2006年,Hinton 發(fā)表了一篇論文《A Fast Learning Algorithm for Deep Belief Nets》,提出了降維和逐層預(yù)訓練方法,該方法可成功運用于訓練多層神經(jīng)網(wǎng)絡(luò),使深度網(wǎng)絡(luò)的實用化成為可能。該論文也被視作深度學習領(lǐng)域的經(jīng)典之作。
從原理來看,深度學習與神經(jīng)網(wǎng)絡(luò)緊密相關(guān):神經(jīng)網(wǎng)絡(luò)由一層一層的神經(jīng)元構(gòu)成,層數(shù)越多,神經(jīng)網(wǎng)絡(luò)越深,而所謂“深度學習”就是模擬人類大腦,運用深層神經(jīng)網(wǎng)絡(luò)對輸入進行“思考”、“分析”并獲得目標輸出的過程。
那么, 自2006年Hinton發(fā)表經(jīng)典論文以來,深度學習領(lǐng)域又取得了哪些突破性成果呢?
Google Brain前員工Denny Britz 在本文中進行了回顧整理,按時間順序介紹了從2012年到2020年深度學習領(lǐng)域的數(shù)項關(guān)鍵性科研成就,包括運用AlexNet和Dropout處理ImageNet(2012年)、使用深度強化學習玩Atari游戲(2013年)、應(yīng)用注意力機制的編碼器-解碼器網(wǎng)絡(luò)(2014年)、生成對抗網(wǎng)絡(luò)(2014-2015年)、ResNet(2015年)、Transformer模型(2017年)、BERT與微調(diào)自然語言處理模型(2018年),以及2019-2020年及之后的BIG語言模型與自監(jiān)督學習等。這些技術(shù)大部分應(yīng)用于視覺、自然語言、語音與強化學習等領(lǐng)域。這些研究均已經(jīng)過時間的考驗,并得到廣泛認可。本文不僅列舉了2012年以來的部分出色成果,還涉及到大量有利于了解當今深度學習研究現(xiàn)狀的基礎(chǔ)技術(shù)與知識。深度學習基礎(chǔ)技術(shù)的概念、方法和代碼等具有相似性,研究人員可以觸類旁通。比方說,一個終生研究計算機視覺(computer vision, CV)的學者很快也能適應(yīng)自然語言處理(Natural Language Processing, NLP),在NLP方向獲得成就。如果你是深度學習領(lǐng)域的入門者,以下閱讀將幫助你了解現(xiàn)有先進技術(shù)的來歷與最初發(fā)明用途,方便你更好地開展自己的研究工作。2012年:應(yīng)用AlexNet和Dropout 方法處理ImageNet- ImageNet Classification with Deep Convolutional Neural Networks (2012),https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
- Improving neural networks by preventing co-adaptation of feature detectors (2012)?,https://arxiv.org/abs/1207.0580
- One weird trick for parallelizing convolutional neural networks (2014)?,https://arxiv.org/abs/1404.5997
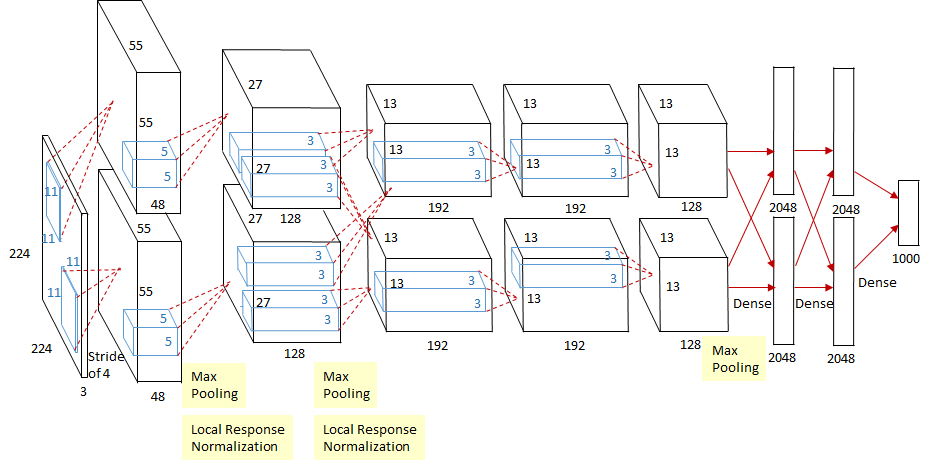
圖源:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networksAlexNet算法被認為是深度學習和人工智能研究蓬勃發(fā)展的主要原因。它是一種以Yann LeCun提出的早期LeNet網(wǎng)絡(luò)為基礎(chǔ)的深度卷積神經(jīng)網(wǎng)絡(luò)(Deep Convolutional Neural Networ)。AlexNet結(jié)合芯片GPU的功能和算法優(yōu)勢,大大超越了以前其他對ImageNet數(shù)據(jù)集中的圖像進行分類的方法。它的出現(xiàn)再一次證明了神經(jīng)網(wǎng)絡(luò)的強大。此外,AlexNet是最早運用Dropout的算法之一,之后也成為了提高各類深度學習模型泛化能力的一項關(guān)鍵技術(shù)。AlexNet 所使用的架構(gòu),包含一系列卷積層、ReLU非線性(ReLU nonlinearity)和最大池化算法(max-pooling),被廣泛視為后來CV架構(gòu)創(chuàng)建和擴展的標準。如今,諸如PyTorch之類的軟件庫具有十分強大的功能,加上與目前最新的神經(jīng)網(wǎng)絡(luò)架構(gòu)相比,AlexNet的構(gòu)成十分簡單,僅需幾行代碼即可通過 PyTorch 等軟件庫實現(xiàn)。有一點要注意的是:上述所介紹到的AlexNet的實現(xiàn)使用了論文《One weird trick for parallelizing convolutional neural networks》里所提到的網(wǎng)絡(luò)變量。2013年:使用深度強化學習玩轉(zhuǎn) Atari 游戲- Playing Atari with Deep Reinforcement Learning (2013),https://arxiv.org/abs/1312.5602
- 用PyTorch搭建深度強化學習模型(DQN),https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html
- 用TensorFlow搭建DQN,https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial
圖源:https://deepmind.com/research/publications/human-level-control-through-deep-reinforcement-learningDeepMind團隊,基于近年來在圖像識別和GPU方面取得的一系列突破,成功訓練了一個能通過原始像素輸入來玩Atari游戲的網(wǎng)絡(luò)。不僅如此,同一個神經(jīng)網(wǎng)絡(luò)架構(gòu)還在沒有被告知詳細游戲規(guī)則的前提下,學會了玩7款不同的游戲,從而證明了該方法的普適性。強化學習與監(jiān)督學習(比如圖像分類)的不同之處在于:在強化學習里,智能體必須在多個時間步(time step)內(nèi)學會如何獲得最多獎勵。具體來說,就是它必須贏得比賽,而不是僅僅預(yù)測某個標簽。由于智能體與環(huán)境直接互動,且每個動作都會影響下一個動作,所以訓練數(shù)據(jù)不是獨立且分布均勻的,這就使得許多機器學習模型的訓練十分不穩(wěn)定。這個現(xiàn)象可以使用經(jīng)驗回放(experience replay)等技術(shù)來解決。盡管這項研究沒有實現(xiàn)明顯的算法創(chuàng)新,但卻巧妙地結(jié)合了現(xiàn)有技術(shù)、基于GPU訓練的卷積神經(jīng)網(wǎng)絡(luò)、經(jīng)驗回放以及一些額外的數(shù)據(jù)處理技術(shù),并獲得了大多數(shù)人始料未及的出色結(jié)果。這也提升了研究人員擴展深度強化學習技術(shù)的信心,有望借鑒這個成果來解決包括圍棋、Dota 2、Starcraft 2等等更復雜的任務(wù)。Atari游戲在之后也成為了強化學習研究的標準基準。早期的深度強化學習方法僅超過人類基本水平、學會7款游戲,但在后來幾年時間里,基于這些思路所取得的進步,開始在更多游戲里打敗人類。其中有一款游戲叫《蒙特祖瑪?shù)膹统稹罚孕枰L期規(guī)劃而聞名,被認為是難度最大的游戲之一。直到最近,AI 已經(jīng)在57款游戲中超越了人類玩家的基準線。2014年:采用“注意力”的編碼器-解碼器網(wǎng)絡(luò)
相關(guān)論文:
- Sequence to Sequence Learning with Neural Networks,https://arxiv.org/abs/1409.3215
- Neural Machine Translation by Jointly Learning to Align and Translate,https://arxiv.org/abs/1409.0473
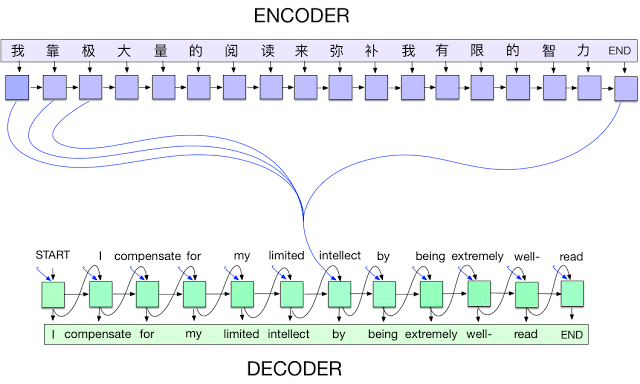
圖源:https://ai.googleblog.com/2017/04/introducing-tf-seq2seq-open-source.html深度學習最卓越的成就大多體現(xiàn)在與視覺相關(guān)的任務(wù)中,并且由卷積神經(jīng)網(wǎng)絡(luò)驅(qū)動。雖然NLP研究已使用LSTM網(wǎng)絡(luò)和編碼器-解碼器架構(gòu)在語言建模和翻譯方面取得了一定成功,但該領(lǐng)域也是直到注意力機制的出現(xiàn)才開始取得令人矚目的成就。在處理語言時,每個 token 都會被輸入循環(huán)網(wǎng)絡(luò)(如LSTM)中,并對先前處理過的輸入保持了記憶。token可能是字符,可能是單詞,也可能是介于字符和單詞之間的某物。換句話說,每個token都是一個時間步,一個句子就像一個時間序列。這些循環(huán)模型通常不擅長處理間隔長時間的依賴關(guān)系。在處理序列時,他們很容易“忘記”較早之前的輸入,因為它們的梯度需要通過大量時間步進行傳播。通過梯度下降方法優(yōu)化這些模型非常困難。新的注意力機制則有助于緩沖這一阻礙。它引入快捷連接(shortcut connections),給網(wǎng)絡(luò)提供了一個能夠在早期的時間步上適應(yīng)性地“回頭看”的選擇。這些連接可以幫助網(wǎng)絡(luò)決定生成特定輸出時哪些輸入是重要的。一個典型的例子就是機器翻譯:在生成輸出詞時,它通常會映射一個甚至多個特定的輸入詞。2014年:Adam優(yōu)化器?
相關(guān)論文:
- Adam: A Method for Stochastic Optimization,https://arxiv.org/abs/1412.6980
- 用PyTorch搭建實現(xiàn)Adam優(yōu)化器,https://d2l.ai/chapter_optimization/adam.html
- PyTorch Adam實現(xiàn),https://pytorch.org/docs/master/_modules/torch/optim/adam.html
- TensorFlow Adam實現(xiàn),https://github.com/tensorflow/tensorflow/blob/v2.2.0/tensorflow/python/keras/optimizer_v2/adam.py#L32-L281? ? ? ?
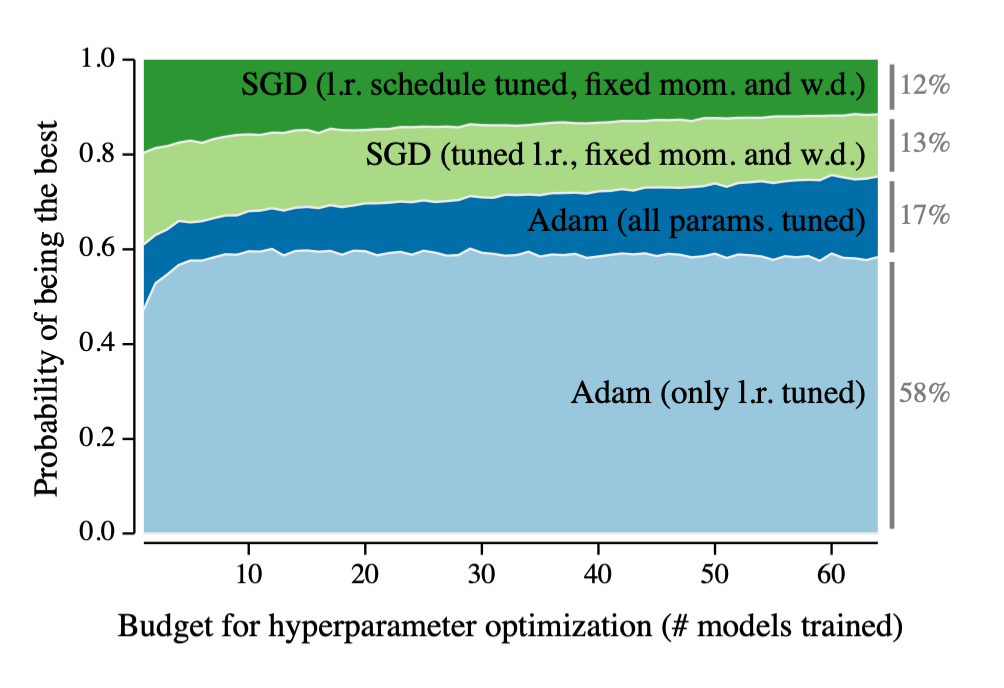
圖源:http://arxiv.org/abs/1910.11758神經(jīng)網(wǎng)絡(luò)通過運用優(yōu)化器將損失函數(shù)(如平均分類誤差)最小化進行訓練。優(yōu)化器負責調(diào)整網(wǎng)絡(luò)參數(shù)來使網(wǎng)絡(luò)學習目標。大多數(shù)優(yōu)化器都是基于隨機梯度下降(Stochastic Gradient Descent, SGD)的變量。但是,也有很多此類優(yōu)化器包含了可調(diào)節(jié)的參數(shù),比如優(yōu)化器本身的學習率。針對特定問題尋找正確設(shè)置不僅能減少訓練時間,還能通過找到局部最小損失函數(shù)來獲取更好的結(jié)果。大型研究實驗室往往會運行成本高昂的、使用了復雜學習速率調(diào)度器(learning rate schedules)的超參數(shù)檢索來獲取簡單但對超參數(shù)敏感的優(yōu)化器(比如SGD)中最好的那一個。有時候,他們的效果雖然超越了現(xiàn)有基準,但是往往是花費了大筆資金調(diào)節(jié)優(yōu)化器的結(jié)果。科研論文里往往不會提到研究成本這些細節(jié)。也就是說,研究人員如果沒有足夠的資金預(yù)算來優(yōu)化他們的優(yōu)化器,就只能深陷“效果不佳”的泥潭。Adam優(yōu)化器主張使用梯度的一階矩和二階矩來自動調(diào)整學習率。研究也表明,運用Adam優(yōu)化器所獲取的結(jié)果非常“魯棒”,且對超參數(shù)的調(diào)整不敏感。換句話說,Adam在大部分情況下無需太多調(diào)整就可以正常運行。就研究結(jié)果而言,目前一個被調(diào)整得很好的SGD表現(xiàn)更好,但Adam能幫助研究人員以較少成本進行研究。這是因為,如果實現(xiàn)的效果不好,研究者起碼知道并不是由于某個調(diào)整得不佳的優(yōu)化器所造成的。2014/2015年:生成對抗網(wǎng)絡(luò)(GAN)
相關(guān)論文:
- Generative Adversarial Networks,https://arxiv.org/abs/1406.2661
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,https://arxiv.org/abs/1511.06434
圖源:https://developers.google.com/machine-learning/gan/gan_structure生成模型(如變分自編器)必須對整個數(shù)據(jù)分布進行建模,圖像數(shù)據(jù)的像素極大,不像判別模型(discriminative model)一樣僅是區(qū)分貓貓與狗狗。生成模型的目標是建立看起來逼真的數(shù)據(jù)樣本,比如你可能在某處已經(jīng)見過的人臉圖像。生成對抗網(wǎng)絡(luò)(GAN)就屬于這類生成模型。GAN的基本內(nèi)容是對生成器(generator)和判別器(discriminator)進行一前一后的訓練。判別器經(jīng)過訓練來分辨真實圖像和生成圖像,而生成器的目標就是生成一些能夠騙過判別器的樣本。隨著訓練的深入,判別器識別偽造物體的能力會提高,但生成器也會越來越狡猾,并漸漸生成看起來更逼真的樣本。第一代GAN生成的圖像分辨率低,模糊不清,并且訓練起來十分不穩(wěn)定。但隨著時間的推移,研究者發(fā)明了許多改良版本,包括深度卷積生成對抗網(wǎng)絡(luò)(DCGAN)、CycleGAN、StyleGAN(v2)等等。這些改良版本基于第一代 GAN 的思路,成功生成高分辨率的、擬真的圖像和視頻。2015年:殘差網(wǎng)絡(luò)(ResNet)
相關(guān)論文:
- Deep Residual Learning for Image Recognition,https://arxiv.org/abs/1512.03385
- 用PyTorch搭建ResNet,https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
- 用TensorFlow搭建ResNet,https://github.com/tensorflow/tensorflow/blob/v2.2.0/tensorflow/python/keras/applications/resnet.py?
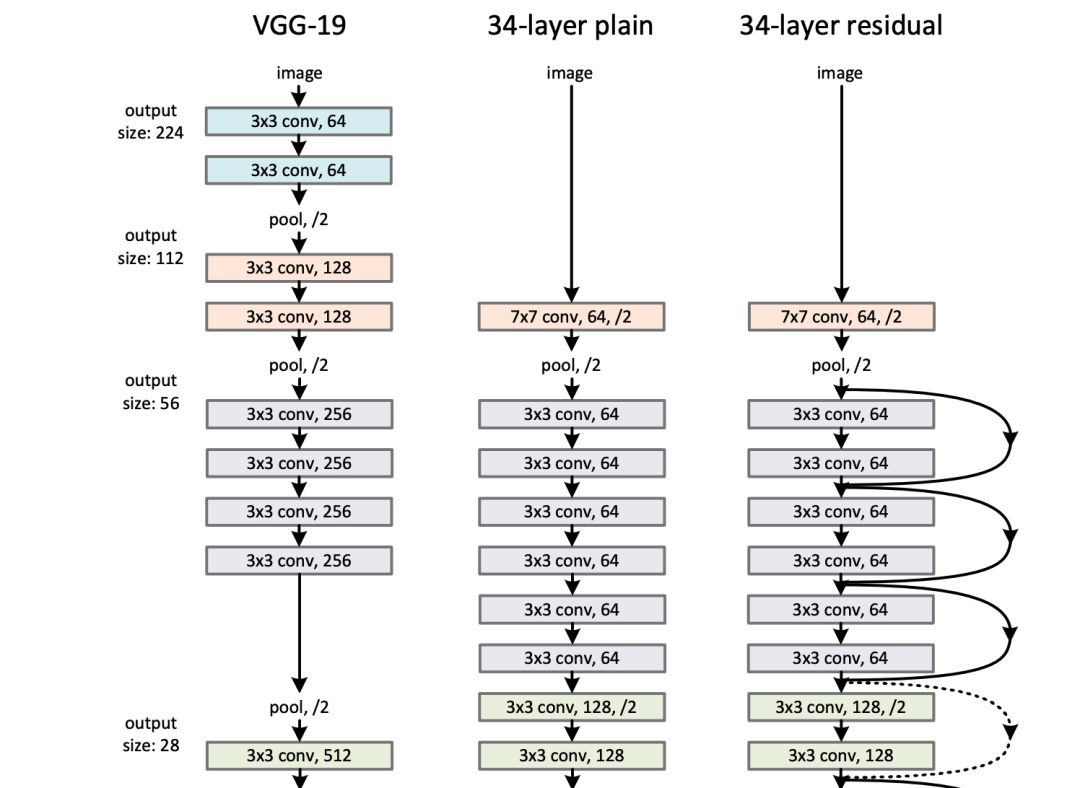 ? ? ? ?
? ? ? ?
研究人員基于AlexNet 的突破進行了一段時間的深入研究,提出了一系列基于卷積神經(jīng)網(wǎng)絡(luò)的性能更佳的架構(gòu),如VGGNet、Inception等等。而ResNet 就是緊接這一波迅速發(fā)展的新架構(gòu)的下一代神經(jīng)網(wǎng)絡(luò)架構(gòu)。迄今為止,ResNet的變體被視為各類任務(wù)的基準模型架構(gòu)和更復雜架構(gòu)的基本構(gòu)建要素,并得到廣泛應(yīng)用。ResNet的出眾,不僅是因為它在ILSVRC 2015的分類挑戰(zhàn)賽中取得了第一名的好成績,還因為與其他網(wǎng)絡(luò)架構(gòu)相比,它具有明顯的深度優(yōu)勢。論文《Deep Residual Learning for Image Recognition》里介紹到該網(wǎng)絡(luò)最深的層數(shù)可以達到1000層,而且,雖然該網(wǎng)絡(luò)在基準任務(wù)上的表現(xiàn)略遜于101層和152層的網(wǎng)絡(luò),但總體表現(xiàn)依然十分優(yōu)秀。這類深度網(wǎng)絡(luò)的訓練是一個非常有挑戰(zhàn)性的優(yōu)化問題,這是因為在訓練深層網(wǎng)絡(luò)的過程中,梯度會隨著層數(shù)的增加而遞減直至消失,這使得網(wǎng)絡(luò)優(yōu)化異常艱難。梯度消失的問題在序列模型(sequence model)中也有出現(xiàn)。極少研究人員相信訓練層數(shù)如此深的網(wǎng)絡(luò)能達到出色而穩(wěn)定的表現(xiàn)結(jié)果。ResNet應(yīng)用恒等快捷連接(identity shortcut connections)來促進梯度的流動。ResNet只需要逐層學習“變化量(Δ)”,難度較低,往往比學習整個變化量容易。這種恒等連接是“高速網(wǎng)絡(luò)”(Highway Network)里所提到的連接特例,反過來又受到長短期記憶網(wǎng)絡(luò)(LSTM)的門控機制(gating mechanism)的啟發(fā)。2017年:Transformer模型
相關(guān)論文:
- Attention is All You Need,https://arxiv.org/abs/1706.03762
- PyTorch: 應(yīng)用nn.Transformer和TorchText的序列到序列模型,https://pytorch.org/tutorials/beginner/transformer_tutorial.html
- Tensorflow: 用于語言理解的Transformer模型,https://www.tensorflow.org/tutorials/text/transformer
- HuggingFace的Transformers開發(fā)庫,https://github.com/huggingface/transformers? ? ??
圖源:https://arxiv.org/abs/1706.03762上文提到,具有注意力的序列到序列模表現(xiàn)地非常好,但由于該模型的循環(huán)特性需要用到序列算法,所以還存在一些缺點。它們很難并行處理,因為每次只運用一個步驟處理輸入。每個時間步都受到上一個時間步的影響。這也使得時間步很難擴展為長序列。即使具備了注意力機制,模型仍然在對復雜的長程依賴關(guān)系建模上面臨挑戰(zhàn)。大多數(shù)“工作”似乎都是在循環(huán)層中完成的。Transformer模型有效解決了上述問題。模型應(yīng)用多個前饋自注意層(feed-forward self-attention layers)取代循環(huán)層(recurrence),從而完全消除循環(huán)過程,從而能夠平行處理所有輸入并且生成輸入和輸出間相對較短的路徑(這就意味著梯度下降更易于優(yōu)化)。在這種情況下,模型能夠進行快速訓練,易于擴展并處理更多數(shù)據(jù)。此外,Transformer模型使用了位置編碼來向網(wǎng)絡(luò)傳遞輸入順序(這是循環(huán)模型無法做到的)。一開始學習Transformer模型也許有些摸不著頭腦,但如果想了解更多Transformer模型的應(yīng)用原理,可以參考以下鏈接里的講解:http://jalammar.github.io/illustrated-transformerTransformer模型的表現(xiàn)超出了所有人的期待。在接下來的幾年里,Transfomer會成為大多數(shù)序列任務(wù)(如NLP)甚至是計算機視覺的架構(gòu)標準。2018年:BERT和微調(diào)NLP模型
相關(guān)論文:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,https://arxiv.org/abs/1810.04805
- 具備Hugging Face的微調(diào)BERT,https://huggingface.co/transformers/training.html
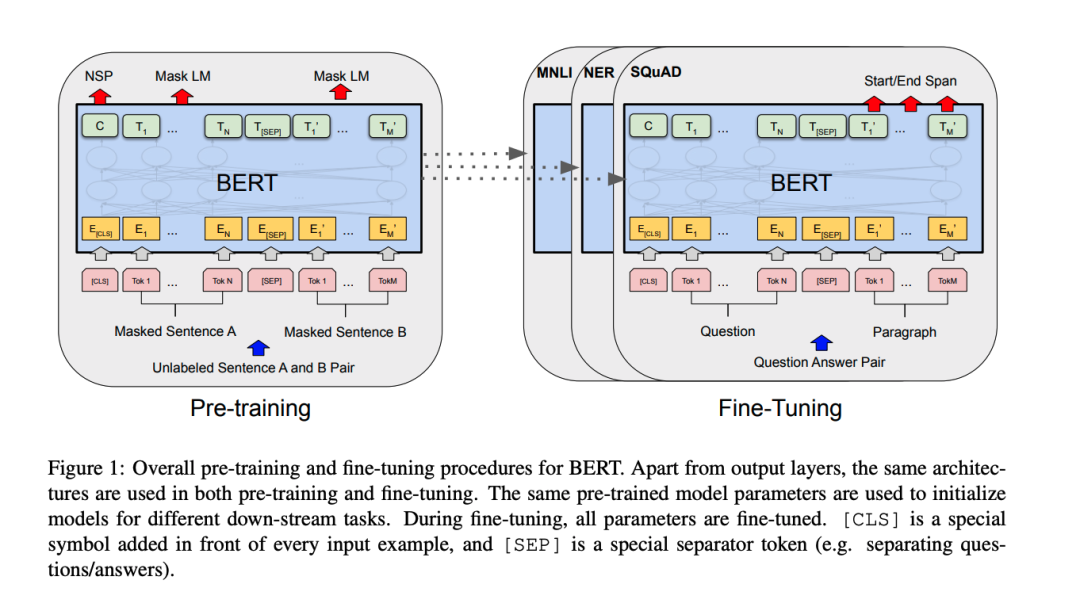
預(yù)訓練指的是事先訓練一個模型來執(zhí)行特定任務(wù),然后將訓練過程中學到的參數(shù)作為初始值以繼續(xù)學習其他相關(guān)任務(wù)。直觀來說,就是如果一個模型已經(jīng)學會進行圖像分類、區(qū)分貓貓和狗狗,也應(yīng)當大概了解圖像和毛茸動物的一般特征。當我們對這個能夠區(qū)分貓貓狗狗的模型進行微調(diào),來對狐貍進行分類時,我們希望這個模型能夠比必須從頭開始訓練的模型表現(xiàn)得更好。同樣地,一個已經(jīng)學會預(yù)測句子里的下一個單詞的模型,也應(yīng)該對人類語言模式有一定的了解。我們可能期望這個模型可以作為翻譯或情感分析等相關(guān)任務(wù)的好的初始化模型。預(yù)訓練和微調(diào)在計算機視覺和自然語言處理中都已有了成功的應(yīng)用。雖然預(yù)訓練和微調(diào)在計算機視覺領(lǐng)域中作為標準已有很長一段時間了,但要在 NLP 領(lǐng)域得到很好的應(yīng)用,似乎還困難重重。NLP 中取得的 SOAT 結(jié)果,依舊還是由于使用了完全監(jiān)督模型。隨著Transformer的出現(xiàn),研究者們終于可以在 NLP 任務(wù)中很好地應(yīng)用預(yù)訓練模型,并隨之提出了ELMo、ULMFiT和OpenAI's GPT等方法。BERT 便是預(yù)訓練模型在 NLP 領(lǐng)域取得的最新進展,許多人認為它開啟了NLP研究的新時代。BERT并不像其他大多數(shù)模型一樣進行預(yù)測下一個字的預(yù)訓練。它所接受的預(yù)訓練是預(yù)測整個句子被故意刪除/屏蔽的詞以及兩個句子之間是否有銜接關(guān)系。請注意:這些任務(wù)不需要用到標注的數(shù)據(jù)。它可以在任何文本上進行訓練,而且適用于篇幅長的文本。這個預(yù)訓練模型可能已學會語言的一些普遍特征,之后可以微調(diào)來執(zhí)行有監(jiān)督的任務(wù)(比如回答問題和預(yù)測情緒)。BERT在許多不同類型的任務(wù)中均有出色表現(xiàn)。之后BERT成為了XLNet、RoBERTa和ALBERT等先進技術(shù)的奠基之作。2019/2020年及之后:BIG語言模型,自監(jiān)督學習?
《慘痛的教訓》一文非常清晰地描述了深度學習發(fā)展史的趨勢。算法在并行化計算(更多數(shù)據(jù))和更多模型參數(shù)方面所取得了進步,一次又一次地超越了所謂“更聰明的技術(shù)”。這個趨勢一直持續(xù)到2020年GPT-3的出現(xiàn)。GPT-3是一個由OpenAI創(chuàng)建的擁有1750億參數(shù)的巨大語言模型。盡管GPT-3的訓練目標和標準架構(gòu)十分簡單,但卻展示了意料之外的良好泛化能力。
?文章鏈接:http://www.incompleteideas.net/IncIdeas/BitterLesson.html同樣的發(fā)展趨勢還包括對比性自監(jiān)督學習(contrastive self-supervised learning,如SimCLR)等能更好利用未標記數(shù)據(jù)的方法。隨著模型變得越來越大,訓練速度變得越來越快,這些能夠高效利用網(wǎng)頁上的大量未標記數(shù)據(jù)以及能夠?qū)W習可遷移到其他任務(wù)上的通用知識的技術(shù),將變得越來越具有價值,越來越普遍使用。- 本文不針對所提及的技術(shù)進行深入解析與代碼示例。我們主要介紹技術(shù)的歷史背景、相關(guān)論文鏈接和具體實現(xiàn)。建議有興趣的讀者能在不借助現(xiàn)有代碼和高階開發(fā)庫的前提下將這些論文研究成果重新演示一遍,相信一定會有收獲。
- 本文聚焦于深度學習的主流領(lǐng)域,包括視覺、自然語言、語音和強化學習/游戲等。
- 本文僅討論運行效果出色的官方或半官方開放源代碼實現(xiàn)。有些研究(比如Deep Mind的AlphaGo和OpenAI的Dota 2 AI)因為工程巨大、不容易被復制,所以在此沒有被重點介紹。
- 同一個時間段往往發(fā)布了許多相似的技術(shù)方法。但由于本文的主要目標是幫助初學者了解涵蓋多個領(lǐng)域的不同觀點,所以在每一類方法里選取了一種技術(shù)作為重點。比方說,GAN模型有上百種,但如果你想學習GAN的整體概念,只需要學習任意一種GAN即可。
via?https://dennybritz.com/blog/deep-learning-most-important-ideas/
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf

喜歡您就點個在看!