
思考 | 深度學(xué)習(xí)領(lǐng)域還有哪些瓶頸?
點擊左上方藍字關(guān)注我們

鏈接 | https://www.zhihu.com/question/40577663/answer/902429604
一、深度學(xué)習(xí)缺乏理論支撐
大多數(shù)文章的idea都是靠直覺提出來的,背后的很少有理論支撐。通過實驗驗證有效的idea,不一定是最優(yōu)方向。就如同最優(yōu)化問題中的sgd一樣,每一個step都是最優(yōu),但從全局來看,卻不是最優(yōu)。
沒有理論支撐的話,計算機視覺領(lǐng)域的進步就如同sgd一樣,雖然有效,但是緩慢;如果有了理論支撐,計算機視覺領(lǐng)域的進步就會像牛頓法一樣,有效且迅猛。
CNN模型本身有很多超參數(shù),比如設(shè)置幾層,每一層設(shè)置幾個filter,每個filter是depth wise還是point wise,還是普通conv,filter的kernel size設(shè)置多大等等。
這些超參數(shù)的組合是一個很大的數(shù)字,如果只靠實驗來驗證,幾乎是不可能完成的。最后只能憑直覺試其中一部分組合,因此現(xiàn)在的CNN模型只能說效果很好,但是絕對還沒達到最優(yōu),無論是效果還是效率。
以效率舉例,現(xiàn)在resnet效果很好,但是計算量太大了,效率不高。然而可以肯定的是resnet的效率可以提高,因為resnet里面肯定有冗余的參數(shù)和冗余的計算,只要我們找到這些冗余的部分,并將其去掉,效率自然提高了。一個最簡單而且大多人會用的方法就是減小各層channel的數(shù)目。
如果一套理論可以估算模型的capacity,一個任務(wù)所需要模型的capacity。那我們面對一個任務(wù)的時候,使用capacity與之匹配的模型,就能使得效果好,效率優(yōu)。
二、領(lǐng)域內(nèi)越來越工程師化思維
因為深度學(xué)習(xí)本身缺乏理論,深度學(xué)習(xí)理論是一塊難啃的骨頭,深度學(xué)習(xí)框架越來越傻瓜化,各種模型網(wǎng)上都有開源實現(xiàn),現(xiàn)在業(yè)內(nèi)很多人都是把深度學(xué)習(xí)當(dāng)樂高用。
面對一個任務(wù),把當(dāng)前最好的幾個模型的開源實現(xiàn)git clone下來,看看這些模型的積木搭建說明書(也就是論文),思考一下哪塊積木可以改一改,積木的順序是否能調(diào)換一樣,加幾個積木能不能讓效果更好,減幾個積木能不能讓效率更高等等。
思考了之后,實驗跑起來,實驗效果不錯,文章發(fā)起來,實驗效果不如預(yù)期,重新折騰一遍。
這整個過程非常的工程師化思維,基本就是憑感覺trial and error,深度思考缺位。很少有人去從理論的角度思考模型出了什么問題,針對這個問題,模型應(yīng)該做哪些改進。
舉一個極端的例子,一個數(shù)據(jù)實際上是一次函數(shù),但是我們卻總二次函數(shù)去擬合,發(fā)現(xiàn)擬合結(jié)果不好,再用三次函數(shù)擬合,三次不行,四次,再不行,就放棄。我們很少思考,這個數(shù)據(jù)是啥分布,針對這樣的分布,有沒有函數(shù)能擬合它,如果有,哪個函數(shù)最合適。
深度學(xué)習(xí)本應(yīng)該是一門科學(xué),需要用科學(xué)的思維去面對她,這樣才能得到更好的結(jié)果。
三、對抗樣本是深度學(xué)習(xí)的問題,但不是深度學(xué)習(xí)的瓶頸
我認(rèn)為對抗樣本雖然是深度學(xué)習(xí)的問題,但并不是深度學(xué)習(xí)的瓶頸。機器學(xué)習(xí)中也有對抗樣本,機器學(xué)習(xí)相比深度學(xué)習(xí)有著更多的理論支撐,依然沒能把對抗樣本的問題解決。
之所以我們覺得對抗樣本是深度學(xué)習(xí)的瓶頸是因為,圖像很直觀,當(dāng)我們看到兩張幾乎一樣的圖片,最后深度學(xué)習(xí)模型給出兩種完全不一樣的分類結(jié)果,這給我們的沖擊很大。
如果修改一個原本類別是A的feature中某個元素的值,然后使得svm的分類改變?yōu)锽,我們會覺得不以為然,“你改變了這個feature中某個元素的值,它的分類結(jié)果改變很正常啊”。
https://www.zhihu.com/question/40577663/answer/413331053
我們已經(jīng)有海量的數(shù)據(jù),海量的算力,但我們卻難以訓(xùn)練大型的深度網(wǎng)絡(luò)模型(GB 到 TB 級別的模型),因為 BP 難以大規(guī)模并行化。數(shù)據(jù)并行不夠,用模型并行后加速比就會大打折扣。即使在加入諸多改進后,訓(xùn)練過程對帶寬的要求仍然太高。
這就是為什么 nVidia 的 DGX-2 只有 16 塊 V100,但就是要賣到 250 萬。因為雖然用少得多的錢就可以湊出相同的總算力,但很難搭出能高效運用如此多張顯卡的機器。

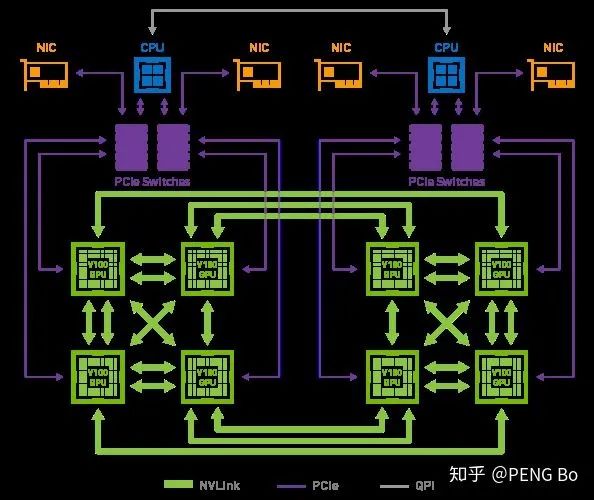
如果什么時候深度學(xué)習(xí)可以無腦堆機器就能不斷提高訓(xùn)練速度(就像挖礦可以堆礦機),從而可以用超大規(guī)模的多任務(wù)網(wǎng)絡(luò),學(xué)會 PB EB 級別的各類數(shù)據(jù),那么所能實現(xiàn)的效果很可能會是令人驚訝的。
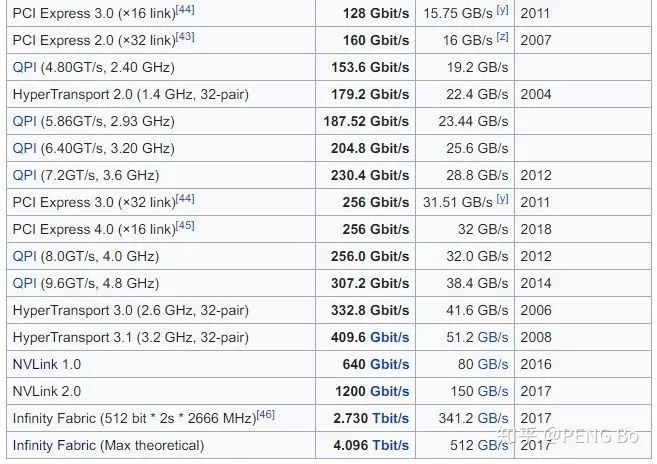
那么我們看現(xiàn)在的帶寬:https://en.wikipedia.org/wiki/List_of_interface_bit_rates
2011年出了PCI-E 3.0 x16,是 15.75 GB/s,現(xiàn)在消費級電腦還是這水平,4.0還是沒出來,不過可能是因為大家沒動力(游戲?qū)捯鬀]那么高)。
NVLink 2.0是 150 GB/s,對于大型并行化還是完全不夠的。
很好,那么,這就來到了最奇怪的問題,我想這個問題值得思考:
AI芯片花了這么大力氣還是帶寬受限,那么人腦為何沒有受限于帶寬?
我的想法是:
人腦的并行化做得太好了,因此神經(jīng)元之間只需要kB級的帶寬。值得AI芯片和算法研究者學(xué)習(xí)。 人腦的學(xué)習(xí)方法比BP粗糙得多,所以才能這樣大規(guī)模并行化。 人腦的學(xué)習(xí)方法是去中心化的,個人認(rèn)為,更接近 energy-based 的方法。 人腦的其它特點,用現(xiàn)在的遷移學(xué)習(xí)+多任務(wù)學(xué)習(xí)+持續(xù)學(xué)習(xí)已經(jīng)可以模仿。 人腦還會用語言輔助思考。如果沒有語言,人腦也很難快速學(xué)會復(fù)雜的事情。
https://www.zhihu.com/question/40577663/answer/1974793135
1. 對標(biāo)注數(shù)據(jù)依賴性大
這也是為什么前期數(shù)據(jù)不足或冷啟動階段,深度學(xué)習(xí)模型效果差強人意的地方。相比人類而言,模型在學(xué)習(xí)新事物時需要更多的事例。
雖然近期有了一些 low-resource 甚至 zero-resource 工作(例如對話生成的兩篇論文[1-2]),總體來說這些方法僅適用于某些特定領(lǐng)域,難以直接推廣。
2. 模型具有領(lǐng)域依賴性,難以直接遷移
或者模型僅在論文數(shù)據(jù)集上表現(xiàn)良好,在其余數(shù)據(jù)中無法復(fù)現(xiàn)類似效果。這些都是非常常見的問題,
提升模型的遷移能力是深度學(xué)習(xí)非常有價值的課題,可以大幅減少數(shù)據(jù)標(biāo)注帶來的成本。好比我一個同學(xué)玩跑跑卡丁車很老練,現(xiàn)在新出了QQ飛車手游,他開兩局就能觸類旁通,輕松上星耀和車神,而不需要從最原始的漂移練起。
雖然NLP預(yù)訓(xùn)練+微調(diào)的方式緩解了這一問題,但深度學(xué)習(xí)可遷移性還有待進一步增強。
3. 巨無霸模型對資源要求高
因為大模型的參數(shù)量在呈指數(shù)增長趨勢:BERT(1.1億)、T5(110億)、GPT3(1500億)、盤古(2000億)...開發(fā)高性能小模型是深度學(xué)習(xí)另一個很有價值的方向。
慶幸的是,在NLP領(lǐng)域已經(jīng)有了一些不錯的輕量化工作,例如TinyBERT[3],F(xiàn)astBERT[4]等。
4. 模型欠缺常識和推理能力
將來的某天,深度學(xué)習(xí)模型除了能寫詩、解方程、下圍棋,還能回答家長里短的常識性問題,才真正算是擁有了“智能”。
5. 應(yīng)用場景有限
雖然NLP有很多子領(lǐng)域,但是目前發(fā)展最好的方向依舊只有分類、匹配、翻譯、搜索幾種,大部分任務(wù)的應(yīng)用場景依然受限。
6. 缺少高效的超參數(shù)自動搜索方案
7. 部分paper僅以比賽SOTA為導(dǎo)向
當(dāng)然這里并不是說這種方法不好,只是我們做研究時不應(yīng)該只以刷榜為唯一目標(biāo)。因為很多時候為了提升小數(shù)點后那0.XX%的分?jǐn)?shù)真的意義不大,難以對現(xiàn)有的深度學(xué)習(xí)發(fā)展帶來任何益處。
這也解釋了面試官詢問“如何在某比賽中獲得了不錯的成績”,聽到“多模集成”等堆模型的方式上分就反感。因為實際場景受限于資源、時間等因素,一般不會這么干。
8. 可解釋性不強

對一些模型學(xué)到的特征可視化(CNN、Attention等),或許可以幫助我們理解模型是怎樣學(xué)習(xí)的。此前,機器學(xué)習(xí)領(lǐng)域也有利用降維技術(shù)(t-SNE等)來理解高維特征分布的方法。
更多深度學(xué)習(xí)可解釋性研究可以參考[6]。
最近,2018圖靈獎獲得者 Bengio, LeCun 和 Hinton 受ACM邀請共聚一堂,回顧了深度學(xué)習(xí)的基本概念和一些突破性成果,也講述了深度學(xué)習(xí)未來發(fā)展面臨的挑戰(zhàn)。
https://www.zhihu.com/question/40577663/answer/224699031
深度學(xué)習(xí),深是表象,不是目的。Universal approximation theorem 理論證明只需要一個隱層就可以擬合任意函數(shù),可見重點不在深。深度學(xué)習(xí)與傳統(tǒng)機器學(xué)習(xí)相比:深度學(xué)習(xí)就是在學(xué)習(xí)表示。也就是說,通過精心設(shè)計的分層結(jié)構(gòu)學(xué)習(xí)到數(shù)據(jù)的本質(zhì)特征(表示)。
說到瓶頸,深度學(xué)習(xí)也算是機器學(xué)習(xí)的一種,它也會有機器學(xué)習(xí)本身的瓶頸。例如對數(shù)據(jù)依賴性很強。是數(shù)據(jù)的“行為智能”而非真的有自主意識的人工智能。這些問題上面的答案都說了不少。
除此之外,它還有一些特有的瓶頸。
比如特征結(jié)構(gòu)難以改變。對于數(shù)據(jù)的格式(尺寸、長短、顏色通道、文本詞典格式等等)要求苛刻。訓(xùn)練好的feature extractor不是那么容易遷移到其他task上。 它非常的不穩(wěn)定。例如在NLP的任務(wù)中,做文本生成(QA)、圖像標(biāo)注之類的工作時,有時候生成的內(nèi)容讓你拍案叫絕。但經(jīng)常也會是匪夷所思。所以它的不可控性導(dǎo)致在工程應(yīng)用中不是很廣泛。很多犧牲recall保precision的應(yīng)用都沒法用深度學(xué)習(xí)去搞,否則容易出危險。相比之下rule based的方法要可靠得多。至少出問題了能debug一下。
它難以hotfix,出了問題基本靠重新調(diào)參訓(xùn)練。在應(yīng)用過程中會遇上很多潛在困難。
深度模型的優(yōu)化過于依賴個人經(jīng)驗。世界三大玄學(xué):西方占星、東方周易、深度學(xué)習(xí)。
模型結(jié)構(gòu)越來越復(fù)雜,不同系統(tǒng)之間越來越難以整合。就好像一直在培養(yǎng)超級士兵,但他們之間語言不通,沒法組成一個超級軍隊。
敏感信息問題。訓(xùn)練模型使用的數(shù)據(jù)如果沒有脫敏,是有可能通過一些方法把敏感信息給試出來。
攻擊問題。現(xiàn)在已經(jīng)證實對抗樣本(Adversarial Sample)的存在。創(chuàng)建一些對抗樣本能直接干掉現(xiàn)有的算法。不過感覺對抗樣本的生成是由于特征抽取并沒有學(xué)習(xí)到數(shù)據(jù)的流型特征而引發(fā)的。或者說,一定程度的overfit帶來了這個問題,
不過目前來說最大的問題還是對海量數(shù)據(jù)的需求。由于需要學(xué)習(xí)真實分布,而我們的數(shù)據(jù)僅僅是從真實分布中采樣得到的一小部分。想要讓模型真的逼近真實分布,那就要盡可能多的數(shù)據(jù)。數(shù)據(jù)量需求上來了,問題有很多:數(shù)據(jù)從哪來?數(shù)據(jù)存在哪?如何洗數(shù)據(jù)?誰來標(biāo)數(shù)據(jù)?如何在大量數(shù)據(jù)上訓(xùn)練?如何在成本(設(shè)備、數(shù)據(jù))和效果之間trade off?
由第8條擴展。需要海量數(shù)據(jù)的深度學(xué)習(xí)真的就是“人工智能”嗎?反正我是不信。人腦可以用有限的知識歸納,而非只是用人為設(shè)計的指導(dǎo)方針來指揮機器學(xué)習(xí)到特征空間的分布。所以真正的人工智能,對數(shù)據(jù)和運算的需求應(yīng)該并沒有那么大!(這條其實也是機器學(xué)習(xí)的問題)
https://www.zhihu.com/question/40577663/answer/311095389
Dropout/BN/Residual這些創(chuàng)新也好trick也罷,至少能編一個有眉有顏的直觀解釋糊弄一下,在截然不同的場景和任務(wù)下也有成功的應(yīng)用。去年這種級別的新的好用的trick基本沒見著。煉丹師的人口越來越龐大,通用性的trick卻沒有被發(fā)掘出來,說明領(lǐng)域已經(jīng)到了一個瓶頸,好摘的桃子已經(jīng)被摘光了。
結(jié)構(gòu)的潛力已經(jīng)被挖光了么?還是我們沒有找到更具有通用性和代表性的任務(wù)來作為新的trick的溫床?這些都是DL研究需要回答的問題。現(xiàn)在看起來形式并不樂觀,傳統(tǒng)的DL研究依賴的改幾根線多加幾個layer,針對一個特定任務(wù)跑個分的范式,現(xiàn)在要發(fā)出高質(zhì)量的paper是越來越困難了。
個人的看法是,如果DL想要真正帶上人工智能的帽子,那就要去做智能改干的事情,現(xiàn)在人為的按照應(yīng)用場景分成NLP/CV/ASR,粗暴的去擬合終究有上限,和人類獲得智能的方式也并沒有共同點。
https://www.zhihu.com/question/40577663/answer/224656397
圖像分類問題。此時x一般就是一個寬度*高度*通道數(shù)的圖像數(shù)值矩陣,y就是分類的類別。 語音識別問題。x為語音采樣信號,y為語音對應(yīng)的文字。 機器翻譯。x就是源語言的句子,y就是目標(biāo)語言的句子。
模型容量大,參數(shù)多 端到端(end-to-end)
一、訓(xùn)練f的效率還不算高
在訓(xùn)練效率上還有一個缺點是樣本的利用率不高。舉個小小的例子:圖片鑒黃。對于人類來說,只需要看幾個“訓(xùn)練樣本”,就可以學(xué)會鑒黃,判斷哪些圖片屬于“色情”是非常簡單的一件事。但是,訓(xùn)練一個深度學(xué)習(xí)的鑒黃模型卻往往需要成千上萬張正例+負(fù)例的樣本,例如雅虎開源的yahoo/open_nsfw。總的來說,和人類相比,深度學(xué)習(xí)模型往往需要多得多的例子才能學(xué)會同一件事。這是由于人類已經(jīng)擁有了很多該領(lǐng)域的“先驗知識”,但對于深度學(xué)習(xí)模型,我們卻缺乏一個統(tǒng)一的框架向其提供相應(yīng)的先驗知識。
那么在實際應(yīng)用中,如何解決這兩個問題?對于訓(xùn)練時間長的問題,解決辦法是加GPU;對于樣本利用率的問題,可以通過增加標(biāo)注樣本來解決。但無論是加GPU還是加樣本,都是需要錢的,而錢往往是制約實際項目的重要因素。
二、擬合得到的f本身的不可靠性
一個比較典型的例子是“對抗生成樣本”。如下所示,神經(jīng)網(wǎng)絡(luò)以60%的置信度將原始圖片識別為“熊貓”,當(dāng)我們對原始圖像加入一個微小的干擾噪聲后,神經(jīng)網(wǎng)絡(luò)卻以99%的置信度將圖片識別為“長臂猿”。這說明深度學(xué)習(xí)模型并沒有想象得那么可靠。

三、f可以實現(xiàn)“強人工智能”嗎
https://www.zhihu.com/question/40577663/answer/225319588
2、深度學(xué)習(xí)在應(yīng)對表格類數(shù)據(jù)的時候并沒有明顯優(yōu)勢,目前比較擅長的領(lǐng)域是計算機視覺,自然語言處理和語音識別。在表格數(shù)據(jù)情境下,大家更愿意使用xgboost等模型。
3、理論支撐薄弱,幾乎沒有人對深度學(xué)習(xí)的數(shù)學(xué)基礎(chǔ)做工作。大家一窩蜂地拿著模型水論文。
4、接上條,調(diào)參基本陷入了煉丹模式,深度學(xué)習(xí)調(diào)參已經(jīng)是一門玄學(xué)。
5、硬件資源消耗大,GPU已經(jīng)是必備,但是價格高昂,因此深度學(xué)習(xí)也稱為富人的游戲。
6、部署落地仍然困難,特別是移動應(yīng)用場景下。
7、無監(jiān)督學(xué)習(xí)仍然是困難,深度學(xué)習(xí)訓(xùn)練目前基本都基于梯度下降去極小化損失函數(shù),因此需要有標(biāo)簽。而對大量數(shù)據(jù)貼標(biāo)簽成本很高。當(dāng)然也有無監(jiān)督學(xué)習(xí)網(wǎng)絡(luò)正在迅猛發(fā)展,不過嚴(yán)格意義上說,GAN和VAE等都屬于自監(jiān)督學(xué)習(xí)。
看到評論中有質(zhì)疑第一條的,我發(fā)表一下自己的看法:一個比較強的學(xué)習(xí)器一般都不會擔(dān)心欠擬合的問題。神經(jīng)網(wǎng)絡(luò)擁有大量參數(shù),只要有足夠多的訓(xùn)練輪數(shù),理論上可以完全擬合訓(xùn)練集。但是這并不是我們想要的,這樣的模型泛化能力會非常差。而造成這一結(jié)果的原因就是,數(shù)據(jù)量太少,不足以代表整個數(shù)據(jù)背后的分布情況。此種情況下,神經(jīng)網(wǎng)絡(luò)幾乎是不加辨別的強行擬合上了訓(xùn)練集這個數(shù)據(jù)子集的分布,導(dǎo)致了過擬合。
https://www.zhihu.com/question/40577663/answer/224756448
1.end-to-end training
2.universal approximation
缺點是對其中間擬合過程我們幾乎沒有任何control,所有我們想讓其學(xué)習(xí)到的東西只能通過大量的數(shù)據(jù),更復(fù)雜的網(wǎng)絡(luò)(inception module, more layers),限定更多constraint(dropout, regularization),期望它最后學(xué)習(xí)到了等同于我們認(rèn)知的判斷。
舉個具體的例子,我們想判斷一直圖像是不是人臉。
其中一個籠統(tǒng)的判斷標(biāo)準(zhǔn)是,這張圖像上是否涵蓋2只眼睛,1個鼻子,1個嘴巴,以及他們之間的位置信息是否符合幾何邏輯。這也正是傳統(tǒng)dpm的思路,雖然以上每一步(subtask)都有可能出錯,致使overall performance不會特別好。但是相對來講每一個subtask都只需要較少的訓(xùn)練數(shù)據(jù),中間結(jié)果都會比較直觀,最后的結(jié)果符合我們?nèi)祟惖呐袛鄻?biāo)準(zhǔn)。
但是這件事由深度學(xué)習(xí)來做,你除了少數(shù)幾個“認(rèn)知”(prior knowledge)可以通過網(wǎng)絡(luò)結(jié)構(gòu)來定義(例如cnn實際上是默認(rèn)feature的local coherent+position invariant的特性),其他的認(rèn)知只能通過大量的數(shù)據(jù)來讓網(wǎng)絡(luò)自己去學(xué)習(xí)。一些簡單的元素如臉的大小,位置,旋轉(zhuǎn)你還可以通過data augmentation來模擬,但對于膚色,背景圖案,頭發(fā)的因素,就要靠找額外數(shù)據(jù)開擴充網(wǎng)絡(luò)對問題的認(rèn)知了。但即使是這樣,我們也無法確定網(wǎng)絡(luò)總結(jié)了哪些高層次的知識,當(dāng)我拿給他一張訓(xùn)練數(shù)據(jù)里沒有的二郎神的圖像,它會做出怎樣的判斷。
這也正是為什么數(shù)據(jù)是深度學(xué)習(xí)里最重要的一項。當(dāng)你數(shù)據(jù)不夠多樣的時候,它可能只學(xué)習(xí)到一些比較hacky的trivial solution;但是當(dāng)數(shù)據(jù)足夠全面的時候,它更有可能總結(jié)出比單純鼻子眼睛更有表達力的特征,只是我們無法理解而已。
END
整理不易,點贊三連↓