
預(yù)訓(xùn)練圖像處理Transformer
、點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
來源 | 小白學(xué)視覺
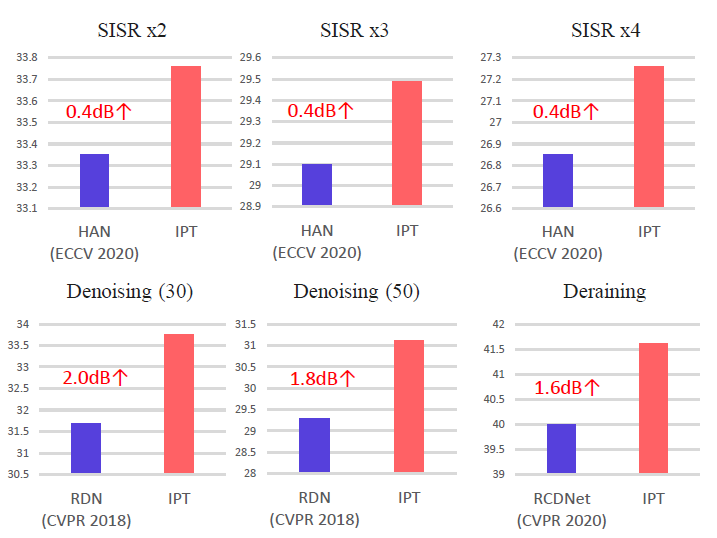
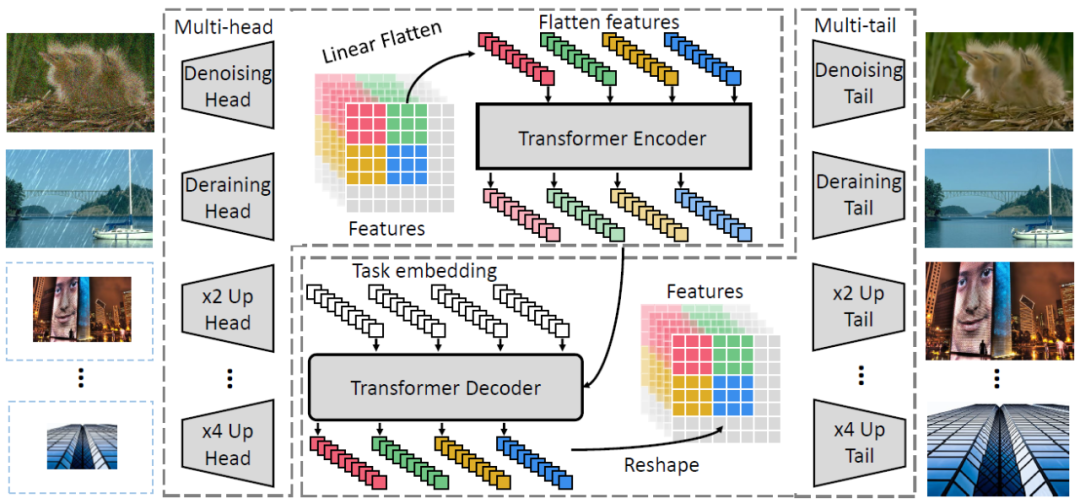
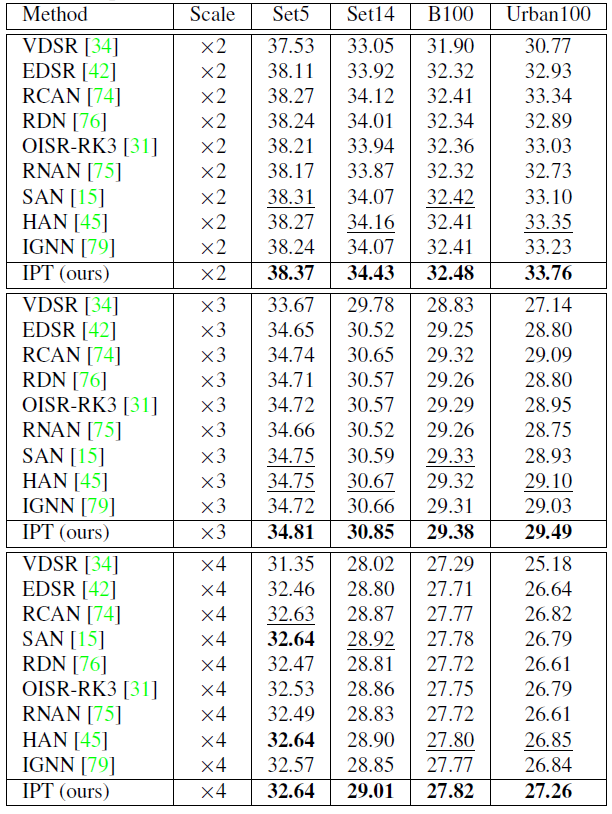
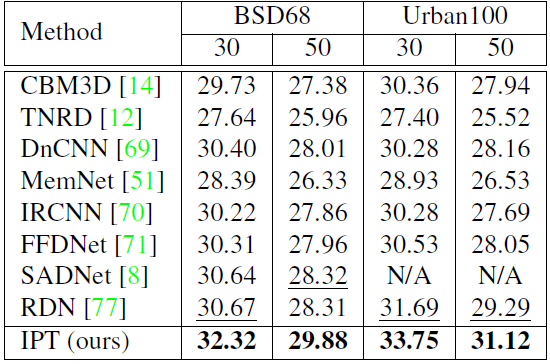
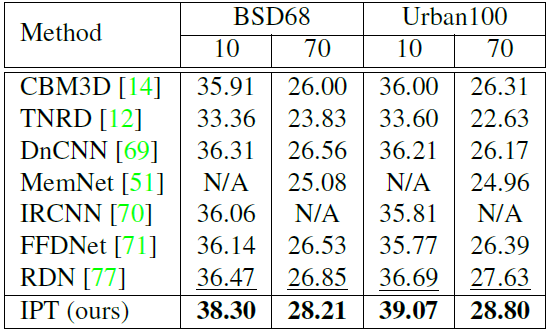
作為自然語言處理領(lǐng)域的主流模型,Transformer 近期頻頻出現(xiàn)在計(jì)算機(jī)視覺領(lǐng)域的研究中。例如 OpenAI 的 iGPT、Facebook 提出的 DETR 等,這些跨界模型多應(yīng)用于圖像識(shí)別、目標(biāo)檢測(cè)等高層視覺任務(wù)。而華為、北大、悉大以及鵬城實(shí)驗(yàn)室近期提出了一種新型預(yù)訓(xùn)練 Transformer 模型——IPT(Image Processing Transformer),用于完成超分辨率、去噪、去雨等底層視覺任務(wù)。該研究認(rèn)為輸入和輸出維度相同的底層視覺任務(wù)更適合 Transformer 處理。








評(píng)論
圖片
表情