
ECCV2020 | 即插即用,漲點(diǎn)明顯!FPT:特征金字塔Transformer
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
來(lái)源:AI算法修煉營(yíng)

這篇文章收錄于ECCV2020,將Transformer機(jī)制應(yīng)用于對(duì)特征金字塔FPN的改進(jìn)上,整體思路新穎,和之前的將Transformer應(yīng)用于目標(biāo)檢測(cè)、語(yǔ)義分割、超分辨率等任務(wù)的思想相類似,是一個(gè)能夠繼續(xù)挖掘的方向。
論文地址:https://arxiv.org/abs/2007.09451
代碼地址:https://github.com/ZHANGDONG-NJUST/FPT
跨空間和尺度的特征交互是現(xiàn)代視覺(jué)識(shí)別系統(tǒng)的基礎(chǔ),因?yàn)樗鼈円肓擞幸娴囊曈X(jué)環(huán)境。通常空間上下文信息被動(dòng)地隱藏在卷積神經(jīng)網(wǎng)絡(luò)不斷增加的感受野中,或者被non-local卷積主動(dòng)地編碼。但是,non-local空間交互作用并不是跨尺度的,因此它們無(wú)法捕獲在不同尺度中的對(duì)象(或部分)的非局部上下文信息。為此,本文提出了一種在空間和尺度上完全活躍的特征交互,稱為特征金字塔Transformer(FPT)。它通過(guò)使用三個(gè)專門設(shè)計(jì)的Transformer,以自上而下和自下而上的交互方式,將任何一個(gè)特征金字塔變換成另一個(gè)同樣大小但具有更豐富上下文的特征金字塔。FPT作為一個(gè)通用的視覺(jué)框架,具有合理的計(jì)算開(kāi)銷。最后,本文在實(shí)例級(jí)(即目標(biāo)檢測(cè)和實(shí)例分割)和像素級(jí)分割任務(wù)中進(jìn)行了廣泛的實(shí)驗(yàn),使用不同的主干和頭部網(wǎng)絡(luò),并觀察到比所有baseline和最先進(jìn)的方法一致的改進(jìn)。
簡(jiǎn)介
現(xiàn)代視覺(jué)識(shí)別系統(tǒng)與上下文息息相關(guān)。由于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的層次結(jié)構(gòu),如圖1(a)所示,通過(guò)pooling池化、stride或空洞卷積等操作,將上下文編碼在逐漸變大的感受野(綠色虛線矩形)中。因此,對(duì)最后一個(gè)特征圖的預(yù)測(cè)基本上是基于豐富的上下文信息。
Scale also matters。尺度scale也很重要,傳統(tǒng)的解決方案是對(duì)同一圖像進(jìn)行堆積多尺度的圖像金字塔,其中較高/較低的層次采用較低/較高分辨率的圖像進(jìn)行輸入。因此,不同尺度的物體在其相應(yīng)的層次中被識(shí)別。然而,圖像金字塔增加了CNN前向傳遞的耗時(shí),因?yàn)槊總€(gè)圖像都需要一個(gè)CNN來(lái)識(shí)別。幸運(yùn)的是,CNN提供了一種特征金字塔FPN,即通過(guò)低/高層次的特征圖代表高/低分辨率的視覺(jué)內(nèi)容,而不需要額外的計(jì)算開(kāi)銷。如圖1(b)所示,可以通過(guò)使用不同級(jí)別的特征圖來(lái)識(shí)別不同尺度的物體,即小物體(電腦)在較低層級(jí)中識(shí)別,大物體(椅子和桌子)在較高層級(jí)中識(shí)別。
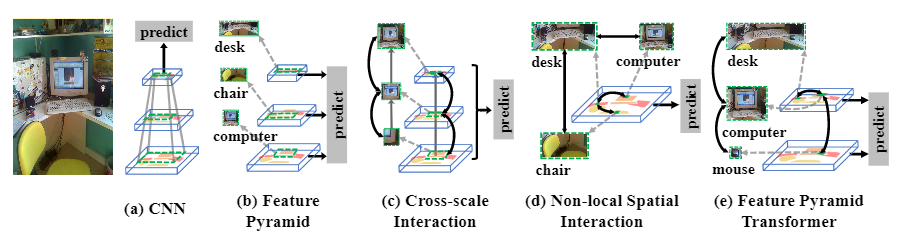
Sometimes the recognition——尤其是像語(yǔ)義分割這樣的像素級(jí)標(biāo)簽,需要結(jié)合多個(gè)尺度的上下文。例如圖1(c)中,要對(duì)顯示的幀區(qū)域的像素賦予標(biāo)簽,也許從較低的層次上看,實(shí)例本身的局部上下文就足夠了;但對(duì)于類外的像素,需要同時(shí)利用局部上下文和較高層次的全局上下文。
為此,本文提出了一種稱為特征金字塔轉(zhuǎn)換器Transformer(FPT)的新穎特征金字塔網(wǎng)絡(luò),用于視覺(jué)識(shí)別任務(wù),例如實(shí)例級(jí)(即目標(biāo)檢測(cè)和實(shí)例分割)和像素級(jí)分割任務(wù)。簡(jiǎn)而言之,如圖2所示,F(xiàn)PT的輸入是一個(gè)特征金字塔,而輸出是一個(gè)變換的金字塔,其中每個(gè)level都是一個(gè)更豐富的特征圖,它編碼了跨空間和尺度的非局部non-local交互作用。然后,可以將特征金字塔附加到任何特定任務(wù)的頭部網(wǎng)絡(luò)。顧名思義,F(xiàn)PT中特征之間的交互采用了 transformer-style。它具有整潔的查詢query,鍵key和值value操作,在選擇遠(yuǎn)程信息進(jìn)行交互時(shí)非常有效,從而可以調(diào)整我們的目標(biāo):以適當(dāng)?shù)囊?guī)模進(jìn)行非局部non-local交互。另外,像其他任何transformer模型一樣,使用TPU可以減輕計(jì)算開(kāi)銷。
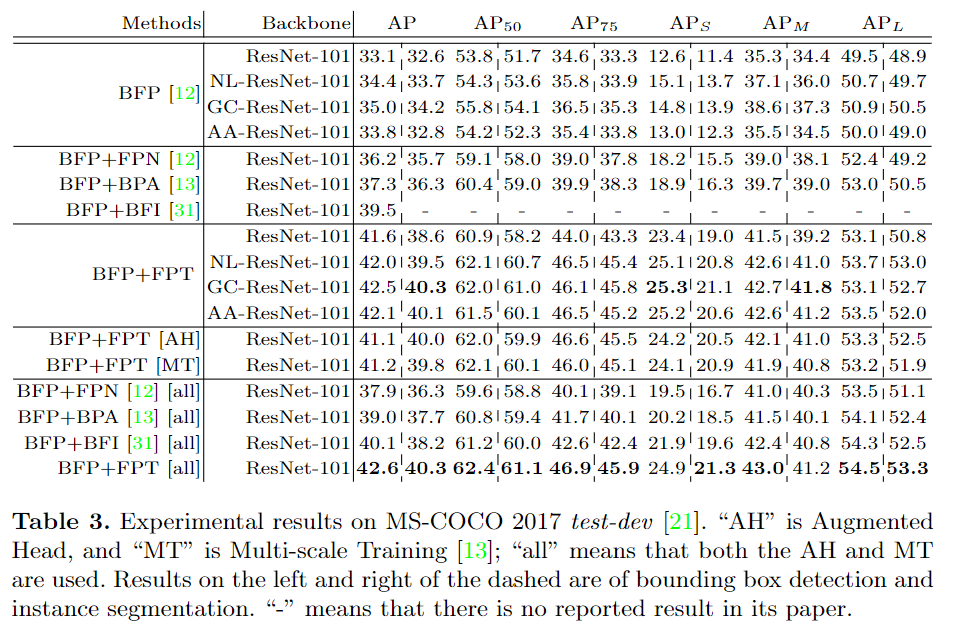
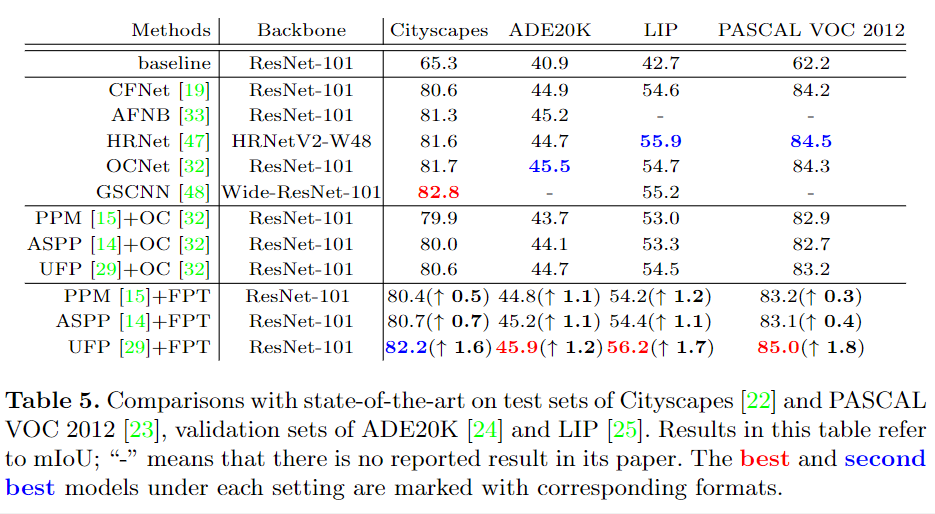
大量的實(shí)驗(yàn)表明,F(xiàn)PT可以極大地改善傳統(tǒng)的檢測(cè)/分割網(wǎng)絡(luò):1)在MS-COCO test-dev數(shù)據(jù)集上,用于框檢測(cè)的百分比增益為8.5%,用于遮罩實(shí)例的mask AP值增益為6.0%;2)對(duì)于語(yǔ)義分割,分別在Cityscapes和PASCAL VOC 2012 測(cè)試集上的增益分別為1.6%和1.2%mIoU;在ADE20K 和LIP 驗(yàn)證集上的增益分別為1.7%和2.0%mIoU。
本文方法
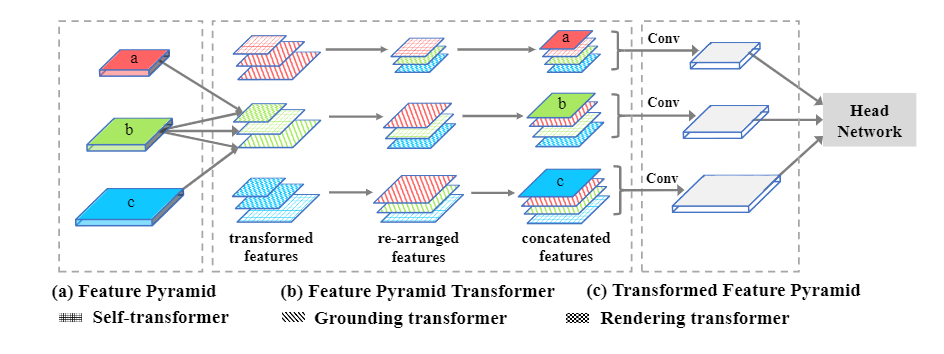
圖2. 本文提出的FPT網(wǎng)絡(luò)的總體結(jié)構(gòu)。不同的紋理圖案表示不同的特征轉(zhuǎn)換器,不同的顏色表示具有不同比例的特征圖。“ Conv”表示輸出尺寸為256的3×3卷積。在不失一般性的前提下,頂層/底層特征圖沒(méi)有rendering/grounding 轉(zhuǎn)換器。
如圖2的FPT分解圖所示,主要是是三種transformer的設(shè)計(jì):1)自變換器Self-Transformer(ST)。它是基于經(jīng)典的同級(jí)特征圖內(nèi)的非局部non-local交互,輸出與輸入具有相同的尺度。2)Grounding Transformer(GT)。它是以自上而下的方式,輸出與下層特征圖具有相同的比例。直觀地說(shuō),將上層特征圖的 "概念 "與下層特征圖的 "像素 "接地。特別是,由于沒(méi)有必要使用全局信息來(lái)分割對(duì)象,而局部區(qū)域內(nèi)的上下文在經(jīng)驗(yàn)上更有參考價(jià)值,因此,還設(shè)計(jì)了一個(gè)locality-constrained的GT,以保證語(yǔ)義分割的效率和準(zhǔn)確性。3)Rendering Transformer(RT)。它是以自下而上的方式,輸出與上層特征圖具有相同的比例。直觀地說(shuō),將上層 "概念 "與下層 "像素 "的視覺(jué)屬性進(jìn)行渲染。這是一種局部交互,因?yàn)橛昧硪粋€(gè)遠(yuǎn)處的 "像素 "來(lái)渲染一個(gè) "對(duì)象 "是沒(méi)有意義的。每個(gè)層次的轉(zhuǎn)換特征圖(紅色、藍(lán)色和綠色)被重新排列到相應(yīng)的地圖大小,然后與原始map連接,然后再輸入到卷積層,將它們調(diào)整到原始 "厚度"。
1、Non-Local Interaction Revisited
傳統(tǒng)的Non-Local Interaction
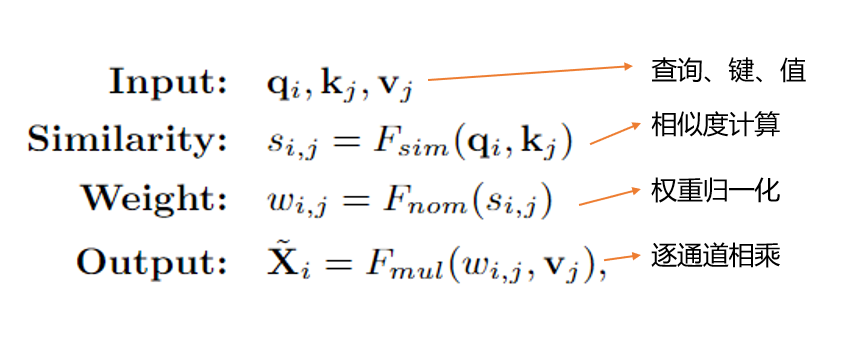
2、Self-Transformer
自變換器(Self-Transformer,ST)的目的是在同一張?zhí)卣鲌D上捕獲共同發(fā)生的對(duì)象特征。如圖3(a)所示,ST是一種修改后的非局部non-local交互,輸出的特征圖與其輸入特征圖的尺度相同。與其他方法區(qū)別在于,作者部署了Mixture of Softmaxes(MoS)作為歸一化函數(shù),事實(shí)證明它比標(biāo)準(zhǔn)的Softmax在圖像上更有效。具體來(lái)說(shuō),首先將查詢q和鍵k劃分為N個(gè)部分。然后,使用Fsim計(jì)算每對(duì)圖像的相似度分?jǐn)?shù)。基于MoS的歸一化函數(shù)Fmos表達(dá)式如下:
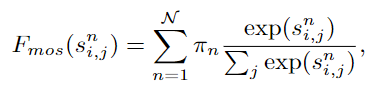
自變換器可以表達(dá)為:

3、Grounding Transformer
Grounding Transformer(GT)可以歸類為自上而下的非局部non-local交互,它將上層特征圖Xct中的 "概念 "與下層特征圖Xf中的 "像素 "進(jìn)行對(duì)接。輸出特征圖與Xf具有相同的尺度。一般來(lái)說(shuō),不同尺度的圖像特征提取的語(yǔ)義或語(yǔ)境信息不同,或者兩者兼而有之。此外,根據(jù)經(jīng)驗(yàn),當(dāng)兩個(gè)特征圖的語(yǔ)義信息不同時(shí),euclidean距離的負(fù)值比點(diǎn)積更能有效地計(jì)算相似度。所以我們更傾向于使用euclidean距離Fedu作為相似度函數(shù),其表達(dá)方式為:

于是,Grounding Transformer可以表述為:

在特征金字塔中,高/低層次特征圖包含大量全局/局部圖像信息。然而,對(duì)于通過(guò)跨尺度特征交互的語(yǔ)義分割,沒(méi)有必要使用全局信息來(lái)分割圖像中的兩個(gè)對(duì)象。從經(jīng)驗(yàn)上講,查詢位置周圍的局部區(qū)域內(nèi)的上下文會(huì)提供更多信息。這就是為什么常規(guī)的跨尺度交互(例如求和和級(jí)聯(lián))在現(xiàn)有的分割方法中有效的原因。如圖3(b)所示,它們本質(zhì)上是隱式的局部non-local樣式,但是本文的默認(rèn)GT是全局交互的。
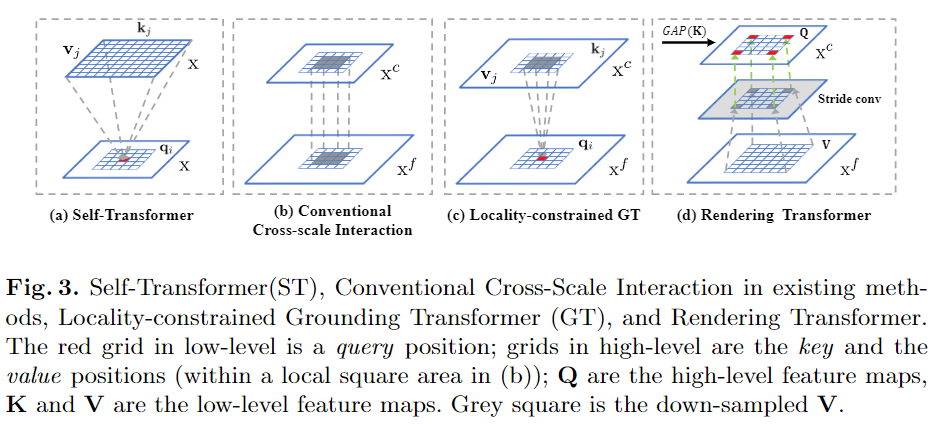
Locality-constrained Grounding Transformer。因此,作者引入了局域性GT轉(zhuǎn)換進(jìn)行語(yǔ)義分割,這是一個(gè)明確的局域特征交互作用。如圖3(c)所示,每個(gè)q(即低層特征圖上的紅色網(wǎng)格)在中心區(qū)域的局部正方形區(qū)域內(nèi)與k和v的一部分(即高層特征圖上的藍(lán)色網(wǎng)格)相互作用。坐標(biāo)與q相同,邊長(zhǎng)為正方形。特別是,對(duì)于k和v超出索引的位置,改用0值。
4、Rendering Transformer
Rendering Transformer(RT)以自下而上的方式工作,旨在通過(guò)將視覺(jué)屬性合并到低層級(jí)“像素”中來(lái)渲染高層級(jí)“概念”。如圖3(d)所示,RT是一種局部交互,其中該局部是基于渲染具有來(lái)自另一個(gè)遙遠(yuǎn)對(duì)象的特征或?qū)傩缘摹皩?duì)象”是沒(méi)有意義的這一事實(shí)。
在本文的實(shí)現(xiàn)中,RT不是按像素進(jìn)行的,而是按整個(gè)特征圖進(jìn)行的。具體來(lái)說(shuō),高層特征圖定義為Q,低層特征圖定義為K和V,為了突出渲染目標(biāo),Q和K之間的交互是以通道導(dǎo)向的關(guān)注方式進(jìn)行的,K首先通過(guò)全局平均池化(GAP)計(jì)算出Q的權(quán)重w。然后,加權(quán)后的Q(即Qatt)通過(guò)3×3卷積進(jìn)行優(yōu)化,V通過(guò)3×3卷積與步長(zhǎng)來(lái)縮小特征規(guī)模(圖3(d)中的灰色方塊)。最后,將優(yōu)化后的Qatt和下采樣的V(即Vdow)相加,再經(jīng)過(guò)一次3×3卷積進(jìn)行細(xì)化處理。
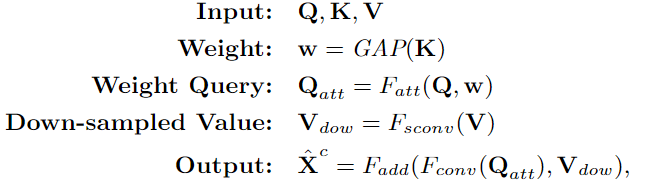
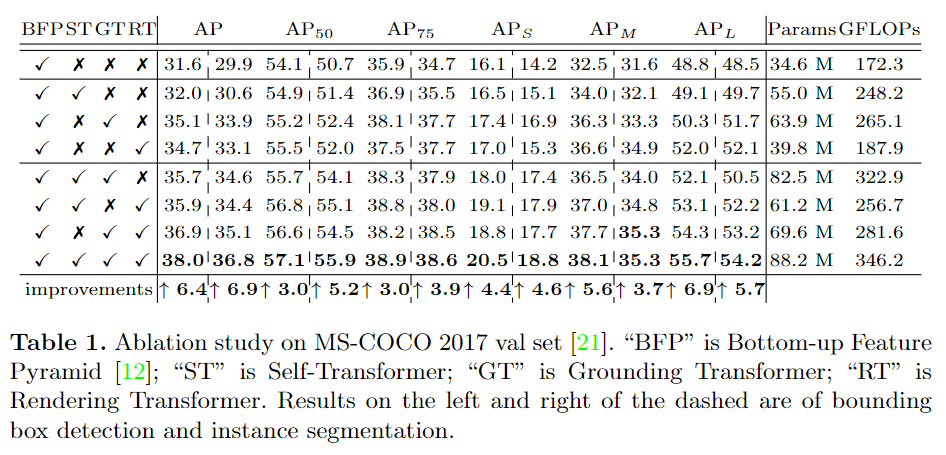
消融實(shí)驗(yàn):
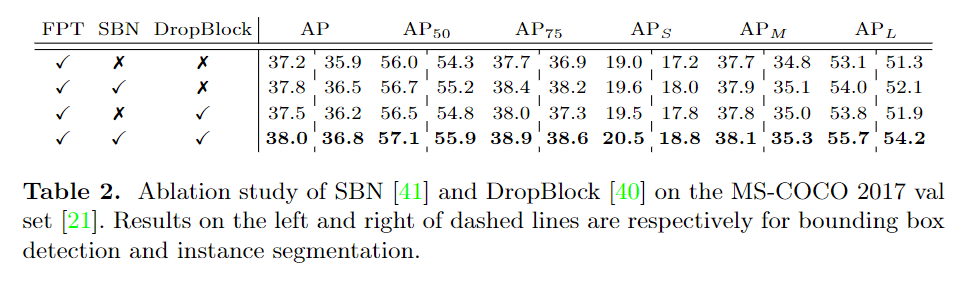
對(duì)比實(shí)驗(yàn)
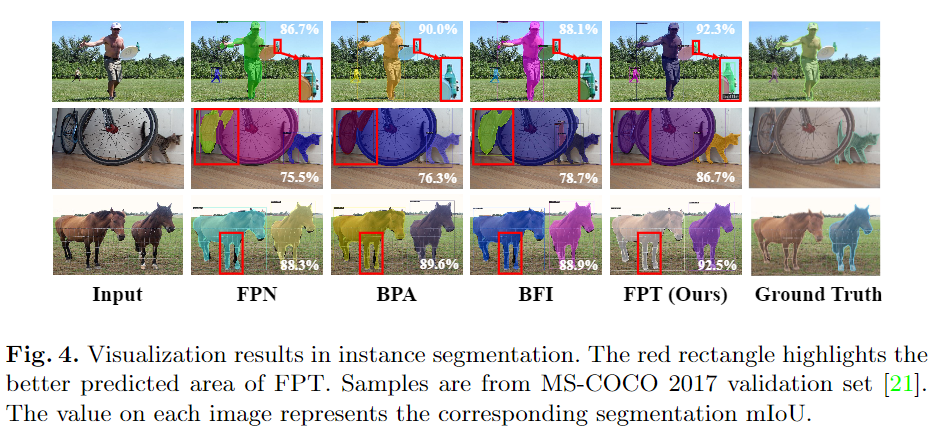
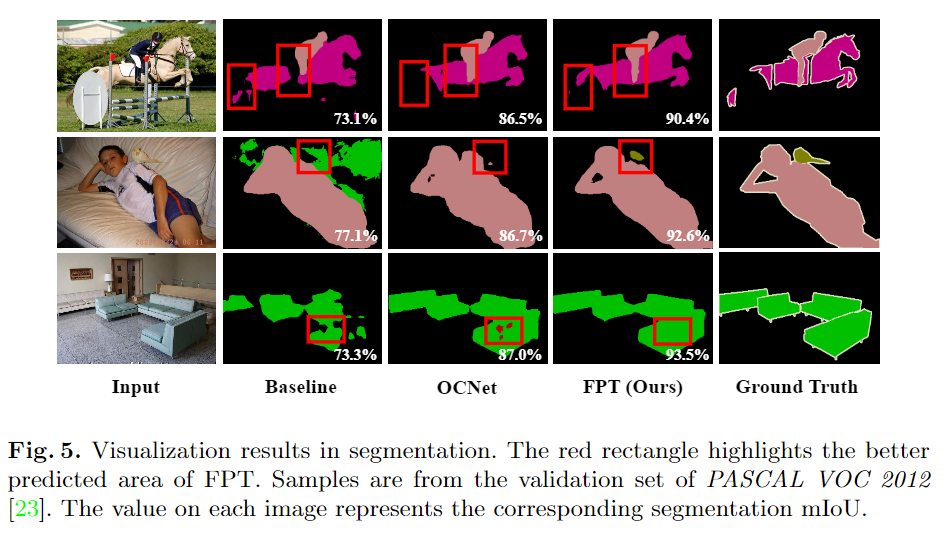
可視化對(duì)比


更多細(xì)節(jié)可參考論文原文。

個(gè)人微信(如果沒(méi)有備注不拉群!)
請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
