
如何基于多模態(tài)識(shí)別廣告文章

導(dǎo)語(yǔ)
本文對(duì)看一看中廣告識(shí)別工作進(jìn)行了介紹,從問題定義出發(fā),劃分成文字,圖片以及文章結(jié)構(gòu)等多個(gè)維度來完成對(duì)問題拆解。在文字和圖片部分,分別介紹了如何通過模型有效的對(duì)廣告區(qū)域進(jìn)行識(shí)別和定位。然后是如何融入文章結(jié)構(gòu)特征可視化輸出,最終實(shí)現(xiàn)一個(gè)基于多模態(tài)的廣告文章識(shí)別系統(tǒng)框架。
背景介紹
在微信生態(tài)體系下每天都會(huì)產(chǎn)生大量的文章數(shù)據(jù),個(gè)別垃圾文章?lián)诫s其中。這些垃圾文章如果出現(xiàn)在看一看中會(huì)影響用戶的閱讀體驗(yàn),而廣告文章作為其中一個(gè)占比最大的垃圾子類型值得重點(diǎn)關(guān)注。對(duì)此我們構(gòu)建了一套完整的廣告識(shí)別系統(tǒng)來對(duì)嚴(yán)重廣告垃圾文章進(jìn)行過濾。
問題挑戰(zhàn)
■ 2.1 廣告文章的定義
先來認(rèn)識(shí)一下什么是廣告文章,廣告的類型是多種多樣的,具體可以劃分為以下幾種類型(該分類依據(jù)系統(tǒng)策略,而并非法律或嚴(yán)格意義上的廣告文章):
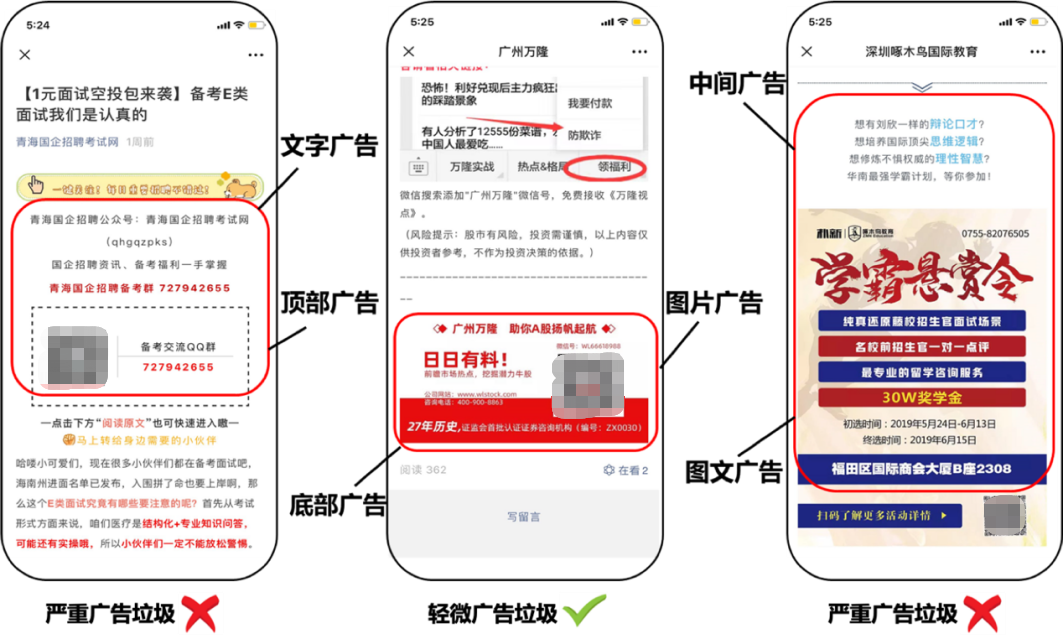
· 多模態(tài),不僅有文字廣告和圖片廣告,還有圖文并茂的圖文廣告。
· 位置不固定,根據(jù)相應(yīng)的位置可以劃分為頂部廣告,中間廣告和底部廣告。不同位置出現(xiàn)的廣告對(duì)用戶閱讀體驗(yàn)影響也存在很大差別,比如對(duì)于頂部廣告,用戶點(diǎn)擊文章后馬上就會(huì)看到,很容易引起反感,而文章出現(xiàn)底部廣告則更容易被接受。
· 廣告區(qū)域占比,如果文章大部分都是廣告我們會(huì)認(rèn)為是主體廣告,與之相反就存在僅由2,3句話組成占比很小的插播廣告。
· 出現(xiàn)次數(shù)不固定,在一篇文章中可能出現(xiàn)多個(gè)廣告區(qū)域,比如同時(shí)出現(xiàn)頂部和底部廣告。
■ 2.2 廣告識(shí)別的挑戰(zhàn)
從業(yè)務(wù)上,首先不僅要識(shí)別廣告文字和廣告圖片,還需要定位廣告區(qū)域的位置。其次并不是文章中出現(xiàn)廣告就需要過濾,還需要考慮整體文章的結(jié)構(gòu)和占比。比如中間這篇文章,它的廣告出現(xiàn)在底部且占比小,對(duì)用戶閱讀體驗(yàn)影響不大是可以放過的。而最右邊這篇文章中間出現(xiàn)了大片圖文廣告屬于嚴(yán)重廣告垃圾需要過濾。
從模型方法上,廣告垃圾文章的識(shí)別顯然是一個(gè)經(jīng)典的多模態(tài)二分類問題,如果直接采用端到端的深度模型就會(huì)產(chǎn)生組合爆炸,而且需要大量的標(biāo)注樣本,最終模型的可解釋性也會(huì)很差,出現(xiàn)問題難以定位。如果是基于規(guī)則策略,雖然比較直觀明了,但是廣告識(shí)別涉及的特征維度眾多,單純規(guī)則難以適應(yīng),后期很難維護(hù)。
廣告識(shí)別系統(tǒng)框架
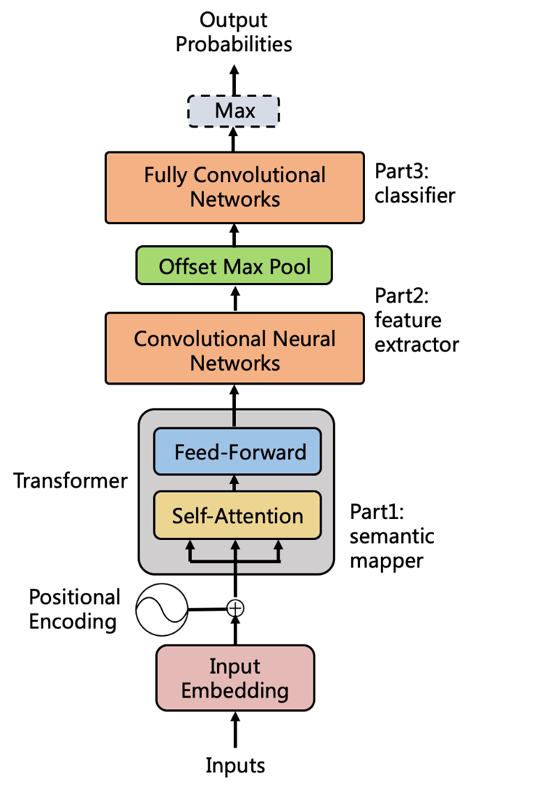
針對(duì)這些問題和挑戰(zhàn),我們構(gòu)建了基于多模態(tài)的文章廣告識(shí)別系統(tǒng),結(jié)合了文本、圖片和文章結(jié)構(gòu)特征,可以有效的綜合多個(gè)角度對(duì)文章中的廣告區(qū)域進(jìn)行細(xì)粒度的刻畫,并且支持相應(yīng)的可視化展示,從而實(shí)現(xiàn)對(duì)嚴(yán)重廣告垃圾文章過濾。它的主體思想就是首先通過廣告文字檢測(cè)模型和廣告圖片識(shí)別模型完成對(duì)廣告區(qū)域的識(shí)別和定位,然后再結(jié)合文章結(jié)構(gòu)特征通過廣告文章序列模型進(jìn)行整體判斷。具體框架如下圖所示,下面分三個(gè)部分來分別闡述:
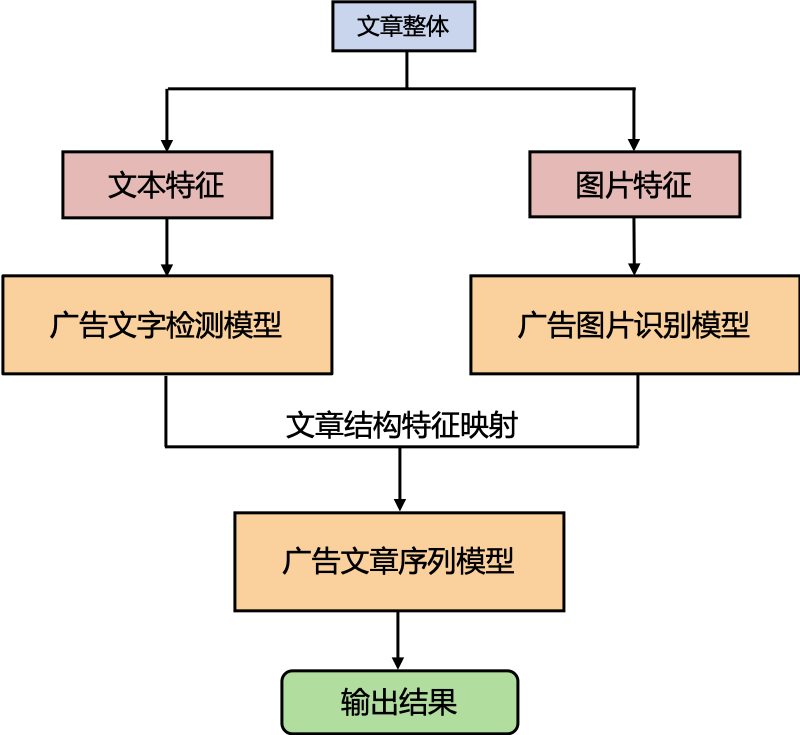
廣告識(shí)別系統(tǒng)整體框架
■ 3.1 廣告文字的檢測(cè)
我們發(fā)現(xiàn)線上問題只有小部分是主體廣告,這類文章的絕大部分都是廣告文字,用一般的文本分類方法就可以很好解決,比如LR+TFIDF。但剩下大部分的問題都是插播廣告。它們平均廣告占比甚至不到全文十分之一,傳統(tǒng)的文本分類方法很難識(shí)別出隱藏在大段正常文本中的小段廣告文字。此外在我們場(chǎng)景下,還需要對(duì)每一段廣告文字進(jìn)行定位。這兩個(gè)任務(wù)綜合在一起就使問題變得更加復(fù)雜。
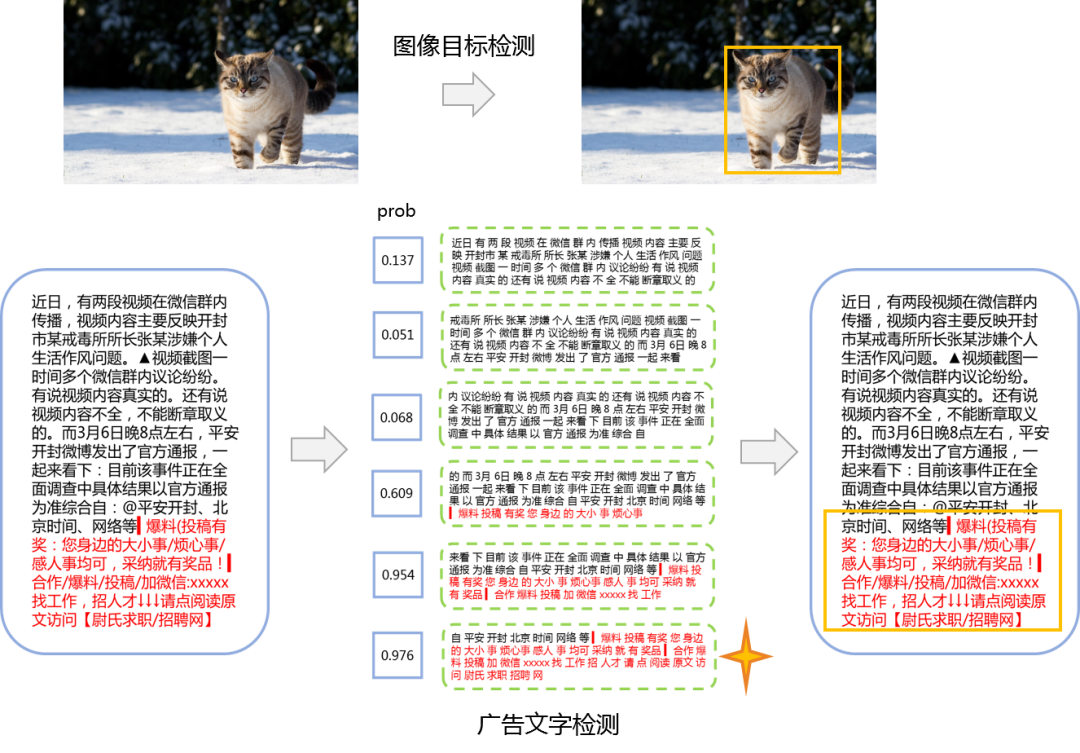
然而我們?nèi)蝿?wù)其實(shí)和圖像中的目標(biāo)檢測(cè)相似,都是需要識(shí)別相應(yīng)的目標(biāo)和它對(duì)應(yīng)的位置,只不過廣告識(shí)別相當(dāng)于從二維變到了一維。受到其中的啟發(fā),我們提出了一個(gè)全新的模型TADL,大體思想是通過滑動(dòng)窗口的檢測(cè)方法將大段文本切分成多個(gè)小片段,并對(duì)每個(gè)小片段進(jìn)行廣告概率打分和反推定位,從而在一個(gè)模型框架內(nèi)同時(shí)實(shí)現(xiàn)了廣告文字的識(shí)別和定位,并且只需要文章級(jí)別的標(biāo)注就能完成訓(xùn)練。具體模型框架如下圖所示,在模型迭代過程中我們主要解決了以下3個(gè)挑戰(zhàn):
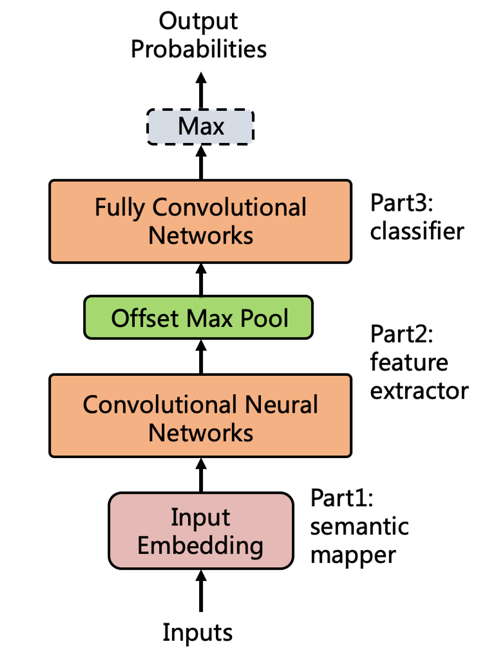
TADL模型
▍挑戰(zhàn)一:如何在文章級(jí)別標(biāo)注下實(shí)現(xiàn)廣告文字檢測(cè)?
(a)局部特征提取:CNN & Offset Max Pool
在模型中我們以CNN為主體架構(gòu),利用CNN強(qiáng)大的局部特征提取能力抓取文章不同區(qū)域下窗口的局部特征,但是傳統(tǒng)cnn的窗口切分方式是固定單一的,而我們的文本片段是連續(xù)的有多種切分方式,所以我們引入了offset max-pool來獲取更多的不同窗口切分方式的組合, 這不僅增強(qiáng)了特征表達(dá),還實(shí)現(xiàn)了相鄰窗口平滑過渡。
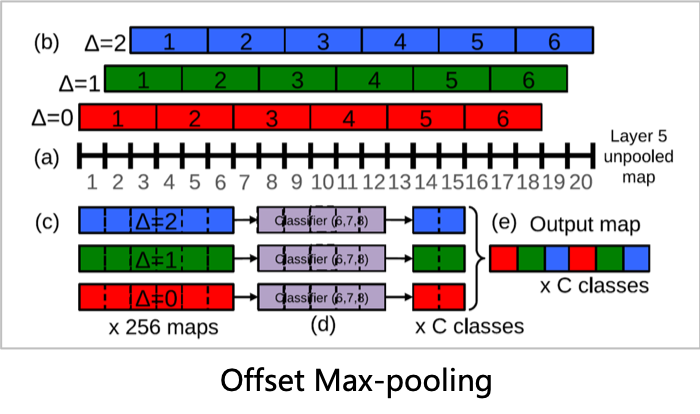
(b)滑動(dòng)窗口檢測(cè):FCN
提取完各個(gè)窗口片段特征后,如果我們使用全鏈接層來對(duì)每個(gè)片段進(jìn)行廣告概率打分,計(jì)算量會(huì)很大,為了簡(jiǎn)化計(jì)算,我們利用CNN共享參數(shù)的機(jī)制將全鏈接層都替換為卷積核為1的全卷積層實(shí)現(xiàn)分類,在這種情況下只需要經(jīng)過一次正向的CNN就能同時(shí)獲得所有片段的概率得分 ,避免了全鏈接層的重復(fù)計(jì)算,同時(shí)使得模型能支持變長(zhǎng)的輸入輸出。
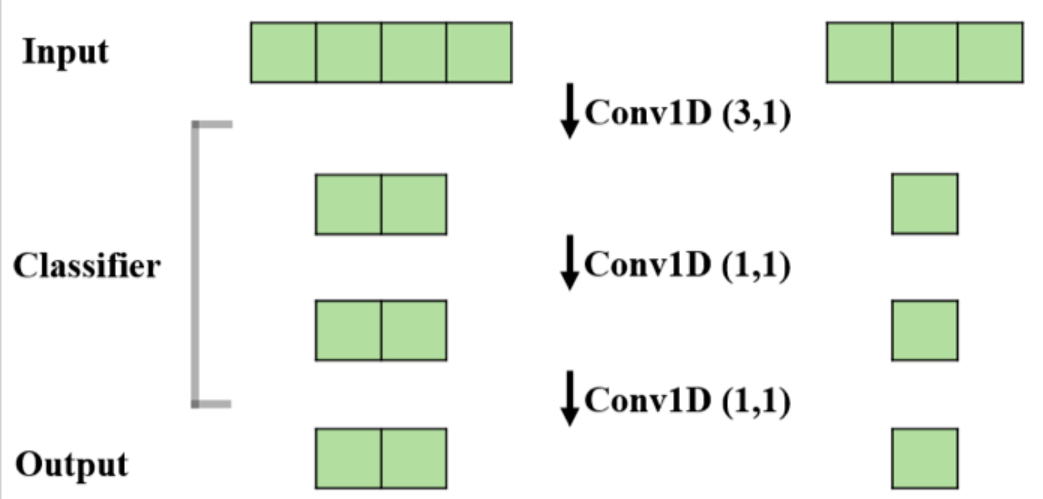
(c)文章級(jí)別輸出:Max
得到所有片段的廣告概率之后,由于標(biāo)注人力的限制 我們不可能去標(biāo)注所有的片段是不是廣告文字,所以在訓(xùn)練的時(shí)候當(dāng)作是文章級(jí)別的二分類任務(wù),通過取max表示文章是否包含廣告文字,模型就能自動(dòng)學(xué)習(xí)對(duì)廣告文字識(shí)別和定位,而在模型使用階段,我們不再做文章級(jí)別的判斷,只需要max之前的各片段的廣告概率即可。
最后,我們可以根據(jù)CNN的參數(shù)反推概率得分在文章中所對(duì)應(yīng)的片段位置。
▍挑戰(zhàn)二:如何平衡局部信息和全局信息到最優(yōu)?
(a)全局信息的引入:Transformer
在分類任務(wù)訓(xùn)練的時(shí)候我們發(fā)現(xiàn)模型的召回很高而精度較低,對(duì)于那種小編推薦類的文章,很容易出現(xiàn)某幾個(gè)關(guān)鍵詞就會(huì)引起誤召回,但從全文來看文章并沒有包含明顯的廣告信息。這是因?yàn)镃NN只關(guān)注了局部信息而忽略了全局信息的作用,但是由于需要從模型計(jì)算的結(jié)果中反推出原始片段的區(qū)域位置,所以在引入全局信息的時(shí)候最好不要打亂原來的輸入和輸出的對(duì)應(yīng)關(guān)系。于是我們選擇從最開始的詞向量中引入全局信息。比如position embedding和tranformer引入都使模型取得顯著提升。值得注意的是如果引入的全局信息過多,就會(huì)使得局部信息作用非常有限,召回就會(huì)降低。具體如下圖所示:
TADL模型全局信息引入
(b)局部信息的調(diào)整
另一方面還可以通過調(diào)整滑動(dòng)窗口大小和步長(zhǎng)來調(diào)節(jié)局部信息的獲取,如果窗口過大,全局信息變多,就難以識(shí)別小段廣告,窗口過小,局部信息則會(huì)過于敏感而引起誤召回。
通過這一系列的參數(shù)調(diào)整使得全局信息和局部信息產(chǎn)生博弈,最終達(dá)到效果最優(yōu)。
▍挑戰(zhàn)三:如何加速優(yōu)化模型并支持超長(zhǎng)文本輸入?
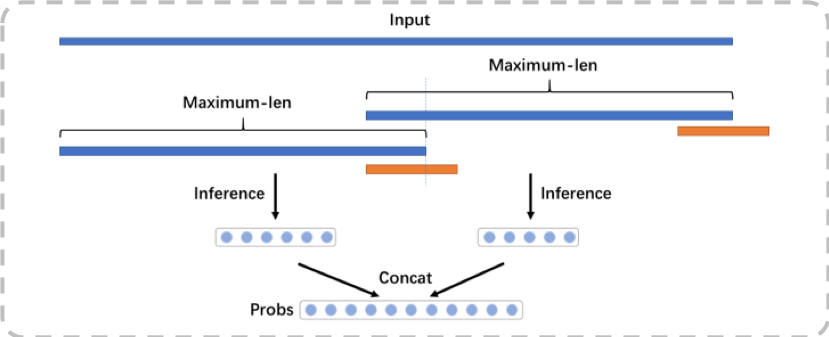
(a)超長(zhǎng)序列預(yù)測(cè):Multiple Segments Inference
Transformer內(nèi)部矩陣的計(jì)算是有長(zhǎng)度限制的,測(cè)試發(fā)現(xiàn)序列輸入超過一定長(zhǎng)度就會(huì)內(nèi)存溢出,而我們文章的輸入長(zhǎng)度range是非常大的,如果直接截?cái)鄷?huì)丟失大量信息。所以在工程上我們也做了很多優(yōu)化,在預(yù)測(cè)的時(shí)候采用了分段預(yù)測(cè)的方法,如下圖所示。通過這個(gè)方法我們的模型可以支持任意長(zhǎng)度的輸入。
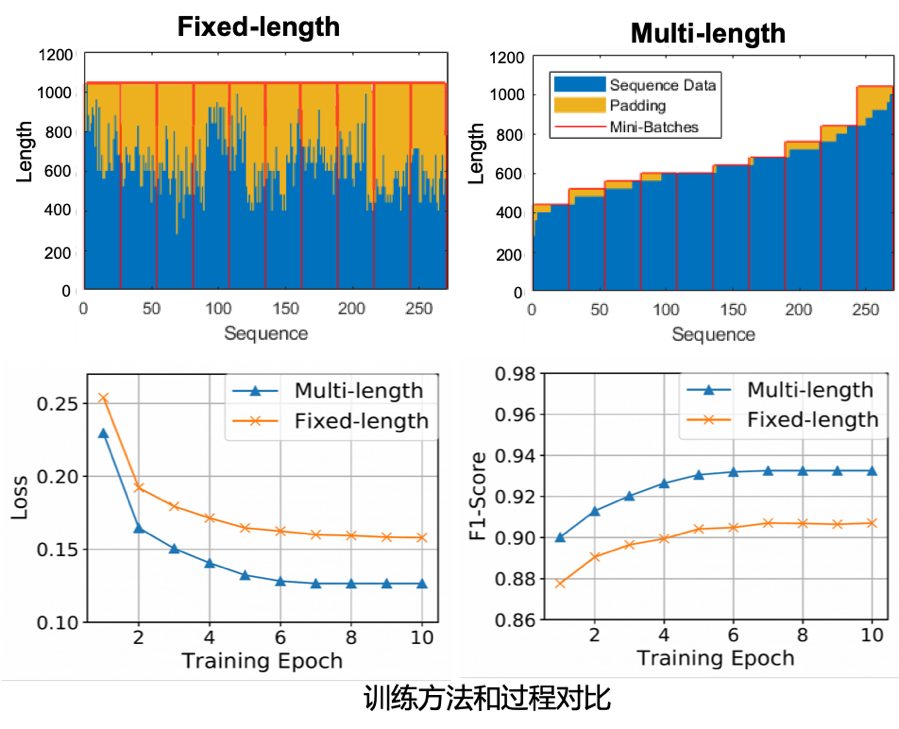
(b)訓(xùn)練加速:Batch Sequence Padding
輸入Range過大給訓(xùn)練階段也帶來了困難,一開始我們采取的是定長(zhǎng)訓(xùn)練,需要補(bǔ)齊大量的padding來計(jì)算,訓(xùn)練時(shí)間較長(zhǎng)。為了減少不相關(guān)padding的干擾,我們采用了Batch Sequence Padding的方法,即讓相同長(zhǎng)度的序列盡可能的放在同一個(gè)batch中實(shí)現(xiàn)變長(zhǎng)訓(xùn)練。這種做法不僅大幅度減少輸入長(zhǎng)度,縮短訓(xùn)練時(shí)間,還顯著提升了模型效果。
■ 3.2 廣告圖片的識(shí)別
廣告圖片的定義是非常寬泛的,像穿衣模特和商品特拍,甚至是廣告文字和二維碼都有可能被認(rèn)定為廣告圖片。并且圖片的特征維度眾多,比如下面的例子,在同一張圖片中同時(shí)出現(xiàn)了多個(gè)維度的特征。另外文字大小和位置和文本語(yǔ)義也存在關(guān)聯(lián),比如業(yè)務(wù)熱線只要出現(xiàn)在圖片中不管大小都會(huì)被認(rèn)為是廣告圖片,而右邊的價(jià)格,只有在占比很大的情況下才會(huì)被認(rèn)為是廣告圖片。這一塊是和優(yōu)圖一起合作的,一開始的方案是將廣告圖片識(shí)別作為了一個(gè)端到端的圖片分類問題,采用了依賴大規(guī)模標(biāo)注的深度模型,這種方法可解釋性較差,并且實(shí)際使用上效果有限。

針對(duì)這些問題和挑戰(zhàn),我們?cè)趦?yōu)圖的基礎(chǔ)之上結(jié)合業(yè)務(wù)特點(diǎn)進(jìn)行了優(yōu)化,采用基于wide&deep模型分而治之。如下圖所示:
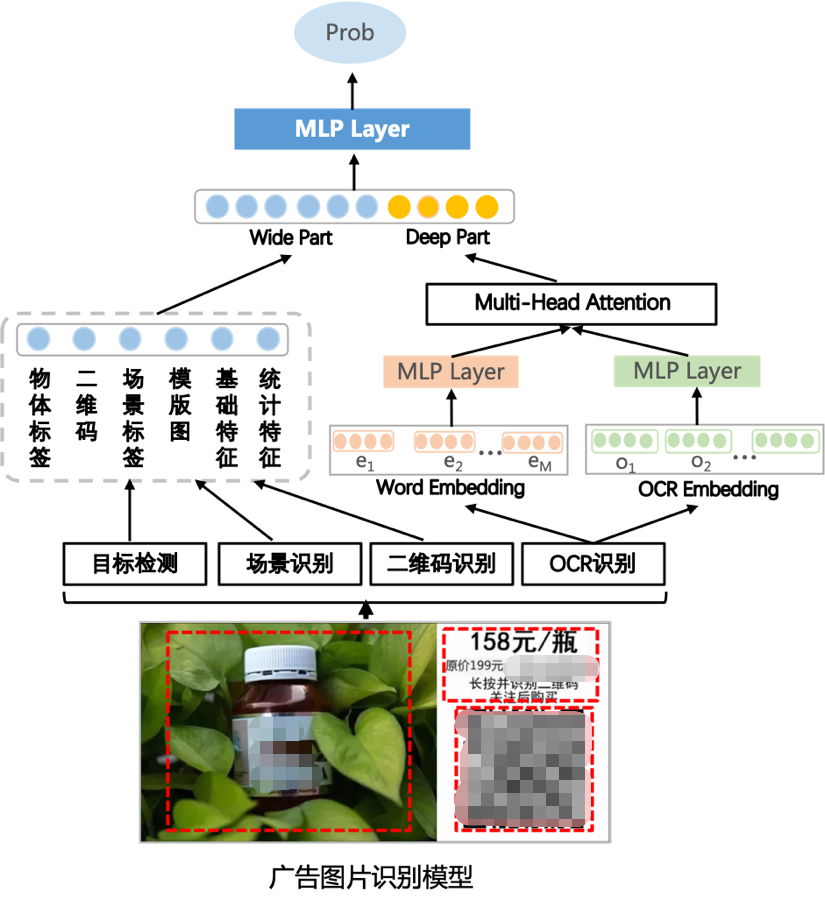
a) Feature Engineering
首先對(duì)圖片的多個(gè)維度進(jìn)行拆解,劃分成多個(gè)不同特征提取模塊,包括目標(biāo)檢測(cè),場(chǎng)景識(shí)別,二維碼和OCR識(shí)別,并不斷完善豐富各個(gè)維度下的標(biāo)簽種類。這樣就能獲得各種數(shù)值型特征和文本Embedding特征。
b) Wide & Deep
這兩種類型的特征非常適合wide&deep模型聯(lián)合學(xué)習(xí),并且在我們的業(yè)務(wù)場(chǎng)景下,性能上有一定要求,而wide&deep模型結(jié)構(gòu)簡(jiǎn)單非常適合大規(guī)模樣本預(yù)測(cè)的場(chǎng)景。
c) Multi-Head Attention
通過多頭注意力機(jī)制來學(xué)習(xí)文字塊大小和文本語(yǔ)義組合之后的語(yǔ)義關(guān)系,進(jìn)一步提升效果。
■ 3.3 廣告文章序列分類
▍3.3.1 文章多模態(tài)分類轉(zhuǎn)化成序列分類問題
通過廣告文字檢測(cè)模型我們可以獲取不同區(qū)域文本片段對(duì)應(yīng)的廣告概率,通過廣告圖片識(shí)別模型我們可以得到圖片的廣告概率,將二者的結(jié)果按文章排版順序組合起來就可以將每一篇文章都轉(zhuǎn)化成一條廣告概率序列。我們將文章位置做橫坐標(biāo)廣告概率為縱坐標(biāo)作圖對(duì)廣告序列進(jìn)行可視化展示,在下面圖中可以直觀的看到不同廣告文章中有哪些廣告區(qū)域以及占比,并呈現(xiàn)出不同的序列模式。這相當(dāng)于我們將一個(gè)復(fù)雜的多模態(tài)文章分類問題轉(zhuǎn)化成序列分類問題,通過前兩個(gè)模型提取出高層次的廣告概率特征來進(jìn)行特征降維。我們通過觀察可以發(fā)現(xiàn)嚴(yán)重廣告文章主要集中在頂部區(qū)域或者比例過大等有限的幾種序列模式。這就大大降低了問題的復(fù)雜度,避免了多模態(tài)端到端分類的組合爆炸,并且模型的可視化具有很高可解釋性。
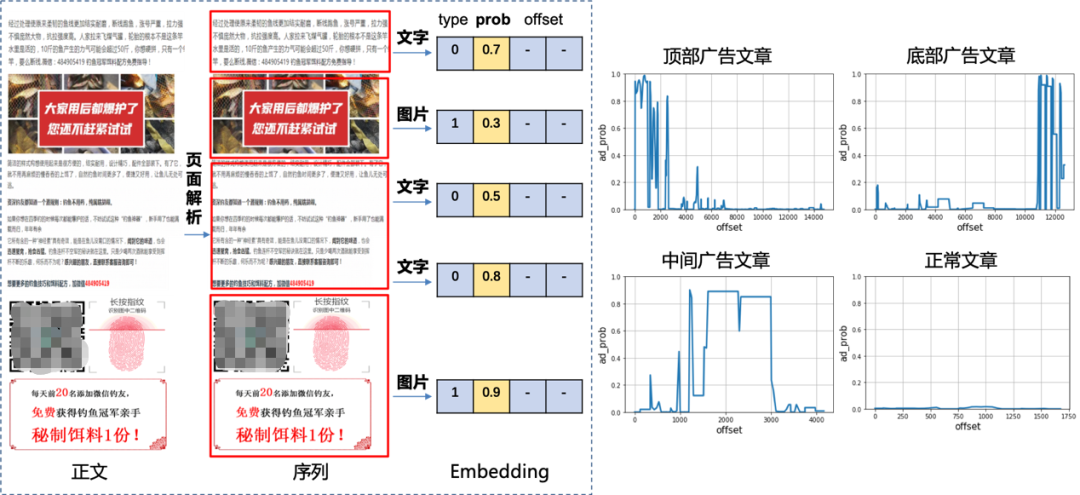
文章序列可視化
▍3.3.2 如何識(shí)別廣告序列模式?
針對(duì)這個(gè)問題我們采用了LSTM+CNN組合的方式進(jìn)行建模,如下圖所示:
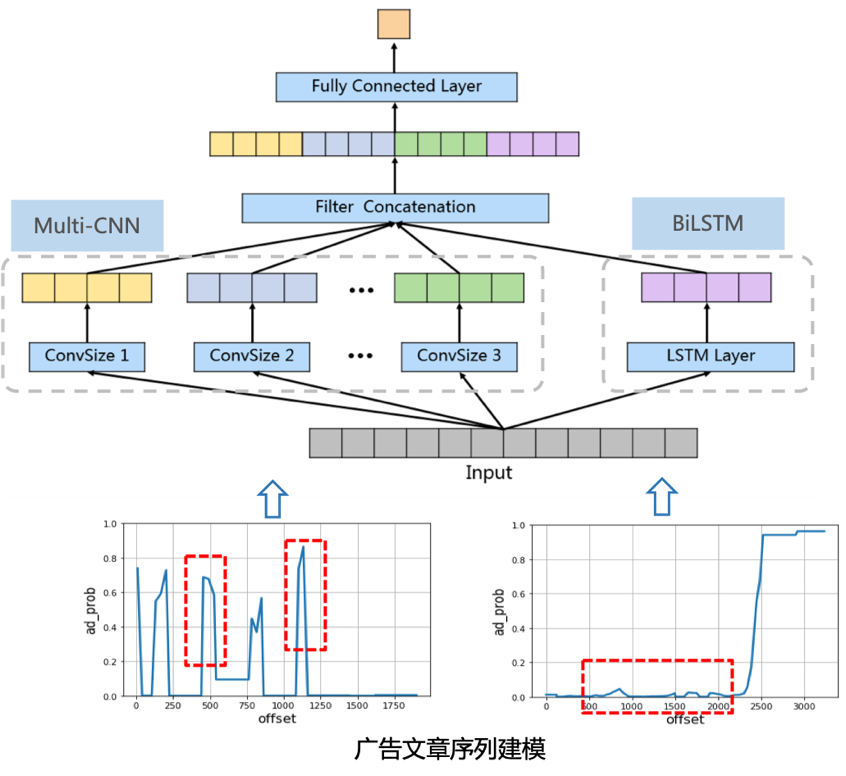
a) BiLSTM: 擬合廣告序列的連續(xù)變化趨勢(shì),比如文章中間一般很少出現(xiàn)廣告
b) Multi-CNN: 利用其強(qiáng)大的局部特征提取能力來捕捉廣告區(qū)域的異常突起,并且通過不同卷積核大小來捕捉不同寬度和高度的突起,從而識(shí)別各種不同的廣告區(qū)域類型。
最后我們將二者提取的特征向量拼接進(jìn)行分類判斷文章是否是嚴(yán)重廣告垃圾文章。
■ 新的挑戰(zhàn):模型的效果和性能存在瓶頸
▍挑戰(zhàn)1:模型無法有效判斷廣告區(qū)域位置
看下面的case,前面是兩張圖片占比很大,底部文字廣告文字可以放過,但模型還是將它誤召回了,分析后發(fā)現(xiàn)我們輸入的序列位置特征不是等間距的,這違背了RNN/LSTM的使用前提,像一句話為什么能用這些序列模型建模,首先一個(gè)前提就是一句話的每個(gè)詞顯然是等間距的。后來我們將多模態(tài)位置特征統(tǒng)一,圖片打散之后有效的解決這問題,模型效果取得了顯著提升。
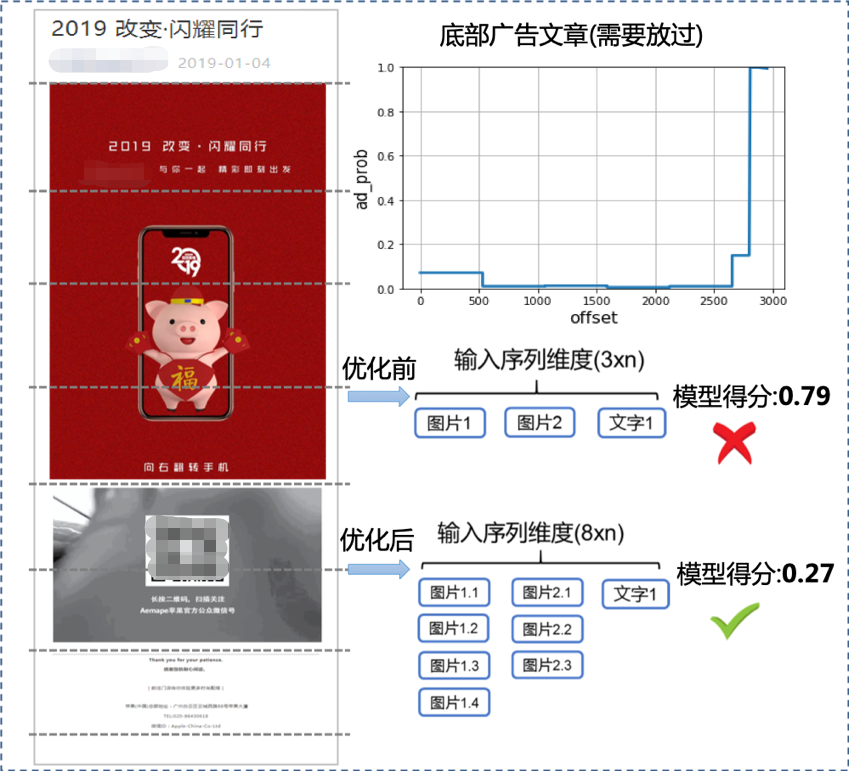
▍挑戰(zhàn)2:文章序列過長(zhǎng)導(dǎo)致模型性能較差
緊接著圖片打散又大幅度增加了序列輸入的長(zhǎng)度,雙向LSTM預(yù)測(cè)2000長(zhǎng)度的序列非常慢,如何在兼顧效果和速度?我們觀察后發(fā)現(xiàn)現(xiàn)在的單點(diǎn)輸入其實(shí)就是文章固定位置上的廣告特征,本質(zhì)上只需要模型學(xué)習(xí)到從文章頂部到底部權(quán)重是不斷降低就行了,可以直接用dense來替換雙向LSTM,實(shí)驗(yàn)結(jié)果也表明我們?cè)谛Ч蛔兊那闆r下,單篇耗時(shí)極大幅度縮短。
總結(jié)與思考
■ 算法模型的更新迭代很大程度依賴于特征工程
整個(gè)系統(tǒng)框架不是一蹴而就的,在一開始的階段,由于提取特征有限,我們也是采取基于規(guī)則策略的方法先解決業(yè)務(wù)問題。而隨著業(yè)務(wù)理解的不斷深入,解決問題所需要的特征維度也越來越多,單純規(guī)則已經(jīng)難以適應(yīng),這時(shí)候才開始用模型來擬合這些特征,并且通過進(jìn)一步的特征分析來確定模型方案。每當(dāng)出新問題時(shí),首先都是分析是否有特征能區(qū)分,然后挖掘新特征,最后根據(jù)特征選擇技術(shù)方案,形成閉環(huán)循環(huán)迭代,不斷優(yōu)化完善整個(gè)系統(tǒng)。
■ 復(fù)雜問題需要分而治之
有的問題并不是能通過單個(gè)維度的特征來解決,比如廣告文章和廣告圖片的識(shí)別都是很多特征維度組合形成的復(fù)雜問題。如果直接采用端到端的深度模型,最終在效果和性能上都不一定適用。所以盡可能的先對(duì)問題進(jìn)行拆解,劃分成多個(gè)子問題來各個(gè)擊破,反而能取得意想不到的效果。
■ 圖像和NLP之間相互借鑒
現(xiàn)如今已經(jīng)不少圖像領(lǐng)域中的trick在nlp中得到應(yīng)用,比如focal loss等。廣告文字檢測(cè)的方法也是從圖像中滑動(dòng)窗口檢測(cè)算法中衍化出來的。但是領(lǐng)域之間還是有一定差別的,不能直接照搬。比如圖像中可以通過放縮得到同樣大小的樣本輸入,而文本卻不行。所以在這個(gè)過程中我們也做了很多適配和創(chuàng)新。
■ 模型效果和性能之間的平衡
模型的效果決定解決問題的多少,而模型的性能直接決定能不能上線。這里涉及到很多工程優(yōu)化方面的工作,包括模型架構(gòu)調(diào)整,特征工程優(yōu)化,實(shí)現(xiàn)負(fù)載均衡等。畢竟我們的算力不是無限的,而是需要在有限資源的情況下解決業(yè)務(wù)問題。通過解決這些問題不僅能加深我們對(duì)模型框架的認(rèn)識(shí)和理解,還能擴(kuò)展對(duì)整個(gè)系統(tǒng)架構(gòu)的認(rèn)知。
微信AI
不描摹技術(shù)的酷炫,不依賴擬人的形態(tài),微信AI是什么?是悄無聲息卻無處不在,是用技術(shù)創(chuàng)造更高效率,是更懂你。
微信AI關(guān)注語(yǔ)音識(shí)別與合成、自然語(yǔ)言處理、計(jì)算機(jī)視覺、工業(yè)級(jí)推薦系統(tǒng)等領(lǐng)域,成果對(duì)內(nèi)應(yīng)用于微信翻譯、微信視頻號(hào)、微信看一看等業(yè)務(wù),對(duì)外服務(wù)王者榮耀、QQ音樂等產(chǎn)品。