
使用Python和YOLO檢測(cè)車(chē)牌
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

計(jì)算機(jī)視覺(jué)無(wú)處不在-從面部識(shí)別,制造,農(nóng)業(yè)到自動(dòng)駕駛汽車(chē)。今天,我們將通過(guò)動(dòng)手實(shí)踐進(jìn)入現(xiàn)代計(jì)算機(jī)視覺(jué)世界,學(xué)習(xí)如何使用YOLO算法檢測(cè)車(chē)牌。

來(lái)自Pexels的mali maeder的照片應(yīng)用于定制的YOLO車(chē)牌檢測(cè)模型
傳統(tǒng)計(jì)算機(jī)視覺(jué)方法使用vision方法進(jìn)行檢測(cè)。但由于閾值和輪廓檢測(cè)的局限性,其算法在部分圖像上有效,但無(wú)法推廣。通過(guò)本次學(xué)習(xí),我們將擁有可以在任何天氣情況下用于檢測(cè)車(chē)牌的強(qiáng)大模型。
我們有一個(gè)可靠的數(shù)據(jù)庫(kù),其中包含數(shù)百?gòu)埰?chē)圖像,但是在網(wǎng)上共享它是不道德的。因此,小伙伴必須自己收集汽車(chē)圖像。我們將使用如下照片進(jìn)行演示和驗(yàn)證:

我們還應(yīng)該收集各種光照條件下的車(chē)牌圖像,并從不同角度拍攝圖像。在完成數(shù)據(jù)收集之后,我們將使用一個(gè)名為L(zhǎng)abelIMG的免費(fèi)工具來(lái)完成這項(xiàng)工作。
cd labelImg-masterbrew install qtbrew install libxml2make qt5py3python labelImg.py
從終端執(zhí)行這些操作將打開(kāi)此窗口:
圖2-啟動(dòng)LabelIMG
接下來(lái),單擊左側(cè)菜單上的“打開(kāi)目錄”圖標(biāo)。找到存儲(chǔ)汽車(chē)圖像的文件夾。它會(huì)自動(dòng)打開(kāi)第一個(gè)圖像:

圖像3 -用LabelIMG打開(kāi)圖像(作者提供的圖像)
左側(cè)面板中的標(biāo)簽會(huì)顯示YOLO。接下來(lái),按鍵盤(pán)上的W鍵以打開(kāi)RectBox 工具。在車(chē)牌周?chē)L制一個(gè)矩形,輸入標(biāo)簽,然后單擊“確定”:
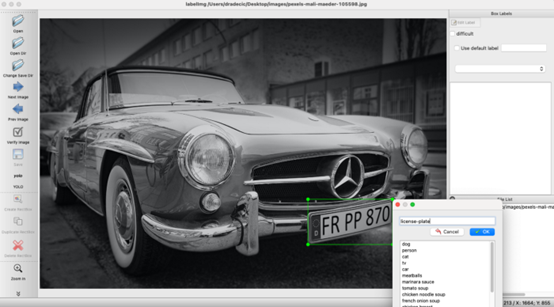
圖4 -在板周?chē)L制矩形
按CTRL + S將板塊坐標(biāo)保存到文本文件。單個(gè)文件應(yīng)如下所示:

圖像5- LabelIMG生成的文本文件
該LabelIMG軟件將保存的矩形框坐標(biāo)文件對(duì)應(yīng)于保存的每個(gè)圖像。還將所有類(lèi)的列表保存到名為classes.txt的文件中。我們打開(kāi)它,其中可能列出了許多我們不感興趣的內(nèi)容。可以刪除license-plate以外的所有內(nèi)容。

圖6-類(lèi)列表
仍然存在一個(gè)問(wèn)題。我們只有一個(gè)類(lèi)(license-plate),但是坐標(biāo)文件中的類(lèi)索引為15,我們只需查看圖片5并自行驗(yàn)證即可。
我們將使用Python加載每個(gè)坐標(biāo)文件,以通過(guò)將類(lèi)索引更改為1來(lái)解決此問(wèn)題。這是代碼段:
import glob# Contains all .txt files except our listof classestxt_files = [file for file inglob.glob('images/*.txt') if file != 'images/classes.txt']# Read every .txt file and store it'scontent into variable currfor file in txt_files:with open(file, 'r') as f:curr = f.read()# Replace class index 15 with 1 and storeit in a variable newnew = curr.replace('15 ', '1 ')# Once again open every .txt file and makethe replacementfor file in txt_files:with open(file, 'w') as f:f.write(new)
到目前為止,我們已經(jīng)完成了數(shù)據(jù)集收集和準(zhǔn)備。接下來(lái),我們需要壓縮文件并進(jìn)行模型訓(xùn)練。
我們已經(jīng)有幾百個(gè)帶有標(biāo)簽的汽車(chē)圖像。足夠我們訓(xùn)練一個(gè)好的YOLO模型,接下來(lái)就是我們要做的。我們將在帶有GPU后端的Google Colab上訓(xùn)練模型。我們的案例中,在Colab中訓(xùn)練模型大約需要2個(gè)小時(shí),但是時(shí)間會(huì)有所變化,具體取決于GPU和數(shù)據(jù)集的大小。
我們將通過(guò)接下來(lái)的七個(gè)步驟來(lái)訓(xùn)練模型。
第1步-配置GPU環(huán)境
在新的筆記本中,轉(zhuǎn)到運(yùn)行時(shí)-更改運(yùn)行時(shí)類(lèi)型,然后在下拉列表中選擇GPU:
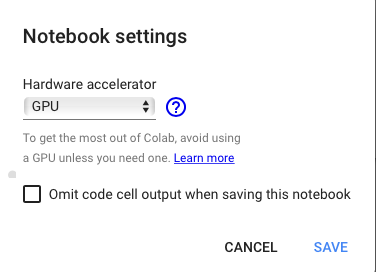
圖7-切換到GPU運(yùn)行時(shí)
第2步-掛載Google云端硬盤(pán)
在Google云端硬盤(pán)中,創(chuàng)建一個(gè)備份文件夾。我們將其命名為yolo-license-plates。這就是存儲(chǔ)模型權(quán)重和配置的地方。在第一個(gè)單元格中,執(zhí)行以下代碼來(lái)安裝Google云端硬盤(pán):
from google.colab import drivedrive.mount('/content/gdrive')!ln -s /content/gdrive/My\ Drive/ /mydrive
步驟3 —下載并配置Darknet
Darknet是一個(gè)開(kāi)源神經(jīng)網(wǎng)絡(luò)框架,具有YOLO對(duì)象檢測(cè)系統(tǒng)。我們可以通過(guò)執(zhí)行以下代碼行來(lái)下載它:
!git clonehttps://github.com/AlexeyAB/darknet接下來(lái),在darknet/Makefile中我們必須配置一些內(nèi)容。在以下行上更改值:
第1行-從GPU=0到GPU=1
第2行-從CUDNN=0到CUDNN=1
第4行-從OPENCV=0到OPENCV=1
并保存文件。這些更改使我們可以在訓(xùn)練時(shí)使用GPU。我們現(xiàn)在可以編譯Darknet
cd darknet!make
這需要等待幾分鐘,我們?cè)诰幾g完成后繼續(xù)進(jìn)行下一步。
步驟4 —配置設(shè)置文件
要知道如何設(shè)置YOLO配置文件,我們需要知道有多少個(gè)類(lèi)。我們只有一個(gè)— license-plate,但這可能會(huì)根據(jù)我們正在處理的問(wèn)題的類(lèi)型而改變。
接下來(lái),我們需要計(jì)算批次數(shù)和過(guò)濾器數(shù)。以下是計(jì)算公式:
批次=類(lèi)數(shù)* 2000
過(guò)濾器=(類(lèi)別數(shù)+ 5)* 3
在我們的例子中,值分別為2000和18。為了準(zhǔn)確起見(jiàn),請(qǐng)復(fù)制YOLO配置文件:
!cp cfg / yolov3.cfg cfg / yolov3-train.cfg并在cfg/yolov3-train.cfg中進(jìn)行以下更改:
第3行-從batch=1到batch=64
第4行-從subdivisions=1到subdivisions=16
第20行-從max_batches=500200到max_batches=2000
603、689和776行-從filters=255到filters=18
610、696和783行-從classes=80到classes=1
保存文件。接下來(lái),我們必須創(chuàng)建兩個(gè)文件-data/obj.names和data/obj.data。這些文件包含有關(guān)類(lèi)名和備份文件夾的信息:
!echo -e 'license-plate' >data/obj.names!echo -e 'classes = 1\ntrain =data/train.txt\nvalid = data/test.txt\nnames = data/obj.names\nbackup =/mydrive/yolo-license-plates' > data/obj.data
到現(xiàn)在,我們已經(jīng)完成了配置,現(xiàn)在讓我們上傳并準(zhǔn)備圖像。
步驟5-上傳和解壓縮圖像
我們只需將zip文件拖放到“文件”側(cè)邊欄菜單中即可。完成后應(yīng)如下所示:
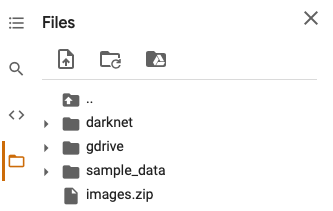
圖8-zip文件上傳后的Colab文件菜單
下一步是為圖像創(chuàng)建一個(gè)文件夾并將其解壓縮:
!mkdir數(shù)據(jù)/對(duì)象!unzip ../images.zip -d data / obj
現(xiàn)在data/obj文件夾應(yīng)包含圖像及其各自的文本文件。
步驟6-訓(xùn)練準(zhǔn)備
接下來(lái),我們要做的就是創(chuàng)建一個(gè)data/train.txt文件。它將包含所有訓(xùn)練圖像的路徑:
import globimages_list = glob.glob('data/obj/*.jpg')with open('data/train.txt', 'w') as f:f.write('\n'.join(images_list))
最后,我們必須下載預(yù)訓(xùn)練的Darknet卷積網(wǎng)絡(luò):
!wgethttps://pjreddie.com/media/files/darknet53.conv.74下載將花費(fèi)幾秒鐘,但是一旦完成,我們便可以進(jìn)入到模型訓(xùn)練階段。
步驟7 —模型訓(xùn)練
現(xiàn)在,開(kāi)始訓(xùn)練過(guò)程可以歸結(jié)為一行shell代碼:!./ darknet檢測(cè)器火車(chē)數(shù)據(jù)/obj.datacfg / yolov3-train.cfg darknet53.conv.74 -dont_show
圖9-Colab中的YOLO模型訓(xùn)練
現(xiàn)在,我們需要等待。訓(xùn)練過(guò)程可能需要幾個(gè)小時(shí),具體取決于圖像的數(shù)量。權(quán)重每10到15分鐘自動(dòng)保存到您的Google云端硬盤(pán)備份文件夾中。在下一部分中,我們將創(chuàng)建一個(gè)腳本,用于在圖像上查找和標(biāo)記車(chē)牌。
模型訓(xùn)練完成后,我們應(yīng)該在Google云端硬盤(pán)備份文件夾中擁有三個(gè)文件:
權(quán)重文件— yolov3_training_final.weights
配置文件- yolov3_testing.cfg
類(lèi)文件— classes.txt
將它們下載到計(jì)算機(jī)上的單個(gè)文件夾中,然后打開(kāi)JupyterLab,我們可以從LicensePlateDetector下面的代碼段中復(fù)制:
import cv2import numpy as npimport matplotlib.pyplot as pltclass LicensePlateDetector:def __init__(self, pth_weights: str, pth_cfg: str, pth_classes: str):self.net = cv2.dnn.readNet(pth_weights, pth_cfg)self.classes = []with open(pth_classes, 'r') as f:self.classes = f.read().splitlines()self.font = cv2.FONT_HERSHEY_PLAINself.color = (255, 0, 0)self.coordinates = Noneself.img = Noneself.fig_image = Noneself.roi_image = Nonedef detect(self, img_path: str):orig = cv2.imread(img_path)self.img = origimg = orig.copy()height, width, _ = img.shapeblob = cv2.dnn.blobFromImage(img, 1 / 255, (416, 416), (0, 0, 0),swapRB=True, crop=False)self.net.setInput(blob)output_layer_names = self.net.getUnconnectedOutLayersNames()layer_outputs = self.net.forward(output_layer_names)boxes = []confidences = []class_ids = []for output in layer_outputs:for detection in output:scores = detection[5:]class_id = np.argmax(scores)confidence = scores[class_id]if confidence > 0.2:center_x = int(detection[0]* width)center_y = int(detection[1]* height)w = int(detection[2] *width)h = int(detection[3] *height)x = int(center_x - w / 2)y = int(center_y - h / 2)boxes.append([x, y, w, h])confidences.append((float(confidence)))class_ids.append(class_id)indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.2, 0.4)if len(indexes) > 0:for i in indexes.flatten():x, y, w, h = boxes[i]label = str(self.classes[class_ids[i]])confidence =str(round(confidences[i],2))cv2.rectangle(img, (x,y), (x +w, y + h), self.color, 15)cv2.putText(img, label + ' ' +confidence, (x, y + 20), self.font, 3, (255, 255, 255), 3)self.fig_image = imgself.coordinates = (x, y, w, h)returndef crop_plate(self):x, y, w, h = self.coordinatesroi = self.img[y:y + h, x:x + w]self.roi_image = roireturn
此類(lèi)有兩種方法:
detect(img_path)–用于從輸入圖像中檢測(cè)車(chē)牌并在其周?chē)L制一個(gè)矩形。crop_plate()–用于從圖像中裁剪檢測(cè)到的車(chē)牌。如果您想應(yīng)用一些OCR來(lái)提取文本,則此方法可用。
lpd = LicensePlateDetector(pth_weights='yolov3_training_final.weights',pth_cfg='yolov3_testing.cfg',pth_classes='classes.txt')# Detect license platelpd.detect('001.jpg')# Plot original image with rectangle aroundthe plateplt.figure(figsize=(24, 24))plt.imshow(cv2.cvtColor(lpd.fig_image, cv2.COLOR_BGR2RGB))plt.savefig('detected.jpg')plt.show()# Crop plate and show cropped platelpd.crop_plate()plt.figure(figsize=(10, 4))plt.imshow(cv2.cvtColor(lpd.roi_image,cv2.COLOR_BGR2RGB))
上面的代碼片段構(gòu)成了LicensePlateDetector該類(lèi)的一個(gè)實(shí)例,檢測(cè)到車(chē)牌,并將其裁剪。這是可視化輸出:

圖10- YOLO模型和LicensePlateDetector類(lèi)的評(píng)估
我們可以在過(guò)去幾個(gè)小時(shí)(或幾天)內(nèi)完成的所有工作。YOLO模型可以完美運(yùn)行,并且可以用于任何使用案例。
這是一篇很長(zhǎng)的分享。祝賀小伙伴一次坐下來(lái)就可以完成實(shí)踐。我們也是花了幾天的時(shí)間才能了解YOLO的工作原理以及如何制作自定義對(duì)象檢測(cè)器。使用相同的方法,小伙伴們可以構(gòu)建任何類(lèi)型的對(duì)象檢測(cè)器。例如,我們重復(fù)使用具有不同文本標(biāo)簽的相同圖像來(lái)檢測(cè)汽車(chē)顏色和汽車(chē)品牌。期待小伙伴們的大顯身手。
") End
End
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~