
字節(jié)跳動踩坑記#2:Go 服務(wù)鎖死

再挖個(gè)墳,講講去年踩的另一個(gè)坑。
== 前方低能 ==
那是去年7月的一天,被透過落地玻璃的宇宙中心五道口的夕陽照著的正在工位搬磚的我,突然聽到一陣騷亂,轉(zhuǎn)頭一看,收到奪命連環(huán)call的D同學(xué)反饋,流量嚴(yán)重異常。
點(diǎn)開報(bào)警群,一串異常赫然在目:
[?規(guī)則?]:「流量波動過大(嚴(yán)重)?」
[?報(bào)警上下文?]:change:-70.38%
值班人:D(不是我)
報(bào)警方式:電話&Lark
報(bào)警URL:報(bào)警詳情頁
再點(diǎn)開報(bào)警詳情頁一看:
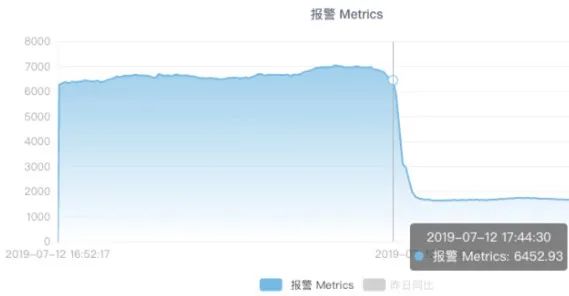
== 排爆?==
解釋一下:在字節(jié)跳動,我們有一個(gè)基于OpenTSDB的metrics平臺(時(shí)序數(shù)據(jù)庫),用于采集和查詢各項(xiàng)監(jiān)控指標(biāo)。
圖中是一個(gè)流量源的請求QPS,在短時(shí)間內(nèi)從 7k 暴降至 2k,從而觸發(fā)了報(bào)警規(guī)則。
除了流量源之外,在這個(gè)指標(biāo)上我們還有機(jī)房、Server IP等其他tag;通過這些tag,我們發(fā)現(xiàn):
來自所有流量源的QPS都在暴降
所有機(jī)房的QPS都在暴降
按IP看,許多機(jī)器的QPS降到0,但部分機(jī)器仍在正常接客
對于異常的機(jī)器,從監(jiān)控上可以看到,其CPU占用陡降至很低的值(約2.5%):
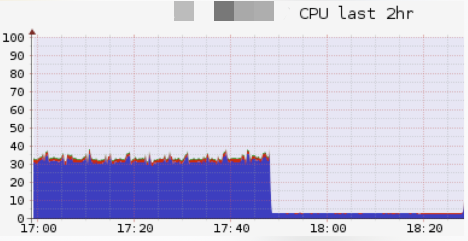
于是這條線索讓我們把問題范圍縮小到某臺機(jī)器上。
進(jìn)一步的排查情況情況是:
ssh可以正常登錄,看起來OS沒啥問題
通過 lsof 可以看到,進(jìn)程仍然在監(jiān)聽業(yè)務(wù)端口,只是不響應(yīng)請求
top看到該進(jìn)程在第一位,占了 99.8%的cpu,有點(diǎn)奇怪
注:這是一臺40核的物理機(jī),top里 99.8% cpu表示進(jìn)程占滿了1個(gè)核心,和前面的CPU監(jiān)控遙相呼應(yīng)。
PID??USER??? RES??%CPU? COMMAND316??user??968497??99.8??./service??1? root? ? 3796???0.0? systemd
雖然尚未定位到問題,但至少進(jìn)一步把問題縮小到進(jìn)程級別了。
既然是 go 程序的問題,那當(dāng)然是要搬出神器?pprof?了,只可惜很快就裝逼失敗?——?因?yàn)檫@個(gè)進(jìn)程已經(jīng)不響應(yīng)任何請求了。

== 減壓 ==
此時(shí)距故障發(fā)生已經(jīng)過了 15 分鐘,對于廣告業(yè)務(wù),不能正常處理請求,對應(yīng)的就是真金白銀的損失。
但這個(gè)case以前沒出現(xiàn)過,一時(shí)半會又定位不了病根,大家都壓力山大。
在這種情況下,經(jīng)驗(yàn)豐富的老司機(jī)們一定不會忘記的,就是壓箱底的大招 —— 重啟大法。
由于線上是大面積機(jī)器異常,我們隨便找了一臺機(jī)器重啟該進(jìn)程,很快,這臺機(jī)器就開始正常接客了。

于是我們留下幾臺異常機(jī)器(保留現(xiàn)場備查)、從服務(wù)注冊中摘掉,并將其余異常機(jī)器全部重啟,暫時(shí)恢復(fù)了業(yè)務(wù)。
但病根未除,問題隨時(shí)可能復(fù)辟,還得繼續(xù)。
== 深挖 ==
前面說到,在top中看到,D項(xiàng)目的進(jìn)程CPU占用率是100%,跑滿了一個(gè)CPU。
這是一個(gè)奇怪的現(xiàn)象,說明它并不是簡單地陷入死鎖,而是在反復(fù)執(zhí)行一些任務(wù),這意味著,如果我們知道它在跑什么,可能就找到病因了。
這時(shí)候老司機(jī)W同學(xué)祭出了 linux 的 perf 命令
$?sudo?perf?top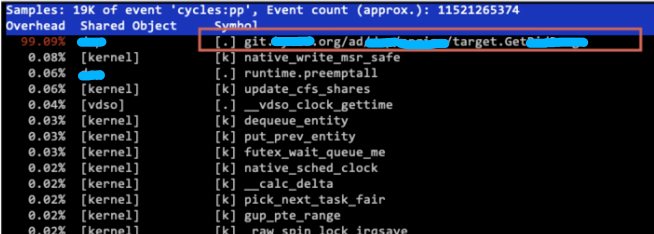
幸福來的太突然,連函數(shù)名都給出來了,送命題秒變送分題

撈了一下代碼,這個(gè) GetXXX 是一個(gè)二分查找的函數(shù),根據(jù)輸入的價(jià)格,查詢對應(yīng)價(jià)格區(qū)間的相關(guān)配置,大概長這樣:
type?Item?struct?{????left?int????right?int????value?int}var?config?=?[]*Item{????{0,?10,?1},????{10,?20,?2},????{20,100,?8},????{100,?1<<31,?10},}func?GetXXX(price?int)?int?{????start,?end?:=?0,?len(config)????mid?:=?(start?+?end)?/?2????for?mid?>=?0?&&?mid?len(config)?{????????if?price?????????????end?=?mid?-?1????????}?else?if?price?>=?config[mid].right?{????????????start?=?mid?+?1????????}?else?{????????????return?config[mid].value????????}????????mid?=?(start?+?end)?/?2}????return?-1}
按說這么簡單的代碼,線上跑了至少也幾個(gè)月了,不應(yīng)該有啥BUG,按照胡爾莫斯·柯南的教誨,排除一切不可能的,真相只有一個(gè),那就是:輸入的價(jià)格是個(gè)負(fù)數(shù)。
負(fù)的價(jià)格?這不由得讓我想起了中行的某款理財(cái)產(chǎn)品……

當(dāng)然這還只是個(gè)推論,在日記里三省吾身的胡適告訴我們,要大膽假設(shè),小心求證。
實(shí)錘起來倒也很簡單,到上游的數(shù)據(jù)庫去查了一下,確實(shí)出現(xiàn)了負(fù)的價(jià)格。
再后面就是上游系統(tǒng)的BUG了,通過日志記錄發(fā)現(xiàn)在17:44確實(shí)有價(jià)格被改成負(fù)數(shù),排查代碼確認(rèn),Web UI及對應(yīng)的后端代碼是有合法性校驗(yàn)的,但是提供的 API 漏了,最終導(dǎo)致了這次事故。
既然找到了病根,修復(fù)起來就簡單了:
修復(fù)API代碼,加上合法性校驗(yàn)
修復(fù)數(shù)據(jù)庫里的無效數(shù)據(jù)
GetXXX里加上無效價(jià)格檢測(防御性編程)
== 填坑 ==
業(yè)務(wù)的坑是填完了,但是技術(shù)的坑還沒:為什么一個(gè)死循環(huán)會導(dǎo)致進(jìn)程卡死呢?
按照調(diào)度的常識來推理,一個(gè)線程(或goroutine)不應(yīng)該阻塞其他線程的執(zhí)行。
比如運(yùn)行下面這段代碼,可以看到,進(jìn)程并沒有卡死,第一個(gè) for 循環(huán)確實(shí)會不斷輸出 i 的值。
var i int64 = 0func main() {go func() {for {fmt.Println(atomic.LoadInt64(&i))????????????time.Sleep(time.Millisecond?*?500)}}()for {atomic.AddInt64(&i, 1)}}
這說明“卡死”的原因還沒有這么簡單。
這樣簡單的代碼無法復(fù)現(xiàn)前面的問題,還是要把死循環(huán)放到復(fù)雜場景下才能復(fù)現(xiàn),比如加入前述 D 項(xiàng)目的代碼里,簡單粗暴直接有效。
通過加上 GODEBUG 環(huán)境變量:
$?GODEBUG="schedtrace=2000,scheddetail=1"?./service可以看到有一個(gè)線索:gcwaiting=1
SCHED?2006ms:?gomaxprocs=64?idleprocs=0?threads=8?spinningthreads=0?idlethreads=5?runqueue=0?gcwaiting=1?nmidlelocked=0?stopwait=1?sysmonwait=0
這就形成了閉環(huán):gc需要STW,但是這個(gè)goroutine在死循環(huán),無法被中斷,而其他goroutine已經(jīng)被中斷、等待gc完成,最終導(dǎo)致了這個(gè)局面。
可以在前述代碼里手動觸發(fā) gc 實(shí)錘一下:現(xiàn)象和線上完全一致。
var?i?int64?=?0func?main()?{????go?func()?{????????for?{????????????fmt.Println(atomic.LoadInt64(&i))????????????time.Sleep(time.Millisecond?*?500)????????????runtime.GC()?//手動觸發(fā)GC????????}}()????for?{????????atomic.AddInt64(&i,?1)}}
但還沒完 —— 以上現(xiàn)象似乎并不符合 go 宣稱的“搶占式調(diào)度”啊!

實(shí)際上 Go 實(shí)現(xiàn)的是一個(gè) Cooperating Scheduler(協(xié)作式調(diào)度器)。一般而言,協(xié)作式調(diào)度器需要線程(準(zhǔn)確地說是協(xié)程)主動放棄CPU來實(shí)現(xiàn)調(diào)度(runtime.Gosched(),對應(yīng) python/java 的 yield),但 Go 的 runtime 會在函數(shù)調(diào)用判斷是否要擴(kuò)展棧空間的同時(shí),檢測 G 的搶占flag,從而實(shí)現(xiàn)了一個(gè)看起來像是搶占式調(diào)度的scheduler。
這還有個(gè)小問題?—— 上面的代碼里不是調(diào)用了 atomic.AddInt64 么?這個(gè)倒是簡單,通過??go?tool compile -S?main.go?可以看到,AddInt64 已經(jīng)被 inline 了;但只要在這里再加上個(gè) fmt.Println 就可以破功了(試試看?)。
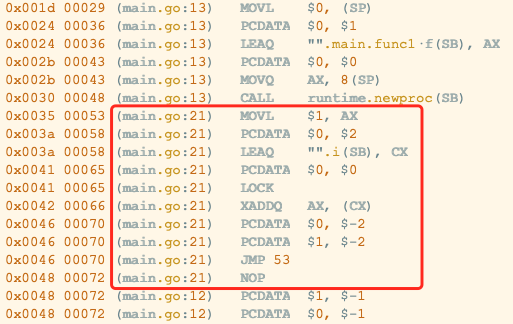
(被inline了的AddInt64)
== 收尾 ==
最后,如果你發(fā)現(xiàn)前面的代碼怎么都不能復(fù)現(xiàn) —— 那你一定是在用 go 1.14+ 了,這個(gè)版本實(shí)現(xiàn)了一個(gè)基于 SIGURG 信號的搶占式調(diào)度,再也不怕死循環(huán)/密集計(jì)算搞死 gc 了(不過代價(jià)是,出現(xiàn)死循環(huán)導(dǎo)致的性能下降問題更難排查了),對此感興趣的同學(xué)推薦學(xué)習(xí)《Go語言原本:6.7 協(xié)作與搶占》,詳見文末“閱讀原文”。
簡單總結(jié)一下:
二分查找可能會死循環(huán);
在 go 1.13 及以下版本,死循環(huán)/密集計(jì)算會導(dǎo)致調(diào)度問題;
特別是遇到 gc 的情況,可能會鎖死進(jìn)程;
在Linux下可以用perf top來做 profiling;
參考鏈接
[1]?如何定位 golang 進(jìn)程 hang 死的 bug
https://xargin.com/how-to-locate-for-block-in-golang/
[2]?關(guān)于 Go1.14,你一定想知道的性能提升與新特性
https://gocn.vip/topics/9611
[3]?Go語言原本:6.7 協(xié)作與搶占
https://changkun.de/golang/zh-cn/part2runtime/ch06sched/preemption/
推薦閱讀
站長 polarisxu
自己的原創(chuàng)文章
不限于 Go 技術(shù)
職場和創(chuàng)業(yè)經(jīng)驗(yàn)
Go語言中文網(wǎng)
每天為你
分享 Go 知識
Go愛好者值得關(guān)注