
DAFormer | 使用Transformer進(jìn)行語(yǔ)義分割無(wú)監(jiān)督域自適應(yīng)的開篇之作



由于為語(yǔ)義分割標(biāo)注真實(shí)圖像是一個(gè)代價(jià)昂貴的過(guò)程,因此可以用更容易獲得的合成數(shù)據(jù)訓(xùn)練模型,并在不需要標(biāo)注的情況下適應(yīng)真實(shí)圖像。
在
無(wú)監(jiān)督域適應(yīng)(UDA)中研究了這一過(guò)程。盡管有大量的方法提出了新的適應(yīng)策略,但它們大多是基于比較經(jīng)典的網(wǎng)絡(luò)架構(gòu)。由于目前網(wǎng)絡(luò)結(jié)構(gòu)的影響尚未得到系統(tǒng)的研究,作者首先對(duì)UDA的不同網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了基準(zhǔn)測(cè)試,并揭示了Transformer在UDA語(yǔ)義分割方面的潛力。在此基礎(chǔ)上提出了一種新的UDA方法DAFormer。
DAFormer的網(wǎng)絡(luò)結(jié)構(gòu)包括一個(gè)Transformer編碼器和一個(gè)多級(jí)上下文感知特征融合解碼器。它是由3個(gè)簡(jiǎn)單但很關(guān)鍵的訓(xùn)練策略來(lái)穩(wěn)定訓(xùn)練和避免對(duì)源域的過(guò)擬合:
源域上的罕見類采樣通過(guò)減輕 Self-training對(duì)普通類的確認(rèn)偏差提高了Pseudo-labels的質(zhì)量;Thing-Class ImageNet Feature Distance Learning rate warmup促進(jìn)了預(yù)訓(xùn)練的特征遷移
DAFormer代表了UDA的一個(gè)重大進(jìn)步。它在GTA→Cityscapes改善了10.8 mIoU、Synthia→Cityscapes提升了5.4 mIoU。
1簡(jiǎn)介
對(duì)于語(yǔ)義分割,標(biāo)注的成本特別高,因?yàn)槊總€(gè)像素都必須被標(biāo)記。例如,標(biāo)注一幅Cityscapes圖片需要1.5小時(shí),而在惡劣的天氣條件下,甚至需要3.3小時(shí)。
解決這個(gè)問(wèn)題的一個(gè)方法是使用合成數(shù)據(jù)進(jìn)行訓(xùn)練。然而,常用的CNN對(duì)域遷移很敏感,從合成數(shù)據(jù)到真實(shí)數(shù)據(jù)的泛化能力較差。該問(wèn)題在無(wú)監(jiān)督域適應(yīng)(UDA)中得到解決,通過(guò)將由源(合成)數(shù)據(jù)訓(xùn)練的網(wǎng)絡(luò)適應(yīng)于不訪問(wèn)目標(biāo)標(biāo)簽的目標(biāo)(真實(shí))數(shù)據(jù)。
以前的UDA方法主要是使用帶有ResNet或VGG Backbone的DeepLabV2或FCN8s網(wǎng)絡(luò)架構(gòu)來(lái)評(píng)估其貢獻(xiàn),以便與之前發(fā)表的作品相媲美。然而,即使他們最強(qiáng)大的架構(gòu)(DeepLabV2+ResNet101)在有監(jiān)督的語(yǔ)義分割領(lǐng)域也過(guò)時(shí)了。
例如,它在Cityscape上只能實(shí)現(xiàn)65 mIoU的監(jiān)督性能,而最近的網(wǎng)絡(luò)達(dá)到85 mIoU。由于存在較大的性能差距,使用過(guò)時(shí)的網(wǎng)絡(luò)架構(gòu)是否會(huì)限制UDA的整體性能,是否會(huì)誤導(dǎo)UDA的基準(zhǔn)測(cè)試進(jìn)展?
為了回答這個(gè)問(wèn)題,本文研究了網(wǎng)絡(luò)體系結(jié)構(gòu)對(duì)UDA的影響,設(shè)計(jì)了一個(gè)更復(fù)雜的體系結(jié)構(gòu),并通過(guò)一些簡(jiǎn)單但關(guān)鍵的訓(xùn)練策略成功地應(yīng)用于UDA。單純地為UDA使用更強(qiáng)大的網(wǎng)絡(luò)架構(gòu)可能是次最優(yōu)的,因?yàn)樗菀讓?duì)源域過(guò)擬合。
基于在UDA環(huán)境下評(píng)估的不同語(yǔ)義分割架構(gòu)的研究,作者設(shè)計(jì)了DAFormer,一個(gè)為UDA量身定制的網(wǎng)絡(luò)架構(gòu)。它是基于最近的Transformer,因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Transformer已經(jīng)被證明比主流的CNN更強(qiáng)大。
DAFormer它們與上下文感知的多級(jí)特征融合相結(jié)合,進(jìn)一步提高了UDA的性能。DAFormer是第一個(gè)揭示Transformer在UDA語(yǔ)義分割方面的巨大潛力的工作。
由于更復(fù)雜和有能力的架構(gòu)更容易適應(yīng)不穩(wěn)定和對(duì)源域過(guò)擬合,在這項(xiàng)工作中,引入了3個(gè)訓(xùn)練策略,以UDA解決這些問(wèn)題。
首先,提出了罕見類抽樣(RCS)來(lái)考慮源域的長(zhǎng)尾分布,這阻礙了罕見類的學(xué)習(xí),特別是在
UDA中,由于Self-training對(duì)常見類的確認(rèn)偏差。通過(guò)頻繁采樣罕見類圖像,網(wǎng)絡(luò)可以更穩(wěn)定地學(xué)習(xí)這些圖像,提高了偽標(biāo)簽的質(zhì)量,減少了確認(rèn)偏差。其次,提出了一個(gè)Thing-Class ImageNet Feature Distance(FD),它從ImageNet特征中提取知識(shí),以規(guī)范源訓(xùn)練。當(dāng)源域僅限于特定類的幾個(gè)實(shí)例(多樣性較低)時(shí),這尤其有用,因?yàn)樗鼈兊耐庥^與目標(biāo)域(域轉(zhuǎn)移)不同。如果沒(méi)有FD,這將導(dǎo)致學(xué)習(xí)缺乏表現(xiàn)力和特定于源領(lǐng)域的特性。當(dāng)ImageNet特征被訓(xùn)練為事物類時(shí),將FD限制為標(biāo)記為事物類的圖像區(qū)域。
最后,在
UDA中引入了學(xué)習(xí)率warm up。通過(guò)在早期訓(xùn)練中線性提高學(xué)習(xí)率到預(yù)期值,學(xué)習(xí)過(guò)程穩(wěn)定,從ImageNet預(yù)處理訓(xùn)練的特征可以更好地遷移到語(yǔ)義分割。

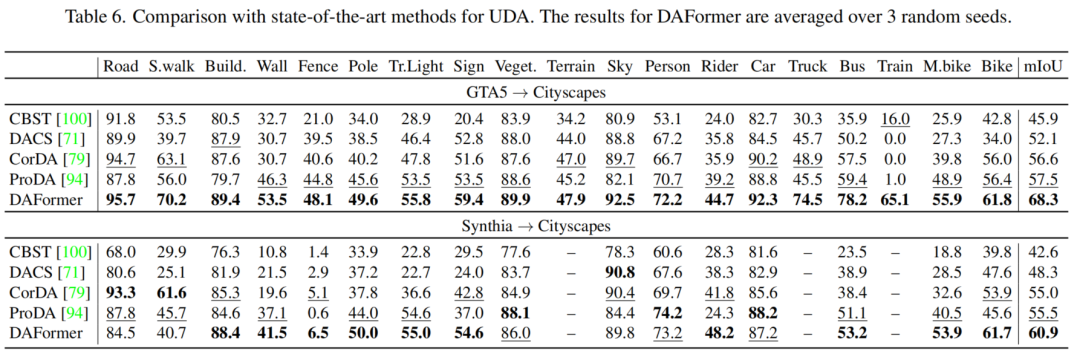
如圖1所示,DAFormer在很大程度上優(yōu)于以前的方法,這支持了作者的假設(shè),即網(wǎng)絡(luò)架構(gòu)和適當(dāng)?shù)挠?xùn)練策略對(duì)UDA發(fā)揮了重要作用。在GTA→cityscape上,將mIoU從57.5提高到68.3及以上,在Synthia→Cityscape上,將mIoU從55.5提高到60.9。
特別是DAFormer學(xué)習(xí)了以前的方法難以處理的更難的類。例如,在GTA→Cityscapes模式中,將火車等級(jí)從16 mIoU提高到65 mIoU,卡車等級(jí)從49 mIoU提高到75 mIoU,公共汽車等級(jí)從59 mIoU提高到78 mIoU。
總體而言,DAFormer代表了UDA的一個(gè)重大進(jìn)步。本文的框架可以在16小時(shí)內(nèi)在單個(gè)RTX 2080 Ti GPU上進(jìn)行一個(gè)階段的訓(xùn)練,這與之前的方法(如ProDA)相比簡(jiǎn)化了它的訓(xùn)練時(shí)間,后者需要在4個(gè)V100 GPU上訓(xùn)練1個(gè)階段需要很多天。
2相關(guān)方法
2.1 語(yǔ)義分割
自從引入卷積神經(jīng)網(wǎng)絡(luò)用于語(yǔ)義分割以來(lái),它們一直占據(jù)著該領(lǐng)域的主導(dǎo)地位。通常,語(yǔ)義分割網(wǎng)絡(luò)遵循編碼器-解碼器的設(shè)計(jì)。為了克服瓶頸處空間分辨率低的問(wèn)題,提出了skip connections、dilated convolutions或resolution preserving的架構(gòu)等補(bǔ)救措施。進(jìn)一步的改進(jìn)是通過(guò)利用上下文信息實(shí)現(xiàn)的,例如使用pyramid pooling或注意力模塊。
受基于注意力的Transformer在自然語(yǔ)言處理方面的成功啟發(fā),它們被用于圖像分類和語(yǔ)義分割,取得了最先進(jìn)的結(jié)果。
對(duì)于圖像分類,
CNN對(duì)分布偏移(如圖像損壞、對(duì)抗性噪聲或域偏移)很敏感。最近的研究表明,在這些特性方面,Transformer比CNN更健壯。CNN關(guān)注的是紋理,而Transformer更關(guān)注的是物體的形狀,它更類似于人類的視覺(jué)。在語(yǔ)義分割方面,采用了
ASPP和跳躍式連接來(lái)提高魯棒性。此外,基于Transformer的架構(gòu)提高了基于CNN網(wǎng)絡(luò)的魯棒性。
2.2 無(wú)監(jiān)督域自適應(yīng)(UDA)
UDA方法可分為Adversarial-training方法和Self-training方法。
Adversarial-training方法的目的是在GAN框架中,在輸入、特征、輸出或patch級(jí)別對(duì)齊源和目標(biāo)域的分布。對(duì)鑒別器使用多個(gè)尺度或類別信息可以優(yōu)化比對(duì)。
在Self-training中,利用目標(biāo)域的偽標(biāo)簽對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練。大多數(shù)的UDA方法都是離線預(yù)計(jì)算偽標(biāo)簽,訓(xùn)練模型,然后重復(fù)這個(gè)過(guò)程。或者,偽標(biāo)簽可以在訓(xùn)練期間在線計(jì)算。為了避免訓(xùn)練不穩(wěn)定性,采用了基于數(shù)據(jù)增強(qiáng)或域混淆的偽標(biāo)簽原型或一致性正則化方法。
幾種方法還包括Adversarial-training和Self-training相結(jié)合,訓(xùn)練與輔助任務(wù)相結(jié)合,或進(jìn)行測(cè)試時(shí)間UDA。
數(shù)據(jù)集通常是不平衡的,并且遵循長(zhǎng)尾分布,這使得模型偏向于學(xué)習(xí)公共類。解決這個(gè)問(wèn)題的策略有重采樣、損失重加權(quán)和遷移學(xué)習(xí)。在UDA中,采用重加權(quán)和類平衡采樣進(jìn)行圖像分類。
本文將類平衡抽樣從分類擴(kuò)展到語(yǔ)義切分,并提出了罕見類抽樣,該抽樣解決了罕見類和常見類在單個(gè)語(yǔ)義切分樣本中同時(shí)出現(xiàn)的問(wèn)題。此外,還證明了重采樣對(duì)于UDA訓(xùn)練Transformer特別有效。
Li等人已經(jīng)證明,從舊任務(wù)中提取的知識(shí)可以作為新任務(wù)的正則化器。作者也將這一思想應(yīng)用于Self-training中,實(shí)驗(yàn)表明它對(duì)Transformer特別有效,并通過(guò)將特征距離限制在圖像區(qū)域中進(jìn)行改進(jìn),如ImageNet主要標(biāo)記事物類。
3本文方法
3.1 Self-Training (ST) for UDA
在UDA中,神經(jīng)網(wǎng)絡(luò)為了實(shí)現(xiàn)良好的性能,對(duì)于目標(biāo)圖像,訓(xùn)練使用源域圖像和One-hot標(biāo)簽,沒(méi)有使用目標(biāo)標(biāo)簽。
在源域上使用分類交叉熵(CE)損失來(lái)訓(xùn)練網(wǎng)絡(luò)
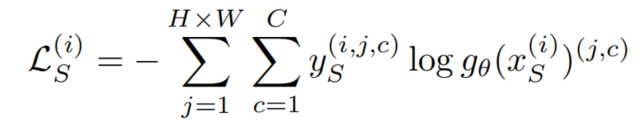
由于該網(wǎng)絡(luò)不能很好地推廣到目標(biāo)域,通常導(dǎo)致對(duì)目標(biāo)圖像的性能較低。
為了解決這一領(lǐng)域的差距,人們提出了幾種策略,可以分為Adversarial-training方法和Self-training方法。在這項(xiàng)工作中使用Self-training,因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Adversarial-training訓(xùn)練不穩(wěn)定。為了更好地將知識(shí)從源域轉(zhuǎn)移到目標(biāo)域,Self-training方法使用教師網(wǎng)絡(luò)來(lái)為目標(biāo)域數(shù)據(jù)生成偽標(biāo)簽:
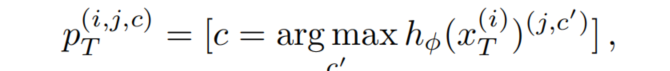
其中[·]為艾弗森括號(hào)。請(qǐng)注意,教師網(wǎng)絡(luò)沒(méi)有梯度反向傳播。另外,對(duì)偽標(biāo)簽進(jìn)行質(zhì)量/置信度估計(jì)。在這里,使用像素超過(guò)閾值τ的最大softmax概率:
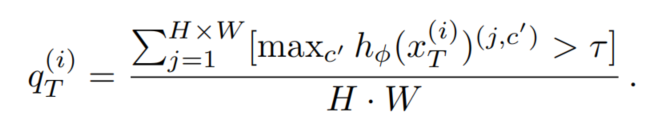
偽標(biāo)簽及其質(zhì)量估計(jì)被用于在目標(biāo)域上額外訓(xùn)練網(wǎng)絡(luò):
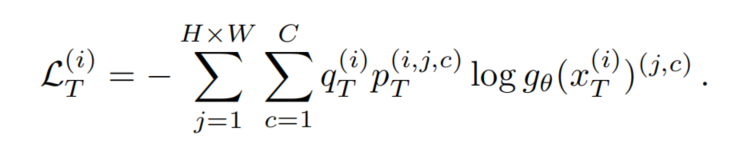
這些偽標(biāo)簽可以通過(guò)在線或離線來(lái)生成。本文選擇了在線Self-training。在在線Self-training中,在訓(xùn)練期間基于進(jìn)行更新。通常,權(quán)值被設(shè)置為每個(gè)訓(xùn)練步驟t后的權(quán)值的指數(shù)移動(dòng)平均值,以增加預(yù)測(cè)的穩(wěn)定性:
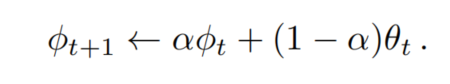
如果學(xué)生網(wǎng)絡(luò)訓(xùn)練增強(qiáng)目標(biāo)數(shù)據(jù),教師網(wǎng)絡(luò)使用非增強(qiáng)目標(biāo)數(shù)據(jù)半監(jiān)督學(xué)習(xí)和無(wú)監(jiān)督域適應(yīng)生成偽標(biāo)簽,Self-training方法已經(jīng)被證明是特別有效的。在這項(xiàng)工作中,遵循DACS和使用顏色抖動(dòng),高斯模糊,類Mix數(shù)據(jù)增強(qiáng)學(xué)習(xí)更多的領(lǐng)域穩(wěn)健的特性。
3.2 DAFormer Network Architecture
以前的UDA方法大多使用(簡(jiǎn)化的)DeepLabV2網(wǎng)絡(luò)架構(gòu)來(lái)評(píng)估,都是一些比較老的方法。因此,作者自行為UDA設(shè)計(jì)了一個(gè)定制的網(wǎng)絡(luò)體系結(jié)構(gòu),不僅可以實(shí)現(xiàn)良好的監(jiān)督性能,還可以提供良好的領(lǐng)域適應(yīng)能力。
對(duì)于編碼器,目標(biāo)是建立一個(gè)強(qiáng)大而又穩(wěn)健的網(wǎng)絡(luò)架構(gòu)。假設(shè)穩(wěn)健性是為了實(shí)現(xiàn)良好的域自適應(yīng)性能的一個(gè)重要特性,因?yàn)樗梢源龠M(jìn)域不變特征的學(xué)習(xí)。
基于最近的發(fā)現(xiàn),Transformer是UDA的一個(gè)很好的選擇,因?yàn)樗鼈儩M足這些標(biāo)準(zhǔn)。雖然Transformer的Self-Attention和卷積都是加權(quán)和,但它們的權(quán)值計(jì)算方式不同:在CNN中,權(quán)值在訓(xùn)練中學(xué)習(xí),但在測(cè)試中固定;在Self-Attention機(jī)制中,權(quán)值是基于每對(duì)Token之間的相似性或親和性動(dòng)態(tài)計(jì)算的。因此,Self-Attention機(jī)制中的自相似性操作提供了可能比卷積操作更具有自適應(yīng)性和通用性的建模手段。
作者遵循Mix Transformer(MiT)的設(shè)計(jì),它是為語(yǔ)義分割量身定制的。圖像被分成4×4大小的小塊(而不是ViT中的16×16),以便為語(yǔ)義分割保留更多的細(xì)節(jié)。為了應(yīng)對(duì)高特征分辨率,在Self-Attention塊中使用了序列約簡(jiǎn)。Transformer編碼器設(shè)計(jì)用于產(chǎn)生多級(jí)特征映射。下采樣是通過(guò)overlapping patch merging實(shí)現(xiàn)的,這樣可以保持局部連續(xù)性。
以前使用Transformer Backbone進(jìn)行語(yǔ)義分割的工作通常只利用局部信息作為解碼器。相反,作者建議在解碼器中利用額外的上下文信息,因?yàn)檫@已被證明可以增加語(yǔ)義分割的穩(wěn)健性,這是UDA的一個(gè)有用屬性。
DAFormer不只是考慮瓶頸特性的上下文信息,而是使用來(lái)自不同編碼器級(jí)別的特性的上下文信息,因?yàn)楦郊拥脑缙谔卣鳛楦叻直媛实恼Z(yǔ)義分割提供了有價(jià)值的low-level信息,這也可以提供重要的上下文信息。
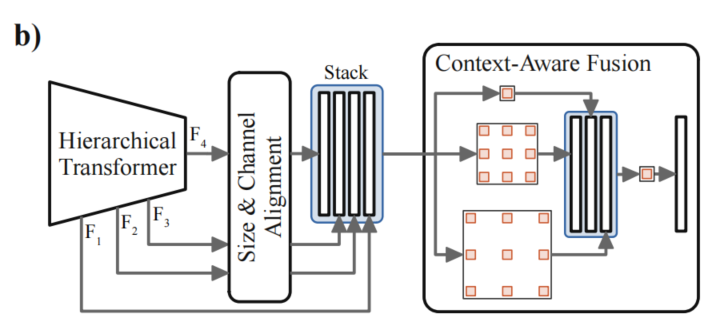
DAFormer解碼器的架構(gòu)如圖2(b)所示。在進(jìn)行特征融合之前,通過(guò)1×1卷積將每個(gè)嵌入到相同數(shù)量的通道中,并對(duì)特征進(jìn)行雙線性上采樣至大小,然后拼接。
對(duì)于上下文感知的特征融合,使用多個(gè)具有不同擴(kuò)張率的并行3×3深度可分離卷積和一個(gè)1×1卷積來(lái)融合它們,類似于ASPP,但沒(méi)有全局平均池化。
與最初使用ASPP相比,不僅將其應(yīng)用于瓶頸特性,而且將其用于融合所有堆疊的多層次特性。深度可分離卷積具有比常規(guī)卷積參數(shù)少的優(yōu)點(diǎn),可以減少對(duì)源域的過(guò)擬合。
3.3 Training Strategies for UDA
為UDA訓(xùn)練一個(gè)更強(qiáng)大的架構(gòu)的一個(gè)挑戰(zhàn)是對(duì)源域的過(guò)擬合。為了解決這個(gè)問(wèn)題,引入了3種策略來(lái)穩(wěn)定和規(guī)范UDA訓(xùn)練:
罕見類采樣 Thing-Class ImageNet特征距離 學(xué)習(xí)率Warmup
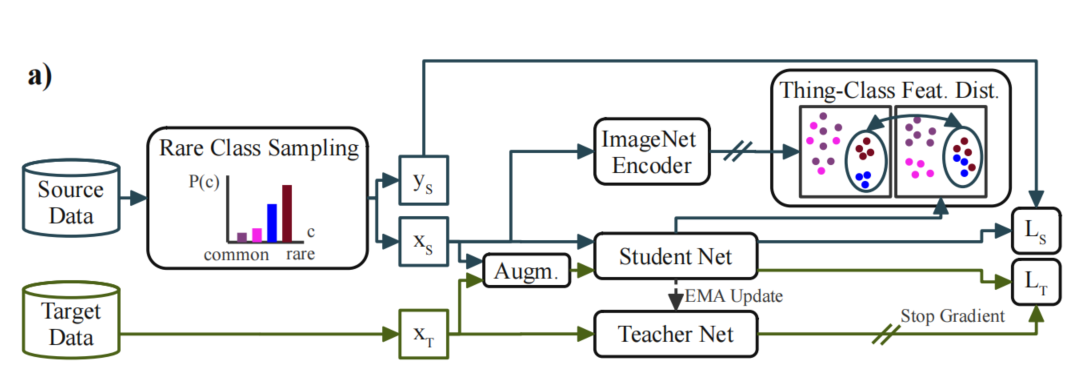
總體UDA框架如圖2(a)所示。
1、罕見類采樣
盡管DAFormer能夠在困難類上獲得比其他架構(gòu)更好的性能,但作者觀察到,源數(shù)據(jù)集中罕見的類的UDA性能在不同運(yùn)行中存在顯著差異。根據(jù)數(shù)據(jù)采樣順序的隨機(jī)種子,這些類是在訓(xùn)練的不同迭代中學(xué)習(xí)的。在訓(xùn)練中學(xué)習(xí)的類越晚,在訓(xùn)練結(jié)束時(shí)的表現(xiàn)越差。
作者假設(shè),如果由于隨機(jī)性,含有罕見類的相關(guān)樣本在訓(xùn)練中出現(xiàn)較晚,網(wǎng)絡(luò)才開始學(xué)習(xí)它們,更重要的是,很有可能這個(gè)網(wǎng)絡(luò)已經(jīng)學(xué)會(huì)了對(duì)普通類別的強(qiáng)烈偏愛,使得用很少的樣本“重新學(xué)習(xí)”新概念變得困難。
為了解決這個(gè)問(wèn)題,作者提出了罕見類采樣(RCS)。它經(jīng)常從源領(lǐng)域?qū)哂泻币婎惖膱D像進(jìn)行采樣,以便更好地、更早地學(xué)習(xí)它們。源數(shù)據(jù)集中每個(gè)c類的頻率可以根據(jù)類像素的個(gè)數(shù)來(lái)計(jì)算:
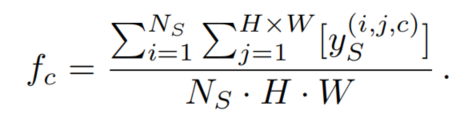
某一類c的采樣概率P(c)被定義為其頻率的函數(shù):
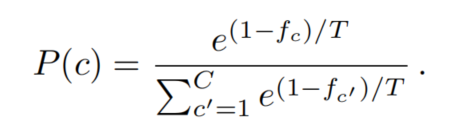
因此,頻率越小的類,其抽樣概率越高。T控制著分布的平滑度。T越高,分布越均勻;T越低,分布越集中在小的稀有類上。
2、Thing-Class ImageNet特征距離
通常,語(yǔ)義分割模型用ImageNet分類的權(quán)重初始化。考慮到ImageNet還包含來(lái)自一些相關(guān)的高級(jí)語(yǔ)義類的圖像,UDA經(jīng)常難以區(qū)分這些類,假設(shè)ImageNet特征可以提供除通常的預(yù)訓(xùn)練之外的有用監(jiān)督。特別是,作者觀察到DAFormer網(wǎng)絡(luò)能夠在訓(xùn)練開始時(shí)分割一些類,但在幾百個(gè)訓(xùn)練步驟后就會(huì)失去監(jiān)督效果。
因此,假設(shè)ImageNet預(yù)訓(xùn)練的有用特征被LS破壞,并且模型對(duì)合成源數(shù)據(jù)的過(guò)擬合。
為了避免這一問(wèn)題,基于語(yǔ)義分割UDA模型的瓶頸特征和ImageNet模型的瓶頸特征的特征距離(FD)對(duì)模型進(jìn)行規(guī)范化:
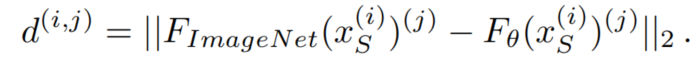
然而,ImageNet模型主要訓(xùn)練對(duì)象類(具有明確形狀的對(duì)象,如汽車或斑馬),而不是對(duì)象類(無(wú)定形的背景區(qū)域,如道路或天空)。因此,只計(jì)算包含由二進(jìn)制Mask 描述的事物類的圖像區(qū)域的:
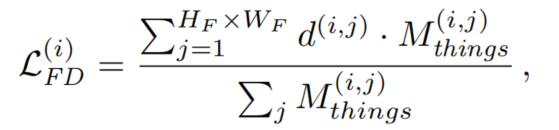
這個(gè)Mask是由 downscaled label 得到的:
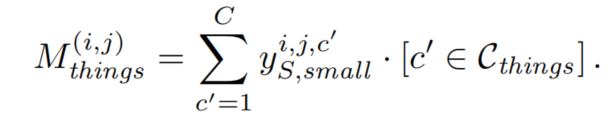
為了將標(biāo)簽降采樣到瓶頸特征大小,對(duì)每個(gè)類通道應(yīng)用patch size為的平均池化,當(dāng)一個(gè)類超過(guò)比率r時(shí),則該類將被保留:
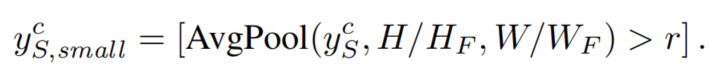
這確保了只有包含主導(dǎo)物類的瓶頸特征像素才被考慮為特征距離。
總體UDA loss L是各loss分量的加權(quán)和:
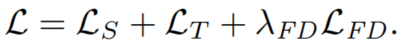
3、學(xué)習(xí)率Warmup
線性Warmup學(xué)習(xí)率開始訓(xùn)練已經(jīng)成功地用于訓(xùn)練網(wǎng)絡(luò)和Transformer,因?yàn)樗ㄟ^(guò)避免一個(gè)大的自適應(yīng)學(xué)習(xí)率方差改善了網(wǎng)絡(luò)泛化。作者最近在UDA中引入了學(xué)習(xí)率Warmup系統(tǒng)。假設(shè)這對(duì)UDA來(lái)說(shuō)特別重要,因?yàn)閬?lái)自ImageNet預(yù)訓(xùn)練的特征會(huì)剝奪網(wǎng)絡(luò)對(duì)真實(shí)領(lǐng)域的有用監(jiān)督。
在Warmup到迭代期間,迭代的學(xué)習(xí)速率設(shè)置為。
4實(shí)驗(yàn)
4.1 SOTA 對(duì)比
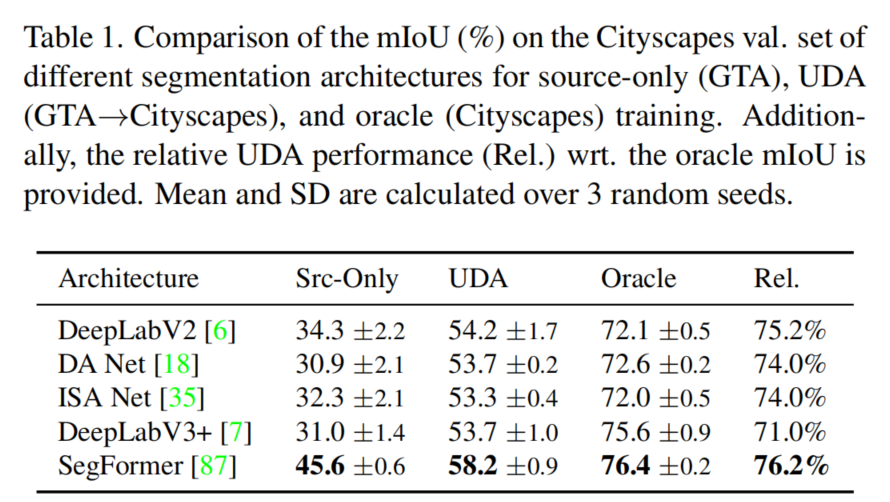
UDA上的大部分工作使用DeepLabV2和ResNet-101 Backbone。有趣的是,更高的Oracle性能并不一定會(huì)提高UDA性能,這在表1中的DeepLabV3+中可以看到。一般來(lái)說(shuō),研究的最新CNN架構(gòu)并沒(méi)有提供比DeepLabV2更好的UDA性能。
然而,作者確定了基于Transformer的SegFormer是一個(gè)強(qiáng)大的UDA架構(gòu)。它顯著提高了僅使用源代碼/UDA/oracle訓(xùn)練的mIoU,從34.3/54.2/72.1增加到45.6/58.2/76.4。作者認(rèn)為,特別是更好的SegFormer的域泛化(僅源訓(xùn)練)對(duì)于提高UDA性能是有價(jià)值的。
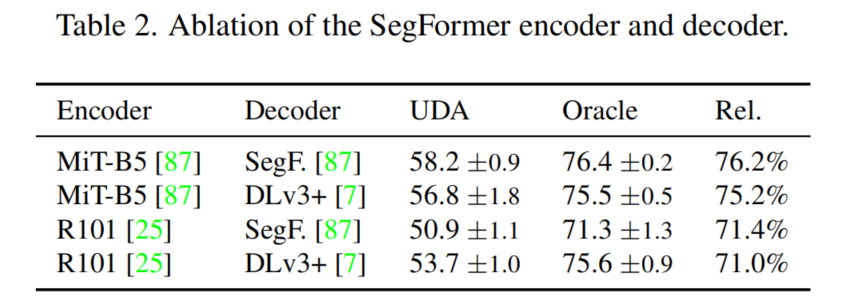
表2顯示,SegFormer的輕量級(jí)MLP解碼器相對(duì)于UDA性能略高于較重的DLv3+解碼器(76.2% vs . 75.2%)。然而,對(duì)于良好的UDA性能的關(guān)鍵貢獻(xiàn)來(lái)自于Transformer MiT編碼器。用ResNet101編碼器替換它會(huì)導(dǎo)致UDA性能的顯著下降。盡管由于ResNet編碼器的感受野變小,oracle的性能也會(huì)下降,但對(duì)于UDA來(lái)說(shuō),相對(duì)性能從76.2%下降到71.4%是不成比例的。
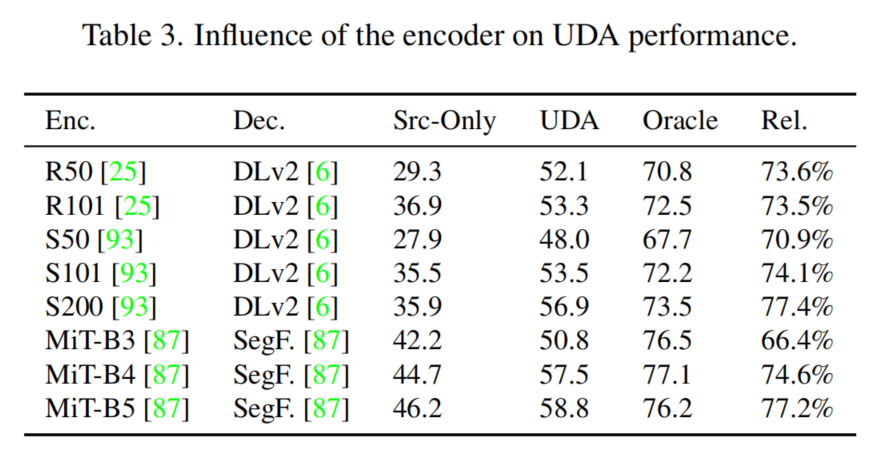
因此,進(jìn)一步研究了編碼器架構(gòu)對(duì)UDA性能的影響。在表3中比較了不同的編碼器的設(shè)計(jì)和大小。可以看出,更深層次的模型可以實(shí)現(xiàn)更好的source-only和相對(duì)性能,這表明更深層次的模型可以更好地概括/適應(yīng)新的領(lǐng)域。這一觀察結(jié)果與關(guān)于網(wǎng)絡(luò)架構(gòu)的魯棒性的研究結(jié)果相一致。
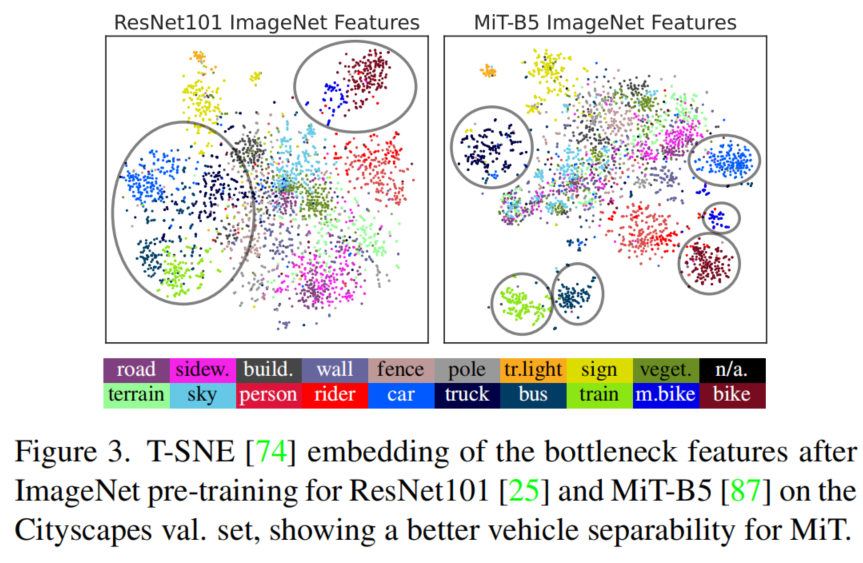
與CNN編碼器相比,MiT編碼器從源域訓(xùn)練推廣到目標(biāo)域。總的來(lái)說(shuō),最好的UDA mIoU是由MiT-B5編碼器實(shí)現(xiàn)的。為了深入了解改進(jìn)的泛化效果,圖3可視化了目標(biāo)域的ImageNet特征。盡管ResNet對(duì)stuff-classes的結(jié)構(gòu)稍微好一些,但MiT在分離語(yǔ)義上相似的類(例如所有車輛類)方面表現(xiàn)出色,而這些類通常特別難以適應(yīng)。
4.2 消融實(shí)驗(yàn)
1、Learning Rate Warmup
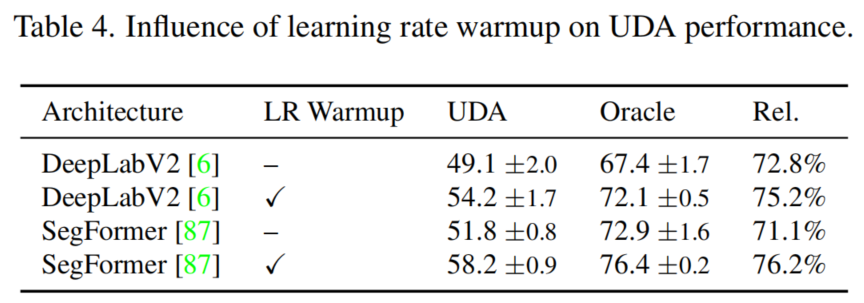
從表4可以看出,學(xué)習(xí)率Warmup顯著提高了UDA和oracle的性能。
2、Rare Class Sampling (RCS)
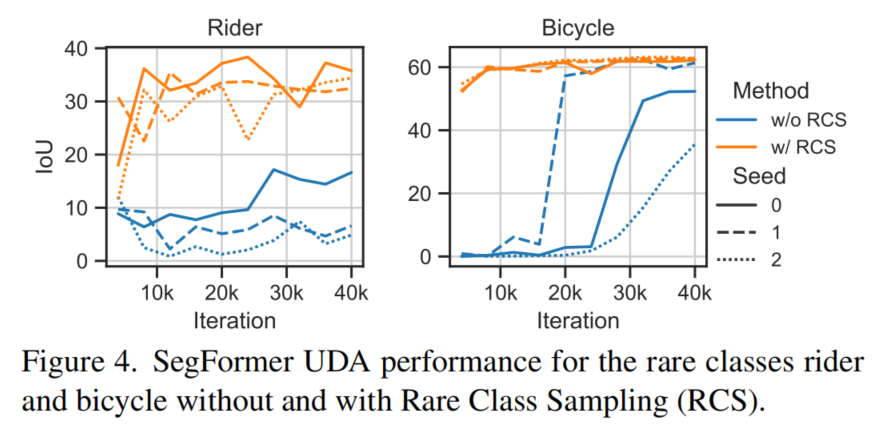
當(dāng)為UDA訓(xùn)練SegFormer時(shí),觀察到一些類的性能依賴于數(shù)據(jù)抽樣的隨機(jī)種子,如圖4中的藍(lán)色I(xiàn)oU曲線所示。源數(shù)據(jù)集中受影響的類沒(méi)有充分表示。有趣的是,對(duì)于不同的種子,自行車類的IoU在不同的迭代中開始增加。
假設(shè)這是由抽樣順序造成的,特別是當(dāng)相關(guān)的稀有類被抽樣時(shí)。此外,IoU越晚開始訓(xùn)練,該類的最后IoU就越差,這可能是由于在早期迭代中積累的自訓(xùn)練的確認(rèn)偏差。因此,對(duì)于UDA,盡早學(xué)習(xí)稀有的類別尤為重要。
為了解決這個(gè)問(wèn)題,所提出的RCS增加了罕見類的抽樣概率。圖4(橙色)顯示RCS導(dǎo)致騎行者/自行車的mIoU更早增加,最終mIoU更高,與數(shù)據(jù)抽樣隨機(jī)種子無(wú)關(guān)。這證實(shí)了假設(shè),即(早期)對(duì)稀有類的抽樣對(duì)于正確學(xué)習(xí)這些類很重要。
3、Thing-Class ImageNet Feature Distance(FD)
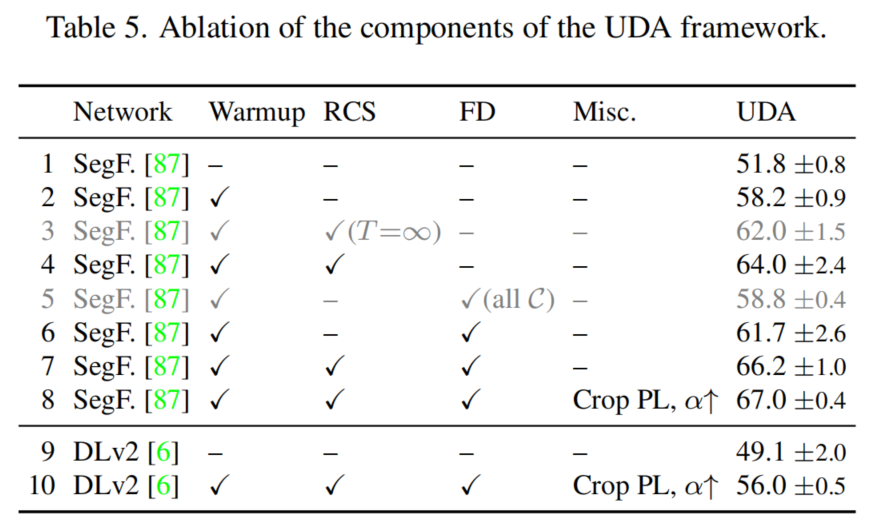

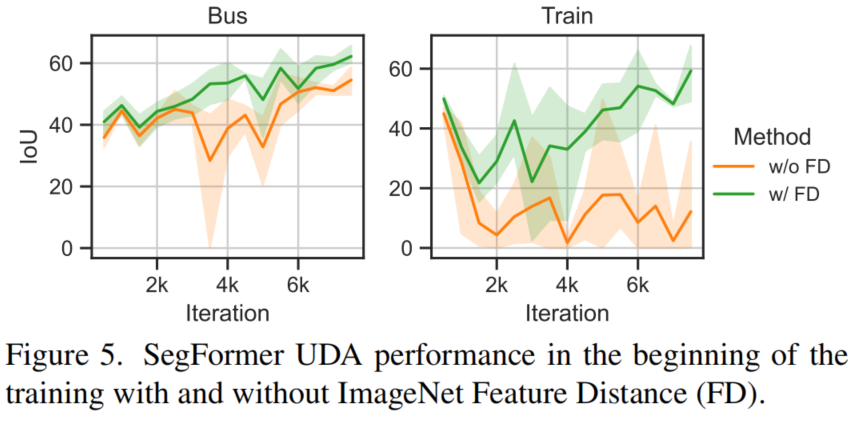
雖然RCS提高了性能,但事物類的性能仍然可以進(jìn)一步提高,因?yàn)樵赨DA訓(xùn)練后,一些在ImageNet特性中分離得相當(dāng)好的對(duì)象類(見圖3右)混合在一起。在調(diào)查早期訓(xùn)練期間的IoU時(shí)(見圖5橙色),觀察到列車Class的早期性能下降。
假設(shè)強(qiáng)大的MiT編碼器過(guò)度適合于合成域。當(dāng)使用建議的FD進(jìn)行正則化訓(xùn)練時(shí),避免了性能下降(見圖5綠色)。其他困難的Class,如公共汽車,摩托車和自行車受益于正規(guī)化(圖6中的第2行和第4行)。總體而言,UDA的性能提高了3.5mIoU(表5中的第2行和第6行).
注意,僅將FD只應(yīng)用于經(jīng)過(guò)ImageNet特性訓(xùn)練的類,對(duì)其良好的性能很重要(cf。第5行和第6行)。
4.3 DAFormer Decoder

5參考
[1].DAFormer6推薦閱讀
ResNet50 文藝復(fù)興 | ViT 原作者讓 ResNet50 精度達(dá)到82.8%,完美起飛!!!
全新Backbone | 模擬CNN創(chuàng)造更具效率的Self-Attention
探究Integral Pose Regression性能不足的原因
長(zhǎng)按掃描下方二維碼添加小助手。
可以一起討論遇到的問(wèn)題
聲明:轉(zhuǎn)載請(qǐng)說(shuō)明出處
掃描下方二維碼關(guān)注【集智書童】公眾號(hào),獲取更多實(shí)踐項(xiàng)目源碼和論文解讀,非常期待你我的相遇,讓我們以夢(mèng)為馬,砥礪前行!
