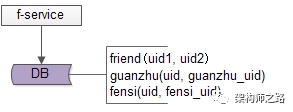
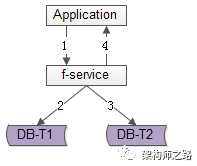
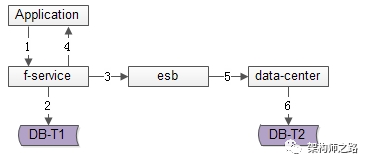
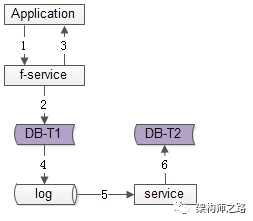
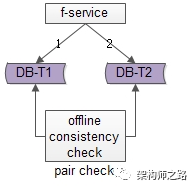
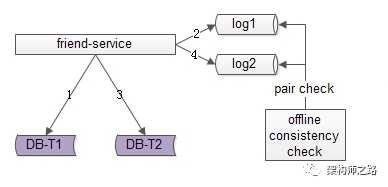
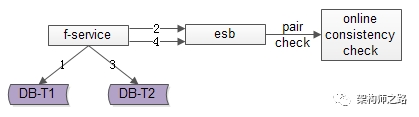
百億關(guān)系鏈,架構(gòu)如何設(shè)計?架構(gòu)師之路關(guān)注共 4880字,需瀏覽 10分鐘 ·2020-08-09 03:58 文章較長,聽我娓娓道來。粉絲與關(guān)注,社交好友,都是典型的“多對多關(guān)系”的業(yè)務(wù),這類業(yè)務(wù)的核心服務(wù)是好友中心,當關(guān)系鏈達到百億之后,好友中心架構(gòu)設(shè)計要考慮哪些因素,是本文將要分享的內(nèi)容。什么是“多對多”關(guān)系?所謂的“多對多”,來自數(shù)據(jù)庫設(shè)計中的“實體-關(guān)系”ER模型,用來描述實體之間的關(guān)聯(lián)關(guān)系,一個學生可以選修多個課程,一個課程可以被多個學生選修,這里學生與課程時間的關(guān)系,就是多對多關(guān)系。什么是好友關(guān)系?好友關(guān)系主要分為兩類:(1)弱好友關(guān)系;(2)強好友關(guān)系;兩類都有典型的互聯(lián)網(wǎng)產(chǎn)品應(yīng)用。什么是弱好友關(guān)系?弱好友關(guān)系的建立,不需要雙方彼此同意:用戶A關(guān)注用戶B,不需要用戶B同意,此時用戶A與用戶B為弱好友關(guān)系,對A而言,他多“關(guān)注”了一個人,對B而言,他多了一個“粉絲”。微博粉絲是一個典型的弱好友關(guān)系應(yīng)用。什么是強好友關(guān)系?強好友關(guān)系的建立,需要好友關(guān)系雙方彼此同意:用戶A請求添加用戶B為好友,用戶B同意,此時用戶A與用戶B則互為強好友關(guān)系,即A是B的好友,B也是A的好友。QQ好友是一個典型的強好友關(guān)系應(yīng)用。什么是好友中心?好友中心是一個典型的多對多業(yè)務(wù),一個用戶可以添加多個好友,也可以被多個好友添加。其典型架構(gòu)如上:(1)friend-service:好友中心服務(wù),對調(diào)用者提供友好的RPC接口;(2)db:對好友數(shù)據(jù)進行存儲;服務(wù)的接口,不外乎:關(guān)注,取關(guān),增加好友,刪除好友,同意好友申請,不同意好友申請。其核心,在于元數(shù)據(jù)的設(shè)計。弱好友關(guān)系,如何設(shè)計元數(shù)據(jù)?通過弱好友關(guān)系業(yè)務(wù)分析,很容易了解到,其核心元數(shù)據(jù)為:(1)guanzhu(uid, guanzhu_uid);(2)fensi(uid, fensi_uid);其中:(1)guanzhu表,用戶記錄uid所有關(guān)注用戶guanzhu_uid;(2)fensi表,用來記錄uid所有粉絲用戶fensi_uid;需要強調(diào)的是,一條弱關(guān)系的產(chǎn)生,會產(chǎn)生兩條記錄,一條關(guān)注記錄,一條粉絲記錄。畫外音:可不可以只有一條記錄?例如:用戶A(uid=1)關(guān)注了用戶B(uid=2),A多關(guān)注了一個用戶,B多了一個粉絲,于是:(1)guanzhu表要插入{1, 2}這一條記錄,1關(guān)注了2;(2)fensi表要插入{2, 1}這一條記錄,2粉了1;如何查詢一個用戶關(guān)注了誰呢?在guanzhu的uid上建立索引:select * from guanzhu where uid=1;即可得到結(jié)果,1關(guān)注了2。如何查詢一個用戶粉了誰呢?在fensi的uid上建立索引:select * from fensi where uid=2;即可得到結(jié)果,2粉了1。強好友關(guān)系,如何設(shè)計元數(shù)據(jù)?通過強好友關(guān)系業(yè)務(wù)分析,很容易了解到,其核心元數(shù)據(jù)為:(1)friend(uid1, uid2);其中:(1)uid1,強好友關(guān)系中一方的uid;(2)uid2,強好友關(guān)系中另一方的uid;uid=1的用戶添加了uid=2的用戶,雙方都同意加彼此為好友,強好友關(guān)系,在數(shù)據(jù)庫中應(yīng)該插入記錄{1, 2}還是記錄{2,1}呢?都可以,為了避免歧義,可以人為約定,插入記錄時uid1的值必須小于uid2。例如:有uid=1,2,3三個用戶,他們互為強好友關(guān)系,那邊數(shù)據(jù)庫中可能是這樣的三條記錄:{1, 2}{2, 3}{1, 3}如何查詢一個用戶的好友呢?假設(shè)要查詢uid=2的所有好友,只需在uid1和uid2上建立索引,然后:select * from friend where uid1=2unionselect * from friend where uid2=2即可得到結(jié)果。畫外音,可不可以使用:select * from friend uid1=2 or uid2=2使用一個表記錄所有關(guān)系鏈,如果數(shù)據(jù)量大了,數(shù)據(jù)庫進行分庫以后,不久無法同時滿足uid1和uid2上的查詢了么,此時要怎么辦呢?此時,可以使用類似于弱關(guān)系實現(xiàn)的方案,用數(shù)據(jù)冗余的方式,即使分庫后,依然能夠滿足兩種查詢需求。即,強好友關(guān)系也可以使用關(guān)注表和粉絲表來實現(xiàn):(1)guanzhu(uid, guanzhu_uid);(2)fensi(uid, fensi_uid);例如:用戶A(uid=1)和用戶B(uid=2)為強好友關(guān)系,即相互關(guān)注:用戶A(uid=1)關(guān)注了用戶B(uid=2),A多關(guān)注了一個用戶,B多了一個粉絲,于是:(1)guanzhu表要插入{1, 2}這一條記錄;(2)fensi表要插入{2, 1}這一條記錄;同時,用戶B(uid=2)也關(guān)注了用戶A(uid=1),B多關(guān)注了一個用戶,A多了一個粉絲,于是:(1)guanzhu表要插入{2, 1}這一條記錄;(2)fensi表要插入{1, 2}這一條記錄;強調(diào)一下:數(shù)據(jù)冗余,是多對多關(guān)系,滿足不同維度的查詢需求,在數(shù)據(jù)量大時,數(shù)據(jù)水平切分的常用實踐。對于強好友關(guān)系的兩類實現(xiàn):第一類:friend(uid1, uid2)表;第二類:數(shù)據(jù)冗余guanzhu表與fensi表(后文稱正表T1與反表T2);在數(shù)據(jù)量小時,看似無差異,但數(shù)據(jù)量大時,只有后者,才能滿足兩類查詢需求:(1)friend表,數(shù)據(jù)量大時,如果使用uid1來分庫,那么uid2上的查詢就需要遍歷多庫;(2)正表T1與反表T2通過數(shù)據(jù)冗余來實現(xiàn)好友關(guān)系,{1, 2}{2,1}分別存在于兩表中,故兩個表都使用uid來分庫,均只需要進行一次查詢,就能找到對應(yīng)的關(guān)注與粉絲,而不需要多個庫掃描;問題轉(zhuǎn)化為,T1和T2正反表,如何進行數(shù)據(jù)冗余呢?數(shù)據(jù)冗余,常見有三種方法。方法一:服務(wù)同步冗余顧名思義,由好友中心服務(wù)同步寫冗余數(shù)據(jù),如上圖1-4流程:(1)業(yè)務(wù)方調(diào)用服務(wù),新增數(shù)據(jù);(2)服務(wù)先插入T1數(shù)據(jù);(3)服務(wù)再插入T2數(shù)據(jù);(4)服務(wù)返回業(yè)務(wù)方新增數(shù)據(jù)成功;這個方法,有什么優(yōu)點呢?(1)不復(fù)雜,服務(wù)層由單次寫,變兩次寫;(2)數(shù)據(jù)一致性相對較高(因為雙寫成功才返回);這個方法,有什么不足呢?(1)請求的處理時間增加(要插入次,時間加倍);(2)數(shù)據(jù)仍可能不一致,例如第二步寫入T1完成后服務(wù)重啟,則數(shù)據(jù)不會寫入T2;如果系統(tǒng)對處理時間比較敏感,引出常用的第二種方案。方法二:服務(wù)異步冗余數(shù)據(jù)的雙寫并不再由好友中心服務(wù)來完成,服務(wù)層異步發(fā)出一個消息,通過消息總線發(fā)送給一個專門的數(shù)據(jù)復(fù)制服務(wù)來寫入冗余數(shù)據(jù),如上圖1-6流程:(1)業(yè)務(wù)方調(diào)用服務(wù),新增數(shù)據(jù);(2)服務(wù)先插入T1數(shù)據(jù);(3)服務(wù)向消息總線發(fā)送一個異步消息(發(fā)出即可,不用等返回,通常很快就能完成);(4)服務(wù)返回業(yè)務(wù)方新增數(shù)據(jù)成功;(5)消息總線將消息投遞給數(shù)據(jù)同步中心;(6)數(shù)據(jù)同步中心插入T2數(shù)據(jù);這個方法,有什么優(yōu)點呢?(1)請求處理時間短(只插入1次);這個方法,有什么不足呢?(1)系統(tǒng)的復(fù)雜性增加了,多引入了一個組件(消息總線)和一個服務(wù)(專用的數(shù)據(jù)復(fù)制服務(wù));(2)因為返回業(yè)務(wù)線數(shù)據(jù)插入成功時,數(shù)據(jù)還不一定插入到T2中,因此數(shù)據(jù)有一個不一致時間窗口(這個窗口很短,最終是一致的);(3)在消息總線丟失消息時,冗余表數(shù)據(jù)會不一致;如果想解除“數(shù)據(jù)冗余”對系統(tǒng)的耦合,引出常用的第三種方案。方法三:線下異步冗余數(shù)據(jù)的雙寫不再由好友中心服務(wù)來完成,而是由線下的一個服務(wù)或者任務(wù)來完成,如上圖1-6流程:(1)業(yè)務(wù)方調(diào)用服務(wù),新增數(shù)據(jù);(2)服務(wù)先插入T1數(shù)據(jù);(3)服務(wù)返回業(yè)務(wù)方新增數(shù)據(jù)成功;(4)數(shù)據(jù)會被寫入到數(shù)據(jù)庫的log中;(5)線下服務(wù)或者任務(wù)讀取數(shù)據(jù)庫的log;(6)線下服務(wù)或者任務(wù)插入T2數(shù)據(jù);這個方法,有什么優(yōu)點呢?(1)數(shù)據(jù)雙寫與業(yè)務(wù)完全解耦;(2)請求處理時間短(只插入1次);這個方法,有什么不足呢?(1)返回業(yè)務(wù)線數(shù)據(jù)插入成功時,數(shù)據(jù)還不一定插入到T2中,因此數(shù)據(jù)有一個不一致時間窗口(這個窗口很短,最終是一致的);(2)數(shù)據(jù)的一致性依賴于線下服務(wù)或者任務(wù)的可靠性;上述三種方案各有優(yōu)缺點,可以結(jié)合實際情況選取。數(shù)據(jù)冗余固然能夠解決多對多關(guān)系的數(shù)據(jù)庫水平切分問題,但又帶來了新的問題,如何保證正表T1與反表T2的數(shù)據(jù)一致性呢?可以看到,不管哪種方案,因為兩步操作不能保證原子性,總有出現(xiàn)數(shù)據(jù)不一致的可能,高吞吐分布式事務(wù)是業(yè)內(nèi)尚未解決的難題,此時的架構(gòu)優(yōu)化方向,并不是完全保證數(shù)據(jù)的一致,而是盡早的發(fā)現(xiàn)不一致,并修復(fù)不一致。需要強調(diào)的是,最終一致性,是高吞吐互聯(lián)網(wǎng)業(yè)務(wù)一致性的常用實踐。更具體的,保證數(shù)據(jù)最終一致性的方案有三種。方法一:線下掃面正反冗余表全部數(shù)據(jù)如上圖所示,線下啟動一個離線的掃描工具,不停的比對正表T1和反表T2,如果發(fā)現(xiàn)數(shù)據(jù)不一致,就進行補償修復(fù)。這個方法,有什么優(yōu)點呢?(1)比較簡單,開發(fā)代價小;(2)線上服務(wù)無需修改,修復(fù)工具與線上服務(wù)解耦;這個方法,有什么不足呢?(1)掃描效率低,會掃描大量的“已經(jīng)能夠保證一致”的數(shù)據(jù);(2)由于掃描的數(shù)據(jù)量大,掃描一輪的時間比較長,即數(shù)據(jù)如果不一致,不一致的時間窗口比較長;有沒有只掃描“可能存在不一致可能性”的數(shù)據(jù),而不是每次掃描全部數(shù)據(jù),以提高效率的優(yōu)化方法呢?方法二:線下掃描增量數(shù)據(jù)每次只掃描增量的日志數(shù)據(jù),就能夠極大提高效率,縮短數(shù)據(jù)不一致的時間窗口,如上圖1-4流程所示:(1)寫入正表T1;(2)第一步成功后,寫入日志log1;(3)寫入反表T2;(4)第二步成功后,寫入日志log2;當然,我們還是需要一個離線的掃描工具,不停的比對日志log1和日志log2,如果發(fā)現(xiàn)數(shù)據(jù)不一致,就進行補償修復(fù)。這個方法,有什么優(yōu)點呢?(1)雖比方法一復(fù)雜,但仍然是比較簡單的;(2)數(shù)據(jù)掃描效率高,只掃描增量數(shù)據(jù);這個方法,有什么不足呢?(1)線上服務(wù)略有修改(代價不高,多寫了2條日志);(2)雖然比方法一更實時,但時效性還是不高,不一致窗口取決于掃描的周期;有沒有實時檢測一致性并進行修復(fù)的方法呢?方法三:實時線上“消息對”檢測這次不是寫日志了,而是向消息總線發(fā)送消息,如上圖1-4流程所示:(1)寫入正表T1;(2)第一步成功后,發(fā)送消息msg1;(3)寫入反表T2;(4)第二步成功后,發(fā)送消息msg2;這次不是需要一個周期掃描的離線工具了,而是一個實時訂閱消息的服務(wù)不停的收消息。假設(shè)正常情況下,msg1和msg2的接收時間應(yīng)該在3s以內(nèi),如果檢測服務(wù)在收到msg1后沒有收到msg2,就嘗試檢測數(shù)據(jù)的一致性,不一致時進行補償修復(fù)。這個方法,有什么優(yōu)點呢?(1)效率高;(2)實時性高;這個方法,有什么不足呢?(1)方案比較復(fù)雜,上線引入了消息總線這個組件;(2)線下多了一個訂閱總線的檢測服務(wù);however,技術(shù)方案本身就是一個投入產(chǎn)出比的折衷,可以根據(jù)業(yè)務(wù)對一致性的需求程度決定使用哪一種方法。總結(jié)文字較多,希望盡量記住如下幾點:(1)好友業(yè)務(wù)是一個典型的多對多關(guān)系,又分為強好友與弱好友;(2)數(shù)據(jù)冗余是一個常見的多對多業(yè)務(wù)數(shù)據(jù)水平切分實踐;(3)冗余數(shù)據(jù)的常見方案有三種:? ? ? ? ?(3.1)服務(wù)同步冗余;???????? (3.2)服務(wù)異步冗余;???????? (3.3)線下異步冗余;(4)數(shù)據(jù)冗余會帶來一致性問題,高吞吐互聯(lián)網(wǎng)業(yè)務(wù),要想完全保證事務(wù)一致性很難,常見的實踐是最終一致性;(5)最終一致性的常見實踐是,盡快找到不一致,并修復(fù)數(shù)據(jù),常見方案有三種:???????? (5.1)線下全量掃描法;???????? (5.2)線下增量掃描法;???????? (5.3)線上實時檢測法;新嘗試,視頻講架構(gòu)希望大家有收獲,幫轉(zhuǎn)喲。 瀏覽 89點贊 評論 收藏 分享 手機掃一掃分享分享 舉報 評論圖片表情視頻評價全部評論推薦 百億日志收集架構(gòu)設(shè)計之 Filebeat武培軒0產(chǎn)品架構(gòu)該如何設(shè)計?明天上線0系鏈系鏈0系鏈系鏈0To B如何設(shè)計品牌的“頂層架構(gòu)”?To B CGO0帖子中心,1億數(shù)據(jù),架構(gòu)如何設(shè)計?架構(gòu)師之路0架構(gòu)設(shè)計方法論互聯(lián)網(wǎng)全棧架構(gòu)0軟件架構(gòu)設(shè)計《軟件架構(gòu)設(shè)計:程序員向架構(gòu)師轉(zhuǎn)型必備(第2版)》圍繞“軟件架構(gòu)設(shè)計”主題,從“程序員”成長的視角,軟件架構(gòu)設(shè)計軟件架構(gòu)設(shè)計0前端架構(gòu)設(shè)計前端架構(gòu)設(shè)計0點贊 評論 收藏 分享 手機掃一掃分享分享 舉報

 下載APP
下載APP