag: enable
source: >
function process(event) {
var str=event.Get("message");
var time=str.split(" ").slice(0, 2).join(" ");
event.Put("time", time);
}
- timestamp:
field: time
timezone: Asia/Shanghai
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
# 下面這個(gè)腳本配置可以忽略,本意是想通過獲取timestamp的時(shí)間轉(zhuǎn)化為時(shí)間戳,然后再轉(zhuǎn)換為本地時(shí)間
- script:
lang: javascript
id: format_time_utc
tag: enable
source: >
function process(event) {
var utc_time=event.Get("@timestamp");
var T_pos = utc_time.indexOf('T');
var Z_pos = utc_time.indexOf('Z');
var year_month_day = utc_time.substr(0, T_pos);
var hour_minute_second = utc_time.substr(T_pos+1, Z_pos-T_pos-1);
var new_time = year_month_day + " " + hour_minute_second;
timestamp = new Date(Date.parse(new_time));
timestamp = timestamp.getTime();
timestamp = timestamp/1000;
var timestamp = timestamp + 8*60*60;
var bj_time = new Date(parseInt(timestamp) * 1000 + 8* 3600 * 1000);
var bj_time = bj_time.toJSON().substr(0, 19).replace('T', ' ');
event.Put("time_utc", bj_time);
}
- timestamp:
field: time_utc
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
- add_fields:
target: ''
fields:
env: prod
- add_kubernetes_metadata:
default_indexers.enabled: true
default_matchers.enabled: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- script:
lang: javascript
id: format_k8s
tag: enable
source: >
function process(event) {
var k8s=event.Get("kubernetes");
var newK8s = {
podName: k8s.pod.name,
nameSpace: k8s.namespace,
imageAddr: k8s.container.name,
hostName: k8s.node.hostname,
k8sName: "saas-pro-hbali"
}
event.Put("k8s", newK8s);
}
- drop_fields:
#刪除的多余字段
fields:
- host
- tags
- ecs
- log
- prospector
- agent
- input
- beat
- offset
- stream
- container
- kubernetes
ignore_missing: true
output.kafka:
hosts: ["127.0.0.1:9092","127.0.0.2:9092","127.0.0.3:9092"]
topic: '%{[k8s.k8sName]}-%{[k8s.nameSpace]}'
partition.round_robin:
reachable_only: true
kind: ConfigMap
metadata:
name: filebeat-daemonset-config
namespace: default
做了一些調(diào)整,需要記住這里創(chuàng)建 topic 時(shí)的方式%{[k8s.k8sName]}-%{[k8s.nameSpace]},后面使用logstash時(shí)還會用到。
總結(jié)
個(gè)人認(rèn)為讓 filebeat 在收集日志的第一層做一些處理,能縮短整個(gè)過程的處理時(shí)間,因?yàn)槠款i大多在 es 和 logstash,所以一些耗時(shí)的操作盡量在 filebeat 這塊去處理,如果處理不了在使用 logstash,另外一個(gè)非常容易忽視的一點(diǎn)就是,對于日志內(nèi)容的簡化,這樣能顯著降低日志的體積,我做過測試,同樣的日志條數(shù),未做簡化的體積達(dá)到 20G,而優(yōu)化后的體積不到 10G,這樣的話對于整個(gè) es 集群來說可以說是非常的友好和作用巨大了。