
玩轉(zhuǎn) Pandas 取數(shù)
DataFrame 數(shù)據(jù)篩選,重點介紹的是 3 對函數(shù)的使用:
iloc 和 loc,最為重要,經(jīng)常使用的一對函數(shù) at 和 iat any 和 all
一、模擬數(shù)據(jù)
本文中模擬了兩份數(shù)據(jù):
第一份的索引為字符類型 第二份的索引使用的是默認(rèn)數(shù)值型
import pandas as pd
import numpy as np
# 第一份模擬數(shù)據(jù) df0
df0 = pd.DataFrame(
[[101, 102, 140], [114, 95, 67], [87, 128, 117]],
index=['語文', '數(shù)學(xué)', '英語'],
columns=['小明', '小紅',"小孫"])
df0

# 第二份模擬數(shù) df
df = pd.DataFrame({
"name":['小明','小王','張菲','關(guān)宇','孫小小','王建國','劉蓓'],
"sex":['男','女','女','男','女','男','女'],
"age":[20,23,18,21,25,21,24],
"score":[np.nan,600,550,np.nan,610,580,634], # 缺失兩條數(shù)據(jù)
"address":[
"廣東省深圳市南山區(qū)",
np.nan, # 數(shù)據(jù)缺失
"湖南省長沙市雨花區(qū)",
"北京市東城區(qū)",
"廣東省廣州市白云區(qū)",
"湖北省武漢市江夏區(qū)",
"廣東省深圳市龍華區(qū)"
]
})
df

二、iloc和loc
iloc 是通過數(shù)值來進(jìn)行篩選,loc 是通過屬性或者行索引名來進(jìn)行篩選
2.1 iloc
直接指定數(shù)值,取出單行記錄
# 1、使用數(shù)值
df1 = df.iloc[1] # 單個數(shù)值取出的行記錄
df1
# 結(jié)果
name 小王
sex 女
age 23
score 600.0
address NaN
Name: 1, dtype: object
使用冒號表示全部
df1 = df.iloc[1,:] # :冒號表示全部
df1
# 結(jié)果
name 小王
sex 女
age 23
score 600.0
address NaN
Name: 1, dtype: object
還可以使用切片來取數(shù):
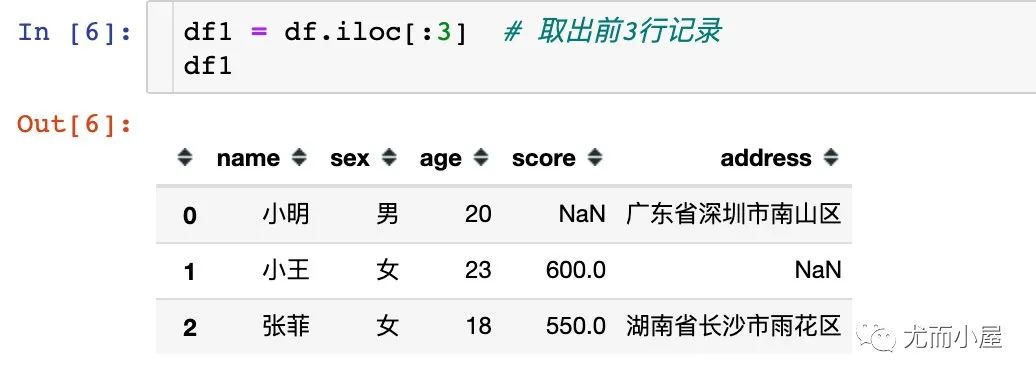
df1 = df.iloc[:3] # 取出前3行記錄
df1
取出非連續(xù)的多行記錄:
df2 = df.iloc[[1,2,4]] # 取出多行記錄
df2
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 張菲 | 女 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
| 4 | 孫小小 | 女 | 25 | 610.0 | 廣東省廣州市白云區(qū) |
# 2、取出行記錄的部分列屬性
df3 = df.iloc[2,0:2]
df3
# 結(jié)果
name 張菲
sex 女
Name: 2, dtype: object
# 列方向上使用切片,步長為2
df4 = df.iloc[2,0:5:2]
df4
# 結(jié)果
name 張菲
age 18
address 湖南省長沙市雨花區(qū)
Name: 2, dtype: object
# 行索引為2,列索引號為1 和 3
df5 = df.iloc[2,[1,3]]
df5
# 結(jié)果
sex 女
score 550.0
Name: 2, dtype: object
# 3、取出具體的值
df6 = df.iloc[2,4]
df6
# 結(jié)果
'湖南省長沙市雨花區(qū)'
在行和列方向上同時使用切片,還可以指定步長:
# 4、行和列方向同時使用切片
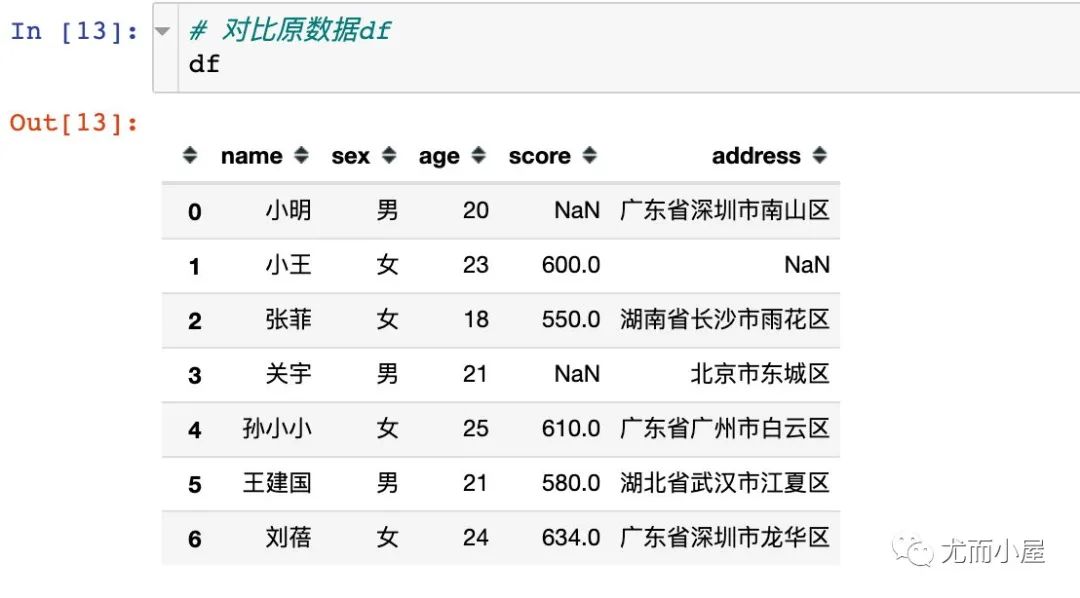
df7 = df.iloc[0:4,0:6:2]
df7

和原數(shù)據(jù)進(jìn)行對比一下:
!!!一個非常有用的方法:np.r_,幫助我們?nèi)〕龇沁B續(xù)的列屬性
# 5、取出不連續(xù)的行列數(shù)據(jù),使用np.r_
df8 = df.iloc[:, np.r_[0,2:4]]
df8
| name | age | score | |
|---|---|---|---|
| 0 | 小明 | 20 | NaN |
| 1 | 小王 | 23 | 600.0 |
| 2 | 張菲 | 18 | 550.0 |
| 3 | 關(guān)宇 | 21 | NaN |
| 4 | 孫小小 | 25 | 610.0 |
| 5 | 王建國 | 21 | 580.0 |
| 6 | 劉蓓 | 24 | 634.0 |
df9 = df.iloc[np.r_[0,2:4],:]
df9
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 0 | 小明 | 男 | 20 | NaN | 廣東省深圳市南山區(qū) |
| 2 | 張菲 | 女 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
| 3 | 關(guān)宇 | 男 | 21 | NaN | 北京市東城區(qū) |
2.2 loc
使用的行索引名或者列屬性直接來取數(shù)
# 1、取出單個列
df10 = df.loc[:,"name"]
df10
0 小明
1 小王
2 張菲
3 關(guān)宇
4 孫小小
5 王建國
6 劉蓓
Name: name, dtype: object
# 2、取出多個列
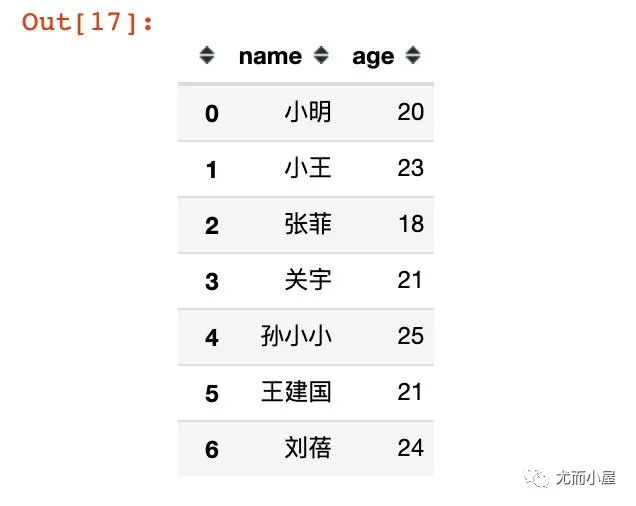
df11 = df.loc[:,["name","age"]]
df11
# 3、使用數(shù)值,取出第一行,索引為0
df12 = df.loc[0]
df12
name 小明
sex 男
age 20
score NaN
address 廣東省深圳市南山區(qū)
Name: 0, dtype: object
# 4、取出索引為0,1,3的行記錄,此時列字段是全部保留
df13 = df.loc[[0,1,3]]
df13

# 使用冒號:,表示全部列,效果同上
df14 = df.loc[[0,1,3],:]
df14

# 5、取出部分行和部分列
df15 = df.loc[[0,1,3],["name","sex","score"]]
df15

# 6、!!!使用索引切片:同時包含起止位置
df16 = df.loc[0:3]
df16

df.loc[:] # 表示所有數(shù)據(jù)

# 7、列篩選的時候,必須有行元素
# 所有行的name和score兩列
df17 = df.loc[:,["name","score"]]
df17
| name | score | |
|---|---|---|
| 0 | 小明 | NaN |
| 1 | 小王 | 600.0 |
| 2 | 張菲 | 550.0 |
| 3 | 關(guān)宇 | NaN |
| 4 | 孫小小 | 610.0 |
| 5 | 王建國 | 580.0 |
| 6 | 劉蓓 | 634.0 |
# 所有行的age及后面全部列
df18 = df.loc[:,"age":]
df18
| age | score | address | |
|---|---|---|---|
| 0 | 20 | NaN | 廣東省深圳市南山區(qū) |
| 1 | 23 | 600.0 | NaN |
| 2 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
| 3 | 21 | NaN | 北京市東城區(qū) |
| 4 | 25 | 610.0 | 廣東省廣州市白云區(qū) |
| 5 | 21 | 580.0 | 湖北省武漢市江夏區(qū) |
| 6 | 24 | 634.0 | 廣東省深圳市龍華區(qū) |
# 8、部分行,age及其后面的全部列
# 謹(jǐn)記:包含起止位置,這是和python切片不同的地方
df19 = df.loc[1:3,"age":]
df19
| age | score | address | |
|---|---|---|---|
| 1 | 23 | 600.0 | NaN |
| 2 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
| 3 | 21 | NaN | 北京市東城區(qū) |
# 9、針對非數(shù)值型行索引的取數(shù)
df20 = df0.loc["語文"]
df20
小明 101
小紅 102
小孫 140
Name: 語文, dtype: int64
# 10、注意兩個方括號取出的是DataFrame數(shù)據(jù),單個括號是Series型數(shù)據(jù)
df0.loc[["語文"]]
| 小明 | 小紅 | 小孫 | |
|---|---|---|---|
| 語文 | 101 | 102 | 140 |
df0.loc[["語文","英語"]]
| 小明 | 小紅 | 小孫 | |
|---|---|---|---|
| 語文 | 101 | 102 | 140 |
| 英語 | 87 | 128 | 117 |
# 11、取出部分行和列數(shù)據(jù)
df21 = df0.loc[["語文","英語"],"小明"]
df21
語文 101
英語 87
Name: 小明, dtype: int64
df0.loc[["語文","英語"],["小明","小孫"]]
| 小明 | 小孫 | |
|---|---|---|
| 語文 | 101 | 140 |
| 英語 | 87 | 117 |
# 12、直接使用行索引名來取數(shù)
df0.loc[["語文","英語"]]
| 小明 | 小紅 | 小孫 | |
|---|---|---|---|
| 語文 | 101 | 102 | 140 |
| 英語 | 87 | 128 | 117 |
2.3 兩者對比
df.loc[[1,2]]
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 張菲 | 女 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
df.iloc[[1,2]]
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 張菲 | 女 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
# 指定我們需要的列屬性名
df.loc[[1,2],["name","score"]]
| name | score | |
|---|---|---|
| 1 | 小王 | 600.0 |
| 2 | 張菲 | 550.0 |
# 取出第1和2行,0和3列
df.iloc[[1,2],np.r_[0,3]]
| name | score | |
|---|---|---|
| 1 | 小王 | 600.0 |
| 2 | 張菲 | 550.0 |
三、at 和 iat
3.1 at
at 函數(shù)類似于 loc,但是 at 函數(shù)取出的僅僅是一個值
df22 = df.at[4,"sex"]
df22
'女'
df.at[2,"name"]
'張菲'
df0
| 小明 | 小紅 | 小孫 | |
|---|---|---|---|
| 語文 | 101 | 102 | 140 |
| 數(shù)學(xué) | 114 | 95 | 67 |
| 英語 | 87 | 128 | 117 |
# 同時指定索引和列名
df23 = df0.at['語文','小孫']
df23
140
# at、loc連用
df.loc[1].at['age']
23
df
| name | sex | age | score | address | |
|---|---|---|---|---|---|
| 0 | 小明 | 男 | 20 | NaN | 廣東省深圳市南山區(qū) |
| 1 | 小王 | 女 | 23 | 600.0 | NaN |
| 2 | 張菲 | 女 | 18 | 550.0 | 湖南省長沙市雨花區(qū) |
| 3 | 關(guān)宇 | 男 | 21 | NaN | 北京市東城區(qū) |
| 4 | 孫小小 | 女 | 25 | 610.0 | 廣東省廣州市白云區(qū) |
| 5 | 王建國 | 男 | 21 | 580.0 | 湖北省武漢市江夏區(qū) |
| 6 | 劉蓓 | 女 | 24 | 634.0 | 廣東省深圳市龍華區(qū) |
# 列名為name的第4個元素
df.name.at[4]
'孫小小'
3.2 iat
和 iloc 一樣,僅僅支持對數(shù)字索引操作
df24 = df.iat[2,4]
df24
'湖南省長沙市雨花區(qū)'
df.loc[2].iat[4]
'湖南省長沙市雨花區(qū)'
df.iloc[2].iat[4]
'湖南省長沙市雨花區(qū)'
四、any 和 all
any:如果至少有一個為 True,則為 True all:需要所有結(jié)果為 True,才會為 True
當(dāng)傳入的 axis=1,會按照行進(jìn)行查詢;axis=0 表示按照列查詢
4.1 在 Series 數(shù)據(jù)的比較
# 兩個 False 通過 any 結(jié)果為 False
pd.Series([False, False]).any() # False
pd.Series([True, False]).any() # True
pd.Series([True, False]).all() # False
# any:是否跳過空值
pd.Series([np.nan]).any() # False
pd.Series([np.nan]).any(skipna=False) # True
# all:是否跳過空值
pd.Series([np.nan]).all() # True
pd.Series([np.nan]).all(skipna=False) #True
4.2 在 DataFrame 的比較
df0
| 小明 | 小紅 | 小孫 | |
|---|---|---|---|
| 語文 | 101 | 102 | 140 |
| 數(shù)學(xué) | 114 | 95 | 67 |
| 英語 | 87 | 128 | 117 |
# 1、取出待查詢的數(shù)據(jù)
df0.loc[:,["小明","小紅"]]
| 小明 | 小紅 | |
|---|---|---|
| 語文 | 101 | 102 |
| 數(shù)學(xué) | 114 | 95 |
| 英語 | 87 | 128 |
# 2、進(jìn)行比較
df0.loc[:,["小明","小紅"]] >= 100
| 小明 | 小紅 | |
|---|---|---|
| 語文 | True | True |
| 數(shù)學(xué) | True | False |
| 英語 | False | True |
any
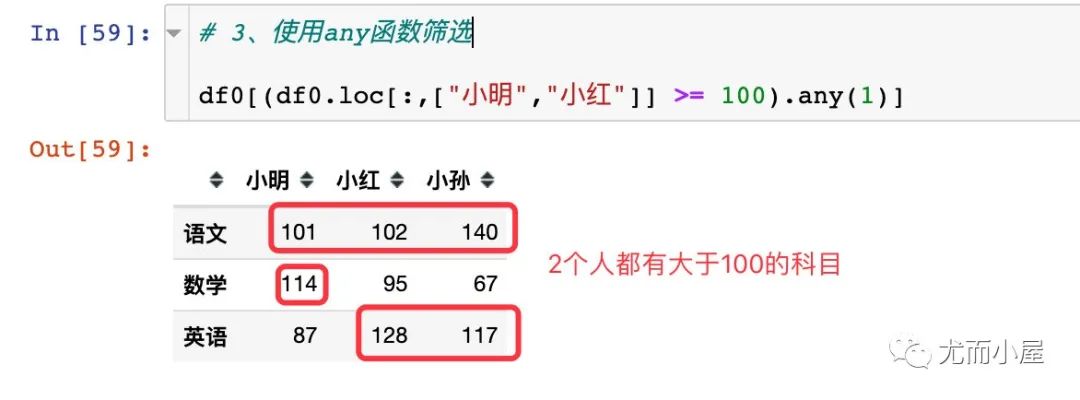
# 3、使用any函數(shù)篩選
df0[(df0.loc[:,["小明","小紅"]] >= 100).any(1)]
all
只有語文同時滿足 3 個人都大于 100
# 4、使用all函數(shù)篩選:只有語文滿足3個人同時大于100
df0[(df0.loc[:,["小明","小紅"]] >= 100).all(1)]

五、總結(jié)
本文通過模擬的數(shù)據(jù)介紹了pandas 的 3 對函數(shù)使用。其中 loc 和 iloc 函數(shù)是十分常用和實用的函數(shù),經(jīng)常會使用。至此,pandas 的數(shù)據(jù)篩選部分已經(jīng)全部介紹完成。
當(dāng)然介紹的方法只是 pandas 豐富取數(shù)技巧中的部分,還有很多的函數(shù)和方法需要讀者自己平時去學(xué)習(xí)和積累,希望介紹的方法對大家有所幫助。
從下一篇文章開始,將會介紹 Pandas 中的各種操作技巧。
評論
圖片
表情