
超越 GLIP! | RegionSpot: 識別一切區(qū)域,多模態(tài)融合的開放世界物體識別新方法
導讀
本文的主題是多模態(tài)融合和圖文理解,文中提出了一種名為RegionSpot的新穎區(qū)域識別架構,旨在解決計算機視覺中的一個關鍵問題:理解無約束圖像中的各個區(qū)域或patch的語義。這在開放世界目標檢測等領域是一個具有挑戰(zhàn)性的任務。
關于這一塊,大家所熟知的大都是基于圖像級別的視覺-語言(ViL)模型(如CLIP),以及使用區(qū)域標簽對的對比模型的訓練等方法。然而,這些方法存在一些問題,包括:
-
計算資源要求高; -
容易受到數(shù)據(jù)噪音的干擾; -
對上下文信息的不足;
為了解決這些問題,作者門提出了RegionSpot,其核心思想是將來自局部基礎模型的位置感知信息與來自ViL模型的語義信息相結合。這種方法的優(yōu)勢在于能夠充分利用預訓練的知識,同時最小化訓練的開銷。此外,文中還介紹了一種輕量級的基于注意力機制的知識集成模塊,以優(yōu)化模型性能。
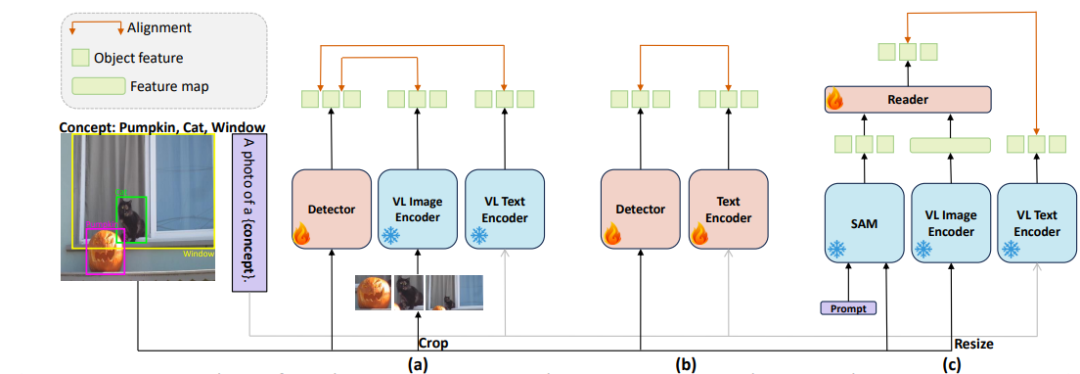
圖1展示了區(qū)域級視覺理解架構:
(a)表示通過從裁剪區(qū)域中提取圖像級 ViL 表示并將其合并到檢測模型中來學習區(qū)域識別模型。
(b)表示使用大量區(qū)域標簽對數(shù)據(jù)集完全微調視覺和文本模型。
(c)表示本文方法,其集成了預訓練(凍結)定位和 ViL 模型,強調學習它們的表征相關性。
通過在開放世界物體識別的背景下進行的大量實驗表明,所提方法相對于以前的方法取得了顯著的性能改進,同時節(jié)省了大量的計算資源。例如,使用8個V100 GPU,僅在一天內便可對300萬數(shù)據(jù)對進行training。最終,該模型在mAP指標上比GLIP還要高出6.5%,尤其是在更具挑戰(zhàn)性和罕見的類別方面,提升高達14.8%!
方法
如上所述,RegionSpot 旨在使用預訓練的ViL模型和局部模型來獲取區(qū)域級別的表示,以實現(xiàn)魯棒的物體概念化,特別是在開放世界的區(qū)域識別中。下面我們?yōu)榇蠹以敿毜亟榻B下。
預備知識
-
Vision-language foundation models:這些模型使用對比學習的技術將視覺和文本數(shù)據(jù)映射到一個共享的嵌入空間,以最小化圖像和其文本描述之間的距離,并最大化無關對之間的距離,例如CLIP和ALIGN。 -
Localization foundation models:這些模型旨在進行圖像的局部理解,特別是在目標檢測和分割任務中。比如Meta開源的SAM模型,它是一個里程碑式的工作,已經在大規(guī)模數(shù)據(jù)集上進行了訓練,包括超過10億自動生成的掩模,以及1100萬張圖像。
使用凍結基礎模型的區(qū)域文本對齊
這一部分我們重點關注下如何獲取位置感知標記和圖像級語義特征,并通過交叉注意力機制進行區(qū)域文本對齊。
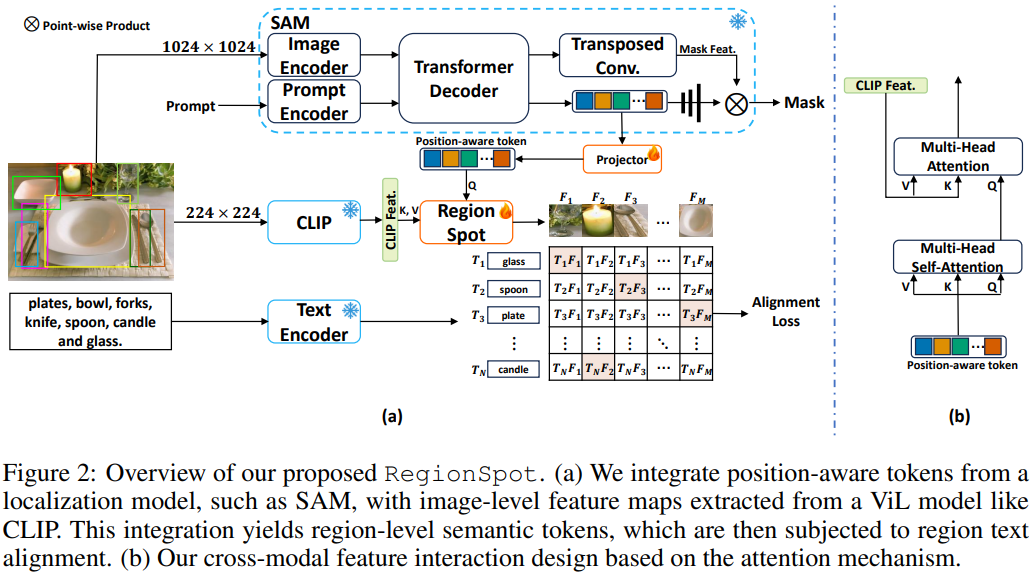
-
區(qū)域級別的位置感知標記:作者使用手動標注的目標邊界框來表示圖像的興趣區(qū)域。對于這些區(qū)域,文中是使用
SAM模型來提取位置感知標記。這些標記通過一個Transformer解碼器生成,這個過程有點像DETR的架構,生成一個稱為“位置感知”的標記,它包含了有關目標的重要信息,包括其紋理和位置。 -
圖像級語義特征圖:一幅圖像可以包含多個對象和多個類別,捕捉了綜合的上下文信息。為了充分利用 ViL 模型,作者將輸入圖像調整到所需的尺寸,然后輸入到 ViL 模型中,獲得圖像級語義特征圖。
-
關聯(lián)位置感知標記和語義特征圖:
RegionSpot中使用了交叉注意力機制來建立區(qū)域級別的位置感知標記和圖像級語義特征圖之間的聯(lián)系。在這個機制中,位置感知標記充當查詢,而語義特征圖充當鍵和值。這種關系可以通過公式表示:
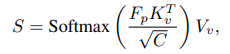
其中
是得分,
是位置感知標記的轉換,
和
是來自
的線性投影,
則是投影特征維度。其實就是常規(guī)的 QKV 操作,可以有效地實現(xiàn)信息融合,至于融合的 gap 可能只有上帝知道。
-
損失函數(shù):最后便是生成文本嵌入,通過處理類別特定的文本和提示模板,例如場景中類別的照片,使用文本編碼器。然后,執(zhí)行每個語義標記和其相應文本特征的點積操作,以計算匹配分數(shù)。這些分數(shù)可以使用 Focal loss進行監(jiān)督。
整體來說,方法部分的核心便是如何從兩個不同的基礎模型中提取信息,并通過交叉注意力機制實現(xiàn)區(qū)域文本對齊,以獲得區(qū)域級別的語義表示。通過下面的實驗部分我們可以直觀感受到該方法在解決開放世界的物體識別問題中表現(xiàn)出色,其提供了豐富的細節(jié)來支持RegionSpot。
實驗
訓練數(shù)據(jù)
RegionSpot 模型采用了多個包含不同類別標簽的數(shù)據(jù)集,以構建強大的訓練環(huán)境。這種靈活的架構允許我們將獨熱標簽(one-hot labels)替換為類別名稱字符串。其中,作者提到了使用了公開可用的檢測數(shù)據(jù)集,總共包括大約300萬張圖像。這些數(shù)據(jù)集包括 Objects 365 (O365)、OpenImages (OI) 和 V3Det (V3D)。

-
Objects 365:大規(guī)模的目標檢測數(shù)據(jù)集,包含了365個不同的對象類別,總共有約66萬張圖像。文中是使用一個經過優(yōu)化的版本,其中包含超過1000萬個邊界框,每張圖像平均約15.8個注釋。 -
OpenImages:這是目前最大的公共對象檢測數(shù)據(jù)集,包括約1460萬個邊界框注釋,每張圖像平均約8個注釋。 -
V3Det:這個數(shù)據(jù)集通過詳細的組織,在類別樹中構建了多達13,029個類別。

基線設置
Benchmark 使用了LVIS檢測數(shù)據(jù)集,該數(shù)據(jù)集包含1203個類別和19809張圖像用于驗證。作者強調不僅僅優(yōu)化在COCO數(shù)據(jù)集上表現(xiàn)的性能,因為COCO只包括Objects365訓練數(shù)據(jù)集中的80個常見類別,這不能充分評估模型在開放世界環(huán)境中的泛化能力。
實現(xiàn)細節(jié)
-
優(yōu)化器: AdamW,初始學習率為2.5 x 10^-5 -
硬件資源:8個GPU上,batchsize 設置為 16 -
超參數(shù):450,000 iters,學習率在350,000次和420,000次迭代時除以10 -
訓練策略: -
第一階段是利用Objects365來啟動區(qū)域-詞對齊的學習; -
第二階段是高級學習,使用來自三個不同的對象檢測數(shù)據(jù)集的豐富信息來進行區(qū)域-詞對齊的學習。
效果

可以看出,相對于 GLIP,RegionSpot 的區(qū)域級語義理解能力更強。
總結
簡單來說,今天介紹的這篇文章主要貢獻是提出了一種有效的多模態(tài)融合方法,用于改進圖像中區(qū)域的語義理解,具有潛在的廣泛應用前景。文中提出了將預訓練的ViL模型與局部模型相結合的 RegionSpot 架構,以改進區(qū)域級別的視覺理解。RegionSpot 的方法旨在優(yōu)化效率和數(shù)據(jù)利用方面具有卓越性,避免了從頭開始訓練的必要。通過大量實驗證明,RegionSpot 在開放世界物體理解領域的性能明顯優(yōu)于 GLIP 等現(xiàn)有方法。
