
【Python辦公自動化】50多個Excel數據的對比查詢
前言
最近公司在進行某項專項檢查工作,要求各單位(公司近60個單位)自查后按要求報表過來,然后將收到的50多張Excel與之前的供應商信息表進行比對查詢。一估算,有超過上萬行的數據,靠人力去查找不知道猴年馬月才能完成,一時沒人能搞定,結果我接到了這個令人頭痛的電話,領導最終把這個苦差事落到了我的頭上,咱也不敢拒絕,畢竟領導掌握著我的生殺大權,只求領導記得月底給我加個雞腿。
需求分析
這個問題,主要體現(xiàn)在數據量比較龐大,其實處理起來沒那么復雜,還好最近跟螞蟻老師學習了Pandas的一些知識,這里推薦一下,螞蟻老師的課真的是純干貨,課程講解都是以實用為主。經過一番思考,已經有了一個大概的思路:
處理各單位的報表、匯總 處理供應商信息表 查找結果。
分步實現(xiàn)
1.處理各單位的報表、匯總
先看一下收到的匯總表: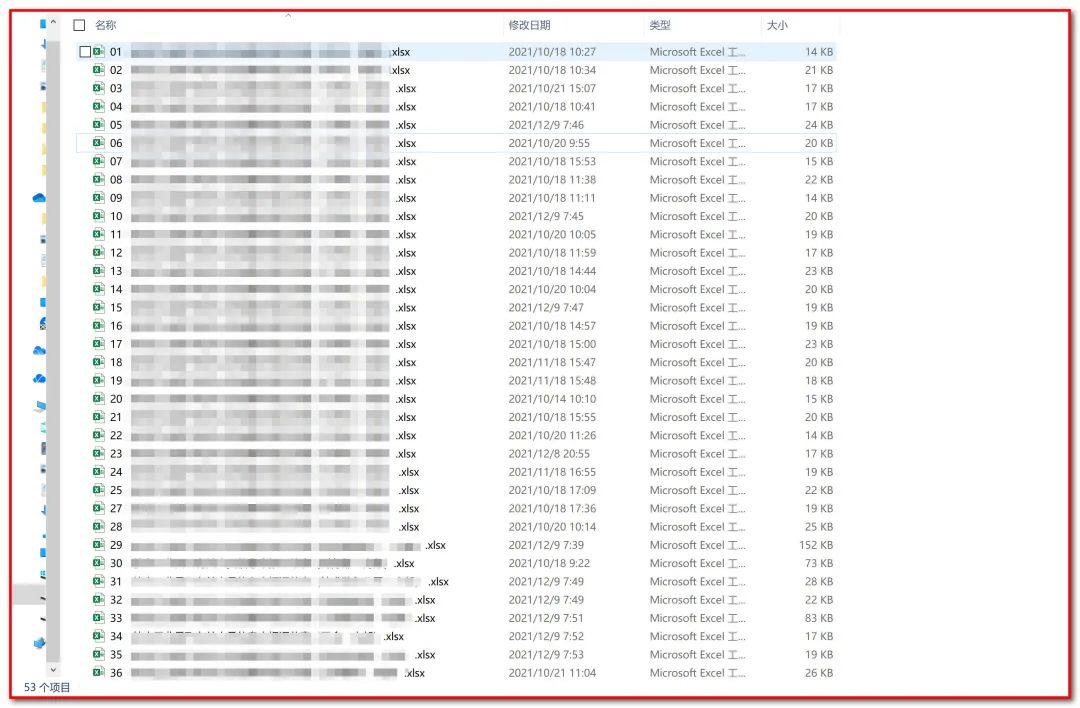
一共53張,這里只截取了一部分,這里要感謝Y老師細心的將每個Excel命名格式給統(tǒng)一了。然后全部打開,檢查格式,補全內容,尋找規(guī)律。
import?os
import?xlwings?as?xw
app?=?xw.App(visible=True,?add_book=False)
path?=?"./原始文件"
fnames?=?os.listdir(path)
for?fname?in?fnames[32:]:
????fpath?=?path+"/"+fname
????app.books.open(fpath)
雖然之前工作開展的時候,有固定的模板,但是做過相應工作的人都知道,總有人會改動模板。快速的過了一遍,所幸這次改動的沒幾個人,少量的補全后,開始觀察規(guī)律。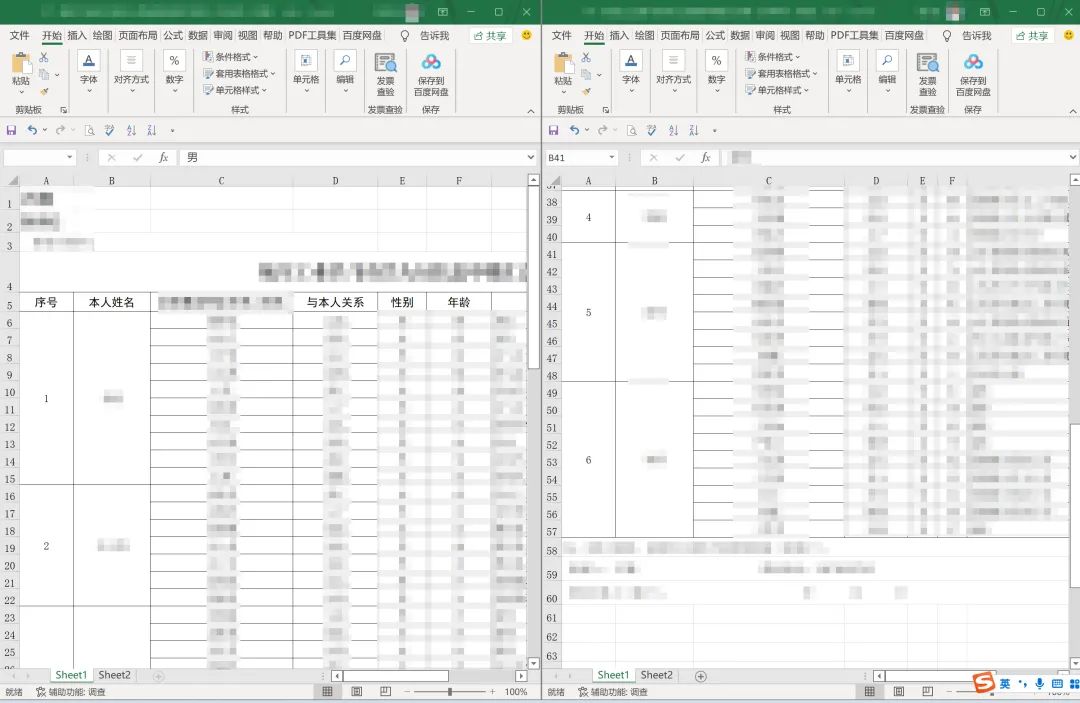
通過觀察發(fā)現(xiàn):每個表的前面4行和后面3行是不需要的信息,這里已經有了第一步的思路,讀取每一個Excel,忽略前4行,遍歷index,取出最后3行刪掉,再合并所有的Dataframe,代碼實現(xiàn):
?def?get_collect(self):
????????'''
????????第一步:整理各單位報表,數據清洗,形成匯總表
????????:return:?Dataframe
????????'''
????????fnames?=?os.listdir(self.path_1)
????????data_list?=?[]
????????for?fname?in?fnames:
????????????#*是需要替換的內容
????????????new_fnamne?=?fname.replace("**************(","")[2:-9]
????????????fpath?=?self.path_1?+"/"+fname
????????????print(fpath)
????????????df?=?pd.read_excel(fpath,skiprows=4,sheet_name="Sheet1")??#打開文件,忽略前四行
????????????del_row_list?=?[i?for?i?in?df.index][-3:]??#遍歷索引,列表取值取出最后三個
????????????df.drop([j?for?j?in?del_row_list],inplace=True)??#刪除最后三行
????????????df.drop("序號",axis=1,inplace=True)???#刪除序號列
????????????df.loc[:,"本人姓名"]?=?df["本人姓名"].fillna(method="ffill")??#向下填充
????????????df.loc[:,"填報單位"]?=?new_fnamne??#新增列
????????????data_list.append(df)
????????df_all?=?pd.concat(data_list,ignore_index=True)
????????df_all.to_excel("匯總表.xlsx")
????????return?df_all
沒有問題,開著手處理第二步
2.處理供應商信息表
有了第一步的良好開端,我們照例還是先打開表格觀察規(guī)律: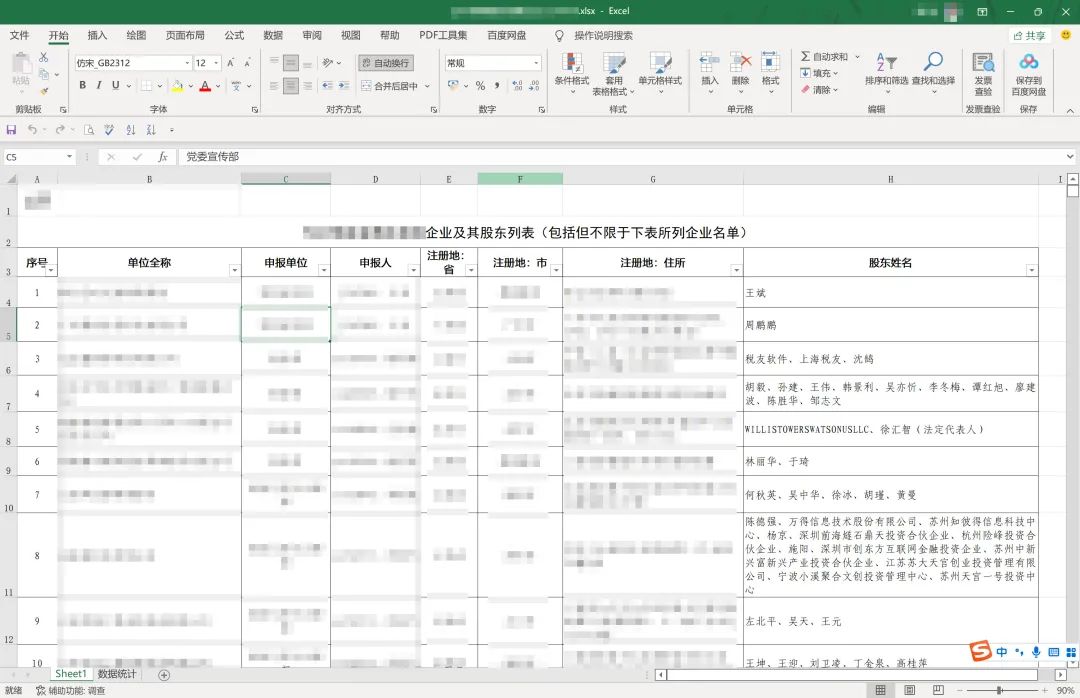
觀察發(fā)現(xiàn):前面2行和其他列都是正常的,唯獨“股東姓名”列是一行多人,而且是用“、”隔開的,這里暫時沒有學到,開始萬能的百度,“pandas一行變多行”,最終處理如下:
?????def?get_proexcel(self):
????????'''
???????第二步:清洗供應商信息表,一行變多行
????????:return:Dataframe
????????'''
????????fnames?=?os.listdir(self.path_2)
????????for?fname?in?fnames:
????????????if?len(fnames)?!=?0:
????????????????fpath?=?self.path_2+"/"+fname
????????????????df?=?pd.read_excel(fpath,skiprows=2,sheet_name="Sheet1")???#打開文件,忽略前兩行
????????????????df.loc[:,?"股東姓名"]?=?df["股東姓名"].map(lambda?x:?x.split("、"))???#將股東姓名按“、”拆分
????????????????df_new?=?df.explode("股東姓名")???#一行變多行
????????????????df_new.to_excel("整理后供應商表.xlsx",?index=False)
????????????????#?print(df_new)
????????????????return?df_new
????????????else:
????????????????pass
運行,沒有問題,到這里基本上已經成功大半了,如果數據較少的話已經可以手動去對比了。但是咱既然選擇了自動處理,那本著“能坐著絕不站著,能躺著絕不坐著”的先進思路,一定要進行第三步的。
3.查找結果
開始第三步merge兩個Dataframe,形成最終的比對檢查結果,形成最終匯總的Excel。
?def?get_merge(self):
????????'''
????????第三步:merge兩個Dataframe
????????:return:
????????'''
????????#選擇供應商表需要merge的列
????????df_sinfo?=?self.get_proexcel()[["單位全稱",?"申報單位",?"申報人","注冊地:省","注冊地:市","注冊地:住所","股東姓名"]]
????????#merge兩個Dataframe
????????df_merge?=?pd.merge(left=self.get_collect(),?right=df_sinfo,?left_on="*******",?right_on="股東姓名")
????????df_merge.to_excel("查詢結果匯總.xlsx")
全部代碼
import?pandas?as?pd
import?os
'''用pandas處理excel,上萬行數據的查找,比對。
'''
class?Dataexcel():
????def?__init__(self,path_1,path_2):
????????self.path_1?=?path_1
????????self.path_2?=?path_2
????def?get_collect(self):
????????'''
????????第一步:整理各單位報表,數據清洗,形成匯總表
????????:return:?Dataframe
????????'''
????????fnames?=?os.listdir(self.path_1)
????????data_list?=?[]
????????for?fname?in?fnames:
????????????#*是需要替換的內容
????????????new_fnamne?=?fname.replace("********(","")[2:-9]
????????????fpath?=?self.path_1?+"/"+fname
????????????print(fpath)
????????????df?=?pd.read_excel(fpath,skiprows=4,sheet_name="Sheet1")??#打開文件,忽略前四行
????????????del_row_list?=?[i?for?i?in?df.index][-3:]??#遍歷索引,列表取值取出最后三個
????????????df.drop([j?for?j?in?del_row_list],inplace=True)??#刪除最后三行
????????????df.drop("序號",axis=1,inplace=True)???#刪除序號列
????????????df.loc[:,"本人姓名"]?=?df["本人姓名"].fillna(method="ffill")??#向下填充
????????????df.loc[:,"填報單位"]?=?new_fnamne??#新增列
????????????data_list.append(df)
????????df_all?=?pd.concat(data_list,ignore_index=True)
????????df_all.to_excel("匯總表.xlsx")
????????return?df_all
????def?get_proexcel(self):
????????'''
???????第二步:清洗供應商信息表,一行變多行
????????:return:Dataframe
????????'''
????????fnames?=?os.listdir(self.path_2)
????????for?fname?in?fnames:
????????????if?len(fnames)?!=?0:
????????????????fpath?=?self.path_2+"/"+fname
????????????????df?=?pd.read_excel(fpath,skiprows=2,sheet_name="Sheet1")???#打開文件,忽略前兩行
????????????????df.loc[:,?"股東姓名"]?=?df["股東姓名"].map(lambda?x:?x.split("、"))???#將股東姓名按“、”拆分
????????????????df_new?=?df.explode("股東姓名")???#一行變多行
????????????????df_new.to_excel("整理后供應商表.xlsx",?index=False)
????????????????#?print(df_new)
????????????????return?df_new
????????????else:
????????????????pass
????def?get_merge(self):
????????'''
????????第三步:merge兩個Dataframe
????????:return:
????????'''
????????#選擇供應商表需要merge的列
????????df_sinfo?=?self.get_proexcel()[["單位全稱",?"申報單位",?"申報人","注冊地:省","注冊地:市","注冊地:住所","股東姓名"]]
????????#merge兩個Dataframe
????????df_merge?=?pd.merge(left=self.get_collect(),?right=df_sinfo,?left_on="*******",?right_on="股東姓名")
????????df_merge.to_excel("查詢結果匯總.xlsx")
if?__name__?==?'__main__':
????dataexcel?=?Dataexcel("./原始文件","./客商匯總")
????dataexcel.get_merge()
最終結果
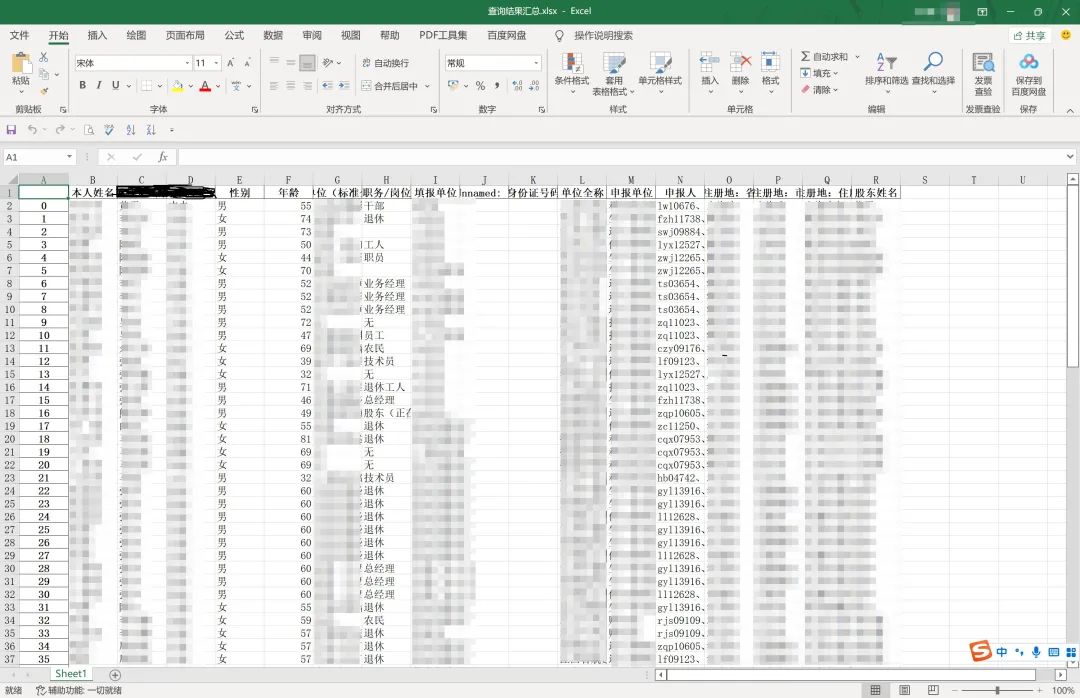
寫在最后
其實這次是的代碼已經是2.0版了,之前用xlrd處理過一版,數據出來有誤,而且讀取相當的不方便,還要再考慮寫入問題。網上有人說用set,但是Excel,尤其是含有人名數據的時候,set會自動去重,結果會有誤。后來學習了螞蟻老師的pandas相關內容,還是pandas相當nice。
最后,推薦螞蟻老師的《零基礎入門到數據分析實戰(zhàn)》課程,極其干貨!還有螞蟻老師的答疑服務(微信:ant_learn_python)
點擊下方《閱讀原文》可以到達課程頁!