
史上最全存儲(chǔ)引擎、索引使用及SQL優(yōu)化的實(shí)踐
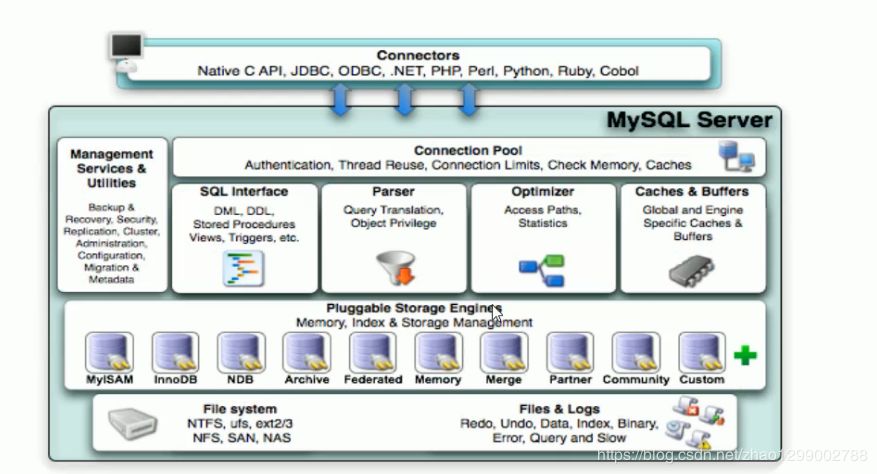
整個(gè)MySQL Server由以下組成 :
Connection Pool :連接池組件
Management Services & Utilities :管理服務(wù)和工具組件
SQL Interface :SQL接口組件
Parser :查詢分析器組件
Optimizer :優(yōu)化器組件
Caches & Buffers :緩沖池組件
Pluggable Storage Engines :存儲(chǔ)引擎
File System :文件系統(tǒng)
1)連接層
上層是一些客戶端和鏈接服務(wù),包含本地sock通信和大多數(shù)基于客戶端/服務(wù)端工具實(shí)現(xiàn)的類似于TCP/IP的通信。主要完成一些類似于連接處理、授權(quán)認(rèn)證、及相關(guān)的安全方案。在該層上引入了線程池的概念,為通過(guò)認(rèn)證安全接入的客戶端提供線程。同樣在該層上可以實(shí)現(xiàn)基于SSL的安全鏈接。服務(wù)器也會(huì)為安全接入的每個(gè)客戶端驗(yàn)證它所具有的操作權(quán)限。
2)服務(wù)層
第二層架構(gòu)主要完成大多數(shù)的核心服務(wù)功能,如SQL接口,并完成緩存的查詢,SQL的分析和優(yōu)化,部分內(nèi)置函數(shù)的執(zhí)行。所有跨存儲(chǔ)引擎的功能也在這一層實(shí)現(xiàn),如過(guò)程、函數(shù)等。在該層,服務(wù)器會(huì)解析查詢并創(chuàng)建相應(yīng)的內(nèi)部解析樹(shù),并對(duì)其完成相應(yīng)的優(yōu)化如確定表的查詢的順序,是否利用索引等,最后生成相應(yīng)的執(zhí)行操作。如果是select語(yǔ)句,服務(wù)器還會(huì)查詢內(nèi)部的緩存,如果緩存空間足夠大,這樣在解決大量讀操作的環(huán)境中能夠很好的提升系統(tǒng)的性能。
3)引擎層
存儲(chǔ)引擎層,存儲(chǔ)引擎真正的負(fù)責(zé)了MySQL中數(shù)據(jù)的存儲(chǔ)和提取,服務(wù)器通過(guò)API和存儲(chǔ)引擎進(jìn)行通信。不同的存儲(chǔ)引擎具有不同的功能,這樣我們可以根據(jù)自己的需要,來(lái)選取合適的存儲(chǔ)引擎。
4)存儲(chǔ)層
數(shù)據(jù)存儲(chǔ)層,主要是將數(shù)據(jù)存儲(chǔ)在文件系統(tǒng)之上,并完成與存儲(chǔ)引擎的交互。
和其他數(shù)據(jù)庫(kù)相比,MySQL有點(diǎn)與眾不同,它的架構(gòu)可以在多種不同場(chǎng)景中應(yīng)用并發(fā)揮良好作用。主要體現(xiàn)在存儲(chǔ)引擎上,插件式的存儲(chǔ)引擎架構(gòu),將查詢處理和其他的系統(tǒng)任務(wù)以及數(shù)據(jù)的存儲(chǔ)提取分離。這種架構(gòu)可以根據(jù)業(yè)務(wù)的需求和實(shí)際需要選擇合適的存儲(chǔ)引擎。
2.1 存儲(chǔ)引擎概述
和大多數(shù)的數(shù)據(jù)庫(kù)不同,MySQL中有一個(gè)存儲(chǔ)引擎的概念,針對(duì)不同的存儲(chǔ)需求可以選擇最優(yōu)的存儲(chǔ)引擎。
存儲(chǔ)引擎就是存儲(chǔ)數(shù)據(jù),建立索引,更新查詢數(shù)據(jù)等等技術(shù)的實(shí)現(xiàn)方式。存儲(chǔ)引擎是基于表,而不是基于庫(kù)的。所以存儲(chǔ)引擎也可被稱為表類型。
Oracle、SqlServer等數(shù)據(jù)庫(kù)只有一種存儲(chǔ)引擎。MySQL提供插件式的存儲(chǔ)引擎架構(gòu)。所以MySQL存在多種存儲(chǔ)引擎,
可以根據(jù)需要使用相應(yīng)的引擎,或者編寫存儲(chǔ)引擎。
MySQL5.0支持的存儲(chǔ)引擎包含 :InooDB、MyISAM、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、
CSV、BLACKHOLE、FEDERATED等,其中InnoDB和BDB提供事物安全表,其他存儲(chǔ)引擎是非事物安全表。
可以通過(guò)指定show engines,來(lái)查詢當(dāng)前數(shù)據(jù)庫(kù)支持的存儲(chǔ)引擎 :
 創(chuàng)建新表時(shí)如果不指定存儲(chǔ)引擎,那么系統(tǒng)就會(huì)使用默認(rèn)的存儲(chǔ)引擎,MySQL5.5之前的默認(rèn)存儲(chǔ)引擎是MyISAM,5.5之后就改為了InnoDB。
創(chuàng)建新表時(shí)如果不指定存儲(chǔ)引擎,那么系統(tǒng)就會(huì)使用默認(rèn)的存儲(chǔ)引擎,MySQL5.5之前的默認(rèn)存儲(chǔ)引擎是MyISAM,5.5之后就改為了InnoDB。
查看MySQL數(shù)據(jù)庫(kù)默認(rèn)的存儲(chǔ)引擎 ,指令 :
show variables like ‘%storage_engine%’;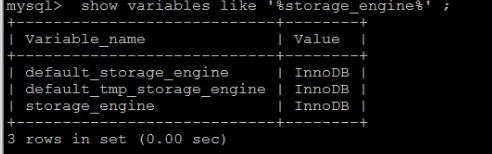
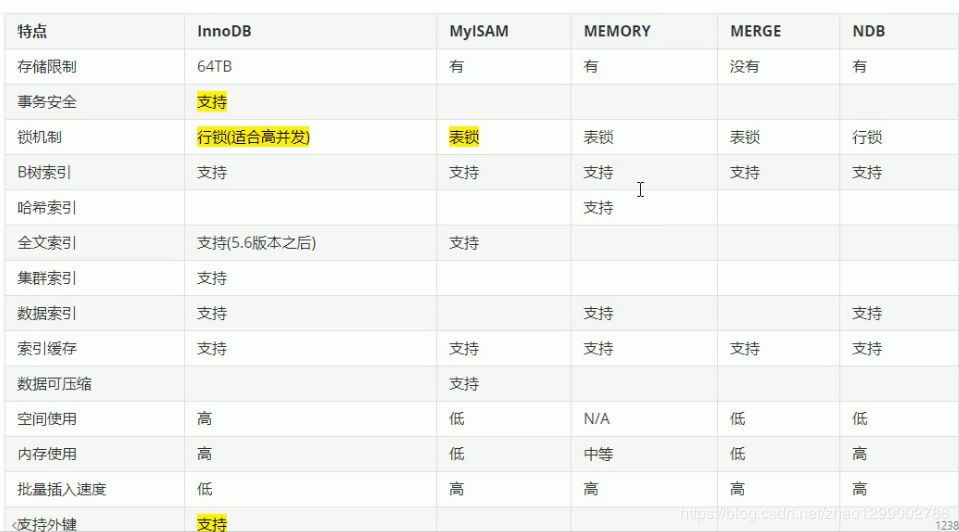
下面重點(diǎn)介紹幾種常用的存儲(chǔ)引擎,并對(duì)比各個(gè)存儲(chǔ)引擎之間的區(qū)別,如下表所示 :
2.2.1 InnoDB
InnoDB存儲(chǔ)引擎是MySQL的默認(rèn)存儲(chǔ)引擎。InnoDB存儲(chǔ)引擎提供了具有提交、回滾、崩潰恢復(fù)能力的事務(wù)安全。但是對(duì)比MyISAM的存儲(chǔ)引擎,
InnoDB寫的處理效率差一些,并且會(huì)占用更多的磁盤空間以保留數(shù)據(jù)和索引。
InnoDB存儲(chǔ)引擎不同于其他存儲(chǔ)引擎的特點(diǎn) :
事務(wù)控制
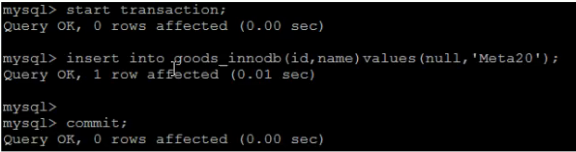
測(cè)試發(fā)現(xiàn)InnoDB中是存在事務(wù)的。
外鍵約束
MySQL支持外鍵的存儲(chǔ)引擎只有InnoDB,在創(chuàng)建外鍵的時(shí)候,要求父表必須有對(duì)應(yīng)的索引,子表在創(chuàng)建外鍵的時(shí)候,也會(huì)自動(dòng)的創(chuàng)建
對(duì)應(yīng)的索引。
下面是兩張表中,country_innodb是父表,country_id為主鍵索引,city_innodb表是子表,country_id字段為外鍵,對(duì)應(yīng)于
country_innodb表的主鍵country_id
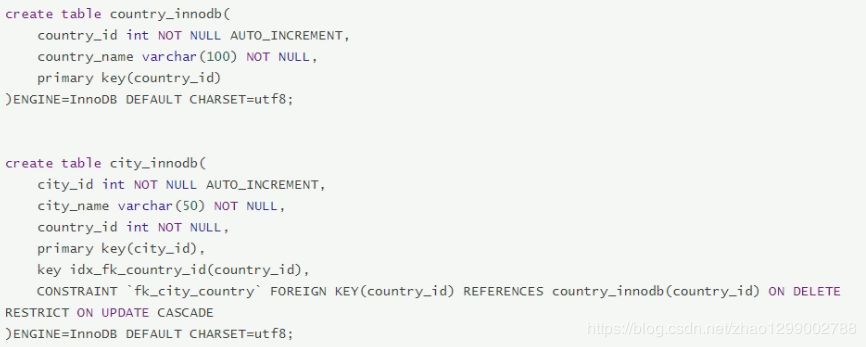
 在創(chuàng)建索引時(shí),可以指定在刪除、更新父表時(shí),對(duì)子表進(jìn)行的相應(yīng)操作,包括RESTRICT、CASCADE、SET NULL和NO ACTION。
在創(chuàng)建索引時(shí),可以指定在刪除、更新父表時(shí),對(duì)子表進(jìn)行的相應(yīng)操作,包括RESTRICT、CASCADE、SET NULL和NO ACTION。
RESTRICT和NO ACTION相同,是指限制在子表有關(guān)聯(lián)記錄的情況下,父表不能更新;
CASCADE表示父表在更新或者刪除時(shí),更新或者刪除子表對(duì)應(yīng)的記錄;
SET NULL則表示父表在更新或者刪除的時(shí)候,子表的對(duì)應(yīng)字段被SET NULL.
針對(duì)上面創(chuàng)建的兩個(gè)表,子表的外鍵指定是ON DELETE RESTRICT ON UPDATE CASCADE方式的,那么在主表刪除記錄的時(shí)候,如果子表有對(duì)應(yīng)記錄,則不允許刪除,主表在更新記錄的時(shí)候,如果子表有對(duì)應(yīng)的記錄,則子表對(duì)應(yīng)更新。
ON DELETE RESTRICT ----> 刪除主表數(shù)據(jù)時(shí),如果有關(guān)聯(lián)記錄,不刪除;
ON UPDATE CASCADE ----> 更新主表時(shí),如果子表有關(guān)聯(lián)記錄,更新子表記錄。
表中數(shù)據(jù)如下圖所示 :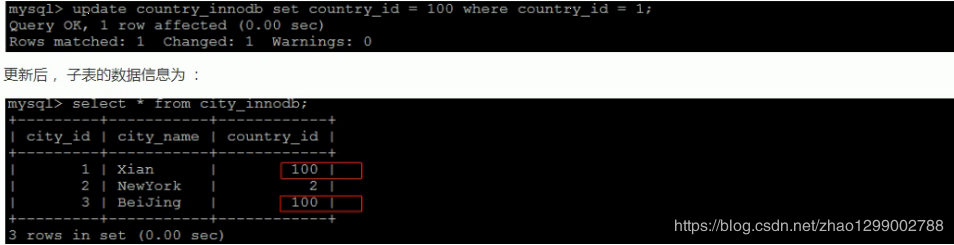 存放方式
存放方式
InnoDB存儲(chǔ)表和索引有以下兩種方式 :
(1)使用共享表空間存儲(chǔ),這種方式創(chuàng)建的表的表結(jié)構(gòu)保存在.frm文件中,數(shù)據(jù)和索引保存在innodb_data_home_dir和innodb_data_file_path定義的表空間中,可以是多個(gè)文件。
(2)使用躲表空間存儲(chǔ),這種方式創(chuàng)建的表的表結(jié)構(gòu)任然存在.frm文件中,但是每個(gè)表的數(shù)據(jù)和索引單獨(dú)保存在.ibd中。
2.2.2 MyISAM
MyISAM不支持事務(wù)、也不支持外鍵,其優(yōu)勢(shì)是訪問(wèn)速度快,對(duì)事物的完整性沒(méi)有要求或者以SELECT、INSERT為主的應(yīng)用基本上都可以使用這個(gè)
引擎來(lái)創(chuàng)建表。有以下兩個(gè)比較重要的特點(diǎn) :不支持事務(wù)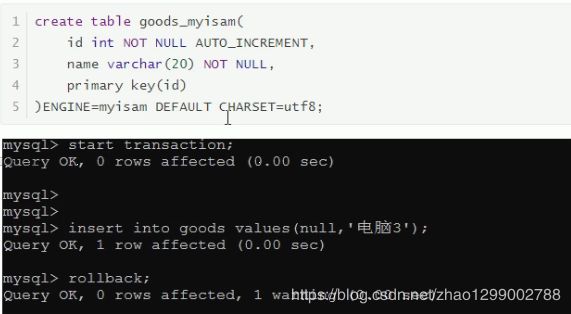 通過(guò)測(cè)試,我們發(fā)現(xiàn),在MyISAM存儲(chǔ)引擎中,是沒(méi)有事務(wù)控制的。
通過(guò)測(cè)試,我們發(fā)現(xiàn),在MyISAM存儲(chǔ)引擎中,是沒(méi)有事務(wù)控制的。
MySQL客戶端連接成功后,通過(guò)show [session | global] status命令可以提高服務(wù)器狀態(tài)信息。show [session | global] status 可以根據(jù)需要加上參數(shù) “session”或者“global”來(lái)顯示session級(jí)(當(dāng)前連接)的計(jì)結(jié)果和global級(jí)(自數(shù)據(jù)庫(kù)上次啟動(dòng)至今)的統(tǒng)計(jì)結(jié)果。如果不寫,默認(rèn)使用參數(shù)是“session”。
下面的命令顯示了當(dāng)前session中所有統(tǒng)計(jì)參數(shù)的值 :
show status like “Com_”;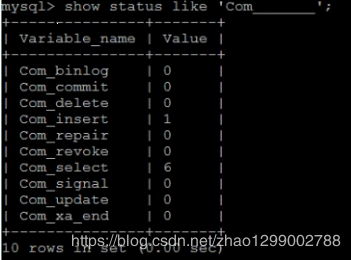 show status like ‘Innodb_rows_%’;
show status like ‘Innodb_rows_%’;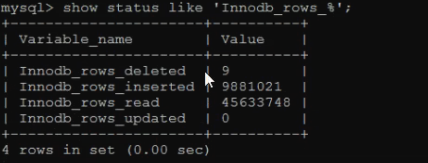 Com_xxx表示每個(gè)xxx語(yǔ)句執(zhí)行的次數(shù),我能通常比較關(guān)心的是以下幾個(gè)統(tǒng)計(jì)參數(shù)
Com_xxx表示每個(gè)xxx語(yǔ)句執(zhí)行的次數(shù),我能通常比較關(guān)心的是以下幾個(gè)統(tǒng)計(jì)參數(shù)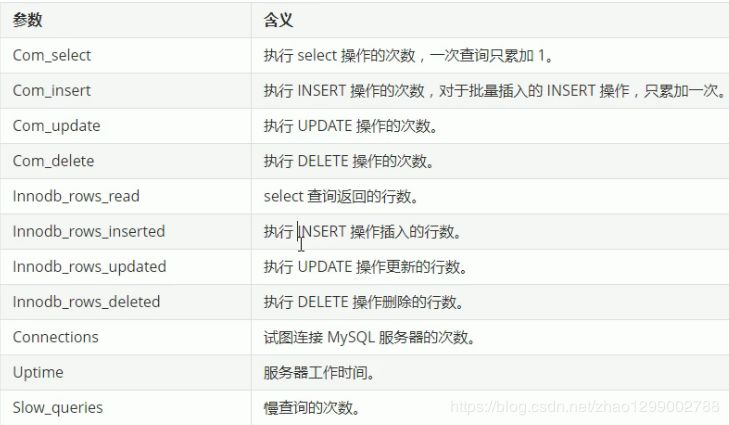 Com_*** : 這些參數(shù)對(duì)于所有存儲(chǔ)引擎的表操作都會(huì)進(jìn)行累計(jì)。
Com_*** : 這些參數(shù)對(duì)于所有存儲(chǔ)引擎的表操作都會(huì)進(jìn)行累計(jì)。
Innodb_*** :這幾個(gè)參數(shù)只是針對(duì)InooDB存儲(chǔ)引擎,累加的算法也略有不同。
可以通過(guò)以下兩種方式定位執(zhí)行效率較低的SQL語(yǔ)句。
1)慢查詢?nèi)罩?:通過(guò)慢查詢?nèi)罩径ㄎ荒切﹫?zhí)行效率較低的SQL語(yǔ)句,用–log-slow-queries[=file_name]選型啟動(dòng)時(shí),mysqld寫一個(gè)包含索引執(zhí)行時(shí)間超過(guò)long_query_time秒的SQL語(yǔ)句的日志文件。
2)show processlist : 慢查詢?nèi)罩驹诓樵兘Y(jié)束以后才記錄,所以在應(yīng)用反映執(zhí)行效率出現(xiàn)問(wèn)題的時(shí)候查詢慢查詢?nèi)罩静⒉荒芏ㄎ粏?wèn)題,可以使用 show processlist 查看當(dāng)前MySQL在進(jìn)行的線程,包括線程的狀態(tài)、是否鎖表等,可以實(shí)時(shí)地查看SQL的執(zhí)行情況,同時(shí)對(duì)一些鎖表操作進(jìn)行優(yōu)化。 1)id列,用戶登錄mysql時(shí),系統(tǒng)分配的"connection_id",可以使用函數(shù)connection_id()查看
1)id列,用戶登錄mysql時(shí),系統(tǒng)分配的"connection_id",可以使用函數(shù)connection_id()查看
2)user列,顯示當(dāng)前用戶。如果不是root,這個(gè)命令就只顯示用戶權(quán)限范圍的sql語(yǔ)句
3)host列,顯示這個(gè)語(yǔ)句是從哪個(gè)ip的哪個(gè)端口上發(fā)的,可以用來(lái)跟蹤出現(xiàn)問(wèn)題語(yǔ)句的用戶
4)db列,顯示這個(gè)進(jìn)程目前連接的哪個(gè)數(shù)據(jù)庫(kù)
5)command列,顯示當(dāng)前連接的執(zhí)行的命令,一般取值為休眠(sleep),查詢(query),連接(connect)等
6)time列,顯示這個(gè)狀態(tài)持續(xù)的時(shí)間,單位是秒
7)state列,顯示使用當(dāng)前連接的sql語(yǔ)句的狀態(tài),很重要的列。state描述的是語(yǔ)句執(zhí)行中的某一個(gè)狀態(tài)。一個(gè)sql語(yǔ)句,查詢?yōu)槔赡苄枰?jīng)過(guò)copying to tmp table、sorting result、sending data等狀態(tài)才可以完成。
8)info列,顯示這個(gè)sql語(yǔ)句,是判斷問(wèn)題語(yǔ)句的一個(gè)重要依據(jù)
通過(guò)以上步驟查詢到效率低的SQL語(yǔ)句后,可以通過(guò)EXPLAIN或者DESC命令獲取MySQL如何執(zhí)行SELECT語(yǔ)句的信息,包括在SELECT語(yǔ)句執(zhí)行過(guò)程中表如何連接和連接的順序。
查詢SQL語(yǔ)句的執(zhí)行計(jì)劃 :
explain select * from tb_item where id = 1; explain select * from tb_item where title = ‘阿爾卡特(ot-979)冰川白 聯(lián)通3G手機(jī)3’;
explain select * from tb_item where title = ‘阿爾卡特(ot-979)冰川白 聯(lián)通3G手機(jī)3’;
id字段是select查詢的序列號(hào),是一組數(shù)字,表示的是查詢中執(zhí)行select子句或者是操作表的順序。id情況有三種 :
1)id相同表示加載表的順序是從上到下。
explain select * from t_role r,t_user u,user_role ur where r.id = ur.role_id and u.id = ur.user_id; 2)id不同id值越大,優(yōu)先級(jí)越高,越先被執(zhí)行。
2)id不同id值越大,優(yōu)先級(jí)越高,越先被執(zhí)行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = ‘stul’)) 3)id有相同,也有不同,同時(shí)存在。id相同的可以認(rèn)為是一組,從上往下順序執(zhí)行;在所有的組中,id的值越大,優(yōu)先級(jí)越高,優(yōu)先執(zhí)行。
3)id有相同,也有不同,同時(shí)存在。id相同的可以認(rèn)為是一組,從上往下順序執(zhí)行;在所有的組中,id的值越大,優(yōu)先級(jí)越高,優(yōu)先執(zhí)行。
EXPLAIN SELECT * FROM t_role r,(SELECT * FROM user_role ur WHERE ur.‘user_id’ = ‘2’) a WHERE r.id = a.role_id;
3.3.3 explain 之 select_type
表示SELECT的類型,常見(jiàn)的取值,如下表所示 :
SIMPLE :簡(jiǎn)單的select查詢,查詢中不包含子查詢或者UNION
PRIMARY :查詢中若包含任何復(fù)雜的子查詢,最外層查詢標(biāo)記為該標(biāo)識(shí)
SUBQUERY :在SELECT或WHERE列表中包含了子查詢
DERIVED :在FROM列表中包含的子查詢,被標(biāo)記為DERIVED(衍生)MySQL會(huì)遞歸執(zhí)行這些子查詢,把結(jié)果放在臨時(shí)表中
UNION :若第二個(gè)SELECT出現(xiàn)在UNION之后,則標(biāo)記為UNION;若UNION包含在FROM子句的子查詢中,外層SELECT將被標(biāo)記為 :DERIVED
UNION RESULT :從UNION表獲取結(jié)果的SELECT
展示這一行的數(shù)據(jù)是關(guān)于哪一張表的
type顯示的是訪問(wèn)類型,是較為重要的一個(gè)指標(biāo),可取值為 :
NULL :MySQL不訪問(wèn)任何表,索引,直接返回結(jié)果
system :表只有一行記錄(等于系統(tǒng)表),這是const類型的特例,一般不會(huì)出現(xiàn)
const :表示通過(guò)索引一次就找到了,const用于比較primary key(主鍵)或者unique(唯一)索引。因?yàn)橹黄ヅ湟恍袛?shù)據(jù),所以很快。如將主鍵置于where列表中,MySQL就能將該查詢轉(zhuǎn)換為一個(gè)常亮。const于將“主鍵”或“唯一”索引的所有部分與常量值進(jìn)行比較。
eq_ref :類似ref,區(qū)域在于使用的是唯一索引,使用主鍵的關(guān)聯(lián)查詢,關(guān)聯(lián)查詢出的記錄只有一條。常見(jiàn)于主鍵或唯一索引掃描
ref :非唯一性索引掃描,返回匹配某個(gè)單獨(dú)值的所有行。本質(zhì)上也是一種索引訪問(wèn),返回所有匹配某個(gè)單獨(dú)值的所有行(多個(gè))
range :只檢索給定返回的行,使用一個(gè)索引來(lái)選擇行。where之后出現(xiàn)between,<,>,in等操作。
index :index與ALL的區(qū)別為 index類型只是遍歷了索引樹(shù),通常比ALL快,ALL是遍歷數(shù)據(jù)文件。
all :將遍歷全表以找到匹配的行
結(jié)果值從最好到最壞依次是 :
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
一般來(lái)說(shuō),我們需要保證查詢至少達(dá)到range基本,最好達(dá)到ref。
possible_keys : 顯示可能應(yīng)用在這張表的索引,一個(gè)或多個(gè)。
key :實(shí)際使用的索引,如果為null,則沒(méi)有使用索引。
key_len : 表示索引中使用的字節(jié)數(shù),該值為索引字段最大可能長(zhǎng)度,并非實(shí)際使用長(zhǎng)度,在不損失精確性的前提下,長(zhǎng)度越短越好。
掃描行的數(shù)量
其他的額外的執(zhí)行計(jì)劃信息,在該列展示。
using filesort : 說(shuō)明mysql會(huì)對(duì)數(shù)據(jù)使用一個(gè)外部的索引排序,而不是按照表內(nèi)的索引順序進(jìn)行讀取,稱為“文件排序”。效率低
using temporary :使用了臨時(shí)表保存中間結(jié)果,MySQL在對(duì)查詢結(jié)果排序時(shí)使用臨時(shí)表。常見(jiàn)于order by 和group by。效率低
using index :表示相應(yīng)的select操作使用了覆蓋索引,避免訪問(wèn)表的數(shù)據(jù)行,效率不錯(cuò)。
當(dāng)extra列出現(xiàn)using filesort和using temporary時(shí)就需要進(jìn)行sql優(yōu)化了。
還有一個(gè)問(wèn)題,很多人認(rèn)為當(dāng)出現(xiàn)效率低的情況,加索引,一味的加索引就認(rèn)為能解決問(wèn)題?實(shí)際上這種想法是錯(cuò)誤的,索引不是想加就加的,每個(gè)索引都需要深思熟慮過(guò)的,不是因?yàn)闃I(yè)務(wù)需要而去加索引,這是一種錯(cuò)誤的做法。索引是為了提升獲取數(shù)據(jù)庫(kù)數(shù)據(jù)的獲取效率而加的。而業(yè)務(wù)的需要可以用其他方式去實(shí)現(xiàn)。比如排序,很多人第一時(shí)間想到數(shù)據(jù)庫(kù)order by去排序,而需要排序的字段又是一些特殊的字段。我不認(rèn)為這個(gè)時(shí)候去加索引是一種很好解決方案,可以嘗試使用ES。
MySQL從5.0.37版本開(kāi)始增加了對(duì) show profiles和show profile語(yǔ)句的支持。show profiles能夠在做SQL優(yōu)化時(shí)幫助我們了解時(shí)間都耗費(fèi)到哪里去了。
通過(guò)have_profiling參數(shù),能夠看到當(dāng)前MySQL是否支持profile; 默認(rèn)profiling是關(guān)閉的,可以通過(guò)set語(yǔ)句在Session級(jí)別開(kāi)啟profiling;
默認(rèn)profiling是關(guān)閉的,可以通過(guò)set語(yǔ)句在Session級(jí)別開(kāi)啟profiling; set profiling=1; // 開(kāi)啟profiling開(kāi)關(guān);
set profiling=1; // 開(kāi)啟profiling開(kāi)關(guān);
通過(guò)profile,我們能夠更清楚地了解SQL執(zhí)行的過(guò)程。
首先,我們可以執(zhí)行一系列的操作,如下圖所示 :
show databasesl
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
執(zhí)行完上述命令之后,再執(zhí)行show profiles指令,來(lái)查看SQL語(yǔ)句執(zhí)行的耗時(shí) :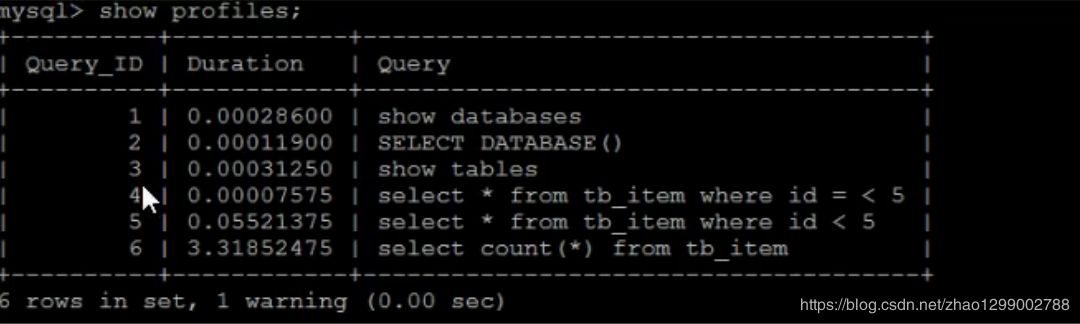 通過(guò)show profile for query query_id 語(yǔ)句可以查看到該SQL執(zhí)行過(guò)程中每個(gè)線程的狀態(tài)和消耗的時(shí)間 :
通過(guò)show profile for query query_id 語(yǔ)句可以查看到該SQL執(zhí)行過(guò)程中每個(gè)線程的狀態(tài)和消耗的時(shí)間 :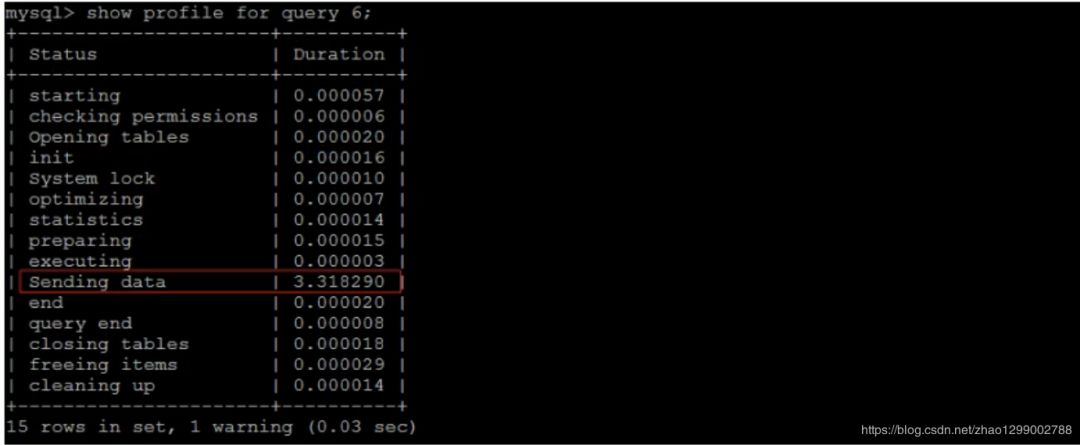 TIP :
TIP :
Sending data 狀態(tài)表示MySQL線程開(kāi)始訪問(wèn)數(shù)據(jù)行并把結(jié)果返回給客戶端,而不僅僅是返回個(gè)客戶端。由于在Sending data狀態(tài)下,MySQL線程往往需要做大量的磁盤讀取操作,所以經(jīng)常是整個(gè)查詢中耗時(shí)最長(zhǎng)的狀態(tài)。
在獲取到最消耗時(shí)間的線程狀態(tài)后,MySQL支持進(jìn)一步選擇all、cpu、block io、context switch、page faults等明細(xì)類型查看MySQL在使用什么資源上耗費(fèi)了過(guò)高的時(shí)間。例如,選擇查看CPU的耗費(fèi)時(shí)間 :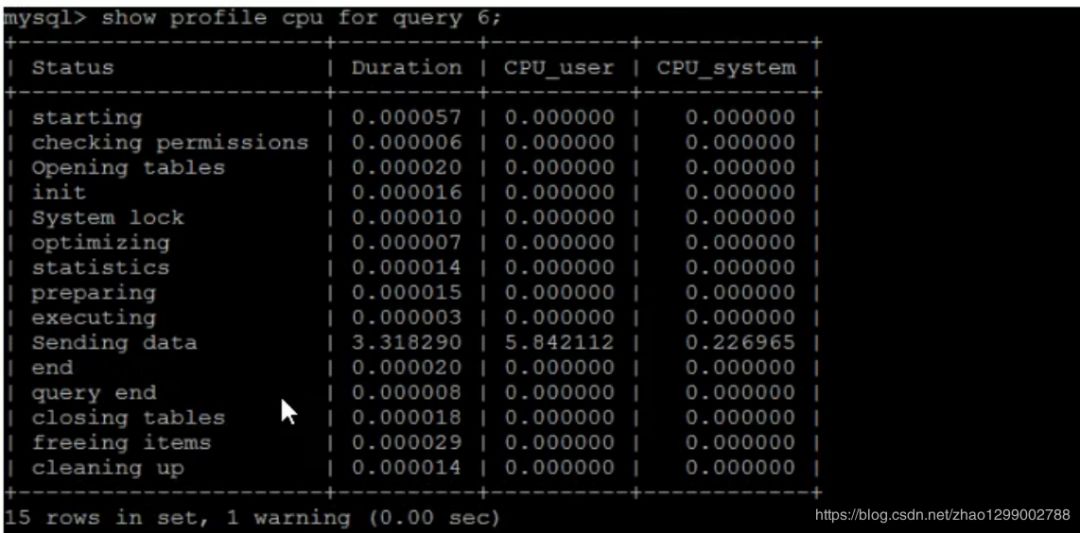 show PROFILE ALL for QUERY 58; 可以查看到所有的狀態(tài)耗時(shí)。
show PROFILE ALL for QUERY 58; 可以查看到所有的狀態(tài)耗時(shí)。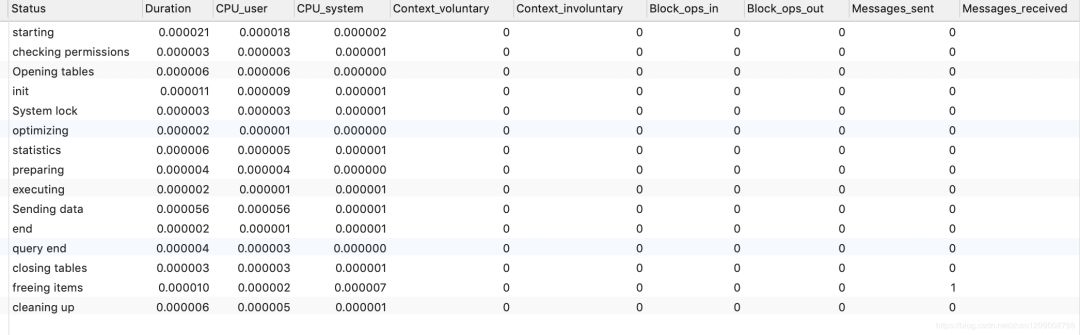
MySQL5.6提供了對(duì)SQL的跟蹤trace,通過(guò)trace文件能夠進(jìn)一步了解為什么優(yōu)化器選擇A計(jì)劃,而不是選擇B計(jì)劃。
打開(kāi)trace,設(shè)置格式為JSON,并設(shè)置trace最大能夠使用的內(nèi)存大小,避免解析過(guò)程中因?yàn)槟J(rèn)內(nèi)存過(guò)小而不能夠完整展示。
set optimizer_trace=“enabled=on”,end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;
執(zhí)行SQL語(yǔ)句 :
select * from tb_item where id < 4;
最后,檢查information_schema.optimizer_trace就可以知道MySQL是如何執(zhí)行SQL的 :
select * from information_schema.optimizer_trace\G;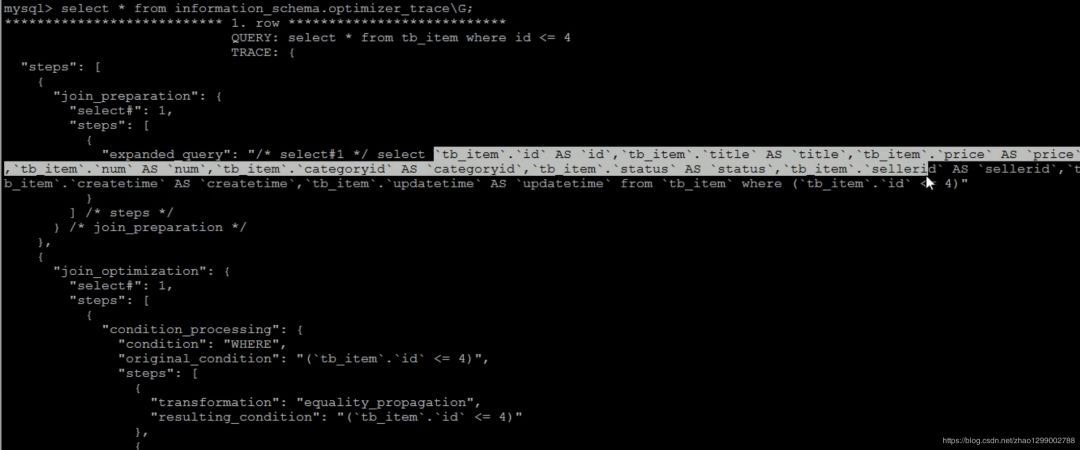 開(kāi)源的小米SQL優(yōu)化工具SOAR可以了解一下。
開(kāi)源的小米SQL優(yōu)化工具SOAR可以了解一下。
索引是數(shù)據(jù)庫(kù)優(yōu)化最常用也是最重要的手段之一,通過(guò)索引通常可以幫助用戶解決大多數(shù)的MySQL的性能優(yōu)化問(wèn)題。
在表中存儲(chǔ)了300萬(wàn)條記錄;
A. 根據(jù)ID查詢
select * from tb_item where id = 1999;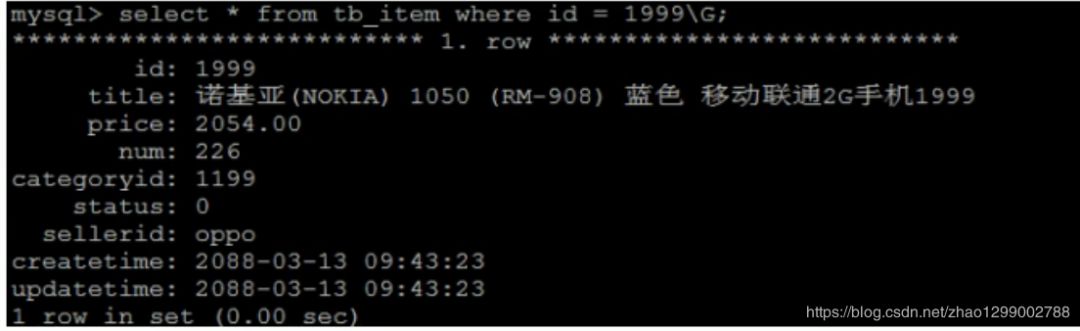 查詢速度很快,接近0秒,主要的原因是因?yàn)閕d 為主鍵,有索引;
查詢速度很快,接近0秒,主要的原因是因?yàn)閕d 為主鍵,有索引;
如果查詢條件沒(méi)有索引那么查詢效率會(huì)很低。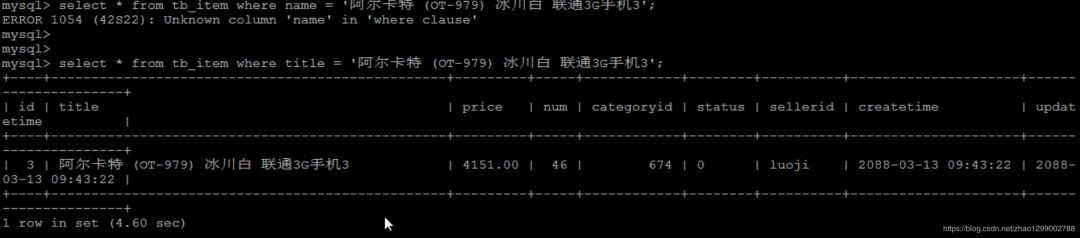
1).全值匹配,對(duì)索引中所有列都指定具體值。
改情況,索引生效,執(zhí)行效率高。
explain select * from tb_seller where name = ‘小米科技’ and status = ‘1’ and address = ‘北京市’;
show status like ‘Handler_read%’;
show global status like ‘Handler_read%’;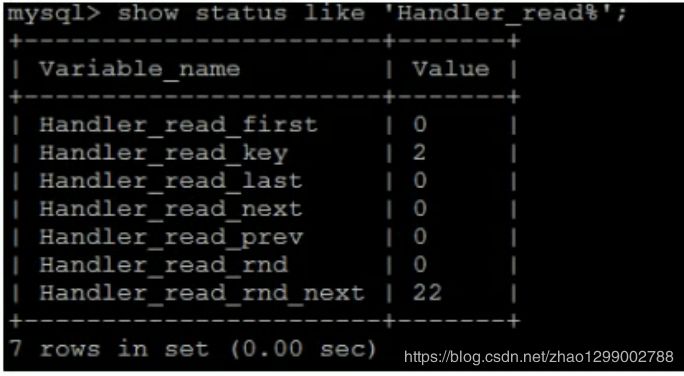 Handler_read_first : 索引中第一條被讀的次數(shù)。如果較高,表示服務(wù)器正執(zhí)行大量全索引掃描(這個(gè)值越低越好)。
Handler_read_first : 索引中第一條被讀的次數(shù)。如果較高,表示服務(wù)器正執(zhí)行大量全索引掃描(這個(gè)值越低越好)。
Handler_read_key : 如果索引正在工作,這個(gè)值代表一個(gè)行被索引值讀的次數(shù),如果值越低,表示索引得到的性能改善不高,因?yàn)樗饕唤?jīng)常使用(這個(gè)值越高越好)。
Handler_read_next : 按照鍵順序讀下一行的請(qǐng)求數(shù)。如果你用范圍約束或如果執(zhí)行索引掃描來(lái)查詢索引列,該值增加。
Handler_read_prev : 按照鍵順序讀取前一行的請(qǐng)求數(shù)。該讀方法主要用于優(yōu)化ORDER BY … DESC。
Handler_read_rnd : 根據(jù)固定位置讀一行的請(qǐng)求數(shù)。如果你正執(zhí)行大量查詢并需要對(duì)結(jié)果進(jìn)行排序該值較高。你可能使用了大量需要MySQL掃描正整個(gè)表的查詢或你的連接沒(méi)有正確使用鍵。這個(gè)值較高,意味著運(yùn)行效率低,應(yīng)該建立索引來(lái)補(bǔ)救。
Handler_read_rnd_next : 在數(shù)據(jù)文件中讀下一行的請(qǐng)求數(shù)。如果你正進(jìn)行大量的表掃描,該值較高。通常說(shuō)明你的表索引不正確或?qū)懭氲牟樵儧](méi)有利用索引。
當(dāng)使用load命令導(dǎo)入數(shù)據(jù)的時(shí)候,適當(dāng)?shù)脑O(shè)置可以提高導(dǎo)入的效率。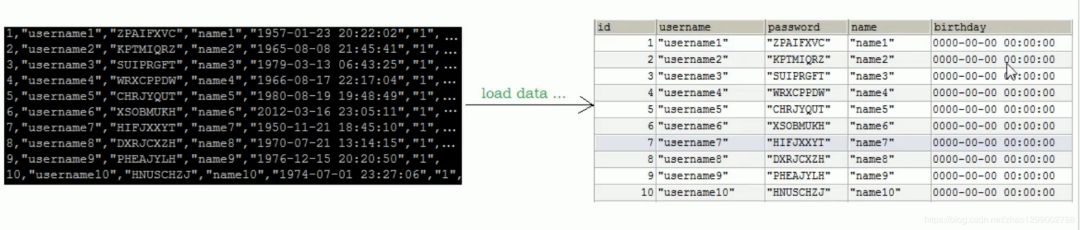 對(duì)于InnoDB類型的表,有以下幾種方式可以提高導(dǎo)入的效率 :
對(duì)于InnoDB類型的表,有以下幾種方式可以提高導(dǎo)入的效率 :
1)主鍵順序插入
因?yàn)镮nnoDB類型的表是按照主鍵的順序保存的,所以將導(dǎo)入的數(shù)據(jù)按照主鍵的順序排列,可以有效的提高導(dǎo)入數(shù)據(jù)的效率。如果InnoDB表沒(méi)有主鍵,那么系統(tǒng)會(huì)自動(dòng)默認(rèn)創(chuàng)建一個(gè)內(nèi)部列做為主鍵,所以如果可以給表創(chuàng)建一個(gè)主鍵,將可以利用這點(diǎn),來(lái)提高導(dǎo)入數(shù)據(jù)的效率。
插入ID順序排列的數(shù)據(jù) : 下圖是有序數(shù)據(jù)導(dǎo)入的時(shí)間
下圖是有序數(shù)據(jù)導(dǎo)入的時(shí)間 下圖是無(wú)序數(shù)據(jù)導(dǎo)入的時(shí)間
下圖是無(wú)序數(shù)據(jù)導(dǎo)入的時(shí)間 2) 關(guān)閉唯一性校驗(yàn)
2) 關(guān)閉唯一性校驗(yàn)
在導(dǎo)入數(shù)據(jù)前執(zhí)行SET_UNIQUE_CHECKS=0,關(guān)閉唯一性校驗(yàn),在導(dǎo)入結(jié)束后執(zhí)行SET_UNIQUE_CHECKS=1,恢復(fù)唯一性校驗(yàn),可以提高導(dǎo)入的效率。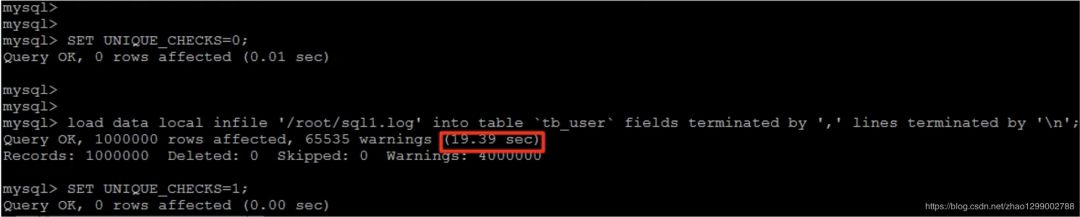 3)手動(dòng)提交事務(wù)
3)手動(dòng)提交事務(wù)
如果應(yīng)用使用自動(dòng)提交的方式,建議在導(dǎo)入前執(zhí)行SET AUTOCOMMIT=0,關(guān)閉自動(dòng)提交,導(dǎo)入結(jié)束后再執(zhí)行SET AUTOCOMMIT=1,打開(kāi)自動(dòng)提交,也可以提高導(dǎo)入的效率。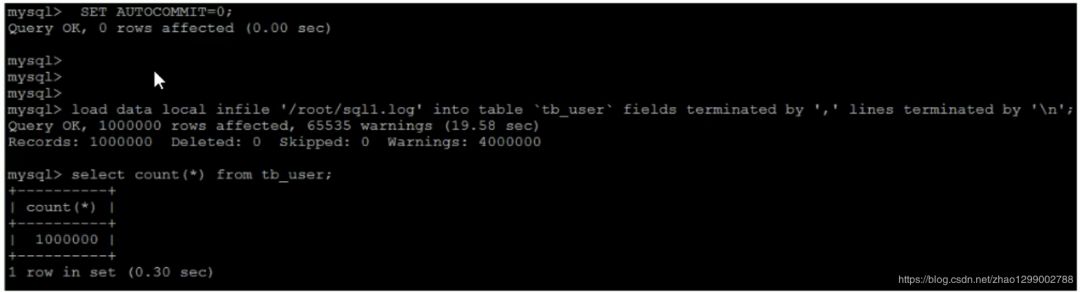
當(dāng)進(jìn)行數(shù)據(jù)的insert操作的時(shí)候,可以考慮采用以下幾種優(yōu)化方案。
如果需要同時(shí)對(duì)一張表插入很多行數(shù)據(jù)時(shí),應(yīng)該盡量使用多個(gè)值表的insert語(yǔ)句;這種方式將大大的縮減客戶端與數(shù)據(jù)庫(kù)之間的連接、關(guān)閉等消耗。使得效率比分開(kāi)執(zhí)行的單個(gè)insert語(yǔ)句快。
示例,原始方式為 : 優(yōu)化后的方案為 :
優(yōu)化后的方案為 : 在事務(wù)中進(jìn)行數(shù)據(jù)插入。
在事務(wù)中進(jìn)行數(shù)據(jù)插入。

1)第一種是通過(guò)對(duì)返回?cái)?shù)據(jù)進(jìn)行排序,也就是通常說(shuō)的filesort排序,所有不是通過(guò)索引直接返回排序結(jié)果的排序都叫FileSort排序。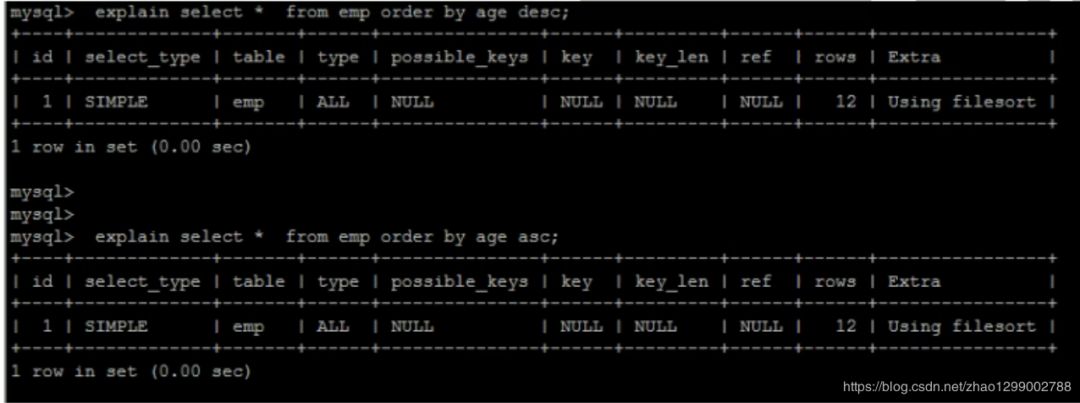 2)第二種通過(guò)有序索引順序掃描直接返回有序數(shù)據(jù),這種情況既為using index,不需要額外排序,操心效率高。
2)第二種通過(guò)有序索引順序掃描直接返回有序數(shù)據(jù),這種情況既為using index,不需要額外排序,操心效率高。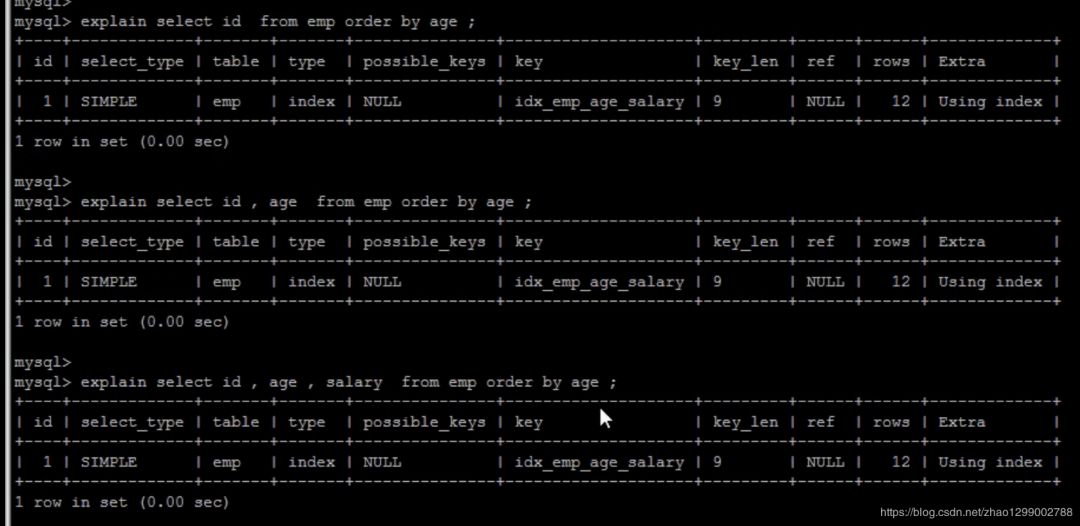 多字段排序
多字段排序
1)order by多字段時(shí),要么全部升序,要么全部降序。并且排序字段使用復(fù)合索引字段。
2)當(dāng)為多字段排序時(shí),排序字段順序要和創(chuàng)建復(fù)合索引的字段順序保持一致。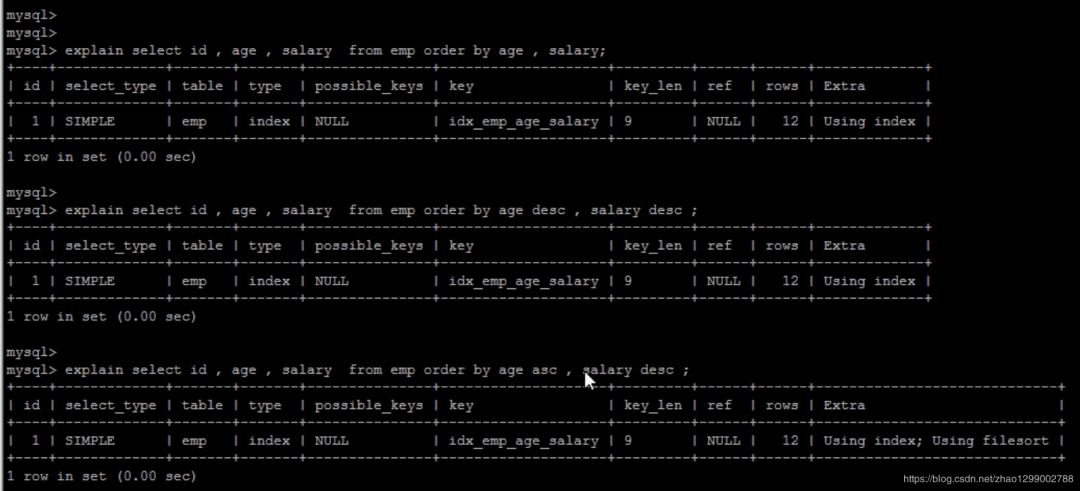
 了解MySQL的排序方式,優(yōu)化目標(biāo)就清晰了 :
了解MySQL的排序方式,優(yōu)化目標(biāo)就清晰了 :
盡量減少額外的排序,通過(guò)索引直接返回有序數(shù)據(jù)。where條件和order by使用相同的索引,并且order by的順序和索引順序相同,并且order by的字段都是升序,或者都是降序。否則肯定需要額外的操作,這樣就會(huì)出現(xiàn)FileSort。
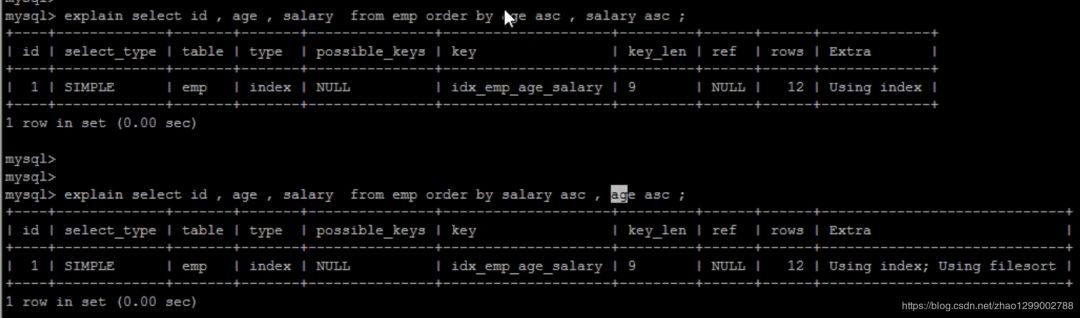
通過(guò)創(chuàng)建合適的索引,能夠減少FileSort的出現(xiàn),但是在某些情況下,條件限制不能讓FileSort消失,那就需要加快FileSort的排序操作。對(duì)于FileSort,MySQL有兩種排序算法 :
1)兩次掃描算法 :MySQL4.1之前,使用該方式排序。首先根據(jù)條件取出排序字段和行指針信息,然后在排序區(qū)sort buffer中排序,如果sort buffer不夠,則在臨時(shí)表temporary table中存儲(chǔ)排序結(jié)果。完成排序之后,再根據(jù)行指針回表讀取記錄,該操作可能會(huì)導(dǎo)致大量隨機(jī)I/O操作。
2)一次掃描算法 :一次性取出滿足條件的所有字段,然后在排序區(qū)sort buffer中排序后直接輸出結(jié)果集。排序時(shí)內(nèi)存開(kāi)銷較大,但是排序效率比兩次掃描算法要高。
MySQL通過(guò)比較系統(tǒng)變量max_length_for_sort_data的大小和Query語(yǔ)句取出的字段總大小,來(lái)判定是否那種排序算法,如果max_length_sort_data更大,那么使用第二種優(yōu)化之后的算法 :否則使用第一種。
可以適當(dāng)提高sort_buffer_size和max_length_for_sort_data系統(tǒng)變量,來(lái)增大排序區(qū)的大小,提高排序的效率。 
由于GROUP BY實(shí)際上也同樣會(huì)進(jìn)行排序操作,而且與ORDER BY相比,GROUP BY主要只是多了排序之后的分組操作。當(dāng)然,如果在分組的時(shí)候還使用來(lái)其他的一些聚合函數(shù),那么還需要一些聚合函數(shù)的計(jì)算。所以,在GROUP BY的實(shí)現(xiàn)過(guò)程中,與ORDER BY一樣也可以利用索引。
如果查詢包含group by但是用戶想要避免排序結(jié)果的消耗,則可以執(zhí)行oerder by null禁止排序。如下 :
drop index inx_emp_age_salary on emp;
explain select age,count() from emp group by age; 優(yōu)化后
優(yōu)化后
explain select age,count() from emp group by age order by null; 從上面的例子可以看出,第一個(gè)SQL語(yǔ)句需要進(jìn)行“filesort”,而第二SQL由于order by null不需要進(jìn)行“filesort”,而上文提過(guò)FileSort往往非常耗費(fèi)時(shí)間。
從上面的例子可以看出,第一個(gè)SQL語(yǔ)句需要進(jìn)行“filesort”,而第二SQL由于order by null不需要進(jìn)行“filesort”,而上文提過(guò)FileSort往往非常耗費(fèi)時(shí)間。
也可以通過(guò)創(chuàng)建索引提高分組列的效率
create index idx_emp_age_salary on emp(age,salary);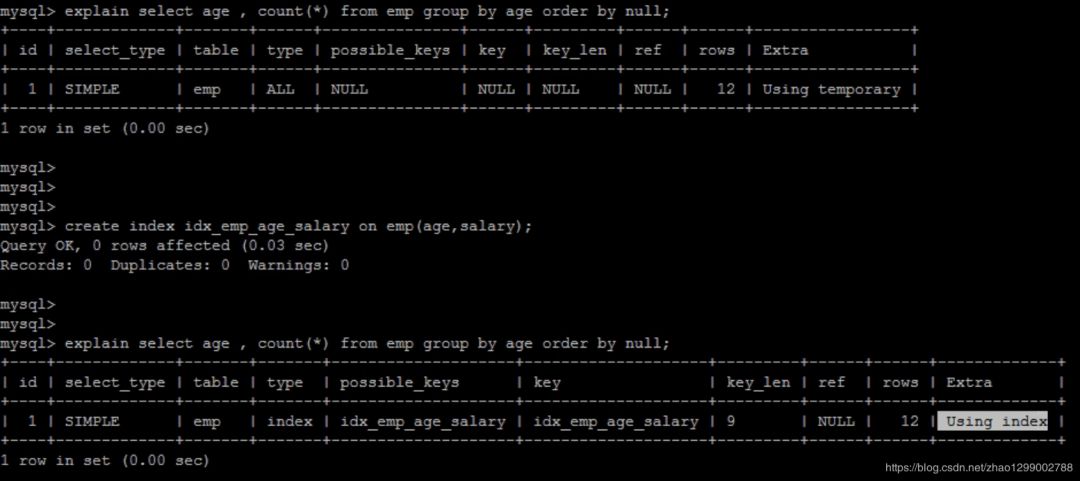
MySQL4.1版本之后,開(kāi)始支持SQL的子查詢。這個(gè)技術(shù)可以使用SELECT語(yǔ)句來(lái)創(chuàng)建一個(gè)單列的查詢結(jié)果,然后把這個(gè)結(jié)果作為過(guò)濾條件用在另一個(gè)查詢中。使用子查詢可以一次性的完成很多邏輯上需要多個(gè)步驟才能完成的SQL操作,同時(shí)也可以避免事務(wù)或者表死鎖,并且寫起來(lái)也很容易。但是,有些情況下,子查詢是可以被更搞笑的連接(JOIN)替代。
示例 :查找有角色的所有的用戶信息 :
explain select * from t_user where id in (select user_id user_role);
執(zhí)行計(jì)劃為 : 優(yōu)化后 :
優(yōu)化后 :
explain select * from t_user u, user_role ur where u.id = ur.user_id;
對(duì)于包含OR的查詢子句,如果要利用索引,則OR之間的每個(gè)條件列都必須使用到索引,而且不能使用到復(fù)合索引;如果沒(méi)有索引,則應(yīng)該考慮增加索引。
獲取emp表的所有索引 : 示例 :
示例 :
explain select * from emp where id = 1 or age = 30;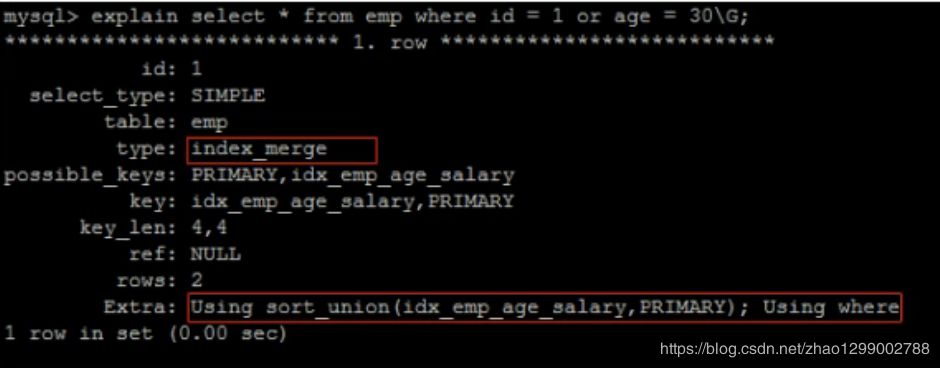
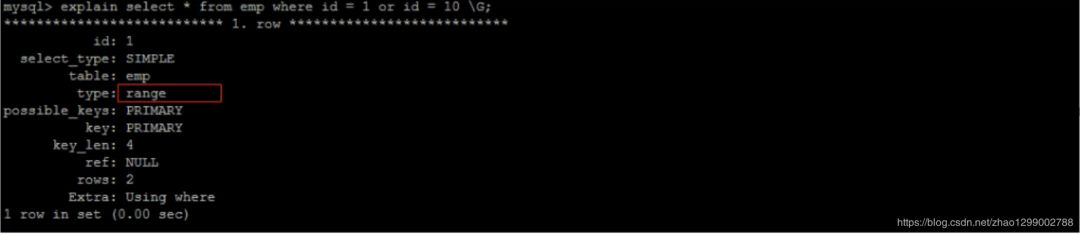 建議使用union 替換or :
建議使用union 替換or :
這里的type中const要性能遠(yuǎn)高于range
 我們來(lái)比較下重要指標(biāo),發(fā)現(xiàn)主要差別是type和ref這兩項(xiàng)
我們來(lái)比較下重要指標(biāo),發(fā)現(xiàn)主要差別是type和ref這兩項(xiàng)
type顯示的是訪問(wèn)類型,是較為重要的一個(gè)指標(biāo),結(jié)果值從好到壞依次是 :
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery >
range > index > ALL
UNION語(yǔ)句的type值為const,OR語(yǔ)句的type值為range,可以看到這是一個(gè)很明顯的差距。
UNION語(yǔ)句的ref值為const,OR語(yǔ)句的type值為null,const表示是常量值引用,非常快這兩項(xiàng)的差距就說(shuō)明來(lái)
UNION要優(yōu)于OR。
一般分頁(yè)查詢時(shí),通過(guò)創(chuàng)建覆蓋索引能夠比較好的提高性能。一個(gè)常見(jiàn)又非常頭痛的問(wèn)題就是 limit 20000000,10,此時(shí)需要MySQL排序前2000010記錄,僅僅返回2000000 - 2000010的記錄,其他記錄丟棄,查詢排序的代價(jià)非常大。
在索引上完成排序分頁(yè)操作,最后根據(jù)主鍵關(guān)聯(lián)回原表查詢所需要的其他列內(nèi)容。 兩個(gè)SQL的執(zhí)行計(jì)劃如下
兩個(gè)SQL的執(zhí)行計(jì)劃如下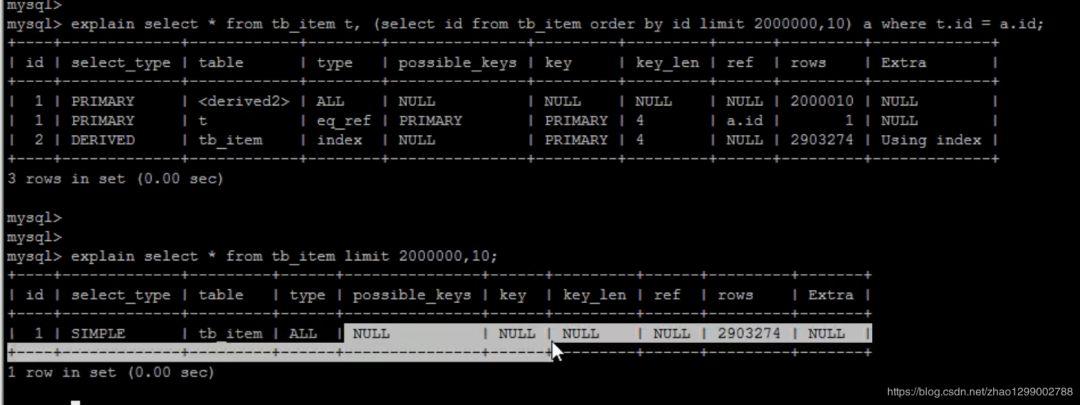
該方案適用于主鍵自增的表(不能出現(xiàn)主鍵斷層),可以把limit查詢轉(zhuǎn)換成某個(gè)位置的查詢。

SQL提示,是優(yōu)化數(shù)據(jù)庫(kù)的一個(gè)重要手段,簡(jiǎn)單來(lái)說(shuō),就是在SQL語(yǔ)句中加入一些人為的提示來(lái)達(dá)到優(yōu)化操作的目的。
在查詢語(yǔ)句中表名的后面,添加use index來(lái)提供希望MySQL去參考的索引列表,就可以讓MySQL不再考慮其他可用的索引。
create index idex_seller_name on tb_seller(name);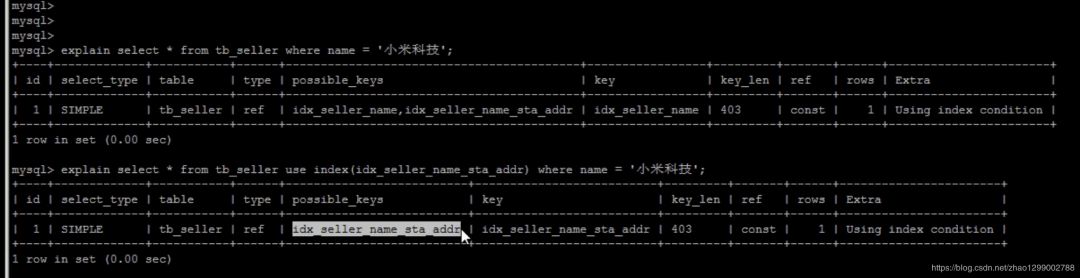
如果用戶只是單純的想讓MySQL忽略一個(gè)或者多個(gè)索引,則可以使用ignore index作為hint
explain select * from tb_seller ignore index(idx_seller_name) where name = ‘小米科技’;
為強(qiáng)制MySQL使用一個(gè)特定的索引,可在查詢中使用force index作為hint。
create index inx_seller_address on tb_seller(address);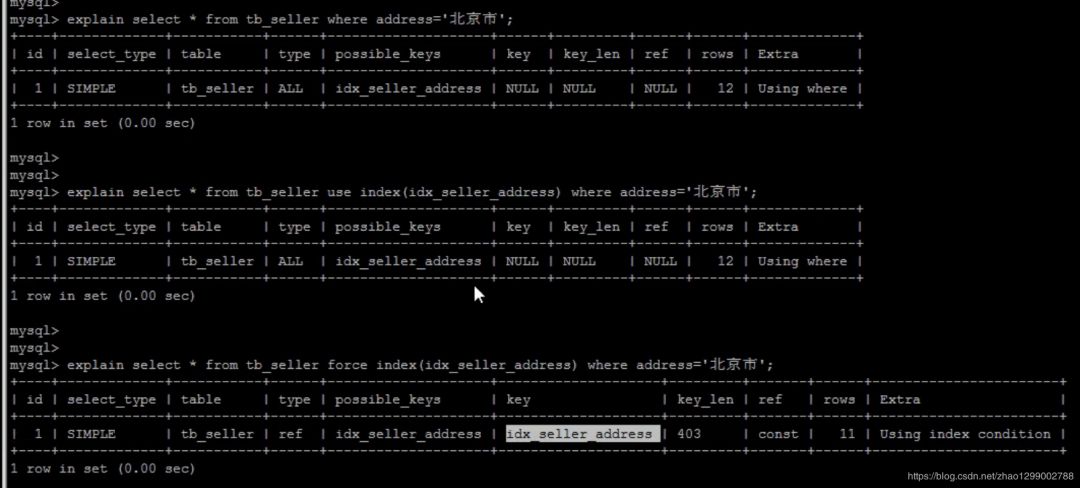
END

