
U2PL: 使用不可靠偽標(biāo)簽的半監(jiān)督語(yǔ)義分割 (CVPR'22)

極市導(dǎo)讀
?半監(jiān)督任務(wù)的關(guān)鍵在于充分利用無(wú)標(biāo)簽數(shù)據(jù),本文基于「 Every Pixel Matters」的理念,有效利用了包括不可靠樣本在內(nèi)的全部無(wú)標(biāo)簽數(shù)據(jù),大幅提升算法精度。目前 U2PL 已被 CVPR 2022 接收,相關(guān)代碼已開(kāi)源。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
論文概況
論文標(biāo)題:_Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels_ 作者信息:商湯科技, 上海交通大學(xué), 香港中文大學(xué) 錄用信息:CVPR 2022 → arXiv:https://arxiv.org/pdf/2203.03884.pdf 代碼開(kāi)源:https://github.com/Haochen-Wang409/U2PL Project Page:https://haochen-wang409.github.io/U2PL/
今天介紹我們?cè)?strong style="color: black;">半監(jiān)督語(yǔ)義分割(Semi-Supervised Semantic Segmentation)領(lǐng)域的一篇原創(chuàng)工作 U2PL (Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels)。
半監(jiān)督任務(wù)的關(guān)鍵在于充分利用無(wú)標(biāo)簽數(shù)據(jù),我們基于「 Every Pixel Matters」的理念,有效利用了包括不可靠樣本在內(nèi)的全部無(wú)標(biāo)簽數(shù)據(jù),大幅提升算法精度。目前 U2PL 已被 CVPR 2022 接收,相關(guān)代碼已開(kāi)源,有任何問(wèn)題歡迎在 GitHub 提出。
Self-training: 樣本篩選導(dǎo)致訓(xùn)練不充分
半監(jiān)督學(xué)習(xí)的核心問(wèn)題在于有效利用無(wú)標(biāo)注數(shù)據(jù),作為有標(biāo)簽樣本的補(bǔ)充,以提升模型性能。
經(jīng)典的 self-training 方法大多遵循著 supervised learning → pseudo labeling → re-training 的基本流程,但學(xué)生網(wǎng)絡(luò)會(huì)從不正確的偽標(biāo)簽中學(xué)習(xí)到錯(cuò)誤的信息,因而存在 performance degradation 的問(wèn)題。
通常作法是通過(guò)樣本篩選等方式降低錯(cuò)誤偽標(biāo)簽的影響,然而只選擇高置信度的預(yù)測(cè)結(jié)果作為無(wú)標(biāo)簽樣本的偽標(biāo)簽,這種樸素的 self-training 策略會(huì)將大量的無(wú)標(biāo)簽數(shù)據(jù)排除在訓(xùn)練過(guò)程外,導(dǎo)致模型訓(xùn)練不充分。此外,如果模型不能較好地預(yù)測(cè)某些 hard class,那么就很難為該類別的無(wú)標(biāo)簽像素分配準(zhǔn)確的偽標(biāo)簽,從而進(jìn)入惡性循環(huán)。
我們認(rèn)為「 Every Pixel Matters」,即使是低質(zhì)量偽標(biāo)簽也應(yīng)當(dāng)被合理利用,過(guò)往的方法并沒(méi)有充分挖掘它們的價(jià)值。
Motivation: Every Pixel Matters
具體來(lái)說(shuō),預(yù)測(cè)結(jié)果的可靠與否,我們可以通過(guò)熵 (per-pixel entropy) 來(lái)衡量,低熵表示預(yù)測(cè)結(jié)果可靠,高熵表示預(yù)測(cè)結(jié)果不可靠。我們通過(guò) Figure 2 來(lái)觀察一個(gè)具體的例子,F(xiàn)igure 2(a) 是一張蒙有 entropy map 的無(wú)標(biāo)簽圖片,高熵的不可靠像素很難被打上一個(gè)確定的偽標(biāo)簽,因此不參與到 re-training 過(guò)程,在 FIgure 2(b) 中我們以白色表示。
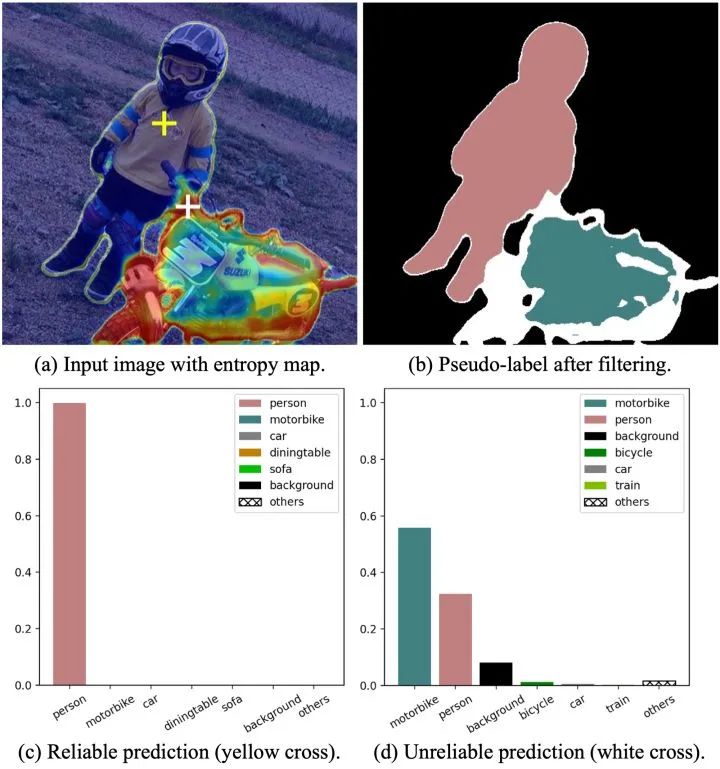
我們分別選擇了一個(gè)可靠的和不可靠的預(yù)測(cè)結(jié)果,在 Figure 2(c) 和 Figure 2(d) 中將它們的 category-wise probability 以柱狀圖的形式畫(huà)出。黃色十字叉所表示的像素在 person 類上的預(yù)測(cè)概率接近于 1,對(duì)于這個(gè)預(yù)測(cè)結(jié)果模型非常確信,低熵的該像素點(diǎn)是典型的 reliable prediction。而白色十字叉所表示的像素點(diǎn)在 motorbike 和 person 兩個(gè)類別上都具有不低的預(yù)測(cè)概率且在數(shù)值上較為接近,模型無(wú)法給出一個(gè)確定的預(yù)測(cè)結(jié)果,符合我們定義的 unralibale prediction。對(duì)于白色十字叉所表示的像素點(diǎn),雖然模型并不確信它具體屬于哪一個(gè)類別,但模型在這兩個(gè)類別上表現(xiàn)出極低的預(yù)測(cè)概率,顯然很確信它不屬于 car 和 train 這些類別。
因而,我們想到即使是不可靠的預(yù)測(cè)結(jié)果,雖然無(wú)法打上確定的偽標(biāo)簽,但可以作為部分類別的負(fù)樣本,從而參與到模型的訓(xùn)練。這樣所有的無(wú)標(biāo)簽樣本都能在訓(xùn)練過(guò)程中發(fā)揮作用。
Method
Overview
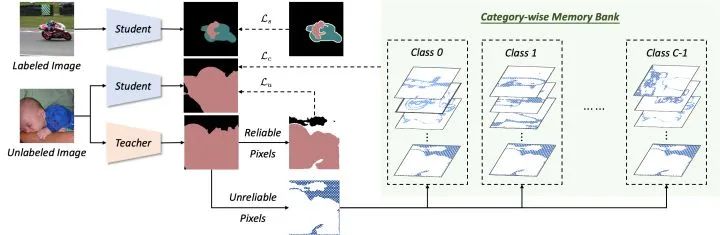
網(wǎng)絡(luò)結(jié)構(gòu)上,U2PL 采用經(jīng)典的 self-training 框架,由 teacher 和 student 兩個(gè)結(jié)構(gòu)完全相同的網(wǎng)絡(luò)組成,teacher 通過(guò) EMA 的形式接受來(lái)自 student 的參數(shù)更新。單個(gè)網(wǎng)絡(luò)的具體組成主要參考的是 ReCo (ICLR'22)[1],具體包括 encoder , decoder 和表征頭 。
損失函數(shù)優(yōu)化上,有標(biāo)簽數(shù)據(jù)直接基于標(biāo)準(zhǔn)的交叉熵?fù)p失函數(shù) 進(jìn)行優(yōu)化。無(wú)標(biāo)簽數(shù)據(jù)則先靠 teacher 給出預(yù)測(cè)結(jié)果,然后根據(jù) pixel-level entropy 分成 reliable pixels 和 unreliable pixels 兩大部分 (分流的過(guò)程在 Figure 2 有所體現(xiàn)), 最后分別基于 和 進(jìn)行優(yōu)化。
如上三個(gè)部分構(gòu)成了 U2PL 全部的損失函數(shù),熟悉 Self-training 的話就只需要關(guān)注 對(duì)比學(xué)習(xí)這部分,其實(shí)也是十分經(jīng)典的 InfoNCE Loss[2],后面會(huì)具體討論。
Pseudo-Labeling
本節(jié)主要探討無(wú)標(biāo)簽樣本中可靠預(yù)測(cè)結(jié)果的利用方式,即損失函數(shù)中的 部分
我們通過(guò)熵
對(duì)預(yù)測(cè)結(jié)果的可靠性進(jìn)行衡量,將最可靠的部分篩選出來(lái),再通過(guò)常規(guī)方式打上偽標(biāo)簽
隨著訓(xùn)練過(guò)程的推進(jìn),我們認(rèn)為模型的性能在不斷攀升,不可靠預(yù)測(cè)結(jié)果的比例相適應(yīng)地也在不斷下降,因此在不同的訓(xùn)練時(shí)刻我們對(duì)可靠部分的定義是不斷變化的,這里我們簡(jiǎn)單采用了線性變化策略而未作過(guò)多探索
需要注意的是,由于僅僅是部分無(wú)標(biāo)簽圖片像素點(diǎn)參與到這部分的計(jì)算,因此需要計(jì)算一個(gè)權(quán)重對(duì)這部分損失進(jìn)行調(diào)節(jié)。
Using Unreliable Pseudo-Labes
本節(jié)主要探討無(wú)標(biāo)簽樣本中不可靠預(yù)測(cè)結(jié)果的利用方式,即損失函數(shù)中的 部分。
U2PL 以對(duì)比學(xué)習(xí)為例介紹了如何將不可靠偽標(biāo)簽用于提升模型精度,既然是對(duì)比學(xué)習(xí),那不可避免的問(wèn)題就是討論如何構(gòu)建正負(fù)樣本對(duì)。接下來(lái)的有關(guān)對(duì)比學(xué)習(xí)內(nèi)容的實(shí)現(xiàn)細(xì)節(jié)大量參考了 ReCo[1],因此建議可以先看下這篇論文。
首先是 anchor pixels (queries),我們會(huì)給訓(xùn)練過(guò)程中出現(xiàn)在 mini-batch 中的每一個(gè)類別都采樣一系列的 anchor pixel。
然后是 anchor pixel 的 positive sampe 的構(gòu)建,我們會(huì)計(jì)算每一個(gè)類別的特征中心,每一個(gè)類別的 anchor pixel 都 share 一個(gè)共同的特征中心作為 postive sample。具體地,我們先從 mini-batch 分類別篩選出可用于計(jì)算特征中心的像素點(diǎn),對(duì)于有標(biāo)簽樣本和無(wú)標(biāo)簽樣本,篩選的標(biāo)準(zhǔn)是一致的,就是該樣本在真值標(biāo)簽類別或偽標(biāo)簽類別上的預(yù)測(cè)概率大于一個(gè)閾值,篩選出來(lái)的這些像素點(diǎn)的表征 的集合 求一個(gè)向量均值就能用作于各個(gè)類別的特征中心 ,這里可以參見(jiàn)如下公式
最后是 anchor pixel 的 negative sampe 的構(gòu)建,同樣的也需要分成有標(biāo)簽樣本和無(wú)標(biāo)簽樣本兩個(gè)部分去討論。對(duì)于有標(biāo)簽樣本,因們明確知道其所屬的類別,因此除真值標(biāo)簽外的所有類別都可以作為該像素的負(fù)樣本類別;而對(duì)于無(wú)標(biāo)簽樣本,由于偽標(biāo)簽可能存在錯(cuò)誤,因此我們并不完全卻行確信標(biāo)簽的正確性,因而我們需要將預(yù)測(cè)概率最高的幾個(gè)類別過(guò)濾掉,將該像素認(rèn)作為剩下幾個(gè)類別的負(fù)樣本。這部分對(duì)應(yīng)的是論文中公式 13-16,但說(shuō)實(shí)話這一段內(nèi)容用公式去描述還是比較晦澀的。

由于數(shù)據(jù)集中存在長(zhǎng)尾問(wèn)題,如果只使用一個(gè) batch 的樣本作為負(fù)樣本可能會(huì)非常受限,因此采用對(duì)比學(xué)習(xí)中很常用的 MemoryBank 來(lái)維護(hù)一個(gè)逐類別的負(fù)樣本庫(kù),存入的是由 teacher 生成的斷梯度特征,以先進(jìn)先出的隊(duì)列結(jié)構(gòu)維護(hù)。
Comparison with Existing Alternatives
本文所有的實(shí)驗(yàn)結(jié)果均是基于 ResNet-101 + Deeplab v3+ 的網(wǎng)絡(luò)結(jié)構(gòu)完成的,所采用的的數(shù)據(jù)集構(gòu)成和評(píng)估方式請(qǐng)參見(jiàn)論文描述。
我們?cè)?Classic VOC, Blender VOC, Cityscapes 三種數(shù)據(jù)集上均和現(xiàn)存方法進(jìn)行了對(duì)比,在全部?jī)蓚€(gè) PASCAL VOC 數(shù)據(jù)集上我們均取得了最佳精度。在 Cityscapes 數(shù)據(jù)集上由于我們沒(méi)能很好的解決長(zhǎng)尾問(wèn)題,落后于致力解決長(zhǎng)尾問(wèn)題的 AEL 方法,我們將 U2PL 疊加在 AEL 上能夠取得超越 AEL 的精度,也側(cè)面證明了 U2PL 的通用性。
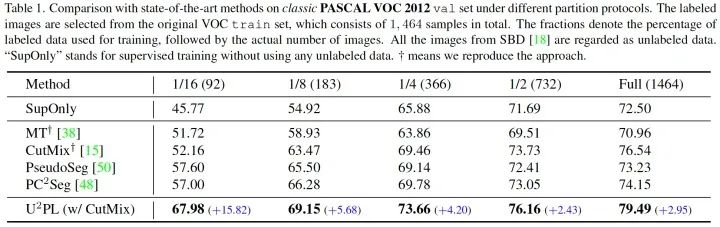
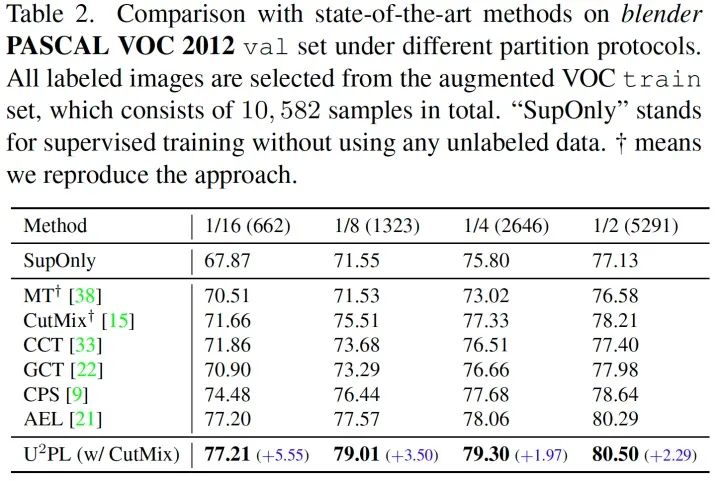
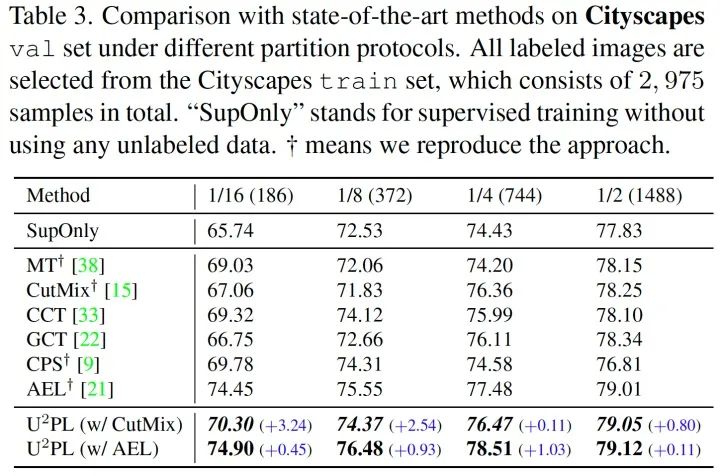
值得一提的是,U2PL 在有標(biāo)簽數(shù)據(jù)較少的劃分下,精度表現(xiàn)極為優(yōu)異。
Ablation Studies
Effectiveness of Using Unreliable Pseudo-Labels
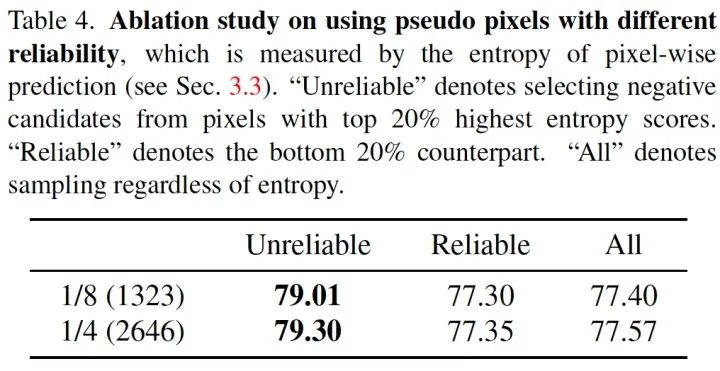
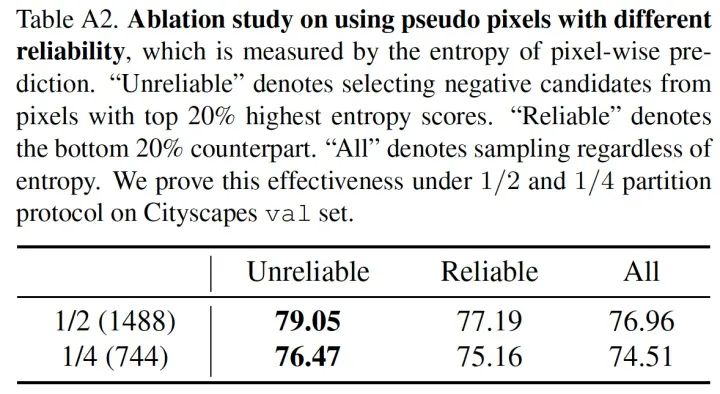
我們?cè)?PSACAL VOC 和 CItyscapes 等多個(gè)數(shù)據(jù)集的多個(gè)劃分上驗(yàn)證了使用不可靠偽標(biāo)簽的價(jià)值。
Alternative of Contrastive Learning
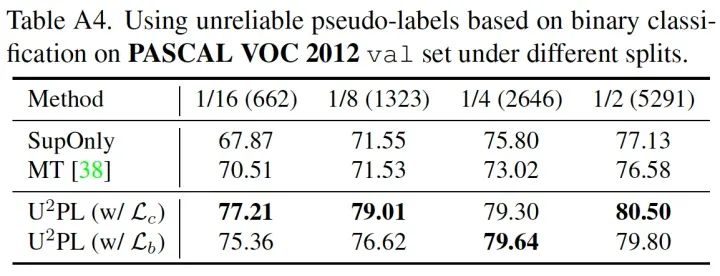
我們?cè)黾恿送ㄟ^(guò)二分類去利用不可靠樣本的對(duì)比實(shí)驗(yàn),證明利用低質(zhì)量偽標(biāo)并不只能通過(guò)對(duì)比學(xué)習(xí)去實(shí)現(xiàn),只要利用好低質(zhì)量樣本,即使是二分類方法也能取得不錯(cuò)的精度提升。
附錄
U2PL 與 negative learning 的區(qū)別
這里需要著重強(qiáng)調(diào)下我們的工作和 negative learning 的區(qū)別, negative learning 選用的負(fù)樣本依舊是高置信度的可靠樣本[3],相比之下我們則提倡充分利用不可靠樣本而不是把它們過(guò)濾掉。
比如說(shuō)預(yù)測(cè)結(jié)果 由于其不確定性會(huì)被 negative learning 方法丟棄,但在 U2PL 中卻可以被作為多個(gè) unlikely class 的負(fù)樣本,實(shí)驗(yàn)結(jié)果也發(fā)現(xiàn) negative learning 方法的精度不如 U2PL。
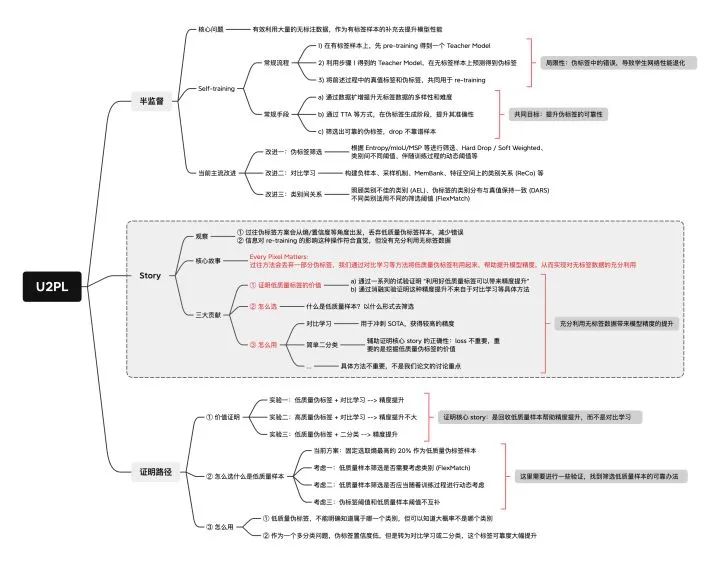
U2PL 技術(shù)藍(lán)圖
這里貼出技術(shù)藍(lán)圖,便于大家更好地理解論文的核心 story 和實(shí)驗(yàn)設(shè)計(jì)
參考
^ab[2104.04465] Bootstrapping Semantic Segmentation with Regional Contrast?https://arxiv.org/abs/2104.04465 ^[1807.03748] Representation Learning with Contrastive Predictive Coding?https://arxiv.org/abs/1807.03748 ^In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning?https://openreview.net/pdf/c979bcaed90f2b14dbf27b5e90fdbb74407f161b.pdf
公眾號(hào)后臺(tái)回復(fù)“數(shù)據(jù)集”獲取50+深度學(xué)習(xí)數(shù)據(jù)集下載~

#?CV技術(shù)社群邀請(qǐng)函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
