
2022年,預(yù)訓(xùn)練何去何從?
?作者?|?李政?
研究方向?|?自然語言處理?
來源?|?PaperWeekly

大規(guī)模預(yù)訓(xùn)練
如何解釋預(yù)訓(xùn)練模型的理論基礎(chǔ)(如大模型智能的參數(shù)規(guī)模極限存在嗎) 如何將大模型高效、低成本的應(yīng)用于實(shí)際系統(tǒng) 如何克服構(gòu)建大模型的數(shù)據(jù)質(zhì)量、訓(xùn)練效率、算力消耗、模型交付等諸多障礙 如何解決目前大部分大模型普遍缺乏認(rèn)知能力的問題

對(duì)比學(xué)習(xí)
數(shù)據(jù)增強(qiáng)生成正例的變化有限 隨機(jī)搭配成負(fù)例,含有除正例組合外其他組合全部為 0 的誘導(dǎo) 0,1 標(biāo)簽的賦予太過絕對(duì),對(duì)相似性表述不夠準(zhǔn)確
score(X,X^{'})?>>?score(X,Y)
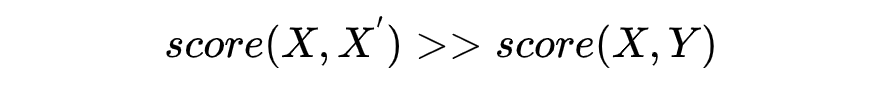
loss?=?-log?\frac{exp(score(X,X^{'}))}{score(X,X^{'})+\sum_{i=1}^{N}score(X,Y_i)}
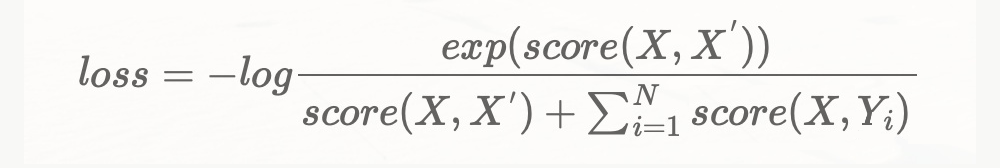

Prompt
x^{'}=f_{prompt}(x)

y?=?f(x^{'})
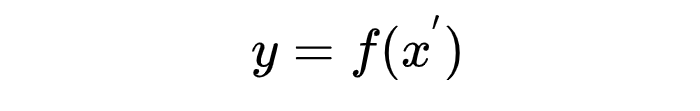

展望未來
太陽有幾只眼睛?
姚明與奧尼爾身高誰比較高?
貓咪可以吃生蛋黃嗎?貓咪是可以吃蛋黃的。這里特定煮熟的白水蛋,貓咪不能吃生雞蛋,因?yàn)樯u蛋中有細(xì)菌。
物質(zhì)都是由分子構(gòu)成的嗎?物質(zhì)都是由分子構(gòu)成的,分子又由原子構(gòu)成-錯(cuò)的!因?yàn)橛行┪镔|(zhì)是不含分子的。
大模型一方面在不少問題上取得了以往難以預(yù)期的成功,另一方面其巨大的訓(xùn)練能耗和碳排放是不能忽視的問題。個(gè)人以為,大模型未來會(huì)在一些事關(guān)國(guó)計(jì)民生的重大任務(wù)上發(fā)揮作用,而在其他一些場(chǎng)景下或許會(huì)通過類似集成學(xué)習(xí)的手段來利用小模型,尤其是通過很少量訓(xùn)練來 “復(fù)用” 和集成已有的小模型來達(dá)到不錯(cuò)的性能。
我們提出了一個(gè)叫做 “學(xué)件” 的思路,目前在做一些這方面的探索。大致思想是,假設(shè)很多人已經(jīng)做了模型并且樂意放到某個(gè)市場(chǎng)去共享,市場(chǎng)通過建立規(guī)約來組織和管理學(xué)件,以后的人再做新應(yīng)用時(shí),就可以不用從頭收集數(shù)據(jù)訓(xùn)練模型,可以先利用規(guī)約去市場(chǎng)里找找看是否有比較接近需求的模型,然后拿回家用自己的數(shù)據(jù)稍微打磨就能用。這其中還有一些技術(shù)挑戰(zhàn)需要解決,我們正在研究這個(gè)方向。
另一方面,有可能通過利用人類的常識(shí)和專業(yè)領(lǐng)域知識(shí),使模型得以精簡(jiǎn),這就要結(jié)合邏輯推理和機(jī)器學(xué)習(xí)。邏輯推理比較善于利用人類知識(shí),機(jī)器學(xué)習(xí)比較善于利用數(shù)據(jù)事實(shí),如何對(duì)兩者進(jìn)行有機(jī)結(jié)合一直是人工智能中的重大挑戰(zhàn)問題。麻煩的是邏輯推理是嚴(yán)密的基于數(shù)理邏輯的 “從一般到特殊”的演繹過程,機(jī)器學(xué)習(xí)是不那么嚴(yán)密的概率近似正確的 “從特殊到一般”的歸納過程,在方法論上就非常不一樣。已經(jīng)有的探索大體上是以其中某一方為倚重,引入另一方的某些成分,我們最近在探索雙方相對(duì)均衡互促利用的方式。

回顧自身算法經(jīng)歷
5.1 需求分析
業(yè)務(wù)屬于什么樣的任務(wù)
算法需要側(cè)重的方向
訓(xùn)練數(shù)據(jù)及線上數(shù)據(jù)的情況
線上的指標(biāo)
線下的評(píng)估方式
……
5.2 模型選型及設(shè)計(jì)
5.3 數(shù)據(jù)分析
數(shù)據(jù)是否存在噪聲:標(biāo)點(diǎn)、大小寫、特殊符號(hào)等 訓(xùn)練集測(cè)試集分布是否存在差異,測(cè)試集能否反映模型在具體業(yè)務(wù)下的表現(xiàn) 數(shù)據(jù)存在哪些特征,通過引入額外的特征,模型可以表現(xiàn)地更好 訓(xùn)練集分布:標(biāo)簽分布、長(zhǎng)度分布等,是否會(huì)給模型帶來類別不均衡、長(zhǎng)文本等問題 數(shù)據(jù)量大小,數(shù)據(jù)量足夠時(shí)可以繼續(xù)預(yù)訓(xùn)練
5.4 模型訓(xùn)練及優(yōu)化
設(shè)置合適的超參數(shù)【可以通過一些超參數(shù)搜索算法】
選擇合適的優(yōu)化器【adam/adamw/sgd】
學(xué)習(xí)率調(diào)整的策略
對(duì)抗訓(xùn)練 對(duì)比學(xué)習(xí) UDA等數(shù)據(jù)增強(qiáng)方式 繼續(xù)預(yù)訓(xùn)練 多任務(wù)學(xué)習(xí) 偽標(biāo)簽 SWA ……
5.5 分析負(fù)例
5.5.1 檢查數(shù)據(jù)質(zhì)量是否過差
5.5.2 根據(jù)指標(biāo)進(jìn)行分析
recall低
???????
召回率表示召回的數(shù)量,測(cè)試集數(shù)據(jù)未召回較多,則從下列角度檢查數(shù)據(jù):
訓(xùn)練集測(cè)試集數(shù)據(jù)差異是否較大,即訓(xùn)練集中是否存在類似數(shù)據(jù),若不存在則引入更多數(shù)據(jù)或者對(duì)該數(shù)據(jù)進(jìn)行數(shù)據(jù)增強(qiáng)。這種情況,常見原因?yàn)閿?shù)據(jù)分布不均衡-少數(shù)數(shù)據(jù)訓(xùn)練不充分;訓(xùn)練集、測(cè)試集分布差異較大導(dǎo)致。 訓(xùn)練集中存在類似數(shù)據(jù),檢查訓(xùn)練集中該種情況有無標(biāo)注錯(cuò)誤:漏標(biāo)、錯(cuò)標(biāo)。
precision低
檢查數(shù)據(jù)分布,是否數(shù)據(jù)分布不均衡。數(shù)據(jù)不均衡導(dǎo)致模型傾向于預(yù)測(cè)數(shù)量較多的數(shù)據(jù),精確率下降。
標(biāo)簽定義是否準(zhǔn)確,是否存在兩類標(biāo)簽混淆的情況。這種情況,需要考慮對(duì)標(biāo)簽進(jìn)行融合。
數(shù)據(jù)增強(qiáng)
resample
reweight
集成學(xué)習(xí)
交叉驗(yàn)證
置信學(xué)習(xí)
聚類分析