
騷氣的 Pandas 取數(shù)操作
本文介紹如何在 Pandas 進(jìn)行 DataFrame 類(lèi)型數(shù)據(jù)的篩選和查看。因?yàn)镻andas中有各種花樣來(lái)進(jìn)行數(shù)據(jù)篩選,本文先介紹其中的一部分。
一、模擬數(shù)據(jù)
本文中各種例子基于一份模擬數(shù)據(jù)展開(kāi),在創(chuàng)建數(shù)據(jù)的時(shí)候引入了部分缺失值,通過(guò) numpy 庫(kù)來(lái)生成:
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name":['小明','小王','張菲','關(guān)宇','孫小小','王建國(guó)','劉蓓'],
"sex":['男','女','女','男','女','男','女'],
"age":[20,23,18,21,25,21,24],
"score":[np.nan,600,550,np.nan,610,580,634], # 缺失兩條數(shù)據(jù)
"address":["廣東省深圳市南山區(qū)",
np.nan, # 數(shù)據(jù)缺失
"湖南省長(zhǎng)沙市雨花區(qū)",
"北京市東城區(qū)",
"廣東省廣州市白云區(qū)",
"湖北省武漢市江夏區(qū)",
"廣東省深圳市龍華區(qū)"]
})
df
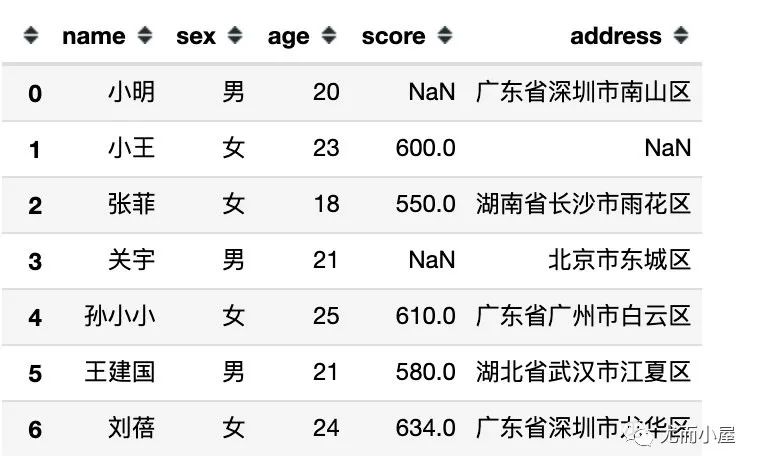
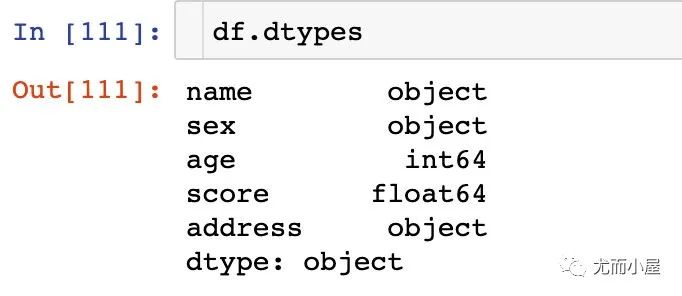
我們查看下各個(gè)字段的數(shù)據(jù)類(lèi)型:3個(gè)字符類(lèi)型,一個(gè)int64,一個(gè)float64類(lèi)型

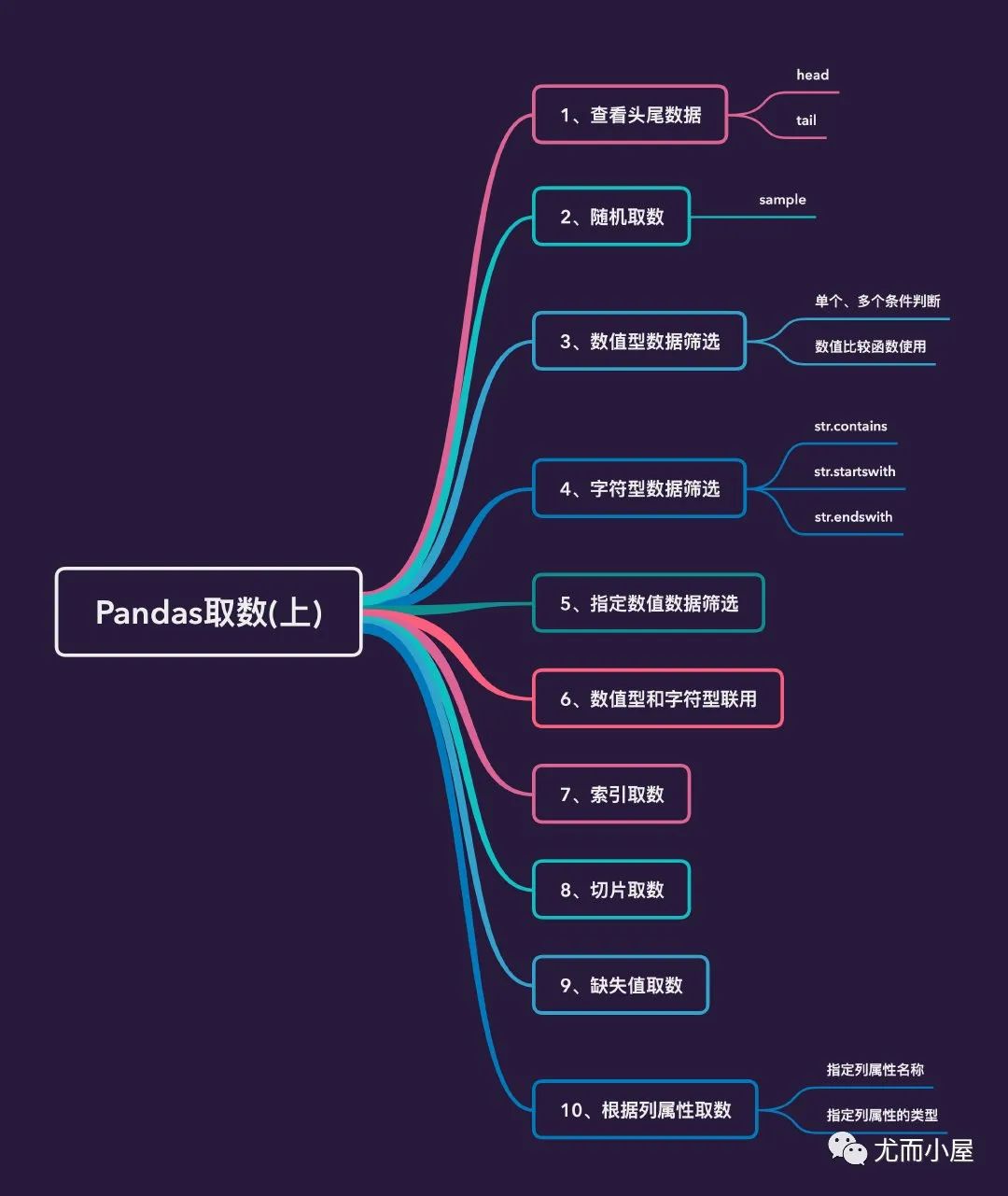
二、思維導(dǎo)圖
下面導(dǎo)圖中介紹的多種基礎(chǔ)的取數(shù)方式:
三、查看頭尾數(shù)據(jù)
查看頭尾數(shù)據(jù),使用的是head和tail方法:
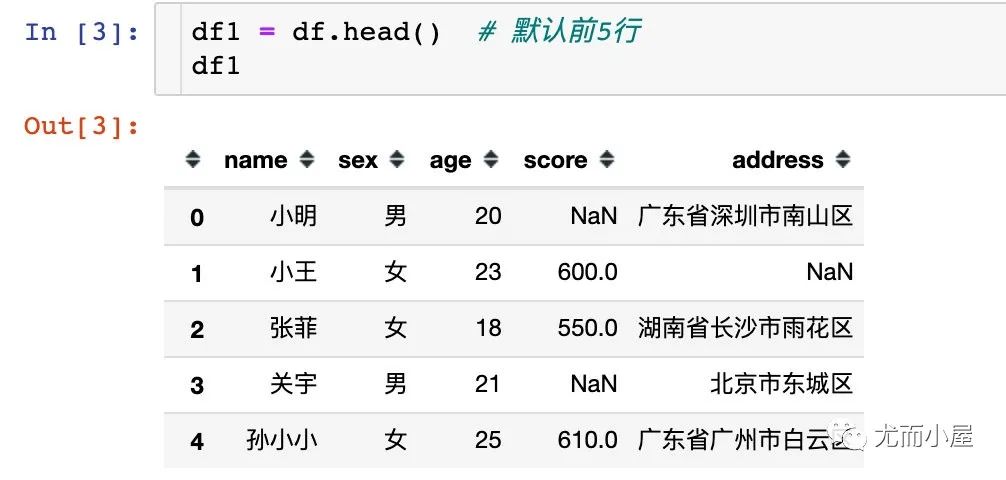
3.1 head
該方法默認(rèn)是前5行
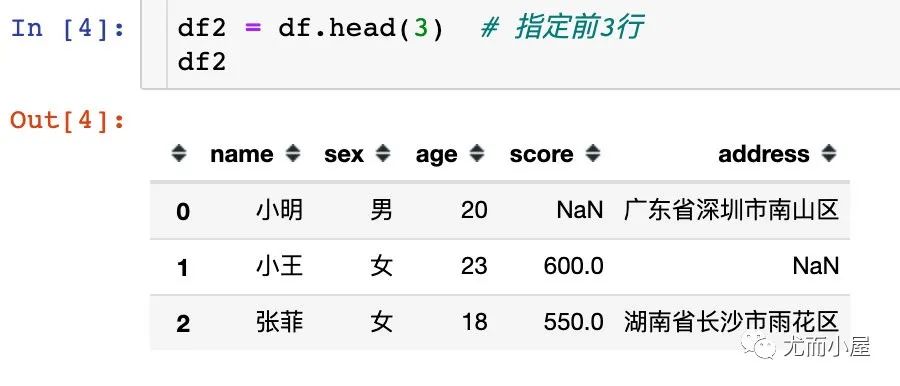
可以自己指定看多少行數(shù)據(jù):
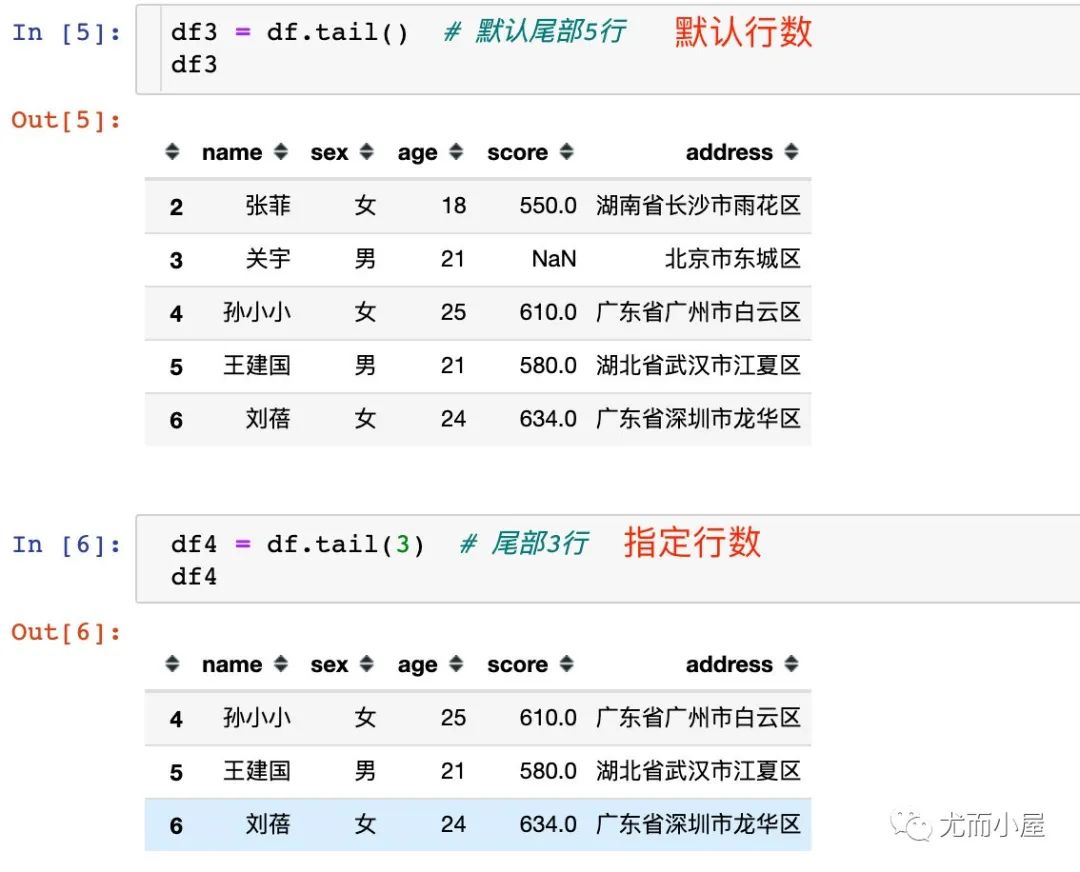
3.2 tail
tail使用方法是類(lèi)似的:
默認(rèn)尾部5行 指定查看行數(shù)
四、隨機(jī)篩選
使用的是sample方法,默認(rèn)是查看一行數(shù)據(jù),也可以指定查看多少行:

五、數(shù)值型數(shù)據(jù)篩選
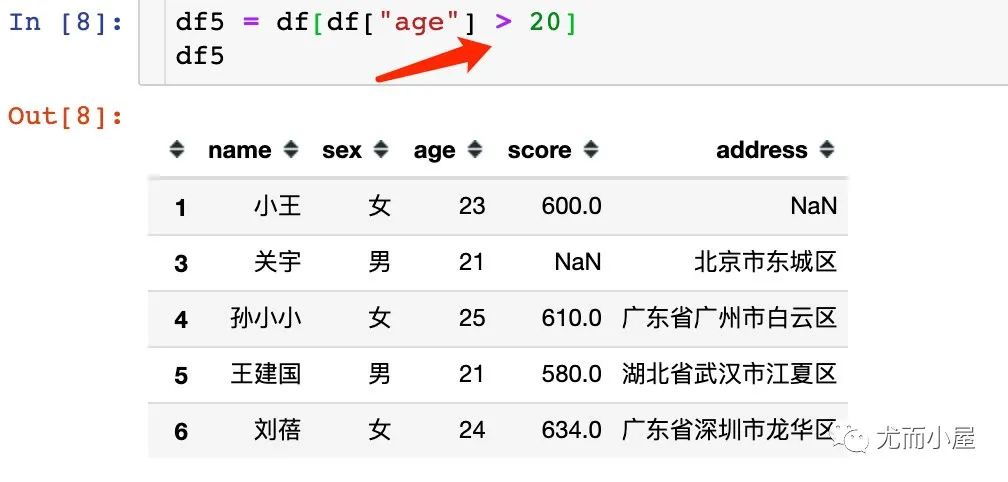
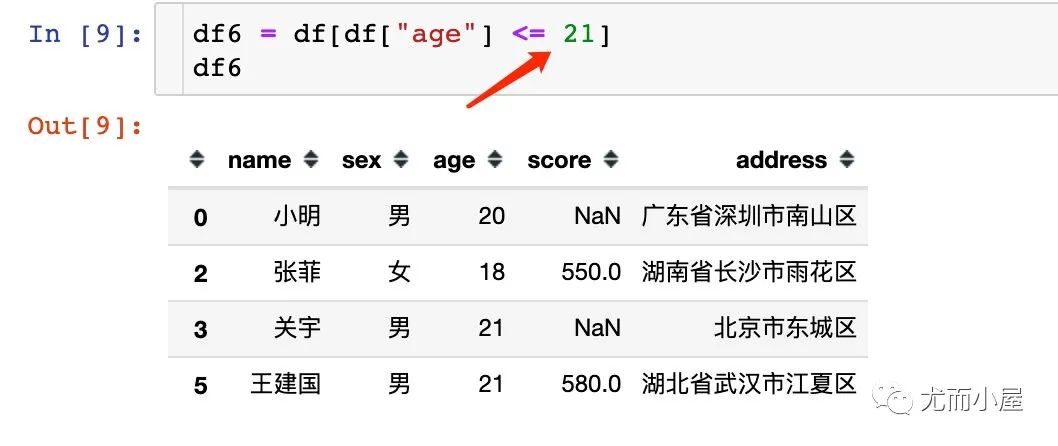
5.1 單個(gè)條件
1、數(shù)值型數(shù)據(jù)的篩選一般是根據(jù)大小比較來(lái)進(jìn)行的:
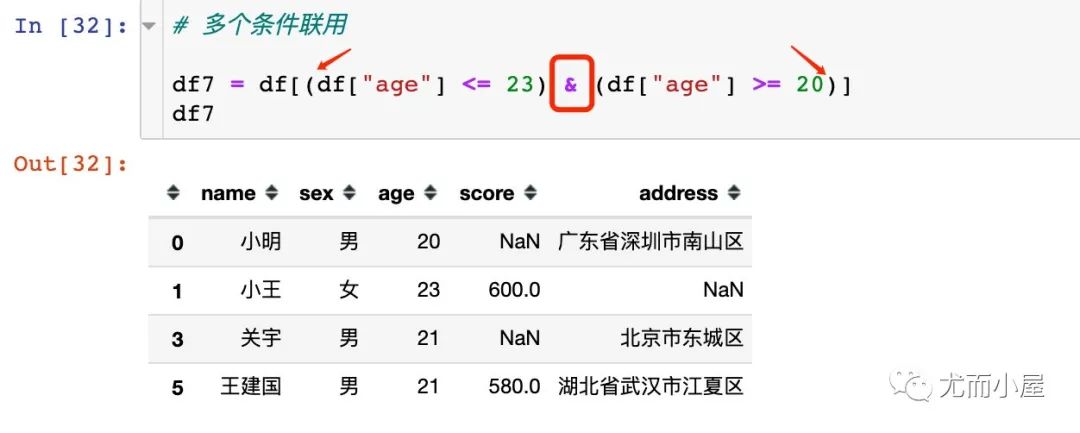
5.2 多個(gè)條件
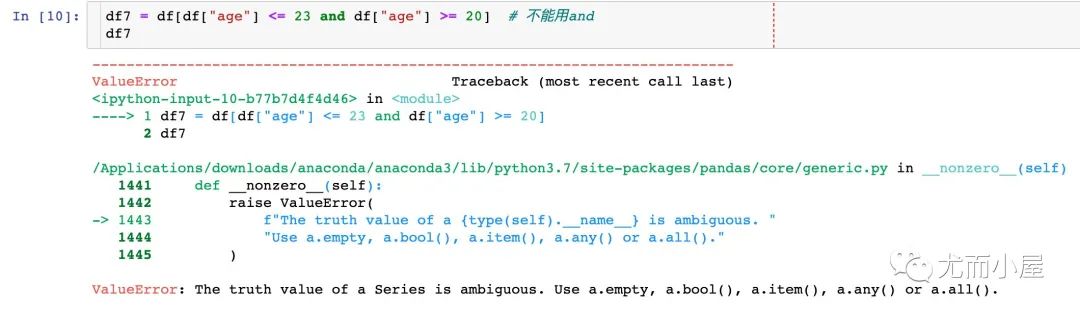
2、當(dāng)我們存在多個(gè)比較條件的時(shí)候,需要注意:
表示“且”不能用and,使用&符號(hào);表示“或”使用用豎線 |每個(gè)條件要使用小括號(hào)
下面是正確的寫(xiě)法:
5.3 使用數(shù)值函數(shù)
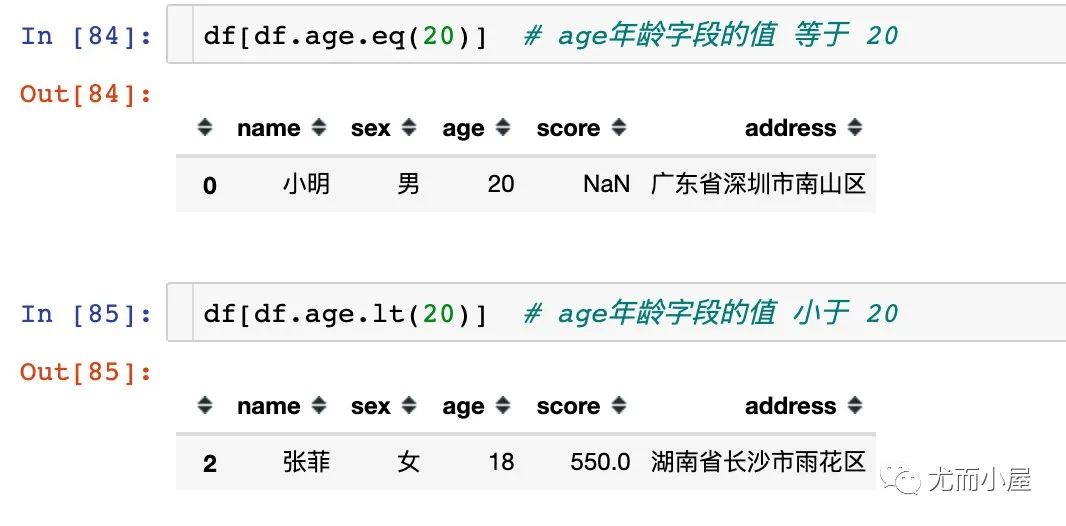
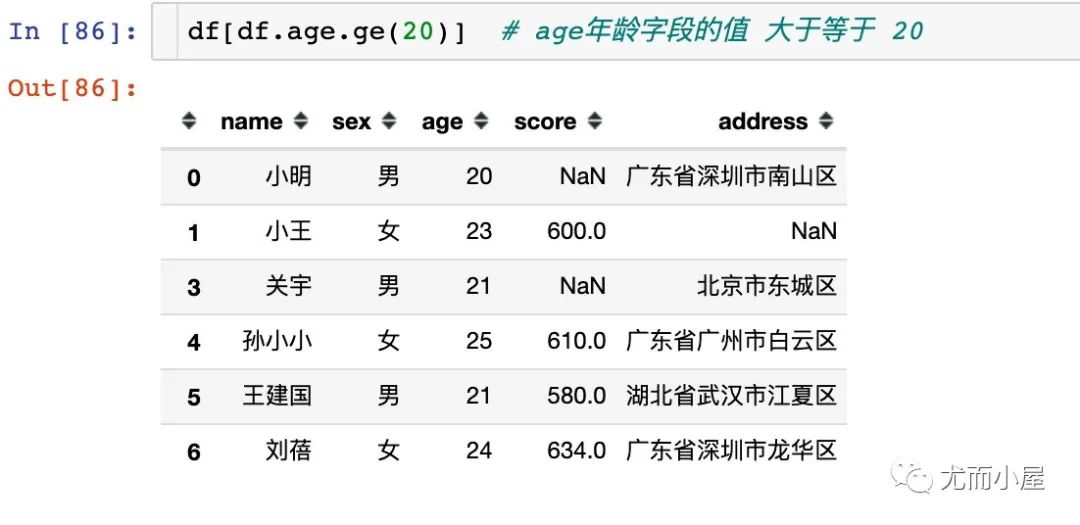
常用的數(shù)值比較函數(shù)如下:
df.eq() # 等于相等 ==
df.ne() # 不等于 !=
df.le() # 小于等于 >=
df.lt() # 小于 <
df.ge() # 大于等于 >=
df.gt() # 大于 >
1、使用單個(gè)數(shù)值函數(shù)篩選
2、使用多個(gè)數(shù)值函數(shù)篩選;

六、字符型數(shù)據(jù)篩選
字符類(lèi)型數(shù)據(jù)的篩選主要是通過(guò)python和pandas中相關(guān)函數(shù);
包含:str.contains 開(kāi)始:str.startswith 結(jié)束:str.endswith
下圖中的3個(gè)例子講解了上面3個(gè)函數(shù)的使用方法:

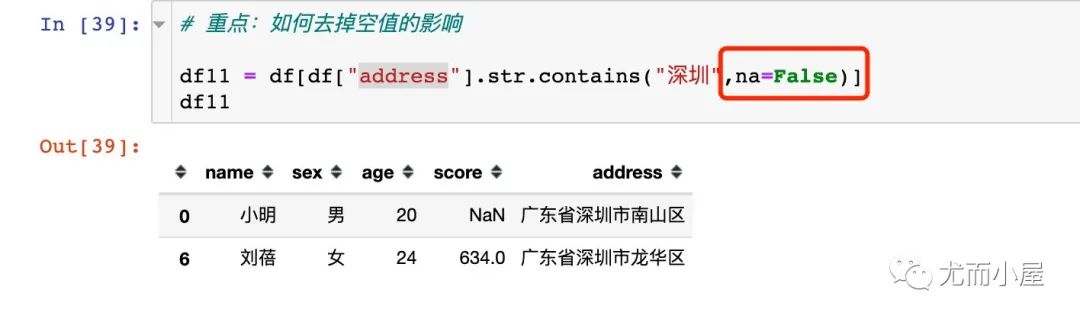
上面的例子中使用的字段本身都是沒(méi)有空值的,如果字段中帶有空值,該如何處理?比如我們想選出address帶有“深圳”的同學(xué):

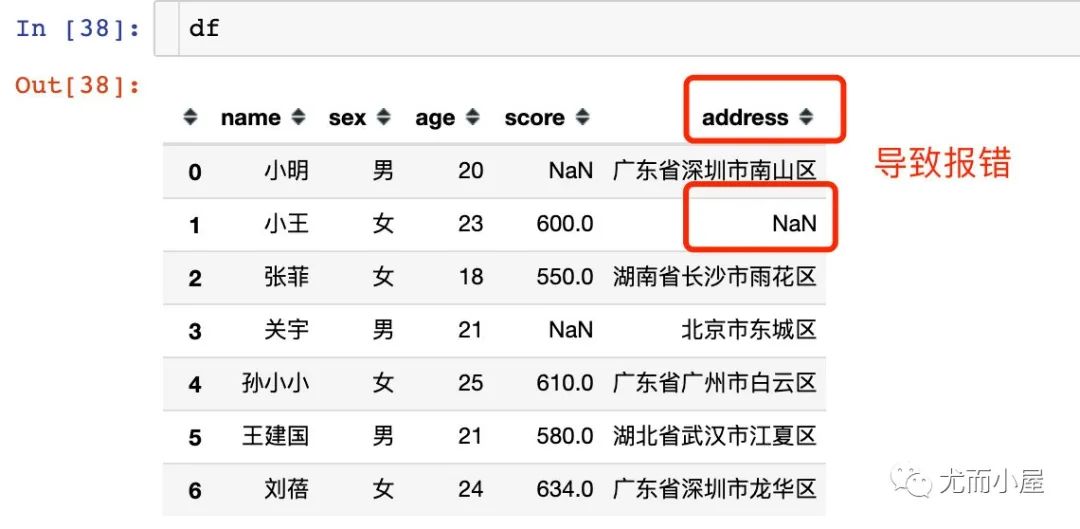
解決方法1:帶上參數(shù)
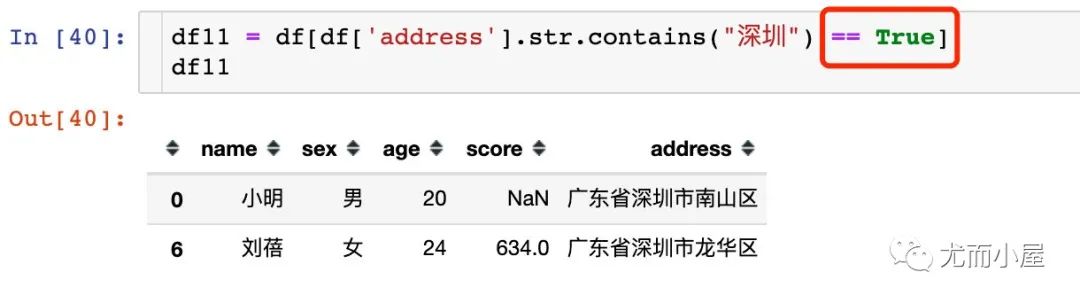
解決方法2:通過(guò)布爾值的比較判斷
七、指定數(shù)據(jù)值篩選
通過(guò)指定某個(gè)字段的具體某個(gè)值來(lái)篩選數(shù)據(jù):

八、數(shù)值型和字符型聯(lián)用
數(shù)值型的大小比較條件和字符相關(guān)條件的聯(lián)合使用:
且:& 或:|
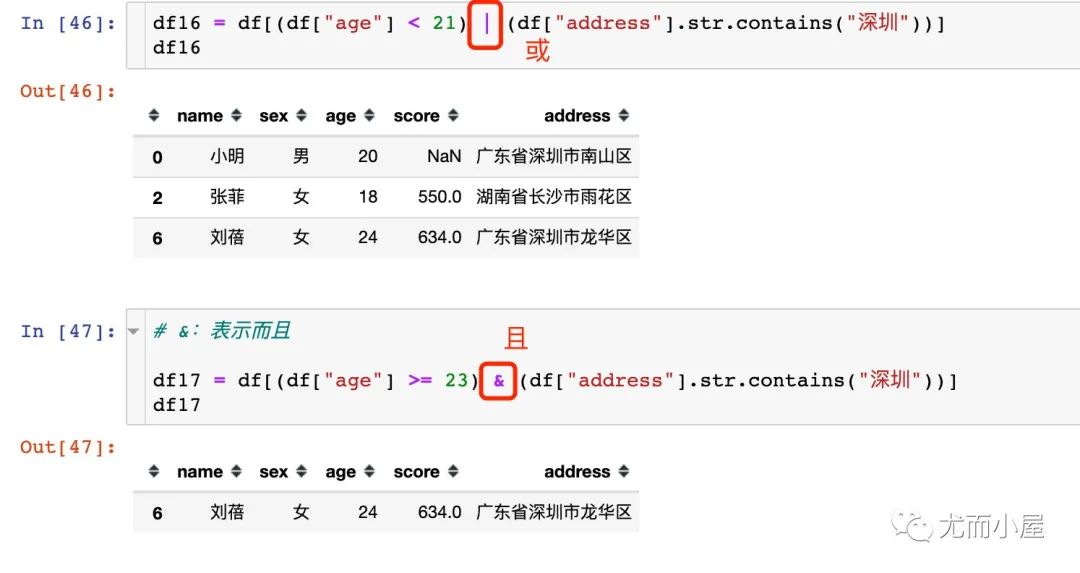
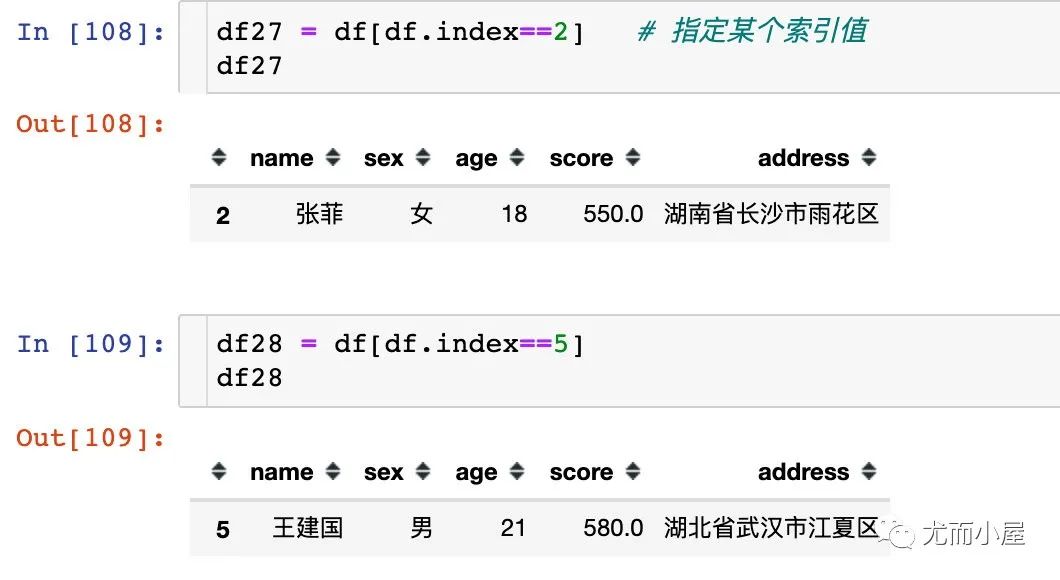
九、索引取數(shù)
直接通過(guò)某個(gè)索引值來(lái)取數(shù),這種情況很少用:
十、切片取數(shù)
pandas中切片取數(shù)和Python中是相同的:
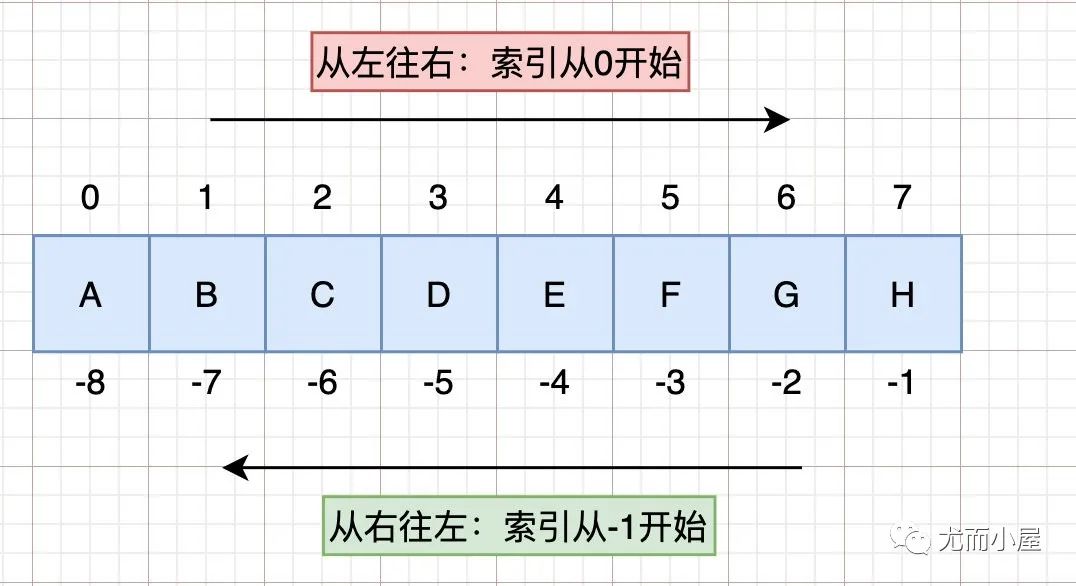
左邊索引從0開(kāi)始計(jì)數(shù),右邊索引從-1開(kāi)始計(jì)數(shù) 切片規(guī)則: start:stop:step,分別表示起始位置start,結(jié)束位置stop,步長(zhǎng)step(可正可負(fù))
不包含結(jié)束索引位置的元素:含頭不含尾,請(qǐng)記住索引切片的重要規(guī)則!!!
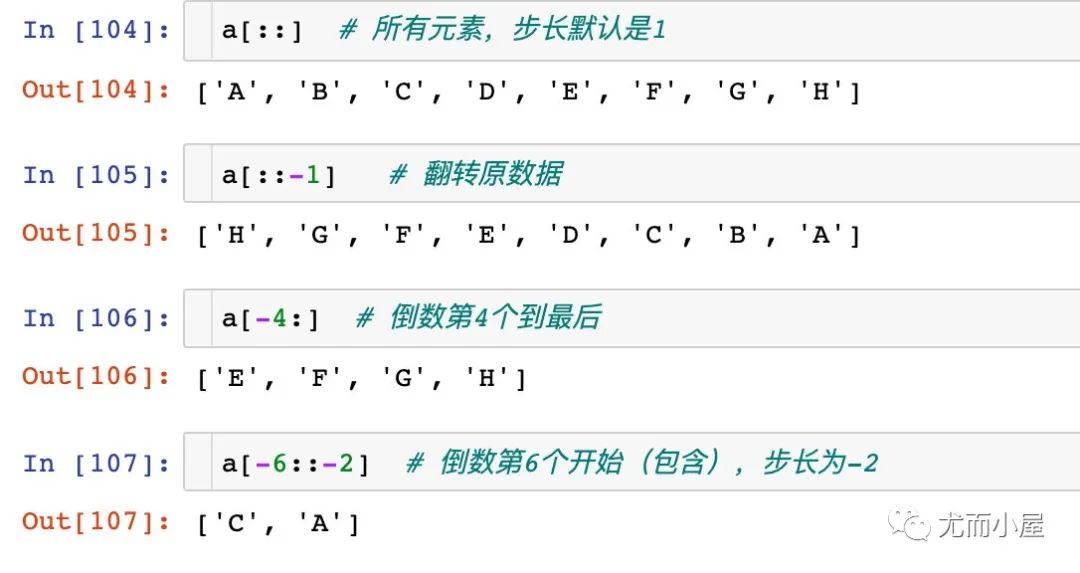
使用切片的單個(gè)數(shù)值取數(shù):

使用切片取數(shù)的多種案例:

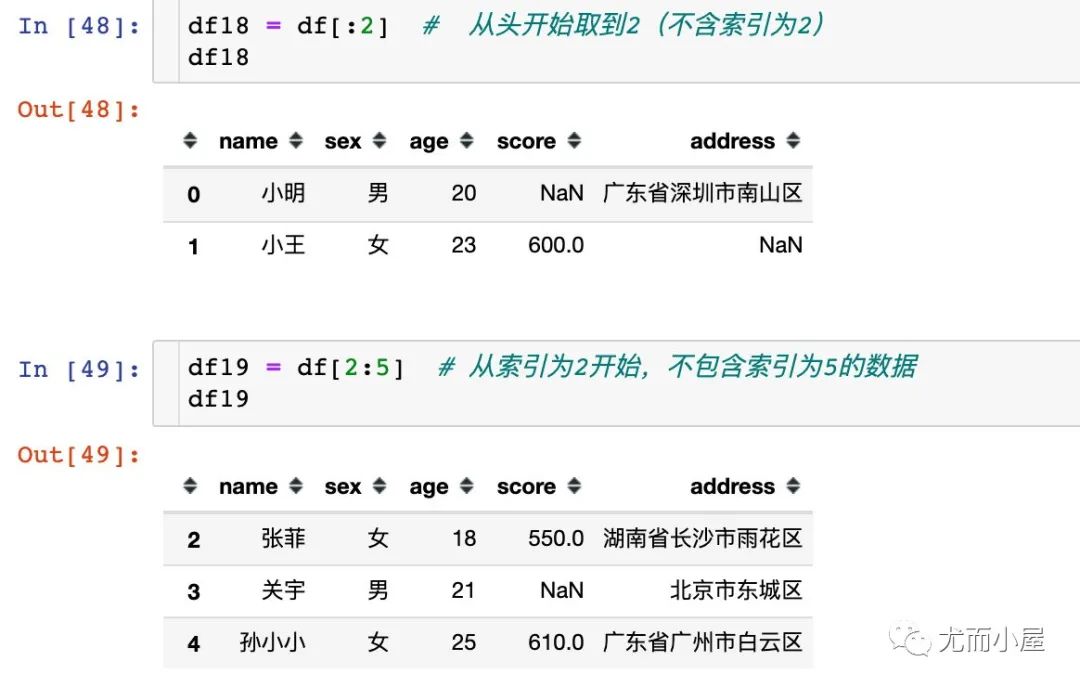
下面看看本文案例中的切片取數(shù):
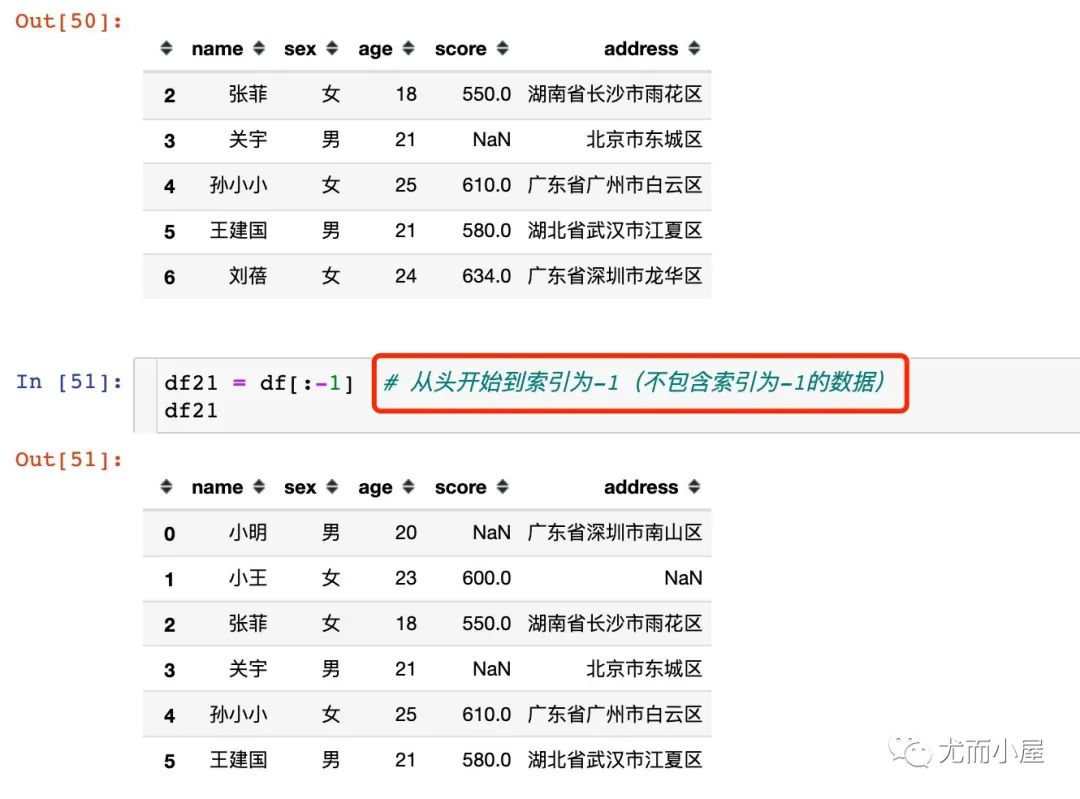
步長(zhǎng)不為1和索引為負(fù)數(shù)的情況:
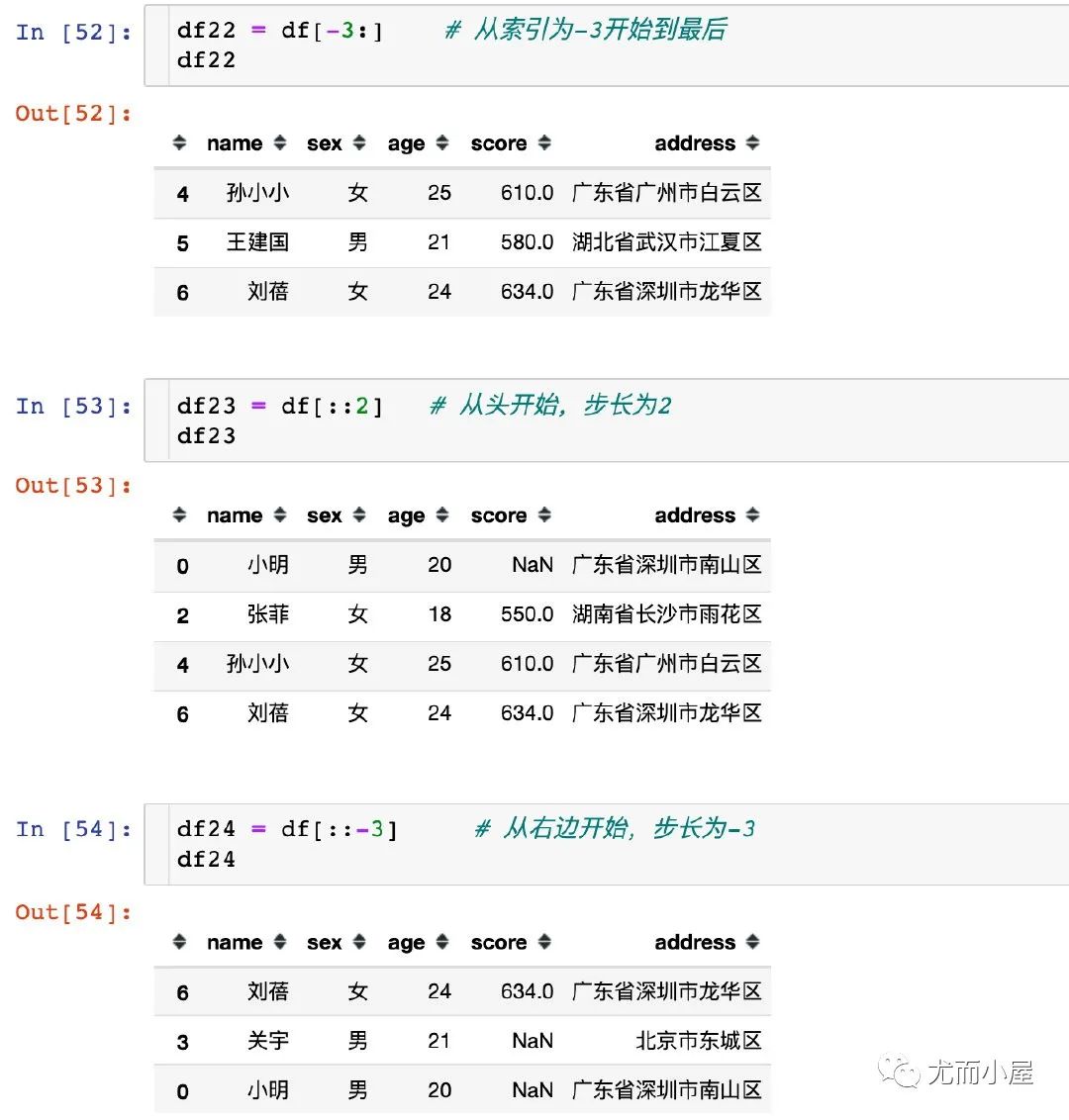
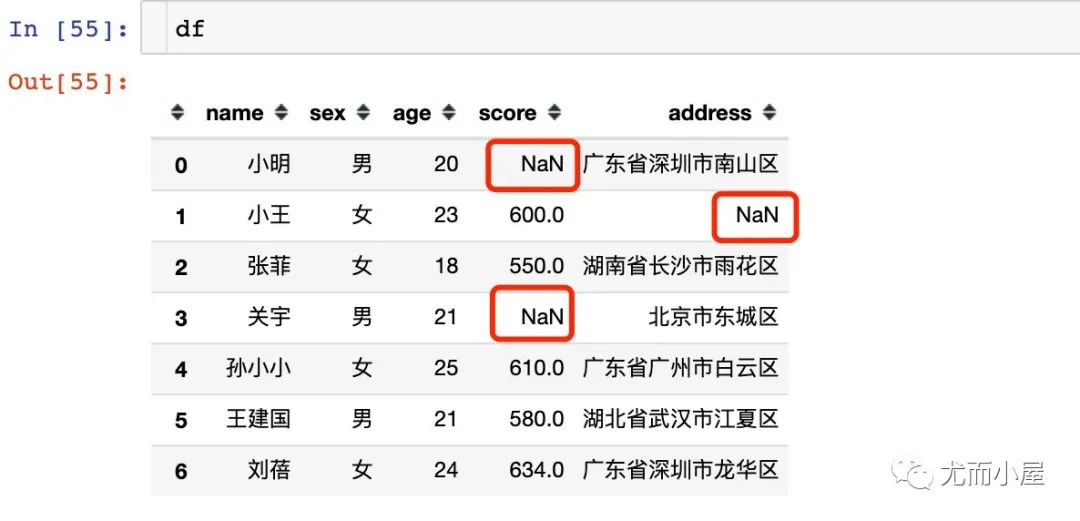
十一、缺失值篩選
本文中使用的案例缺失值情況為:
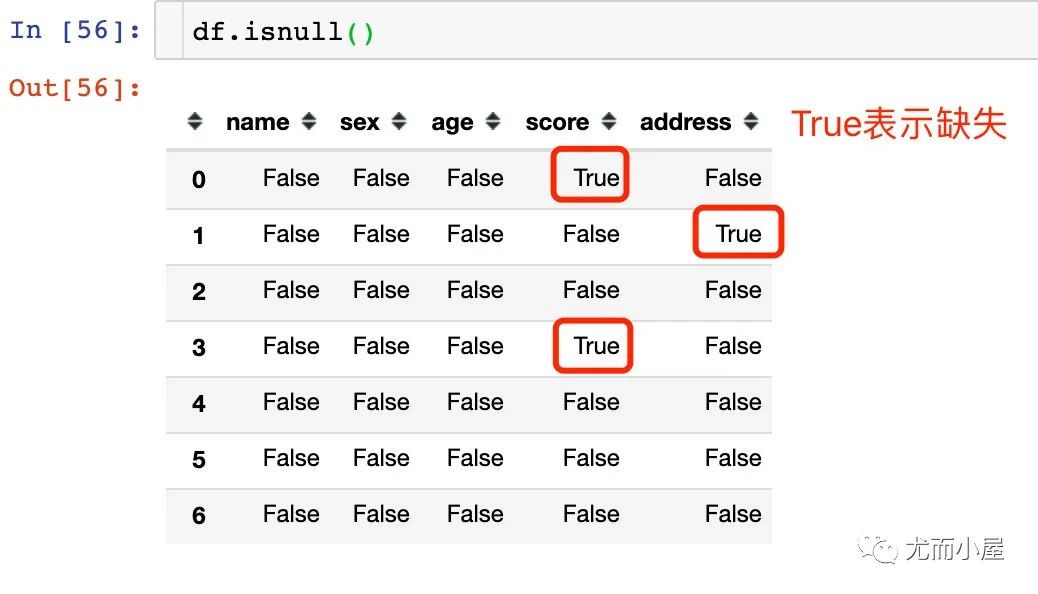
11.1 查看缺失值
df.isnull()
11.2 查看字段缺失值
df25 = df.isnull().any() # 列中是否存在空值
df25

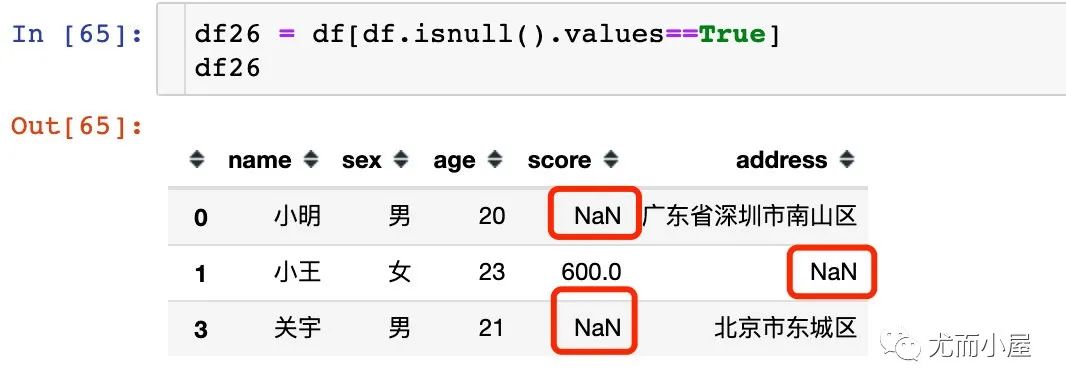
11.3 鎖定缺失值存在的行
df26 = df[df.isnull().values==True]
df26
十二、列屬性取數(shù)
12.1 指定屬性名
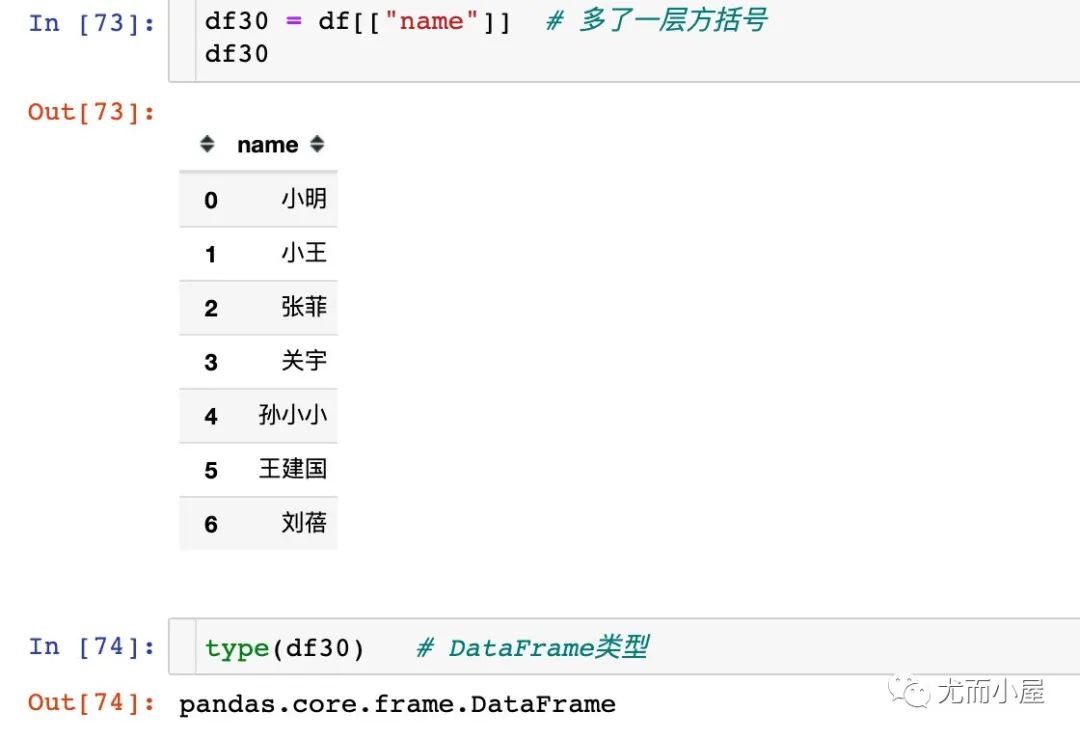
第一種是我們直接指定列屬性的名稱(chēng),在這種情況下取出來(lái)的是Series類(lèi)型數(shù)據(jù)

第二種情況下取出來(lái)的是DataFram e類(lèi)型數(shù)據(jù):

12.2 指定字段屬性的類(lèi)型
本文案例的數(shù)據(jù)字段類(lèi)型為:
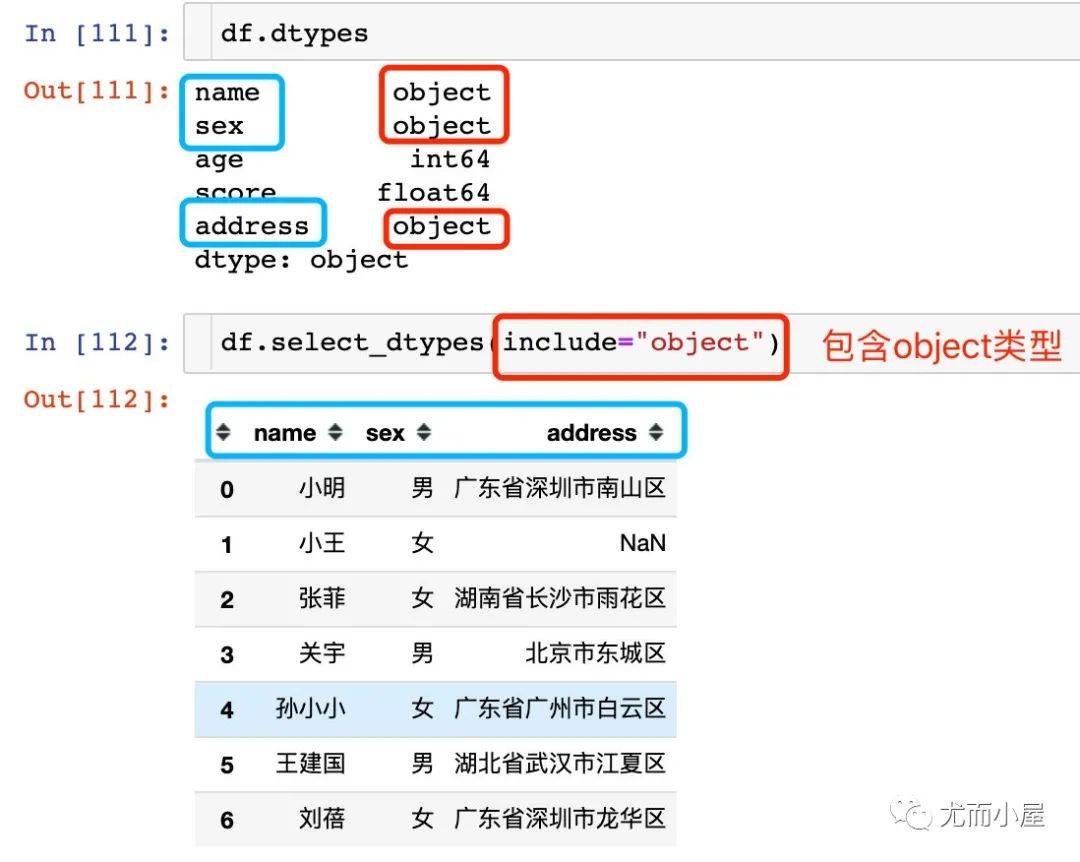
1、取出包含object類(lèi)型的數(shù)據(jù):
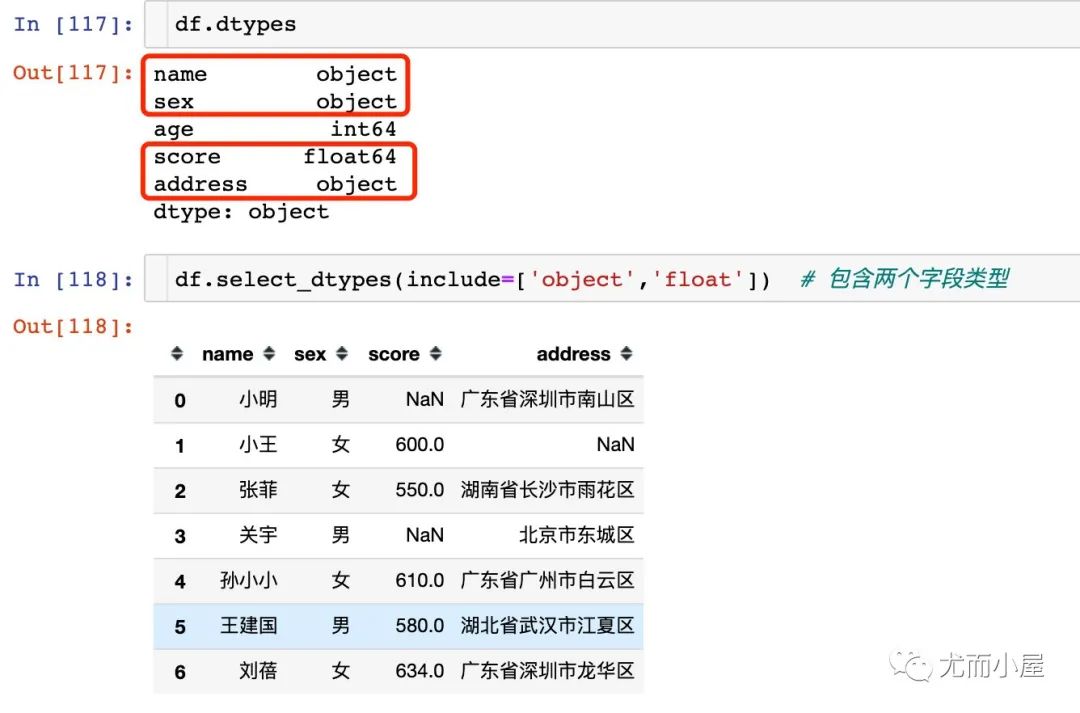
如果是想取出包含多種類(lèi)型的數(shù)據(jù):
2、取出不包含object類(lèi)型的數(shù)據(jù):

十三、總結(jié)
Pandas中取數(shù)的方式真的是五花八門(mén),有很多方式能夠取到我們想要的數(shù)據(jù)。本文中介紹的多種方式算是比較基本,比如頭尾部數(shù)據(jù)、基于條件判斷的篩選、切片篩選等,后續(xù)將會(huì)介紹更多Pandas中取數(shù)技巧,敬請(qǐng)期待!