
教你Python使用隨機(jī)森林模型預(yù)測(cè)機(jī)票價(jià)格
印度的機(jī)票價(jià)格基于供需關(guān)系浮動(dòng),很少受到監(jiān)管機(jī)構(gòu)的限制。因此它通常被認(rèn)為是不可預(yù)測(cè)的,而動(dòng)態(tài)定價(jià)機(jī)制更增添了人們的困惑。
我們的目的是建立一個(gè)機(jī)器學(xué)習(xí)模型,根據(jù)歷史數(shù)據(jù)預(yù)測(cè)未來(lái)航班的價(jià)格,這些航班價(jià)格可以給客戶或航空公司服務(wù)提供商作為參考價(jià)格。

1.準(zhǔn)備
開始之前,你要確保Python和pip已經(jīng)成功安裝在電腦上,如果沒(méi)有,可以訪問(wèn)這篇文章:超詳細(xì)Python安裝指南?進(jìn)行安裝。
(可選1)?如果你用Python的目的是數(shù)據(jù)分析,可以直接安裝Anaconda:Python數(shù)據(jù)分析與挖掘好幫手—Anaconda,它內(nèi)置了Python和pip.
(可選2)?此外,推薦大家用VSCode編輯器,它有許多的優(yōu)點(diǎn):Python 編程的最好搭檔—VSCode 詳細(xì)指南。
請(qǐng)選擇以下任一種方式輸入命令安裝依賴:
1. Windows 環(huán)境 打開 Cmd (開始-運(yùn)行-CMD)。
2. MacOS 環(huán)境 打開 Terminal (command+空格輸入Terminal)。
3. 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install?pandas
pip install?numpy
pip install?matplotlib
pip install?seaborn
pip install?scikit-learn2.導(dǎo)入相關(guān)數(shù)據(jù)集
本文的數(shù)據(jù)集是 Data_Train.xlsx,首先看看訓(xùn)練集的格式:
import?pandas as?pd
import?numpy as?np
import?matplotlib.pyplot as?plt
import?seaborn as?sns
sns.set_style('whitegrid')
flights = pd.read_excel('./Data_Train.xlsx')
flights.head()
可見訓(xùn)練集中的字段有航空公司(Airline)、日期(Date_of_Journey)、始發(fā)站(Source)、終點(diǎn)站(Destination)、路線(Route)、起飛時(shí)間(Dep_Time)、抵達(dá)時(shí)間(Arrival_Time)、歷經(jīng)時(shí)長(zhǎng)(Duration)、總計(jì)停留站點(diǎn)個(gè)數(shù)(Total_Stops)、額外信息(Additional_Info),最后是機(jī)票價(jià)格(Price)。
與其相對(duì)的測(cè)試集,除了缺少價(jià)格字段之外,與訓(xùn)練集的其他所有字段均一致。
下載完整數(shù)據(jù)源和代碼請(qǐng)?jiān)L問(wèn):
https://pythondict.com/download/predict-ticket/
或在Python實(shí)用寶典后臺(tái)回復(fù):預(yù)測(cè)機(jī)票。
3.探索性數(shù)據(jù)分析
3.1 清理缺失數(shù)據(jù)
看看所有字段的基本信息:
flights.info()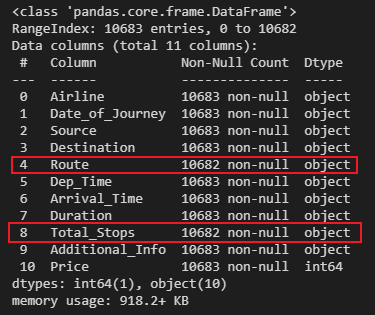
其他的非零值數(shù)量均為10683,只有路線和停靠站點(diǎn)數(shù)是10682,說(shuō)明這兩個(gè)字段缺少了一個(gè)值。
謹(jǐn)慎起見,我們刪掉缺少數(shù)據(jù)的行:
# clearing the missing data
flights.dropna(inplace=True)
flights.info()
現(xiàn)在非零值達(dá)到一致數(shù)量,數(shù)據(jù)清理完畢。
3.2 航班公司分布特征
接下來(lái)看看航空公司的分布特征:
sns.countplot('Airline', data=flights)
plt.xticks(rotation=90)
plt.show()
前三名的航空公司分別是 IndiGo, Air India, JetAirways.
其中可能存在廉價(jià)航空公司。
3.3 再來(lái)看看始發(fā)地的分布
sns.countplot('Source',data=flights)
plt.xticks(rotation=90)
plt.show()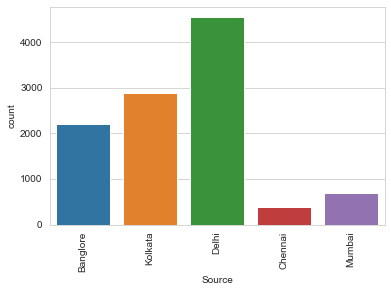
某些地區(qū)可能是冷門地區(qū),存在冷門機(jī)票的可能性比較大。
3.4 停靠站點(diǎn)的數(shù)量分布
sns.countplot('Total_Stops',data=flights)
plt.xticks(rotation=90)
plt.show()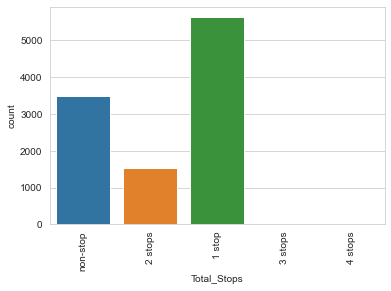
看來(lái)大部分航班在飛行途中只停靠一次或無(wú)停靠。
會(huì)不會(huì)某些停靠多的航班比較便宜?
3.5 有多少數(shù)據(jù)含有額外信息
plot=plt.figure()
sns.countplot('Additional_Info',data=flights)
plt.xticks(rotation=90)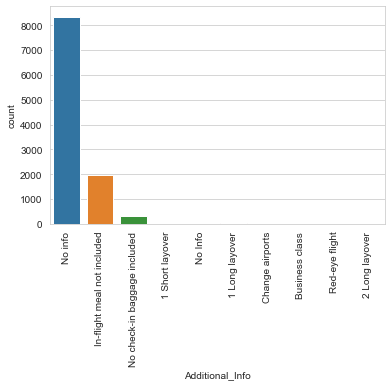
大部分航班信息中都沒(méi)有包含額外信息,除了部分航班信息有:不包含飛機(jī)餐、不包含免費(fèi)托運(yùn)。
這個(gè)信息挺重要的,是否不包含這兩項(xiàng)服務(wù)的飛機(jī)機(jī)票比較便宜?
3.6 時(shí)間維度分析
首先轉(zhuǎn)換時(shí)間格式:
flights['Date_of_Journey'] = pd.to_datetime(flights['Date_of_Journey'])
flights['Dep_Time'] = pd.to_datetime(flights['Dep_Time'],format='%H:%M:%S').dt.time
接下來(lái),研究一下出發(fā)時(shí)間和價(jià)格的關(guān)系:
flights['weekday'] = flights[['Date_of_Journey']].apply(lambda?x:x.dt.day_name())
sns.barplot('weekday','Price',data=flights)
plt.show()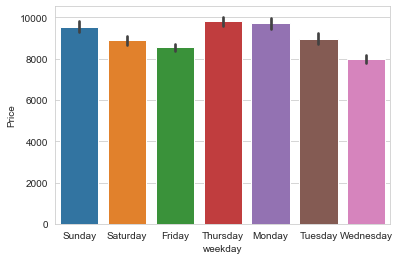
大體上價(jià)格沒(méi)有差別,說(shuō)明這個(gè)特征是無(wú)效的。
那么月份和機(jī)票價(jià)格的關(guān)系呢?
flights["month"] = flights['Date_of_Journey'].map(lambda?x: x.month_name())
sns.barplot('month','Price',data=flights)
plt.show()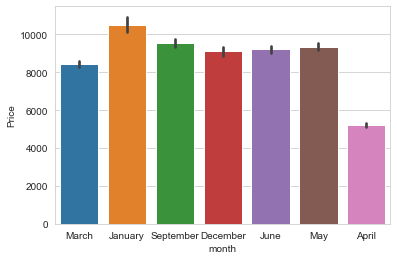
沒(méi)想到4月的機(jī)票價(jià)格均價(jià)只是其他月份的一半,看來(lái)4月份是印度的出行淡季吧。
起飛時(shí)間和價(jià)格的關(guān)系:
flights['Dep_Time'] = flights['Dep_Time'].apply(lambda?x:x.hour)
flights['Dep_Time'] = pd.to_numeric(flights['Dep_Time'])
sns.barplot('Dep_Time','Price',data=flights)
plot.show()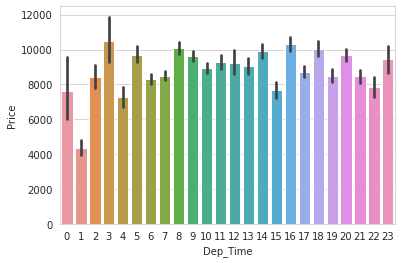
可以看到,紅眼航班(半夜及早上)的機(jī)票比較便宜,這是符合我們的認(rèn)知的。
3.7 清除無(wú)效特征
把那些和價(jià)格沒(méi)有關(guān)聯(lián)關(guān)系的字段直接去除掉:
flights.drop(['Route','Arrival_Time','Date_of_Journey'],axis=1,inplace=True)
flights.head()
4.模型訓(xùn)練
接下來(lái),我們可以準(zhǔn)備使用模型來(lái)預(yù)測(cè)機(jī)票價(jià)格了,不過(guò),還需要對(duì)數(shù)據(jù)進(jìn)行預(yù)處理和特征縮放。
4.1 數(shù)據(jù)預(yù)處理
將字符串變量使用數(shù)字替代:
from?sklearn.preprocessing import?LabelEncoder
var_mod = ['Airline','Source','Destination','Additional_Info','Total_Stops','weekday','month','Dep_Time']
le = LabelEncoder()
for?i in?var_mod:
????flights[i] = le.fit_transform(flights[i])
flights.head()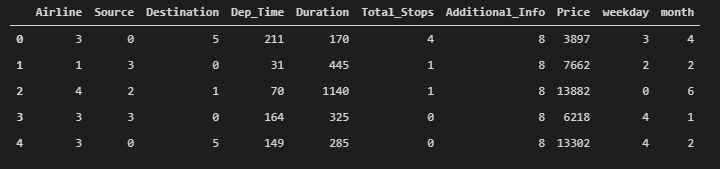
對(duì)每列數(shù)據(jù)進(jìn)行特征縮放,提取自變量(x)和因變量(y):
flights.corr()
def?outlier(df):
????for?i in?df.describe().columns:
????????Q1=df.describe().at['25%',i]
????????Q3=df.describe().at['75%',i]
????????IQR= Q3-Q1
????????LE=Q1-1.5*IQR
????????UE=Q3+1.5*IQR
????????df[i]=df[i].mask(df[i]????????df[i]=df[i].mask(df[i]>UE,UE)
????return?df
flights = outlier(flights)
x = flights.drop('Price',axis=1)
y = flights['Price'] 劃分測(cè)試集和訓(xùn)練集:
from?sklearn.model_selection import?train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=101)
4.2 模型訓(xùn)練及測(cè)試
使用隨機(jī)森林進(jìn)行模型訓(xùn)練:
from?sklearn.ensemble import?RandomForestRegressor
rfr=RandomForestRegressor(n_estimators=100)
rfr.fit(x_train,y_train)在隨機(jī)森林中,我們有一種根據(jù)數(shù)據(jù)的相關(guān)性來(lái)確定特征重要性的方法:
features=x.columns
importances = rfr.feature_importances_
indices = np.argsort(importances)
plt.figure(1)
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), features[indices])
plt.xlabel('Relative Importance')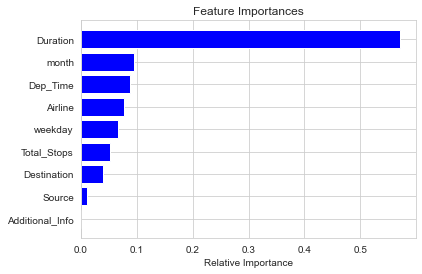
可以看到,Duration(飛行時(shí)長(zhǎng))是影響最大的因子。
對(duì)劃分的測(cè)試集進(jìn)行預(yù)測(cè),得到結(jié)果:
predictions=rfr.predict(x_test)
plt.scatter(y_test,predictions)
plt.show()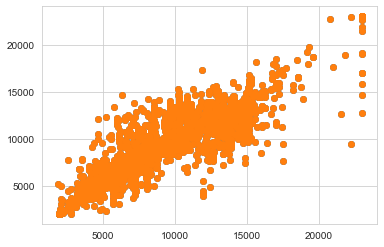
這樣看不是很直觀,接下來(lái)我們要數(shù)字化地評(píng)價(jià)這個(gè)模型。
4.3 模型評(píng)價(jià)
sklearn 提供了非常方便的函數(shù)來(lái)評(píng)價(jià)模型,那就是 metrics :
from?sklearn import?metrics
print('MAE:', metrics.mean_absolute_error(y_test, predictions))
print('MSE:', metrics.mean_squared_error(y_test, predictions))
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, predictions)))
print('r2_score:', (metrics.r2_score(y_test, predictions)))結(jié)果:
MAE: 1453.9350628905618
MSE: 4506308.3645551
RMSE: 2122.806718605135
r2_score: 0.7532074710409375這4個(gè)值中你可以只關(guān)注R2_score,r2越接近1說(shuō)明模型效果越好,這個(gè)模型的分?jǐn)?shù)是0.75,算是很不錯(cuò)的模型了。
看看其殘差直方圖是否符合正態(tài)分布:
sns.distplot((y_test-predictions),bins=50)
plt.show()
不錯(cuò),多數(shù)預(yù)測(cè)結(jié)果和真實(shí)值都在-1000到1000的范圍內(nèi),算是可以接受的結(jié)果。其殘差直方圖也基本符合正態(tài)分布,說(shuō)明模型是有效果的。
譯自kaggle社區(qū),有較多的增刪:
https://www.kaggle.com/harikrishna9/how-to-predict-flight-ticket-price/notebook
我們的文章到此就結(jié)束啦,如果你喜歡今天的Python 實(shí)戰(zhàn)教程,請(qǐng)持續(xù)關(guān)注Python實(shí)用寶典。
有任何問(wèn)題,可以在公眾號(hào)后臺(tái)回復(fù):加群,回答相應(yīng)紅字驗(yàn)證信息,進(jìn)入互助群詢問(wèn)。
原創(chuàng)不易,希望你能在下面點(diǎn)個(gè)贊和在看支持我繼續(xù)創(chuàng)作,謝謝!
點(diǎn)擊下方閱讀原文可獲得更好的閱讀體驗(yàn)
Python實(shí)用寶典?(pythondict.com)
不只是一個(gè)寶典
歡迎關(guān)注公眾號(hào):Python實(shí)用寶典